在用新能源汽车的高风险车辆筛选方法及存储介质与流程
1.本发明涉及电动汽车评价方法领域,具体涉及在用新能源汽车的高风险车辆筛选方法及存储介质。
背景技术:
2.新能源汽车是利用清洁能源作为动力进行驱动的代步工具,因污染物排放少,新能源汽车运行过程中对环境造成的污染很小,市场对于新能源汽车的需求量大,企业针对旺盛的市场需求也进行了新能源汽车的研发升级,所以,新能源汽车的发展非常迅速。新能源汽车的迅速发展也促使了对高风险新能源汽车筛选要求的提高,而目前高风险新能源汽车的筛选还是按照相关规则中规定的条件进行,即将一年内行驶了八万公里的新能源汽车作为风险车辆,这种筛选方法使得其安全问题日益突出,使得新能源汽车的风险车辆筛选非常重要。
3.使用现有规则中固定的条件进行新能源汽车风险状态判断的方法,判断纬度单一,容易忽略掉新能源汽车的部分潜在风险问题,新能源汽车忽略掉潜在风险问题可能会导致潜在风险烈化,引发安全事故,严重时还可能造成起火等严重安全问题。
技术实现要素:
4.本发明意在提供一种在用新能源汽车的高风险车辆筛选方法,以在新能源汽车的行驶服役过程中及时发现潜在风险问题。
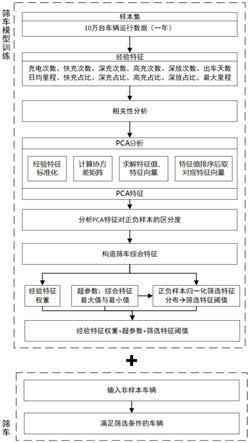
5.本方案中的在用新能源汽车的高风险车辆筛选方法,包括以下步骤:
6.步骤1,确定与新能源汽车安全状态相关联的多个经验特征,计算多个经验特征之间的相关系数矩阵,对相关系数矩阵中相关系数值大于阈值的经验特征的占比进行统计,判断占比是否大于预设值,当占比大于预设值时,对经验特征进行主成分分析,得到主成分特征;
7.步骤2,获取运行中新能源汽车预设时间段内行驶的运行数据,根据累计行驶里程是否大于预设里程将新能源汽车的运行数据分成正样本和负样本;
8.步骤3,基于每个主成分特征对正样本和负样本的特征分布进行对比,得到正样本与负样本的特征分布的总区分度,根据总区分度中最大两个值对应的主成分特征处理得到筛车综合特征;
9.步骤4,以步骤3中的筛车综合特征对待筛车的数据进行筛选。
10.本方案的有益效果是:
11.将新能源汽车的经验特征进行相关系数矩阵的计算,并将相关系数矩阵进行主成分分析得到主成分特征,并利用主成分特征对正样本和负样本进行特征分布的对比分析,以总区分度最大的两个主成分特征处理得到筛车综合特征,利用筛车综合特征进行新能源汽车的筛选,能够从多个方面进行风险车辆的筛选,能够有效筛选出满足预设高风险状态的在用新能源汽车。
12.进一步,所述主成分分析步骤包括:
13.步骤a:根据新能源汽车的分析需求选取初始分析变量,所述初始分析变量包括长时间尺度上的累积效应特征和使用强度特征;
14.步骤b:将初始分析变量中非标准化的累积效应特征按照预设模型进行标准化处理;
15.步骤c:对标准化后的初始分析变量特征求协方差矩阵,计算协方差矩阵的特征值和特征向量;
16.步骤d:将特征值按照从大至小顺序进行排序,得到主成分个数,并根据主成分个数得到主成分特征;
17.步骤e:从两个方面选择初始分析变量进行分析,根据主成分特征的线性变换系数,得到初始分析变量到主成分特征的线性变换系数矩阵。
18.有益效果是:利用主成分分析,对累积效应特征和使用强度特征进行分析处理,并对累积效应特征进行标准化处理,保证数据都在0-1之间,有效避免了不同量纲的数据对于权重计算结果的干扰,能够保证新能源车辆在时间的累积效应特征得到准确的测试,提高完整性,能够保留特征中携带的信息,减少信息损失。
19.进一步,所述步骤b中,所述预设模型为(x1-min1)/(max1-min1),其中x1为初始分析变量的当前值,min1为多辆新能源汽车的经验特征数据中x1同类型初始分析变量的最小值,max1为多辆新能源汽车的经验特征数据中x1同类型初始分析变量的最大值。
20.有益效果是:按照预设模型对各个特征进行标准化处理,保证多个特质之间量纲的统一性,有效避免不同量纲的数据对于权重计算结果的干扰,以提高后续筛车特征与车辆风险状态之间映射关系的可靠性。
21.进一步,所述步骤d中,针对每个主成分特征计算特征贡献率,并对主成分特征的特征贡献率求和得到累计贡献率,当累计贡献率大于贡献阈值时,以累计贡献率大于贡献阈值的主成分特征为主成分个数,以主成分个数的主成分特征为最终主成分特征;所述步骤e中,将累计贡献率大于贡献阈值的多个主成分特征线性变换系数进行组合,得到线性变换系数矩阵。
22.有益效果是:通过计算累计贡献率,并以累计贡献率大于贡献阈值的多个主成分特征为最终主成分特征,在保留主成分特征对正样本和负样本区分度的前提下,能够对多个主成分特征进行筛选和降维。
