用于数据传输指令的寄存器寻址信息的制作方法
用于数据传输指令的寄存器寻址信息
1.本技术涉及数据处理领域。
2.数据传输指令可在数据处理中用于控制向或从寄存器存储装置传输数据。
3.至少一些示例提供了一种装置,该装置包括:指令解码电路,该指令解码电路用于对指令进行解码;寄存器存储装置,该寄存器存储装置用于存储数据;以及处理电路,该处理电路用于响应于由该指令解码电路解码的指令来执行数据处理,以生成要写入该寄存器存储装置中的至少一个寄存器的处理结果;其中:响应于指定用于识别该寄存器存储装置的目标部分的寄存器寻址信息的数据传输指令,该指令解码电路被配置为控制该处理电路执行数据传输操作以向或从该寄存器存储装置的该目标部分传输数据;并且该寄存器寻址信息至少包括:基址寄存器标识,该基址寄存器标识识别该寄存器存储装置中的用于存储基址值的基址寄存器;以及立即值,该立即值在该数据传输指令的编码中指定,该立即值表示要与该基址值相加以提供索引值的值,该索引值用于选择该寄存器存储装置的该目标部分。
4.至少一些示例提供了一种方法,该方法包括:对指令进行解码;以及响应于被解码的指令,控制处理电路执行数据处理以生成要写入寄存器存储装置中的至少一个寄存器的处理结果;其中:响应于指定用于识别该寄存器存储装置的目标部分的寄存器寻址信息的数据传输指令,控制该处理电路执行数据传输操作以向或从该寄存器存储装置的该目标部分传输数据;并且该寄存器寻址信息至少包括:基址寄存器标识,该基址寄存器标识识别该寄存器存储装置中的用于存储基址值的基址寄存器;以及立即值,该立即值在该数据传输指令的编码中指定,该立即值表示要与该基址值相加以提供索引值的值,该索引值用于选择该寄存器存储装置的该目标部分。
5.一种计算机程序,该计算机程序用于控制主机数据处理装置以提供用于执行目标代码的指令的指令执行环境,该计算机程序包括:指令解码程序逻辑,该指令解码程序逻辑用于对该目标代码的指令进行解码,以控制该主机数据处理装置执行与被解码的指令相对应的处理操作;以及寄存器仿真程序逻辑,该寄存器仿真程序逻辑用于在该主机数据处理装置的主机存储装置中维护寄存器仿真数据结构,以对与该目标代码相关联的目标指令集架构的寄存器存储装置进行仿真;其中响应于指定用于识别该寄存器存储装置的目标部分的寄存器寻址信息的数据传输指令,该指令解码程序逻辑被配置为控制该主机数据处理装置执行数据传输操作,以向或从该寄存器仿真数据结构的与该寄存器存储装置的该目标部分相对应的位置传输数据;并且该寄存器寻址信息至少包括:基址寄存器标识,该基址寄存器标识识别该寄存器存储装置中的用于存储基址值的基址寄存器;以及立即值,该立即值在该数据传输指令的编码中指定,该立即值表示要与该基址值相加以提供索引值的值,该索引值用于选择该寄存器存储装置的该目标部分。
6.至少一些示例提供了一种存储介质,该存储介质存储上述计算机程序。存储介质可以是暂态存储介质或非暂态存储介质。
7.本技术的另外的方面、特征和优点将从结合附图阅读的示例的以下描述中显而易见,在这些附图中:
8.图1示意性地示出了支持矩阵处理的数据处理装置的第一示例;
9.图2a至图2d示出了支持矩阵处理的数据处理装置的第二示例;
10.图3示出了可以如何将矩阵乘法运算拆分为外积运算以生成等效结果;
11.图4示出了外积引擎的示例,该外积引擎用于对一对向量操作数执行外积运算以生成二维(2d)数据阵列作为结果;
12.图5示出了处理装置的架构寄存器的示例,该架构寄存器包括用于存储向量操作数的向量寄存器和用于存储2d数据阵列的阵列寄存器;
13.图6示出了阵列寄存器的物理具体实施的示例;
14.图7至图11示出了可以如何将阵列寄存器的物理存储容量逻辑地划分为可变数量的架构阵列寄存器;
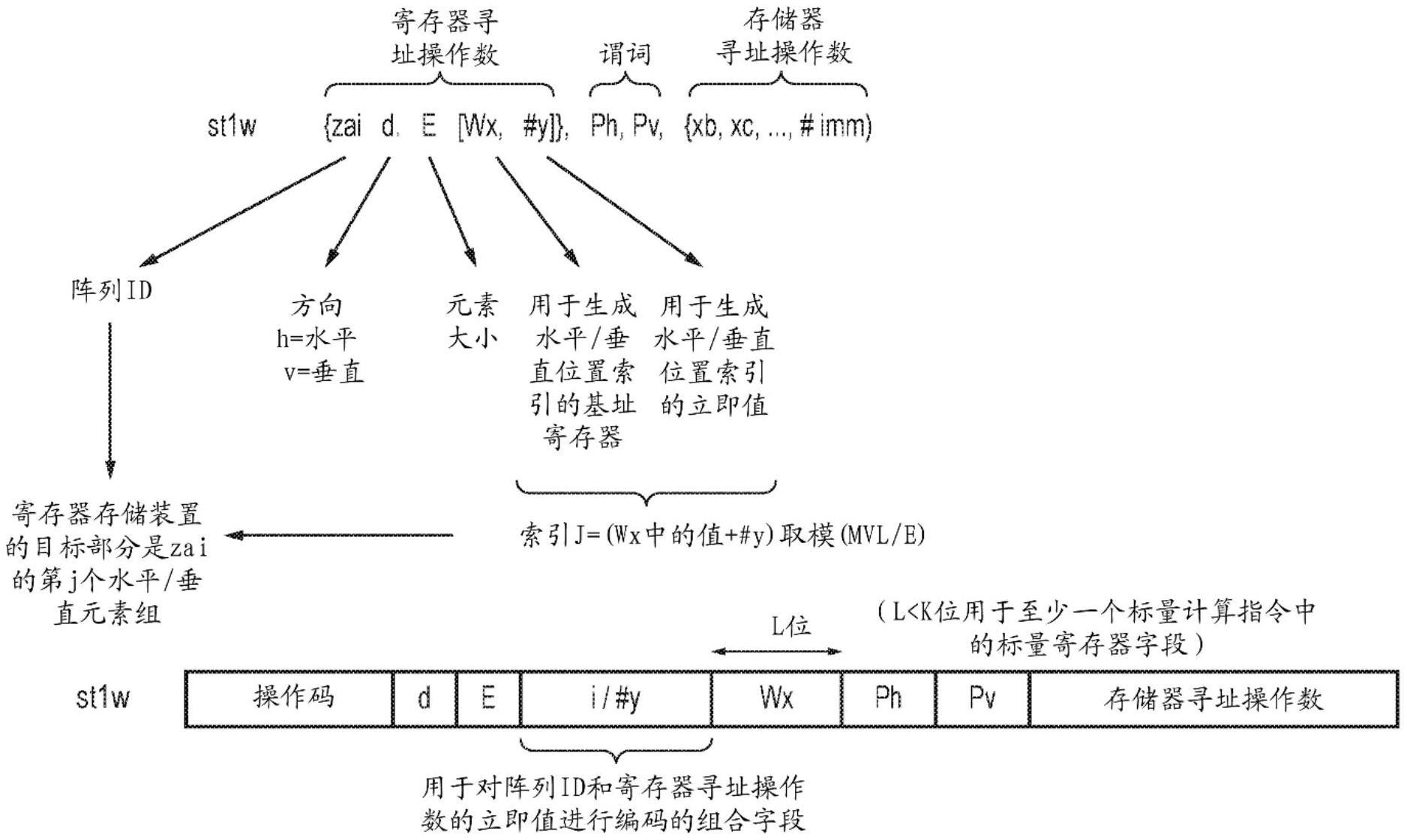
15.图12示出了用于在阵列寄存器存储装置与存储器之间传输2d数据阵列的一部分的加载/存储数据传输指令的编码的示例;
16.图13示出了使用数据传输指令的指令编码的组合字段对阵列标识和立即值进行编码的示例;
17.图14示出了使用图12的数据传输指令的程序代码的示例;
18.图15示出了用于在阵列寄存器与向量寄存器之间传输2d数据阵列的一部分的寄存器移动数据传输指令的示例;
19.图16是示出处理指令的方法的流程图;并且
20.图17示出了可以使用的模拟器示例。
21.数据处理装置可以具有用于对指令进行解码的指令解码电路和用于响应于被解码的指令而执行数据处理的处理电路。可以提供寄存器存储装置以存储数据。寄存器存储装置可以用于提供用于由处理电路进行处理的操作数。当处理电路响应于指令而生成处理结果时,可以将该处理结果写入寄存器存储装置中的至少一个寄存器。
22.数据传输指令被提供用于向或从寄存器存储装置传输数据。响应于数据传输指令,指令解码电路控制处理电路执行数据传输操作。数据传输操作包括向或从寄存器存储装置的目标部分传输数据。数据传输指令指定识别寄存器存储装置的目标部分的寄存器寻址信息。
23.在典型的数据传输指令中,用作寄存器存储装置的目标部分的寄存器可以由指令编码中的寄存器字段来识别,其中寄存器字段中的值是直接指定要向/从其传输数据的架构寄存器的标识。
24.然而,在下文所讨论的示例中,寄存器寻址信息至少包括基址寄存器标识和立即值。基址寄存器标识识别寄存器存储装置中的用于存储基址值的基址寄存器,并且立即值在数据传输指令的编码中被直接指定并且表示要与基址值相加以提供用于选择寄存器存储装置的目标部分的索引值的值(针对该目标部分的数据要被传输到存储器或者数据要从存储器被传输到该目标部分)。
25.使用基址寄存器和立即值来定义寄存器寻址信息的这种方法将被指令集架构结构设计领域的技术人员视为违反直觉的。虽然基于基址寄存器和立即值的寻址对于存储器寻址可能是已知的,但是对于寄存器寻址似乎是不必要的,因为原本期望在数据传输中要访问的特定寄存器可以由要执行的程序代码的编译器直接选择,并且因此不需要使用对基
址寄存器的间接引用。然而,发明人认识到,使用基址寄存器来提供用于生成索引以选择寄存器存储装置的目标部分的基址值的寄存器寻址信息对于允许编译器生成可以动态地适应可缩放数据存储大小的代码可以是有用的。
26.而且,当生成索引值时使用立即值来提供要与基址值相加的偏移对于使编译器能够使用称为循环展开的技术可以是有用的,该技术可以帮助减少控制程序循环的迭代的开销。在执行循环控制指令(诸如用于递增循环计数器或其它变量(诸如数据传输指令的基址寄存器中的基址值)的指令)时,以及在测试是否满足循环终止条件时,循环的每次迭代可能招致性能损失。通过执行循环展开,编译器可以将在由程序员写入的高级代码中包括的循环的一组两次或更多次迭代映射到经编译代码中的单次循环迭代,该单次循环迭代执行与高级代码循环中的两次或更多次迭代相同的操作。这减少了针对高级代码中的给定循环迭代数量而需要执行循环控制指令的次数,并且实现更大的指令级并行性,因为如果来自高级代码中的循环的后续迭代的一些指令与较早迭代的指令是独立的,则它们可以并行执行,而如果循环已经被编译到在经编译代码中每次循环迭代实现单次高级循环迭代的代码中,则用于高级循环的后续迭代的指令可以取决于来自较早迭代的指令,从而减少可能的并行性的量。使用基址寄存器和立即值来定义寄存器寻址信息对于支持循环展开是有用的,因为立即值可以用于将不同偏移与基址寄存器中的值相加,以用于与高级代码循环的单独迭代的展开版本相对应的不同数据传输指令,这些迭代的展开版本在经编译代码中被组合成单次循环迭代。
27.因此,概括地说,具有如上所述使用基址寄存器标识和立即值定义的寄存器寻址信息的数据传输指令对于支持可缩放代码可以是特别有用的,该可缩放代码可以缩放为不同的数据存储大小并且可以允许编译器执行循环展开。
28.立即值表示要与基址值相加以提供用于选择寄存器存储装置的目标部分的索引值的值。在指令的一些具体实施中,要与基址值相加的值可以是被指定为立即值的确切值。在其它示例中,立即值可以具有不直接指定要相加的值的编码。例如,立即值可以将要相加的值指定为给定常数z的倍数,使得z与立即值的乘积与基址值相加。
29.而且,在一些示例中,索引值可以等于基址值与由立即值表示的值的和。在其它示例中,索引值可以取决于基址值与由立即值表示的值的加法,但可以不确切地等于基址值与由立即值表示的值的和。例如,为了处置基址值的范围外的值,在一些情况下,索引值可以对应于:基址值与由立即值表示的值的和,针对被选择用于确保所得索引在所要求的范围内的给定值进行取模(即,索引值是和除以给定值之后的余数)。
30.使用基址寄存器标识和立即值对寄存器寻址信息的编码可以应用于任何形式的数据传输指令,包括索引值用于其以选择在数据传输中要访问哪个整数寄存器、浮点寄存器、向量寄存器或其它类型的寄存器存储装置的数据传输指令。
31.然而,在一个示例中,寄存器存储装置包括用于存储至少一个2d数据阵列的二维(2d)阵列寄存器存储装置,并且寄存器存储装置的目标部分包括2d阵列寄存器存储装置的目标部分。因此,在该示例中,数据传输指令可以为用于向或从阵列寄存器存储装置传输2d数据阵列的至少一部分的阵列数据传输指令。2d阵列(诸如矩阵)对于广泛的处理应用是有用的。一个示例是在机器学习领域中,其中矩阵乘法可以为用于许多类型的机器学习模型的推断和训练算法的骨干,但是其它应用也可以使用矩阵算术,诸如在增强现实、虚拟现
和“垂直组”可以用于指存储在2d阵列寄存器存储装置中的2d阵列中的元素的布置。
39.在一些具体实施中,数据传输指令可以仅支持在水平/垂直方向中的一者上向/从2d阵列寄存器存储装置传输数据。例如,一些具体实施可以仅支持在水平方向上访问2d阵列寄存器存储装置。这可以简化用于访问2d阵列寄存器存储装置的电路逻辑。
