决策模型训练、决策方法、装置、电子设备及存储介质与流程
1.本发明实施例涉及人工智能技术领域,尤其涉及一种决策模型训练、决策方法、装置、电子设备及存储介质。
背景技术:
2.人工智能(artificial intelligence,ai)是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。该领域研究包含机器学习、图像识别、语音识别以及自然语言处理等。深度学习(deep learning,dl)是机器学习领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能。它源于人工神经网络的研究,由多层感知机模型发展而来,具有更深层次的网络结构。原理是通过学习大量的样本,基于梯度反传算法多次迭代优化网络层中的参数,使网络模型以一种较优的方式抽取、组合样本特征,输出每个样本的预期结果。强化学习同样是机器学习的一个领域,它注重的是软件主体在一个环境中应该如何进行行动从而达到最大化累积奖励的想法。
3.目前,深度学习和强化学习被广泛应用于数据处理分析领域,可以集成检查、清理、转换和建模数据的过程,以用于发现有用的信息、告知结论和支持决策。
4.发明人在实现本发明的过程中,发现现有技术存在如下缺陷:在进行数据处理决策分析时,深度学习技术和强化学习技术往往被单独应用,如仅基于深度学习技术进行数据处理决策分析,或仅基于强化学习技术进行数据处理决策分析,各项技术之间结合性不强,数据处理决策分析准确率无法进一步提高,没有充分发挥人工智能的优势。
技术实现要素:
5.本发明实施例提供一种决策模型训练、决策方法、装置、电子设备及存储介质,能够充分发挥人工智能的优势,进一步提高数据决策的准确率。
6.第一方面,本发明实施例提供了一种决策模型训练方法,包括:
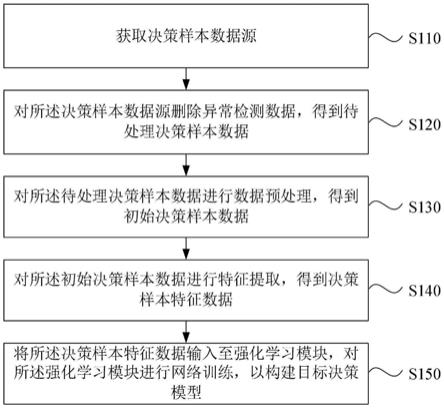
7.获取决策样本数据源;
8.对所述决策样本数据源删除异常检测数据,得到待处理决策样本数据;
9.对所述待处理决策样本数据进行数据预处理,得到初始决策样本数据;
10.对所述初始决策样本数据进行特征提取,得到决策样本特征数据;
11.将所述决策样本特征数据输入至强化学习模块,对所述强化学习模块进行网络训练,以构建目标决策模型。
12.第二方面,本发明实施例还提供了一种决策方法,应用于目标决策模型;所述目标决策模型通过上述任一所述的决策模型训练方法训练得到;所述方法包括:
13.获取待决策数据源;
14.对所述待决策数据源删除异常检测数据,得到待处理决策数据;
15.对所述待处理决策数据进行数据预处理,得到初始决策数据;
16.对所述初始决策数据进行特征提取,得到决策特征数据;
17.将所述决策特征数据输入至所述强化学习模块,获取所述强化学习模块的输出动作决策;
18.根据所述输出动作决策与目标决策环境进行交互,得到目标决策结果。
19.第三方面,本发明实施例还提供了一种决策模型训练装置,包括:
20.决策样本数据源获取模块,用于获取决策样本数据源;
21.异常检测模块,用于对所述决策样本数据源删除异常检测数据,得到待处理决策样本数据;
22.第一数据处理模块,用于对所述待处理决策样本数据进行数据预处理,得到初始决策样本数据;
23.第一特征提取模块,用于对所述初始决策样本数据进行特征提取,得到决策样本特征数据;
24.第一强化学习模块,用于将所述决策样本特征数据作为输入进行网络训练,以构建目标决策模型。
25.第四方面,本发明实施例还提供了一种决策装置,配置于目标决策模型,所述目标决策模型通过上述任一所述的决策模型训练方法训练得到;包括:
26.待决策数据源获取模块,用于获取待决策数据源;
27.第二异常检测模块,用于对所述待决策数据源删除异常检测数据,得到待处理决策数据;
28.第二数据处理模块,用于对所述待处理决策数据进行数据预处理,得到初始决策数据;
29.第二特征提取模块,用于对所述初始决策数据进行特征提取,得到决策特征数据;
30.第二强化学习模块,用于将所述决策特征数据作为输入,根据输入输出动作决策;
31.交互模块,用于根据所述输出动作决策与目标决策环境进行交互,得到目标决策结果。
32.第五方面,本发明实施例还提供了一种电子设备,所述电子设备包括:
33.一个或多个处理器;
34.存储装置,用于存储一个或多个程序;
35.当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现本发明任意实施例所提供的决策模型训练方法或决策方法。
36.第六方面,本发明实施例还提供了一种计算机存储介质,其上存储有计算机程序,该程序被处理器执行时实现本发明任意实施例所提供的决策模型训练方法或决策方法。
37.本发明实施例通过训练得到的目标决策模型获取待决策数据源之后,对待决策数据源删除异常检测数据,得到待处理决策数据,对待处理决策数据进行数据预处理,得到初始决策数据,对初始决策数据进行特征提取,得到决策特征数据,进而将决策特征数据输入至强化学习模块,获取强化学习模块的输出动作决策,最终根据输出动作决策与目标决策环境进行交互,得到目标决策结果,解决现有利用单一模型进行数据处理决策时存在的准确率较低的问题,能够充分发挥人工智能的优势,进一步提高数据决策的准确率。
附图说明
38.图1是本发明实施例一提供的一种决策模型训练方法的流程图;
39.图2是mo-gaal模型的结构示意图;
