一种自动预测垃圾产出分布及规划最优运输路线的方法
1.本发明属于城市垃圾处理分布预测及最优路线规划领域,涉及一种自动预测垃圾产出分布及规划最优运输路线的方法。
背景技术:
2.近年来,随着经济快速发展,城市化进程加快,城市的规模变得越发庞大。与此同时,城市的垃圾产出呈现指数级增长的趋势,垃圾问题变得较为棘手。特别是对于大城市而言,垃圾大量产生的地方例如居住区,商业区等地区的位置均与城市垃圾处理站的距离较远。如果垃圾处理的问题不能得到解决,轻则影响人民的日常生活,重则带来污染环境,浪费资源等后果。而如果不仔细研究垃圾产出分布以及规划合适的运输路线,则垃圾运输成本会居高不下。并且,由于各种因素的影响,城市中的各个垃圾处理站的垃圾处理容量并不统一。
3.专利202010984181.1,公开了一种用于城市生活垃圾产量的预测方法,该方法从数据集中筛选有用的信息作为lstm神经网络的输入,以此预测城市的垃圾产量。然而,该专利仅考虑了垃圾产量的预测,并没有细致化考虑城市的垃圾产量分布并对其进行运输路线规划。本专利不仅对垃圾产量分布进行预测,而且规划了最优的垃圾运输路线,可以更好地帮助有关部门对垃圾进行管理。因此,急需一种自动预测垃圾产出,并且能够根据多个垃圾处理站的处理能力规划最优运输路线的方法为决策者提供建议。
技术实现要素:
4.发明目的:本发明的目的在于提供了一种自动预测垃圾产出分布及规划最优运输路线的方法,采用深度神经网络(dnn)构成的启发式神经网络预测城市各地区的垃圾产出分布,使用sinkhorn迭代方法计算出垃圾最优运输方法。
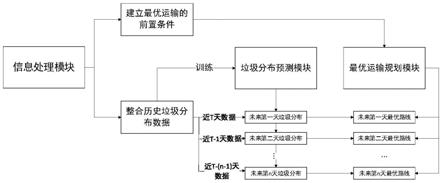
5.技术方案:本发明所述的一种自动预测垃圾产出分布及规划最优运输路线的方法,其具体操作步骤如下:
6.(1)、通过信息处理模块,整合历史垃圾分布数据并建立最优运输路线规划模块所必要的前置条件;
7.(2)、建立垃圾分布预测模块,将步骤(1)中整合完毕的历史垃圾分布数据作为训练集送入该模块中进行训练;
8.(3)、结合步骤(1)中通过前置条件建立的最优运输路线规划模块,通过步骤(2)中训练后的垃圾分布预测模块,对未来各地区的垃圾产出分布进行预测,随后使用最优运输规划模块计算得到最优运输路线。
9.进一步的,在步骤(1)中,所述建立最优运输路线规划模块所必要的前置条件具体包括:
10.一、将城市平均分为数个地区,确定包含垃圾处理站的地区,并计算各个地区到含有垃圾处理站的地区的运输代价,从而得到代价矩阵;
11.二、连接到城市当地的数据采集库,收集数据库中关于各个地区垃圾产出的数据,并根据垃圾处理站的每日处理量,最终得到垃圾最优运输的目标分布。
12.进一步的,在步骤(2)中,所述建立的垃圾分布预测模块是由深度神经网络组成。
13.进一步的,在步骤(2)中,所述将整合完毕的历史垃圾分布数据作为训练集送入建立的垃圾分布预测模块中进行训练具体是指:采用启发式学习方法对深度神经网络进行训练。
14.进一步的,在步骤(3)中,所述使用最优运输规划模块计算得到最优运输路线的必备条件是:以垃圾分布预测模块的输出作为预测分布,以各垃圾站的每日垃圾处理量作为目标分布,使用wasserstein距离度量预测分布与期望分布之间的差异,并使用sinkhorn迭代方法缩小该差异,最终得到差异的最小值和与之对应的最优运输路线。
15.有益效果:本发明与现有技术相比,本发明的特点是:本发明提出一种自动预测垃圾产出及规划最优运输路线的方法,首先将城市平均划分为多个地区,并获取每个地区的历史基础数据,包括垃圾每日产出分布,是否包含垃圾处理站,垃圾处理站的每日处理量等;其次构建启发式神经网络,预测未来每个地区的垃圾产出分布;最后,以神经网络得到的结果作为预测分布,以各个垃圾处理站的日处理量作为目标分布,以各地区的间隔距离作为代价矩阵,使用sinkhorn迭代方法计算最优运输路线。