40.然而,在其它示例中,指令集架构(isa)可以支持在水平和垂直两个方向上读取/写入2d阵列寄存器存储装置。因此,数据传输指令可以指定识别水平方向和垂直方向中的一者的阵列方向标识。当阵列方向标识识别水平方向时,目标2d阵列的子部分包括由索引值识别的目标2d阵列的至少一个水平元素组,每个水平元素组包括在目标2d阵列内共享同一垂直位置的元素。当阵列方向标识识别垂直方向时,目标2d阵列的子部分包括由索引值识别的目标2d阵列的至少一个垂直元素组,每个垂直元素组包括在目标2d阵列内共享同一水平位置的元素。这对于在将数据从存储器传输到2d阵列寄存器存储装置中时或在将数据从2d阵列寄存器存储装置传输回到存储器时实现矩阵的即时转置可以是有用的,由于当在存储器与寄存器存储装置之间传输矩阵数据时,此类即时转置可以远快于执行大量加载/存储指令或向量重组指令以混洗元素,因此即时转置在矩阵存储器布局与计算的要求不兼容的情况下帮助提高应用的性能。
41.数据传输指令可以用于处理以特定固定数据元素大小定义的2d阵列的实施方案,其中元素大小是指2d阵列的一个单个元素中的位数。
42.然而,支持可变数据元素大小可以是有用的,使得数据传输指令可以用于可以处理使用不同精度水平的数据值定义的矩阵的应用。因此,数据传输指令可以与来自由处理电路支持的两个或更多个数据元素大小当中针对数据传输指令指定的当前数据元素大小e相关联。
43.可以各种方式针对数据传输指令指定当前数据元素大小e。在一些情况下,数据传输指令自身的参数可以指定当前信息元素大小e。例如,数据传输指令的指令编码的一部分可以指定当前信息元素大小e。另一选项是存储在控制寄存器或其它存储位置中的控制信息可以定义当前信息元素大小e。在这种情况下,数据传输指令自身的编码不需要包括标识当前信息元素大小e的任何位。在执行数据传输指令之前执行的指令可以用于设置控制存储位置中的值,以设置要用于后续数据传输指令的当前数据元素大小e。一些方法还可以使用模态方法,其中所使用的当前数据元素大小取决于处理电路在执行数据传输指令时正在其中操作的操作模式。因此,应当理解,存在可以标识针对给定数据传输指令的当前数据元素大小e的多种方式。
44.在支持可变数据元素大小的具体实施中,可以使用数据传输指令的指令编码的特定位数n
imm
来编码寄存器寻址信息的立即值,其中n
imm
根据当前数据元素大小e是可变的,其中n
imm
随着e减小而增大。在立即值用于生成标识在响应于数据传输指令而执行的数据传输中要传输目标2d阵列的哪个子部分的索引的情况下,该方法可以是特别有用的。随着数据元素大小减小,这意味着更大数量的数据元素可以装在给定大小的寄存器内,从而支持在水平/垂直方向中的与寄存器的宽度相对应的第一方向上具有更大维度的2d阵列。通过随着元素大小减小而增大立即值的大小,这允许选择目标2d阵列的更大数量的子部分,从而使2d阵列在相反的垂直/水平方向上的第二维度能够以与在第一方向上的缩放相当的方式进行缩放。通过使用具有可变长度的立即值的编码,使得与数据元素大小较小时相比,当数
据元素大小较大时使用较小位数来编码立即值,在较大元素大小下,这可以释放一些额外位,这些额外位可以用于编码其它参数。
45.在一个示例中,2d阵列寄存器存储装置可以包括特定数量nr个向量寄存器,其中每个向量寄存器包括特定位数mvl(mvl指示单个向量寄存器的“向量长度”)。通过将2d阵列寄存器存储装置实现为向量寄存器组,这可以简化处理器的微架构的具体实施,因为用于提供用于将1d数据阵列存储为向量的向量寄存器的技术可以再用于实现2d阵列寄存器存储装置。例如,单个2d数据阵列可以在向量寄存器组内表示,其中该组中的每个向量寄存器存储2d阵列的不同的水平(或垂直)元素组,并且该向量寄存器组作为整体存储多个此类元素组以形成2d阵列。
46.在一些具体实施中,由处理电路和指令解码电路支持的isa可以支持可变向量长度mvl用于2d阵列寄存器存储装置的向量寄存器。这允许微架构设计者根据设计偏好(诸如是优先考虑更高性能还是更高能量效率)来改变在给定微架构处理器具体实施上使用的寄存器的大小。例如,isa可以支持从最小向量长度mvl
min
延伸到最大向量长度mvl
max
的向量长度范围。
47.为了简化软件开发,设计isa可以是有用的,使得程序代码可以在使用不同向量长度mvl的一系列处理器上正确地操作,而不需要对程序代码进行任何修改以解决向量长度的此类差异。该属性可以称为是程序代码是向量长度无关的。例如,isa可以支持指示在当前平台上实现的向量长度的寄存器,该向量长度对于给定具体实施可以是静态的,但是可以在处理器具体实施之间变化,并且程序代码可以在控制程序代码循环时引用该寄存器以根据所实现的向量长度mvl来改变每次循环迭代处理多少数据。因此,具有给定的待处理数据量的程序可以在实现较长向量长度的微架构上使用比在实现较短长度的微架构上更少的循环迭代来处理该数据,但在两种情况下都执行相同的功能处理操作以生成相同的计算结果(尽管具有不同的性能水平)。
48.立即值可以表示要传输2d阵列的哪个子部分。由于可以装在向量寄存器内的元素的数量随着向量长度mvl增大而增大,可能想到(为了允许2d阵列的其它维度类似地缩放),应向立即值提供足够的位数,以能够区分与实现最大向量长度mvl
max
时可以装在一个向量寄存器内的元素的数量相对应的向量寄存器的数量。
49.然而,发明人认识到,在实践中,如果针对立即值的不同编码的数量大于mvl
min
/e(具有由isa支持的最小向量长度mvl
min
的向量寄存器内的元素的数量),则这将意味着程序代码将不是向量长度无关的,因为指定大于mvl
min
/e的索引的指令不能在实现最小向量长度mvl
min
的微架构上正确地操作。因此,在设计用于向量长度无关的isa中,不值得花费指令编码的附加位来提供较大的立即值。通过限制立即值编码的位数使得不同编码的数量小于或等于mvl
min
/e,这释放了用于其它参数的编码位空间,并且改进了对向量长度无关性的支持。
50.当然,如果在对于其而言向量长度无关性不优先的isa中实现上述数据传输指令,则仍然可以支持立即值的较大值。
51.在一些示例中,基于寄存器寻址信息的基址值和立即值生成的索引值可以是用于选择要对其执行数据传输的寄存器存储装置的目标部分的唯一寄存器标识信息项。例如,索引值可以指定上述在2d阵列寄存器存储装置内的各个向量寄存器的寄存器标识。在该方
法中,尽管可以将向量寄存器组作为整体视为形成2d数据阵列(诸如矩阵),但指令可以通过指定用于存储阵列的单个水平/垂直元素组的向量寄存器的特定寄存器标识来引用该元素组。
52.然而,特定编程技术需要处理多个2d阵列,而不是单个水平/垂直元素组。因此,另一种方法可以是2d阵列寄存器存储装置能够被逻辑地划分为至少两个阵列存储区域,其中每个阵列存储区域存储相应的2d阵列。除了索引值之外,寄存器寻址信息还可以包括识别2d阵列寄存器存储装置的被选择的阵列存储区域的阵列标识。在这种情况下,索引值可以识别所选择的阵列存储区域的哪个子部分是寄存器存储装置的目标部分。因此,数据传输指令可以指定要被访问以进行数据传输的阵列的阵列id,并且使用基址寄存器和立即值定义的索引值可以用于从该阵列选择单个水平/垂直元素组。这种方法可以使软件更简单地定义程序循环,该程序循环在阵列中的每个水平/垂直元素组上循环以向/从寄存器存储装置传输2d阵列。
53.在一些具体实施中,将2d阵列寄存器存储装置划分为阵列存储区域可以是固定的,使得给定阵列标识总是对应于2d阵列寄存器存储装置的特定固定部分。例如,当如上所讨论使用一组向量寄存器来实现2d阵列寄存器存储装置时,每个阵列存储区域可以对应于向量寄存器的固定块。
54.然而,在如上所讨论支持可变数据元素大小的具体实施中,使用取决于当前数据元素大小的变量映射对于将2d阵列寄存器存储装置划分为阵列存储区域可以是有用的。处理电路可以基于取决于针对数据传输操作指定的当前数据元素大小e的变量映射来识别2d阵列寄存器存储装置的哪个部分是与阵列标识的给定值相对应的阵列存储区域。这可以通过提高在硬件中实现的可用寄存器容量的利用效率来帮助提高性能。
55.如上所述,当数据元素大小e可变时,则这意味着单个寄存器可以存储可变数量的数据元素,但是可能期望阵列的第二维度以类似方式缩放,使得如果更大数量的元素装在一个向量寄存器(表示水平或垂直方向)内,则阵列也跨越更大数量的向量寄存器(表示阵列在水平/垂直方向中的另一个方向上的维度)。如果更大数量的向量寄存器被分配用于表示单个2d阵列结构,则这意味着总共更少的2d阵列可以被容纳在2d阵列寄存器存储装置作为整体的可用寄存器存储容量内。另一方面,当数据元素大小变得更大时,则每个向量寄存器可以在阵列的第一维度中存储更少的数据元素,因此需要更少的向量寄存器来容纳阵列的另一个维度,从而允许更大数量的不同2d阵列装在可用硬件存储容量内。如果在阵列标识与阵列存储区域之间使用固定映射,则每个存储区域将必须大到足以存储采用最小数据元素大小的2d阵列,这在使用较大元素大小的情况下将浪费存储容量。通过如上所述在阵列标识与阵列存储区域之间使用变量映射,可以调整划分以充分利用可用寄存器容量,这可以帮助提高性能,因为当更多阵列可以装在寄存器存储装置内时,则可以减少每个计算指令执行的(较慢)加载/存储指令的数量。
56.在一个示例中,2d阵列寄存器存储装置可以被逻辑地划分为特定数量na个阵列存储区域,并且na可以根据当前数据元素大小e而变化,其中na随着e增大而增大。这种关系可以被视为违反直觉的,因为通常(在向量处理的情况下)原本期望分区的数量随着数据元素大小增大而减小。然而,在2d阵列处理的情况下,尽管在第一维度中装在单个寄存器内的元素的数量随着元素大小e增大而减小,但是在元素在其中跨向量寄存器条带化布置的第二
维度中,每个元素需要单个向量寄存器(无论其元素大小如何),因此在第二维度中用于单个2d阵列的向量寄存器的数量实际上随着增大的元素大小而减小。因此,可以装在特定量的物理存储量中的阵列存储区域的总数(na)可以随着元素大小增大而增大。
57.由于以较小元素大小区分的阵列存储区域比以较大元素大小区分的阵列存储区域更少,因此由数据传输指令编码的阵列标识也可以具有取决于当前元素大小e的可变位数。然而,与如前所讨论的立即值与当前数据元素大小的关系相比,阵列标识所需的位数可以与当前数据元素大小e具有相反的关系。阵列标识在较大数据元素大小时可以具有比在较小数据元素大小时更多的位数,而立即值在较小数据元素大小时可以具有比在较大数据元素大小时更多的位数。
