由助理设备基于周围感测来推理助理动作的制作方法
由助理设备基于周围感测来推理助理动作
背景技术:
1.人类能够利用在本文中称为“自动助理”(也称为“聊天机器人”、“交互式个人助理”、“智能个人助理”、“个人语音助理”、“谈话代理”等)的交互式软件应用从事人机对话。例如,人类(当与自动助理交互时可以被称为“用户”)可以向自动助理提供显式输入(例如,命令、查询和/或请求),该显式输入能够使自动助理生成并提供响应输出、控制一个或多个物联网(iot)设备,并且/或者执行一个或多个其他功能(例如,助理动作)。由用户提供的此显式输入能够是例如说出的自然语言输入(即,口语话语)和/或键入的自然语言输入,说出的自然语言输入可以在一些情况下被转换成文本(或其他语义表示),然后被进一步处理。
2.在一些情况下,自动助理可以包括自动助理客户端以及基于云的(多个)对应方,该自动助理客户端由助理设备在本地运行并且由用户直接地从事,该基于云的对应方利用云的几乎无限的资源来帮助自动助理客户端对用户的输入做出响应。例如,自动助理客户端能够向(多个)基于云的对应方提供用户的口语话语的音频数据(或其文本转换),以及可选地指示用户的身份的数据(例如,凭证)。基于云的对应方可以对显式输入执行各种处理以将(多个)结果返回给自动助理客户端,该自动助理客户端然后向用户提供对应输出。在其他情况下,自动助理可以由助理设备在本地专门运行并且由用户直接地从事以减少延时。
3.许多用户可以经由助理动作使自动助理从事于执行例程日常任务。例如,用户可以例行地提供使自动助理检查天气、检查上班路线沿途的交通、启动车辆的一个或多个显式用户输入,和/或使自动助理在用户吃早餐时执行其他助理动作的其他显式用户输入。作为另一示例,用户可以例行地提供使自动助理播放特定播放列表、跟踪锻炼的一个或多个显式用户输入,和/或使自动助理执行其他助理动作以为用户去跑步做准备的其他显式用户输入。然而,如果自动助理能够推理用户的周围状态(例如,即将去跑步)和/或用户的环境(例如,厨房)的周围状态,则自动助理能够前摄地建议执行这些助理动作中的一个或多个助理动作,从而减少涉及自动助理的一些显式用户输入并且缩短与自动助理交互的持续时间。另外或替代地,这些助理动作中的一个或多个助理动作能够被自动地执行,从而消除涉及自动助理的一些显式用户输入并且缩短与自动助理交互的持续时间。
技术实现要素:
4.本文中描述的实施方式涉及生成被建议由自动助理代表用户执行的一个或多个建议的动作(例如,例程)。自动助理能够使用周围感测机器学习(ml)模型来处理传感器数据的实例,以生成建议的动作中的一个或多个。传感器数据的实例能够从用户的环境中的一个或多个助理设备获得(例如,从(多个)助理设备的(多个)传感器获得)。在一些实施方式中,能够基于处理传感器数据的实例来确定周围状态,并且周围感测ml模型能够处理该周围状态以生成建议的动作中的一个或多个。在另外或替代的实施方式中,周围感测ml模型能够直接地处理传感器数据的实例以生成建议的动作中的一个或多个。在各种实施方式中,使用周围感测ml模型所生成的一个或多个建议的动作中的每一个能够与对应的预测量
度相关联。在那些实施方式的一些版本中,诸如当与建议的动作中的一个或多个相关联的对应的预测量度满足第一阈值量度但不满足第二阈值量度时,自动助理能够使得建议的动作中的一个或多个的对应表示被提供以供呈现给用户(例如,在视觉上和/或可听地)。在那些实施方式的另外或替代版本中,诸如当与建议的动作中的一个或多个相关联的对应的预测量度满足第一阈值量度和第二阈值量度时,自动助理能够使得代表用户自动地执行建议的动作中的一个或多个。
5.例如,假定给定助理设备是具有显示器并位于用户的主要住所中的交互式独立扬声器设备。进一步假定用户每工作日早晨在主要住所的厨房里制作和/或吃早餐(例如,基于至少捕获用户制作并吃早餐的声音的周围音频数据来确定)。进一步假定,当用户在厨房里制作并吃早餐时,用户通常经由给定助理设备调用自动助理,并且要求自动助理提供用户的当前位置的天气更新和通勤的交通更新。因此,当用户随后在主要住所的厨房里制作和/或吃早餐(例如,基于至少捕获用户制作并吃早餐的声音的后续周围音频数据来确定)时,自动助理能够前摄地向用户建议天气更新和/或交通更新并且/或者自动地提供天气更新和/或交通更新(例如,早餐例程),而没有自动助理曾经被用户显式地调用。
6.在一些实施方式中,能够基于多个训练实例来训练周围感测ml模型。训练实例中的每一个能够包括训练实例输入和训练实例输出。训练实例输入能够包括例如传感器数据的实例和/或基于传感器数据的实例而确定的周围状态。如本文中描述的,传感器数据能够包括由用户的环境中的一个或多个助理设备生成的、与周围感测事件相对应的任何数据。例如,传感器数据的实例能够包括捕获周围噪声或声音的音频数据、捕获用户的环境运动的运动数据、捕获周围中的多个助理设备的配对的配对数据、捕获助理设备中的一个或多个的状态(或状态变化)的设备状态数据、时间数据、和/或由助理设备中的一个或多个生成的其他数据。如本文中描述的,基于传感器数据的实例而确定的周围状态能够是多个根本不同的周围状态(例如,类、类别等)中的一个或多个,该多个根本不同的周围状态可以利用不同程度的粒度来定义。例如,并且参考以上示例,所确定的周围状态可以是早餐周围状态或基于传感器数据的实例而确定的更一般烹饪周围状态,传感器数据包括捕获烹饪声音(例如,食物咝咝响、电器叮当响等)和/或用户吃饭(例如,刀具发叮当声、咀嚼声音等)的周围音频数据。此外,训练实例输出能够包括例如经由助理设备中的一个或多个进行的一个或多个用户发起的时间上对应的动作的指示,时间上对应的动作在时间上对应于传感器数据和/或周围状态的实例。例如,并且参考以上示例,一个或多个时间上对应的动作的指示能够包括天气更新动作、交通更新动作的指示,和/或在处于早餐或烹饪周围状态下时执行的任何其他用户发起的动作的指示。
7.如以上所指出的,在一些实施方式中,训练实例输入能够包括周围状态。在这些实施方式中,可以使用分类器或周围ml模型(例如,其不同于本文中描述的周围感测ml模型)来处理传感器数据的实例,以确定训练实例输入的周围状态。例如,能够处理传感器数据的实例以生成嵌入(例如,较低维度表示),并且能够在嵌入空间中将该嵌入与指配给相应周围状态的多个根本不同的嵌入进行比较。能够基于嵌入空间中所生成的嵌入与指配给相应周围状态的多个根本不同的嵌入之间的距离来确定周围状态。例如,并且关于以上示例,基于处理烹饪声音而生成的音频嵌入可能在嵌入空间中更接近与烹饪周围状态相关联的第一嵌入,而不是与锻炼周围状态相关联的第二嵌入。结果,能够确定周围状态对应于烹饪周
围状态。能够使用周围感测ml模型随后处理周围状态,以在给定周围状态的情况下(可选地使用嵌入空间或另外的嵌入空间)预测一个或多个动作。此外,能够将一个或多个预测的动作(和/或与其相关联的对应的预测量度)与一个或多个时间上对应的动作(和/或与其相关联的真实值量度)的指示进行比较以生成一个或多个损失,并且能够基于损失中的一个或多个更新周围感测ml模型。在另外或替代的实施方式中,可以直接地使用周围感测ml模型来处理传感器数据的实例。在这些实施方式中,能够在嵌入空间中将所生成的嵌入直接地映射到一个或多个预测的动作的指示。换句话说,周围状态可以是使用周围感测ml模型所生成的中间输出,并且能够以相同或类似的方式、但基于中间输出(例如,基于传感器数据的实例而生成的实际嵌入和/或嵌入的语义表示(例如,以上示例中的烹饪周围状态))生成一个或多个预测的动作。值得注意的是,在各种实施方式中,能够完全在一个或多个助理设备处在本地执行本文中描述的技术,使得传感器数据、用户的环境状态、时间上对应的动作的指示、建议的动作的指示和/或本文中描述的任何其他数据不离开助理设备。
8.如以上所指出的,并且在周围感测ml模型的训练之后,能够处理传感器数据的实例以生成被建议以供由自动助理并代表用户执行的一个或多个建议的动作(例如,例程)。在一些实施方式中,能够提供建议的动作中的一个或多个的对应表示以供呈现给用户。例如,响应于确定与建议的动作中的一个或多个相关联的对应的预测量度满足第一阈值量度,但未能满足第二阈值量度,能够提供建议的动作中的一个或多个的对应表示以供呈现给用户。换句话说,如果自动助理认为用户将执行动作,但不高度地确信用户将执行动作,则能够提供建议的动作中的一个或多个的对应表示以供呈现给用户。此外,能够将建议的动作中的一个或多个的对应表示作为可听输出和/或视觉输出来提供以供呈现给用户。例如,自动助理能够生成并输出包括建议的动作中的一个或多个的指示的合成语音(例如,经由一个或多个助理设备的(多个)扬声器),并且用户能够响应于合成语音提供口语输入,该口语输入使自动助理执行建议的动作中的一个或多个。作为另一示例,自动助理能够生成并输出包括建议的动作中的一个或多个的指示的视觉内容(例如,经由一个或多个助理设备的(多个)显示器),并且用户能够响应于视觉内容被渲染来提供对建议的动作中的一个或多个的用户选择,该用户选择使自动助理执行建议的动作中的一个或多个。在另外或替代的实施方式中,能够由自动助理自动地执行建议的动作中的一个或多个(例如,一些或全部)。例如,响应于确定与建议的动作中的一个或多个相关联的对应的预测量度满足第一阈值量度和第二阈值量度,能够自动地执行建议的动作中的一个或多个。
9.在各种实施方式中,能够将响应于建议的动作中的一个或多个的对应表示和/或响应于建议的动作中的一个或多个被自动地执行而接收到的用户输入用作用于更新周围感测ml模型的反馈信号。例如,如果用户使一个或多个建议的动作被执行,则当随后确定了相同的周围状态时,使用周围感测ml模型所生成的一个或多个建议的动作能够被偏向那些动作。作为另一示例,如果用户使一个或多个建议的动作被执行,则能够进一步训练周围感测ml模型以强化生成一个或多个建议的动作的指示。然而,如果用户未选择给定动作(或者使自动助理撤销给定动作),则当获得了指示周围状态的传感器数据的后续实例时,使用周围感测ml模型所生成的一个或多个建议的动作能够被偏离给定动作。以这种方式,周围感测ml模型能够基于当前周围状态生成最有可能由用户发起的建议的动作。
10.通过使用本文中描述的技术,能够实现各种技术优点。作为一个非限制性示例,在
一个或多个建议的动作被提供以供呈现给用户的实施方式中,能够简化显式用户输入(例如,用于执行建议的动作中的一个或多个的单次点击、单次触摸、“是”或“否”,而不是完整口语话语等)以使得建议的动作中的一个或多个的执行。此外,在代表用户自动地执行建议的动作中的一个或多个的实施方式中,可以一起消除用于执行建议的动作中的一个或多个的显式用户输入。此外,在训练周围感测ml模型以基于周围状态和时间上对应的动作针对用户生成建议的动作中的一个或多个时,周围感测ml模型能够更稳定地和/或准确地生成给定周围状态最适合于用户的建议的动作中的一个或多个。结果,能够减少由一个或多个助理设备接收到的用户输入的数量和/或持续时间,因为用户不需要提供自由形式输入来使得建议的动作中的一个或多个被执行,从而通过减少网络业务来节约助理设备中的一个或多个处的计算资源和/或网络资源。
11.以上描述仅作为本公开的一些实施方式的概述被提供。本文中更详细地描述那些实施方式和其他实施方式的进一步描述。作为一个非限制性示例,在本文中包括的权利要求中更详细地描述各种实施方式。
附图说明
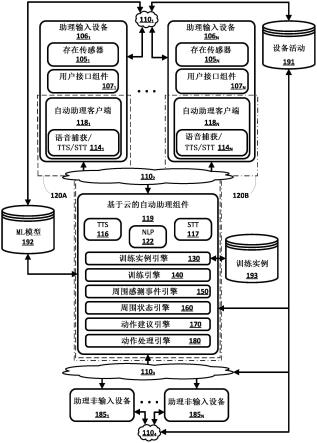
12.图1是其中可以实现本文中公开的实施方式的示例周围的框图。
13.图2是图示依照各种实施方式的生成用于训练周围感测机器学习模型的多个训练实例并且训练该周围感测机器学习模型的示例方法的流程图。
14.图3a和图3b描绘依照各种实施方式的与能够在生成用于训练周围感测机器学习模型的多个训练实例时利用的自动助理的交互的各种非限制性示例。
15.图4是图示依照各种实施方式的使用周围感测机器学习模型的示例方法的流程图。
16.图5a和图5b描绘依照各种实施方式的用户与正在使用周围感测机器学习模型的自动助理的交互的各种非限制性示例。
17.图6描绘依照各种实施方式的计算设备的示例架构。
具体实施方式
18.存在以下大量智能多感测连网设备(在本文中也称为助理设备),诸如智能电话、平板计算机、车辆计算系统、可穿戴计算设备、智能电视、交互式独立扬声器(例如,具有或没有显示器)、声音扬声器、家庭警报器、门锁、相机、照明系统、跑步机、恒温器、体重计、智能床、灌溉系统、车库门开启器、电器、婴儿监视器、火灾警报器、湿度检测器等。常常,多个助理设备位于诸如家庭的结构的界限内—或者位于以下多个相关结构内,诸如用户的主要住宅和用户的次要住宅、用户的车辆和/或用户的工作地点。
19.此外,存在各自包括自动助理客户端的大量助理设备,该自动助理客户端能够形成自动助理(在本文中也称为助理输入设备)的逻辑实例。这些助理输入设备能够只致力于助理功能(例如,包括仅助理客户端和相关接口并只致力于助理功能的交互式独立扬声器和/或独立音频/视觉设备)或者能够执行除了其他功能之外的助理功能(例如,包括助理客户端作为多个应用之一的移动电话或平板)。此外,一些iot设备也能够是助理输入设备。例如,一些iot设备能够包括自动助理客户端和至少(多个)扬声器和/或(多个)麦克风,这些
扬声器和/或麦克风(至少部分地)用作自动助理客户端的助理接口的用户接口输出和/或输入设备。尽管一些助理设备可能未实现自动助理客户端或者具有用于与用户接口的装置(例如,(多个)扬声器和/或(多个)麦克风),但是它们仍然可以由自动助理(在本文中也称为助理非输入设备)控制。例如,智能灯泡可能不包括自动助理客户端、(多个)扬声器和/或(多个)麦克风,但是能够经由自动助理向智能灯泡传送命令和/或请求,以控制智能灯的功能(例如,打开/关闭、调光、改变颜色等)。
