一种基于随机森林的光纤生产合格指标预测方法与流程
1.本发明涉及光纤生产领域,具体来说,涉及一种基于随机森林的光纤生产合格指标预测方法。
背景技术:
2.在光纤生产过程中,通常会有一些指标来评价生产的合格情况,这些指标的好坏影响着产品的验收。由于产品加工过程是相对固定的,因此原料的一些特征是最终合格指标的重要影响因素。企业迫切希望能根据原料的参数特征能提前预知产品最终的合格指标,以便及时做出调整,从而减少成本,提高产品合格率。
3.目前大部分企业采用机理模型加人工经验的方式,但存在一些问题,一方面机理模型的准确率较低,影响着后续工作,且预测速度并不高效,这对机器生产的速度来说很难接受;另一方面人工指导受到工人工作状态所影响,容易误操作和判断不正确的情况。
4.针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现要素:
5.(一)解决的技术问题
6.针对现有技术的不足,本发明提供了基于随机森林的光纤生产合格指标预测方法,具备对已有生产线的数据参数和产品剖面特征分析,从而通过模型学习来预测出能优化生产的参数的优点,进而解决了传统机理模型精度和速度较低,且整个过程受到人工状态影响的问题。
7.(二)技术方案
8.为实现上述对已有生产线的数据参数和产品剖面特征分析,从而通过模型学习来预测出能优化生产的参数的优点,本发明采用的具体技术方案如下:
9.一种基于随机森林的光纤生产合格指标预测方法,该方法包括以下步骤:
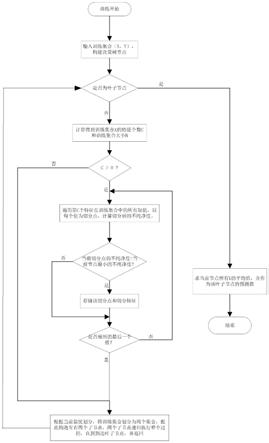
10.s1:获取若干个产品的剖面特征,并将若干个产品的剖面特征组成产品特征流通图,作为随机森林算法的输入特征,其中,输入特征包括芯棒模场直径及折射率剖面等;
11.s2:输入训练集合(x,y),构建决策树节点,其中,x为筛选出的产品输入特征,y为要预测的合格指标;
12.s3:判断所述决策树节点是否为叶子节点,若是,则求当前节点所有y的平均值,并作为该叶子节点的预测值,并接受训练,若否,进行下一步;
13.s4:计算得到训练集合x的特征个数c和集合大小n;
14.s5:判断c是否大于0,若否,则根据当前最优划分,将训练集合划分为两个集合,据此构造左右两个子节点,两个子节点递归执行本步骤,直到到达叶子节点并返回,若是则进行下一步;
15.s6:遍历第c个特征在训练集中的所有取值,且以每个值为切分点,计算切分后的不纯净度;
16.s7:判断当前切分点的不纯净度是否小于当前节点最小的不纯净度,若是则存储该切分点和切分特征,若否则执行下一步;
17.s8:判断是否遍历到最后一个值,若是,则执行步骤s5,若否,则执行步骤s6;
18.其中,使用local outlier factor算法来进行原始数据的异常点检测,并在对输入数据进行随机森林算法训练前将异常点剔除,同时在随机森林算法训练过程中,采用网格搜索算法来搜寻模型的最佳参数。
19.进一步的,所述产品的生产过程包括芯棒生产、芯棒检测、光棒生产、光纤生产和光纤检测。
20.进一步的,所述随机森林算法训练后的输出特征为截止波长和光纤模场直径。
21.进一步的,所述将若干个产品的剖面特征组成产品特征流通图时,通过将剖面特征可视化,提取影响预测结果的特征来组成产品特征流通图。
22.进一步的,所述s5中据此构造左右两个子节点,两个子节点递归执行本步骤,直到到达叶子节点并返回还包括以下步骤:
23.选择第j个特征和它的取值s作为切分变量和切分点,并将训练集合(x,y)划分为区域r1(j,s)和区域r2(j,s),其中:
24.r1(j,s)={x∣x
(j)
≤s},r2(j,s)={x∣x
(j)
》s};
25.利用公式:寻找最优切分变量j和切分点s,
[0026][0027]
i为非零自然数,x、y为训练集,c1和c2分别表示数据集被划分成两部分后的输出值,和表示c1和c2的函数值,ave表示求平均值函数;
[0028]
采用穷举找到最优的切分变量j和最优切分点s,并继续循环执行s5中的步骤,直到满足停止条件。
[0029]
进一步的,所述使用local outlier factor算法来进行异常点检测还包括以下步骤:
[0030]
设定点p的第k距离记做dk(p);
[0031]