58.因此,虽然数据传输指令的一些具体实施可以利用指令编码内的两个不同的非共享字段对阵列标识和立即值进行编码,但是一种特别有效的编码可以是使用数据传输指令的指令编码的位的共享部分对阵列标识和立即值进行编码。对于该共享部分内的给定位,指令解码电路根据针对数据传输指令指定的当前数据元素大小e而变化,无论该给定位是被解释为指示阵列标识的一部分还是指示立即值的一部分。这可以帮助减少表示阵列标识和立即值两者所需的总位数,从而释放指令编码中的用于其它目的的其它位。这在isa设计中可以是非常有价值的,因为编码空间通常是很有限的。
59.在一些示例中,数据传输指令的指令编码的用于对阵列标识和立即值进行编码的总位数可以是恒定的,与当前数据元素大小e无关。
60.在一些示例中,数据传输指令可以是指定寄存器寻址信息和用于识别存储器目标部分的存储器寻址信息的加载/存储指令,针对该指令,数据传输操作包括在寄存器存储装置的目标部分与存储器目标部分之间传输数据。在这种情况下,可以根据任何已知存储器寻址模式(例如,使用基址寄存器和偏移寄存器,或者使用基址寄存器和立即值来定义要访问的存储器地址)来定义存储器寻址信息。
61.此外,数据传输指令可以是指定寄存器寻址信息和用于识别寄存器存储装置的另外部分的另外寄存器寻址信息的寄存器移动指令,并且数据传输操作可以包括在寄存器存储装置的目标部分与寄存器存储装置的另外部分之间传输数据。在这种情况下,虽然可以如前所述使用基址寄存器标识来识别寄存器存储装置的目标部分,但是另外寻址信息不需要包括基址寄存器标识。例如,另外寻址信息可以简单地是寄存器标识,该寄存器标识直接指定要访问的寄存器作为寄存器存储装置的另外部分。例如,在先前提到的寄存器存储装置的目标部分是2d阵列寄存器存储装置的一部分的示例中,寄存器存储装置的另外部分可以是向量寄存器。
62.因此,数据传输指令可以用于在寄存器存储装置与存储器之间传输数据,或者用于在寄存器存储装置的各个部分之间传输数据。一些isa可能仅支持加载/存储指令和寄存器移动指令中的一者使用基址寄存器标识和立即值作为寄存器寻址信息的一部分(其中另一类型的指令不使用基于基址寄存器标识和立即值的寻址)。其它isa可以支持加载/存储指令和寄存器移动指令两者使用包括基址寄存器标识和立即值的寄存器寻址信息。
63.应当理解,包括包含基址寄存器标识和立即值的寄存器寻址信息的数据传输指令可以不是由指令解码电路和处理电路实现的isa中支持的唯一类型的数据传输指令。还可以存在其它类型的数据传输指令,这些指令不使用基址寄存器标识和立即值来定义用于选
择在数据传输中要访问的寄存器存储装置的一部分的索引。
64.针对寄存器寻址信息标识的基址寄存器可以是标量寄存器。标量寄存器是旨在存储单个数据值的寄存器(与向量寄存器相反,向量寄存器可以被划分为多个独立数据元素,其中每个数据元素表示不同的数据值)。
65.在一些具体实施中,可以从可供指令选择的特定的标量寄存器池当中选择标量寄存器。例如,标量计算指令可以具有k位标量寄存器字段,该字段用于指定要存储针对指令的操作数或指令的结果的特定标量寄存器作为指令的源或目标寄存器。在k位标量寄存器字段的情况下,这可以允许系统支持2k个不同的标量寄存器。
66.在一些具体实施中,如果isa中支持的不同的标量寄存器的数量为2k,则用于寄存器寻址信息的基址寄存器字段的位数可以是k位,使得可以选择所支持的标量寄存器中的任一者作为基址寄存器。
67.然而,在其它示例中,数据传输指令可以使用l位标量寄存器字段来指定基址寄存器,其中l《k,使得能够指定为针对至少一个标量计算指令的源或目标寄存器的至少一个标量寄存器不能被指定为用于数据传输指令的寄存器寻址信息的基址寄存器。即,基址寄存器字段是压缩字段,该字段比允许选择架构中支持的任何标量寄存器原本所需的位数更短。这可以帮助释放指令编码中的用于其它目的的位。在实践中,将基址寄存器限制为从标量寄存器的有限子集中选择可以足以处置针对应用的期望用例(诸如矩阵处理)。
68.指令解码电路可以支持2d阵列生成计算指令,响应于该指令,指令解码电路控制处理电路执行计算操作以生成要写入2d阵列寄存器存储装置的2d结果值阵列。2d结果值阵列可以响应于2d阵列生成计算指令的单个实例而生成。在可以支持响应于单个指令而生成2d值阵列的系统中,处理吞吐量可以远大于使用向量处理一次处理单个1d数据阵列的具体实施。如上所讨论,这对于诸如机器学习和信号处理等应用可以是特别有用的。例如,计算操作可以是矩阵乘法运算,其中用于计算的输入操作数是2d数据阵列,并且结果是表示将由2d阵列操作数表示的矩阵相乘的结果的2d阵列。然而,在其它示例中,计算操作可以包括对第一向量操作数和第二向量操作数执行的外积运算,以生成2d结果值阵列。在硬中实现外积运算可以比全矩阵乘法更简单。累加一系列外积运算的结果可以生成与矩阵乘法等效的结果。因此,计算指令可以是外积及累加指令,该指令除了生成两个向量的外积之外,还将所得元素加到累加器2d元素阵列(例如,存储在上述寄存器存储装置的2d阵列存储区域中的一个区域中)。上文所讨论类型的数据传输指令对于支持此类2d阵列生成计算指令的系统是特别有用的,因为该指令允许有效地访问2d阵列寄存器的各个水平/垂直元素组。数据传输指令的编码允许此类访问由编译器展开并被调度,同时仍然能够动态地适应可缩放阵列大小。
69.上文所讨论技术可以在数据处理装置内实现,该数据处理装置具有提供用于实现指令解码器和上文所讨论的处理电路的硬件电路。
70.然而,同样的技术也可以在计算机程序内实现,该计算机程序在主机数据处理装置上执行以提供用于执行目标代码的指令执行环境。此类计算机程序可以控制主机数据处理装置来模拟将在目标数据处理装置上提供的架构环境,该目标数据处理装置实际上支持根据特定isa的目标代码,即使主机数据处理装置自身不支持该架构。例如,当在支持不同isa的主机处理器上执行针对一种isa编写的遗留代码时,这种模拟程序是有用的。另外,模
拟可以允许在支持新架构版本的处理硬件准备好之前开始针对isa的较新版本的软件开发,因为软件在模拟执行环境上的执行可以使得软件测试与支持该新架构的硬件设备的正在进行的开发并行地进行。模拟程序可以存储在存储介质上,该存储介质可以是非暂态存储介质。
71.因此,计算机程序可以包括指令解码程序逻辑,该解码程序逻辑对目标代码的程序指令进行解码,以控制主机数据处理装置响应于程序指令而执行数据处理(例如,将目标代码中的每个指令映射到主机的本地指令集中实现等效功能的一系列一个或多个指令)。此外,计算机程序可以具有寄存器仿真程序逻辑,该寄存器仿真程序逻辑在主机数据处理装置的主机存储装置中(例如,主机的寄存器或存储器中)维护数据结构,以对正被仿真的目标isa的寄存器存储装置(原本期望该寄存器存储装置在实际支持目标isa的处理器中的硬件中被提供)进行仿真。
72.在此类具体实施中,指令解码程序逻辑可以支持具有如上所讨论的相同寄存器寻址信息的数据传输指令,但在这种情况下,基于寄存器寻址信息对寄存器存储装置的引用由寄存器仿真数据结构映射到存储在主机存储装置中的寄存器仿真数据结构的对应位置。因此,基址寄存器标识和立即值可以用于识别在针对数据传输指令的数据传输中要访问仿真寄存器的哪个部分,该数据传输指令在目标处理装置上的执行正在主机装置上进行仿真。
73.图1示意性地示出了数据处理装置20的示例。数据处理装置具有包括多个流水线阶段的处理流水线24。在该示例中,该流水线包括:提取级26,该提取级用于从指令高速缓存28中提取指令;解码级(指令解码电路)30,该解码级用于对所提取的程序指令进行解码,以生成要由流水线的其余级处理的微操作;发出级32,该发出级用于检查微操作所需的操作数在寄存器文件34中是否可用,并且一旦给定微操作所需的操作数可用就发出供执行的微操作;执行级36(处理电路),该执行级用于通过处理从寄存器文件34读取的操作数以生成结果值来执行对应于微操作的数据处理操作;以及写回级38,该写回级用于将处理的结果写回到寄存器文件34。应当理解,这仅仅是可能的流水线架构的一个示例,并且其他系统可具有附加阶段或不同的阶段配置。例如,在乱序处理器中,可以包括寄存器重命名级,该寄存器重命名级用于将由程序指令或微操作指定的架构寄存器映射到标识寄存器文件34中的物理寄存器的物理寄存器指定符。
74.执行级36包括用于执行不同类别的处理操作的多个处理单元。例如,执行单元可包括标量算术/逻辑单元(alu)40,该标量alu用于对从寄存器34读取的标量操作数执行算术或逻辑操作;浮点单元42,该浮点单元用于对浮点值进行操作;分支单元44,该分支单元用于评估分支操作的结果并且相应地调整表示当前执行点的程序计数器;矩阵处理单元46,该矩阵处理单元用于矩阵处理(其将在下面更详细地讨论);以及加载/存储单元48,该加载/存储单元用于执行加载/存储操作以访问存储器系统50、52、54中的数据。
75.在该示例中,存储器系统包括一级数据高速缓存50、共享二级高速缓存52和主系统存储器54。应当理解,这仅为可能的存储器分级结构的一个示例,并且还可以提供其他高速缓存布置方式。在执行级36中示出的处理单元40到48的具体类型仅为一个示例,并且其他具体实施可具有一组不同的处理单元或可包括同一类型的处理单元的多个实例,使得可以并行处理同一类型的多个微操作。应当理解,图1仅仅是可能的处理器流水线架构的一些
组件的简化表示,并且处理器可包括其他许多为简洁起见未示出的元件。
76.在一些具体实施中,数据处理装置20可以是多处理器装置,其包括多个cpu(中央处理单元或处理器内核)60,每个cpu具有与针对图1的cpu 60中的一个cpu所示的处理流水线类似的处理流水线24。装置20还可包括至少一个图形处理单元(gpu)62和/或其他主装置64,这些主装置可经由用于访问存储器54的互连66彼此通信并与cpu通信。
77.支持矩阵处理操作的一种方法可以是将给定矩阵处理操作的各个乘法分解为单独的标量整数或浮点指令,这些指令可在给定cpu 60的处理流水线24上处理。然而,这可能相对较慢。
