一种无监督能耗异常检测方法、装置及存储介质与流程
1.本发明涉及数据挖掘技术领域,尤其是指一种无监督能耗异常检测方法、设备、装置及计算机存储介质。
背景技术:
2.随着人民生活水平的提高,狭义的建筑能耗,即建筑的运行能耗,就是人们日常用能,如采暖、空调、照明、炊事、洗衣等的能耗,迅速上升,可见我们对家庭用电能耗的异常检测是非常必要的。
3.目前,针对用电行为的异常检测方法主要是有监督的方法,该方法的问题在于需要利用有标签的数据集对模型进行训练,然而在很多现实场景中,对数据进行人工标记的成本过高;并且异常用电行为发生的概率较低,没有进行预处理的能耗数据,通常因为一些冗余信息的干扰,使得异常检测模型对于异常用电行为不敏感,异常检测的精度低。
4.因此如何提供一种成本低、精确度更高的无监督能耗异常检测方法是目前待解决的问题。
技术实现要素:
5.为此,本发明所要解决的技术问题在于克服现有技术中有监督异常检测方法成本大、精度低的问题。
6.为解决上述技术问题,本发明提供了一种无监督能耗异常检测方法、设备、装置及计算机存储介质,包括:
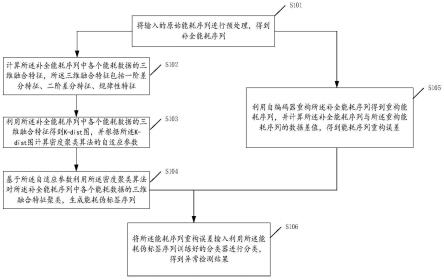
7.将输入的原始能耗序列进行预处理,得到补全能耗序列;
8.计算所述补全能耗序列中各个能耗数据的三维融合特征,所述三维融合特征包括一阶差分特征、二阶差分特征、规律性特征;
9.利用所述补全能耗序列中各个能耗数据的三维融合特征得到k-dist图,并根据所述k-dist图计算密度聚类算法的自适应参数;
10.基于所述自适应参数利用所述密度聚类算法对所述补全能耗序列中各个能耗数据的三维融合特征聚类,生成能耗伪标签序列;
11.利用自编码器重构所述补全能耗序列得到重构能耗序列,并计算所述补全能耗序列与所述重构能耗序列的数据差值,得到能耗序列重构误差;
12.将所述能耗序列重构误差输入利用所述能耗伪标签序列训练后的分类器进行分类,得到异常检测结果。
13.优选地,所述利用所述能耗伪标签序列训练分类器包括:
14.将所述能耗序列重构误差按预设比例划分出能耗序列重构误差训练集;
15.利用smote算法对能耗序列重构误差训练集中的异常样本进行重采样;
16.将重采样后的能耗序列重构误差训练集输入所述分类器,并利用所述能耗伪标签序列对所述分类器进行训练。
17.优选地,所述将输入的原始能耗序列进行预处理,得到补全能耗序列包括:
18.设置长度为k的滑动窗口,计算所述滑动窗口中的所述原始能耗序列{xi,x
i+1
,
…
,x
i+k
}的均值利用μ对所述原始能耗序列的缺失值进行补全;
19.对补全后的所述原始能耗序列进行归一化得到所述补全能耗序列x={x1,x2,
…
,xn},n为能耗数据点个数。
20.优选地,所述计算所述补全能耗序列的三维融合特征包括:
21.分别提取所述补全能耗序列x中i时刻的能耗值xi的一阶差分特征f
id1
、二阶差分特征f
id2
、规律性特征f
ir
,构成所述三维融合特征(f
id1
,f
id2
,f
ir
)。
22.优选地,所述利用所述补全能耗序列中各个能耗数据的三维融合特征得到k-dist图,并根据所述k-dist图计算密度聚类算法的自适应参数包括:
23.计算所述补全能耗序列中各个能耗数据的三维融合特征到其第k个近邻融合特征点的距离d,得到k-dist序列{d1,d2,
…
,dn};
24.对所述k-dist序列递增排序得到k-dist图;
25.通过所述k-dist图计算出dbscan算法的自适应参数eps。
26.优选地,所述基于所述自适应参数利用所述密度聚类算法对所述补全能耗序列中各个能耗数据的三维融合特征聚类,生成能耗伪标签序列包括:
27.基于所述自适应参数利用所述dbscan算法对所述补全能耗序列中各个能耗数据的三维融合特征聚类,得到多个能耗模式簇;
28.将聚类后不属于任何所述能耗模式簇的离群三维融合特征点标记为异常点,将其他三维融合特征点标记为正常点,生成所述能耗伪标签序列:
[0029][0030]
优选地,所述利用自编码器重构所述补全能耗序列得到重构能耗序列,并计算所述补全能耗序列与所述重构能耗序列的数据差值,得到能耗序列重构误差包括:
[0031]
采用滑动窗口机制,基于lstm网络构建自编码器模型重建所述补全能耗序列,得到重构能耗序列;
[0032]