23.进一步,所述步骤3中,基于每个主成分特征对正样本和负样本的特征分布进行对比,将负样本与正样本未重合部分车辆数量与负样本中车辆总数量的比值作为负样本区分度,将正样本与负样本未重合部分车辆数量与正样本中车辆总数量的比值作为正样本区分度,以负样本区分度和正样本区分度之和作为总区分度。
24.有益效果是:将最终得到的每个主成分特征用于对正样本和负样本进行区分,并计算对应的总区分度,保证主成分特征对正样本和负样本的区分能力最大。
25.进一步,所述步骤3中,将总区分度进行排序,以总区分度最大的两个主成分特征相减得到经验特征权重;
26.将总区分度最大的两个主成分特征与经验特征值作积,并将正样本作积并标准化后的20%分位数特征值作为特征筛选阈值;
27.计算总区分度最大的两个主成分特征的综合特征取值范围,根据特征取值范围确定超参数;
28.将经验特征权重、特征筛选阈值和超参数作为筛车综合特征。
29.有益效果是:将总区分度最大的两个主成分特征分析处理得到对应的筛车综合特征,并应有筛车综合特征进行筛车,从多个维度筛选得到,在达到预设里程前筛选出风险车辆,提高筛车准确性。
30.进一步,所述步骤3中,以总区分度最大的两个主成分特征各自的最大值减去最小值得到上边界值,以总区分度最大的两个主成分特征各自的最小值减去最大值得到下边界值,以[下边界值,上边界值]作为综合特征取值范围,将上边界值和下边界值确定为超参数。
[0031]
有益效果是:将确定的超参数用于筛车,能够将车辆特征的值统一至0-100的分值进行评价,更直观准确。
[0032]
进一步,所述步骤4中,将经验特征权重与待筛车的车辆数据作积得到初始值,将初始值在超参数条件下进行标准化得到评分值,将评分值与特征筛选阈值进行对比,当评分值大于特征筛选阈值时,对待评价车辆的风险进行评价。
[0033]
有益效果是:通过多个经验特征分析,重新定下的特征对新能源汽车进行筛选,能够筛选出最准确的高风险的新能源汽车,以提前发现新能源汽车在达到预设里程前的异常情况。
[0034]
存储介质,存储有计算机可执行程序,所述可执行程序被运行时执行上述方法的步骤。
附图说明
[0035]
图1为本发明在用新能源汽车的高风险车辆筛选方法实施例一的流程框图;
[0036]
图2为本发明在用新能源汽车的高风险车辆筛选方法实施例一中主成分特征对样本区分度的分布图;
[0037]
图3为本发明在用新能源汽车的高风险车辆筛选方法实施例一中新能源汽车风险判定阈值。
具体实施方式
[0038]
下面通过具体实施方式进一步详细说明。
[0039]
实施例一
[0040]
在用新能源汽车的高风险车辆筛选方法,如图1所示,包括以下步骤:
[0041]
步骤1,确定与新能源汽车安全状态相关联的多个经验特征,例如十台新能源汽车的经验特征如表1所示,实际计算时以十万台车的经验特征进行计算。
[0042]
表1十台新能源汽车的经验特征
[0043][0044]
计算多个经验特征之间的相关系数矩阵,相关系数矩阵通过对所获得的十万辆新能源汽车的多个经验特征以现有的公式进行计算,例如将十万辆新能源汽车的十二个经验特征组成12
×
100000的矩阵和100000
×
12的矩阵进行相关计算,得到12
×
12的矩阵,相关系数矩阵通过python软件中的函数进行计算,计算得到的相关系数矩阵如表2所示。
[0045]
表2相关系数矩阵
[0046][0047]
对相关系数矩阵中相关系数值大于阈值的经验特征的占比进行统计,阈值设置为0.3,判断占比是否大于预设值,占比按照相关系数值大于阈值的经验特征数量除以经验特征总数量来计算,预设值设置成56%,当占比大于预设值时,对经验特征进行主成分分析,得到主成分特征。从表2可知相关系数大于0.3的经验特征占比》56%,能够采用主成分分析方法对100000
×
12的经验特征进行降维和去重,对相关系数值大于阈值的经验特征的占比进行判断,能够保证主成分分析的效果以及分析结果的有效性。
[0048]
所述主成分分析步骤包括:
[0049]
步骤a:根据新能源汽车的分析需求选取初始分析变量,所述初始分析变量包括长时间尺度上的累积效应特征和使用强度特征,例如实施例中的初始分析变量即为总充电次数、快充次数、深充次数、高充次数、深放次数、出车天数、日均中位里程、快充占比、深充占比、高充占比、深放占比和最大里程,将十万辆新能源汽车的多个初始分析变量形成100000
×
12的矩阵。
[0050]
步骤b:将初始分析变量中的非标准化的累积效应特征按照预设模型进行标准化处理,初始分析变量即为经验特征,即对100000