78.加速矩阵处理的另一种方法可以是,作为连接到互连66的装置64中的一个装置,提供具有专用硬件的硬件加速器,该专用硬件被设计用于处理矩阵操作。为了与这样的硬件加速器交互,cpu 24将使用加载/存储单元48来执行加载/存储指令,以向存储器54(或者向硬件加速器内的存储器映射的寄存器)写入配置数据,该配置数据定义要由硬件加速器从存储器读取的矩阵操作数,并定义要应用于操作数的处理操作。一旦硬件加速器已经执行了矩阵处理,cpu 60就可以使用指定映射到硬件加速器内的寄存器的地址的加载指令从硬件加速器读回矩阵处理的结果。虽然这种方法可能比在流水线内使用整数操作更快,但仍然可能存在与使用加载/存储机制在通用处理器60和硬件加速器64之间传输信息相关联的开销,当在同一处理系统上运行的不同虚拟机需要共享对硬件加速器的访问时,硬件加速器方法也可能会带来挑战。因此,这种方法在具有多个虚拟机的虚拟化具体实施中可能无法很好地缩放。
79.因此,如图1所示,可以在给定cpu 60的常规处理流水线24内提供矩阵处理电路46,该矩阵处理电路可被控制以响应于由流水线的解码级30解码的计算程序指令来执行矩阵处理(类似于使用alu 40或浮点单元42控制常规整数或浮点算术操作)。这避免了在cpu 60和硬件加速器之间来回传输数据的需要,并且使得允许多个不同的虚拟机执行矩阵操作变得更加简单。
80.虽然图1示出了具有若干cpu 60的多处理器装置20,但这不是必需的,矩阵处理电路46也可在单核系统中实现。
81.在图1的示例中,在cpu 60自身内提供矩阵处理功能。
82.图2a至图2d示出了数据处理装置的第二示例,其中每个cpu 60自身不具有矩阵处理功能,但是在经由互连66连接到cpu 60的协处理器70中支持矩阵处理。该方法对于降低实现矩阵处理功能的硬件成本可以是有用的,因为用于在协处理器70中支持矩阵处理的硬件资源可以在cpu 60之间被共享。为了允许协处理器70使用与由cpu 60自身使用的地址转换数据相对应的地址转换数据来访问存储器,可以提供存储器管理单元(mmu)72作为在cpu 60与协处理器70之间共享的不同块(如图2a所示),或者每个cpu 60和协处理器70都具有其自己的mmu 72(如图2b所示),mmu可以从存储器中的公共页表集加载地址转换数据。需注意,尽管为了简明起见而未在图1中示出,但是在该示例中,cpu 60还可以具有内部mmu 72。而且,在一些示例中,用于协处理器加载/存储操作的地址的转换可以由cpu 60中的mmu执行,并且所得物理地址可以与加载/存储指令一起被传递到协处理器70。mmu 72将基于由程序指令指定的存储器寻址信息标识的虚拟地址转换成标识在存储器54中要访问的位置的物理地址。mmu 72还可以实现权限检查以检查是否允许程序代码访问给定存储器地址。
83.图2c示出了图2a/图2b的示例中的cpu 60。用相同附图标号指示与图1中相同的元件。在该示例中,图1中所示的标量执行单元40、42、44统称为标量处理电路,该标量处理电路对存储在标量寄存器80中的标量操作数执行操作。执行级36还包括向量处理电路76,该向量处理电路用于对存储在向量寄存器82中的向量操作数执行向量处理操作。尽管图1中未示出向量处理电路76和向量寄存器82,但是在该示例中也可以提供向量处理电路和向量寄存器。
84.在图2a至图2d的示例中,处理装置支持在非矩阵处理模式中或在矩阵处理模式中对程序的处理。在非矩阵处理模式中处理的指令由cpu 60的发出级32的发出电路85发出,以供执行级36中的处理单元执行。
85.然而,在矩阵处理模式中处理的指令由cpu 60的发出级32的协处理器接口87转发到协处理器70中的队列管理器84(如图2d所示)。队列管理器84将指令传递到协处理器70内的流水线,该流水线类似于cpu 60,包括指令解码电路30、发出电路32、执行级36和回写电路38,然而,与cpu 60相比,协处理器70中的流水线可以支持isa的不同的指令子集。例如,协处理器70可以支持比cpu 60更有限的指令集,以在支持期望对矩阵处理有用的操作的同时,限制协处理器的复杂性。
86.该示例中的cpu 60不支持任何矩阵处理计算指令,而是由协处理器70中的矩阵处理执行单元86支持矩阵处理计算指令。可以基于启用/停用矩阵处理模式的特定模式控制指令来作出程序当前是在矩阵处理模式中还是在非矩阵处理模式中执行的选择。
87.为了支持矩阵处理,协处理器70具有被指定用于存储2d数据阵列(矩阵)的矩阵寄存器(2d阵列寄存器)88。在矩阵寄存器88与存储器54之间或在矩阵寄存器88与其它类型的寄存器(诸如向量寄存器82)之间传输矩阵的部分的数据传输指令限于在矩阵处理模式中执行。尽管图1中未示出,但是在cpu自身支持矩阵处理的实施方案中,cpu 60可以类似地在其寄存器34内具有矩阵寄存器88。
88.协处理器70中的向量寄存器82的向量长度可以与cpu 60中的向量寄存器82的向量长度不相同。由于矩阵处理操作在更大的向量长度可以更有效(以实现更大的数据吞吐量),因此在一些情况下,处理器设计者可能希望针对向量寄存器82(以及用于提供协处理器的矩阵寄存器88的向量寄存器)选择比用于cpu 60中的向量寄存器82的向量长度vl1更长的向量长度vl2。然而,isa可以针对非矩阵处理模式和矩阵处理模式支持可变向量长度vl1、vl2,vl1和vl2两者可以针对给定硬件具体实施从由isa支持的向量长度的范围当中选择(在一些情况下,作为vl1可供选择的范围可以与作为vl2可供选择的范围不同,尽管范围可以重叠,并且因此特定具体实施可以选择vl1=vl2)。可以在cpu 60中提供向量控制寄存器(zcr,zcr')81、81',以分别指示在非矩阵处理模式中和在矩阵处理模式中使用的相应向量长度vl1、vl2。
89.根据isa定义的程序代码可以在两个硬件具体实施(图1在cpu 60内实现的矩阵处理,或者图2a至图2d的协处理器示例)上以等效方式运行。如果在如图1所示的具体实施上执行,则模式选择指令可以被视为无操作指令,并且在两种模式中针对任何向量寄存器实现的向量长度可以相同(因为在两种模式中使用相同的寄存器)。如果在图2a至图2d所示的具体实施上执行,则模式选择指令可以发信号通知指令应被转发到协处理器以供执行,并且在两个模式中支持不同的向量长度vl1、vl2可以是有用的。无论以哪种方式,从软件开发
者的角度来看,矩阵处理由矩阵处理逻辑46、86响应于常规cpu指令(计算/算术指令)而执行,该常规cpu指令定义作用于存储在寄存器中的操作数并且生成写回到寄存器的结果的寄存器到寄存器操作,这使得矩阵处理的控制远比使用基于加载/存储指令控制的硬件处理器来执行矩阵处理的具体实施(其可能需要专门的软件驱动器来实现矩阵处理)更直接。当然,即使在包括cpu 60或具有支持实现矩阵处理的寄存器到寄存器计算指令的isa的协处理器的系统中,仍然可以提供专用硬件加速器作为使用加载/存储指令能够经由互连66访问的设备64,以对在isa的寄存器到寄存器计算指令中不支持的矩阵处理形式提供附加支持。然而,这种硬件加速器不是必需的。
90.图3示出了第一矩阵a与第二矩阵b之间的矩阵乘法以生成结果矩阵c的示例。在该示例中,矩阵是用于特定示例的具有4
×
4维度的全正方矩阵,尽管这不是必要的。对于矩阵乘法运算,c=ab,其中a为m
×
n矩阵并且b为n
×
p矩阵,则c为m
×
p矩阵,其中在c的位置(i,j)处的给定元素对应于将矩阵a的第i行的元素与矩阵b的第j列的元素逐对相乘的乘积相加的结果,使得结果矩阵的给定元素c
ij
对应于
91.如图3右侧所示,可以通过执行一系列外积运算来生成等效结果。外积运算取第一向量操作数u=(u1,u2,
…
,um)和第二向量操作数v=(v1,v2,
…
,vn),每个向量操作数都包括一维元素阵列,并将它们组合以形成二维结果矩阵w,其中因此,外积结果矩阵的每个元素都是从输入向量操作数的一个元素与第二向量操作数的一个元素的单个乘法得出的。如图3所示,如果矩阵a的元素以列为单位读出(而不是如上所述矩阵乘法那样以行为单位读出)并且第二矩阵b的元素以行为单位读出(而不是如矩阵乘法那样以列为单位读出),则通过对矩阵a的第i列和矩阵b的第i行执行外积运算,并且对于i=1至n累加结果,该结果等效于矩阵乘法运算的结果。将矩阵乘法运算拆分成单独的外积运算对于减少响应于单个程序指令需要计算的乘积和加法的数量可以是有用的。这是更快的操作,并且当设计其定时与处理器内的其它操作的流水线定时相匹配的电路逻辑时,可以使在硬件中的设计更简单。在任何情况下,外积自身对于特定算法也是重要的操作,因此可用于除实现矩阵乘法以外的目的。
92.因此,在一些示例中,处理电路的矩阵处理单元46、88(在图1和图2a至图2d的示例中的任一者中)可以包括如图4所示的用于执行外积运算的外积引擎。外积引擎采用与第一谓词值pa相关联的第一向量操作数opa和与第二谓词值pb相关联的第二向量操作数opb作为输入。由外积引擎输出的结果是2d阵列(矩阵)c'。结果矩阵可以存储到被提供用于存储2d阵列的2d阵列寄存器存储装置(例如,图2d所示的矩阵寄存器88,该矩阵寄存器在图1的示例中还将被提供在寄存器34内)。存储在结果阵列存储装置的每个元素c中的先前值也可以用作操作的输入,以便执行外积及累加操作,针对该操作的给定元素c'[i,j]根据图4所示的等式生成,其中pa[i].opa[i]指示opa的元素i由pa的元素i断定,并且pb[j].opb[j]指示opb的元素j由pa的元素j断定。对于实现合并断定的外积指令,当谓词元素pa[i]或pb[j]被指示为非活动时,对应的元素c'[i,j]将保持其先前值。还可以实现归零断定,其中将结果矩阵的与非活动谓词元素pa[i]或pb[j]相对应的元素c'[i,j]设置为0,覆写针对该元素位置的先前值c[i,j]。例如,当矩阵处理到达矩阵结构的边缘并且要处理的元素的数量不
足以填充在硬件中被支持的整个矩阵时,断定可以是有用的。如图4所示的外积及累加运算是有用的,因为它们简化了用于矩阵乘法运算的硬件支持的具体实施,并且累加意味着不必单独地存储每个外积结果,并且随后将它们相加作为最终步骤。然而,图4中所示的外积引擎仅为一个示例,并且在矩阵处理引擎46、88的其它具体实施中,将可以对在一个指令中执行完整矩阵处理操作提供支持。然而,如上所讨论,外积运算在实践中可以更容易实现。