附图说明
16.图1是本发明的操作流程图;
17.图2是本发明的代价矩阵计算示意图;
18.图3是本发明实施例中垃圾分布均差对比图;
19.图4是本发明实施例中运输代价对比图。
具体实施方式
20.为了更清楚地说明本发明的技术方案,下面结合附图对本发明的技术方案做进一步的详细说明:
21.本发明所述的一种自动预测垃圾产出分布及规划最优运输路线的方法,在本发明中包括有信息处理模块,垃圾分布预测模块与最优运输规划模块;
22.其具体操作步骤如下:
23.(1)、通过信息处理模块,整合历史垃圾分布数据并建立最优运输路线规划模块所必要的前置条件;
24.在步骤(1)中,所述建立最优运输路线规划模块所必要的前置条件主要包含两点:
25.一、将城市平均分为数个地区,确定包含垃圾处理站的地区,并计算各个地区到含有垃圾处理站的地区的运输代价,得到代价矩阵;代价矩阵可以通过以下方式得到:
26.使用正方形网格将城市覆盖,正方形边长为n,每个小格边长为1,其中一个小格即代表一个地区,因此该城市被划分为n2个地区;相邻的两个小格运输代价为1;设该城市的一个垃圾处理站位于地区(x
l
,y
l
)中,则任意地区(x0,y0)对于该垃圾处理站的运输代价cost
0l
可以表示为:
27.cost
0l
=|x
l-x0|+|y
l-y0|
28.假设该城市有m座垃圾处理站,每个地区对m个处理站均有各自的运输代价,可以组合为一个维度为(n2,m)的代价矩阵;
29.图2为一个示例,将城市平均划分为16个地区,某些地区中的黑点含义为该地区有垃圾处理站;以地区(a,a)为例,若要将垃圾分别送往(a,d),(d,a),(d,c),则对应的运输代价为3,3,5;以此类推,每个地区均包含前往三个垃圾站所对应的代价,因此可以组成一个维度为(16,3)的代价矩阵;
30.二、连接到城市当地的数据采集库,收集数据库中关于各个地区垃圾产出的数据,并根据垃圾处理站的每日处理量,得到垃圾最优运输的目标分布;
31.将收集到的各个地区垃圾产出的数据将垃圾处理站每日处理量求平均,得到每个处理站的垃圾处理量的期望值,将所有垃圾站的期望值组合起来,得到一个一维向量,作为垃圾最优运输的目标分布;
32.(2)、建立垃圾分布预测模块,将步骤(1)中整合完毕的历史垃圾分布数据作为训练集送入该模块中进行训练;
33.在步骤(2)中,所述垃圾分布预测模块由深度神经网络(dnn)组成。
34.在步骤(2)中,所述将整合完毕的历史垃圾分布数据作为训练集送入建立的垃圾分布预测模块中进行训练具体是指:采用启发式学习方法对深度神经网络进行训练;
35.具体的,将步骤(1)所获得的各地区垃圾产出输入垃圾分布预测模块,按照启发式学习方法进行训练,即将第一天至第t天的数据作为输入,第t+1天的数据作为目标进行训练;完成训练后,将第二天至第t+1天的数据作为输入,第t+2天的数据作为目标进行训练;以此类推;当历史数据的最后一天被作为目标,并完成训练之后,模块训练过程结束;其中dnn的参数设置如下所示:
36.a、神经网络层数:12(包含输入层和输出层);
37.b、隐藏层神经元个数:100;
38.c、最大迭代次数:50;
39.d、批量大小:32;
40.e、隐藏层激活函数:relu;
41.f、输出层激活函数:线性;
42.g、损失函数:均方误差(mse);
43.h、优化器:adam;
44.(3)、结合步骤(1)中通过前置条件建立的最优运输路线规划模块,通过步骤(2)中训练后的垃圾分布预测模块,对未来各地区的垃圾产出分布进行预测,随后使用最优运输规划模块计算得到最优运输路线。
45.在步骤(3)中,所述使用最优运输规划模块计算得到最优运输路线的必备条件是:以垃圾分布预测模块的输出作为预测分布,以各垃圾站的每日垃圾处理量作为目标分布,使用wasserstein距离度量预测分布与期望分布之间的差异,并使用sinkhorn迭代方法缩小该差异,最终得到差异的最小值和与之对应的最优运输路线;