计算所述补全能耗序列与重构能耗序列的数据差值,得到能耗序列重构误差。
[0033]
本发明还提供了一种无监督能耗异常检测装置,包括:
[0034]
预处理模块,将输入的原始能耗序列进行预处理,得到补全能耗序列;
[0035]
三维融合特征计算模块,计算所述补全能耗序列中各个能耗数据的三维融合特征,所述三维融合特征包括一阶差分特征、二阶差分特征、规律性特征;
[0036]
自适应参数计算模块,利用所述补全能耗序列中各个能耗数据的三维融合特征得到k-dist图,并根据所述k-dist图计算密度聚类算法的自适应参数;
[0037]
伪标签序列生成模块,基于所述自适应参数利用所述密度聚类算法对所述补全能耗序列中各个能耗数据的三维融合特征聚类,生成能耗伪标签序列;
[0038]
重构误差计算模块,利用自编码器重构所述补全能耗序列得到重构能耗序列,并计算所述补全能耗序列与所述重构能耗序列的数据差值,得到能耗序列重构误差;
[0039]
异常检测模块,将所述能耗序列重构误差输入利用所述能耗伪标签序列训练后的分类器进行分类,得到异常检测结果。
[0040]
本发明还提供了一种无监督能耗异常检测设备,包括:
[0041]
存储器,用于存储计算机程序;
[0042]
处理器,用于执行所述计算机程序时实现上述一种无监督能耗异常检测方法的步骤。
[0043]
本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述一种无监督能耗异常检测的方法的步骤。
[0044]
本发明的上述技术方案相比现有技术具有以下优点:
[0045]
本发明通过计算三维融合特征,提取的能耗数据差分特征以及规律性特征,更精准地描述了能耗数据序列,避免了冗余特征的干扰,提升计算速度的同时有效提升了异常检测精度;通过自适应的密度聚类算法提取能耗序列的伪标签,避免了有监督异常检测模型对于有标签数据依赖的问题;不需要设定聚类类别数,这使得本发明适用于能耗模式簇数量未知时的场景;自适应参数机制,充分利用了能耗数据的多种特征,增强了对不同能耗场景的泛化能力,使得本发明的方法更适用于现实任务;利用伪标签指导重构误差的分类,克服了对重构误差进行分类需要设定阈值的困难,并且本发明的异常检测精度也优于设定固定阈值对重构误差进行分类。本发明采用无监督异常检测方法,降低了人工成本,更加适用于现实场景,并提升了异常检测精度和速度。
附图说明
[0046]
为了使本发明的内容更容易被清楚的理解,下面根据本发明的具体实施例并结合附图,对本发明作进一步详细的说明,其中:
[0047]
图1是本发明无监督能耗异常检测方法的实现流程图;
[0048]
图2是本发明的算法流程图;
[0049]
图3是本发明的k-dist图;
[0050]
图4是lstm自编码器模型图;
[0051]
图5为本发明实施例提供的一种无监督能耗异常检测装置的结构框图。
具体实施方式
[0052]
本发明的核心是提供一种无监督能耗异常检测方法、装置、设备及计算机存储介质,降低了人工成本高、提高了检测精度。
[0053]
为了使本技术领域的人员更好地理解本发明方案,下面结合附图和具体实施方式对本发明作进一步的详细说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0054]
请参考图1,图1为本发明所提供的无监督能耗异常检测方法的实现流程图;具体操作步骤如下:
[0055]
s101:将输入的原始能耗序列进行预处理,得到补全能耗序列;
[0056]
设置长度为k的滑动窗口,计算所述滑动窗口中的所述原始能耗序列{xi,x
i+1
,
…
,
x
i+k
}的均值利用μ对所述原始能耗序列的缺失值进行补全;
[0057]
对补全后的所述原始能耗序列进行归一化得到所述补全能耗序列x={x1,x2,
…
,xn},n为能耗数据点个数。
[0058]
s102:计算所述补全能耗序列中各个能耗数据的三维融合特征,所述三维融合特征包括一阶差分特征、二阶差分特征、规律性特征;
[0059]
分别提取所述补全能耗序列x中i时刻的能耗值xi的一阶差分特征f
id1
、二阶差分特征f
id2
、规律性特征f
ir
,构成所述三维融合特征(f
id1
,f
id2
,f
ir
)。
[0060]
s103:利用所述补全能耗序列中各个能耗数据的三维融合特征得到k-dist图,并根据所述k-dist图计算密度聚类算法的自适应参数;