20.本文中描述的实施方式涉及经由用户的一个或多个助理设备(例如,(多个)助理输入设备和/或(多个)助理非输入设备)生成要由自动助理代表用户执行的一个或多个建议的动作。能够基于使用周围感测机器学习(ml)模型处理周围状态来生成一个或多个建议的动作,该周围状态反映用户的环境状态和/或用户的环境的周围状态。能够基于至少经由(多个)助理设备中的一个或多个的传感器获得的传感器数据的实例确定周围状态。
21.传感器数据能够包括由用户的助理输入设备和/或用户的助理非输入设备生成的任何数据。例如,传感器数据能够包括:由捕获用户的口语话语、用户的环境中的周围噪声和/或任何其他音频数据的(多个)麦克风生成的音频数据;由捕获用户的移动信息(例如,用户步行、慢跑、步行、骑自行车和/或其他交通模式)的(多个)gps传感器和/或加速度计生成的运动或位置数据;与检测通过一个或多个网络在多个助理输入设备和/或助理非输入设备之间建立或者移除的连接的一个或多个设备相关联的配对数据(例如,与耳机配对的移动设备、与家庭wi-fi网络配对的移动设备等);由用户的环境中的(多个)视觉组件(例如,(多个)相机、(多个)radar传感器、(多个)lidar传感器和/或任何其他视觉组件)生成的视觉数据;一个或多个助理输入设备和/或助理非输入设备的设备状态数据(例如,智能锁的状态、智能灯的状态、智能电器的状态等);和/或由用户的助理输入设备和/或助理非输入设备生成的任何其他数据(例如,诸如由本文中描述的其他存在传感器生成的其他数据)。此外,传感器数据的实例能够包括前述传感器数据的任何组合。值得注意的是,传感器数据的实例不限于与特定时刻相对应的传感器数据。例如,传感器数据的实例能够包括捕获在多个时刻的用户的口语话语和/或用户的环境中的周围噪声的音频数据、捕获在多个时刻的用户的移动信息的运动数据、和/或在多个时刻的应用状态数据和/或设备状态数据。此外,传感器数据的实例能够包括由多个助理输入设备和/或助理非输入设备生成的数据。
22.周围状态能够是可以用不同程度的粒度来定义的多个根本不同的周围状态(例如,类、类别等)中的一个。例如,周围状态可以是一般烹饪周围状态,或更具体地,早餐周围状态、午餐周围状态、晚餐周围状态、小吃周围状态和/或与一般烹饪周围状态相关联的其他周围状态;一般锻炼周围状态,或更具体地,举重周围状态、跑步周围状态、慢跑周围状态、步行周围状态和/或与一般锻炼周围状态相关联的其他周围状态;一般媒体消费周围状态,或更具体地,电视周围状态、音乐周围状态、播客周围状态、新闻周围状态和/或与一般媒体消费周围状态相关联的其他周围状态;一般通信周围状态,或更具体地,谈话周围状态(例如,当面谈话、电话谈话等)、消息周围状态(例如,电子邮件、文本消息、社交媒体消息等)和/或与一般谈话周围状态相关联的其他周围状态;一般房屋维护周围状态,或更具体地,草坪养护周围状态、洗衣房周围状态、清洁周围状态和/或与一般房屋维护周围状态相关联的其他周围状态;一般离开周围状态,或更具体地,在工作周围状态、度假周围状态和/
或与一般离开周围状态相关联的其他周围状态;和/或用不同程度的粒度来定义的其他周围状态。尽管在上面枚举了特定周围状态,但是应该理解,那些是为了举例起见而提供的,而不意在为限制性的。
23.如以上所指出的,能够基于至少传感器数据的实例确定周围状态。在一些实施方式中,诸如当传感器数据的实例包括音频数据或运动数据时,能够处理传感器数据的实例以确定周围状态。例如,在传感器数据的实例包括音频数据和/或运动数据的实施方式中,能够使用分类器或(多个)其他周围ml模型来处理音频数据和/或运动数据,以确定周围状态。例如,假定用户位于他或她的主要住所处,并且假定共同位于用户的主要住所中的给定助理设备生成在早晨时间期间捕获周围噪声的音频数据(例如,经由(多个)麦克风)。进一步假定音频数据使用分类器(或周围噪声检测ml模型)来处理,以生成指示该音频数据捕获以下周围噪声的输出:食物咝咝响、电器叮当响或嗡嗡响和/或刀具在餐具上发叮当声。在此示例中,所确定的周围状态可以对应于烹饪周围状态,或更具体地,早餐周围状态。另外,例如,假定用户紧接在他或她的主要住所外面,并且运动数据是经由移动电话的gps传感器和/或加速度计生成的。进一步假定运动数据使用分类器(或周围运动检测ml模型)来处理,以生成指示运动数据捕获用户步行的输出。在此示例中,所确定的周围状态可以对应于锻炼周围状态,或更具体地,步行状态。另外,在此示例中,周围状态可以对应于离开周围状态,因为用户不再在主要住所中。在另外的或替代实施方式中,诸如当传感器数据的实例包括配对数据和/或设备状态数据时,能够基于传感器数据的实例并且在不用处理传感器数据的实例的情况下确定周围状态。例如,假定用户的移动设备与一个或多个耳机(例如,蓝牙耳机)配对。在此示例中,所确定的周围状态可以对应于媒体消费周围状态和/或谈话周围状态。
24.尽管关于基于传感器数据(例如,音频数据、运动数据、配对数据或设备数据)的实例的离散部分来确定周围状态描述了上面提供的以上示例,但是应该理解,那是为了举例起见,而不意在为限制性的。例如,能够相结合地利用传感器数据的实例的每一个方面来确定周围状态。例如,再次假定用户紧接在他或她的主要住所外面,并且运动数据是经由移动电话的gps传感器和/或加速度计生成的。进一步假定运动数据使用分类器(或周围运动检测ml模型)来处理,以生成指示运动数据捕获用户步行的输出。在此示例中,所确定的周围状态可以对应于锻炼周围状态,或更具体地,如上所述的步行状态。然而,进一步假定用户的移动设备生成捕获当用户正在步行时的周围噪声的音频数据(例如,经由(多个)麦克风)。进一步假定音频数据使用分类器(或周围噪声检测ml模型)来处理,以生成指示音频数据捕获割草机的周围噪声的输出。因此,基于割草机的噪声结合用户步行的组合,所确定的周围状态可以对应于房屋维护周围状态,或更具体地,草坪养护周围状态。
25.现在转向图1,图示了其中可以实现本文中公开的技术的示例周围。该示例周围包括多个助理输入设备106
1-n
(在本文中也简称为“助理输入设备106”)、一个或多个基于云的自动助理组件119、一个或多个助理非输入设备185
1-n
(在本文中也简称为“助理非输入设备185”)、设备活动数据库191、(多个)ml模型数据库192和训练实例数据库193。图1的助理输入设备106和助理非输入设备185在本文中也可以被统称为“助理设备”。
26.助理输入设备106中的一个或多个(例如,全部)能够执行相应的自动助理客户端118
1-n
的相应实例。然而,在一些实施方式中,助理输入设备106中的一个或多个能够可选地
缺少相应的自动助理客户端118
1-n
的实例,并且仍然包括用于接收并处理涉及自动助理的用户输入的引擎和硬件组件(例如,(多个)麦克风、(多个)扬声器、(多个)语音识别引擎、(多个)自然语言处理引擎、(多个)语音合成引擎等)。自动助理客户端118
1-n
的实例能够是与相应的助理输入设备106的操作系统分开的应用(例如,安装在操作系统“之上”)—或者能够替代地由相应的助理输入设备106的操作系统直接地实现。如在下面进一步描述的,自动助理客户端118
1-n
的每个实例能够响应于由相应的助理输入设备106中的任何一个的相应的用户接口组件107
1-n
提供的各种请求来与一个或多个基于云的自动助理组件119可选地交互。此外,并且如在下面同样描述的,助理输入设备106的(多个)其他引擎能够与基于云的自动助理组件119中的一个或多个可选地交互。
27.能够在一个或多个计算系统(例如,统称为“云”或“远程”计算系统的服务器)上实现一个或多个基于云的自动助理组件119,该计算系统经由一个或多个局域网(“lan”,包括wi-fi lan、蓝牙网络、近场通信网络、网状网络等)、广域网(“wan”,包括互联网等)和/或其他网络通信地耦合到相应的助理输入设备106。基于云的自动助理组件119与助理输入设备106的通信耦合通常由图1的1101指示。另外,在一些实施方式中,助理输入设备106可以经由通常由图1的1102指示的一个或多个网络(例如,lan和/或wan)彼此通信地耦合。
28.一个或多个基于云的自动助理组件119也能够经由一个或多个网络(例如,lan、wan和/或其他网络)与助理非输入设备185通信地耦合。基于云的自动助理组件119与(多个)助理非输入系统180的通信耦合通常由图1的1103指示。在一些实施方式中,一个或多个对应的助理非输入系统(为了清楚起见未描绘)能够经由一个或多个网络(例如,lan、wan和/或(多个)其他网络)通信地耦合到助理非输入设备185中的一个或多个(例如,组)。例如,第一助理非输入系统能够与助理非输入设备185中的一个或多个的第一组通信地耦合并从其接收数据,第二助理非输入系统能够与助理非输入设备185中的一个或多个的第二组通信地耦合并从其接收数据,依此类推。另外,在一些实施方式中,助理非输入设备185中的一个或多个(例如,组或全部)可以经由通常由图1的1104指示的一个或多个网络(例如,lan、wan和/或(多个)其他网络)彼此通信地耦合。图1的网络110
1-4
在本文中也可以被统称为“(多个)网络110”。
29.自动助理客户端118的实例,通过其与基于云的自动助理组件119中的一个或多个的交互,可以形成从用户的角度来看似乎是用户可以与其从事人机对话的自动助理的逻辑实例的东西。在图1中描绘了这样的自动助理的两个实例。由虚线涵盖的第一自动助理120a包括助理输入设备1061的自动助理客户端1181和一个或多个基于云的自动助理组件119。由虚点线涵盖的第二自动助理120b包括助理输入设备106n的自动助理客户端118n和一个或多个基于云的自动助理组件119。图1的第一自动助理120a和第二自动助理在本文中也可以被简称为“自动助理120”。因此应该理解,与在助理输入设备106中的一个或多个上运行的自动助理客户端118接洽的每个用户实际上可以与他或她自己的自动助理的逻辑实例(或在用户的家庭或其他组当中共享和/或在多个自动助理客户端118当中共享的自动助理的逻辑实例)接洽。尽管在图1中图示了仅多个助理输入设备106,但是理解,(多个)基于云的自动助理组件119能够另外为助理输入设备的许多另外的组服务。此外,尽管基于云的自动助理组件119的各种引擎在本文中被描述为与自动助理客户端118分开实现(例如,在(多个)服务器处),但是应该理解,这是为了举例起见,而不意在为限制性的。例如,关于基于云的
自动助理组件119描述的引擎中的一个或多个(例如,全部)能够由助理输入设备106中的一个或多个在本地实现。
30.例如,助理输入设备106可以包括以下的一个或多个:台式计算设备、膝上型计算设备、平板计算设备、移动电话计算设备、用户的车辆的计算设备(例如,车载通信系统、车载娱乐系统、车载导航系统)、交互式独立扬声器(例如,具有或没有显示器)、诸如智能电视或智能洗衣机/烘干机的智能电器、包括计算设备的用户的可穿戴装置(例如,具有计算设备的用户的手表、具有计算设备的用户的眼镜、虚拟或增强现实计算设备)、和/或能够接收涉及自动助理120的用户输入的任何iot设备。可以提供另外和/或替代的助理输入设备。助理非输入设备185可以包括许多与助理输入设备106相同的设备,但是不能够接收涉及自动助理120的用户输入(例如,不包括(多个)用户接口输入组件)。尽管助理非输入设备185不接收涉及自动助理120的用户输入,但是助理非输入设备185可以仍然由自动助理120控制。
31.在一些实施方式中,多个助理输入设备106和助理非输入设备185能够以各种方式彼此相关联以有助于本文中描述的技术的执行。例如,在一些实施方式中,多个助理输入设备106和助理非输入设备185可以借助于经由一个或多个网络(例如,经由图1的(多个)网络110)通信地耦合彼此相关联。这可以是例如跨诸如家庭、建筑物等的特定区域或周围部署多个助理输入设备106和助理非输入设备185的情况。另外或替代地,在一些实施方式中,多个助理输入设备106和助理非输入设备185可以借助于它们是协调生态系统的成员彼此相关联,该成员至少可由一个或多个用户(例如,个人、家庭、组织的雇员、其他预定义组等)选择性地访问。在那些实施方式中的一些实施方式中,多个助理输入设备106和助理非输入设备185的生态系统能够在该生态系统的设备拓扑表示中手动地和/或自动地彼此相关联。
32.助理非输入设备185和对应的非输入系统能够包括一个或多个第一方(1p)设备和系统和/或一个或多个第三方(3p)设备和系统。1p设备或系统引用由与本文中引用的控制自动助理120方相同的一方控制的系统。相比之下,3p设备或系统引用由与本文中引用的控制自动助理120方不同的一方控制的系统。
33.助理非输入设备185能够通过(多个)网络110并可选地经由对应的(多个)助理非输入系统向自动助理120选择性地传送数据(例如,(多个)状态、(多个)状态变化、和/或其他数据)。例如,假定助理非输入设备1851是智能门铃iot设备。响应于个人按压门铃iot设备上的按钮,门铃iot设备能够直接地向自动助理120和/或向由门铃的制造商管理的可以是1p系统或3p系统的(多个)助理非输入系统传送对应数据。自动助理120(或助理非输入系统)能够基于此类数据来确定门铃iot设备的状态变化。例如,自动助理120(或助理非输入系统)能够确定门铃从不活动状态(例如,最近未按压按钮)到活动状态(最近按压按钮)的变化。值得注意的是,尽管在助理非输入设备1851处接收到用户输入(例如,按压门铃上的按钮),但是用户输入不涉及自动助理120(因此术语“助理非输入设备”)。作为另一示例,假定助理非输入设备1851是具有(多个)麦克风的智能恒温器iot设备,但是该智能恒温器不包括自动助理客户端118。个人能够与智能恒温器交互(例如,使用触摸输入或口语输入)以改变温度,设定特定值作为用于经由智能恒温器控制hvac系统的设定点等。然而,个人不能经由智能恒温器与自动助理120直接地通信,除非智能恒温器包括自动助理客户端118。