点p的第k距离邻域记为nk(p),代表的是点p的第k距离范围以内的所有的数据点,点p的第k邻域点个数为|nk(p)|≥k;
[0032]
点a对于点p的可达距离定义为:
[0033]
d(a,p)=max(dk(p),d(a,p));
[0034]
点p的局部可达密度为;
[0035]
其中,reach-dist表示可达距离;
[0036]ai
的局部离群因子定义如下:
[0037]
局部离群因子越小,局部可达密度越大,ai是离群点的可能性越小,反之ai是异常点的可能性越大,i为非零自然数。
[0038]
进一步的,所述使用local outlier factor算法来进行异常点检测之后进行数据点的归一化处理。
[0039]
进一步的,所述数据点的归一化处理包括以下步骤:
[0040]
对数据点特征e1,e2,
…
,en进行标准化:
[0041]
并得到f1,f2,
…
,fn∈[0,1],为无量纲的数据,是所运算特征中数据的最小值,是所运算特征中数据的最大值;j及n均为非零自然数。
[0042]
进一步的,所述采用网格搜索算法来搜寻模型的最佳参数时,在指定的参数范围内,按步长依次调整参数,并利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数。
[0043]
进一步的,所述随机森林算法训练过程中,进行10折交叉验证来训练模型,取每次测试指标的均值作为模型的评价标准。
[0044]
(三)有益效果
[0045]
与现有技术相比,本发明提供了基于随机森林的光纤生产合格指标预测方法,具备以下有益效果:
[0046]
本发明通过对已有生产线的数据参数和产品剖面特征分析,从而通过模型学习来预测出能优化生产的参数。相比传统机理模型,本发明具有更好的精度和速度,且整个过程无需人工干预。
[0047]
通过对产品生产流程进行分析,结合给定的产品数据,先确定整个需求属于机器学习中的回归过程。通过分析各个数据间的关系,本发明建立了对应法则来整合数据特征,形成一对一的数据以便模型训练和测试。由于原始特征相对较少,不足以表示整个剖面的信息,因此通过对剖面数据可视化,本发明提取了理论上可能影响预测结果的一些特征来扩充输入特征库。本发明构建随机森林模型来训练预测,应用一些手段来提高模型精度(如异常点剔除、调参优化等)。此外,为了提高模型的泛化能力,本发明采用交叉验证方法。通过在测试集上的对比,本发明模型的预测精度远远好于企业原始的机理模型。
附图说明
[0048]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0049]
图1是根据本发明实施例的基于随机森林的光纤生产合格指标预测方法的流程
图;
[0050]
图2是产品生产流程图;
[0051]
图3是产品特征流通图;
[0052]
图4是产品1与产品2对应关系图;
[0053]
图5是产品的相关特征信息图;
[0054]
图6是产品5检测结果图;
[0055]
图7是产品4检测结果图;
[0056]
图8是产品2、3、4、5之间对应关系图;
[0057]
图9是剖面可视化图;
[0058]
图10是部分额外剖面特征信息图;
[0059]
图11是数据中的异常点图;
[0060]
图12是异常点过滤前后原始机理模型的精度对比图;
[0061]
图13是各模型在默认参数下测试精度对比图之一;
[0062]
图14是各模型在默认参数下测试精度对比图之一;
[0063]
图15是网格搜索算法流程图;
[0064]
图16是x3参数预测调参精度示意图;
[0065]
图17是x4参数预测调参精度示意图;
[0066]
图18是10折交叉验证精度情况示意图之一;
[0067]
图19是10折交叉验证精度情况示意图之一。
具体实施方式
[0068]
为进一步说明各实施例,本发明提供有附图,这些附图为本发明揭露内容的一部分,其主要用以说明实施例,并可配合说明书的相关描述来解释实施例的运作原理,配合参考这些内容,本领域普通技术人员应能理解其他可能的实施方式以及本发明的优点,图中的组件并未按比例绘制,而类似的组件符号通常用来表示类似的组件。
[0069]
根据本发明的实施例,提供了一种基于随机森林的光纤生产合格指标预测方法。
[0070]
现结合附图和具体实施方式对本发明进一步说明,如图1所示,根据本发明实施例的基于随机森林的光纤生产合格指标预测方法,该方法包括以下步骤:
[0071]
s1:获取若干个产品的剖面特征,并将若干个产品的剖面特征组成产品特征流通图,作为随机森林算法的输入特征,其中,输入特征包括芯棒模场直径及折射率剖面等;
[0072]
s2:输入训练集合(x,y),构建决策树节点,其中,x为筛选出的产品输入特征,y为要预测的合格指标;
[0073]
s3:判断所述决策树节点是否为叶子节点,若是,则求当前节点所有y的平均值,并作为该叶子节点的预测值,并接受训练,若否,进行下一步;
[0074]
s4:计算得到训练集合x的特征个数c和集合大小n;
[0075]
s5:判断c是否大于0,若否,则根据当前最优划分,将训练集合划分为两个集合,据此构造左右两个子节点,两个子节点递归执行本步骤,直到到达叶子节点并返回,若是则进行下一步;
[0076]
其中,所述s5中据此构造左右两个子节点,两个子节点递归执行本步骤,直到到达
叶子节点并返回还包括以下步骤:
[0077]
选择第j个特征和它的取值s作为切分变量和切分点,并将训练集合(x,y)划分为区域r1(j,s)和区域r2(j,s),其中:
[0078]
r1(j,s)={x∣x
(j)
≤s},r2(j,s)={x∣x
(j)
》s};
[0079]
利用公式:寻找最优切分变量j和切分点s,
[0080][0081]
i为非零自然数,x、y为训练集,c1和c2分别表示数据集被划分成两部分后的输出值,和表示c1和c2的函数值,ave表示求平均值函数;
[0082]
采用穷举找到最优的切分变量j和最优切分点s,并继续循环执行s5中的步骤,直到满足停止条件。
[0083]
s6:遍历第c个特征在训练集中的所有取值,且以每个值为切分点,计算切分后的不纯净度;
[0084]
s7:判断当前切分点的不纯净度是否小于当前节点最小的不纯净度,若是则存储该切分点和切分特征,若否则执行下一步;
[0085]
s8:判断是否遍历到最后一个值,若是,则执行步骤s5,若否,则执行步骤s6;
[0086]
数据分析与预处理:
[0087]
如图4-8所示,原始数据包含6部分——产品1与产品2对应关系、产品的相关特征信息、产品4检测结果、产品5检测结果、产品2、3、4、5之间对应关系以及剖面数据。
[0088]
由于原始数据分为几个文件存储,而每个文件数据量都不同,因此需要合并对齐,便于分析。本发明依据数据5中产品2、3、4、5的关系信息和数据1中产品2与产品1对应关系信息,反向推导搜寻,最终可以获得产品5对应产品1的信息,从而与数据2的特征进行整合,得到最终完整的数据特征。
[0089]
由图2产品生产流程和图3产品特征流通可知,一个产品1的特征对应多个产品5,因此对于模型训练和测试来说,必须先对齐数据,得到单个产品5合格指标对应产品1输入特征,所以需要反向溯源。由图8中产品5编号,我们可以整合图6中产品5有关测试结果,再根据图8中产品5相对产品4,产品4相对产品2的位置关系,从而整合图4,最后根据产品2相对产品1的位置关系和方向、长度等信息,整合图5中的原始输入特征,最终形成单个产品5合格指标和单条输入特征相对应的数据。
[0090]
根据剖面数据图,本发明提取了可能和预测结果相关的部分信息作为输入特征的额外信息。如图9-10所示。
[0091]
如图11所示,由于生产过程中不可避免会有额外因素的影响,且数据存储过程中可能会产生一些问题,因此原始数据中肯定含有噪点数据,所以在处理数据之前需要先对异常数据剔除。
[0092]
其中,使用local outlier factor算法(一种基于密度的经典算法)来进行原始数据的异常点检测,并在对输入数据进行随机森林算法训练前将异常点剔除,同时在随机森
林算法训练过程中,采用网格搜索算法来搜寻模型的最佳参数;在lof之前的异常检测算法大多是基于统计方法的,或者是借用了一些聚类算法用于异常点的识别。基于统计的异常检测算法通常需要假设数据服从特定的概率分布,这个假设往往是不成立的。而聚类的方法通常只能给出0/1的判断(即:是不是异常点),不能量化每个数据点的异常程度。相比较而言,基于密度的lof算法要更简单、直观。它不需要对数据的分布做太多要求,还能量化每个数据点的异常程度。如图12所示为异常点过滤前后原始机理模型的精度对比。其中,mse表示均方误差,mae表示平均绝对误差。两者都是越小表示精度越高。