40.图3是ddpg算法的流程示意图;
41.图4是ddpg算法的流程示意图;
42.图5是本发明实施例二提供的一种决策模型训练方法的流程图;
43.图6是本发明实施例三提供的一种决策模型训练装置的示意图;
44.图7是本发明实施例四提供的一种决策装置的示意图;
45.图8为本发明实施例五提供的一种电子设备的结构示意图。
具体实施方式
46.下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。
47.另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部内容。在更加详细地讨论示例性实施例之前应当提到的是,一些示例性实施例被描述成作为流程图描绘的处理或方法。虽然流程图将各项操作(或步骤)描述成顺序的处理,但是其中的许多操作可以被并行地、并发地或者同时实施。此外,各项操作的顺序可以被重新安排。当其操作完成时所述处理可以被终止,但是还可以具有未包括在附图中的附加步骤。所述处理可以对应于方法、函数、规程、子例程、子程序等等。
48.本发明实施例的说明书和权利要求书及附图中的术语“第一”和“第二”等是用于区别不同的对象,而不是用于描述特定的顺序。此外术语“包括”和“具有”以及他们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有设定于已列出的步骤或单元,而是可包括没有列出的步骤或单元。
49.实施例一
50.图1是本发明实施例一提供的一种决策模型训练方法的流程图,本实施例可适用于结合深度学习和强化学习技术训练目标决策模型的情况,该方法可以由决策模型训练装置来执行,该装置可以由软件和/或硬件的方式来实现,并一般可集成在电子设备中,该电子设备可以是终端设备,也可以是服务器设备,本发明实施例并不对电子设备的具体设备类型进行限定。相应的,如图1所示,该方法包括如下操作:
51.s110、获取决策样本数据源。
52.其中,决策样本数据源可以是用于提供数据处理决策的,未经任何处理的样本数据源。所谓数据处理决策也即对在对数据处理分析的基础上,得到对应的决策结果。
53.在本发明实施例中,可以首先获取决策样本数据源,以根据决策样本数据源训练目标决策模型。可以理解的是,任何可以用于决策的数据源均可以作为决策样本数据源,例如,量化投资数据、业务的统计分析数据以及用户行为操作数据等,其中,所谓量化投资也即通过数量化方式及计算机程序化发出买卖指令,以获取稳定收益为目的的交易方式,本发明实施例并不对决策样本数据源的数据类型和数据获取方式进行限定。
54.可选的,目标决策模型可以包括但不限于异常检测模块、数据处理模块、特征提取模块以及强化学习模块。在模型训练过程中,模型的各个模块需要利用决策样本数据源进
行训练,以训练各个模型的数据处理能力,如异常检测模块需要训练异常数据检测能力,数据处理模块则需要训练数据预处理能力,特征提取模块需要训练特征提取能力,而强化学习模块则需要训练强化学习的能力。当目标决策模型完成训练后,各个模块的数据处理能力也训练完成,可以对需要进行决策的数据进行自动处理和决策。
55.s120、对所述决策样本数据源删除异常检测数据,得到待处理决策样本数据。
56.其中,异常检测数据也即决策样本数据源中经异常检测得到的异常数据。待处理决策样本数据可以是对决策样本数据源删除异常检测数据后得到的数据。
57.具体的,当目标决策模型获取到决策样本数据源之后,可以将决策样本数据源输入至目标决策模型的异常检测模块,以通过异常检测模块对决策样本数据源进行异常检测,得到异常检测数据,并对决策样本数据源删除异常检测数据,从而得到待处理决策样本数据,以训练异常检测模块的异常检测能力。可以理解的是,异常检测也即从数据集中的大量数据里找出与正常数据点有着很大偏差的异常点数据的过程。
58.在现有技术中,往往利用箱线图法来进行异常检测,这种异常检测方法针对现在维度高的大数据不具有适用性。如果数据源较为复杂,如面对复杂多变的金融市场的高维度的数据来说,使用箱线图法无法准确地分清异常数据和正常数据。
59.在本发明的一个可选实施例中,异常检测模块可以包括基于gan(generative adversarial networks,生成式对抗网络)网络的mo-gaal模型;对所述决策样本数据源删除异常检测数据,得到待处理决策样本数据,可以包括:对异常检测样本数据划分为设定数量的样本集;将所述设定数量的样本集和噪声数据作为输入数据输入至所述基于gan网络的mo-gaal模型,以对所述基于gan网络的mo-gaal模型进行训练;将所述决策样本数据源输入至训练得到的基于gan网络的mo-gaal模型的判别器中,以通过所述基于gan网络的mo-gaal模型的判别器删除所述异常检测数据,得到所述待处理决策样本数据。
60.其中,异常检测样本数据可以是用于训练异常检测模块的样本数据。设定数量可以根据实际需求设定,本发明实施例并不对设定数量的具体数值进行限定。可选的,设定数量可以与mo-gaal模型生成器的数量相同。
61.具体的,目标决策模型的异常检测模块可以采用基于gan网络的mo-gaal模型进行异常检测。mo-gaal模型是在so-gaal模型的基础上扩展得到的,将so-gaal模型的结构从单个生成器扩展到多个具有不同目标的生成器,从而得到mo-gaal模型。