[0061]
计算所述补全能耗序列中各个能耗数据的三维融合特征到其第k个近邻融合特征点的距离d,得到k-dist序列{d1,d2,
…
,dn};
[0062]
对所述k-dist序列递增排序得到k-dist图;
[0063]
通过所述k-dist图计算出dbscan算法的自适应参数eps。
[0064]
s104:基于所述自适应参数利用所述密度聚类算法对所述补全能耗序列中各个能耗数据的三维融合特征聚类,生成能耗伪标签序列;
[0065]
基于所述自适应参数利用所述dbscan算法对所述补全能耗序列中各个能耗数据的三维融合特征聚类,得到多个能耗模式簇;
[0066]
将聚类后不属于任何所述能耗模式簇的离群三维融合特征点标记为异常点,将其他三维融合特征点标记为正常点,生成所述能耗伪标签序列:
[0067][0068]
s105:利用自编码器重构所述补全能耗序列得到重构能耗序列,并计算所述补全能耗序列与所述重构能耗序列的数据差值,得到能耗序列重构误差;
[0069]
采用滑动窗口机制,基于lstm网络构建自编码器模型重建所述补全能耗序列,得到重构能耗序列;
[0070]
计算所述补全能耗序列与重构能耗序列的数据差值,得到能耗序列重构误差。
[0071]
s106:将所述能耗序列重构误差输入利用所述能耗伪标签序列训练后的分类器进行分类,得到异常检测结果。
[0072]
将所述能耗序列重构误差按预设比例划分出能耗序列重构误差训练集;
[0073]
利用smote算法对能耗序列重构误差训练集中的异常样本进行重采样;
[0074]
将重采样后的能耗序列重构误差训练集输入所述分类器,并利用所述能耗伪标签序列对所述分类器进行训练。
[0075]
图2表示本发明的算法模型图。算法为无监督框架,适用于现实应用场景中的无标签数据。模型包括三维融合特征提取模块、dbscan聚类获取伪标签模块、lstm自动编码器重建能耗数据模块以及异常分类器模块四个关键部分。其中,左上框图中包括三维融合特征提取以及获取伪标签,获取伪标签模块采用自适应参数的dbscan算法。下方框图中包含lstm自编码器,这一重构能耗数据网络利用lstm构建。最终,伪标签用于指导重构误差的分类任务,实现异常检测功能。
[0076]
本发明通过计算三维融合特征,提取的能耗数据差分特征以及规律性特征,更精
准地描述了能耗数据序列,避免了冗余特征的干扰,提升计算速度的同时有效提升了异常检测精度;通过自适应的密度聚类算法提取能耗序列的伪标签,避免了有监督异常检测模型对于有标签数据依赖的问题;不需要设定聚类类别数,这使得本发明适用于能耗模式簇数量未知时的场景;自适应参数机制,充分利用了能耗数据的多种特征,增强了对不同能耗场景的泛化能力,使得本发明的方法更适用于现实任务;利用smote对异常样本重采样,使得正负样本均衡,提升了模型对用电异常的敏感度;利用lstm自动编码器对能耗数据进行重建,充分提取了时序信息;利用伪标签指导重构误差的分类,克服了对重构误差进行分类需要设定阈值的困难,并且本发明的异常检测精度也优于设定固定阈值对重构误差进行分类。本发明利用伪标签指导重构误差分类,实现了无监督异常检测,克服了对标签数据的依赖。特别是,提取了能耗数据的关键特征,并采用了一种自适应参数的dbscan算法来生成能耗数据的伪标签,以避免不同的场景中参数选择困难的问题。利用lstm自动编码器对能耗数据进行重建,充分提取了时序信息,将正负样本均衡化,利用伪标签指导重构误差的分类,使得分类效果更好,实现了更高的异常检测精度。
[0077]
基于以上实施例,本发明对以上步骤进行进一步详细说明,具体如下:
[0078]
s201:假设x
i-1
为缺失值,设置长度为k的滑动窗口,计算所述滑动窗口中的所述原始能耗序列{xi,x
i+1
,
…
,x
i+k
}的均值利用μ对所述原始能耗序列的缺失值x
i-1
进行补全;
[0079]
本实施例中k=8;
[0080]
该步骤也可更换为其他缺失值补全方法,如极大似然估计,多重插补等方法。
[0081]
s202:分别提取所述补全能耗序列x中i时刻的能耗值xi(i∈1,2,
…
,n)的一阶差分特征f
id1
=x
i-x
i-1
、二阶差分特征f
id2
=x
i-x
i-2
、规律性特征f
ir
=xi,构成所述三维融合特征(f
id1
,f
id2
,f
