一种轻量级的基于2D视频的人脸表情驱动方法和系统与流程
一种轻量级的基于2d视频的人脸表情驱动方法和系统
技术领域
1.本发明属于人脸表情驱动技术领域,更具体的说是涉及一种轻量级的基于2d视频的人脸表情驱动方法和系统。
背景技术:
2.随着计算机技术的发展,计算机视觉相关应用已经融入人们的日常生活,人脸表情驱动广泛应用于游戏制作、影视制作、人机交互等领域。近几年,随着影视、游戏、短视频、直播等领域的发展,人脸表情驱动技术成为热门研究领域。其中基于2d视频的人脸重建技术是人脸表情驱动重要的一环,也是计算机视觉领域具有挑战的课题。
3.目前人脸表情驱动主要有关键参数化方法、基于肌肉模型的方法、表演驱动的方法等。
4.(1)参数化方法
5.参数化人脸模型由表情参数和形状参数组成,其中表情参数控制人脸的各种表情,形状参数控制个性化的人脸形状,通过改变各参数的值便可获得各种人脸表情。该方法能够精确控制特殊的人脸形状,经少量计算便可控制较多的人脸表情,但当多个参数控制同一点时,容易发生冲突,产生不自然的表情。
6.(2)基于肌肉模型的方法
7.人脸的肌肉结构非常复杂,形变难以控制,基于肌肉模型的方法通过肌肉仿真技术描述人脸上不同部位的肌肉运动,尽管肌肉模型可以产生高逼真的人脸表情动画,但肌肉模型的构造及其参数的标定是非常复杂而艰巨的工作,并且复杂的肌肉模型计算量巨大,而简单的肌肉模型无法产生令人满意的视觉效果,限制了肌肉模型生成人脸表情的应用。
8.(3)表演驱动的方法
9.目前通过表演驱动人脸表情动画的方法更能产生精细的表情,同时也避免了不自然的表情的产生,主要分为基于标记的人脸表情动画技术和基于非标记的人脸表情驱动。
10.基于标记的人脸表情驱动是在人脸上标记若干标记点,通过运动捕捉设备获取人脸的三维运动轨迹,再应用径向基差值等技术驱动人脸表情,该方法设备昂贵、制作成本高。
11.因此,如何提供一种轻量级的基于2d视频的人脸表情驱动方法和系统成为了本领域技术人员亟需解决的问题。
技术实现要素:
12.有鉴于此,本发明。
13.为了实现上述目的,本发明采用如下技术方案:
14.一种轻量级的基于2d视频的人脸表情驱动方法,包括如下步骤:
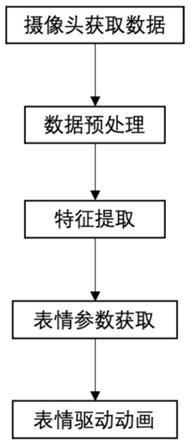
15.s1,通过摄像头获取数据;
16.s2,数据预处理:对摄像头获取的数据进行预处理,获取截取的人脸区域图片;
17.s3,特征提取:通过s2截取的人脸区域图片获取人脸特征以及面部关键点信息;
18.s4,表情参数获取,根据人脸特征以及面部关键点信息,获取表情参数,通过表情参数对人脸动画进行驱动。
19.进一步的,s2中数据预处理具体方法为:将摄像头获取的图片或视频数据进行处理,使用计算机视觉技术检测人脸,并返回人脸位置的相关信息,根据位置信息对人脸区域进行裁剪,用于后续特征提取。
20.进一步的,s3中特征提取具体方法为:针对s2中裁剪的人脸区域图片,使用深度神经网络进行特征提取,并对图片中的面部进行关键点检测,将两部分数据作为后续深度神经网络训练的输入数据。
21.进一步的,s4中表情参数获取具体方法为:针对s3中获取的人脸特征以及面部关键点信息,训练深度学习模型,拟合出表情参数,通过表情参数对人脸动画进行驱动。
22.一种轻量级的基于2d视频的人脸表情驱动系统,包括摄像头、数据预处理模块、特征提取模块和表情参数获取模块,其中:
23.摄像头,用于获取图片或视频数据;
24.数据预处理模块,用于对摄像头获取的数据进行预处理,获取截取的人脸区域图片;
25.特征提取模块,通过s2截取的人脸区域图片获取人脸特征以及面部关键点信息;
26.表情参数获取模块,根据人脸特征以及面部关键点信息,获取表情参数,通过表情参数对人脸动画进行驱动。
27.本发明的有益效果在于:
28.本发明通过对图片进行面部特征提取以及关键点信息提取,通过深度神经网络学习表情相关参数,进而驱动人脸,方法计算量小,资源占用少;产生的表情自然;数据获取简单、方便,实用性强。
附图说明
29.为了更清楚地说明本实用新式实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本实用新式的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
