横向联邦学习方法、系统及参与设备与流程
本发明涉及联邦学习及大数据分析领域,尤其是指一种横向联邦学习方法、系统及参与设备。
背景技术:
1、近年来,人工智能进入以深度学习为主导的大数据时代,大数据是当前人工智能应用的基本元素。然而,在实际应用中,我们面对是数据现状是:小规模、碎片化、缺乏数据标签、数据分散、由用户隐私保护和数据安全引发的数据孤岛现象等。传统的方法是将分散在各处的数据聚合到数据中心,在数据中心进行建模。随着应用领域的不断扩大和用户隐私保护各项法律法规的不断完善,传统的数据聚合后再建模的方法越来越难以实施,于是,联邦学习应运而生,联邦学习的基本思想是在保证用户隐私和数据安全的条件下,构建多个参与方共享的高性能模型,旨在解决隐私保护和数据孤岛问题。具体方法是使用多方的数据联合建模,建模过程中各方数据不离开本地,不暴露给各参与建模方,以达到保护用户隐私和数据安全的目的,同时利用各方数据建立高性能模型。
2、横向联邦学习是联邦学习的重要组成部分,主要应用于多个参与方的数据结构相同,但数据量不足,希望在互相不暴露数据隐私的条件下,通过联合建模,得到高性能模型。横向联邦学习中各参与方算法模型与数据特征一致,各个参与方利用本地数据训练局部模型,并将参数传给协调方,由协调方将各方上传的模型参数合并为全局模型,再将全局模型传输给各个参与方进行本地化更新。基本流程如下:①本地训练任务配置;②本地模型训练并提取参数;③模型参数加密传输;④参数化模型合并;⑤合并后模型参数下发;⑥本地化更新。上述过程是目前业界通用的横向联邦学习流程,实际应用中,会出现模型效果不佳等问题,各节点数据非独立同分布是其中的一个重要原因。目前尚未见到解决此类问题的较为成熟的方法。
技术实现思路
1、本发明的目的在于提供一种横向联邦学习方法、系统及参与设备,以解决现有技术横向联邦学习方法的建模效果不佳、精度不高的问题。
2、为了解决上述问题,本发明实施例提供一种横向联邦学习方法,包括:
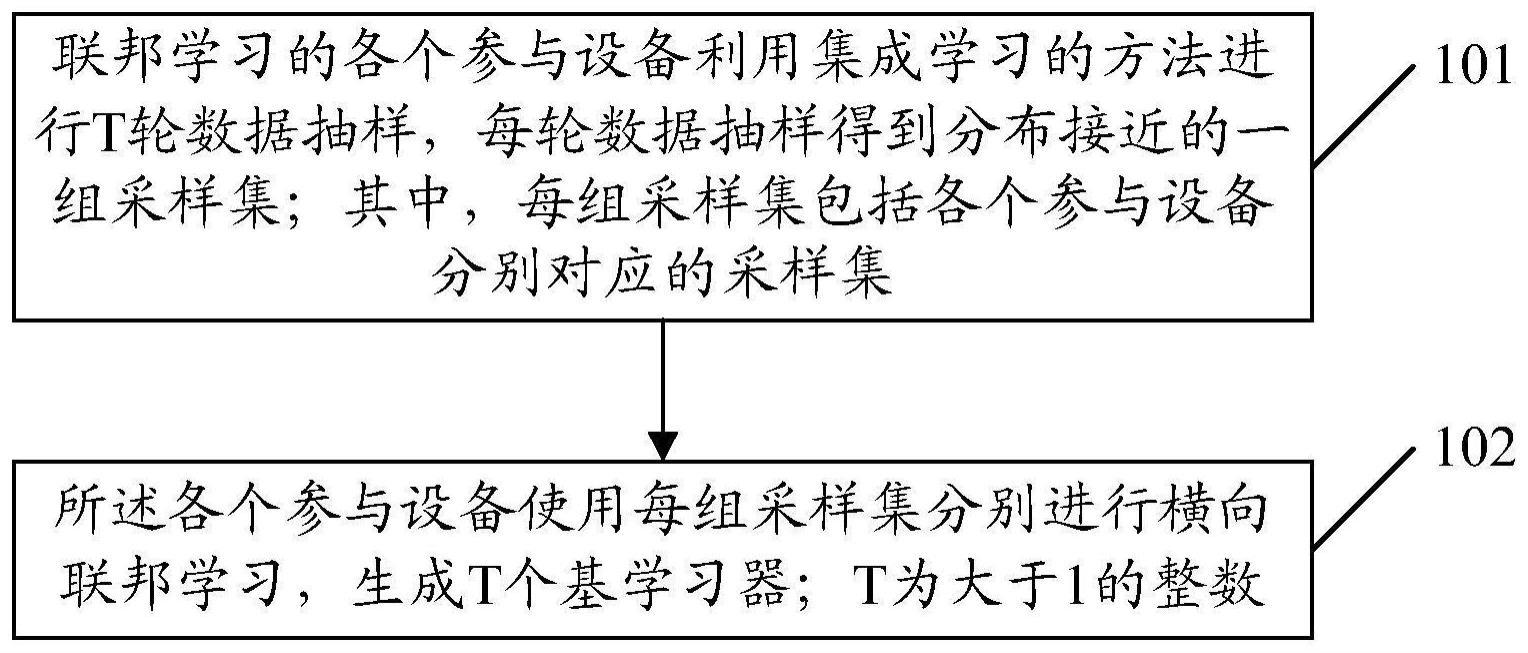
3、联邦学习的各个参与设备利用集成学习的方法进行t轮数据抽样,每轮数据抽样得到分布接近的一组采样集;其中,每组采样集包括各个参与设备分别对应的采样集;
4、所述各个参与设备使用每组采样集分别进行横向联邦学习,生成t个基学习器;t为大于1的整数。
5、其中,联邦学习的各个参与设备利用集成学习的方法进行一轮数据抽样,得到分布接近的一组采样集,包括:
6、主导参与设备在本地数据集随机抽样得到第一采样集;
7、其他参与设备根据所述第一采样集的样本分布向量在本地数据集进行抽样,得到与所述第一采样集分布接近的第二采样集;
8、其中,所述分布接近的一组采样集包括所述第一采样集和至少一个所述第二采样集。
9、其中,联邦学习的所有参与设备依次作为所述主导参与设备。
10、其中,联邦学习的各个参与设备利用集成学习的方法进行t轮数据抽样之前,所述方法还包括:
11、各个参与设备接收协调设备发送的各数值型特征的数据取值范围划分方案、各类别型特征的取值点;