62.mo-gaal模型不需要真实数据分布的先验信息即可学习到真实数据的分布规律,能有效减少计算量兼顾到算法的性能,并且能够生成大量接近正常数据的异常数据,克服异常检测中异常数据较少的问题,是一种很好的无监督异常检测模型,适合金融领域的异常数据检测。
63.其中,mo-gaal模型的判别器模型具体可以为:
[0064][0065]
其中,θd表示判别器d使用优化算法时的参数,vd表示判别器d优化的目标函数,d(x
(j)
)表示数据x的第j个样本,表示第i个生成器的第j个样本的输入噪声,表示
第i个生成器的第j个样本的输入噪声通过第i个生成器生成的伪数据,表示判别器对第i个生成器的第j个样本的输入噪声通过第i个生成器生成的伪数据的评分。
[0066]
mo-gaal模型的生成器模型具体可以为:
[0067][0068]
其中,θ
gi
表示第i个生成器gi使用优化算法时的参数,v
gi
表示第i个生成器优化的目标函数。ti表示判别器对真实数据子集评分的最小值。其中,
[0069]
图2是mo-gaal模型的结构示意图。如图2所示,mo-gaal模型由多个生成器和一个判别器。由于判别器d(x)输出相似的样本,其样本在样本空间中分布也类似。因此,同一个子集里的样本彼此之间是相似的。因此,在对mo-gaal模型输入数据之前,首先需要对真实数据划分为设定数量的样本集,如s个样本集,每个样本集的样本数量为si。生成器的总数量为s个,噪声分布为pz,将划分得到的样本集加入噪声数据,得到s个子集,将s个子集作为输入数据分别输入至生成器,让生成器分别主动学习对应s个子集的空间分布,生成器通过使生成的潜在离群值输出与它们相似的值来逐渐学习真是数据子集的生成机制。同时使用ti而不是1代替每个子集中生成器学习的目标,使得每个生成器能够学习到对应子集的分布。这样生成器就可以获取到足够的信息生成潜在的异常点,而又不会生成与真实数据分布一样的数据,避免了模式崩溃。mo-gaal模型在生成器和判别器达到纳什平衡后,优化判别器直到判别器的参数不再更新,此时判别器能够更精准地划分正常数据和异常数据的边界。
[0070]
为此,可以预先采用异常检测样本数据,并将异常检测样本数据划分为设定数量的样本集,以将设定数量的样本集和噪声数据作为输入的样本数据训练mo-gaal模型。当mo-gaal模型训练完成后,即可将决策样本数据源输入至训练得到的基于gan网络的mo-gaal模型的判别器中,以通过基于gan网络的mo-gaal模型的判别器进行判别,得到异常检测数据,并删除异常检测数据,得到待处理决策样本数据。
[0071]
上述技术方案,采用基于gan网络的无监督异常检测模型,适用于高维大数据,能够有效地提高整个系统的准确性。
[0072]
s130、对所述待处理决策样本数据进行数据预处理,得到初始决策样本数据。
[0073]
其中,初始决策样本数据可以是对待处理决策样本数据进行数据预处理后得到的数据。
[0074]
在通过异常检测模块删除异常检测数据,得到待处理决策样本数据之后,即可通过目标决策模型的数据处理模块对待处理决策样本数据进行数据预处理,得到初始决策样本数据。可以理解的是,数据预处理的方式有多种,因此可以根据具体需求选择相应的数据预处理方式来训练数据处理模块的数据处理能力。
[0075]
在本发明的一个可选实施例中,所述对所述待处理决策样本数据进行数据预处理,得到初始决策样本数据,可以包括:对所述待处理决策样本数据检测缺失数据;获取所述缺失数据的维度特征的平均值,并根据所述缺失数据的维度特征的平均值对所述缺失数据进行补充,得到补充决策样本数据;根据决策指标对所述补充决策样本数据进行归一化
处理,得到所述初始决策样本数据。
[0076]
其中,补充决策样本数据也即对待处理决策样本数据的缺失数据进行补充后得到的数据。决策指标可以是对补充决策样本数据进行归一化处理所筛选的参考指标。可以理解的是,数据类型不同,决策指标也不同,以量化投资数据为例说明,决策指标可以是根据价量信息和宏观信息计算得到的指标。
[0077]
具体的,数据处理模块可以首先对待处理决策样本数据进行数值缺失检查,检测待处理决策样本数据的确实数据,并计算缺失数据对应维度特征的平均值,以使用缺失数据对应维度特征的平均值对缺失数据进行补充,得到补充决策样本数据。或者,也还可以采用数值插值的方式对缺失数据进行补充,得到补充决策样本数据。相应的,在得到补充决策样本数据之后,数据处理模块可以进一步确定补充决策样本数据匹配的决策指标,以根据决策指标对补充决策样本数据进行归一化的标准处理,得到对应的初始决策样本数据。可选的,归一化处理得到的初始决策样本数据每个维度的数值信息都将标准化为均值0且方差为1的数据。
[0078]
s140、对所述初始决策样本数据进行特征提取,得到决策样本特征数据。
[0079]
其中,决策样本特征数据可以是对初始决策样本数据进行特征提取得到的数据。
[0080]
相应的,在数据处理模块得到初始决策样本数据后,可以将初始决策样本数据输入至目标决策模型的特征提取模块,以通过特征提取模块对初始决策样本数据进行特征提取,得到决策样本特征数据。
[0081]
在本发明的一个可选实施例中,特征提取模块可以包括自编码器(autoencoder,ae);所述对所述初始决策样本数据进行特征提取,得到决策样本特征数据,可以包括:筛选所述初始决策样本数据的目标技术指标作为待处理决策样本特征;通过自编码器ae提取所述待处理决策样本特征的深度特征,得到所述决策样本特征数据。
