图像检测方法、装置、设备及存储介质与流程
1.本技术涉及计算机技术领域,涉及但不限于一种图像检测方法、装置、设备及存储介质。
背景技术:
2.图像检测作为计算机视觉的一个长期的、具有挑战性的问题,已经成为几十年来一个活跃的研究领域。图像检测的目的是在给定的图像中确定出是否存在目标对象,如果存在,则输出目标对象的空间位置。图像检测广泛应用在人工智能、信息技术等多个领域,例如交通监管、自动驾驶、人机交互、无人机、基于内容的图像检索、智能视频监控和增强现实等。
3.随着人工智能领域的发展,人们越来越追求人机交互体验的提升,现有的图像检测方法已经不能满足人们的需求。
技术实现要素:
4.有鉴于此,本技术实施例提供一种图像检测方法、装置、设备及存储介质。
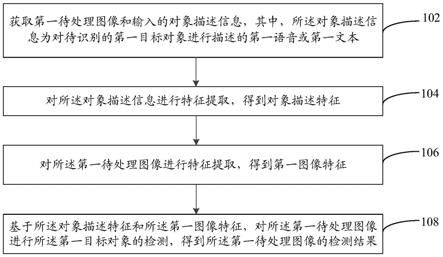
5.第一方面,本技术实施例提供一种图像检测方法,所述方法包括:获取第一待处理图像和输入的对象描述信息,其中,所述对象描述信息为对待识别的第一目标对象进行描述的第一语音或第一文本;对所述对象描述信息进行特征提取,得到对象描述特征;对所述第一待处理图像进行特征提取,得到第一图像特征;基于所述对象描述特征和所述第一图像特征,对所述第一待处理图像进行所述第一目标对象的检测,得到所述第一待处理图像的检测结果。
6.第二方面,本技术实施例提供一种图像检测模型训练方法,所述方法包括:获取图像样本集合和对象描述样本集合,其中,所述对象描述样本集合为对待识别的对象进行描述的语音样本集合或文本样本集合;利用所述图像样本集合和所述对象描述样本集合,对图像检测模型进行训练,得到所述图像样本集合中各图像样本的检测结果;基于各所述图像样本的检测结果,确定所述图像检测模型的损失;采用所述损失,对所述图像检测模型的网络参数进行调整,以使调整后的所述图像检测模型输出的检测结果的损失满足收敛条件。
7.第三方面,本技术实施例提供一种图像检测装置,所述装置包括:第一获取模块,用于获取第一待处理图像和输入的对象描述信息,其中,所述对象描述信息为对待识别的第一目标对象进行描述的第一语音或第一文本;第一提取模块,用于对所述对象描述信息进行特征提取,得到对象描述特征;第二提取模块,用于对所述第一待处理图像进行特征提取,得到第一图像特征;目标对象检测模块,用于基于所述对象描述特征和所述第一图像特征,对所述第一待处理图像进行所述第一目标对象的检测,得到所述第一待处理图像的检测结果。
8.第四方面,本技术实施例提供一种图像检测模型的训练装置,所述装置包括:第四
获取模块,用于获取图像样本集合和对象描述样本集合,其中,所述对象描述样本集合为对待识别的对象进行描述的语音样本集合或文本样本集合;第一训练模块,用于利用所述图像样本集合和所述对象描述样本集合,对图像检测模型进行训练,得到所述图像样本集合中各图像样本的检测结果;第二确定模块,用于基于各所述图像样本的检测结果,确定所述图像检测模型的损失;调整模块,用于采用所述损失,对所述图像检测模型的网络参数进行调整,以使调整后的所述图像检测模型输出的检测结果的损失满足收敛条件。
9.第五方面,本技术实施例提供一种电子设备,所述设备包括:存储器和处理器,所述存储器存储有可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述方法中的步骤。
10.第六方面,本技术实施例提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述方法中的步骤。
11.本技术实施例中,通过提取对象描述信息(第一语音或第一文本)的特征和第一待处理图像的特征,得到对象描述特征和第一图像特征,然后基于对象描述特征和第一图像特征,对第一待处理图像进行第一目标对象的检测,得到第一待处理图像的检测结果。即通过结合第一语音和第一待处理图像,或,第一文本和第一待处理图像,实现了在图像中检测目标对象,因此,可以广泛应用在人机交互的场景,利用文本或语音发出指令,在图像中检测目标对象,增加人机交互的趣味性;同时,在对象描述信息为第一语音的情况下,由于语音在效率、可访问性和可适用性方面的优势,使得操作更加方便高效,使用人群更广,应用场景更多,更加有助于提升实际应用中的人机交互体验。
附图说明
12.图1a为本技术实施例提供的一种图像检测系统的架构示意图;
13.图1b为本技术实施例提供的一种图像检测方法的流程示意图;
14.图2a为本技术实施例提供的另一种图像检测方法的流程示意图;
15.图2b为本技术实施例提供的不同跟踪方法的示意图;
16.图3a和图3b为本技术实施例提供的一种目标跟踪方法的流程示意图;
17.图4为本技术实施例提供的lasot和tnl2k两大数据库中不同语音时长对应的语音文件的数量和比例的柱状图和扇形图;
18.图5为本技术实施例提供的不同模型的成功分数和精度分数图;
19.图6为本技术实施例提供的一种图像检测装置的结构示意图;
20.图7为本技术实施例提供的一种图像检测模型的训练装置的结构示意图;
21.图8为本技术实施例电子设备的一种硬件实体示意图。
具体实施方式
22.下面结合附图和实施例对本技术的技术方案进一步详细阐述。显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。基于本技术的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本技术保护的范围。
23.在以下的描述中,涉及到“一些实施例”,其描述了所有可能实施例的子集,但是可
以理解,“一些实施例”可以是所有可能实施例的相同子集或不同子集,并且可以在不冲突的情况下相互结合。
24.在后续的描述中,使用用于表示元件的诸如“模块”、“部件”或“单元”的后缀仅为了有利于本技术的说明,其本身没有特定的意义。因此,“模块”、“部件”或“单元”可以混合地使用。
25.需要指出,本技术实施例所涉及的术语“第一\第二\第三”仅仅是是区别类似的对象,不代表针对对象的特定排序,可以理解地,“第一\第二\第三”在允许的情况下可以互换特定的顺序或先后次序,以使这里描述的本技术实施例能够以除了在这里图示或描述的以外的顺序实施。
26.本技术实施例提供一种图像检测方法,应用于电子设备。所述电子设备包括但不限于手机、笔记本电脑、平板电脑、掌上上网设备、多媒体设备、流媒体设备、移动互联网设备、无人机、机器人或其他类型的电子设备。该方法所实现的功能可以通过电子设备中的处理器调用程序代码来实现,当然程序代码可以保存在计算机存储介质中,可见,该电子设备至少包括处理器和存储介质。处理器可以用于进行图像检测,存储器可以用于存储进行图像检测过程中需要的数据以及产生的数据。
27.图1a为本技术实施例一种图像检测系统10的一个可选的架构示意图,参见图1a,在一些实施例中,图像采集装置100可以将图像集合发送到服务器200,通过服务器200传输给电子设备300,由电子设备300执行图像检测;在一些实施例中,图像采集装置100可以直接将图像集合传输给电子设备300进行图像检测;在一些实施例中,电子设备300可以利用本地存储的图像集合进行图像检测。
28.在一些实施例中,服务器200可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、内容分发网络(content delivery network,cdn)、以及大数据和人工智能平台等基础云计算服务的云服务器。图像采集装置、电子设备以及服务器可以通过有线或无线通信方式直接或间接地连接,本技术实施例不做限定。下面将说明电子设备300的示例性应用。
29.本技术实施例提供一种图像检测方法,如图1b所示,所述方法包括:
30.步骤102:获取第一待处理图像和输入的对象描述信息,其中,所述对象描述信息为对待识别的第一目标对象进行描述的第一语音或第一文本;
31.这里,第一待处理图像可以为图像集合中的某一图像,其中,图像集合可以为图像文件夹中的至少两个图像,也可以为图像序列,即具有时序的图像,例如视频帧。
32.在一些实现方式中,该图像集合可以为电子设备上设置的图像采集装置,如摄像头模组实时采集的图像;在另一些实现方式中,该图像集合可以为其他设备通过即时通信的方式传输给电子设备的需要进行图像检测的图像;在一些实现方式中,该图像集合也可以是电子设备响应于任务处理指令,调用本地相册并从中获取的图像集合,对此本技术实施例不做限定。