[0093]
图5示出了用于支持矩阵操作的cpu 60或协处理器的架构寄存器34的示例。架构寄存器(如isa中所定义)可以包括一组标量整数寄存器,该组标量整数寄存器充当用于由alu 40执行的alu操作或在流水线中处理的其它指令的通用寄存器。例如,可以提供特定数量的通用寄存器,例如在该示例中的31个寄存器x0至x30(标量寄存器字段的第32个编码不可以对应于在硬件中提供的寄存器,因为例如该编码可以被默认地认为指示零值,或者可以用于指示不是通用寄存器的专用类型的寄存器)。可以访问映射到相同物理存储装置的不同大小的标量寄存器。例如,寄存器标记x0至x30可以指64位寄存器,但相同寄存器也可以作为32位寄存器来访问(例如,使用在硬件中提供的每个64位寄存器的较低32位来访问),在这种情况下,可以在汇编程序代码中使用寄存器标记w0至w30以引用相同寄存器。
[0094]
此外,可供被由解码器30支持的isa中的程序指令选择的架构寄存器可以包括特定数量的向量寄存器82(在该示例中标记为z0至z31)。当然,提供图5所示的数量的标量/向量寄存器不是必需的,并且其它示例可以提供可以由程序指令指定的不同数量的寄存器。每个向量寄存器可以存储包括可变数量的数据元素的向量操作数,其中每个数据元素可以表示独立的数据值。响应于向量处理(simd)指令,处理电路可以对存储在寄存器中的向量操作数执行向量处理以生成结果。例如,向量处理可以包括逐通道操作,其中对一个或多个操作数向量中的元素中的每个通道执行对应操作以生成针对结果向量的元素的对应结果。当执行向量处理或simd处理时,每个向量寄存器可以具有特定向量长度vl,其中向量长度是指在给定向量寄存器中的位数(例如,针对向量指令的向量长度vl可以为参照图2a至图2d的先前提到的第一向量长度vl1)。在向量处理模式中使用的向量长度vl对于给定硬件具体实施可以是固定的或者可以是可变的。由cpu 60支持的isa可以支持可变向量长度,使得不同处理器具体实施可以选择实现不同大小的向量寄存器,但是isa可以是向量长度无关的,使得指令被设计成使得代码可以正确地运行,而与在执行该程序的给定cpu上实现的特定向量长度无关。例如,可存在控制寄存器(例如,zcr 81),该控制寄存器存储指示用于向量处理指令的特定向量长度vl的值。该寄存器可以由软件读取以控制循环,该循环通过处理特定数量的元素而迭代,使得具有较长向量长度的具体实施可以比具有较短向量长度的具体实施以更少的循环的迭代处理给定数量的元素。
[0095]
向量寄存器z0至z31还可以充当用于存储向量操作数的操作数寄存器,该操作数寄存器向由外积引擎48、86执行的外积运算(如上参照图4所讨论)提供输入。当向量寄存器用于向外积运算或其它矩阵操作提供输入时,则向量寄存器具有矩阵向量长度mvl,其可以与用于向量操作的向量长度vl相同,或者可以是不同的向量长度(例如,vl2而不是vl1,如上针对在使用协处理器70的实施方案中的模态功能所讨论)。通过在isa级提供架构支持以支持用于simd操作和矩阵操作的不同向量长度,这可以为处理器微设计师提供更多的灵活性以选择不同的物理具体实施,包括使用如上所讨论的协处理器70来实现矩阵操作的选项。isa可以支持模式选择指令,该模式选择指令可以选择处理器是在矩阵处理模式中操作
还是在非矩阵处理模式中操作,并且这对于配置cpu以将处理卸载到协处理器(如果实现的话)可以是有用的。在这种情况下,除了其它功能之外,模式选择指令还可以触发所实现的当前向量长度的切换,根据当前模式来选择vl和mvl中的一者。可以提供向量控制寄存器81、81'以指示用作针对相应模式的vl和mvl的特定向量长度。
[0096]
因此,一般来讲,针对后续示例所讨论的向量长度mvl是在矩阵处理模式中使用的向量长度,该向量长度可以或可以不与在其它模式中使用的向量长度vl相同。控制寄存器可以存储指示矩阵向量长度mvl对于当前处理器具体实施是多少的值,可以使该值对软件可用以便控制程序循环。
[0097]
如图5所示,架构寄存器还包括特定数量na个阵列寄存器88,za0至za(n
a-1)。每个阵列寄存器可以被视为用于存储单个2d数据阵列(例如,如上所讨论的外积运算的结果)的一组寄存器存储装置。然而,外积运算可不是可以使用阵列寄存器的唯一运算。阵列寄存器还可以用于在存储器中执行矩阵结构的行/列方向的转置时存储阵列。当程序指令引用阵列寄存器88中的一个阵列寄存器时,使用阵列标识zai将其作为单个实体来引用,但是一些类型的指令(例如,数据传输指令)也可以通过定义选择阵列的一部分(例如,一个水平/垂直元素组)的索引值来选择该阵列的子部分。
[0098]
图5示出了由软件看到的阵列寄存器的架构视图。然而,如图6所示,在实践中,与阵列寄存器相对应的寄存器存储装置的物理具体实施可以包括特定数量nr个向量寄存器,zar0至zar(n
r-1)。形成阵列寄存器存储装置88的向量寄存器zar可以是与用于simd处理向量寄存器z0至z31以及到矩阵处理的向量输入不同的寄存器组。向量寄存器zar中的每个向量寄存器可以具有矩阵向量长度mvl,因此每个向量寄存器zar可以存储具有长度mvl的1d向量,该向量可以被逻辑地划分为可变的数据元素数量。例如,如果mvl为512位,则这可以是例如一组64个8位元素、32个16位元素、16个32位元素、8个64位元素或4个128位元素。应当理解,并非所有这些选项都需要在给定具体实施中得到支持。通过支持可变元素大小,这对处理涉及不同精度的数据结构的计算提供了灵活性。为了表示2d数据阵列,向量寄存器组zar0至zar(n
r-1)可以被逻辑地认为是被分配阵列寄存器标识za0至za(n
a-1)中的给定阵列寄存器标识的单个实体,使得2d阵列由在与阵列的一个维度相对应的单个向量寄存器内延伸的元素以及在阵列的另一个维度中跨多个向量寄存器条带化布置的元素形成。
[0099]
实现矩阵处理电路46、86以使得阵列寄存器za存储数据的正方阵列可以是有用的,尽管这不是必需的,其中在水平方向的元素数量等于在垂直方向的元素数量。通过对在水平方向或在垂直方向读取/写入阵列寄存器88提供支持,这可以帮助支持矩阵的即时转置,其中当在阵列寄存器88与存储器54之间传输矩阵时,可以切换存储器中的矩阵结构的行/列维度。机器学习算法和处理矩阵数据的其它应用通常以如上所讨论的以行为主的格式或以列为主的格式来表示存储在存储器中的数据,并且一些算法可能需要以混合格式来处理数据。在先前技术中,如果一些处理要求输入数据以与其在存储器中的布局不同的格式表示,则这可能要求在可以在矩阵处理操作中处理数据之前使用多个加载/存储指令或向量重组指令来对存储在存储器中的数据进行某种重新布置,以确保格式的一致性。这些操作可能很慢。通过对在水平方向或在垂直方向对2d阵列寄存器写入/读取数据提供支持,这可以允许在一个方向(例如,逐行)从存储器加载的数据在相反的方向(例如,逐列)写回到存储器,可以比用多个聚集/分散加载/存储或重组操作在存储器与向量寄存器之间传输
数据更快。
[0100]
因此,当将阵列寄存器za 88实现为一组向量寄存器zar,每个向量寄存器存储对应2d阵列的一个水平/垂直元素组时,为了确保满足正方矩阵约束,可能期望阵列跨越多个向量寄存器,其数量等于装在一个向量寄存器内的数据元素的数量。当如上所讨论支持可变数据元素大小时,可以装在一个向量寄存器内的数据元素的数量是可变的,并且因此被分组在一起以形成单个阵列寄存器za的向量寄存器的数量也可以是可变的。
[0101]
一种方法可以是每个阵列寄存器za(可以通过在指令内指定阵列寄存器id作为架构寄存器来访问)可以对应于特定向量寄存器数量,该数量对应于可以以所支持的最小数据元素大小装在一个向量寄存器内的数据元素的最大数量。然而,在将阵列寄存器固定映射到物理向量寄存器存储装置上的这种情况下,则当数据元素大小较大并且较少数据元素装在一个向量寄存器内时,随着阵列维度收缩,映射到特定阵列寄存器标识的固定向量寄存器组中的一些向量寄存器实际上将被浪费。
[0102]
因此,更有效的具体实施可以是阵列寄存器的数量na能够根据数据元素大小e而变化,使得用于实现阵列寄存器za的物理寄存器存储装置zar0至zar(nr-1)可以根据数据元素大小e而被逻辑地划分为不同大小的组,以便充分利用可用物理存储装置,而与数据元素大小无关。这意味着由给定阵列寄存器标识za0至za(n
a-1)引用的实际物理存储区域并不总是相同的,而是根据用于给定操作的当前数据元素大小e而变化。
[0103]
图7至图11示出了可以使用针对阵列寄存器za0至za(n
a-1)的架构寄存器指定符来划分和引用物理存储装置的不同方式。在图7至图11的示例中,假设矩阵向量长度mvl为512位,但是应当理解,其它具体实施可以使用不同的矩阵向量长度,并且在这种情况下,所支持的阵列寄存器za的特定数量或者映射到给定阵列寄存器的向量寄存器zar的特定分组可以改变。另外,该示例假设提供用于阵列(矩阵)寄存器88的向量寄存器zar的总数为64,但这在isa的其它具体实施中也可以改变。
[0104]
图7示出了在当前数据元素大小e为32位时对阵列寄存器存储装置的划分。在这种情况下,在512位向量寄存器的情况下,可以在单个向量寄存器内装16个元素,每个元素的大小为32位。因此,为了表示正方2d阵列,可以将16个向量寄存器分组在一起以表示由阵列寄存器标识za0至za(n
a-1)的给定值标识的单个16
×
16 2d阵列。例如,对于阵列寄存器id za0,该阵列寄存器映射到向量寄存器zar0至zar15,这些向量寄存器可以分别存储阵列za0的第0个至第15个水平元素组,并且第i个垂直元素组跨向量寄存器zar0至zar15中的每一者内的位置i处的元素集条带化布置(另选地,其它具体实施可以将垂直元素组布置于单个向量寄存器zar内并且跨多个向量寄存器zar的对应元素位置条带化布置水平元素组)。
[0105]
由于16个向量寄存器zr足以表示32位元素的16
×
16块,并且总共有64个向量寄存器,这意味着4个单独的16
×