34.在各种实施方式中,助理输入设备106中的一个或多个可以包括一个或多个相应的存在传感器105
1-n
(在本文中也简称为“存在传感器105”),这些存在传感器105被配置成
在来自(多个)对应用户的批准情况下,提供指示检测到的存在特别是人类存在的信号。在那些实施方式中的一些实施方式中,自动助理120能够标识助理输入设备106中的一个或多个以满足来自用户的口语话语,该口语话语至少部分地基于助理输入设备106中的一个或多个处的用户的存在或助理输入设备106中的一个或多个的存在与生态系统相关联。通过使助理输入设备106和/或助理非输入设备185中的一个或多个基于口语话语被控制,和/或通过使一个或多个助理输入设备106和/或助理非输入设备185执行任何其他动作以满足口语话语,通过在助理输入设备106中的一个或多个处渲染响应内容(例如,可听地和/或在视觉上)能够满足口语话语。如本文中描述的,自动助理120能够在基于用户在附近或最近在附近的地方确定那些助理输入设备106时利用基于相应的存在传感器105确定的数据,并且向仅那些助理输入设备106提供对应命令。在一些另外或替代的实施方式中,自动助理120能够在确定任何(多个)用户(任何用户或特定用户)当前是否接近于助理输入设备106的任一个时利用基于相应的存在传感器105确定的数据,并且能够在确定了没有用户(任何用户或特定用户)接近助理输入设备106的任一个的情况下可选地抑制命令的提供。
35.相应的存在传感器105可以以各种形式出现。一些助理输入设备106可以被配备有一个或多个数码相机,该一个或多个数码相机被配置成捕获并提供指示在其视场中检测到的移动的(多个)信号。另外,或替代地,一些助理输入设备106可以被配备有其他类型的基于光的存在传感器105,诸如无源红外(“pir”)传感器,该pir传感器测量从其视场内的对象辐射的红外(“ir”)光。另外,或替代地,一些助理输入设备106可以被配备有检测声学(或压力)波的存在传感器105,诸如一个或多个麦克风。此外,除了助理输入设备106之外,助理非输入设备185中的一个或多个还能够另外或替代地包括本文中描述的相应的存在传感器105,并且自动助理120能够另外在根据本文中描述的实施方式确定是否和/或如何满足口语话语时利用来自此类传感器的信号。
36.另外,或替代地,在一些实施方式中,存在传感器105可以被配置成检测与生态系统中的人类存在或设备存在相关联的其他现象。例如,在一些实施方式中,助理设备106、185中的给定一者可以被配备有存在传感器105,该存在传感器105检测由例如由特定用户携带/操作的其他助理设备(例如,移动设备、可穿戴计算设备等)和/或生态系统中的其他助理设备发出的各种类型的无线信号(例如,诸如无线电波、超声波、电磁波等的波)。例如,一些助理设备106、185可以被配置成发出不可被人类感知的波,诸如超声波或红外波,这些波可以被助理输入设备106中的一个或多个检测到(例如,经由诸如有超声能力的麦克风的超声/红外接收器)。
37.另外,或替代地,各种助理设备可以发出其他类型的人类不可感知的波,诸如可以被由特定用户携带/操作的其他助理设备(例如,移动设备、可穿戴计算设备等)检测到并且用于确定操作用户的特定位置的无线电波(例如,wi-fi、蓝牙、蜂窝等)。在一些实施方式中,gps和/或wi-fi三角测量可以被用于检测人的位置,例如,基于到/来自助理设备的gps和/或wi-fi信号。在其他实施方式中,诸如飞行时间、信号强度等的其他无线信号特性可以由各种助理设备单独或共同地使用,以基于由特定用户携带/操作的其他助理设备所发出的信号来确定特定人的位置。
38.另外,或替代地,在一些实施方式中,助理输入设备106中的一个或多个可以执行语音识别以从用户的声音识别用户。例如,自动助理120的一些实例可以被配置成将声音与
用户的简档匹配,例如,出于提供/限制对各种资源的访问的目的。在一些实施方式中,讲话者的移动然后可以例如由助理设备106、185中的一个或多个的存在传感器105(以及可选地gps传感器和/或加速度计)确定。在一些实施方式中,基于这种检测到的移动,可以预测用户的位置,并且当至少部分地基于那些(多个)助理设备与用户的位置的接近度来使任何内容被渲染在助理设备106、185中的一个或多个处时,可以将此位置假定为用户的位置。在一些实施方式中,可以简单地假定用户处于他或她与自动助理120接洽的最后位置中,尤其是在自最后接洽以来尚未经过多少时间的情况下。
39.每一个助理输入设备106进一步包括相应的用户接口组件107
1-n
(在本文中也简称为“用户接口组件107”),它们能够各自包括一个或多个用户接口输入设备(例如,麦克风、触摸屏、键盘和/或其他输入设备)和/或一个或多个用户接口输出设备(例如,显示器、扬声器、投影仪和/或其他输出设备)。作为一个示例,助理输入设备1061的用户接口组件1071能够包括仅(多个)扬声器和(多个)麦克风,然而助理输入设备106n的用户接口组件107n能够包括(多个)扬声器、触摸屏和(多个)麦克风。另外,或替代地,在一些实施方式中,助理非输入设备185可以包括(多个)用户接口组件107的一个或多个用户接口输入设备和/或一个或多个用户接口输出设备,但是用于助理非输入设备185的用户输入设备(若有的话)可能不允许用户直接地与自动助理120交互。
40.助理输入设备106中的每一个和/或操作基于云的自动助理组件119中的一个或多个的(多个)任何其他计算设备可以包括用于存储数据和软件应用的一个或多个存储器、用于访问数据并运行应用的一个或多个处理器、以及有助于通过网络通信的其他组件。由助理输入设备106中的一个或多个和/或由自动助理120执行的操作可以跨多个计算机系统分布。可以将自动助理120实现为例如在一个或多个位置中通过网络(例如,图1的(多个)网络110)彼此耦合的一个或多个计算机上运行的计算机程序。
41.如以上所指出的,在各种实施方式中,助理输入设备106中的每一个可以操作相应的自动助理客户端118。在各种实施方式中,每个自动助理客户端118可以包括相应的语音捕获/文本至语音(tts)/语音至文本(stt)模块114
1-n
(在本文中也简称为“语音捕获/tts/stt模块114”)。在其他实施方式中,相应的语音捕获/tts/stt模块114的一个或多个方面可以与相应的自动助理客户端118分开地实现(例如,由基于云的自动助理组件119中的一个或多个实现)。
42.每个相应的语音捕获/tts/stt模块114可以被配置成执行一个或多个功能,包括例如:捕获用户的语音(语音捕获,例如,经由相应的(多个)麦克风(其在一些情况下可以包括存在传感器105中的一个或多个));使用存储在(多个)ml模型数据库192中的(多个)语音识别模型来将所捕获的音频转换为文本和/或转换为其他表示或嵌入(stt);和/或使用存储在(多个)ml模型数据库192中的(多个)语音合成模型来将文本转换为语音(tts)。这些模型的(多个)实例可以被在本地存储在每一个相应的助理输入设备106处和/或可由助理输入设备访问(例如,通过图1的(多个)网络110)。在一些实施方式中,因为助理输入设备106中的一个或多个在计算资源(例如、处理器周期、存储器、电池等)方面可能相对地受约束,所以对于助理输入设备106中的每一个本地的相应的语音捕获/tts/stt模块114可以被配置成使用(多个)语音识别模型来将有限数目的不同口语短语转换为文本(或者转换为其他形式,诸如较低维数嵌入)。其他语音输入可以被发送到基于云的自动助理组件119中的一
个或多个,其可以包括基于云的tts模块116和/或基于云的stt模块117。
43.基于云的stt模块117可以被配置成利用云的几乎无限的资源来使用存储在(多个)ml模型数据库192中的(多个)语音识别模型来将由语音捕获/tts/stt模块114捕获的音频数据转换成文本(其然后可以被提供给自然语言处理(nlp)模块122)。基于云的tts模块116可以被配置成利用云的几乎无限的资源来使用存储在(多个)ml模型数据库192中的(多个)语音合成模型来将文本数据(例如,由自动助理120制定的文本)转换成计算机生成的语音输出。在一些实施方式中,基于云的tts模块116可以将计算机生成的语音输出提供给助理设备106、185中的一个或多个以被直接地输出,例如,使用相应助理设备的(多个)相应扬声器来输出。在其他实施方式中,由自动助理120使用基于云的tts模块116生成的文本数据(例如,包括在命令中的客户端设备通知)可以被提供给相应助理设备的语音捕获/tts/stt模块114,该语音捕获/tts/stt模块114然后可以使用(多个)语音合成模型来将文本本地数据转换成计算机生成的语音,并且使计算机生成的语音经由相应助理设备的(多个)本地扬声器被渲染。
44.nlp模块122处理由用户经由助理输入设备106生成的自然语言输入并且可以生成带注释的输出以供自动助理120、助理输入设备106和/或助理非输入设备185的一个或多个其他组件使用。例如,nlp模块122可以处理由用户经由助理输入设备106的一个或多个相应的用户接口输入设备生成的自然语言自由格式输入。基于处理自然语言自由形式输入而生成的带注释的输出可以包括自然语言输入的一个或多个注释以及可选地自然语言输入的词语中的一个或多个(例如,全部)。
45.在一些实施方式中,nlp模块122被配置成标识并注释自然语言输入中的各种类型的语法信息。例如,nlp模块122可以包括语音标记器的一部分,该语音标记器被配置成利用词语的语法作用来注释词语。在一些实施方式中,nlp模块122可以另外或替代地包括实体标记器(未描绘),该实体标记器被配置成注释一个或多个分段中的实体引用,诸如对人们(包括例如文学角色、名人、公众人物等)、组织、位置(真实的和想象的)等的引用。在一些实施方式中,关于实体的数据可以被存储在一个或多个数据库中,诸如在知识图(未描绘)中。在一些实施方式中,知识图可以包括表示已知实体(以及在一些情况下,实体属性)的节点,以及连接节点并表示实体之间的关系的边。
46.nlp模块122的实体标记器可以在高粒度水平(例如,以能够标识对诸如人们的实体类的所有引用)和/或较低粒度水平(例如,以能够标识对诸如特定人的特定实体的所有引用)下注释对实体的引用。实体标记器可以依靠自然语言输入的内容来解析特定实体并且/或者可以可选地与知识图或其他实体数据库通信以解析特定实体。
47.在一些实施方式中,nlp模块122可以另外和/或替代地包括共指解析器(未描绘),该共指解析器被配置成基于一个或多个上下文线索来将对同一实体的引用进行分组或“聚类”。例如,基于在紧接在接收自然语言输入“lock it(锁定它)”之前渲染的客户端设备通知中提及了“front door lock(前门锁)”,可以利用共指解析器来将自然语言输入“lock it”中的词语“it”解析为“front door lock”。
48.在一些实施方式中,nlp模块122的一个或多个组件可以依靠来自nlp模块122的一个或多个其他组件的注释。例如,在一些实施方式中,命名的实体标记器可以依靠来自在注释对特定实体的所有提及时的共指解析器和/或依赖分析器的注释。另外,例如,在一些实
施方式中,共指解析器可以依靠来自在将对同一实体的引用进行聚类时的依赖分析器的注释。在一些实施方式中,在处理特定自然语言输入时,nlp模块122的一个或多个组件可以使用特定自然语言输入之外的相关数据来确定一个或多个注释—诸如紧接在接收助理输入设备通知基于的自然语言输入之前渲染的助理输入设备通知。
49.在各种实施方式中,一个或多个基于云的自动助理组件119可以进一步包括各种引擎。例如,如图1所示,一个或多个基于云的自动助理组件119可以进一步包括训练实例引擎120、训练引擎130、周围感测事件引擎150、动作建议引擎170和动作处理引擎180。尽管在图1中这些各种引擎被描绘为一个或多个基于云的自动助理组件119,但是应该理解,那是为了举例起见,而不意在为限制性的。例如,助理输入设备106可以包括这些各种引擎中的一个或多个。作为另一示例,这些各种引擎能够跨助理输入设备106和/或一个或多个基于云的自动助理组件119分布。
50.在一些实施方式中,训练实例引擎130能够生成一个或多个训练实例,该一个或多个训练实例被利用来训练周围感测ml模型(例如,关于图2、图3a和图3b所描述的)。训练实例中的每一个能够包括训练实例输入和训练实例输出。训练实例输出能够包括例如基于传感器数据和/或时间数据的实例而确定的周围状态。训练实例输出能够包括例如时间上对应于周围状态的一个或多个时间上对应的动作的指示。一个或多个时间上对应的动作能够是由用户经由助理设备106、185中的一个或多个(例如,关于图3a和图3b所描述的)执行的用户发起的动作。此外,如果在正在由助理设备中的一个或多个捕获的传感器数据的实例的阈值持续时间内检测到一个或多个时间上对应的动作,则能够认为该一个或多个时间上对应的动作时间上对应于周围状态。在各种实施方式中,训练实例中的一个或多个能够被存储在一个或多个数据库(例如,(多个)训练实例数据库193)中。在另外或替代的实施方式中,训练实例引擎130能够从一个或多个源(例如,1p源和/或3p源)获得一个或多个训练实例(例如,训练实例输入和/或训练实例输出),诸如基于来自一个或多个应用编程接口(api)的能够作为用于给定训练实例的训练实例输入被利用的传感器数据的实例而确定的周围状态。如本文中描述的,本文中描述的周围感测ml模型被训练(基于训练实例中的一个或多个)以生成一个或多个建议的动作,该一个或多个建议的动作被建议以供自动助理120经由助理设备106、185中的一个或多个代表用户执行。