33.这里,对象描述信息为输入的对象描述信息,体现了所述图像检测方法为端到端的图像检测方法。对象描述信息为对待识别的第一目标对象的描述,例如第一目标对象的类别(人、车、鸟等)、属性(红色、长头发等)等,用于识别出第一目标对象,描述的方式可以
为语音或文本,例如待识别的第一目标对象为一只鸟,则语音可以为“一只鸟”的第一语音,文本可以为“一只鸟”的第一文本。
34.对象描述信息可以通过人工语音输入,也可以通过即时通信的方式输入给电子设备,还可以通过电子设备响应于任务处理指令,调用本地的文本或语音。
35.在一些实施例中,步骤102中获取输入的对象描述信息的实施可以包括:例如,获取输入的语音或文本,基于预设的第一关键词确定输入的语音或文本为第一语音或第一文本,其中,预设的第一关键词可以根据目标对象的类别进行设定,例如,需要识别的目标对象为动物,则预设的第一关键词可以为动物类别,例如小鸟、小狗等,若输入的语音或文本为小鸟,则输入的语音或文本为第一语音或第一文本;预设的第一关键词还可以根据目的进行设定,例如,需要对目标对象进行检测,则预设的第一关键词可以为检测,若输入的语音或文本中包含检测时,则输入的语音或文本为第一语音或第一文本。又例如,还可以设置触发按钮或触发词,通过先按触发按钮或说出触发词例如“小溪小溪”等,来触发对第一语音或第一文本的识别,再输入第一语音或第一文本,从而分辨出输入的语音或文本为第一语音或第一文本。
36.步骤104:对所述对象描述信息进行特征提取,得到对象描述特征;
37.这里,步骤104用于通过网络模型提取对象描述信息的特征,将对象描述信息转化为包含对象描述信息特征的向量形式,方便后续的运算。
38.在一些实施例中,在对象描述信息为第一语音的情况下,可以采用wav2vec2网络模型进行特征提取,得到第一语音特征;
39.在对象描述信息为第一文本的情况下,可以采用bert网络模型进行特征提取,得到第一文本特征;本技术实施例对提取第一语音特征和第一文本特征的网络模型不做限定。
40.步骤106:对所述第一待处理图像进行特征提取,得到第一图像特征;
41.这里,步骤106用于通过网络模型提取第一待处理图像的特征,将第一待处理图像转化为包含第一待处理图像特征的向量形式,方便后续的运算。
42.在一些实施例中,步骤106的实施可以采用resnet34、resnet50、resnet101或resnet152等残差网络模型对第一待处理图像进行特征提取,得到第一图像特征,本技术实施例对提取第一图像特征的网络模型不做限定。
43.步骤108:基于所述对象描述特征和所述第一图像特征,对所述第一待处理图像进行所述第一目标对象的检测,得到所述第一待处理图像的检测结果。
44.这里,检测结果表征检测到或未检测到第一目标对象,在检测结果表征检测到第一目标对象的情况下,检测结果中包含第一目标对象的位置信息,位置信息可以由第一目标对象所在区域的左上角点坐标和右下角点坐标组成,例如(x1,y1,x2,y2),其中,(x1,y1)为左上角点坐标,(x2,y2)为右下角点坐标。
45.步骤108实施时,可以先将对象描述特征和第一图像特征融合为一个特征,再输入transformer模型,通过transformer模型融合对象描述特征和第一图像特征,最后通过检测头实现对第一目标对象的检测和定位。其中,transformer模型是在2017年提出的一种nlp(natural language processing,自然语言处理)经典模型,transformer模型使用了自注意力(self-attention)机制,transformer模型包括编码器和解码器,编码器包括自注意
力层,解码器包括自注意力层和交叉注意力层,通过transformer模型的自注意力机制,可实现对对象描述特征和第一图像特征的融合,并将更多的注意力放在第一目标对象上,再通过检测头检测第一目标对象的位置信息。
46.在一些实施例中,步骤108的实施可以包括:
47.步骤1081:融合所述对象描述特征和第二图像特征,得到第一融合特征,其中,所述第二图像特征包括第一图像特征;
48.这里,为了融合对象描述特征和第二图像特征,得到第一融合特征,步骤1081的实施可以先将对象描述特征和第二图像特征转化为维度数量相同、且最多有一个维度的维数不同的特征,然后将具有维度数量相同且最多有一个维度的维数不同的两个特征连接,得到第一融合特征。
49.下面以第二图像特征即第一图像特征的维度为wg/s
×
hg/s
×
c1,对象描述特征(例如:第一语音特征)的维度为ns
×
c2为例进行说明,其中,第二图像特征为第一待处理图像通过resnet网络模型提取特征之后得到的特征,第一语音特征为对象描述信息为第一语音时,通过wav2vec2网络模型进行特征提取后得到的特征。第二图像特征的维度数量为3,第一语音特征的维度数量为2,为了使第二图像特征的维度数量与第一语音特征的维度数量相同,在一些实施例中,可以将第二图像特征的宽度维度和高度维度展平为一个维度,即为wg/s*hg/s
×
c1,从而将第二图像特征的维度数量从3转变为2,使得第二图像特征的维度数量与第一语音特征的维度数量相同;为了使第二图像特征与第一语音特征最多有一个维度的维数不同,在一些实施例中,可以将具有维度数量相同的第一语音特征的通道维度c2和第二图像特征的通道维度c1都转化为cei,其中,cei可以等于c1、c2或其他数,即第二图像特征的维度为wg/s*hg/s
×
cei,第一语音特征的维度为ns
×
cei,从而得到只有一个维度的维数不同的第二图像特征与第一语音特征;然后连接具有维度数量相同且只有一个维度的维数不同的第一语音特征和第二图像特征,得到维度为(ns+wg/s*hg/s)
×
cei的第一融合特征。
50.在一些实施例中,步骤1081的实施也可以先将对象描述特征的通道维度和第二图像特征的通道维度转化成相同的维数,再将第二图像特征的宽度维度和高度维度展平为一个维度,从而得到维度数量相同且最多有一个维度的维数不同的对象描述特征和第二图像特征。
51.需要说明的是,融合对象描述特征和第二图像特征的方法需要根据对象描述信息和第一待处理图像提取特征的网络模型而定,例如,对象描述信息和第一待处理图像经过网络模型提取特征后的维度数量都是3,则可以将对象描述特征和第二图像特征都通过展平的方法得到两个维度,再将其中一个维度的维数转变成相同的维数,连接后得到第一融合特征;又例如,对象描述信息和第一待处理图像经过网络模型提取特征后的维度数量都是2,则不需要展平,直接将其中一个维度的维数转变成相同的维数,连接后得到第一融合特征。
52.步骤1082:基于所述第一融合特征,确定所述第一待处理图像的检测结果。
53.在一些实施例中,步骤1082的实施可以包括:
54.步骤1821:通过第一编码器对所述第一融合特征进行编码处理,得到融合所述对象描述特征和所述第二图像特征的第一编码特征;
55.这里,第一编码器为transformer模型中的编码器,用于利用第一编码器中的自注意力层,实现对象描述特征和第二图像特征的融合,得到第一编码特征。
56.步骤1822:通过第一解码器对所述第一编码特征进行解码处理,得到融合所述对象描述特征和所述第二图像特征的第一解码特征;
57.这里,第一解码器为transformer模型中的解码器,用于利用第一解码器中的自注意力层和交叉注意力层,进一步实现对象描述特征和第二图像特征的融合,得到第一解码特征。
58.步骤1823:通过第一检测头基于所述第一编码特征和所述第一解码特征实现对所述第一目标对象的定位,得到所述第一待处理图像的检测结果。
59.这里,第一检测头通过融合第一编码特征和第一解码特征,并对融合后的第一编码特征和第一解码特征运算,得到第一目标对象的左上角点概率图和右下角点概率图,分别在左上角点概率图和右下角点概率图中确定大于阈值的最大值,若存在大于阈值的最大值,则第一待处理图像中存在第一目标对象,即检测结果表征检测到第一目标对象,同时,将大于阈值的最大值所在的位置分别确定为第一目标对象的左上角点坐标和右下角点坐标;若不存在大于阈值的数值,则第一待处理图像中不存在第一目标对象,检测结果表征未检测到第一目标对象。