16阵列可以存储在可用的64个向量寄存器中,因此对于32位元素大小,所支持的阵列寄存器的数量na为4。即,将物理存储装置分成4组的16个向量寄存器,用阵列标识za0至za3标记,这些标识可以由在阵列存储寄存器与存储器之间传输数据的数据传输指令来识别。
[0106]
如图7左侧所示,由于可以同时地在阵列寄存器88中存储四个单独的2d阵列za0至za3,因此这允许分摊一些与处理给定的矩阵数据量相关联的加载/存储开销。例如,可以从四个向量操作数的不同组合生成四个不同的输出块za0至za3(例如,如图7所示,基于opa0、
opb0的外积的za0,基于opa0、opb1的外积的za1,基于opa1、opb0的外积的za2,以及基于opa1、opb1的外积的za3)。这可以是有用的,因为矩阵处理算法可能够将相同输入向量与许多其它输入向量组合地重新使用,因此使得能够从存储在向量寄存器(z0至z31中的一者)中的输入向量的相同实例计算出多个外积结果,以在较大数量的计算操作当中共享与加载向量相关联的加载开销,从而增大每次加载实现的乘法的有效数量,与针对所生成的每个单个结果块za单独加载一对输入操作数opa、opb相比,这可以帮助提高性能。
[0107]
图8示出了在当前数据元素大小e为16位时物理寄存器存储装置的另选划分,这意味着32个元素装在一个512位向量寄存器(对于该示例为mvl大小)内,并且因此32个向量寄存器的两个组zar0至zar31和zar32至zar63被映射到阵列标识za0、za1,每个阵列标识表示16位元素的32
×
32块。通过该方法,则阵列存储装置可以支持基于向量寄存器中的单组所加载的向量操作数opa、opb0、opb1来执行两个单独的外积运算,以分别基于opa和opb0的外积与opa和opb1的外积来生成两个32
×
32块za0、za1。因此,与图7相比,单个块内的元素数量更大(32
×
32而不是16
×
16),但是可以针对给定的一组负载处理更少的块。
[0108]
图9示出了另一种配置,其中数据元素大小为8位,并且因此64个元素装在一个向量寄存器内,意味着所有64个向量寄存器zar0至zar63被分组在一起以形成单个2d阵列za0。图9示出了对向量opa、opb执行单个外积运算以生成8位元素的64
×
64阵列za0。然而,在一些具体实施中,8位元素结果可能不被支持用于计算操作,而是可能限于用于阵列加载/存储数据传输或寄存器移动数据传输指令,这些指令在阵列寄存器与存储器或向量寄存器之间传输数据,用于相对于存储器中的数据结构来转置行/列方向时使用。
[0109]
相似地,图10和图11分别示出了针对64位和128位的数据元素大小的阵列存储装置的划分。
[0110]
应当理解,可以针对阵列存储装置88中提供的其它矩阵向量长度mvl或其它数量nr个向量寄存器执行类似划分。
[0111]
控制处理电路执行外积运算的外积指令可以指定向量寄存器标识,其标识哪些向量寄存器z0至z31存储用于外积运算的两个向量操作数,并且可以指定目标阵列寄存器标识za0至za(n
a-1),其标识要用外积运算的结果来更新的块。处理器的矩阵处理硬件48、86可以基于当前数据元素大小e和所指定的阵列寄存器标识zai来确定哪些物理向量寄存器zar要基于外积结果来更新,这取决于上文所讨论的变量映射。
[0112]
isa还可以定义用于向或从所选择的阵列寄存器zai传输2d阵列的一部分的阵列数据传输指令。为了简化硬件电路逻辑的具体实施并且减少针对任何单个指令需要传输的数据量,针对给定数据传输指令,作用于所选择的阵列寄存器zai内的单个水平/垂直元素组可以比在一个指令中传输整个2d阵列更简单。这也帮助支持先前所讨论的即时转置功能,因为指令可以根据数据传输指令的参数来选择是在水平方向上还是在垂直方向上读取/写入。因此,除了所选择的阵列寄存器之外,数据传输指令还可以识别索引,该索引识别要传输哪个水平/垂直元素组。
[0113]
图12示出了阵列数据传输指令的示例性编码。在该示例中,指令是用于将数据从2d阵列寄存器存储装置za 88传输到存储器54的存储指令。还可以提供阵列数据传输指令,该指令是用于将数据从存储器54加载到阵列寄存器存储装置88的加载指令,该加载指令以与图12中所示的针对存储指令相同的方式指定其存储器寻址信息和寄存器寻址信息。
[0114]
图12的上部示出了阵列数据传输指令在以汇编代码编写时的示例性语法,而图12的下部示出了具有被分配用于表示汇编表示中指定的不同参数的各种位字段的指令的二进制编码。
[0115]
如图12的上部所示,数据传输指令指定多个参数,包括:
[0116]
●
寄存器寻址信息(操作数),其用于识别阵列寄存器存储装置88中的要用于数据传输的部分,
[0117]
●
存储器寻址信息(操作数),其用于识别存储器中的要从其加载数据或要向其存储数据的目标区域。
[0118]
●
谓词操作数,其提供谓词值以用于控制数据传输,使得可以针对与由谓词指示的非活动元素相对应的元素位置禁用阵列的一些数据元素以防止更新存储器(在存储指令的情况下)或更新寄存器存储装置(在加载指令的情况下)。存在分别与阵列中的水平和垂直元素组相对应的两个谓词值ph、pv。
[0119]
存储器寻址操作数可以根据任何已知寻址方案来识别存储器中要更新的地址。例如,存储器寻址操作数可以包括用于得出加载/存储操作的地址以及零个、一个或多个立即值的标量寄存器的一个或多个寄存器标识。例如,第一标量寄存器可以提供基址地址。偏移值可以由存储在第二标量寄存器中的值表示,或者由直接编码在指令编码中的立即值表示,其中偏移要与基址寄存器中的值相加以生成用于数据传输的地址。在一些情况下,存储器寻址操作数还可以包括用于指定关于寻址模式的其它信息的其它操作数,例如指示是在计算当前加载/存储指令的地址之前还是在计算该地址之后递增基址寄存器中的值的操作数。操作数还可以包括指定移位量的参数,该移位量要在由第二寄存器或立即值表示的偏移与基址寄存器值相加之前应用于该偏移。一般来讲,多种存储器寻址模式在本领域中是已知的,其中可以使用任何此类已知寻址模式来定义阵列数据传输指令的存储器寻址操作数。
[0120]
对于存储指令,阵列数据传输指令的寄存器寻址操作数用于识别阵列寄存器存储装置88的哪个部分应传输到存储器(对于加载指令,寄存器寻址操作数将识别阵列寄存器存储装置88的哪个部分要用所加载的数据更新)。寄存器寻址操作数包括阵列标识(id)zai(或在由软件使用的汇编表示中的“zai”),其中i表示针对当前加载/存储指令选择的特定架构阵列寄存器za0至za(na-1)的编号。寄存器寻址操作数还包括方向标识d,该标识指示所识别的阵列寄存器zai应在水平方向上还是在垂直方向上进行访问。寄存器寻址操作数还包括可以如前所讨论从多个不同的元素大小中选择的元素大小e的指示,该元素大小e是用于当前操作的当前元素大小。而且,寄存器寻址操作数包括用于生成行/列索引j的基址寄存器wx和立即值#y,该索引指示所选择的阵列寄存器zai内要向其传输数据的水平/垂直元素组的位置。基址寄存器标识wx标识提供基址值的标量寄存器,该基址值要与由直接在数据传输指令的指令编码内编码的立即值#y表示的偏移相加以生成索引j。在该示例中,为了确保索引j在针对给定向量长度mvl和元素大小e支持的元素位置范围内,将索引值j设置为(wx中的值+#y)modulo(mvl/e)。取模操作是指确定当(wx中的值+#y)除以(mvl/e)时的余数,尽管在实践中由于mvl和e都是2的幂,取模操作可以简单地通过返回和的低阶位来实现,因为如果dim=mvl/e,则j是(wx中的值+#y)的最低有效log2(dim)位。通过使用基址寄存器和立即值的组合来表示行/列索引,这对于支持可以缩放为矩阵结构的不同维度并且
支持如下文将进一步讨论的循环展开的软件代码是有用的。
[0121]
在该示例中,以相同方式表示索引值j,与阵列寄存器zai的所选择的访问方向是水平方向还是垂直方向无关。方向标识d选择读取/写入与所选择的阵列寄存器zai相对应的向量寄存器组zar中的哪些特定元素。例如,如果方向标识选择水平方向,则从与zai相对应的组中的第j个向量寄存器zar读取所传输的元素(或者对于加载指令,向该向量寄存器写入所传输的元素),并且如果方向标识选择垂直方向,则从与zai相对应的组中的向量寄存器zar中的每个向量寄存器中的第j个元素读取所传输的元素(或者对于加载指令,向该第j个元素写入所传输的元素)(或者如果水平/垂直方向相对于向量寄存器zar中的布局转置,反之亦然)。
[0122]
如图12的下部所示,指令的二进制编码可以包括识别该指令是阵列加载/存储数据传输指令的操作码,以及如前所述与在指令的汇编表示中指定的各种参数相对应的多个字段。例如,可以分配指令编码的字段来表示方向标识d、当前数据元素大小e、识别用于生成寄存器寻址操作数的行/列索引的基址寄存器的基址寄存器标识wx、用于提供水平和垂直谓词值的谓词寄存器ph和pv,以及各种存储器寻址操作数。
[0123]
在该示例中,用于识别寄存器寻址操作数的基址寄存器的标量寄存器字段wx具有特定位数l,该特定位数l小于用于由解码器30和处理器支持的至少一个其它指令中的标量寄存器字段的位数k(例如,整数alu指令可针对其源/目标寄存器指定k位寄存器字段)。例如,在图5的示例中,k=5。然而,为了减小阵列加载/存储数据传输指令中的基址寄存器字段的大小,如图12所示,wx字段可以具有l位(l《k),使得存在不允许被指定为用于生成用于阵列数据传输指令的行/列索引的基址寄存器的一些标量寄存器。例如,如果l=2,则数据传输指令可以被限制为从4个标量寄存器(例如,w12至w15)的有限子集进行选择。这认识到指令已经具有大量要指定的参数,并且对于在控制矩阵处理循环时的期望用例,仅定义几个不同基址寄存器用于单个程序循环内的寄存器寻址可以是足够的,因此通过限制用于识别用于生成索引j的基址寄存器的标量寄存器字段的大小,这使得指令编码更高效并且释放用于表示其它参数的其它位空间。当然,这不是必需的,并且其它具体实施可以提供标量寄存器字段wx,该字段支持任何标量寄存器被识别为用于寄存器寻址操作数的基址寄存器。
[0124]