51.在一些实施方式中,如果传感器数据的给定实例对应于周围感测事件,则训练实例引擎130可以仅基于传感器数据的给定实例来生成训练实例中的一个或多个。例如,自动助理120能够使周围感测事件引擎150处理传感器数据的给定实例以确定它是否事实上对应于周围感测事件。周围感测事件引擎150能够基于例如包括以下各项的传感器数据的给定实例来确定传感器数据的给定实例对应于周围感测事件:捕获特定噪声和/或高于阈值噪声水平的噪声的音频数据(经由上述存在传感器105中的一个或多个捕获)、捕获特定持续时间的移动信息和/或指示特定助理设备(例如,移动电话)被握持并且可选地被以特定角度握持的运动数据(例如,经由上述存在传感器105中的一个或多个捕获)、捕获(多个)网络110上的一个或多个特定助理设备106、185的配对信息(例如,蓝牙耳机和移动设备、移动设备和助理输入设备中的特定一个(例如,车载助理设备))的配对数据、检测助理设备106、185中的一个或多个中的状态变化和/或一些其他设备事件(例如,特定状态被维持达特定时间量)的设备状态数据、和/或时间数据。尽管训练实例引擎130可以仅在传感器数据的给
定实例对应于周围感测事件的情况下生成训练实例中的一个或多个,但是应该注意,传感器数据的给定实例能够包括在确定了给定实例对应于周围感测事件之前、期间和/或之后捕获的传感器数据。例如,传感器数据能够被存储在某个短期存储器(例如,缓冲器或其他短期存储器)中达阈值持续时间。如果确定了传感器数据的给定实例事实上确实对应于周围感测事件,则能够从短期存储器中检索并且在确定周围状态时利用传感器数据。
52.换句话说,周围感测事件引擎150能够防止基于偶然周围感测器数据生成训练实例,使得所得的训练实例事实上确实对应于应该为其生成一个或多个建议的动作的周围感测事件。例如,假定传感器数据的实例包括经由位于用户的主要住所中的给定助理设备的麦克风捕获的音频数据。进一步假定音频数据使用存储在(多个)ml模型数据库192中的分类器或(多个)其他周围ml模型来处理,该分类器或其他周围ml模型被训练成将音频数据分类成一个或多个根本不同的类别。进一步假定确定了音频数据捕获割草机和除草机的声音,但是由割草机和除草机引起的噪声未能满足噪声阈值。在此示例中,由割草机和除草机引起的噪声可能是由执行草坪养护的邻居引起的。因此,执行草坪养护的邻居不应该被认为是针对用户或用户的环境的周围感测事件。作为另一示例,假定传感器数据的实例包括经由用户的移动设备的(多个)gps传感器和/或加速度计捕获的运动数据。进一步假定确定了运动数据捕获用户在主要住所外面步行,但是步行达到短持续时间并且用户从未将任何其他设备与移动设备配对。在此示例中,步行可以对应于用户步行到邮箱去取回邮件。因此,可能不将用户仅仅步行去取得邮件认为是针对用户或用户的环境的周围感测事件。
53.在一些实施方式中,周围状态引擎160能够基于传感器数据的实例(并且可选地响应于周围感测事件引擎150确定传感器数据的实例事实上确实对应于周围感测事件)来确定周围状态。能够将周围状态用作给定训练实例的训练实例输入。周围状态能够反映用户的环境状态或用户的环境的周围状态。周围状态能够是可以如本文中描述的那样利用不同程度的粒度定义的多个根本不同的周围状态(例如,类、类别等)中的一个。在那些实施方式的版本中,周围状态引擎160能够基于传感器数据的实例直接地确定周围状态。在另外或替代的实施方式中,周围状态引擎160能够使用存储在(多个)ml模型数据库中的(多个)各种分类器和/或(多个)周围ml模型来处理传感器数据的实例以确定周围状态。
54.例如,在传感器数据的实例包括音频数据的实施方式中,周围状态引擎160能够在确定周围状态时利用分类器或周围噪声检测ml模型(例如,存储在(多个)ml模型数据库192中)来处理音频数据。能够使用例如监督学习技术来训练周围噪声检测ml模型。例如,能够获得多个训练实例。训练实例中的每一个能够包括训练实例输入和训练实例输出,该训练实例输入包括捕获周围噪声的音频数据,该训练实例输出包括训练实例输入是否包括(多个)周围噪声检测模型正被训练成检测的(多个)特定声音的指示。例如,如果周围噪声检测模型正被训练成检测厨房噪声,则包括食物烹饪声、餐具发叮当声等的正训练实例能够被指配标签(例如,“是”或“烹饪”)或值(例如,“1”),而不包括厨房声音的负训练实例能够被指配不同标签(例如,“否”或与诸如“草坪养护”、“锻炼”等的另一周围状态相关联的标签)或值(例如,“0”)。作为另一示例,在传感器数据的实例包括运动数据的实施方式中,周围状态引擎160能够在确定周围状态时利用分类器或周围运动检测模型(例如,存储在(多个)ml模型数据库192中)来处理运动数据。能够以关于周围噪声检测模型描述的相同或类似方式、但是使用各自包括与运动数据相对应的训练实例输入和与不同类型的运动相对应的训
练实例输出的训练实例来训练周围运动检测模型。
55.在一些实施方式中,能够利用周围噪声检测ml模型来基于音频数据(或其声学特征,诸如梅尔倒谱频率系数、原始音频波形和/或其他声学特征)来生成音频嵌入(例如,周围噪声的实例的较低维表示,诸如嵌入)。这些嵌入能够是嵌入空间内的点,其中类似的声音(或捕获声音的声学特征)与嵌入空间的相同或类似部分相关联。此外,嵌入空间的这些部分能够与多个根本不同的周围状态中的一个或多个相关联,并且如果这些嵌入中的给定一个与嵌入空间的各部分中的一个或多个之间的距离度量满足距离阈值,则能够将这些嵌入中的给定一个分类成周围状态中的给定一个。例如,食物烹饪的实例能够与嵌入空间的与“食物烹饪”声音相关联的第一部分相关联,餐具发叮当声的实例能够与嵌入空间的与“餐具发叮当声”声音相关联的第二部分相关联,割草机轰鸣的实例能够与嵌入空间的与“割草机”声音相关联的第三部分相关联,依此类推。在此示例中,嵌入空间的与“食物烹饪”声音相对应的第一部分和嵌入空间的与“餐具发叮当声”声音相对应的第二部分可能在嵌入空间中相对靠近,因为它们是“厨房噪声”。然而,嵌入空间的第三部分可能在嵌入空间中相对较远,因为它对应于“草坪养护”声音。类似地,能够利用周围运动检测模型在与音频嵌入相同的嵌入空间或与音频嵌入不同的嵌入空间中生成运动嵌入。
56.在一些实施方式中,训练引擎140能够利用训练实例中的一个或多个来训练周围感测ml模型(例如,使用监督学习技术)。周围感测ml模型能够是神经网络,例如卷积模型、长短期记忆(lstm)模型、变换器模型、和/或能够处理周围状态和/或传感器数据的实例以生成一个或多个建议的动作的任何其他模型,该一个或多个建议的动作被建议以供自动助理120经由助理设备106、185中的一个或多个代表用户执行。例如,对于给定训练实例,训练引擎140能够使周围感测ml模型处理训练实例输入。在处理训练实例输入时,周围感测ml模型能够生成用户将基于所确定的周围状态执行的一个或多个预测的动作的指示。能够将用户将基于所确定的周围状态执行的一个或多个预测的动作的指示与训练实例输出中包括的一个或多个时间上对应的动作的指示进行比较以生成一个或多个损失。此外,能够基于损失中的一个或多个更新周围感测ml模型。例如,如果一个或多个预测的动作的指示与一个或多个时间上对应的动作的指示不同,则可以生成一个或多个损失。例如,如果一个或多个预测的动作包括发起经由音乐应用播放跑步播放列表和经由锻炼应用跟踪跑步的预测的动作的指示,但是时间上对应的动作的指示指示用户仅发起了经由音乐应用播放跑步播放列表并且确实未经由锻炼应用跟踪跑步,则能够生成一个或多个损失,其指示不应该基于给定周围状态来预测跟踪跑步。然而,如果一个或多个预测的动作的指示与一个或多个时间上对应的动作的指示相同,则一个或多个损失可以是零或接近零(例如,时间上对应的动作的指示指示用户既发起了跑步播放列表的播放又发起了跑步的跟踪)。
57.在那些实施方式的一些版本中,一个或多个预测的动作中的每一个能够与对应的预测量度相关联。对应的预测量度能够是例如对应概率、对数可能性、二进制值和/或指示是否应该建议给定预测的动作以供自动助理120经由助理设备106、185中的一个或多个代表用户执行的任何其他量度。在这些实施方式中,一个或多个损失能够另外或替代地基于预测量度。例如,如果一个或多个预测的动作包括发起按0.9的概率经由音乐应用播放跑步播放列表和按0.6的概率经由锻炼应用跟踪跑步的预测的动作的指示,但是时间上对应的动作的指示指示用户仅发起了经由音乐应用播放跑步播放列表(例如,与真实值量度或概
率1.0相关联),但是确实未经由锻炼应用跟踪跑步(例如,与真实值量度或概率0.0相关联),则能够生成一个或多个损失,其指示不应该基于给定周围状态并且进一步基于预测量度与真实值量度之间的差异来预测跟踪跑步。
58.在各种实施方式中,能够将被利用来处理包括在传感器数据的实例中的音频数据和/或运动数据以确定周围的分类器或(多个)周围ml模型与周围感测ml模型以端到端方式组合。这能够直接地基于传感器数据的实例生成一个或多个建议的动作。在这些实施方式中,能够在嵌入空间中将为了确定周围状态而生成的嵌入直接地映射到一个或多个建议的动作的指示。例如,能够利用周围感测ml模型基于音频数据(或其声学特征,诸如梅尔倒谱频率系数、原始音频波形和/或其他声学特征)来生成音频嵌入(例如,周围噪声的实例的较低维表示)。这些嵌入能够是嵌入空间内的点,其中类似声音(或捕获声音的声学特征)与嵌入空间的相同或类似部分相关联。此外,嵌入空间的这些部分能够与多个根本不同的周围状态中的一个或多个相关联,并且如果这些嵌入中的给定一个与嵌入空间的各部分中的一个或多个之间的距离度量满足距离阈值,则能够将这些嵌入中的给定一个分类成周围状态中的给定一个。
59.例如,并且如上所述,食物烹饪的实例能够与嵌入空间的与“食物烹饪”声音相关联的第一部分相关联,餐具发叮当声的实例能够与嵌入空间的与“餐具发叮当声”声音相关联的第二部分相关联,割草机轰鸣的实例能够与嵌入空间的与“割草机”声音相关联的第三部分相关联,依此类推。然而,在这些实施方式中,嵌入空间的与“食物烹饪”声音相关联的第一部分和嵌入空间的与“餐具发叮当声”声音相关联的第二部分也能够与用户可以在烹饪或吃饭时执行的一个或多个动作的指示(例如,诸如当周围状态对应于烹饪或吃饭周围状态时由用户执行的一个或多个时间上对应的动作的指示)相关联。此外,嵌入空间的与“割草机”声音相关联的第三部分能够与用户可以在割草时执行的一个或多个动作的指示(例如,诸如当周围状态对应于草坪养护周围状态时由用户执行的一个或多个时间上对应的动作的指示)相关联。能够以上面关于周围ml模型描述的相同或类似方式基于嵌入生成一个或多个损失。然而,在这些实施方式中基于损失中的一个或多个更新端到端模型时,端到端模型的周围ml模型部分可以被固定,使得仅该端到端模型的周围感测ml模型部分被更新。
60.在一些实施方式中,并且在训练周围感测ml模型之后,自动助理120能够使动作建议引擎170在生成一个或多个建议的动作时利用周围感测ml模型,该一个或多个建议的动作被建议以供自动助理120经由助理设备106、185中的一个或多个代表用户执行(例如,关于图4、图5a和图5b所描述的)。动作建议引擎170能够基于处理经由助理设备106、185中的一个或多个获得的传感器数据的实例而生成建议的动作中的一个或多个。此外,自动助理120能够使动作处理引擎180响应于接收到对建议的动作中的一个或多个的用户选择来发起建议的动作中的一个或多个的执行。例如,在一些实施方式中,自动助理120能够使周围状态引擎160确定用户的环境状态和/或用户的环境的周围状态,并且能够使动作建议引擎使用存储在(多个)ml模型数据库192中的周围感测ml模型来处理周围状态,以生成建议的动作中的中的一个或多个。作为另一示例,在其他实施方式中,诸如当周围感测ml模型是端到端模型时,自动助理120能够使动作建议引擎使用存储在(多个)ml模型数据库192中的周围感测ml模型来处理传感器数据的实例,以在不使用周围状态引擎160显式地确定周围状
态的情况下生成建议的动作中的一个或多个。在各种实施方式中,自动助理120可以仅响应于确定传感器数据的实例事实上确实对应于周围感测事件(例如,上面关于周围感测事件引擎160所描述的)来使动作建议引擎170处理周围状态和/或传感器数据的实例以生成建议的动作中的一个或多个。
61.在那些实施方式的一些版本中,自动助理120能够使建议的动作中的一个或多个的指示被提供以供呈现给用户。例如,能够经由助理设备106、185中的一个或多个的显示器在视觉上渲染对应的建议片或可选图形元素以供呈现给用户。对应的建议片或可选图形元素能够与建议的动作中的根本不同的一个相关联(例如,如图5a和图5b所示作为能够由自动助理120执行的根本不同的动作)和/或与一个或多个建议的动作中的每一个相关联(例如,作为要由自动助理120执行的例程)。在此示例中,动作处理引擎180能够基于对对应的建议片或可选图形元素中的一个或多个的用户选择来发起建议的动作中的一个或多个的执行(例如,生成履行数据并将其传送到助理设备106、185中的适当一个)。作为另一示例,能够经由助理设备106、185中的一个或多个的(多个)扬声器可听地渲染包括具有一个或多个建议的动作的指示的合成语音的合成语音音频数据以供呈现给用户。合成语音能够包括一个或多个建议的动作的指示。在此示例中,动作处理引擎180能够基于处理响应于合成语音并且选择建议的动作中的一个或多个的口语输入来发起建议的动作中的一个或多个的执行(例如,生成履行数据并将其传送到助理设备106、185中的适当一个)。