[0093]
其中,所述使用local outlier factor算法来进行异常点检测还包括以下步骤:
[0094]
设定点p的第k距离记做dk(p);
[0095]
点p的第k距离邻域记为nk(p),代表的是点p的第k距离范围以内的所有的数据点,点p的第k邻域点个数为|nk(p)|≥k;
[0096]
点a对于点p的可达距离定义为:
[0097]
d(a,p)=max(dk(p),d(a,p));
[0098]
点p的局部可达密度为;
[0099]
其中,reach-dist表示可达距离;
[0100]ai
的局部离群因子定义如下:
[0101]
局部离群因子越小,局部可达密度越大,ai是离群点的可能性越小,反之ai是异常点的可能性越大,i为非零自然数。
[0102]
所述使用local outlier factor算法来进行异常点检测之后进行数据点的归一化处理。
[0103]
所述数据点的归一化处理包括以下步骤:
[0104]
对数据点特征e1,e2,
…
,en进行标准化:
[0105]
并得到f1,f2,
…
,fn∈[0,1],为无量纲的数据,是所运算特征中数据的最小值,是所运算特征中数据的最大值;j及n均为非零自然数。
[0106]
模型选择:
[0107]
依据数据特征和要预测的特征,此任务属于回归模型。为此,本发明选取了机器学习中长常用的6个模型——线性回归、多项式回归、随机森林、岭回归、xgboost、gbdt,以及lgbm来进行模型学习训练,依据最终模型测试结果与原始机理模型对比来选取合适的模型。
[0108]
本发明将整个数据集分为训练集和测试集,比例为7:3。在超参数为经验值的情况下,本发明对各个模型进行训练,在训练好的模型上对测试集评估,最终结果如图13-14所
示。其中,左侧坐标值为mse范围,右侧为mae范围。经过初步对比,显然随机森林算法具有更高的精度,故选择随机森林作为最终的模型。
[0109]
模型调参:
[0110]
如图15所示,由于前期测试训练超参数设置的是经验值,因此可以通过进一步优化参数来提高精度。本发明采用gridsearchcv算法来搜寻模型的最佳参数,gridsearchcv,即网格搜索和交叉验证。网格搜索,搜索的是参数,即在指定的参数范围内,按步长依次调整参数,利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数,这其实是一个训练和比较的过程。
[0111]
本发明通过对影响模型精度较大的几个参数逐步进行调参优化,结果如图16-17所示。
[0112]
在一个实施例中,所述产品的生产过程包括芯棒生产、芯棒检测、光棒生产、光纤生产和光纤检测。
[0113]
在一个实施例中,所述随机森林算法训练后的输出特征为截止波长和光纤模场直径。
[0114]
在一个实施例中,所述将若干个产品的剖面特征组成产品特征流通图时,通过将剖面特征可视化,提取影响预测结果的特征来组成产品特征流通图。
[0115]
如图2-3所示,通过产品特征流通图来将产品5对应到输入特征,从而形成1对1的数据。
[0116]
在一个实施例中,由于本发明是人工划分数据集,因此模型可能存在泛化能力不强的情况。因此所述随机森林算法训练过程中,进行10折交叉验证来训练模型,取每次测试指标的均值作为模型的评价标准,如图18-19所示。
[0117]
综上所述,本发明通过对已有生产线的数据参数和产品剖面特征分析,从而通过模型学习来预测出能优化生产的参数。相比传统机理模型,本发明具有更好的精度和速度,且整个过程无需人工干预。通过对产品生产流程进行分析,结合给定的产品数据,先确定整个需求属于机器学习中的回归过程。通过分析各个数据间的关系,本发明建立了对应法则来整合数据特征,形成一对一的数据以便模型训练和测试。由于原始特征相对较少,不足以表示整个剖面的信息,因此通过对剖面数据可视化,本发明提取了理论上可能影响预测结果的一些特征来扩充输入特征库。本发明构建随机森林模型来训练预测,应用一些手段来提高模型精度(如异常点剔除、调参优化等)。此外,为了提高模型的泛化能力,本发明采用交叉验证方法。通过在测试集上的对比,本发明模型的预测精度远远好于企业原始的机理模型。
[0118]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1