虽然图12示出了使用特定位字段在指令的编码内直接编码当前数据元素大小e的示例,但是另一个选项可以是当前数据元素大小可以存储在控制寄存器中,该控制寄存器可以由较早指令设置并且在处理阵列数据传输指令时被引用以识别当前数据元素大小,使得可以不必在指令编码自身内表示当前数据元素大小e。
[0125]
在该示例中,用于生成寄存器寻址信息的行/列索引的阵列id i和立即值#y由数据传输指令的指令编码内的组合字段表示。这在图13中更详细地示出。这种组合编码利用了以下事实:对于可变数据元素大小e,随着数据元素大小增大,可以装在可用物理阵列存储装置内的不同2d阵列的数量增大,而单个阵列的维度减小。因此,阵列id和立即值都取决于数据元素大小,但是具有相反缩放关系,并且这意味着可以高效地在组合字段中表示这两个参数,其中组合字段的恒定位数针对一些数据元素大小可变地映射为阵列id的一部分并且针对其它数据元素大小可变地映射为立即值的一部分。
[0126]
此外,应当认识到,为了支持可以在可能已经针对矩阵向量长度mvl实现了不同大
小的一系列处理器具体实施上正确操作的向量长度无关代码,期望针对寄存器寻址操作数指定的特定立即值应由代码设置为相同值,与所实现的特定矩阵向量长度mvl无关。在实践中,这意味着在以所支持的最小矩阵向量长度mvl
min
操作的处理器具体实施中,针对#y提供用于支持多种编码的编码空间是没有优势的,该#y大于可以装在单个向量寄存器zar内的数据元素的最大数量。这是因为,即使在具有比最小向量长度更大的向量长度的具体实施中,可以每个向量寄存器引用更大数量的元素,代码也不能以立即值#y直接引用那些附加数据元素,因为否则代码将不再是向量长度无关的,因为它将不能在实现最小向量长度mvl
min
的具体实施上正确地运行。这意味着可以选择组合阵列id/立即值字段的大小,使得针对立即值#y支持的不同值的数量小于或等于mvl
min
/e(换句话讲,对于n位立即值,2n≤mvl
min
/e)。例如,如果由isa支持的最小向量长度mvl
min
为128位,则在当前数据元素大小e为8时,4位将足以表示立即值,因为128/8=16,其可以用4位表示(即,0至15)。
[0127]
因此,如图13的示例所示,数据传输指令的4位组合字段可以表示用于生成水平/垂直索引j的阵列id i(定义访问哪个阵列寄存器zai)和立即值#y两者。在所支持的最小数据元素大小(例如,8位)处,可以将组合字段的所有4位分配来表示立即值#y的位,因为在该元素大小处,则根本不需要指定阵列id,因为如图9所示,与阵列寄存器相对应的整个物理寄存器存储装置zar0至zar63被映射到单个2d阵列za0。在这种情况下,尽管在水平/垂直方向上存在64个不同的元素位置,但立即值#y仅在范围0至15中缩放以支持其中mvl=mvl
min
=128位的具体实施,其中仅16个8位元素可以装在单个向量寄存器中。访问在范围16至63中的元素位置将要求软件代码将寄存器wx中的基址值指定为除0以外的值。
[0128]
另一方面,在较大数据元素大小处,立即值需要较少的位,因为可以装在所支持的最小向量长度的向量寄存器内的该大小的数据元素的数量减小,但接着在这些示例中,分配组合字段的附加位以用于表示阵列id i。
[0129]
图14示出了可利用上文所讨论的阵列数据传输指令的程序代码的示例。图14的左侧示出了由程序员以高级编程语言编写的高级程序代码,以将两个矩阵a[n
×
k]和b[k
×
m]相乘,从而给出结果c[n
×
m]。程序员可以编写程序循环,该程序循环旨在步进通过存储在存储器中的两个矩阵结构的相应行/列,加载用于处理的行/列,并且对与矩阵中的一个矩阵的行和另一个矩阵的列相对应的向量对执行多个外积运算,并且将累积多个外积结果的所生成的结果写回到存储器。
[0130]
例如,在图14中,高级代码示出了循环,其中在每次迭代中,矩阵a的两列和矩阵b的两行被加载作为外积运算的输入向量。对列和行的相应对执行四个外积运算(类似于图7所示的示例)以生成四个单独的2d输出数据阵列。加载/计算循环在存储器中的矩阵结构的不同行/列位置上迭代,使得za0至za3累加将来自矩阵a的块与来自矩阵b的块相乘的结果。后续存储循环将结果块za0至za3的相应行/列存储回到存储器中的结果矩阵结构c。外循环在加载/计算循环和存储循环两者上迭代,以在矩阵a和b的块的其它组合上迭代。
[0131]
图14的右侧示出了图14的左侧的高级代码的经编译的汇编表示。在内部循环(加载/计算循环)内,存在一些向量加载指令,其用存储器中的矩阵a/b的相应列或行来加载向量寄存器z4至z7,并且存在外积指令fmopa,其从向量寄存器z4至z7中的向量操作数的相应对生成写入阵列寄存器za0至za3的外积结果。在该示例中,元素大小为32位,并且因此存在可以在内循环的单次迭代内生成的4个块(给出了图7的示例)。在该示例中,通过在各种加
载/存储指令和外积指令的汇编表示内具有元素大小标识.s来表示e=32位的数据元素大小。外积指令是外积及累加指令,因此例如指令“fmopa za0.s
…”
将阵列寄存器za0的每个元素的先前内容与在对向量寄存器z4和向量寄存器z6中的向量操作数执行的外积运算中生成的元素相加。
[0132]
在图14中的在汇编代码的底部的循环包括阵列存储数据传输指令“st1w”,这些指令用于将所生成的2d阵列从阵列寄存器za0至za3传输到存储器。这些指令具有参照图12所讨论的编码。在该示例中,方向标识d指定水平方向(如汇编表示中的zaih.s所指),因此图14的示例所示的基址寄存器w12和立即值#0用于生成索引值j,该索引值识别阵列寄存器zai(za0至za3中的一者)中要响应于对应存储指令而传输到存储器的所选择的特定水平元素组。构造循环,该循环用针对循环的每次迭代递增的基址寄存器w12中的值进行迭代,使得存储指令步进通过所生成的2d阵列的每个水平元素组,直到所生成的阵列za0至za3中的每一者的所有元素已经存储到存储器。在存储循环的底部的“add”指令递增分别用于存储器寻址信息和寄存器寻址信息的基址寄存器x17、w12,并且比较指令“cmp”比较w12中的值(在该示例中w12还充当循环计数器)以使得分支指令“blt”能够确定是否终止循环。
[0133]
图14示出了当在代码的下部生成存储循环时编译器尚未使用循环展开的汇编代码的示例。在此示例中,用于四个存储指令中的每个存储指令的立即值为#0,使得用于从给定2d阵列za0至za3选择要存储的特定行/列的索引值简单地由存储在基址寄存器w12中的值标识。
[0134]
然而,在代码的此类具体实施的情况中,在用于递增w12的“add”指令以及用于确定是否终止循环的比较指令“cmp”和分支指令“blt”中,在存储循环中的每次循环迭代中存在一定量的开销。可以通过执行循环展开来减少与这些循环控制指令相关联的开销,其中将循环的多次迭代展开为包括了将与原始循环中的多次迭代相对应的显式指令的较大循环的单次迭代。例如,图14所示的存储循环可以用如下代码替换:
[0135]
mov w12,#0
[0136]
1:st1w{za0h.s[w12,#0]},p0,p4,[x17,xzr,lsl#2]
[0137]
st1w{za1h.s[w12,#0]},p0,p5,[x17,x2,lsl#2]
[0138]
st1w{za2h.s[w12,#0]},p1,p4,[x17,x3,lsl#2]
[0139]
st1w{za3h.s[w12,#0]},p1,p5,[x17.x4,lsl#2]
[0140]
st1w{za0h.s[w12,#1]},p0,p4,[x18,xzr,lsl#2]
[0141]
st1w{za1h.s[w12,#1]},p0,p5,[x18,x2,lsl#2]
[0142]
st1w{za2h.s[w12,#1]},p1,p4,[x18,x3,lsl#2]
[0143]
st1w{za3h.s[w12,#1]},p1,p5,[x18.x4,lsl#2]
[0144]
st1w{za0h.s[w12,#2]},p0,p4,[x19,xzr,lsl#2]
[0145]
st1w{za1h.s[w12,#2]},p0,p5,[x19,x2,lsl#2]
[0146]
st1w{za2h.s[w12,#2]},p1,p4,[x19,x3,lsl#2]
[0147]
st1w{za3h.s[w12,#2]},p1,p5,[x19.x4,lsl#2]
[0148]
st1w{za0h.s[w12,#3]},p0,p4,[x20,xzr,lsl#2]
[0149]
st1w{za1h.s[w12,#3]},p0,p5,[x20,x2,lsl#2]
[0150]
st1w{za2h.s[w12,#3]},p1,p4,[x20,x3,lsl#2]
[0151]
st1w{za3h.s[w12,#3]},p1,p5,[x20.x4,lsl#2]
[0152]
add x17,x17,x2,lsl#3//x17+=2*dim
[0153]
add x18,x18,x2,lsl#3//x18+=2*dim
[0154]
add x19,x19,x2,lsl#3//x19+=2*dim
[0155]
add x20,x20,x2,lsl#3//x20+=2*dim
[0156]
add w12,w12,#4
[0157]
cmp w12,dim
[0158]
blt 1b
[0159]
[
…
]
[0160]
mstop
[0161]
在该示例中,可以将原始循环的四个单独迭代展开为新循环的单次迭代,这减少了执行用于递增w12的“add”指令以及比较指令和分支指令的次数。如果用于生成存储器地址的存储器寻址信息使用基址+立即值寻址模式(其中将指示元素大小的倍数的附加立即值偏移与基址值相加)来生成目标存储器地址,则可以实现进一步性能改进,如在这种情况下,不同存储指令可以基于单个寄存器x17针对展开循环迭代以不同地址为目标,以进一步消除用于在每次循环迭代上递增寄存器x18至x20的3个加法指令。
[0162]
应当理解,以上代码仅为一个示例,但其帮助说明为什么使用寄存器寻址信息中的基址寄存器和立即值来表示水平/垂直位置索引j可用于支持由编译器进行的循环展开,以及支持可以与数据结构的不同维度一起操作的可缩放代码(见图14所示的可变dim,其表示每次迭代要计算的za矩阵块的维度)。