12、所述各个参与设备根据所述各数值型特征的数据取值范围划分方案以及所述各类别型特征的取值点,对本地数据集进行独热编码,将所述本地数据集的各个样本转化为一个k维的0-1向量,k为大于1的整数。
13、其中,所述主导参与设备在本地数据集随机抽样得到第一采样集之后,所述方法还包括:
14、所述主导参与设备根据所述第一采样集中各个标签包括的样本的k维的0-1向量,计算所述第一采样集的样本分布向量;所述样本分布向量用于指示各个数值型特征取值落在协调设备发送的子区间的样本数量占所述数值型特征所属的标签样本总量的比例,和/或,各个类别性特征取值落在协调设备发送的类别内的样本数量占该类别性特征所属标签的样本总量的比例;
15、所述主导参与设备向其他参与设备发送所述第一采样集的样本分布向量。
16、其中,其他参与设备根据所述第一采样集的样本分布向量在本地数据集进行抽样,得到与所述第一采样集分布接近的第二采样集,包括:
17、所述其他参与设备在本地数据集中进行有放回随机采样,并根据采样样本的0-1向量与所述第一采样集的样本分布向量的曼哈顿距离判断是否将所述采样样本纳入所述第二采样集,直到所述第二采样集中的样本数量达到设定值则停止采样。
18、其中,所述其他参与设备根据采样样本的0-1向量与所述第一采样集的样本分布向量的曼哈顿距离判断是否将所述采样样本纳入所述第二采样集,包括:
19、所述其他参与设备计算所述采样样本与所述第一采样集的样本分布向量的曼哈顿距离;
20、若所述曼哈顿距离小于第一门限,所述其他参与设备确定采样样本为有效样本,将所述采样样本纳入所述第二采样集;否则确定所述采样样本为无效样本。
21、其中,所述方法还包括:
22、各个参与设备确定本地数据集的每个数值型特征的取值范围以及每个类别型特征的取值点;
23、所述各个参与设备给每个数值型特征的取值范围以及每个类别型特征的取值点分别添加扰动,并向协调设备发送添加了扰动的每个数值型特征的取值范围以及每个类别型特征的取值点;以由所述协调设备确定各数值型特征的数据取值范围划分方案以及各类别型特征的取值点。
24、本发明实施例还提供一种横向联邦学习系统,包括:
25、抽样模块,用于由联邦学习的各个参与设备利用集成学习的方法进行t轮数据抽样,每轮数据抽样得到分布接近的一组采样集;其中,每组采样集包括各个参与设备分别对应的采样集;
26、生成模块,用于由所述各个参与设备使用每组采样集分别进行横向联邦学习,生成t个基学习器;t为大于1的整数。
27、其中,所述抽样模块包括:
28、第一抽样子模块,用于由主导参与设备在本地数据集随机抽样得到第一采样集;
29、第二抽样子模块,用于由其他参与设备根据所述第一采样集的样本分布向量在本地数据集进行抽样,得到与所述第一采样集分布接近的第二采样集;
30、其中,所述分布接近的一组采样集包括所述第一采样集和至少一个所述第二采样集。
31、其中,联邦学习的所有参与设备依次作为所述主导参与设备。
32、其中,所述系统还包括:
33、第一接收模块,用于由各个参与设备接收协调设备发送的各数值型特征的数据取值范围划分方案、各类别型特征的取值点;