ir
);
[0082]
其中,规律性特征f
ir
提取步骤如下:首先,将原始数据分成p个子序列,其集合s可以表示为s={s1,s2,
…
,s
p
},其中第m个序列的计算方式为sm={xm,x
m+p
,
…
,x
m+k*p
},m∈1,2,
…
,p,m+k*p≤n《m+(k+1)*p,其次计算每个子序列的中位数xi的规律性特征表示为f
ir
=xi;
[0083]
本实施例中p=24。
[0084]
s203:以三维融合特征作为输入,基于欧式距离,计算每个融合特征(f
id1
,f
id2
,f
ir
)到其第k个近邻融合特征点的距离d,得到k-dist序列{d1,d2,
…
,dn},对k-dist做递增排序,得到的k-dist图,基于k-dist图中的拐点计算dbscan定义邻域半径的参数eps;
[0085]
所述k-dist图如图3所示;
[0086]
本实施例中k为5,dbscan阈值minpts也设置为5;
[0087]
本发明计算拐点的具体实现如下:lstm图中除开始点s及结束点e外的其他点i表示为为点i到开始点s的向量表示为点i到结束点e的向量表示为两个向量之间的夹角的余弦表示为
计算k-dist图中除开始点及结束点外所有点的向量和向量的cosθ值,cosθ值最小的点即定义为拐点d
turning
,得到拐点的k-dist值此外,k-dist图中的中位数点的值表示为计算自适应参数eps的方法表示为
[0088]
本实施例中α=2,β=1。
[0089]
s204:基于得到的自适应参数eps,应用dbscan聚类算法对所述补全能耗序列中各个能耗数据的三维融合特征进行聚类,得到不同的能耗模式簇,将不属于任何模式簇的离群三维融合特征点标记为异常点,将其他三维融合特征点标记为正常点,得到能耗伪标签序列;
[0090]
本实施例中,密度聚类算法采用dbscan算法,可以变换为其他密度聚类算法,例如,密度最大值聚类算法mdca(maximum density clustering algorithm))等。
[0091]
s205:利用滑动窗口机制,提取能耗序列{xi,x
i+1
,
…
,x
i+u
},其中u为滑动窗口的长度,将能耗序列送入lstm自编码器模型,提取时序信息,利用最后一个单元的输出重建能耗x
′i,得到重构能耗序列{x
′i,x
′
i+1
,
…
,x
′
i+u
},计算计算所述补全能耗序列与所述重构能耗序列的数据差值得到重构误差序列{x
′i,x
′
i+1
,
…
,x
′
i+u
}{x
′i,x
′
i+1
,
…
,x
′
i+u
};
[0092]
所述lstm自编码器模型图如图4所示,本实施例中设置u为128;
[0093]
对于重构误差,利用smote对异常样本重采样,使得正负样本均衡;
[0094]
本实施例中重采样后正常样本与异常样本的比例设置为1:1。
[0095]
s206:利用能耗伪标签序列,指导重构误差分类器的训练,利用训练好的分类器进行异常检测。
[0096]
本实施例中采用单层神经网络作为分类器,其输入为重构误差序列,利用获取的能耗伪标签序列指导神经网络的训练,得到训练好的分类器用于重构误差的分类,执行异常检测。
[0097]
基于以上实施例,本实施例为验证本发明的准确性和鲁棒性,本发明在某高校能耗数据集上进行了实验,具体如下:
[0098]
该能耗数据集包含12座不同用途建筑物的能耗数据,建筑用途包括住宿、科研、教学、食堂。数据起止时间为2020.6.1-2020.12.31,采样率为每小时一个数据点,总计157248个采样点。
[0099]
在实验中,将数据集划均分成两部分,作为训练集与测试集。其中,训练集中的异常比例为0.09%,测试集中的异常比例为0.06%,实验中,选择精准率precision,召回率recall与f1 score作为评价指标。
[0100]
本实施例中,训练lstm自编码器以及训练重构误差分类的单层神经网络的参数如表1所示:
[0101]
表1实验参数设置
[0102]
模型训练样本数测试样本数学习率迭代次数
lstm自编码器占1/2占1/20.000350重构误差分类网络占1/2占1/20.00150
[0103]
本发明为了验证提出的伪标签异常检测无监督框架plad的优势,进行的对比实验如表2所示,比较对象为基于knn、cblof、if、hbos、pca的无监督异常检测模型,本发明在指标上均达到了最优性能:
[0104]
表2对比实验结果
[0105]
方法precisionrecallf1 scoreplad0.99980.98380.9918knn0.99950.90920.9522cblof0.99970.89650.9453if0.99980.89400.9440hbos0.99970.9602.0.9795pca0.99980.89720.9457
[0106]
本发明公开了利用伪标签指导重构误差分类的无监督能耗异常检测方法plad。该方法提出了一种自适应伪标签异常检测框架,利用伪标签指导能耗数据重构误差的分类,克服了有监督异常检测方法对于标签数据的依赖。本发明设计的异常检测框架含有两部分:自适应伪标签部分和lstm自动编码器部分。自适应伪标签部分先从能耗数据中提取差分特征以及规律性特征,并通过这些特征得到k-dist图,再利用k-dist图获取dbscan算法的自适应参数,生成能耗数据的伪标签,解决了在不同场景下参数选择困难的问题。lstm自动编码器部分对能耗数据进行重构,得到能耗数据的重构误差。最终,本发明将两个部分结合,利用伪标签指导能耗数据重构误差的分类,得到能耗数据异常检测的结果。
[0107]
请参考图5,图5为本发明实施例提供的一种无监督能耗异常检测装置的结构框图;具体装置可以包括:
[0108]
预处理模块100,用于将输入的原始能耗序列进行预处理,得到补全能耗序列;
[0109]
三维融合特征计算模块200,用于计算所述补全能耗序列中各个能耗数据的三维融合特征,所述三维融合特征包括一阶差分特征、二阶差分特征、规律性特征;
[0110]
自适应参数计算模块300,用于利用所述补全能耗序列中各个能耗数据的三维融合特征得到k-dist图,并根据所述k-dist图计算密度聚类算法的自适应参数;
[0111]
伪标签序列生成模块400,用于基于所述自适应参数利用所述密度聚类算法对所述补全能耗序列中各个能耗数据的三维融合特征聚类,生成能耗伪标签序列;
[0112]
重构误差计算模块500,用于利用自编码器重构所述补全能耗序列得到重构能耗序列,并计算所述补全能耗序列与所述重构能耗序列的数据差值,得到能耗序列重构误差;
[0113]
异常检测模块600,用于将所述能耗序列重构误差输入利用所述能耗伪标签序列训练得到的分类器进行分类,得到异常检测结果。
[0114]
本实施例的无监督能耗异常检测装置用于实现前述的无监督能耗异常检测方法,因此无监督能耗异常检测装置中的具体实施方式可见前文无监督能耗异常检测方法的实施例部分,例如,预处理模块100,三维融合特征计算模块200,自适应参数计算模块300,伪标签序列生成模块400,重构误差计算模块500,异常检测模块600,分别用于实现上述无监督能耗异常检测方法中步骤s101,s102,s103,s104、s105和s106,所以,其具体实施方式可
以参照相应的各个部分实施例的描述,在此不再赘述。
[0115]
本发明具体实施例还提供了一种无监督能耗异常检测的设备,包括:存储器,用于存储计算机程序;处理器,用于执行所述计算机程序时实现上述一种无监督能耗异常检测的方法的步骤。
[0116]
本发明具体实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述一种无监督能耗异常检测的方法的步骤。
[0117]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0118]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0119]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0120]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0121]
显然,上述实施例仅仅是为清楚地说明所作的举例,并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引伸出的显而易见的变化或变动仍处于本发明创造的保护范围之中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1