×
12的矩阵中的总充电次数、快充次数、深充次数、高充次数、深放次数、出车天数、日均中位里程、最大里程的值进行标准化处理,预设模型为(x1-min1)/(max-min1),其中x1为当前初始分析变量的当前值,min1为多辆新能源汽车的经验特征数据中x1同类型初始分析变量的最小值,max1为多辆新能源汽车的经验
特征数据中x1同类型初始分析变量的最大值,以表1中的十台新能源汽车为例,针对矩阵中多个累积效应特征的每列数据进行标准化,例如对车辆1的单日里程中位数进行标准化处理得到标准化结果为(1240-100)/(1240-100)=1,对车辆2的单日里程中位数进行标准化处理得到标准化结果为(1040-100)/(1240-100)=0.8245614,以此方法依次对每个经验特征的值进行标准化处理,将多个经验特征的值变成0-1之间的值,从而统一多个经验特征的量纲。
[0051]
步骤c:对标准化后的初始分析变量特征求协方差矩阵,计算协方差矩阵的特征值和特征向量,将特征值,即对标准化后的100000
×
12矩阵求协方差矩阵的特征值与特征向量,求得的协方差矩阵为12
×
12的矩阵,特征值组成为1
×
12的矩阵,每个特征值表示为pca_x,x=1,2,3
…
12,特征向量表示为12
×
12的矩阵,协方差矩阵的计算以及对协方差矩阵求特征值和特征向量可用python软件中的函数进行,在此不再赘述。
[0052]
步骤d:将特征值按照从大至小顺序进行排序,并针对每个特征值计算特征贡献率,特征值对于的特征表示为pca特征,特征贡献率是指特征值在所考察的随机变量的总方差中所占的比例,并将特征贡献率求和得到累计贡献率,如表3所示,当累计贡献率大于贡献阈值时,以累计贡献率大于贡献阈值的特征值数量为主成分个数,贡献阈值可以设置成85%,以主成分个数的主成分特征为最终主成分特征,主成分特征为pca_1、pca_2、pca_3、pca_、pca_5。
[0053]
表3特征贡献率
[0054]
pca特征pca_1pca_2pca_3pca_4pca_5pca_6pca_7pca_8pca_9pca_10pca_11pca_12特征贡献率0.4090470.1969910.1251930.0836150.0636920.0418390.0295890.0225160.0128390.0072720.0055490.001857累计贡献率0.4090470.6060380.7312310.8148470.8785390.9203780.9499670.9724830.9853220.9925940.9981431
[0055]
从表3可知,前五个主成分的累计贡献率的和为87.854%,已经包含原特征中的绝大部分信息,选取前5个主成分特征,可起到降维与信息去重的作用。
[0056]
步骤e:将累计贡献率大于贡献阈值的多个主成分特征线性变换系数进行组合,根据主成分特征的线性变换系数,得到初始分析变量到主成分特征的线性变换系数矩阵,按特征值大小排列的特征向量矩阵即为该线性变化系数矩阵,如表4所示的线性变换系数矩阵。
[0057]
表4线性变换系数矩阵
[0058]
pca 1pca 2pca 3pca 4pca 5总充电状数0.334860.313980.265730.116200.12074快充次数0.334810.12889-0.420150.061940.34690深充次数0.357450.311050.15696-0.19081-0.03104高充次数0.37366-0.271230.15569-0.08709-0.01741深放次数0.33093-0.340060.213220.074810.09281出车天数0.236930.248480.413680.256030.32564日均中位里程0.259250.05183-0.189930.26900-0.69120快充占比0.22241-0.01936-0.64336-0.028380.35125深充占比0.233970.20597-0.03294-0.73044-0.22811高充占比0.27111-0.436350.03661-0.26628-0.05236深放占比0.13526-0.538840.052900.130780.05372
最大里程0.283170.10422-0.173750.41570-0.30060
[0059]
步骤2,获取运行中新能源汽车预设时间段内行驶的运行数据,根据累计行驶里程是否大于预设里程将新能源汽车的运行数据分成正样本和负样本,预设里程为八万公里,将累计行驶里程大于预设里程的新能源汽车划分为负样本,将累计行驶里程小于预设李里程的新能源汽车划分为正样本。