62.在那些实施方式的一些另外或替代的版本中,能够由自动助理120自动地执行建议的动作中的一个或多个。使建议的动作中的一个或多个由自动助理120自动地执行能够基于例如与建议的动作中的一个或多个相关联的对应的预测量度满足阈值。换句话说,如果自动助理120充分地确信用户将执行给定动作(例如,当用户将耳机与移动设备配对并开始跟踪跑步时发起跑步播放列表的播放),则自动助理120能够自动地执行建议的动作,而不使建议的动作中的一个或多个的指示被提供以供呈现给用户。在这些实施方式中,自动助理120能够使动作处理引擎180发起要自动地执行的建议的动作中的一个或多个的执行,而不使建议的动作中的一个或多个的指示被提供以供呈现给用户。然而,自动助理120能够使助理设备106、185中的一个或多个向用户提供关于为什么建议的动作中的一个或多个被自动地执行的通知(例如,“it looks like you just started a run,i’ll begin tracking it for you(看起来你刚刚开始跑步,我将为你开始跟踪它)”)。
63.尽管图1被描绘为具有由助理设备和/或(多个)服务器实现的组件的特定配置,并且被描绘为具有通过特定网络通信的助理设备和/或(多个)服务器,但是应该理解,那是为了举例起见,而不意在为限制性的。例如,助理输入设备106和/或助理非输入设备185可以通过(多个)网络直接地彼此通信地耦合。作为另一示例,能够完全在助理输入设备106中的一个或多个和/或助理非输入设备185中的一个或多个处在本地实现一个或多个基于云的自动助理组件119的操作。作为又一示例,存储在(多个)ml模型数据库192中的各种ml模型的(多个)实例可以在本地被存储在助理设备106、185处。因此,能够完全在助理设备106、185中的一个或多个处在本地实现本文中描述的技术。此外,在通过图1的一个或多个网络110中的任一个传送数据(例如、设备活动、音频数据或与其相对应的识别文本、设备拓扑表示和/或本文中描述的任何其他数据)的实施方式中,数据能够被加密、过滤或者以其他方式以任何方式被保护以确保用户的隐私。
64.尽管在本文中关于在推理时生成要由自动助理代表用户执行的建议的动作描述了技术,但是应该理解,那是为了举例起见,而不意在为限制性的。例如,本文中描述的技术还能够生成一个或多个通知以便用户执行自动助理可能无法执行的一个或多个建议的动作。例如,假定基于处理传感器数据的实例而确定的周围状态是洗衣房周围状态(例如,基于处理捕获来自洗衣机的噪声(例如,自旋声音)后面是来自烘干机的噪声(例如,滚筒声音)的音频数据来确定)。进一步假定,在洗涤周期或干燥周期完成时,用户将送洗衣物从洗衣机切换到烘干机并且/或者从烘干机中移除送洗衣物(例如,基于由智能洗衣机/烘干机生成的设备数据和/或基于其他传感器数据(例如,用户在洗衣房中的位置、捕获到用户执行洗衣动作的周围噪声等)来确定)。在此示例中,训练实例输出能够包括使用户在洗衣机/烘干机声音停止时和/或在预定时间段(例如,洗衣机周期的时间和/或烘干机周期的时间)之后执行洗衣动作的通知的指示(例如,“it’s time to switch loads of laundry(是切换送洗衣物的负载的时候了)”,“your laundry is complete(你的送洗衣物完成了)”等)。因此,还能够训练周围感测ml模型来生成一个或多个建议的动作以供用户执行,因为自动助理可能无法执行一些动作(例如,切换送洗衣物的负载)。在一些情况下,训练实例输入能够可选地包括另外的周围状态,诸如基于给定助理设备(例如,用户的移动设备)与另一助理设备或家庭网络的配对数据而确定的在家或到家周围状态。通过在训练实例输入中包括这对周围状态,周围感测ml模型能够学习仅当用户到家时提供这些通知,从而在用户能够对通知采取行动的时间提供通知(例如,用户在离家时不能切换送洗衣物的负载)。
65.通过使用本文中描述的技术,能够实现各种技术优点。作为一个非限制性示例,在提供一个或多个建议的动作以供呈现给用户的实施方式中,能够简化显式用户输入(例如,单次点击,单次触摸、“是”或“否”,而不是完整口语话语等)以使建议的动作中的一个或多个执行。此外,在代表用户自动地执行建议的动作中的一个或多个的实施方式中,可以一起完全消除用于执行建议的动作中的一个或多个的显式用户输入。此外,在训练周围感测ml模型以针对用户基于周围状态和时间上对应的动作生成建议的动作中的一个或多个时,周围感测ml模型能够更稳定地和/或准确地生成给定周围状态的情况下最适合于用户的建议的动作中的一个或多个。结果,能够减少由一个或多个助理设备接收到的用户输入的数量和/或持续时间,因为用户不需要提供自由形式输入以使建议的动作中的一个或多个被执行,从而通过减少网络业务来节约助理设备中的一个或多个处的计算资源和/或网络资源。
66.现在转向图2,描绘了图示生成用于训练周围感测机器学习模型的多个训练实例的示例方法200的流程图。为了方便,方法200的操作是参考执行操作的系统来描述的。方法200的系统包括计算设备的一个或多个处理器和/或其他组件。例如,方法200的系统能够由图1、图3a、图3b、图5a或图5b的助理设备106、185中的一个或多个、图1的基于云的自动助理组件119、图6的计算设备610、一个或多个服务器、其他计算设备和/或其任何组合实现。此外,虽然按照特定顺序示出方法200的操作,但是这不意在为限制性的。一个或多个操作可以被重新排序、省略和/或添加。
67.在框252,系统经由用户的助理设备的一个或多个传感器获得传感器数据的实例。传感器数据的实例能够包括例如音频数据(例如,捕获口语话语、周围噪声等的音频数据)、运动数据(例如,gps信号、加速度计数据等)、配对数据、设备状态数据和/或由用户的助理设备和/或用户的一个或多个另外的助理设备的各种传感器生成的任何其他传感器数据。
68.在框254,系统确定传感器数据的实例是否对应于周围感测事件。系统能够基于例如包括以下各项的传感器数据的实例确定传感器数据的实例对应于周围感测事件:捕获特定噪声和/或高于阈值噪声水平的噪声的音频数据、捕获特定持续时间的移动信息的运动数据、捕获(多个)网络上的一个或多个特定助理设备的配对信息的配对数据、检测一个或多个助理设备中的状态变化和/或一些其他设备事件(例如,特定状态被维持达特定时间量)的设备状态数据、和/或时间数据。换句话说,系统能够防止基于偶然周围感测器数据生成训练实例,使得任何所得的训练实例事实上确实对应于应该为其生成一个或多个建议的动作的周围感测事件。如果在框254的迭代时,系统确定传感器数据的实例不对应于周围感测事件,则系统返回到框252以经由助理设备的传感器中的一个或多个获得传感器数据的另外的实例,并且在框254的后续迭代时确定传感器数据的另外的实例是否对应于周围感测事件。系统可以重复框252和254的操作,直到确定了存在周围感测事件为止。如果在框254的迭代时,系统确定传感器数据的实例对应于周围感测事件,则系统进行到框256。
69.在框256,系统确定对于周围感测事件是否存在一个或多个时间上对应的动作。如果在框256的迭代时,系统确定对于周围感测事件没有时间上对应的动作,则系统返回到框252以经由助理设备的传感器中的一个或多个获得传感器数据的另外的实例,并且在框254的后续迭代时确定传感器数据的另外的实例是否对应于周围感测事件。进一步地,并且假定系统在框254的后续迭代时确定传感器数据的另外的实例对应于周围感测事件,系统在框256的后续迭代时确定对于周围感测事件是否存在一个或多个时间上对应的动作。系统可以重复框252、254和256的操作,直到确定存在周围感测事件为止。如果在框256的迭代时,系统确定对于周围感测事件存在一个或多个时间上对应的动作,则系统进行到框258。
70.在框258,系统基于传感器数据的实例和一个或多个时间上对应的动作来生成要在训练周围感测ml模型时利用的一个或多个训练实例。在一些实施方式中,能够基于传感器数据的实例和一个或多个时间上对应的动作来生成单个训练实例。在另外或替代的实施方式中,能够基于传感器数据的实例和一个或多个时间上对应的动作来生成多个训练实例。一个或多个训练实例中的每一个能够包括训练实例输入和训练实例输出。例如,并且如在子框258a处指示的,训练实例输入能够包括至少基于传感器数据的实例确定的周围状态。此外,如在子框258b处指示的,训练实例输出能够包括时间上对应的动作中的一个或多个的指示。
71.例如,并且简要地参考图3a和图3b,现在提供图1的各种组件以及依照图2的方法200的框252-258生成训练实例的另外的描述。在图3a和图3b中描绘了家庭平面图。所描绘的平面图包括多个房间250-262。多个助理输入设备106
1-5
被部署于至少一些房间中各处。助理输入设备106
1-5
中的每一个可以实现被配置有本公开的所选方面的自动助理客户端118的相应实例并且可以包括一个或多个输入设备,诸如能够捕获附近的人讲出的话语的(多个)麦克风。例如,采取交互式独立扬声器和显示设备(例如,显示幕、投影仪等)的形式的第一助理输入设备1061被部署于在此示例中为厨房的房间250中。采取所谓的“智能”电视(例如,具有实现自动助理客户端118的相应实例的处理器的一个或多个处理器的联网电视)的形式的第二助理输入设备1062被部署于在此示例中为书房的房间252中。采取没有显示器的交互式独立扬声器的形式的第三助理输入设备1063被部署于在此示例中为卧室的房间254中。采取另一交互式独立扬声器的形式的第四助理输入设备1064被部署于在此示
例中为客厅的房间256中。还采取智能电视的形式的第五助理输入设备1065也被部署于在此示例中为厨房的房间250中。
72.虽然在图3a和图3b中未描绘,但是多个助理输入设备106
1-5
可以经由一个或多个有线或无线wan和/或lan(例如,经由图1的网络110)与彼此和/或其他资源(例如,因特网)通信地耦合。另外,其他助理输入设备—特别是诸如智能电话、平板、膝上型电脑、可穿戴设备等的移动设备—也可以存在,例如,由家庭中的一个或多个人(例如,用户101)携带并且也可以或可以不连接到相同的wan和/或lan。应该理解,图3a和图3b中描绘的助理输入设备的配置仅仅是一个示例;更多的或更少的和/或不同的助理输入设备106可以跨家庭的任何数目的其他房间和/或区域被部署,并且/或者被部署于除住宅家庭以外的位置(例如,企业、酒店、公共地方、机场、车辆和/或其他位置或空间)中。
73.图3a和图3b中进一步描绘的是多个助理非输入设备185
1-5
。例如,采取智能门铃的形式的第一助理非输入设备1851被部署于家庭的在家庭的前门附近的外墙上。采取智能锁的形式的第二助理非输入设备1852被部署于家庭的位于家庭的前门上的外墙上。采取智能洗衣机的形式的第三助理非输入设备1853被部署于在此示例中为洗衣房的房间262中。采取门打开/关闭传感器的形式的第四助理非输入设备1854被部署于房间262中的后门附近,并且检测后门被打开还是关闭。采取智能恒温器的形式的第五助理非输入设备1855被部署于在此示例中为书房的房间252中。
74.多个助理非输入设备185中的每一个能够与相应的助理非输入系统通信(例如,经由图1的网络110)以向相应的助理非输入系统提供数据并且可选地基于由相应的助理非输入系统180提供的命令被控制。助理非输入设备185中的一个或多个能够另外或替代地直接地与助理输入设备106中的一个或多个通信(例如,经由图1的网络110)以向助理输入设备106中的一个或多个提供数据并且可选地基于由助理输入设备106中的一个或多个提供的命令被控制。应该理解,图3a和图3b中描绘的助理非输入设备185的配置仅仅是一个示例;更多的或更少的和/或不同的助理非输入设备185可以跨家庭的任何数目的其他房间和/或区域被部署,并且/或者被部署于除住宅家庭以外的位置(例如,企业、酒店、公共地方、机场、车辆和/或其他位置或空间)中。
75.例如,并且关于图3a,假定与生态系统相关联的用户101位于在此示例中为厨房的房间250中,如由咝咝响平底锅352a1指示的那样制作早餐,并且随后如餐食352a2指示的那样在房间250中吃早餐。随着用户101制作并吃早餐,助理设备106、185中的一个或多个可以生成传感器数据。例如,进一步假定助理输入设备1061或1065中的一个或多个的麦克风生成与咝咝响平底锅352a1和吃餐食352a2的噪声相对应的音频数据。在此示例中,用户101烹饪和吃饭的厨房噪声可以对应于周围感测事件,并且所得的基于由助理输入设备1061或1065中的一个或多个生成的音频数据而确定的周围状态可以对应于烹饪周围状态、吃饭周围状态、早餐周围状态、和/或基于音频数据、用户101在厨房中的位置和/或其他传感器数据而确定的另一周围状态。
76.进一步假定,当用户101正在烹饪和/或吃饭时,用户101在第一时间(例如,时间=t1)提供了调用自动助理120来使其检索并向用户101呈现天气信息的“assistant what’s the weather?(助理天气怎么样?)”的口语话语354a1,在第二时间(例如,时间=t2)提供了使自动助理120检索并向用户101呈现交通信息的“how’s traffic?(交通如何?)”的口语话