[0082]
其中,目标技术指标可以是需要决策处理的指标类型。
[0083]
具体的,特征提取模块可以首先筛选初始决策样本数据的目标技术指标作为待处理决策样本特征,实现对特征的基础提取过程,可以降低噪声干扰。进一步的,将待处理决策样本特征输入至特征提取模块的自编码器ae中,以通过自编码器ae对待处理决策样本特征提取深度特征,从而得到最终的决策样本特征数据。
[0084]
s150、将所述决策样本特征数据输入至强化学习模块,对所述强化学习模块进行网络训练,以构建目标决策模型。
[0085]
在本发明实施例中,当特征提取过程结束后,即可将提取到的决策样本特征数据输入至决策模型的强化学习模块,以对强化学习模块进行训练。当强化学习模块训练完成后,整个目标决策模型即训练完成。
[0086]
可以理解的是,强化学习模块可以通过神经网络模型构建。神经网络是深度学习领域具体的实现方式,由多层感知机模型发展而来,具有非常深的网络结构。先要选定足够量的样本反复训练该网络结构,当大部分样本的输出结果与预期结果差值小于一个阈值时,代表该网络模型已训练好,此时该网络可以运用到新场景中去,完成预期功能。
[0087]
在本发明的一个可选实施例中,强化学习模块可以包括actor(动作)当前网络、actor目标网络、critic(策略)当前网络以及critic目标网络;所述将所述决策样本特征数据输入至强化学习模块,对所述强化学习模块进行网络训练,可以包括:通过所述actor当
前网络根据所述决策样本特征数据选择当前动作,以根据当前动作和环境交互得到更新状态;通过所述actor目标网络根据所述更新状态确定更新动作;其中,所述更新动作用于与环境进行交互,得到新的更新状态;通过所述critic当前网络迭代更新所述强化学习模块的网络参数,并计算所述强化学习模块的当前奖励值;通过所述critic目标网络计算所述强化学习模块的更新奖励值。
[0088]
具体的,强化学习模块可以由actor当前网络、actor目标网络、critic当前网络以及critic目标网络四种不同类型的神经网络构成。在训练强化学习模块时,可以采用ddpg(deep reinforcement learning,深度确定性策略梯度算法)算法进行训练。其中,actor当前网络主要负责q网络中参数θ的迭代更新,负责根据当前状态s选择当前动作a,用于和环境交互生成更新状态s
′
和奖励值r。actor目标网络主要负责根据经验回放池中采样的下一状态s
′
选择最优下一动作作为更新动作a
′
。网络参数θ
′
则可以定期从θ复制。critic当前网络主要负责价值网络参数w的迭代更新,负责计算当前奖励值,也可以称为当前q值,即q(s,a,w)。critic目标网络主要负责计算强化学习模块的更新奖励值,也可以称为目标q值,具体可以是计算目标q值中的q
′
(s
′
,a
′
,w
′
)部分,目标q值的表达式具体可以为:r+γq
′
(s
′
,a
′
,w
′
)。其中,网络参数w
′
定期从w复制。同时,为了学习过程可以增加一些随机性,增加学习的覆盖,ddpg还可以对选择出来的动作a会增加一定的噪声nn,即最终和环境交互的动作a的表达式是:a=πθ(s)+n。其中,π表示策略,n表示一次训练取的经验样本个数。
[0089]
相应的,ddpg算法的流程示意图如图3和图4所示,ddpg的损失函数表达式可以为:
[0090][0091]
如图4所示,各个符号的含义具体为:
[0092]
1:按一定的有噪声的行为策略β选择行为。
[0093]
2:环境根据选取的动作给予奖励和新的状态反映。
[0094]
3:将有智能或者没智能行为记忆进行存储。
[0095]
4:从记忆库中选取批次以及进行两个网络不同形式和利用的训练。
[0096]
5:在critic中,q现实网络根据下一状态和下一个该选取的动作作为网络输入,r+q(next)计算获取q现实值。
[0097]
6:critic网络通过计算td-error梯度后进行网络的更新。
[0098]
7:actor网络的online网络进行更新时,针对于自己现在的行为,需要进行梯度的计算调整,使得让网络在相同的状态下倾向于生成更好的动作选择,所以要依赖于这个action的q值,q值则需要critic网络计算得到。
[0099]
8:采用优化器计算的梯度结果进行网络参数的更新。
[0100]
9:两种网络形式之间的软更新。
[0101]
本发明实施例通过对获取的决策样本数据源删除异常检测数据,得到待处理决策样本数据,并对待处理决策样本数据进行数据预处理,得到初始决策样本数据,对初始决策样本数据进行特征提取,得到决策样本特征数据,以将决策样本特征数据输入至强化学习模块,对强化学习模块进行网络训练,以构建目标决策模型,解决现有通过单一模型进行数据处理决策时存在的准确率较低的问题,能够提高用于数据处理决策的决策模型的准确
率,充分发挥人工智能的优势,进一步提高数据决策的准确率。
[0102]
实施例二
[0103]
图5是本发明实施例二提供的一种决策模型训练方法的流程图,本实施例可适用于结合深度学习和强化学习技术训练得到的目标决策模型进行决策的情况,该方法可以由决策装置来执行,该装置可以由软件和/或硬件的方式来实现,并一般可集成在电子设备中,该电子设备可以是终端设备,也可以是服务器设备,本发明实施例并不对电子设备的具体设备类型进行限定。在本发明实施例中,目标决策模型可以通过本发明实施例任一所述的决策模型训练方法训练得到。