[0163]
图12的示例示出了作为加载/存储指令的阵列数据传输指令,其中数据在阵列寄存器存储装置88的目标部分与存储器54之间传输。
[0164]
图15中示出了使用寄存器寻址信息来访问阵列寄存器88的数据传输指令的另一个示例。图15示出了用于在阵列寄存器88与向量寄存器82之间传输数据的寄存器移动指令。操作码具有与图12的加载/存储阵列数据传输指令的操作码不同的值。寄存器移动指令的寄存器寻址信息以与图12的示例中相同的方式进行编码。然而,代替提供标识存储器的目标区域的存储器寻址信息,寄存器移动指令指定向量寄存器标识zk,该向量寄存器标识指定被选择的向量寄存器82。可以提供寄存器移动指令的不同变体(由不同操作码表示)。例如,可存在向量到阵列寄存器移动变体,其控制处理电路将元素向量从向量寄存器zk传输到所选择的阵列寄存器zai的水平/垂直元素组j,以与如上针对图12的示例所讨论相同的方式基于阵列寄存器寻址信息来识别,该阵列寄存器寻址信息包括方向标识d、阵列寄存器id i、元素大小e、基址寄存器wx和立即值#y。相似地,可存在阵列到向量寄存器移动变体,其控制处理电路将数据从所选择的阵列寄存器zai的水平/垂直元素组j移动到向量寄存器zk。两种形式的指令都可以用于支持特定矩阵处理算法,其中有时可需要在对矩阵作为整体执行2d操作之前或之后对矩阵的单个行/列内的元素执行一些操纵。寄存器移动指令可以支持向/从向量寄存器传输元素以使得能够执行此类单个行/列操纵。
[0165]
图16示出了示出数据传输指令(诸如上文所述的阵列数据传输指令)的处理的流程图。在步骤s200处,由指令解码器30解码等待进行处理的下一个指令,并且在步骤s202处,指令解码器30标识被解码的指令的类型。如果指令不是阵列数据传输指令,则在步骤
s204处,由处理电路在指令解码器30的控制下执行由指令表示的操作,并且方法返回到步骤s200以对下一个指令进行解码。
[0166]
如果由指令解码器30解码的指令被识别为阵列数据传输指令,则在步骤s206处,指令解码器30和/或cpu 60的执行级36或协处理器70识别寄存器存储装置的要用于数据传输操作的目标部分,其中基于数据传输指令的寄存器寻址信息来识别寄存器存储装置的目标部分。寄存器寻址信息包括基址寄存器标识和立即值。处理电路基于由立即值表示的值与由基址寄存器标识识别的基址寄存器中保存的值的加法来生成索引值j。索引值j用于选择寄存器存储装置的要进行数据传输的目标部分。
[0167]
在步骤s208处,处理电路(在指令解码器的控制下)标识被解码的阵列数据传输指令的类型。虽然为了简明起见,步骤s208在步骤s206之后被示出,但是在其它示例中,步骤s208也可以在步骤s206之前执行,其中步骤s206在这种情况下出现在步骤s208之后的处理的两个供选择的分支上。
[0168]
如果数据传输指令是类似于图12的示例的加载/存储指令,则在步骤s210处,处理电路基于由指令指定的存储器寻址信息来确定在数据传输中要使用的存储器目标部分。这可以根据任何已知的寻址模式来完成,并且可以基于由指令标识的寄存器或者由指令编码标识的立即值。
[0169]
在步骤s212处,然后处理电路由指令解码器30控制以执行数据传输操作以在寄存器存储装置的目标部分与存储器目标部分之间传输数据。如果指令是加载指令,则数据传输操作包括从存储器目标部分加载数据并将数据存储在寄存器存储装置的目标部分中。如果指令是存储指令,则数据传输包括将数据从寄存器存储装置的目标部分存储到存储器目标部分。然后该方法返回到步骤s200以对下一个指令进行解码。
[0170]
如果在步骤s208处确定阵列数据传输指令为寄存器移动指令(类似于图15),则在步骤s214处基于另外寄存器寻址信息(例如,基于指令编码中的寄存器字段zk,该字段标识哪个寄存器是寄存器存储装置的另外部分)来识别寄存器存储装置的另外部分。在步骤s216处,执行数据传输操作以在寄存器存储装置的基于基址寄存器wx和立即值#y来识别的目标部分与寄存器存储装置的另外部分之间传输数据(根据所执行的特定指令类型在任一方向上传输)。同样,该方法返回到步骤s200以对下一个指令进行解码。
[0171]
图12和图15的示例示出了包括寄存器寻址信息的阵列数据传输指令,该寄存器寻址信息使用基址寄存器和立即值来表示用于选择阵列寄存器存储装置88的在数据传输中要使用的目标部分的索引值。然而,寄存器寻址信息的此类编码也可以用于其它类型的指令,该其它类型的指令访问除用于存储2d数据阵列的阵列寄存器88以外的类型的寄存器。更一般地,以这种方式,寄存器寻址信息的编码对于旨在处理可具有可变维度的数据部分的指令同时支持循环展开可以是有用的。
[0172]
图17示出了可以使用的模拟器具体实施。虽然先前所述的实施方案在用于操作支持所涉及的技术的特定处理硬件的装置和方法方面实现了本发明,但也可以提供根据本文所述的实施方案的指令执行环境,该指令执行环境是通过使用计算机程序来实现的。此类计算机程序通常被称为模拟器,在一定程度上是因为此类计算机程序提供硬件架构的基于软件的具体实施。模拟器计算机程序的种类包括仿真器、虚拟机、模型和二进制转换器,其包括动态二进制转换器。通常,模拟器具体实施可以在支持模拟器程序310的主机处理器
330上运行,该主机处理器任选地运行主机操作系统320。在一些布置中,在硬件和所提供的指令执行环境和/或在同一主机处理器上提供的多个不同指令执行环境之间可存在多个模拟层。在历史上,需要强大的处理器来提供以合理速度执行的模拟器具体实施,但这种方法在某些情况下可能是合理的,诸如当出于兼容性或重复使用原因而希望运行另一个处理器本地的代码时。例如,模拟器具体实施可向指令执行环境提供主机处理器硬件不支持的附加功能,或者提供通常与不同硬件架构相关联的指令执行环境。模拟概述在以下文献中给出:“some efficient architecture simulation techniques”,robert bedichek,winter 1990usenix conference,第53-63页。
[0173]
就先前已参考特定硬件构造或特征描述了实施方案而言,在模拟的实施方案中,等效功能可由合适的软件构造或特征提供。例如,特定电路系统可在模拟的实施方案中被实现为计算机程序逻辑。类似地,存储器硬件诸如寄存器或高速缓存存储器可在模拟的实施方案中被实现为软件数据结构。在先前描述的实施方案中参考的硬件元件中的一个或多个硬件元件存在于主机硬件(例如,主机处理器330)上的布置中,在合适的情况下,一些模拟的实施方案可以利用主机硬件。
[0174]
模拟器程序310可以存储在计算机可读存储介质(其可以是非暂时性介质)上,并且向目标代码300(其可以包括应用程序、操作系统和管理程序)提供程序接口(指令执行环境),该程序接口与由模拟器程序310建模的硬件架构的接口相同。因此,可以使用模拟器程序310从指令执行环境内执行目标代码300的程序指令(包括上述混合元素大小的指令),使得实际上不具有上文所讨论装置的硬件特征的主机计算机330可仿真这些特征。
[0175]
因此,一个示例提供了一种模拟器计算机程序310,该模拟器计算机程序在主机数据处理装置上执行时控制该主机数据处理装置提供用于执行目标代码的指令的指令执行环境;该计算机程序包括:指令解码程序逻辑312,该指令解码程序逻辑用于对程序指令进行解码以控制主机数据处理装置响应于程序指令而执行数据处理;以及寄存器仿真程序逻辑314,该寄存器仿真程序逻辑维护主机硬件330的主机存储装置中的数据结构,以对在由目标代码支持的仿真isa中定义的架构寄存器80、82、88进行仿真。计算机程序可存储在计算机可读记录介质上。该记录介质可以是非暂态记录介质。
[0176]
例如,指令解码程序逻辑312可以包括检查目标代码的程序指令的指令编码并且将每种类型的指令映射到由主机硬件330支持的本机指令集中的一个或多个程序指令的对应集上的指令,这些指令实现与由被解码的指令表示的功能相对应的功能。寄存器仿真程序逻辑314可以包括维护主机数据处理装置330的虚拟地址空间中和/或在主机装置330的寄存器中的数据结构的指令集,其中寄存器仿真数据结构表示寄存器80、82、88的寄存器内容,目标代码期望在硬件中提供该寄存器内容,但是该寄存器内容可能实际上不在主机装置330的硬件中提供。目标代码300中的指令(其在仿真指令集架构中引用特定寄存器)可以使得寄存器仿真程序逻辑314访问主机330的寄存器或在主机装置的本机指令集中生成加载/存储指令,以请求读取/写入对应的仿真寄存器状态。
[0177]
指令解码程序逻辑312可以支持使用寄存器寻址信息的数据传输指令,该寄存器寻址信息是以与上文针对硬件实施方案所讨论相同的方式使用基址寄存器和立即值来定义的。在图17的仿真器示例的情况下,当在目标代码中处理的指令是数据传输指令的加载/存储形式时,则响应于加载/存储数据传输指令指定用于识别寄存器存储装置的目标部分
的寄存器寻址信息和用于识别仿真存储器目标部分的存储器寻址信息,指令解码程序逻辑312控制主机330执行数据传输操作以在映射到寄存器存储装置的目标部分的寄存器仿真数据结构的位置与映射到仿真存储器目标部分的主机数据处理装置的主机存储装置中的位置之间传输数据。
[0178]
在本技术中,字词“被配置为
…”
用于意指装置的元件具有能够执行所限定的操作的配置。在该上下文中,“配置”意指硬件或软件的互连的布置或方式。例如,该装置可具有提供所限定的操作的专用硬件,或者可对处理器或其他处理设备进行编程以执行该功能。“被配置为”并不意味着装置元件需要以任何方式改变以便提供所限定的操作。
[0179]
虽然本文已结合附图详细描述了本发明的示例性实施方案,但应当理解,本发明并不限于那些精确的实施方案,并且在不脱离所附权利要求书所限定的本发明的范围和实质的前提下,本领域的技术人员可在其中实现各种变化和修改。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1