一种低比特神经网络输入源相加层优化的实现方法与流程
本发明涉及神经网路,特别涉及一种低比特神经网络输入源相加层优化的实现方法。
背景技术:
1、近年来,随着科技的飞速发展,大数据时代已经到来,神经网络中大量的数据处理技术日益成为重要的应用技术之一。特别是随着深度卷积神经网络cnn模型的发展,利用cnn模型中神经网络输入源相加(shortcut)的使用也日益频繁。此外,bankround(银行家舍入)的应用也是数据处理中常见的方法。shortcut(捷径)常用方法:输入相加除以2,结果为float类型,四舍五入。bankround:四舍六入,然后直接判断小数是否为5,以及整数部分是否为偶数。一般情况shortcut直接相加,将数据转换为浮点,除以2,然后进行round计算,实际应用过程中float占用32bit,对于低比特数据而言,存在内存空间浪费,计算速度较慢的问题,因此如果通过占用较小的数据位宽进行计算至为重要。
2、换句话说,现有技术中,存在以下缺陷:
3、shortcut:数据相加除以2,结果四舍五入,不仅速度慢,而且存在一定的精度误差。
4、bankround:直接使用float类型数据计算,导致计算速度慢,耗时增加。
5、此外,现有技术中的常用术语如下:
6、1、shortcut是cnn模型发展中出现的一种非常有效的结构,用于解决由于网络加深而导致的梯度发散的情况。
7、2、bankround:四舍六入五考虑,五后非零就进一,五后为零看奇偶,五前为偶应舍去,五前为奇要进一。
8、3、位宽扩展:基于低比特相加,会出现相加结果越界,需要对原数据进行高位补0,增加位宽。
9、4、simd:single instruction multiple data,单指令流多数据流,一次运算指令可以执行多个数据流,可以提高程序的运算速度。(每个寄存器512bit位宽)。
技术实现思路
1、为了解决上述问题,本技术的目的在于:对低比特数据使用simd指令进行加速,节省数据空间,减少计算指令,优化计算逻辑,提高计算效率。
2、具体地,本发明提供一种低比特神经网络输入源相加层优化实现方法,所述方法通过使用simd指令对数据进行并行计算,对低比特数据进行神经网络输入源相加加速,即优化数据比特bit位宽,将低bit数据相加,结果移位,以及利用bankround计算逻辑,对结果进行移位,得到小数与奇偶标志位,判断最后是否需要加1,全部计算基于simd低比特指令,将乘法转换为移位指令,浮点转换为低比特整形,通过&操作,完成对结果的奇偶判断,最终实现低比特神经网络输入源相加层优化。
3、所述的一种低比特神经网络输入源相加层优化的实现方法,所述方法包括:
4、低比特相加:对于低比特数据,2bit扩展为4bit,4bit扩展为8bit,直接使用二进制相加,结果移位;
5、使用bankround:计算逻辑,对结果进行移位,得到小数与奇偶标志位,判断最后是否需要+1。
6、所述方法包括优化数据bit位宽以及bankround计算逻辑,进一步包括:
7、1,内存:计算逻辑基于低比特,无需扩展到32bit位宽;
8、低比特数据扩展之后相加,防止出现相加结果越界,需要对数据进行位宽扩展;