[0104]
相应的,如图5所示,该方法包括如下操作:
[0105]
s210、获取待决策数据源。
[0106]
其中,待决策数据源可以是需要利用目标决策模型自动进行数据处理决策的,未经任何处理的数据源。
[0107]
s220、对所述待决策数据源删除异常检测数据,得到待处理决策数据。
[0108]
其中,待处理决策数据也即对待决策数据源删除异常检测数据后得到的数据。
[0109]
在本发明实施例中,在获取到待决策数据源之后,可以将待决策数据源输入到训练好的目标决策模型中,以通过目标决策模型自动对待决策数据源进行数据处理决策,得到对应的决策结果。首先,可以利用目标决策模型的异常检测模块对待决策数据源删除异常检测数据,得到待处理决策数据。
[0110]
s230、对所述待处理决策数据进行数据预处理,得到初始决策数据。
[0111]
其中,初始决策数据可以是对待处理决策数据进行数据预处理后得到的数据。
[0112]
相应的,在异常检测模块得到待处理决策数据之后,可以将待处理决策数据发送至数据处理模块,以通过数据处理模块对待处理决策数据进行数据预处理,得到初始决策数据。
[0113]
s240、对所述初始决策数据进行特征提取,得到决策特征数据。
[0114]
其中,决策特征数据可以是对初始决策数据进行特征提取得到的数据。
[0115]
在数据处理模块得到初始决策数据之后,可以将初始决策数据发送至特征提取模块,以通过特征提取模块对初始决策数据进行特征提取,得到决策特征数据。
[0116]
s250、将所述决策特征数据输入至所述强化学习模块,获取所述强化学习模块的输出动作决策。
[0117]
其中,输出动作决策也即强化学习模块输出的动作,可以用于与待决策数据源匹配的数据环境进行交互得到交互结果。
[0118]
s260、根据所述输出动作决策与目标决策环境进行交互,得到目标决策结果。
[0119]
其中,目标决策环境也即与待决策数据源匹配的数据环境。目标决策结果可以是根据输出动作决策与目标决策环境进行交互所得到的交互结果,可以提现输出动作决策的决策效果。
[0120]
相应的,在提取得到决策特征数据之后,特征提取模块可以将决策特征数据输入至强化学习模块,以通过强化学习模块对决策特征数据进行强化学习,得到输出动作决策,并将强化学习模块输出的输出动作决策与目标决策环境进行交互,从而得到最终的目标决策结果。
[0121]
本发明实施例通过训练得到的目标决策模型获取待决策数据源之后,对待决策数据源删除异常检测数据,得到待处理决策数据,对待处理决策数据进行数据预处理,得到初始决策数据,对初始决策数据进行特征提取,得到决策特征数据,进而将决策特征数据输入至强化学习模块,获取强化学习模块的输出动作决策,最终根据输出动作决策与目标决策环境进行交互,得到目标决策结果,解决现有利用单一模型进行数据处理决策时存在的准确率较低的问题,能够充分发挥人工智能的优势,进一步提高数据决策的准确率。
[0122]
具体应用场景:
[0123]
在金融市场中,高收益与高风险并存,收益最大化是金融市场的终极目标。随着计算机技术的快速发展,量化投资开始在金融投资领域兴起,现有技术已经结合金融投资细分领域的各自特点,衍生出许多量化投资模型,其中股票的量化投资最具代表性。目前,相关技术人员将人工智能应用到股票的量化投资和交易方面,基于人工智能的股票量化投资在国内外逐渐兴起。近年来,监督学习和强化学习先后应用到股票量化投资的研究上,使用这类深度学习技术实现海量数据分析,量化投资从单纯的策略逐渐过渡到人工智能实现的交易策略。一方面,基于股票价格随机理论和行为-价格关联性理论,部分技术人员使用监督学习来解决股票价格的多变性问题。其中有使用改进的svr(support vector regression,支持向量既回归)进行短时高频的交易数据进行了分析;根据股票价格的时序特性使用rnn(recurrent neural network,循环神经网络)网络进行预测;将市场情绪与股价相关性研究对象,使用深度网络对金融新闻标题进行分析从而预测股票价格等方法。相对传统统计学模型而言,它在一定程度上解决了因为金融时间序列的非平稳性、非线性和高噪声所带来的拟合难和鲁棒性差等问题。另一方面,部分技术人员提出模仿人类认知过程,使用强化学习进行行为建模,实现交易策略。其中有为自动金融交易建立的q-learning模型,它在三支意大利股票数据上显现出更好的收益;有的提出了循环强化学习rrl的自适应算法,实现了比q-learning更好的交易策略;还有的设计了多类别强化学习agent,并且测试了它们在不同交易频率下的收益表现等等。人工智能应用于量化投资领域目前已取得一定成绩,同时也存在很多有待进一步改进的问题。但是,目前通常仅采用单一的模型应用于量化投资领域,模型应用效果并不理想。
[0124]
为了解决上述问题,可以通过融合多种人工智能技术的目标决策模型来处理量化投资数据并自动进行决策处理。其中,目标决策模型通过上述实施例所述的决策模型训练方法训练得到。相应的,通过目标决策模型处理量化投资数据并自动进行决策处理的过程可以包括下述步骤:
[0125]
步骤(1):获取数据源。具体的,可以获取股票市场原始交易数据作为数据源。
[0126]
步骤(2):通过目标决策模型的异常检测模块对股票市场原始交易数据进行异常数据的剔除。
[0127]
步骤(2.1):首先对基于gan网络的mo-gaal模型进行预训练。