60.在对象描述信息为第一文本的情况下,步骤108的实施可以包括:基于第一文本特征和第一图像特征,对所述第一待处理图像进行所述第一目标对象的检测,得到所述第一待处理图像的检测结果。则在对象描述信息为第一文本的情况下可以广泛应用在人机交互的场景中,例如对于视频分类,可以通过文本说明类别,要求将视频按照类别进行分类,则可以在视频中识别出不同类别后,对视频进行分类;又例如在多个图像中找出目标,可以通过文本说明目标,则在多个图像中识别出目标后,输出目标所在的图像。
61.在对象描述信息为第一语音的情况下,步骤108的实施可以包括:基于第一语音特征和第一图像特征,对所述第一待处理图像进行所述第一目标对象的检测,得到所述第一待处理图像的检测结果。则在对象描述信息为第一语音的情况下,也可以广泛应用在人机交互的场景,例如对于自动驾驶,可以通过语音发出指令,要求车辆跟踪前方的小鸟,则可以在车辆采集的前方图像中识别出小鸟后,控制车辆跟踪小鸟。又例如对于智能视频监控,可以通过语音发出指令,要求在监控视频中找出目标人物,则可以在监控视频中识别出目标人物之后,输出目标人物所在图像。
62.由于语音相比于文本,在效率、可访问性和可适用性方面,都具有无法比拟的优势,其中,在效率方面,人类说话的速度约为每分钟150字,而打字的速度仅为每分钟40字;在可访问性方面,人类从婴儿就可以讲话,但认字或者打字需要后天的训练,世界上仍有约14%的文盲人口,这部分人是无法打字的;在可适用性方面,一个麦克风相比于一个打字设备(键盘或者触摸屏)要更小更便宜,而且当手被占用时,如在开车的时候,人无法打字。因此,当对象描述信息为第一语音时,可以使得操作更加方便高效,使用人群更广,应用场景更多,更有助于提升实际应用中的人机交互体验。
63.本技术实施例中,通过提取对象描述信息(第一语音或第一文本)的特征和第一待处理图像的特征,得到对象描述特征和第一图像特征,然后基于对象描述特征和第一图像特征,对第一待处理图像进行第一目标对象的检测,得到第一待处理图像的检测结果。即通
过结合第一语音和第一待处理图像,或,第一文本和第一待处理图像,实现了在图像中检测目标对象,因此,可以广泛应用在人机交互的场景,利用文本或语音发出指令,在图像中检测目标对象,增加人机交互的趣味性;同时,在对象描述信息为第一语音的情况下,由于语音在效率、可访问性和可适用性方面的优势,使得操作更加方便高效,使用人群更广,应用场景更多,更加有助于提升实际应用中的人机交互体验。
64.在一些实施例中,步骤108之后,还可以包括:
65.步骤110a:获取第二语音;
66.步骤112a:在所述第二语音包括预设的第一关键词的情况下,对所述第二语音进行特征提取,得到第二语音特征;
67.这里,步骤110a和步骤112a可参见步骤102。
68.在第二语音包括预设的第一关键词的情况下,可以判断第二语音为第二目标对象的语音,即在完成第一目标对象的检测之后,进行第二目标对象的检测。
69.步骤114a:获取第二待处理图像;
70.这里,步骤114a可参见步骤102。
71.步骤116a:对所述第二待处理图像进行特征提取,得到第三图像特征;
72.步骤118a:基于所述第二语音特征和所述第三图像特征,对所述第二待处理图像进行第二目标对象的检测,得到所述第二待处理图像的检测结果。
73.这里,步骤116a和步骤118a可参见步骤106和步骤108。
74.本技术实施例中,在获取第二语音的情况下,通过判断第二语音的类别,确定第二语音是否为需要检测的第二目标对象,来实现在完成第一目标对象的检测之后,对第二目标对象进行检测。
75.在一些实施例中,步骤108之后,还可以包括:
76.步骤110b:获取第二语音;
77.这里,步骤110b可参见步骤102。
78.步骤112b:在所述第二语音包括预设的第二关键词的情况下,确定所述第二语音为纠正语音;
79.这里,纠正语音为用于纠正第一待处理图像检测结果中第一目标对象位置信息的大小和方位的语音,例如:“向右向下”。预设的第二关键词可以为表示方向和大小的词,例如“上下左右大小宽窄长短”。在第二语音包括预设的第二关键词的情况下,则第二语音为纠正语音,例如,第二语音为“向左向上”,其中包括“左和上”,则第二语音为纠正语音。
80.表1-1中显示了纠正语音中位置的说明,表1-2中显示了纠正语音中大小的说明。
81.表1-1
[0082][0083]
表1-2
[0084]
[0085]
在一些实施例中,纠正语音可以结合表1-1中的位置说明和表1-2中的大小说明,例如“向右移动且变小一些”[0086]
步骤114b:至少基于所述纠正语音,在所述第一待处理图像中更新所述第一目标对象的位置信息。
[0087]
在一些实施例中,步骤114b的实施可以包括:
[0088]
步骤1141:基于所述纠正语音,确定纠正卷积核;
[0089]
在一些实施例中,步骤1141的实施可以包括步骤141a至步骤141c:
[0090]
步骤141a:提取所述纠正语音的纠正语音特征;
[0091]
这里,步骤141a用于通过网络模型提取纠正语音的特征,将纠正语音转化为包含纠正语音特征的向量形式,方便后续的运算。
[0092]
在一些实施例中,可以采用wav2vec2网络模型进行特征提取,得到纠正语音特征,本技术实施例对提取纠正语音特征的网络模型不做限定。
[0093]
步骤141b:通过第二编码器对所述纠正语音特征进行编码,得到第二编码特征;
[0094]
步骤141c:通过第二解码器对所述第二编码特征进行解码,得到所述纠正语音卷积核。
[0095]
这里,步骤141b和步骤141c可参见步骤1821和步骤1822。
[0096]
其中,纠正语音卷积核为后续卷积操作的卷积核。在一些实施例中,在通过第二解码器对第二编码特征进行解码得到解码特征之后,可以通过维度变换方式改变所述解码特征的维度,以得到用于后续卷积操作的纠正语音卷积核。
[0097]
步骤1142:基于所述第一目标对象在所述第一待处理图像中的位置信息和所述第一待处理图像,确定目标掩膜图;
[0098]
这里,目标掩膜图为包含目标对象位置信息的掩膜图。
[0099]
在一些实施例中,步骤1142的实施可以包括步骤142a和步骤142b:
[0100]
步骤142a:基于所述第一目标对象在所述第一待处理图像中的位置信息和所述第一待处理图像,将所述第一待处理图像生成二值图;
[0101]
这里,在后续卷积操作中,为了降低第一待处理图像中第一目标对象之外的图像对第一目标对象位置信息的影响,可以将第一待处理图像生成二值图。
[0102]
实施时,可以基于第一目标对象在第一待处理图像中的位置信息,将第一目标对象所在的区域设置为1,第一待处理图像中的其他区域设置为0,从而将第一待处理图像生成二值图。
[0103]
步骤142b:基于所述第一待处理图像的第一图像特征的通道维度,沿着通道维度方向复制m份所述二值图,得到所述目标掩膜图。
[0104]
这里,由于二值图通道维度的数量为1,为了在后续卷积操作中,增大第一待处理图像中第一目标对象位置信息的影响力,可以将二值图复制m份,其中,m可以为第一待处理图像的第一图像特征的通道维度的维数;也可以为第一待处理图像的第一图像特征的通道维度维数附近的数字,例如,m-1,m+1等。
[0105]
在一些实施例中,若截取第一待处理图像的部分图像区域进行特征提取,则步骤142b的实施可以包括:基于图像区域特征的通道维度,沿着通道维度方向复制m份所述二值图,得到所述目标掩膜图
[0106]
步骤1143:基于所述纠正卷积核、所述目标掩膜图和所述第一待处理图像的第一图像特征,在所述第一待处理图像中更新所述第一目标对象的位置信息。
[0107]
在一些实施例中,若截取第一待处理图像的部分图像区域进行特征提取,则步骤1143的实施可以包括:基于所述纠正卷积核、所述目标掩膜图和图像区域特征,在所述第一待处理图像中更新所述第一目标对象的位置信息。
[0108]
在一些实施例中,步骤1143的实施可以包括步骤143a至步骤143c:
[0109]
步骤143a:融合所述目标掩膜图和所述第一待处理图像的第一图像特征,得到第二融合特征;
[0110]
这里,在目标掩膜图和第一图像特征的维度数量相同,且宽度维度和高度维度的维数相同的情况下,步骤143a的实施可以为:直接连接目标掩膜图和第一待处理图像的第一图像特征,得到第二融合特征。