9、a):2bit数据扩展到4bit,直接相加、移位,一个字节高低4位存储两个2bit计算结果,一个寄存器可存储128个数;
10、b):4bit数据扩展到8bit,相加、移位,一个寄存器可存储64个数;
11、2,时间:浮点float计算慢,使用与&操作代替原先的乘除法,优化实现逻辑,减少simd指令,即:
12、原本逻辑指令(38):数字越大表示需要实现的步骤越多,逻辑越复杂;使用simd实现功能步骤
13、
14、ext_fmt_p(u,4bi,l,vrd0,vrs0)x 2:
15、无符号4bit扩展为8bit,两个输入源
16、add(b,vrd0,vrs0,vrs1)
17、两个输入源相加
18、ext_fmt_p(u,b,l,vrd1,vrd0):
19、ext_fmt_p(u,b,h,vrd2,vrd0):
20、无符号8bit扩展为16bit(寄存器512bit,64个数需要存储在两个寄存器)
21、ext_fmt_p(u,h,l,vrd3,0,vrd1):
22、ext_fmt_p(u,h,h,vrd4,1,vrd1):
23、ext_fmt_p(u,h,l,vrd5,0,vrd2):
24、ext_fmt_p(u,h,h,vrd6,1,vrd2):
25、无符号16bit扩展为32bit,(64个数需要存储在4个寄存器)
26、fmulw(vrd3,vrd3,0.5)x 4
27、结果*0.5(4个寄存器)
28、ftuiw(vrd3,vrd3)x 4
29、结果浮点bankround转换为int(4个寄存器)
30、gt_fmt(h,vrd3,vrd3)
31、gt_fmt(h,vrd4,vrd4)
32、gt_fmt(h,vrd5,vrd5)
33、gt_fmt(h,vrd6,vrd6)
34、gt_n_fmt(2,w,vrd3,0,vrd3,0)
35、gt_n_fmt(2,w,vrd3,1,vrd4,0)
36、gt_n_fmt(2,w,vrd5,0,vrd5,0)
37、gt_n_fmt(2,w,vrd5,1,vrd6,0)
38、将32bit数据转换为16bit数据保存
39、gt_fmt(b,vrd3,vrd3)
40、gt_fmt(b,vrd5,vrd5)
41、gt_n_fmt(2,w,vrd3,0,vrd3,0)
42、gt_n_fmt(2,w,vrd3,1,vrd5,0)
43、将16bit数据转换为8bit数据保存
44、gt_fmt(4bi,vrd3,vrd3)
45、gt_n_fmt(2,w,vrd3,0,vrd3,0)
46、将8bit数据转换为4bit数据保存;
47、而本方法优化后simd逻辑(9):
48、 功能: simd指令功能 simd指令数 总指令数 bit扩展: 4bit扩展8bit 2 2 逻辑计算 加法add 1 1 bankround: 移位+& 4 4 bit合并 8bit合并为4bit 2 2 合计:9
49、ext_fmt_p(u,4bi,l,vrd0,vrs0)x 2:
50、无符号4bit扩展为8bit,两个输入源
51、add(b,vrd0,vrs0,vrs1)
52、两个输入源相加