[0128]
步骤(2.2):预训练完成后,将股票市场原始交易数据输入至基于gan网络的mo-gaal模型的判别器中,得到异常检测数据并删除。
[0129]
步骤(3):通过目标决策模型的数据处理模块对股票市场交易数据进行数据预处理。
[0130]
步骤(3.1):通过目标决策模型的数据处理模块对删除异常检测数据的股票市场
交易数据进行数值缺失检查,检测其缺失的部分,并使用该维度特征的平均值代替缺失值,补充缺失值。
[0131]
步骤(3.2):对补充缺失值后的股票市场交易数据进行归一化处理,具体可以根据价量信息与宏观信息计算出对应的指标,并且将补充缺失值后的股票市场交易数据标准化,处理后的数据,每个维度的数值信息都将标准化为均值为0,方差为1的数据;得到经过处理的市场状态特征向量。
[0132]
步骤(4):通过目标决策模型的特征提取模块对预处理后的股票市场交易数据提取特征。
[0133]
步骤(4.1):优选股票市场交易数据中重要的技术指标信息作为待处理特征,降低噪声。
[0134]
步骤(4.2):通过ae自编码器作为特征提取网络,将待处理特征通过ae自编码器进行深度特征提取,输出提取的特征数据。
[0135]
步骤(5):通过目标决策模型的强化学习模块对提取的特征信息作为输入,以根据输入输出得到的关于对应的动作(如减仓、平仓或加仓)的概率。
[0136]
步骤(6):根据输出动作与环境进行交互,实时调整金融市场的目标仓位,达到最优化收入的目的。
[0137]
上述技术方案,通过基于gan网络的无监督异常检测模型进行异常数据处理,能够有效提高初始数据的准确性,提高目标决策模型的准确度。量化投资模型中,可以适应更加复杂的真实股票交易市场环境,能够处理连续的动作空间集。对复杂的环境采用多源特征提取,对股票市场表层特征进行充分抽象提取、减少特征间相关性和冗余度。且将提取的特征组成向量,作为神经网络的输入,通过强化学习模块可以处理连续动作的ddpg算法处理连续动作,表示的动作更加具体,目标决策模型的决策准确率能够得到明显提升。
[0138]
需要说明的是,以上各实施例中各技术特征之间的任意排列组合也属于本发明的保护范围。
[0139]
实施例三
[0140]
图6是本发明实施例三提供的一种决策模型训练装置的示意图,如图6所示,所述装置包括:决策样本数据源获取模块310、第一异常检测模块320、第一数据处理模块330、第一特征提取模块340、第一强化学习模块350以及目标决策模型构建模块360,其中:
[0141]
决策样本数据源获取模块310,用于获取决策样本数据源;
[0142]
第一异常检测模块320,用于对所述决策样本数据源删除异常检测数据,得到待处理决策样本数据;
[0143]
第一数据处理模块330,用于对所述待处理决策样本数据进行数据预处理,得到初始决策样本数据;
[0144]
第一特征提取模块340,用于对所述初始决策样本数据进行特征提取,得到决策样本特征数据;
[0145]
第一强化学习模块350,用于将所述决策样本特征数据作为输入进行网络训练,以构建目标决策模型。
[0146]
本发明实施例通过对获取的决策样本数据源删除异常检测数据,得到待处理决策样本数据,并对待处理决策样本数据进行数据预处理,得到初始决策样本数据,对初始决策
样本数据进行特征提取,得到决策样本特征数据,以将决策样本特征数据输入至强化学习模块,对强化学习模块进行网络训练,以构建目标决策模型,解决现有通过单一模型进行数据处理决策时存在的准确率较低的问题,能够提高用于数据处理决策的决策模型的准确率,充分发挥人工智能的优势,进一步提高数据决策的准确率。
[0147]
可选的,第一异常检测模块320包括基于gan网络的mo-gaal模型,具体用于:对异常检测样本数据划分为设定数量的样本集;将所述设定数量的样本集和噪声数据作为输入数据输入至所述基于gan网络的mo-gaal模型,以对所述基于gan网络的mo-gaal模型进行训练;将所述决策样本数据源输入至训练得到的基于gan网络的mo-gaal模型的判别器中,以通过所述基于gan网络的mo-gaal模型的判别器删除所述异常检测数据,得到所述待处理决策样本数据。
[0148]
可选的,第一数据处理模块330具体用于:对所述待处理决策样本数据检测缺失数据;获取所述缺失数据的维度特征的平均值,并根据所述缺失数据的维度特征的平均值对所述缺失数据进行补充,得到补充决策样本数据;根据决策指标对所述补充决策样本数据进行归一化处理,得到所述初始决策样本数据。
[0149]
可选的,第一特征提取模块340包括自编码器ae,具体用于:通过所述特征提取模块筛选所述初始决策样本数据的目标技术指标作为待处理决策样本特征;通过所述自编码器ae提取所述待处理决策样本特征的深度特征,得到所述决策样本特征数据。
[0150]
可选的,第一强化学习模块350包括actor当前网络、actor目标网络、critic当前网络以及critic目标网络,具体用于:通过所述actor当前网络根据所述决策样本特征数据选择当前动作,以根据当前动作和环境交互得到更新状态;通过所述actor目标网络根据所述更新状态确定更新动作;其中,所述更新动作用于与环境进行交互,得到新的更新状态;通过所述critic当前网络迭代更新所述强化学习模块的网络参数,并计算所述强化学习模块的当前奖励值;通过所述critic目标网络计算所述强化学习模块的更新奖励值。