[0111]
在目标掩膜图和第一图像特征的维度数量不同、且宽度维度和高度维度的维数不同的情况下,步骤143a的实施可以为:先通过维度变换方法,使目标掩膜图和第一图像特征的维度数量相同、且宽度维度和高度维度的维数相同,再通过连接得到第二融合特征。
[0112]
步骤143b:利用所述纠正语音卷积核,对所述第二融合特征进行卷积操作,得到第三融合特征;
[0113]
这里,通过利用纠正语音卷积核,对第二融合特征进行卷积操作,使得纠正语音卷积核中的位置和大小的变化信息融入第二融合特征中,得到第三融合特征。
[0114]
步骤143c:通过第二检测头基于所述第三融合特征,在所述第一待处理图像中更新所述第一目标对象的位置信息。
[0115]
这里,步骤143c可参见步骤1823。
[0116]
由于第三融合特征中融入了纠正语音卷积核中的位置和大小的变化信息,因此,通过第二检测头对第三融合特征的进行运算处理之后,可以得到包含纠正语音卷积核中的位置和大小变化信息的更新后的第一目标对象的位置信息,以实现在第一待处理图像中更新第一目标对象的位置信息。
[0117]
本技术实施例中,在得到第一待处理图像的检测结果之后,通过获取纠正语音,并基于纠正卷积核、目标掩膜图和第一待处理图像的第一图像特征,实现在第一待处理图像中更新第一目标对象的位置信息,以提高第一目标对象位置信息的准确度。
[0118]
在第一对象描述信息为第一语音,第一待处理图像为图像集合中的每一图像的情况下,本技术实施例还提供一种图像检测方法,所述方法包括:
[0119]
步骤202:获取图像集合中的每一图像和输入的第一语音,其中,所述第一语音为对待识别的第一目标对象的描述。
[0120]
这里,图像集合可以为以下之一:图像文件夹中的至少两个图像;图像序列;
[0121]
步骤204:对所述第一语音进行特征提取,得到第一语音特征;
[0122]
步骤206:对所述图像集合中的每一图像进行特征提取,得到每一图像特征;
[0123]
这里,步骤202至步骤206可参见步骤102至步骤106;
[0124]
步骤208:基于所述第一语音特征和所述每一图像特征,对所述图像集合中的每一图像进行所述第一目标对象的检测,获取并记录所述图像集合中每一图像的检测结果,得到记录结果;其中,所述检测结果表征检测到或未检测到所述第一目标对象;
[0125]
这里,步骤208可参见步骤108,步骤208相比于步骤108的区别在于,步骤208需要获取图像集合中的每一图像的检测结果。
[0126]
步骤210:至少输出所述记录结果。
[0127]
本技术实施例中,通过获取图像集合中的每一图像的检测结果,实现在图像集合中检测出存在目标对象的图像,并输出,从而提升实际应用中的人机交互体验。
[0128]
在对象描述信息为第一语音的情况下,本技术实施例还提供一种图像检测方法,所述方法包括:
[0129]
步骤302:获取第一待处理图像和输入的第一语音,其中,所述第一语音为对待识别的第一目标对象的描述;
[0130]
这里,步骤302可参见步骤102。
[0131]
步骤304:将所述第一语音转化成第二文本;
[0132]
这里,步骤304的实施可以通过语音识别的网络模型例如transformer、conformer等将第一语音转化成第二文本,本技术实施例对将第一语音转化成第二文本的网络模型不做限定。
[0133]
步骤306:对所述第二文本进行特征提取,得到第二文本特征;
[0134]
步骤308:对所述第一待处理图像进行特征提取,得到第一图像特征;
[0135]
步骤310:基于所述第二文本特征和所述第一图像特征,对所述第一待处理图像进行所述第一目标对象的检测,得到所述第一待处理图像的检测结果。
[0136]
这里,步骤306至步骤310可参见步骤104至步骤108。
[0137]
本技术实施例中,通过将第一语音转化为第二文本,再基于第二文本和第一待处理图像,得到第一待处理图像的检测结果,为图像检测提供了一种新的方法。
[0138]
在第一待处理图像为图像序列中的第i帧图像,对象描述信息为第一语音的情况下,本技术实施例还提供一种图像检测方法,如图2a所示,所述方法包括:
[0139]
步骤402:获取第i帧图像和输入的第一语音,其中,第一语音为对待识别的第一目标对象的描述;
[0140]
步骤404:对所述第一语音进行特征提取,得到第一语音特征;
[0141]
步骤406:对所述第i帧图像进行特征提取,得到第i帧图像特征;
[0142]
步骤408:基于所述第i帧图像特征和所述第一语音特征,对所述第i帧图像进行所述第一目标对象的检测,得到所述第i帧图像的检测结果。
[0143]
这里,步骤402至步骤408可参见步骤102至步骤108。
[0144]
在步骤408之后,所述方法还包括步骤410a或410b:
[0145]
步骤410a:对所述第i+1帧图像进行特征提取,得到第i+1帧图像特征;基于所述第i+1帧图像特征和第一语音特征,对所述第i+1帧图像进行所述第一目标对象的跟踪;
[0146]
即在得到第i帧图像的检测结果之后,对第i+1帧图像进行第一目标对象的跟踪。
[0147]
图2b为不同跟踪方法的示意图,如图2b所示,传统的视觉跟踪方法(即图2b中的图(a)),需要在第一帧图像中标注出目标对象的真值框,从第二帧开始跟踪。相比于传统的视觉跟踪方法,本技术实施例提供的方法(即图2b中的图(b)和图(c),其中,图(b)为对象描述信息为第一文本时对应的方法,图(c)为对象描述信息为第一语音时对应的方法),不依赖于第一帧图像的目标对象的真值框的标注,可以直接对目标对象进行跟踪,同时,在采用语
音与图像结合的方式,进行目标对象的跟踪的情况下,由于语音在效率,可访问性和可适用性方面的优势,使得操作更加方便高效,使用人群更广,应用场景更多,更加有助于提升实际应用中的人机交互体验。
[0148]
步骤410b:在所述第i帧图像的检测结果表征检测到所述第一目标对象的情况下,基于所述第i帧图像的检测结果中的所述第一目标对象的位置信息,对所述第i+1帧图像进行所述第一目标对象的跟踪。
[0149]
在一些实施例中,步骤410b的实施可以包括步骤41b1至步骤41b3:
[0150]
步骤41b1:基于所述第i帧图像的检测结果中的所述第一目标对象的位置信息,在所述第i+1帧图像中确定出第i+1帧图像区域,将所述第i+1帧图像区域作为待处理区域;
[0151]
这里,待处理区域即为第i+1帧图像中的一部分。
[0152]
在一些实施例中,步骤41b1的实施可以包括步骤4111和步骤4112:
[0153]
步骤4111:获取所述第i帧图像的检测结果中的所述第一目标对象的位置信息所在的预测区域的中心位置;
[0154]
例如:第一目标对象的位置信息为(x1,y1,x2,y2),则中心位置为((x1+x2)/2,(y1+y2)/2)。
[0155]
在一些实施例中,若在获取第一目标对象的位置信息之后,对第一目标对象的位置信息进行了更新,则步骤4111的实施还可以包括:获取所述第i帧图像更新后的第一目标对象的位置信息所在的预测区域的中心位置,则后续以更新后的第一目标对象的位置信息所在的预测区域的中心位置中心,得到所述第i+1帧图像区域。
[0156]
步骤4112:以所述中心位置为中心,在所述第i+1帧图像中截取所述预测区域的n倍区域,得到所述第i+1帧图像区域,将所述第i+1帧图像区域作为待处理区域;。
[0157]
其中,n可以根据电子设备的计算能力进行设定,若电子设备的计算能力较大,则n可以取较大的数值;若电子设备的计算能力较小,则n可以取较小的数值。实施时,可以以中心位置为中心,使预测区域的长边和短边扩大相同的倍数,得到第i+1帧图像区域,也可以以中心位置为中心,使预测区域的长边和短边扩大不同的倍数,得到第i+1帧图像区域。在一些实施例中,n可以为4。
[0158]
这里,第i帧可以为任意一帧,若第i帧为第1帧时,则只有第1帧图像采用的是整张图进行图像检测,从第2帧图像开始采用的是第2帧图像区域进行图像检测。若第i帧为第2帧时,则只有前两帧图像采用的是整张图进行图像检测,从第3帧图像开始采用的是第3帧图像区域进行图像检测。相比于采用整张图进行图像检测的方法,采用待处理区域进行图像检测,可以减少计算量。
[0159]