语354a2,并且在第三时间(例如,时间=t3)提供了调用自动助理120并使其自动地启动用户101的汽车的“assistant.start my car(助理。启动我的汽车)”的口语话语354a3。在此示例中,与口语话语354a1相关联的动作(例如,天气动作)、与口语话语354a2相关联的动作(例如,交通动作)和与口语话语354a3相关联的动作(例如,汽车启动动作)能够各自被认为是针对所确定的周围状态的时间上对应的动作。与口语话语354a1、354a2和354a3相关联的动作能够被认为是时间上对应的,因为它们是在获得被利用来确定周围状态的音频数据的阈值持续时间内接收到的。值得注意的是,用于标识时间上对应的动作的阈值持续时间能够变化。例如,假定口语话语354a1是在用户开始烹饪早餐时接收到的,而口语话语354a2是作为口语话语354a1的后续话语接收到的,使得用户不需要在第二时间重新调用自动助理120(例如,经由热词、软件按钮、硬件按钮、基于手势的调用等)。进一步假定当口语话语354a3被接收到时的第三时间是在用户101结束吃饭20分钟以后之后。在一些情况下,第三时间仍然能够被认为是时间上对应的,因为传感器数据指示早餐周围状态仍然适用于用户101和/或用户101的周围。因此,在获得传感器数据的实例之前、期间和/或之后执行的任何用户发起的能够被认为是针对周围状态的时间上对应的动作。
77.因此,能够利用由助理输入设备1061或1065中的一个或多个生成的捕获烹饪噪声的音频数据的实例和/或基于音频数据的实例而确定的周围状态的指示作为用于给定训练实例的训练实例输入。此外,能够利用与口语话语354a1、354a2和/或354a3相对应的动作中的一个或多个的指示作为用于给定训练实例的训练实例输出。例如,训练实例能够包括与咝咝响平底锅352a1和吃餐食352a2的噪声相对应的音频数据和/或烹饪或早餐周围状态的训练实例输入,以及天气动作、交通动作和汽车启动动作的指示的训练实例输出。另外,例如,第一训练实例能够包括与咝咝响平底锅352a1和吃餐食352a2的噪声相对应的音频数据和/或烹饪或早餐周围状态的训练实例输入,以及天气动作的指示的训练实例输出;第二训练实例能够包括与咝咝响平底锅352a1和吃餐食352a2的噪声相对应的音频数据和/或烹饪或早餐周围状态的训练实例输入,以及交通动作的指示的训练实例输出;并且第三训练实例能够包括与咝咝响平底锅352a1和吃餐食352a2的噪声相对应的音频数据和/或烹饪或早餐周围状态的训练实例输入,以及汽车启动动作的指示的训练实例输出。另外,例如,第一训练实例能够包括与咝咝响平底锅352a1和吃餐食352a2的噪声相对应的音频数据和/或烹饪或早餐周围状态的训练实例输入,以及天气动作和交通动作的指示的训练实例输出;第二训练实例能够包括与咝咝响平底锅352a1和吃餐食352a2的噪声相对应的音频数据和/或烹饪或早餐周围状态的训练实例输入,以及汽车启动动作的指示的训练实例输出。通过基于这些训练实例训练周围感测ml模型,能够训练周围感测ml模型基于处理周围感测器数据的实例而推理用于用户的助理例程。
78.作为另一示例,并且关于图3b,假定与生态系统相关联的用户101紧接在主要住所外面。当用户101在外面时,助理设备106、185中的一个或多个可以生成传感器数据。例如,进一步假定用户的移动设备(例如,未被描绘的助理输入设备)使用移动设备的gps传感器和/或加速度计来生成运动数据。在此示例中,运动数据可以对应于周围感测事件,并且所得的基于由移动设备生成的运动数据而确定的周围状态可以对应于锻炼周围状态、跑步周围状态、慢跑周围状态、醒着周围状态、和/或基于运动数据、用户101在家庭外面的位置和/或其他传感器数据而确定的另一周围状态。此外,由于用户101已离开主要住所,所以所得
的周围状态可以另外或替代地是离开周围状态。
79.进一步假定,当用户101在外面时,用户101如由352b1指示的那样在第一时间(例如,时间=t1)将移动设备与蓝牙耳机配对,在第二时间(例如,时间=t2)提供使自动助理120经由智能锁1854锁后门的“assistant,lock the back door(助理,锁后门)”的口语话语352b2,并且如由352b3指示的那样在第三时间(例如,时间=t3)发起用3p软件应用跟踪跑步。在此示例中,与配对352b1相关联的动作(例如,配对动作)、与口语话语352b2相关联的动作(例如,门锁动作)和与3p软件应用352b3相关联的动作(例如,跑步跟踪动作)能够各自被认为是针对所确定的周围状态的时间上对应的动作。这些动作能够被认为是时间上对应的,因为它们是在获得被利用来确定周围状态的运动数据和/或用户101离开主要住所的阈值持续时间内接收到的。值得注意的是,用于标识时间上对应的动作的阈值持续时间能够变化。例如,并且和图3a对比,第一时间、第二时间和第三时间能够是相对较短的,因为通常在较短持续时间内执行352b1、352b2和/或352b3所指示的动作。因此,在获得传感器数据的实例之前、期间和/或之后执行的任何用户发起的能够被认为是针对周围状态的时间上对应的动作。
80.因此,能够利用由用户101的移动设备生成的捕获运动信息的运动数据的实例和/或基于运动数据的实例而确定的周围状态的指示作为用于给定训练实例的训练实例输入。此外,能够利用与352b1、352b2和/或352b3相关联的动作中的一个或多个的指示作为用于给定训练实例的训练实例输出。例如,训练实例能够包括运动数据和/或配对数据或锻炼周围状态的训练实例输入,以及门锁动作和跑步跟踪动作的指示的训练实例输出。另外,例如,第一训练实例能够包括运动数据和/或配对数据的训练实例输入,以及门锁动作的指示的训练实例输出;并且第二训练实例能够包括运动数据和/或配对数据的训练实例输入,以及跑步跟踪动作的指示的训练实例输出。
81.尽管关于图3a和图3b描述了特定示例,但是应该理解,那些是为了图示起见而提供的,而不意在为限制性的。此外,虽然关于用户101的主要住所描述了图3a和图3b,但是应该理解,那也是为了举例起见,而不意在为限制性的。
82.往回转向图2,在框260,系统使得基于训练实例中的一个或多个训练周围感测ml模型。例如,系统能够使周围感测ml模型处理训练实例输入以生成一个或多个预测的动作的指示。能够将一个或多个预测的动作的指示与训练实例输出中包括的一个或多个时间上对应的动作的指示进行比较以生成一个或多个损失。系统能够使得基于损失中的一个或多个更新周围感测ml模型。能够针对多个另外的训练实例重复这些操作以更新周围感测ml模型。
83.在框262,系统确定是否满足一个或多个条件。如果在框262的迭代时,系统确定不满足条件中的一个或多个,则系统继续在框262监测是否满足条件中的一个或多个。该一个或多个条件能够包括例如助理设备正在充电、助理设备具有至少阈值充电状态、助理设备的温度(基于一个或多个设备上温度传感器)小于阈值、助理设备未在被用户握持、与(多个)助理设备相关联的(多个)时间条件(例如,在特定时间段之间、每n小时(其中n是正整数)和/或与助理设备相关联的(多个)其他时间条件)、是否已基于阈值数目的训练实例训练了周围感测ml模型和/或(多个)其他条件。在一些实施方式中,当系统继续在框262监测是否满足条件中的一个或多个时,系统能够继续生成另外的训练实例并且/或者训练周围
感测ml模型。
84.此外,虽然框262的操作被描绘为发生在框260与框264之间,但是应该理解,那是为了举例起见,而不意在为限制性的。例如,方法200可以在执行包括在方法200中的一个或多个其他框的操作之前采用框262的多个实例。例如,系统可以存储传感器数据的一个或多个实例,并且忍住不执行框254、256、258和260的操作直到满足条件中的一个或多个为止。另外,例如,系统可以执行框252、254、256和258的操作,但是忍住不训练周围感测ml模型直到满足条件中的一个或多个(例如,诸如阈值数目的训练实例是否可用于训练周围感测ml模型)为止。
85.如果在框262的迭代时,系统确定满足条件中的一个或多个,则系统进行到框264。在框264,系统使得在基于传感器数据的一个或多个另外的实例生成一个或多个建议的动作时利用训练后的周围感测ml模型。
86.现在转向图4,描绘了图示使用周围感测机器学习模型的示例方法400的流程图。为了方便,方法400的操作是参考执行操作的系统来描述的。方法400的系统包括计算设备的一个或多个处理器和/或(多个)其他组件。例如,方法400的系统能够由图1、图3a、图3b、图5a或图5b的助理设备106、185中的一个或多个、图1的(多个)基于云的自动助理组件119、图6的计算设备610、一个或多个服务器、其他计算设备和/或其任何组合实现。此外,虽然按照特定顺序示出方法400的操作,但是这不意在为限制性的。一个或多个操作可以被重新排序、省略和/或添加。
87.在框452,系统经由用户的助理设备的一个或多个传感器获得传感器数据的实例。例如,传感器数据的实例能够包括音频数据(例如,捕获口语话语、周围噪声等的音频数据)、运动数据(例如,(多个)gps信号、加速度计数据等)、配对数据、设备状态数据和/或由用户的助理设备和/或用户的一个或多个另外的助理设备的各种传感器生成的任何其它传感器数据。
88.在框454,系统基于传感器数据的实例确定周围状态。周围状态反映助理设备的用户的环境状态和/或助理设备的用户的环境的周围状态。能够基于传感器数据的实例确定周围状态。
89.在框456,系统确定周围状态是否对应于周围感测事件。系统能够基于例如包括以下各项的传感器数据的实例确定周围状态对应于周围感测事件:捕获特定噪声和/或高于阈值噪声水平的噪声的音频数据、捕获特定持续时间的运动信息的运动数据、捕获(多个)网络上的一个或多个特定助理设备的配对信息的配对数据、检测一个或多个助理设备中的状态变化和/或一些其他设备事件(例如,特定状态被维持达特定时间量)的设备状态数据、和/或时间数据。换句话说,系统可以仅处理事实上确实对应于应该为其生成一个或多个建议的动作的周围感测事件的周围状态。如果在框456的迭代时,系统确定周围状态不对应于周围感测事件,则系统返回到框452以经由助理设备的传感器中的一个或多个获得传感器数据的另外的实例,在框454的后续迭代时基于传感器数据的另外的实例确定另外的周围状态,并且在框456的后续迭代时确定另外的周围状态是否对应于周围感测事件。如果在框456的迭代时,系统确定周围状态对应于周围感测事件,则系统进行到框458。
90.在框458,系统使用训练后的周围感测ml模型来处理周围状态以生成被建议代表用户被执行的一个或多个建议的动作。在处理周围状态以生成一个或多个建议的动作时,
系统能够针对一个或多个建议的动作中的每一个生成一个或多个对应的预测量度。换句话说,系统能够基于处理基于传感器数据的实例而确定的周围状态来预测用户将有多可能执行建议的动作中的一个或多个。在一些实施方式中,可以省略框456,使得系统试图基于周围状态来生成一个或多个建议的动作,但是如果没有动作与周围状态相关联(例如,对应的预测量度未能满足阈值量度和/或都超出嵌入空间中的阈值距离),则可以不提供任何建议的动作以供呈现给用户。
91.在框460,系统确定是否代表用户自动地执行建议的动作中的一个或多个。系统能够经由用户的助理设备和/或用户的一个或多个另外的助理设备执行建议的动作中的一个或多个。系统能够基于与一个或多个建议的动作相关联的对应的预测量度来确定要执行建议的动作中的一个或多个。对应的预测量度能够是例如在使用周围感测ml模型处理周围状态时生成的。例如,系统能够确定要自动地执行与满足阈值量度的对应的预测量度相关联的一个或多个建议的动作。在一些实施方式中,系统可以不自动地执行任何建议的动作。在其他实施方式中,系统可以自动地执行一个或多个建议的动作中的一些,但不是一个或多个建议的动作中的全部。在其他实施方式中,系统可以自动地执行一个或多个建议的动作中的每一个。如果在框460的迭代时,系统确定自动地执行建议的动作中的一个或多个,则系统进行到框466。在下面描述框466。如果在框460的迭代时,系统确定不自动地执行建议的动作中的一个或多个,则系统进行到框462。
92.在框462,系统使得建议的动作中的一个或多个的对应表示被提供以供经由用户的助理设备和/或另外的助理设备呈现给用户。在框464,系统确定是否从用户接收到对建议的动作中的一个或多个的对应表示的用户选择。例如,用户选择能够是指向助理设备的显示器的触摸输入、由助理设备的(多个)麦克风接收到的口语输入等。如果在框464的迭代时,系统确定未从用户接收到对建议的动作中的一个或多个的对应表示的用户选择,则系统继续在框464监测用户选择。系统能够继续监测对建议的动作中的一个或多个的用户选择达阈值持续时间,直到用户解除与一个或多个建议的动作相关联的接口(例如,提示、通知等)。如果在框464的迭代时,系统确定从用户接收到对建议的动作中的一个或多个的对应表示的用户选择,则系统进行到框462。
93.在框462,系统使建议的动作中的一个或多个由用户的助理设备和/或另外的助理设备代表用户执行。在一些实施方式中,诸如当系统从框460的实例到达框466的操作时,则能够自动地并在不接收任何用户输入的情况下执行建议的动作中的一个或多个。在这些实施方式中的一些实施方式中,能够提供建议的动作中的一个或多个已被自动地执行的通知以供呈现给用户。在另外或替代的实施方式中,诸如当系统从框464的实例到达框466的操作时,能够响应于接收到用户选择执行一个或多个建议的动作。
