一种基于改进循环神经网络的预测方法
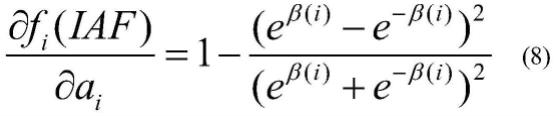
1.本发明涉及一种基于改进循环神经网络的预测方法,属于人工智能领域。
背景技术:
2.本发明是针对大豆价格进行预测,通过对大豆价格进行准确的预测,帮助政府进行合理的决策,可以实现更高的收入和减小经济损失。因此,大豆价格的预测对我国的社会稳定和安全至关重要。
3.深度学习(deep learning)算法渐渐成为人工智能热点研究领域。因此如何改进深度学习算法,优化现有算法的性能是众多学者一直致力于解决的问题。其中改变lstm网络结构可以将一些离散突发事件加入,以此来增加预测的精准度。
4.由于激活函数的重要性,众多学者通过对神经网络的研究,提出了多种不同类型的激活函数。例如sigmoid,tanh,relu等经典激活函数以及其改进结构。然而至今为止,对激活函数研究还没有明确的指导性原则。
技术实现要素:
5.本发明设计并实现一种基于改进循环神经网络的预测方法并针对大豆价格预测进行阐述。
6.设计的重点和优点主要在于:(1)提出一种新的lstm循环神经网络结构,在传统lstm网络结构的候选记忆权重处加入了离散事件单元,发生离散事件时,通过灰色关联方法得到不同特征的的关联度并对其进行加权,使影响因子大的特征更加明显,以此来提高的大豆价格的预测精度;(2)对大豆数据集下tanh函数的输入分布进行分析,在原tanh函数基础上提出了一种新的激活函数iaf,改善了tanh函数的饱和区间,加快了算法的收敛速度;(3)将提出的新激活函数应用在改进的lstm循环神经网络结构中作为大豆价格预测方法的模型,最终实现对大豆价格的预测。
附图说明
7.下面结合附图和实例对本发明进一步说明。附图用来提供对本发明的进一步理解,与本发明的实例共同用于解释本发明,并不构成对本发明的限制。
8.图1:部分大豆特征比较。
9.图2:改进lstm循环神经网络的结构图像。
10.图3:改进的lstm网络与传统lstm网络loss值对比。
11.图4:三种数据集下tanh函数的输入分布。
12.图5:tanh函数与iaf函数参数=0.5的图像。
13.图6:不同参数下iaf函数导数的图像。
14.图7:大豆价格预测值与实际值对比。
具体实施方式
15.本发明收集了一组数据集,原始数据由于过于粗糙,无法将其直接输入至lstm网络中,因此需要对其预处理,预处理包括数据平衡以及正则归一化。
16.首先进行数据平衡,一般来说,在总体水平上,年度数据概况使年度大豆价格相对更容易预测。考虑到有效性和成本之间的权衡,本发明对收集的大豆数据特征进行小范围和大范围采用,前者收集每日变化的数据,后者收集每月和每年数据,最后使用平均值法进行数据平衡,使每个特征的时间跨度一致。平均值公式如式(1)所示:
ꢀꢀꢀꢀꢀꢀꢀꢀ
(1)其中为平均值,为数据总量,代表单个特征的量。式(1)为平均值公式。
17.数据平衡之后,对于不同的大豆特征,由于它们的单位千差万别,为了更好的观察不同特征的联系,本发明对它们进行min-max标准化处理,使其缩放到[0,1]区间上。公式如式(2)所示:
ꢀꢀꢀꢀ
(2)其中为原始序列,为序列中最小值,为序列中最大值。
[0018]
图1展示了部分大豆数据的特征。通过对收集的大豆数据进行分析发现,不同的特征之间存在内联性,不同指标对大豆价格的影响程度不同,尤其是发生离散事件时,不同特征影响更加明显,针对这个发现,本发明在传统lstm循环神经网络中候选记忆权重处添加了一个离散事件单元,离散事件选择的是贸易战事件和大豆储备制度建立事件。当离散事件发生时,通过灰色关联方法得到不同特征的关联度,并对其进行加权,使其影响因子高的特征更加明显,以此来提高预测准确度。图2展示了改进的lstm循环神经网络结构。
[0019]
本发明对收集到的数据进行了正则归一化预处理,将其缩放到[-1,1]区间内。公式如式(3)所示:(3)其中为原始数据的均值,为原始数据的标准差,将其统一为6位小数,不足的补0。
[0020]
对于发生离散事件时,本发明通过灰色关联方法得到不同特征的关联度,公式如(4-6) 所示:δ(k)=|x(k)-y(k)|
ꢀꢀ
(5)