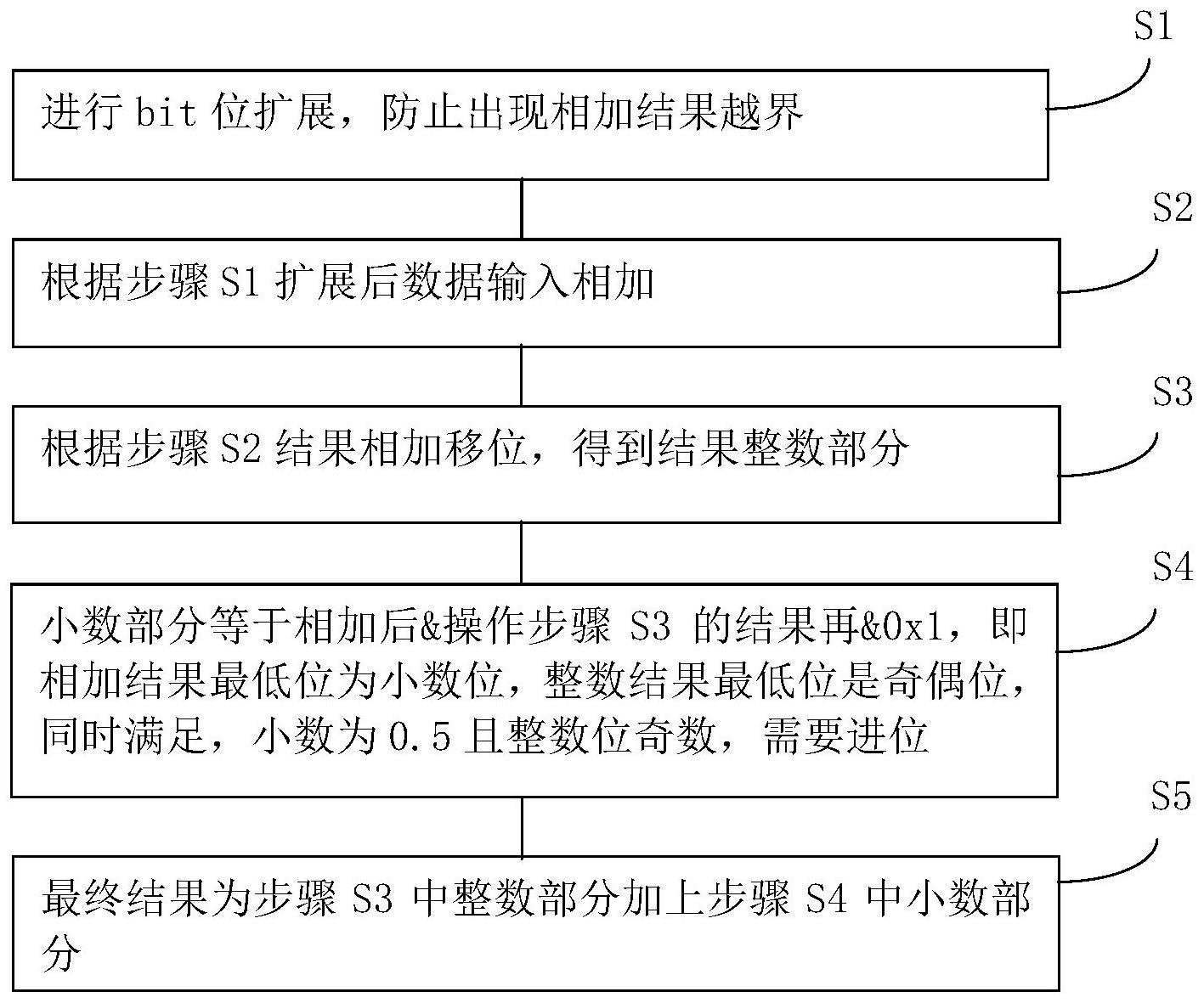
53、srai(b,vrd1,vrd0,1)
54、结果右移>>1,得到整数部分
55、andv(vrd2,vrd0,vrd1)
56、相加结果与整数部分&,确定小数标志位和奇偶标志位同时满足
57、andv(vrd3,vrd2,vrd0)
58、标志位&0x1,得到进位的数,0 or 1
59、add(vrd4,vrd1,vrd3)
60、结果=整数+小数
61、gt_fmt(4bi,vrd3,vrd3)
62、gt_n_fmt(2,w,vrd3,0,vrd3,0)
63、将8bit数据转换为4bit数据保存
64、优化核心逻辑在于无需扩展位宽至32bit,基于低比特使用位与计算,实现bankround逻辑。
65、所述方法进一步包括以下步骤:
66、s1:进行bit位扩展,防止出现相加结果越界;
67、s2:根据步骤s1扩展后数据输入相加;
68、s3:根据步骤s2结果相加移位,得到结果整数部分;
69、s4:小数部分等于相加后与&操作步骤s3的结果再&0x1,即相加结果最低位为小数位,整数结果最低位是奇偶位,同时满足,小数为0.5且整数位奇数,需要进位;
70、s5:最终结果为步骤s3中整数部分加上步骤s4中小数部分。
71、所述方法以二进制显示4比特数据,设f0+f1=1111+1111,进一步包括:
72、s1:1111->0000 1111bit位扩展,防止出现相加结果越界;
73、s2:f0+f1=00001111+00001111=0001 1110输入相加;
74、s3:res=(f0+f1)>>1=0001 1110>>1=0000 1111相加移位,得到结果整部部分;
75、s4:decimal=(f0+f1)&res&0x1=0001 1110&0000 1111&0000 0001=0000 0000f0+f1最低位为小数位,res最低位是奇偶位,同时满足,表示小数为0.5,且整数位为奇数,需要进位;
76、s5:res=res+decimal整数+小数得到最后的结果。
77、所述方法中原始数据计算逻辑为:
78、输入源相加:目标=源0+源1,表示为:dst=src0+src1;
79、使用bankround:将数据x定义为目标/2并取浮点型,表示为:float x=dst/2;
80、将数据x四舍五入,表示为:int res=round(x);
81、将数据x取整数部分,表示为:int integer=(int)x;
82、将数据x-整数部分得到的小数取浮点型,表示为float decimal=x-integer;
83、判断是否满足整数部分为奇数且小数部分为0.5,当满足时,则
84、当res为正时,res+1;
85、当res小于等于0时,res-1;
86、表示为:
87、
88、所述方法通过使用simd指令对数据进行并行计算,每个寄存器具有512bit位宽,float类型为32bit位宽,一次性只能处理16个数。
89、由此,本技术的优势在于:通过简单的方法,计算逻辑基于低比特,无需扩展到32bit位宽,节省寄存器空间,提高并行效率,减少计算指令,优化计算逻辑。
- 还没有人留言评论。精彩留言会获得点赞!