[0151]
上述决策模型训练装置可执行本发明任意实施例所提供的决策模型训练方法,具备执行方法相应的功能模块和有益效果。未在本实施例中详尽描述的技术细节,可参见本发明任意实施例提供的决策模型训练方法。
[0152]
由于上述所介绍的决策模型训练装置为可以执行本发明实施例中的决策模型训练方法的装置,故而基于本发明实施例中所介绍的决策模型训练方法,本领域所属技术人员能够了解本实施例的决策模型训练装置的具体实施方式以及其各种变化形式,所以在此对于该决策模型训练装置如何实现本发明实施例中的决策模型训练方法不再详细介绍。只要本领域所属技术人员实施本发明实施例中决策模型训练方法所采用的装置,都属于本技术所欲保护的范围。
[0153]
实施例四
[0154]
图7是本发明实施例四提供的一种决策装置的示意图,决策装置配置于目标决策模型,所述目标决策模型通过本发明任一所述的决策模型训练方法训练得到,如图7所示,所述决策装置包括:待决策数据源获取模块410、第二异常检测模块420、第二数据处理模块430、第二特征提取模块440、第二强化学习模块450以及交互模块460,其中:
[0155]
待决策数据源获取模块410用于获取待决策数据源;
[0156]
第二异常检测模块420用于对所述待决策数据源删除异常检测数据,得到待处理
决策数据;
[0157]
第二数据处理模块430用于对所述待处理决策数据进行数据预处理,得到初始决策数据;
[0158]
第二特征提取模块440用于对所述初始决策数据进行特征提取,得到决策特征数据;
[0159]
第二强化学习模块450用于将所述决策特征数据作为输入,根据输入输出动作决策;
[0160]
交互模块460用于根据所述输出动作决策与目标决策环境进行交互,得到目标决策结果。
[0161]
本发明实施例通过训练得到的目标决策模型获取待决策数据源之后,对待决策数据源删除异常检测数据,得到待处理决策数据,对待处理决策数据进行数据预处理,得到初始决策数据,对初始决策数据进行特征提取,得到决策特征数据,进而将决策特征数据输入至强化学习模块,获取强化学习模块的输出动作决策,最终根据输出动作决策与目标决策环境进行交互,得到目标决策结果,解决现有利用单一模型进行数据处理决策时存在的准确率较低的问题,能够充分发挥人工智能的优势,进一步提高数据决策的准确率。
[0162]
上述决策装置可执行本发明任意实施例所提供的决策方法,具备执行方法相应的功能模块和有益效果。未在本实施例中详尽描述的技术细节,可参见本发明任意实施例提供的决策方法。
[0163]
由于上述所介绍的决策装置为可以执行本发明实施例中的决策方法的装置,故而基于本发明实施例中所介绍的决策方法,本领域所属技术人员能够了解本实施例的决策装置的具体实施方式以及其各种变化形式,所以在此对于该决策装置如何实现本发明实施例中的决策方法不再详细介绍。只要本领域所属技术人员实施本发明实施例中决策方法所采用的装置,都属于本技术所欲保护的范围。
[0164]
实施例五
[0165]
图8为本发明实施例五提供的一种电子设备的结构示意图。图8示出了适于用来实现本发明实施方式的示例性电子设备12的框图。图8显示的电子设备12仅仅是一个示例,不应对本发明实施例的功能和使用范围带来任何限制。
[0166]
如图8所示,电子设备12以通用计算设备的形式表现。电子设备12的组件可以包括但不限于:一个或者多个处理器16,存储器28,连接不同系统组件(包括存储器28和处理器16)的总线18。
[0167]
总线18表示几类总线结构中的一种或多种,包括存储器总线或者存储器控制器,外围总线,图形加速端口,处理器或者使用多种总线结构中的任意总线结构的局域总线。举例来说,这些体系结构包括但不限于工业标准体系结构(industry standardarchitecture,isa)总线,微通道体系结构(micro channel architecture,mca)总线,增强型isa总线、视频电子标准协会(video electronics standardsassociation,vesa)局域总线以及外围组件互连(peripheral component interconnect,pci)总线。
[0168]
电子设备12典型地包括多种计算机系统可读介质。这些介质可以是任何能够被电子设备12访问的可用介质,包括易失性和非易失性介质,可移动的和不可移动的介质。
[0169]
存储器28可以包括易失性存储器形式的计算机系统可读介质,例如随机存取存储
器(random access memory,ram)30和/或高速缓存存储器32。电子设备12可以进一步包括其它可移动/不可移动的、易失性/非易失性计算机系统存储介质。仅作为举例,存储系统34可以用于读写不可移动的、非易失性磁介质(图8未显示,通常称为“硬盘驱动器”)。尽管图8中未示出,可以提供用于对可移动非易失性磁盘(例如“软盘”)读写的磁盘驱动器,以及对可移动非易失性光盘(例如只读光盘(compact disc-read only memory,cd-rom)、数字视盘(digital video disc-read only memory,dvd-rom)或者其它光介质)读写的光盘驱动器。在这些情况下,每个驱动器可以通过一个或者多个数据介质接口与总线18相连。存储器28可以包括至少一个程序产品,该程序产品具有一组(例如至少一个)程序模块,这些程序模块被配置以执行本发明各实施例的功能。