步骤41b2:对所述待处理区域进行特征提取,得到待处理区域特征;
[0160]
这里,步骤41b2可参见步骤106。
[0161]
步骤41b3:基于所述待处理区域特征和所述第一语音特征,对所述第i+1帧图像进行所述第一目标对象的跟踪。
[0162]
这里,步骤41b3可参见步骤108(包括步骤1081和步骤1082)。
[0163]
其中,在步骤1081中,所述第二图像特征还包括待处理区域特征。即步骤1081的实施可以为:融合所述对象描述特征和待处理区域特征,得到第一融合特征。
[0164]
在一些实施例中,在第二图像特征为第一图像特征和待处理区域特征时,采用的
编码器、解码器和检测头可以相同,也可以不同,本技术实施例对此不做限定。
[0165]
本技术实施例中,通过基于第i帧图像的检测结果中的第一目标对象的位置信息,在第i+1帧图像中确定出第i+1帧图像区域,再利用第i+1帧图像区域进行图像检测,实现对第i+1帧图像进行第一目标对象的跟踪,相比于采用整张图进行第一目标对象跟踪的方法,可以减少计算量。
[0166]
本技术实施例提供一种目标跟踪方法,如图3a和图3b所示,所述方法包括:
[0167]
第一部分:获取第t1帧图像(即第一待处理图像)和第一语音,其中,所述第一语音为对待识别的第一目标对象的描述;对所述第一语音采用wav2vec2网络模型进行特征提取,得到第一语音特征101(即对象描述特征);对所述第t1帧图像采用resnet50网络模型进行特征提取,得到第t1帧图像特征102(即第一图像特征);
[0168]
这里,第一部分可参见步骤102至步骤106。
[0169]
第二部分:融合所述第一语音特征和所述第t1帧图像特征,得到第三融合特征103(即第一融合特征);
[0170]
这里,第二部分可参见步骤1081。
[0171]
第三部分:通过第一编码器对所述第三融合特征进行编码处理,得到融合所述第一语音特征和所述第t1帧图像特征的第三编码特征104(即第一编码特征);通过第一解码器对所述第三编码特征进行解码处理,得到融合所述第一语音特征和所述第t1帧图像特征的第三解码特征(即第一解码特征);通过第一检测头基于所述第三编码特征和所述第三解码特征实现对所述第一目标对象的定位,得到所述第t1帧图像的检测结果;
[0172]
这里,第三部分可参见步骤1821至步骤1823。
[0173]
第四部分:获取所述第ti帧图像的检测结果中的所述第一目标对象的位置信息所在的预测区域的中心位置,其中,i为大于等于1的整数,当i等于1时,第ti帧为第t1帧;以所述中心位置为中心,在所述第t
i+1
帧图像中截取所述预测区域的n倍区域,得到所述第t
i+1
帧图像区域,将所述第t
i+1
帧图像区域作为待处理区域;
[0174]
这里,第四部分可参见步骤4111和步骤4112。
[0175]
第五部分:对所述待处理区域进行特征提取,得到待处理区域特征105;
[0176]
这里,第五部分可参见步骤41b2。
[0177]
第六部分:融合所述第一语音特征和待处理区域特征,得到第四融合特征106(即第一融合特征);通过第三编码器对所述第四融合特征进行编码处理,得到融合所述第一语音特征和待处理区域特征的第四编码特征107(即第一编码特征);通过第三解码器对所述第三编码特征进行解码处理,得到融合所述第一语音特征和待处理区域特征的第四解码特征(即第一解码特征);通过第三检测头基于所述第四编码特征和所述第四解码特征实现对所述第一目标对象的定位,得到第t
i+1
帧图像的检测结果;
[0178]
这里,第六部分可参见步骤1081、步骤1821至步骤1823。
[0179]
第七部分:获取第二语音;在所述第二语音包括预设的第二关键词的情况下,确定所述第二语音为纠正语音;
[0180]
这里,第七部分可参见步骤110b和步骤112b。
[0181]
第八部分:提取所述纠正语音的纠正语音特征;通过第二编码器对所述纠正语音特征进行编码,得到第二编码特征;通过第二解码器对所述第二编码特征进行解码,得到所
述纠正语音卷积核。
[0182]
这里,第八部分可参见步骤141a至步骤141c。
[0183]
第九部分:基于所述第一目标对象在所述第一待处理图像中的位置信息和所述第一待处理图像,将所述第一待处理图像生成二值图108;基于所述待处理区域特征的通道维度,沿着通道维度方向复制m份所述二值图,得到所述目标掩膜图。
[0184]
这里,第九部分可参见步骤142a和步骤142b。
[0185]
第十部分:融合所述目标掩膜图和所述待处理区域特征,得到第二融合特征109;利用所述纠正语音卷积核,对所述第二融合特征进行卷积操作,得到第三融合特征;通过第二检测头基于所述第三融合特征,在所述第一待处理图像中更新所述第一目标对象的位置信息,包括更新后的左上角点坐标110和更新后的右下角点坐标111。
[0186]
这里,第十部分可参见步骤143a至步骤143c。
[0187]
本技术实施例中,第一方面,通过将语音与图像结合的方式,实现了对第一目标对象的跟踪,相比于传统的视觉跟踪方法,不需要在第一帧图像中标注出目标对象的真值框,使得操作更方便,同时,由于语音在效率,可访问性和可适用性方面的优势,使得操作更加方便高效,使用人群更广,应用场景更多,更加有助于提升实际应用中的人机交互体验;第二方面,通过采用第ti帧图像的检测结果中的第一目标对象的位置信息,确定第t
i+1
帧图像区域,然后利用第t
i+1
帧图像区域,对第t
i+1
帧图像进行第一目标对象的跟踪,可以减少计算量;第三方面,通过引入纠正语音,更新第一目标对象的位置信息,使得结果更加准确,提高了跟踪的准确度。
[0188]
本技术实施例提供一种图像检测模型训练方法,所述方法包括:
[0189]
步骤602:获取图像样本集合和对象描述样本集合,其中,所述对象描述样本集合为对待识别的对象进行描述的语音样本集合或文本样本集合;
[0190]
在一些实施例中,图像样本集合可以来自lasot和tnl2k两大数据库。在对象描述样本集合为文本样本集合的情况下,对象描述样本集合也可以来自lasot和tnl2k两大数据库;在对象描述样本集合为语音样本集合的情况下,可以通过对lasot和tnl2k两大数据库人工语音标注的方式得到对象描述样本集合。实施时,可以通过具有不同口音的人对lasot和tnl2k两大数据库进行多种人工语音标注,来模拟实际应用场景,减少不同语音特征(例如速度、口音、噪声)对检测结果的影响。
[0191]
在一些实施例中,对象描述样本集合可以设置为如表2所示的6种不同难度的语音样本集合,来对模型进行训练。
[0192]
表2
[0193]
设置语音来源母语为英语的人数比例噪音mf机器转换女士语音100% mm机器转换男士语音100% hf英文母语女士语音100%
★
hm英文母语男士语音100%
★
hc117个不同的人的语音58.8%
★★
hc217个不同的人的语音29.4%
★★
[0194]
其中,
★
越多,表示噪音越大。前两个语音来自机器转换,分别转换为男声(mm)和
女声(mf),这类声音属于标准的英语且无噪音,在实际中很少存在。第三第四种语音,分别来自母语为英语的女标注人员和男标注人员,让他们为每个视频提供语音标注,这两部分语音会含有少量因为录音设备而引入的噪音。为了更贴近实际情况,第五第六种语音,分别来自17个不同的人,其中只有部分人员的母语为英语。实施时,将3400个视频(其中,1400个来自lasot数据集,2000个来自tnl2k)分为17组,找到34个标注人员,每人标注200段语音,并将标注语音分为两个部分(hc1和hc2),由于这两部分语音只有部分来自母语为英语的标注人员,因此,标注的语音中包含口音变化,噪声水平也高于前四个语音标注。
[0195]
表3为lasot和tnl2k两大数据库的语音时长和文件数量的统计表。
[0196]
表3
[0197][0198]
其中,语音文件为表2中6种不同难度的语音文件。
[0199]
图4显示了lasot和tnl2k两大数据库中不同语音时长对应的语音文件数量和比例。其中,大部分语音文件持续3到4秒(s),tnl2k数据集中1至2s和大于7s的文件的比例(18%)大于lasot数据集中1至2s和大于7s的文件的比例(8%)。
[0200]