46.具体的,首先将数据库中最近t天的数据作为输入垃圾分布预测模块,得到未来第一天的垃圾产出的预测分布;随后最小化wasserstein距离以求得预测分布与期望分布的最小代价转变方式(即垃圾运输的最优方法),其公式如下:
[0047][0048]
其中,p代表从预测分布p1转化到期望分布p2的所有方式,m为代价矩阵;最小化该距离等价于最小化:
[0049][0050]
该距离被称为sinkhorn距离,其中:
[0051][0052]
为p的信息熵矩阵;上述问题的最优解可以表示为:
[0053][0054]
其中αi,βj为要求的解的常数;
[0055]
具体的,sinkhorn迭代方法如下伪代码所示:
[0056]
给定:m,p1,p2,λ;(本例选择给定λ=5)
[0057]
初始化:p
λ
=exp-λm
;
[0058]
迭代次数达到5000次以前,重复:
[0059]
对于矩阵p
λ
,对行进行缩放,使得行总和与p1相等;
[0060]
对于矩阵p
λ
,对列进行缩放,使得列总和与p2相等;
[0061]
输出p
λ
;
[0062]
最终的输出矩阵p
λ
(n2,m)即为最优运输方法,其中的元素p
λij
表示第i个地区所应该输送给第j个垃圾处理站的垃圾所占总量的百分比。
[0063]
得到未来第一天的预测分布后,可以继续使用数据库中最近t-1天与未来第一天的数据作为输入,得到未来第二天的垃圾产出的预测分布,使用sinkhorn迭代方法得到未来第二天的最佳运输路线;以此类推,可以得到未来任意时间的垃圾产出分布与最佳运输路线。
[0064]
为了对垃圾预测分布进行性能验证,本发明在同一数据集上,使用多种预测方法进行对比,如线性回归预测方法、多项式回归预测方法;度量标准采用均方误差(mse),其公式如下:
[0065][0066]
其中,i为样本索引,n为样本总量,为模型对第i个样本的垃圾分布预测值,yi为第i个样本的真实垃圾分布。mse描述预测值与真实值的误差均值,因此mse越低说明模型预测结果越精准;测试结果如图3所示,本发明的预测方法获得了最低的mse值22.35%,说明该方法最适合用于垃圾分布的预测,而线性回归预测方法的mse值高达54.34%,说明该方法难以预测真实的垃圾分布;而多项式回归预测方法的mse值为34.68%,其误差仍然高于本发明方法;因此本发明所使用的启发式神经网络对垃圾分布的预测有良好的适用性。
[0067]
同时,为确认路径规划方案为最优,本发明选择将上述的三种垃圾分布预测方法
与三种不同的运输方案,即本发明运输方案、随机运输方案(即各地区的垃圾随机送往不同的垃圾站)与最近运输方案(即每个地区优先将垃圾送往最近的垃圾站)进行组合,使用计算运输代价的方式进行性能对比;由于同一种方案可能涉及多条运输路线,因此垃圾运输代价的计算公式如下:
[0068][0069]
其中,j为运输路线索引,m为运输路线总量,pj为第j条路线所运输的垃圾占总量的百分比,dj为第j条路线的运输距离;运输方案越合理,则方案所带来的运输代价越低;测试结果如图4所示;
[0070]
首先,本发明所提的自动预测垃圾产出分布及规划最优运输路线的方法获得了最小的运输代价1.56;其次,使用本发明的垃圾分布预测方法,在三种运输方案的搭配下,均获得了最低的运输代价,分别是1.56、3.24和2.33;再次,使用本发明的运输方案,在三种垃圾分布预测方法的搭配下,仍然获得了最低的运输代价,分别为1.56、3.67和1.97;因此,本发明所提的自动预测垃圾产出分布及规划最优运输路线的方法相比其他方法更具有优越性。
[0071]
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1