公式如(4-6)所示,其中k为影响指标,x(k)为影响指标的目标序列,y(k)为影响指标的参考序列,δ(k)为目标序列与参考序列的绝对差值,δs和δb为目标序列与参考序列的最小和最大差值,ρ是相关系数,其取值范围为[0,1],一般为0.5。δ(k)为当前指标输出的关联值,m为个数,γ为最终输出的关联值,取值范围为[0-1]表1 不同特征的关联度通过灰色关联模型得到不同特征的关联度如表1所示。
[0021]
图3展示了本发明提出改进的模型和标准lstm下loss值对比,我们可以看出在loss值比较上,本发明改进的模型比标准lstm预测模型整体波动较小,在迭代60次后,本发明改进的模型的波动已经趋于缓和,开始收敛,但lstm模型仍有波动,在迭代90次之后开始逐渐收敛,从整体上来看,本发明改进的模型性能更优,收敛速度更快。
[0022]
本发明其次对lstm网络中的激活函数进行了改进,图4展示了本发明在收集到的大豆数据集下tanh函数的输入分布,分析发现大豆数据集中的猪肉价格,豆粕产量、汇率、豆油进口,豆油出口,种植面积财政支出等特征部分年份分布在两端饱和区,其余特征分布在0中心区域,对于部分分布在饱和区的特征对预测来说较为重要,例如猪肉价格,豆粕产量,由反向传播算法可知导数偏低会限制反向传播的计算速度,从而制约了算法的收敛速度。针对这个问题在tanh函数的基础上提出了iaf函数,该函数改善了饱和区问题,式(7)为iaf公式:
ꢀꢀ
(7)图5展示了tanh函数与iaf函数参数=0.5图像对比。
[0023]
本发明选择不同参数下的iaf函数,通过对其导数区间对比选择更加合适参数下的iaf函数作为本发明最后的激活函数。如图6所示,本发明设置参数分别为0.1,0.5,1.0。通过对比可以发现当参数越小时,iaf函数的非饱和区间越大,然而很明显当参数过小时,其导数也较小,对比其导数可知参数越小,其导数最大值越小,同时相对更缓和。
[0024]
通过对比本发明发现,人工设置参数难以选择出最优的结果。这里本发明借鉴prelu的在训练中获得参数的方法,使用反向传播算法来更新iaf函数中参数a。其中a的梯度如式(8-9)所示:fi
代表iaf激活函数,由于在lstm网络中包含多个隐藏层,且每个隐藏层中具有多个通道用到激活函数,i代表不同通道的激活函数。ai为不同通道下的激活函数参数。ε为目标函数,β(i)代表aixi。
[0025]
通过反向传播更新后的如式(10)所示:
ꢀꢀꢀꢀ
(10)为动量系数,学习率。得到参数的更新公式后,本发明需要设置一个初始值,根据选择不同值的参数对比发现当为0.5时,其非饱和区间相对较大,且导数值不至于过低。因此本发明选择的初始值为0.5。
[0026] 表2为在本发明收集的大豆数据集下的测试,在迭代60次之后,iaf函数的loss为0.3125,而tanh函数loss值为0.3328,在迭代80次之后趋于稳定,iaf函数的loss达到0.01121,而tanh函数的loss值0.01873表2 大豆数据集下不同激活函数loss值对比为进一步验证新激活函数的有效性,本发明在耶拿天气数据集和空气质量数据集下使用改进的激活函数iaf和tanh函数进行测试对比。表3为在耶拿天气数据集下的测试,在迭代40次时,iaf的loss值下降开始变快,在最终迭代80次之后,iaf函数的loss趋于稳定,iaf函数的loss达到0.0163,而tanh函数的loss值为0.0243。在表4中展示了在空气质量数据集下的测试,在迭代40次时,tanh函数的loss值为0.01476,而iaf函数的loss值为0.01473,在最终迭代80次后,iaf的loss值开始趋于稳定,达到0.01424,而tanh函数的loss值为0.01435表3 耶拿天气数据集下不同激活函数loss值对比
表4 空气质量数据集下不同激活函数loss值对比综合上面数据集的测试结果,证明了本发明提出的新激活函数iaf在相同迭代次数下,能达到更低的loss值,因此证明了iaf函数比tanh函数的收敛速度更快。
[0027]
本发明将改进的lstm循环神经网络结合改进的激活函数作为大豆价格预测的最终模型,图7为大豆价格预测值和实际值比较,可以看到,两者非常接近。因此可以证明本发明的改进是有效的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1