步骤604:利用所述图像样本集合和所述对象描述样本集合,对图像检测模型进行训练,得到所述图像样本集合中各图像样本的检测结果;
[0201]
在一些实施例中,步骤604的实施可以包括:
[0202]
步骤6041a:利用所述图像检测模型对所述对象描述样本集合进行特征提取,得到对象描述特征集合;
[0203]
步骤6042a:利用所述图像检测模型对所述图像样本集合进行特征提取,得到第一图像特征集合;
[0204]
步骤6043a:基于所述对象描述特征集合和所述第一图像特征集合,利用所述图像检测模型对所述图像样本集合中各图像样本进行所述待识别的对象的检测,得到所述图像样本集合中各图像样本的检测结果。
[0205]
这里,步骤6041a至步骤6043a可参见步骤104至步骤108。
[0206]
步骤606:基于各所述图像样本的检测结果,确定所述图像检测模型的损失;
[0207]
这里,图像检测模型的损失函数可以为:
[0208][0209]
其中,l
iou
为表示真值框与预测框重合度的损失,l1为表示真值框与预测框之间差值的损失,即最小绝对值误差;θ为网络参数,λ为损失函数的权重系数,bi为预测值,为真值。
[0210]
第一损失为当bi为各图像样本的检测结果时的损失值,通过将各图像样本的检测结果和真值代入公式(6-1),得到第一损失。
[0211]
步骤608:采用所述损失,对所述图像检测模型的网络参数进行调整,以使调整后的所述图像检测模型输出的检测结果的损失满足收敛条件。
[0212]
这里,网络参数的公式可以为:
[0213][0214]
其中,θ为网络参数,α为损失函数的权重系数。
[0215]
通过将l(θ)代入公式(6-2),得到调整后的网络参数。
[0216]
本技术实施例中,通过获取图像样本集合和对象描述样本集合,然后利用图像样本集合和对象描述样本集合,对图像检测模型进行训练,得到图像样本集合中各图像样本的检测结果,再基于各图像样本的检测结果,确定图像检测模型的损失,最后采用损失,对图像检测模型的网络参数进行调整,实现对图像检测模型的训练,使得调整后的图像检测模型输出的检测结果的损失能够满足收敛条件。
[0217]
在一些实施例中,所述检测模块可以包括第一检测模块和第二检测模块,步骤604的实施可以包括:
[0218]
步骤6041b:利用所述图像样本集合中的第i帧图像样本和所述对象描述样本集合,对所述第一检测模块进行训练,得到所述图像样本集合中各第i帧图像样本的检测结果;
[0219]
这里,步骤6041b可参见步骤104至步骤108。
[0220]
步骤6042b:在所述图像样本集合中各第i帧图像样本的检测结果表征检测到所述待识别的对象的情况下,利用所述图像样本集合中各第i帧图像样本的检测结果中的所述待识别的对象的位置信息,所述第i+1帧图像样本和所述对象描述样本集合,对所述第二检测模块进行训练,得到所述图像样本集合中各第i+1帧图像样本的检测结果;
[0221]
在一些实施例中,步骤6042b的实施可以包括:
[0222]
步骤6421:基于所述图像样本集合中各第i帧图像样本的检测结果中的所述待识别的对象的位置信息,在各所述第i+1帧图像样本中确定出各第i+1帧图像样本区域,将各所述第i+1帧图像样本区域作为待处理区域集合;
[0223]
步骤6422:对所述待处理区域集合进行特征提取,得到待处理区域特征集合;
[0224]
步骤6423:基于所述待处理区域特征集合和所述对象描述特征集合,对所述第二检测模块进行训练,得到所述图像样本集合中各第i+1帧图像样本的检测结果。
[0225]
这里,步骤6421至步骤6423可参见步骤41b1至步骤41b3。
[0226]
对应地,步骤606“所述基于各所述图像样本的检测结果,确定所述图像检测模型的损失”,包括:
[0227]
步骤6061:基于所述图像样本集合中各第i帧图像样本的检测结果,确定所述第一检测模块的第三损失;
[0228]
这里,第一检测模块的损失函数可以为:
[0229][0230]
其中,g代表第一检测模块。
[0231]
步骤6062:基于所述图像样本集合中各第i+1帧图像样本的检测结果,确定所述第二检测模块的第四损失;
[0232]
这里,第二检测模块的损失函数可以为:
[0233][0234]
其中,l代表第二检测模块。
[0235]
步骤6063:至少基于所述第三损失和所述第四损失,确定所述图像检测模型的损失。
[0236]
这里,图像检测模型的损失函数可以为:
[0237]
l(θ)=αglg(θ)+α
l
l
l
(θ)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6-5);
[0238]
其中,α为损失函数的权重系数。
[0239]
对应的网络参数的表达式为:
[0240][0241]
本技术实施例中,通过加入第二检测模块,将图像样本转化成图像样本区域后进行训练,可以减少计算量。
[0242]
本技术实施例还提供一种图像检测模型训练方法,所述图像检测模型包括检测模块和纠正模块,所述方法包括:
[0243]
步骤701:获取图像样本集合和对象描述样本集合,其中,所述对象描述样本集合为对待识别的对象进行描述的语音样本集合或文本样本集合;
[0244]
步骤702:所述利用所述图像样本集合和所述对象描述样本集合,对所述检测模块进行训练,得到所述图像样本集合中各图像样本的检测结果;
[0245]
这里,步骤702可参见步骤104至步骤108。
[0246]
步骤703:确定所述各图像样本的检测结果中的所述待识别的对象的位置信息与真值之间的偏差;
[0247]
这里,偏差可以为待识别的对象的位置信息与真值之间的交并比iou,则步骤703的实施可以为确定待识别的对象的位置信息与真值之间的交并比iou。
[0248]
本技术实施例对偏差的类型不做限定。
[0249]
步骤704:在所述偏差超出预设范围的情况下,获取纠正语音;
[0250]
这里,预设范围可以根据偏差的类型和要求的准确度而定,例如当偏差为待识别的对象的位置信息与真值之间的交并比iou,准确度要求较高时,预设范围可以为小于0.4。
[0251]
步骤705:至少利用所述纠正语音,对所述纠正模块进行训练,在所述各图像样本中更新所述待识别的对象的位置信息;
[0252]
在一些实施例中,步骤705的实施可以包括:
[0253]
步骤7051:基于所述纠正语音,确定纠正卷积核;
[0254]
步骤7052:基于所述待识别的对象在所述各图像样本中的位置信息和所述各图像样本,确定目标掩膜图;
[0255]
步骤7053:基于所述纠正卷积核、所述目标掩膜图和所述第一图像特征集合,在所述各图像样本中更新所述待识别的对象的位置信息。
[0256]
这里,步骤7051至步骤7053可参见步骤141a至步骤141c。
[0257]
步骤706:基于更新后的所述待识别的对象的位置信息,确定所述纠正模块的第一损失;
[0258]
这里,纠正模块的损失函数可以为:
[0259][0260]
其中,t代表纠正模块。
[0261]
步骤707:基于各所述图像样本的检测结果,确定所述检测模块的第二损失;
[0262]
这里,检测模块的损失函数可以为:
[0263][0264]
在所述检测模块包括第一检测模块和第二检测模块的情况下:
[0265]
检测模块的损失函数可以为:
[0266]
lr(θ)=αglg(θ)+α
l
l
l
(θ)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7-3);
[0267]
其中,g代表第一检测模块,l代表第二检测模块。
[0268]
步骤709:基于所述第一损失和所述第二损失,确定所述图像检测模型的损失。
[0269]
这里,图像检测模型的损失函数可以为:
[0270]
l(θ)=αrlr(θ)+α
t
l
t
(θ)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7-4);
[0271]
步骤710:采用所述损失,对所述图像检测模型的网络参数进行调整,以使调整后的所述图像检测模型输出的检测结果的损失满足收敛条件。
[0272]
这里,网络参数的公式可以为:
[0273][0274]
本技术实施例中,通过加入纠正模块,提高了检测结果的准确度。
[0275]