94.在框468,系统使得基于对建议的动作中的一个或多个的对应表示的用户选择或其缺少来更新周围感测ml模型。在接收到对建议的动作中的一个或多个的用户选择的实施方式中,能够利用用户选择作为正反馈信号以加强针对周围状态的所选动作中的一个或多个的生成。在未接收到用户选择(或省略建议的动作中的一个或多个的用户选择)的实施方式中,能够利用用户选择的缺少作为负反馈信号以偏离针对周围状态的所选动作中的一个或多个的将来生成。例如,能够基于用户选择来生成包括和/或省略某些动作的另外的训练实例,并且能够基于那些另外的训练实例进一步训练周围感测ml模型。以这种方式,周围感
测ml模型能够生成对用户而言最相关的建议的动作,从而减少在助理设备处接收的用户输入的数量。
95.现在转向图5a和图5b,提供了用户与正在使用周围感测ml模型的自动助理的交互的各种非限制性示例。自动助理能够在助理输入设备1061处在本地和/或在通过(多个)网络(例如,图1的网络110)与助理输入设备1061通信的一个或多个服务器处远程地实现图1中描绘的(多个)组件和/或引擎中的一个或多个。图5a的用户交互对应于当与图3a相对应的周围状态被随后确定时用户与自动助理的交互。此外,图5b的用户交互对应于当与图3b相对应的周围状态被随后确定时用户与自动助理的交互。
96.图5a和图5b中描绘的助理输入设备1061可以包括各种用户接口组件,包括例如用于基于口语话语和/或其他可听输入来生成音频数据的(多个)麦克风、用于可听见地渲染合成语音和/或其他可听输出的(多个)扬声器、以及用于接收触摸输入和/或用于在视觉上渲染转录和/或其他视觉输出的显示器1891。此外,助理输入设备1061的显示器1891包括各种系统接口元素191、192和193(例如,硬件和/或软件接口元素),各种系统接口元素191、192和193可以由用户(例如,图3a和图3b的用户101)与之交互以使助理输入设备1061执行一个或多个动作。助理输入设备1061的显示器1891使得用户能够通过触摸输入(例如,通过将用户输入指向显示器1891或其部分)和/或通过口语输入(例如,通过选择麦克风接口元素194—或者仅仅通过讲话而不一定选择麦克风接口元素194(即,自动助理120可以在助理输入设备1061处监测一个或多个词语或短语、(多个)手势、(多个)凝视、(多个)嘴移动、(多个)唇移动和/或其他条件以激活口语输入)来与显示器189上渲染的内容交互。
97.例如,并且关于图5a,假定用户在主要住所的厨房中制作并随后吃早餐(例如,如关于图3a所描述的),并且假定助理输入设备1061(或生态系统中的另一助理设备)生成捕获用户制作并吃早餐的音频数据。在此示例中,自动助理能够基于处理至少音频数据如由552a1指示的那样接收一个或多个建议的动作,并且使一个或多个建议的动作的对应表示被呈现给用户。在一些实施方式中,对应表示能够是例如可听表示,使得合成语音音频数据是经由助理输入设备1061的(多个)扬声器可听地渲染的。在这些实施方式中,用户能够经由响应于对应表示被可听地呈现的口语输入来选择建议的动作中的一个或多个以供由自动助理执行。
98.在另外或替代的实施方式中,对应表示能够是例如视觉表示,使得能够经由助理输入设备1061的显示器1891在视觉上渲染对应的可选择元素或建议片。这些视觉表示能够经由显示器1891被呈现在助理输入设备1061的主页屏幕处、被呈现在助理输入设备1061的锁定屏幕处、作为零状态建议的动作或作为用户与自动助理之间的对话的转录的部分被呈现在自动助理应用处、被呈现在通知接口(例如,弹出通知)处、和/或以任何其他方式被呈现。在这些实施方式中,用户能够经由响应于正在视觉上呈现对应表示的触摸或口语输入来选择建议的动作中的一个或多个以供由自动助理执行。在各种实施方式中,自动助理能够使所确定的周围状态的指示被呈现以供呈现给此用户。这关于为什么要提供一个或多个建议的动作以供呈现来告知用户。
99.例如,并且如图5a所描绘的,自动助理能够通过说“hi john,inoticed that you are eating breakfast(嗨john,我注意到你正在吃早餐)”来使助理输入设备1061渲染合成语音552a2。进一步地,假定自动助理充分地确信用户将要求助理提供天气和交通更新
(例如,基于与天气和交通动作相关联的对应的预测量度满足阈值量度)。因此,自动助理能够基于用户制作和/或吃早餐来自动地执行天气动作和交通动作,并且使“the weather today is a beautiful sunny and 75degrees(今天天气是美丽的晴天并且75度)”的合成语音552a3和“traffic on the way into the office is moderate(去办公室路上的交通是适度的)”的合成语音552a4经由助理输入设备1061被可听地呈现给用户(例如,作为单个话语或多个话语的部分)。进一步假定自动助理充分地确信用户将要求助理启动他或她的汽车(例如,基于与汽车启动动作相关联的对应的预测量度满足阈值量度)。然而,当提供了满足其他动作的合成语音552a3和554a4时,自动助理可能不自动地使用户的汽车被启动。相反,自动助理可以使“i’ll start your car for you a few minutes before you typically leave(我将在你通常离开之前几分钟为你启动你的汽车)”的合成语音552a5经由助理输入设备1061在视觉上和/或可听地被呈现给用户并且随后在用户离开之前启动用户的汽车。天气和交通动作的执行与汽车启动动作的执行之间的这种时间差能够由周围感测ml模型在训练实例包括与时间上对应的动作中的一个或多个相关联的时间数据的实施方式中学习。
100.另外或替代地,动作接口能够包括各种可选择元素。值得注意的是,动作接口根据建议的动作为由自动助理使用周围感测ml模型基于周围状态推理的早晨或早餐例程包括“do you like this routine(select all that apply)?(你喜欢此例程吗(选择适用的全部)?)”的提示560a。提示560a包括各种可选择元素,各种可选择元素当被选择时,细化所推理的例程并且/或者使得周围感测ml模型能够基于用户选择来更新(例如,关于图4的框468所描述的)。特别地,对“是”的第一可选择元素560a1的选择指示用户喜欢该例程并且能够在总体上针对该例程更新周围感测ml模型时作为正反馈信号被利用,对“否”的第二可选择元素560a2的选择指示用户不喜欢该例程并且能够在总体上针对该例程更新周围感测ml模型时作为负反馈信号被利用,对“无天气”的第三可选择元素560a2a的选择指示用户不喜欢该例程的天气动作并且能够在针对天气动作更新周围感测ml模型时作为负反馈信号被利用,对“无交通”的第四可选择元素560a2b的选择指示用户不喜欢该例程的交通动作并且能够在针对交通动作更新周围感测ml模型时作为负反馈信号被利用,以及对“无汽车启动”的第五可选择元素560a2c的选择指示用户不喜欢该例程的汽车启动动作并且能够在针对汽车启动动作更新周围感测ml模型时作为负反馈信号被利用。此外,动作接口可以包括可滑动元素195以解除动作接口,这能够被用作用于更新周围感测ml模型的中性信号(例如,如果执行一个或多个动作)或负信号(例如,如果不执行动作)。
101.作为另一示例,并且关于图5b,假定用户紧接在主要住所外面(例如,如关于图3a和图3b所描述的),并且假定助理输入设备1061检测到助理输入设备1061与蓝牙耳机的配对以及生成捕获用户步行的运动数据。在此示例中,自动助理能够基于处理至少配对数据和运动数据如由552b1指示的那样接收一个或多个建议的动作,并且使一个或多个建议的动作的对应表示被呈现给用户。在一些实施方式中,对应表示能够是例如可听表示,使得合成语音音频数据是经由助理输入设备1061的(多个)扬声器可听地渲染的。在这些实施方式中,用户能够经由响应于对应表示被可听地呈现的口语输入来选择建议的动作中的一个或多个以供由自动助理执行(例如,如由用户的口语输入554b1示出的)。
102.在另外或替代的实施方式中,对应表示能够是例如视觉表示,使得能够如关于图
5a所描述的那样经由助理输入设备1061的显示器1891在视觉上渲染对应的可选择元素或建议片。例如,并且如图5b中描绘的,自动助理能够通过说“hi john,it looks like you are about to run(嗨john,看起来你即将跑步)”使助理输入设备1061渲染合成语音552b2。进一步地,假定自动助理不充分地确信用户将锁他们的门、启动跑步播放列表或者开始跟踪跑步(例如,基于与这些动作相关联的对应的预测量度未能满足阈值量度)。因此,自动助理能够经由(例如,作为单个话语或多个话语的部分)要经由助理输入设备1061被可听地呈现给用户的“lock your doors(锁你的门)”的合成语音552b3、“start your running playlist(启动你的跑步播放列表)”的合成语音552b4和“start tracking your run(开始跟踪你的跑步)”的合成语音552b5使建议的动作的列表被提供以供呈现给用户(例如,“would you like me to(你想让我)”)。
103.另外或替代地,动作接口能够包括各种可选择元素。值得注意的是,动作接口根据建议的动作为由自动助理使用周围感测ml模型基于周围状态推理的早晨或早餐例程包括“do you like this routine(select all that apply)?(你喜欢此例程吗(选择适用的全部)?)”的提示560b。提示560b包括各种可选择元素,各种可选择元素当被选择时,细化所推理的例程和/或使得周围感测ml模型能够基于用户选择来更新(例如,关于图4的框468所描述的)。特别地,对“是”的第一可选择元素560b1的选择指示用户喜欢该例程并且能够在总体上针对该例程呈现更新周围感测ml模型时作为正反馈信号被利用,对“否”的第二可选择元素560b2的选择指示用户不喜欢该例程并且能够在总体上针对该例程呈现更新周围感测ml模型时作为负反馈信号被利用,对“无门锁”的第三可选择元素560b2a的选择指示用户不喜欢该例程的门锁动作并且能够在针对天气动作更新周围感测ml模型时作为负反馈信号被利用,对“无播放列表”的第四可选择元素560b2b的选择指示用户不喜欢该例程的播放列表动作并且能够在针对播放列表动作更新周围感测ml模型时作为负反馈信号被利用,以及对“无跑步跟踪”的第五可选择元素560b2c的选择指示用户不喜欢该例程的跑步跟踪动作并且能够在针对跑步跟踪动作更新周围感测ml模型时作为负反馈信号被利用。此外,动作接口可以包括可滑动元素195以解除动作接口,这能够被用作用于更新周围感测ml模型的中性(例如,如果执行一个或多个动作)或负信号(例如,如果不执行任何动作)。进一步假定用户提供“start my playlist and track my run,but do not lock the doors(启动我的播放列表并跟踪我的跑步,但不锁门)”的口语输入554b1。在此示例中,自动助理能够发起播放来自播放列表的音乐并且开始跟踪跑步(例如,经由关于图3b所描述的软件应用)。然而,自动助理将不控制智能锁。
104.尽管关于图5a和图5b描述了特定示例,但是应该理解那些是为了图示起见而提供的,而不意在为限制性的。此外,虽然从图3a和图3b关于用户101的主要住所描述图5a和图5b,但是应该理解,这也是为了举例起见,而不意在为限制性的。此外,虽然关于图5a和图5b描述特定可选择元素,但是应该理解,这也是为了举例起见,而不意在为限制性的。例如,能够提供图形可选择元素,该图形可选择元素当被选择时,使自动助理在进入相关周围状态的任何时候自动地执行建议的动作中的一个或多个(并且可选地避免对经由周围感测ml模型的任何处理的需要)。这能够使用减少的用户输入来建立与用户上下文相关的助理例程(例如,用户不需要手动地定义(多个)周围条件来触发例程或者手动地定义例程)。此外,能够以更高效的方式建立这些例行例程,因为用户可能未认识到正在执行的动作能够是助理
例程的部分。
105.此外,尽管关于图5a和图5b描述呈现和/或执行一个或多个建议的动作的特定顺序,但是应该理解,那也是为了举例起见,而不意在为限制性的。在各种实施方式中,自动助理能够基于与建议的动作中的一个或多个相关联的对应的预测量度或者响应于接收到引起动作中的一个或多个的执行的用户输入来使建议的动作中的一个或多个被自动地执行。自动助理可以高度确信用户将执行这些建议的动作(例如,基于与这些建议的动作相关联的对应的预测量度)。此外,自动助理能够提示执行自动助理不太确信用户将执行的一个或多个其他建议的动作(例如,基于与这些其他建议的动作相关联的对应的预测量度)。例如,并且关于图5a,自动助理能够自动地使天气动作和交通动作被自动地执行。然而,自动助理能够提示用户“would you also like me to start your car(你还想让我启动你的汽车吗)”(并且可选地允许用户在启动汽车之前定义时间段)。另外,例如,并且关于图5a,自动助理能够使天气动作和交通动作的对应表示被提供以供呈现给用户。然而,如果用户未提供使那些动作被执行的任何选择,则在对应的预测量度指示用户更有可能使天气动作和动作的执行的情况下,自动助理可能不关于汽车启动动作的执行提示用户。因此,由自动助理提供的用户体验能够是动态的,因为自动助理能够不仅基于一个或多个建议的动作和与其相关联的对应的预测量度,而且还基于用户如何与自动助理交互来定制用户体验。