[0170]
具有一组(至少一个)程序模块42的程序/实用工具40,可以存储在例如存储器28中,这样的程序模块42包括但不限于操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。程序模块42通常执行本发明所描述的实施例中的功能和/或方法。
[0171]
电子设备12也可以与一个或多个外部设备14(例如键盘、指向设备、显示器24等)通信,还可与一个或者多个使得用户能与该电子设备12交互的设备通信,和/或与使得该电子设备12能与一个或多个其它计算设备进行通信的任何设备(例如网卡,调制解调器等等)通信。这种通信可以通过输入/输出(input/output,i/o)接口22进行。并且,电子设备12还可以通过网络适配器20与一个或者多个网络(例如局域网(local area network,lan),广域网wide area network,wan)和/或公共网络,例如因特网)通信。如图所示,网络适配器20通过总线18与电子设备12的其它模块通信。应当明白,尽管图8中未示出,可以结合电子设备12使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、(redundant arrays of independent disks,raid)系统、磁带驱动器以及数据备份存储系统等。
[0172]
处理器16通过运行存储在存储器28中的程序,从而执行各种功能应用以及数据处理,实现本发明实施例所提供的决策模型训练方法或决策方法。其中:
[0173]
决策模型训练方法包括:获取决策样本数据源;对所述决策样本数据源删除异常检测数据,得到待处理决策样本数据;对所述待处理决策样本数据进行数据预处理,得到初始决策样本数据;对所述初始决策样本数据进行特征提取,得到决策样本特征数据;将所述决策样本特征数据输入至强化学习模块,对所述强化学习模块进行网络训练,以构建目标决策模型。
[0174]
决策方法包括:获取待决策数据源;对所述待决策数据源删除异常检测数据,得到待处理决策数据;对所述待处理决策数据进行数据预处理,得到初始决策数据;对所述初始决策数据进行特征提取,得到决策特征数据;将所述决策特征数据输入至强化学习模块,获取所述强化学习模块的输出动作决策;根据所述输出动作决策与目标决策环境进行交互,得到目标决策结果。
[0175]
实施例六
[0176]
本发明实施例六还提供一种存储计算机程序的计算机存储介质,所述计算机程序在由计算机处理器执行时用于执行本发明上述实施例任一所述的决策模型训练方法或决策方法。其中:
[0177]
决策模型训练方法包括:获取决策样本数据源;对所述决策样本数据源删除异常检测数据,得到待处理决策样本数据;对所述待处理决策样本数据进行数据预处理,得到初始决策样本数据;对所述初始决策样本数据进行特征提取,得到决策样本特征数据;将所述决策样本特征数据输入至强化学习模块,对所述强化学习模块进行网络训练,以构建目标决策模型。
[0178]
决策方法包括:获取待决策数据源;对所述待决策数据源删除异常检测数据,得到待处理决策数据;对所述待处理决策数据进行数据预处理,得到初始决策数据;对所述初始决策数据进行特征提取,得到决策特征数据;将所述决策特征数据输入至强化学习模块,获取所述强化学习模块的输出动作决策;根据所述输出动作决策与目标决策环境进行交互,得到目标决策结果。
[0179]
本发明实施例的计算机存储介质,可以采用一个或多个计算机可读的介质的任意组合。计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质。计算机可读存储介质例如可以是但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器(ram)、只读存储器(read only memory,rom)、可擦式可编程只读存储器(erasable programmable read only memory,eprom,或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本文件中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。
[0180]
计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。
[0181]
计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于无线、电线、光缆、射频(radio frequency,rf)等等,或者上述的任意合适的组合。
[0182]
可以以一种或多种程序设计语言或其组合来编写用于执行本发明操作的计算机程序代码,所述程序设计语言包括面向对象的程序设计语言—诸如java、smalltalk、c++,还包括常规的过程式程序设计语言,诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络,包括局域网(lan)或广域网(wan)连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。
[0183]
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1