基于上述方法,为了将本技术实施例提供的图像检测模型与其他模型进行对比,所有模型都使用lasot数据集和来自表2中mm设置的语音进行训练。其中,本技术实施例提供的图像检测模型的第一检测模块输入的图像大小为640
×
640像素,第二检测模块输入的图像大小为320
×
320像素,整个模型以端到端的方式进行训练,总共有250个时期(epoch)。当真值框与预测框之间的i
ou
小于0.4时,触发纠正模块。
[0276]
实施时,采用精度图和成功图来评估不同模型的性能,其中,成功图表示预测框和真实框之间的i
ou
值高于预定义重叠阈值的帧的比率。精度图表示预测框和真实框之间的位置误差小于预定义阈值的帧的百分比。根据成功图和精度图,可以得到成功分数和精度分数。图5显示了不同模型的成功分数和精度分数,可以看出,本技术实施例提供的图像检测模型的成功分数0.70和精度分数0.743相比于其他模型的成功分数和精度分数都高一些,说明了本技术实施例提供的模型的可行性和具有较高的准确度。
[0277]
基于前述的实施例,本技术实施例提供一种图像检测装置,该装置包括所包括的各模块、以及各模块所包括的各子模块,各子模块所包括的各单元,以及各单元所包括的各子单元,都可以通过电子设备来实现;当然也可通过具体的逻辑电路实现;在实施的过程中,处理器可以为中央处理器(cpu)、微处理器(mpu)、数字信号处理器(dsp)或现场可编程门阵列(fpga)等。
[0278]
图6为本技术实施例提供的一种图像检测装置的组成结构示意图,如图6所示,所述图像检测装置600包括第一获取模块601、第一提取模块602、第二提取模块603和第一目
标对象检测模块604,其中:
[0279]
第一获取模块601,用于获取第一待处理图像和输入的对象描述信息,其中,所述对象描述信息为对待识别的第一目标对象进行描述的第一语音或第一文本;
[0280]
第一提取模块602,用于对所述对象描述信息进行特征提取,得到对象描述特征;
[0281]
第二提取模块603,用于对所述第一待处理图像进行特征提取,得到第一图像特征;
[0282]
目标对象检测模块604,用于基于所述对象描述特征和所述第一图像特征,对所述第一待处理图像进行所述第一目标对象的检测,得到所述第一待处理图像的检测结果。
[0283]
在一些实施例中,所述对象描述信息为所述第一语音,所述第一待处理图像为图像集合中的每一图像;所述图像检测装置600还包括:第二获取模块,用于获取并记录所述图像集合中每一图像的检测结果,得到记录结果;所述检测结果表征检测到或未检测到所述第一目标对象;输出模块,用于至少输出所述记录结果。
[0284]
在一些实施例中,在获取所述第一语音之后,所述图像检测装置600还包括:转化模块,用于将所述第一语音转化成第二文本;第一提取模块602,还用于对所述第二文本进行特征提取,得到第二文本特征;目标对象检测模块604,还用于基于所述第二文本特征和所述第一图像特征,对所述第一待处理图像进行所述第一目标对象的检测,得到所述第一待处理图像的检测结果。
[0285]
在一些实施例中,所述第一待处理图像为图像序列中的第i帧图像,所述图像检测装置600还包括以下至少之一:第一跟踪模块,用于对所述第i+1帧图像进行特征提取,得到第i+1帧图像特征;基于所述第i+1帧图像特征和第一语音特征,对所述第i+1帧图像进行所述第一目标对象的跟踪;第二跟踪模块,用于在所述第i帧图像的检测结果表征检测到所述第一目标对象的情况下,基于所述第i帧图像的检测结果中的所述第一目标对象的位置信息,对所述第i+1帧图像进行所述第一目标对象的跟踪。
[0286]
在一些实施例中,所述第二跟踪模块包括:第一确定子模块,用于基于所述第i帧图像的检测结果中的所述第一目标对象的位置信息,在所述第i+1帧图像中确定出第i+1帧图像区域,将所述第i+1帧图像区域作为待处理区域;一提取子模块,用于对所述待处理区域进行特征提取,得到待处理区域特征;跟踪子模块,用于基于所述待处理区域特征和所述第一语音特征,对所述第i+1帧图像进行所述第一目标对象的跟踪。
[0287]
在一些实施例中,所述第一确定子模块包括:获取单元,用于获取所述第i帧图像的检测结果中的所述第一目标对象的位置信息所在的预测区域的中心位置;截取单元,用于以所述中心位置为中心,在所述第i+1帧图像中截取所述预测区域的n倍区域,得到所述第i+1帧图像区域。
[0288]
在一些实施例中,所述目标对象检测模块604包括:融合子模块,用于融合所述对象描述特征和第二图像特征,得到第一融合特征,其中,所述第二图像特征包括所述第一图像特征或待处理区域特征;第二确定子模块,用于基于所述第一融合特征,确定所述第一待处理图像的检测结果。
[0289]
在一些实施例中,所述第二确定子模块包括:编码单元,用于通过第一编码器对所述第一融合特征进行编码处理,得到融合所述对象描述特征和所述第二图像特征的第一编码特征;解码单元,通过第一解码器对所述第一编码特征进行解码处理,得到融合所述对象
描述特征和所述第二图像特征的第一解码特征;定位单元,用于通过第一检测头基于所述第一编码特征和所述第一解码特征实现对所述第一目标对象的定位,得到所述第一待处理图像的检测结果。
[0290]
在一些实施例中,在得到所述第一待处理图像的检测结果之后,所述图像检测装置600还包括:第三获取模块,用于获取第二语音;第一提取模块602,还用于在所述第二语音包括预设的第一关键词的情况下,对所述第二语音进行特征提取,得到第二语音特征;第一获取模块601,还用于获取第二待处理图像;第二提取模块603,还用于对所述第二待处理图像进行特征提取,得到第三图像特征;目标对象检测模块604,还用于基于所述第二语音特征和所述第三图像特征,对所述第二待处理图像进行第二目标对象的检测,得到所述第二待处理图像的检测结果。
[0291]
在一些实施例中,在得到所述第一待处理图像的检测结果之后,所述图像检测装置600还包括:第三获取模块,用于获取第二语音;第一确定模块,用于在所述第二语音包括预设的第二关键词的情况下,确定所述第二语音为纠正语音;更新模块,用于至少基于所述纠正语音,在所述第一待处理图像中更新所述第一目标对象的位置信息。
[0292]
在一些实施例中,所述更新模块包括:第三确定子模块,用于基于所述纠正语音,确定纠正卷积核;第四确定子模块,用于基于所述第一目标对象在所述第一待处理图像中的位置信息和所述第一待处理图像,确定目标掩膜图;第一更新子模块,用于基于所述纠正卷积核、所述目标掩膜图和所述第一待处理图像的第一图像特征,在所述第一待处理图像中更新所述第一目标对象的位置信息。
[0293]
在一些实施例中,所述第四确定子模块,包括:生成单元,用于基于所述第一目标对象在所述第一待处理图像中的位置信息和所述第一待处理图像,将所述第一待处理图像生成二值图;复制单元,用于基于所述第一待处理图像的第一图像特征的通道维度,沿着通道维度方向复制m份所述二值图,得到所述目标掩膜图。
[0294]
在一些实施例中,所述第三确定子模块,包括:第一提取单元,用于提取所述纠正语音的纠正语音特征;编码单元,用于通过第二编码器对所述纠正语音特征进行编码,得到第二编码特征;解码单元,用于通过第二解码器对所述第二编码特征进行解码,得到所述纠正语音卷积核。
[0295]
在一些实施例中,所述第一更新子模块包括:融合单元,用于融合所述目标掩膜图和所述第一待处理图像的第一图像特征,得到第二融合特征;卷积单元,用于利用所述纠正语音卷积核,对所述第二融合特征进行卷积操作,得到第三融合特征;更新单元,用于通过第二检测头基于所述第三融合特征,在所述第一待处理图像中更新所述第一目标对象的位置信息。
[0296]
图7为本技术实施例提供的一种图像检测模型的训练装置的组成结构示意图,如图7所示,所述图像检测模型的训练装置700包括:
[0297]
第四获取模块701,用于获取图像样本集合和对象描述样本集合,其中,所述对象描述样本集合为对待识别的对象进行描述的语音样本集合或文本样本集合;
[0298]
第一训练模块702,用于利用所述图像样本集合和所述对象描述样本集合,对图像检测模型进行训练,得到所述图像样本集合中各图像样本的检测结果;
[0299]
第二确定模块703,用于基于各所述图像样本的检测结果,确定所述图像检测模型
的损失;
[0300]