[0060]
步骤3,如图2和图3所示,图2和图3中的横坐标为每个主成分特征的特征值,纵坐标为新能源汽车的数量。基于每个主成分特征对正样本和负样本的特征分布进行对比,得到正样本与负样本的特征分布的总区分度,总区分度包括正样本区分度和正样本区分度,负样本区分度为图2中负样本与正样本未重合部分车辆数量与负样本中车辆总数量的比值,正样本区分度为图2中正样本与负样本未重合部分车辆数量与正样本中车辆总数量的比值,以负样本区分度和正样本区分度之和作为总区分度,图3中黑色框内的部分为正样本和负样本的重叠区域。
[0061]
将总区分度进行排序,以总区分度最大的两个主成分特征相减得到经验特征权重,即将表4中的pca_1-pca_2得到的12
×
1的矩阵表示经验特征权重。
[0062]
如图3所示,将总区分度最大的两个主成分特征与经验特征值作积,并将正样本作积并标准化后的20%分位数特征值作为特征筛选阈值,例如经验特征值为100000
×
12矩阵,总区分度最大的两个主成分特征作差后的经验特征权重表示为12
×
1的矩阵,作积后得到100000
×
1的矩阵,对该矩阵中的值进行标准化,标准化的公式为(x-min2)/(max2-min2),其中:x为该矩阵中任一个值,min2为该矩阵中的最小值,max2为该矩阵中的最大值,20%为经验值,是结合大数据统计分析结果,经过试验能够尽可能多包含正样本而少包含负样本的阈值。
[0063]
计算总区分度最大的两个主成分特征的综合特征取值范围,以总区分度最大的两个主成分特征各自的最大值减去最小值得到上边界值,即(pca_1)max-(pca_2)min=上边界值,以总区分度最大的两个主成分特征各自的最小值减去最大值得到下边界值,即(pca_1)min-(pca_2)max=下边界值,例如,从图2可以得到综合特征取值范围为[-16,14],将综合特征取值范围的上边界值表示为max3,将综合特征取值范围的下边界值表示为min3,将max3和min3作为超参数。
[0064]
以经验特征权重、超参数和筛选特征阈值作为筛车综合特征。
[0065]
步骤4,以步骤3中的筛车综合特征对待筛车的数据进行筛选,将经验特征权重与待筛车的车辆数据作积得到初始值,将初始值在超参数条件下进行标准化得到评分值,将评分值与特征筛选阈值进行对比,当评分值大于特征筛选阈值时,对待评价车辆的风险进行评价,车辆的风险评价使用现有技术,在此不再赘述。
[0066]
由于目前针对筛车普遍是以一年内行驶八万公里的时间和行程参量为尺度,筛选出高风险的新能源汽车,一年内八万公里的判断能够筛选出高风险车,故普遍均是利用该时间和里程参数进行高风险车的筛选,但影响新能源汽车安全性的因素很多,现有的时间和里程参数筛选方法不能绝对地评价车辆是否为高风险车,且时间和里程为评价尺度,评价尺度非常单一,无法准确筛选出行驶里程小于八万公里部分车辆中的风险车辆。而本实施例通过先以新能源汽车经验特征的相关系数矩阵进行主成分分析,得到主成分特征,并判断主成分特征对正样本和负样本特征分布的区分能力,并将区分能力较大的主成分特征
综合处理,得到筛车综合特征,在实际进行高风险车辆筛选是,利用筛车综合特征进行高风险新能源汽车的筛选。本实施例无需再次计算相关系数矩阵,筛选高风险车辆的速度不会被降低,同时,从多个方面进行高风险车辆的筛选,能够有效筛选出未达到高风险评价标准之前且又具有高风险的在用新能源汽车。
[0067]
实施例二
[0068]
存储介质,存储有计算机可执行程序,计算机可执行程序被运行时执行如实施例一中在用新能源汽车的高风险车辆筛选方法的步骤。
[0069]
本实施例通过存储介质中的在用新能源汽车的高风险车辆筛选方法,先对新能源汽车的多个经验特征进行分析得到主成分特征,并验证主成分特征对正样本和负样本的区分性,最后构造得到新的筛车综合特征,利用筛车综合特征进行筛车。即时在研发过程中,想到利用多特征进行筛车,但是,普遍都是利用多特征结合进行筛车,毕竟多个经验特征对于车辆的影响结果是已知,在已知影响结果基础上改进提高筛车效果比较有效,而所构造的新的特征对于筛车效果未知,研发时一般不会想到构造新的特征进行筛车。
[0070]
以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本技术要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1