34、预处理模块,用于由所述各个参与设备根据所述各数值型特征的数据取值范围划分方案以及所述各类别型特征的取值点,对本地数据集进行独热编码,将所述本地数据集的各个样本转化为一个k维的0-1向量,k为大于1的整数。
35、其中,所述系统还包括:
36、计算模块,用于由所述主导参与设备根据所述第一采样集中各个标签包括的样本的k维的0-1向量,计算所述第一采样集的样本分布向量;所述样本分布向量用于指示各个数值型特征取值落在协调设备发送的子区间的样本数量占所述数值型特征所属的标签样本总量的比例,和/或,各个类别性特征取值落在协调设备发送的类别内的样本数量占该类别性特征所属标签的样本总量的比例;
37、发送模块,用于由所述主导参与设备向其他参与设备发送所述第一采样集的样本分布向量。
38、其中,所述第二抽样子模块包括:
39、抽样单元,用于所述其他参与设备在本地数据集中进行有放回随机采样,并根据采样样本的0-1向量与所述第一采样集的样本分布向量的曼哈顿距离判断是否将所述采样样本纳入所述第二采样集,直到所述第二采样集中的样本数量达到设定值则停止采样。
40、其中,所述抽样单元包括:
41、计算子单元,用于由所述其他参与设备计算所述采样样本与所述第一采样集的样本分布向量的曼哈顿距离;
42、确定子单元,用于若所述曼哈顿距离小于第一门限,由所述其他参与设备确定采样样本为有效样本,将所述采样样本纳入所述第二采样集;否则确定所述采样样本为无效样本。
43、其中,所述系统还包括:
44、确定模块,用于由各个参与设备确定本地数据集的每个数值型特征的取值范围以及每个类别型特征的取值点;
45、上报模块,用于由所述各个参与设备给每个数值型特征的取值范围以及每个类别型特征的取值点分别添加扰动,并向协调设备发送添加了扰动的每个数值型特征的取值范围以及每个类别型特征的取值点;以由所述协调设备确定各数值型特征的数据取值范围划分方案以及各类别型特征的取值点。
46、本发明实施例还提供一种横向联邦学习的参与设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的程序,所述处理器执行所述程序时实现如上所述的横向联邦学习方法。
47、本发明实施例还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上所述的横向联邦学习方法中的步骤。
48、本发明的上述技术方案至少具有如下有益效果:
49、本发明实施例的横向联邦学习方法、系统及参与设备,联邦学习的各个参与设备利用集成学习的方法进行t轮数据抽样,每轮数据抽样得到分布接近的一组采样集;一组采样集一起进行联邦学习,训练出一个基学习器。由于每一组采样集分布接近,克服了原始数据非独立同分布问题,因此能够提高训练出的基学习器的模型精度;同时,不同组采样集的分布也各不相同,则不同组采样集训练出的基学习器会有差异。根据集成学习理论,满足这两个条件的基学习器集合,进行集成学习会有较高的模型精度。
- 还没有人留言评论。精彩留言会获得点赞!