106.此外,虽然本发明的各方面在本文中被描述为训练并利用周围感测模型以生成要由自动助理代表给定用户执行的一个或多个建议的动作,但是应该理解,那是为了举例起见,而不意在为限制性的。在一些实施方式中,多个用户(例如,住户的成员、在酒店的客人、在办公室的雇员等)可以与本文描述的助理设备相关联。在那些实施方式中的一些实施方式中,能够针对相应用户的每一个(例如,基于由相应用户中的每一个执行的时间上对应的动作)训练周围感测ml模型的相应实例。一种或多种技术(例如,语音标识、脸部标识、设备id标识等)能够被利用标识相应用户,并且使自动助理利用与相应用户相关联的周围感测ml模型的相应实例。因此,能够利用本文中描述的技术来针对相应用户中的每一个个性化一个或多个建议的动作。例如,自动助理可以基于如关于图5a所描述的烹饪或早餐周围状态来针对与助理设备相关联的第一用户生成天气动作、交通动作和汽车启动动作的指示。然而,自动助理可以基于相同的烹饪或早餐周围状态来针对与助理设备相关联的第二用户生成新闻动作的指示。针对不同用户的这些不同建议的动作能够由相同助理设备或不同助理设备呈现(或者被自动地执行)。
107.现在转向图6,描绘了可以可选地被利用来执行本文中描述的技术的一个或多个方面的示例计算设备610的框图。在一些实施方式中,助理输入设备中的一个或多个、基于云的自动助理组件中的一个或多个、一个或多个助理非输入系统、一个或多个助理非输入设备和/或(多个)其他组件可以包括示例计算设备610的一个或多个组件。
108.计算设备610通常包括至少一个处理器614,该至少一个处理器614经由总线子系统612与许多外围设备通信。这些外围设备可以包括存储子系统624,包括例如存储器子系统625和文件存储子系统626、用户接口输出设备620、用户接口输入设备622和网络接口子系统616。输入和输出设备允许用户与计算设备610交互。网络接口子系统616提供到外部网络的接口并且耦合到其他计算设备中的对应接口设备。
109.用户接口输入设备622可以包括键盘、诸如鼠标、轨迹球、触摸板或图形平板的指
点设备、扫描仪、并入到显示器中的触摸屏、诸如语音识别系统的音频输入设备、麦克风和/或其他类型的输入设备。一般而言,术语“输入设备”的使用旨在包括用于将信息输入到计算设备610或到通信网络上的所有可能类型的设备和方式。
110.用户接口输出设备620可以包括显示子系统、打印机、传真机或诸如音频输出设备的非视觉显示。显示子系统可以包括阴极射线管(crt)、诸如液晶显示器(lcd)的平板设备、投影设备、或用于创建可见图像的某种其他机制。显示子系统也可以例如经由音频输出设备提供非视觉显示。一般而言,术语“输出设备”的使用旨在包括用于从计算设备610向用户或者向另一机器或计算设备输出信息的所有可能类型的设备和方式。
111.存储子系统624存储提供本文中描述的一些或所有模块的功能的编程和数据构造。例如,存储子系统624可以包括用于执行本文中描述的方法的所选方面以及用于实现图1中描绘的各种组件的逻辑。
112.这些软件模块通常由处理器614单独或与其他处理器相结合地运行。存储子系统624中使用的存储器625能够包括许多存储器,包括用于在程序运行期间存储指令和数据的主随机存取存储器(ram)630和存储有固定指令的只读存储器(rom)632。文件存储子系统626能够为程序和数据文件提供持久存储,并且可以包括硬盘驱动器、软盘驱动器以及相关可移动介质、cd-rom驱动器、光驱、或可移动介质盒。实现某些实施方式的功能的模块可以由文件存储子系统626存储在存储子系统624中,或者存储在可由(多个)处理器614访问的其他机器中。
113.总线子系统612提供用于让计算设备610的各种组件和子系统按预期彼此通信的机制。尽管总线子系统612被示意性地示出为单条总线,但是总线子系统的替代的实施方式可以使用多条总线。
114.计算设备610能够具有包括以下各项的不同类型:工作站、服务器、计算集群、刀片服务器、服务器场、或任何其他数据处理系统或计算设备。由于计算机和网络的不断变化性质,图6中描绘的计算设备610的描述仅旨在作为出于说明一些实施方式的目的的特定示例。计算设备610的许多其他配置与图6中描绘的计算设备比可能具有更多或更少的组件。
115.在本文中讨论的某些实施方式可以收集或者使用关于用户的个人信息(例如,从其他电子通信中提取的用户数据、关于用户的社交网络的信息、用户的位置、用户的时间、用户的生物计量信息、以及用户的活动和人口统计信息、用户之间的关系等)的情况下,用户被提供有一个或多个机会来控制信息是否被收集、个人信息是否被存储、个人信息是否被使用、以及信息如何关于用户被收集、存储和使用。也就是说,本文中讨论的系统和方法仅在从相关用户接收到要这样做的显式授权时才收集、存储和/或使用用户个人信息。
116.例如,用户被提供有对程序或特征是否收集关于该特定用户或与该程序或特征相关的其他用户的用户信息的控制。将被收集个人信息的每个用户被呈现有允许控制与该用户相关的信息收集、关于是否收集信息以及关于将收集信息的哪些部分提供许可或授权的一个或多个选项。例如,能够通过通信网络向用户提供一个或多个此类控制选项。另外,某些数据可以在它被存储或者使用之前以一种或多种方式被处理,使得个人可标识的信息被移除。作为一个示例,可以处理用户的身份,使得不能确定个人可标识的信息。作为另一示例,用户的地理位置可以被概括为一个更大的区域,使得不能确定用户的特定位置。
117.在一些实施方式中,提供了一种由一个或多个处理器实现的方法,并且该方法包
括:确定传感器数据的实例对应于周围感测事件;标识在周围感测事件的阈值持续时间内执行的时间上对应的动作,该时间上对应的动作是由用户经由用户的助理设备或另外的助理设备执行的用户发起的动作;以及响应于标识时间上对应的动作:在助理设备处并且基于传感器数据的实例和时间上对应的动作,生成要在训练周围感测机器学习(ml)模型时利用的训练实例;并且使得基于训练实例训练周围感测ml模型。
118.本文中公开的技术的这些和其他实施方式能够包括以下特征中的一个或多个。
119.在一些实施方式中,训练实例能够包括训练实例输入和训练实例输出。训练实例输入能够包括传感器数据的实例,并且训练实例输出能够包括时间上对应的动作的指示。
120.在那些实施方式的一些版本中,传感器数据的实例能够包括由助理设备的一个或多个麦克风捕获的音频数据的实例,并且训练实例输入能够包括与用户的推理活动相关联的周围状态,该用户的推理活动是基于处理音频数据的实例而推理的。
121.在那些实施方式的另外或替代的版本中,传感器数据的实例能够包括由助理设备的一个或多个麦克风捕获的音频数据的实例,并且训练实例输入能够包括与用户的推理位置相关联的周围状态,该用户的推理位置是基于处理音频数据的实例而推理的。
122.在那些实施方式的另外或替代的版本中,传感器数据的实例能够包括由助理设备的加速度计或gps传感器捕获的运动数据的实例,并且训练实例输入能够包括与用户的推理活动相关联的周围状态,该用户的推理活动是基于处理运动数据的实例而推理的。
123.在那些实施方式的另外或替代的版本中,传感器数据的实例能够包括由助理设备的加速度计或gps传感器捕获的运动数据的实例,并且训练实例输入能够包括用户的推理位置,该用户的推理位置是基于处理运动数据的实例而推理的。
124.在那些实施方式的另外或替代的版本中,传感器数据的实例能够包括基于助理设备与用户的客户设备配对而标识的配对数据的实例,并且训练实例输入能够包括配对数据。
125.在一些实施方式中,该方法能够进一步包括经由另外的助理设备的一个或多个另外的传感器检测到另外的传感器数据的另外的实例对应于周围感测事件。生成训练实例能够进一步基于另外的传感器数据的另外的实例。
126.在一些实施方式中,标识时间上对应的动作能够包括从用户接收用户输入,该用户输入使助理设备或另外的助理设备中的一个或多个在周围感测事件的阈值持续时间内执行用户发起的动作。
127.在一些实施方式中,阈值持续时间能够包括在周围感测事件之前的时间的第一部分,并且阈值持续时间还能够包括在周围感测事件之后的时间的第二部分。在一些实施方式中,阈值持续时间在周围感测事件之后。在一些实施方式中,能够基于周围感测事件的类型来确定阈值持续时间。
128.在一些实施方式中,该方法能够进一步包括在使得基于训练实例和多个另外的训练实例训练周围感测ml模型之后:使助理设备在基于处理传感器数据的另外的实例来生成一个或多个建议的动作时利用周围感测ml模型,该一个或多个建议的动作被建议由助理设备或另外的助理设备代表用户执行;以及使建议的动作中的一个或多个的表示被提供以供经由助理设备或另外的助理设备呈现给用户。
129.在那些实施方式的一些版本中,该方法能够进一步包括,响应于接收到对动作中
的一个或多个的用户选择:利用用户选择作为用于更新训练后的周围感测ml模型的正反馈信号。在另外或替代的实施方式中,该方法能够进一步包括,响应于未接收到对动作中的一个或多个的用户选择,利用用户选择的缺少作为用于更新训练后的周围感测ml模型的负反馈信号。
130.在一些实施方式中,生成训练实例能够进一步基于以下一个或多个:当对应于周围感测事件的传感器数据实例被检测到时的时间或周中日。
131.在一些实施方式中,提供了一种由一个或多个处理器实现的方法,并且该方法包括:基于传感器数据的实例确定周围状态,传感器数据的实例是经由用户的助理设备的一个或多个传感器检测到的,并且周围状态反映用户的状态或用户的环境的状态;使用训练后的周围感测机器学习(ml)模型来处理周围状态以生成一个或多个建议的动作,该一个或多个建议的动作被建议由用户的助理设备或另外的助理设备代表用户执行;使建议的动作中的一个或多个的对应表示被提供以供经由助理设备或另外的助理设备呈现给用户;以及响应于接收到对建议的动作中的一个或多个的对应表示的用户选择:使建议的动作中的一个或多个由助理设备或另外的助理设备代表用户执行。
132.本文中公开的技术的这些和其他实施方式能够包括以下特征中的一个或多个。
133.在一些实施方式中,一个或多个建议的动作中的每一个与预测量度相关联。在那些实施方式的一些版本中,使一个或多个建议的动作的表示被提供以供呈现给用户能够是响应于确定与一个或多个建议的动作中的每一个相关联的预测量度满足第一阈值量度以及响应于确定与一个或多个建议的动作中的每一个相关联的预测量度未能满足第二阈值量度。
134.在一些实施方式中,使一个或多个建议的动作的对应表示被提供以供经由助理设备或另外的助理设备呈现给用户能够包括使针对一个或多个建议的动作中的每一个的对应的可选择元素在助理设备或另外的助理设备的显示器处在视觉上被渲染。在一些实施方式中,接收对建议的动作中的一个或多个的对应表示的用户选择能够包括接收对对应的可选择元素中的给定对应的可选择元素的用户选择。
135.在一些实施方式中,使一个或多个建议的动作的对应表示被提供以供经由助理设备或另外的助理设备呈现给用户能够包括使一个或多个建议的动作的指示在助理设备或另外的助理设备的一个或多个扬声器处被可听地渲染。在那些实施方式的一些版本中,接收对建议的动作中的一个或多个的对应表示的用户选择能够包括经由用户的口语话语接收用户选择,该用户的口语话语是经由助理设备或另外的助理设备的一个或多个麦克风检测到的。
136.在一些实施方式中,该方法能够进一步包括使周围状态的指示被提供以供连同一个或多个动作的表示一起呈现给用户。
137.在一些实施方式中,基于传感器数据的实例确定周围状态能够包括处理传感器数据的实例以确定周围状态。在那些实施方式的一些版本中,传感器数据的实例捕获以下一个或多个:音频数据、运动数据或配对数据。
138.在一些实施方式中,提供了一种由一个或多个处理器实现的方法,并且该方法包括:基于传感器数据的实例确定周围状态,传感器数据的实例是经由用户的助理设备的一个或多个传感器检测到的,并且周围状态反映用户的状态或用户的环境的状态;使用训练
后的周围感测机器学习(ml)模型来处理周围状态以生成一个或多个建议的动作,该一个或多个建议的动作被建议由用户的助理设备或另外的助理设备代表用户执行;以及使建议的动作中的一个或多个由助理设备或另外的助理设备代表用户自动地执行。
139.本文中公开的技术的这些和其他实施方式能够包括以下特征中的一个或多个。
140.在一些实施方式中,一个或多个建议的动作中的每一个能够与预测量度相关联。在那些实施方式的一些版本中,使建议的动作中的一个或多个由助理设备或另外的助理设备自动地执行能够响应于确定与一个或多个建议的动作中的每一个相关联的预测量度满足第一阈值量度以及响应于确定与一个或多个建议的动作中的每一个相关联的预测量度满足第二阈值量度。
141.此外,一些实施方式包括一个或多个计算设备的一个或多个处理器(例如、(多个)中央处理单元(cpu)、(多个)图形处理单元(gpu)和/或(多个)张量处理单元(tpu)),其中一个或多个处理器可操作以执行存储在相关存储器中的指令,并且其中指令被配置成引起前述方法中的任一种的执行。一些实施方式还包括一个或多个非暂时性计算机可读存储介质,该一个或多个非暂时性计算机可读存储介质存储可由一个或多个处理器执行来执行前述方法中的任一种的计算机指令。一些实施方式还包括计算机程序产品,该计算机程序产品包括可由一个或多个处理器执行来执行前述方法中的任一种的指令。
142.应该理解,前面的构思以及本文中更详细地描述的另外的构思的所有组合都被设想为是本文中公开的主题的部分。例如,在本公开的末尾处出现的要求保护的主题的所有组合都被设想为是本文中公开的主题的部分。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1