30.图1为本发明的方法流程图。
31.图2为本发明数据预处理、特征提取以及表情参数获取间的逻辑关系图。
具体实施方式
32.下面将结合本发明的实施例中,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
33.实施例1
34.参考图1-2,本发明提供了一种轻量级的基于2d视频的人脸表情驱动方法,包括如下步骤:
35.s1,通过摄像头获取数据;
36.s2,数据预处理:对摄像头获取的数据进行预处理,获取截取的人脸区域图片;
37.s3,特征提取:通过s2截取的人脸区域图片获取人脸特征以及面部关键点信息;
38.s4,表情参数获取,根据人脸特征以及面部关键点信息,获取表情参数,通过表情参数对人脸动画进行驱动。
39.进一步的,s2中数据预处理具体方法为:将摄像头获取的图片或视频数据帧i
frame
进行处理,使用mtcnn算法对图片或视频进行人脸检测,并返回人脸位置及关键点等相关信息,根据位置信息对人脸区域进行裁剪,获取人脸区域图片记为i
face
,用于后续特征提取。
40.进一步的,s3中特征提取具体方法为:针对s2中裁剪的人脸区域图片i
face
,首先使用resnet50进行特征提取,获取人脸的特征数据d
fea
;同时使用训练好的人脸关键点检测模型m
landmark
对i
face
进行面部关键点检测,获取人脸关键点信息d
lm
,将两部分数据作为后续模型训练的输入数据。
41.进一步的,s4中表情参数获取具体方法为:首先根据s3中获取的关键点信息,通过几何方法计算面部几何度量;其次将s3中获取的人脸区域特征d
fea
以及面部关键点位置信息d
lm
作为表情模型m
exp
的输入,使用面部几何度量对模型增加限制,训练面部表情模型m
exp
,拟合出表情参数,进而对人脸动画进行驱动。
42.s4具体实施步骤如下:
43.(1)人脸关键点检测模型m
landmark
训练
44.构建人脸关键点检测模型,其中人脸区域图片i
face
作为输入数据,设备采集的面部关键点信息作为输出数据。首先将人脸区域图片i
face
进行标准化并缩放至统一尺寸,设置学习率、批处理大小等参数,定义损失函数以及优化函数,对网络进行调参训练,最终得到可以正确检测人脸关键点信息的模型。
45.(2)面部几何度量计算
46.选取自然状态下的面部关键点信息进行几何度量的设定,依次计算眼睛内眼角距离、瞳孔与内眼角距离、嘴角与鼻子距离以及弧度等参考值;进一步选取面部表情极限状态下的关键点信息,依次计算眼睛内眼角距离、瞳孔与内眼角距离、嘴角与鼻子距离以及弧度等参考值,作为后续面部表情模型m
exp
的限制条件。
47.(3)面部表情模型m
exp
训练
48.将面部特征数据d
fea
以及面部关键点数据d
lm
作为面部表情模型m
exp
的输入,面部表情参数作为输出,构建深度神经网络模型,设置学习率等参数,定义损失函数以及优化函数,进行调参训练,得到可以获取面部表情参数的网络模型。
49.通过(2)中设定的几何度量参考值、当前帧的关键点信息以及模型输出的表情参数,计算瞳孔相对内眼角距离、嘴角距离、唇部中心点距离,对模型输出的结果进行修正,以获取更加准确、自然的面部表情数值。
50.实施例2
51.本实施例提供了一种轻量级的基于2d视频的人脸表情驱动系统,包括摄像头、数据预处理模块、特征提取模块和表情参数获取模块,其中:
52.摄像头,用于获取图片或视频数据;摄像头采用普通的rgb摄像头。
53.数据预处理模块,用于对摄像头获取的数据进行预处理,获取截取的人脸区域图片;
54.特征提取模块,通过s2截取的人脸区域图片获取人脸特征以及面部关键点信息;
55.表情参数获取模块,根据人脸特征以及面部关键点信息,获取表情参数,通过表情参数对人脸动画进行驱动。
56.本发明通过对图片进行面部特征提取以及关键点信息提取,通过深度神经网络学习表情相关参数,进而驱动人脸,方法计算量小,资源占用少;产生的表情自然;数据获取简单、方便,实用性强。
57.本发明解决了人脸表情获取过程计算量大的问题;解决人脸表情获取过程中出现的不自然的表情的问题;解决人脸表情驱动的设备昂贵的问题,只需普通的rgb摄像头即可完成人脸表情驱动。
58.最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1