调整模块704,用于采用所述损失,对所述图像检测模型的网络参数进行调整,以使调整后的所述图像检测模型输出的检测结果的损失满足收敛条件。
[0301]
在一些实施例中,所述第一训练模块,包括:第二提取子模块,用于利用所述图像检测模型对所述对象描述样本集合进行特征提取,得到对象描述特征集合;第三提取子模块,用于利用所述图像检测模型对所述图像样本集合进行特征提取,得到第一图像特征集合;目标对象检测子模块,用于基于所述对象描述特征集合和所述第一图像特征集合,利用所述图像检测模型对所述图像样本集合中各图像样本进行所述待识别的对象的检测,得到所述图像样本集合中各图像样本的检测结果。
[0302]
在一些实施例中,所述图像检测模型包括检测模块和纠正模块,所述第一训练模块,包括:训练子模块,用于所述利用所述图像样本集合和所述对象描述样本集合,对所述检测模块进行训练,得到所述图像样本集合中各图像样本的检测结果;
[0303]
在得到所述图像样本集合中各图像样本的检测结果之后,所述图像检测模型的训练装置700还包括:第三确定模块,确定所述各图像样本的检测结果中的所述待识别的对象的位置信息与真值之间的偏差;第五获取模块,用于在所述偏差超出预设范围的情况下,获取纠正语音;第二训练模块,用于至少利用所述纠正语音,对所述纠正模块进行训练,在所述各图像样本中更新所述待识别的对象的位置信息;
[0304]
第四确定模块,用于基于更新后的所述待识别的对象的位置信息,确定所述纠正模块的第一损失;对应地,所述第二确定模块包括:第五确定子模块,用于基于各所述图像样本的检测结果,确定所述检测模块的第二损失;第六确定子模块,用于基于所述第一损失和所述第二损失,确定所述图像检测模型的损失。
[0305]
在一些实施例中,所述第二训练模块,包括:第七确定子模块,用于基于所述纠正语音,确定纠正卷积核;第八确定子模块,用于基于所述待识别的对象在所述各图像样本中的位置信息和所述各图像样本,确定目标掩膜图;第二更新子模块,用于基于所述纠正卷积核、所述目标掩膜图和所述第一图像特征集合,在所述各图像样本中更新所述待识别的对象的位置信息。
[0306]
在一些实施例中,所述检测模块包括第一检测模块和第二检测模块;所述第一训练模块,包括:第一训练子模块,用于利用所述图像样本集合中的第i帧图像样本和所述对象描述样本集合,对所述第一检测模块进行训练,得到所述图像样本集合中各第i帧图像样本的检测结果;第二训练子模块,用于在所述图像样本集合中各第i帧图像样本的检测结果表征检测到所述待识别的对象的情况下,利用所述图像样本集合中各第i帧图像样本的检测结果中的所述待识别的对象的位置信息,所述第i+1帧图像样本和所述对象描述样本集合,对所述第二检测模块进行训练,得到所述图像样本集合中各第i+1帧图像样本的检测结果;
[0307]
对应地,所述第二确定模块,包括:第九确定子模块,用于基于所述图像样本集合中各第i帧图像样本的检测结果,确定所述第一检测模块的第三损失;第十确定子模块,用于基于所述图像样本集合中各第i+1帧图像样本的检测结果,确定所述第二检测模块的第四损失;第十一确定子模块,用于至少基于所述第三损失和所述第四损失,确定所述图像检测模型的损失。
[0308]
在一些实施例中,所述第二训练子模块,包括:确定单元,用于基于所述图像样本集合中各第i帧图像样本的检测结果中的所述待识别的对象的位置信息,在各所述第i+1帧图像样本中确定出各第i+1帧图像样本区域,将各所述第i+1帧图像样本区域作为待处理区域集合;第二提取单元,用于对所述待处理区域集合进行特征提取,得到待处理区域特征集合;训练单元,用于基于所述待处理区域特征集合和所述对象描述特征集合,对所述第二检测模块进行训练,得到所述图像样本集合中各第i+1帧图像样本的检测结果。
[0309]
以上装置实施例的描述,与上述方法实施例的描述是类似的,具有同方法实施例相似的有益效果。对于本技术装置实施例中未披露的技术细节,请参照本技术方法实施例的描述而理解。
[0310]
需要说明的是,本技术实施例中,如果以软件功能模块的形式实现上述的图像检测方法及相关训练方法,并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术实施例的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台电子设备(可以是个人计算机、服务器等)执行本技术各个实施例所述方法的全部或部分。而前述的存储介质包括:u盘、移动硬盘、rom(read only memory,只读存储器)、磁碟或者光盘等各种可以存储程序代码的介质。这样,本技术实施例不限制于任何特定的硬件和软件结合。
[0311]
对应地,本技术实施例提供一种电子设备,包括存储器和处理器,所述存储器存储有可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述实施例中提供的图像检测方法及相关训练方法中的步骤。
[0312]
对应地,本技术实施例提供一种可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述图像检测方法及相关训练方法中的步骤。
[0313]
这里需要指出的是:以上存储介质和平台实施例的描述,与上述方法实施例的描述是类似的,具有同方法实施例相似的有益效果。对于本技术存储介质和平台实施例中未披露的技术细节,请参照本技术方法实施例的描述而理解。
[0314]
需要说明的是,图8为本技术实施例电子设备的一种硬件实体示意图,如图8所示,该电子设备800的硬件实体包括:处理器801、通信接口802和存储器803,其中
[0315]
处理器801通常控制电子设备800的总体操作。
[0316]
通信接口802可以使电子设备800通过网络与其他平台或电子设备或服务器通信。
[0317]
存储器803配置为存储由处理器801可执行的指令和应用,还可以缓存待处理器801以及电子设备800中各模块待处理或已经处理的数据(例如,图像数据、音频数据、语音通信数据和视频通信数据),可以通过flash(闪存)或ram(random access memory,随机访问存储器)实现。
[0318]
在本技术所提供的几个实施例中,应该理解到,所揭露的设备和方法,可以通过其它的方式实现。以上所描述的设备实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,如:多个单元或组件可以结合,或可以集成到另一个系统,或一些特征可以忽略,或不执行。另外,所显示或讨论的各组成部分相互之间的耦合、或直接耦合、或通信连接可以是通过一些接口,设备或单元的间接耦合或通信连接,可以是电性的、机械的或其它形式的。
[0319]
上述作为分离部件说明的单元可以是、或也可以不是物理上分开的,作为单元显示的部件可以是、或也可以不是物理单元,即可以位于一个地方,也可以分布到多个网络单元上;可以根据实际的需要选择其中的部分或全部单元来实现本实施例方案的目的。
[0320]
另外,在本技术各实施例中的各功能单元可以全部集成在一个处理模块中,也可以是各单元分别单独作为一个单元,也可以两个或两个以上单元集成在一个单元中;上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于一计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:移动存储设备、rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。
[0321]
本技术所提供的几个方法实施例中所揭露的方法,在不冲突的情况下可以任意组合,得到新的方法实施例。
[0322]
本技术所提供的几个产品实施例中所揭露的特征,在不冲突的情况下可以任意组合,得到新的产品实施例。
[0323]
本技术所提供的几个方法或设备实施例中所揭露的特征,在不冲突的情况下可以任意组合,得到新的方法实施例或设备实施例。
[0324]
以上所述,仅为本技术的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应以所述权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1