一种基于运动协同空间的人体行为识别方法
1.本发明涉及人体行为识别方法,尤其涉及一种基于运动协同空间的人体行为识别方法。
背景技术:
2.人体行为识别是计算机视觉领域中的研究热点之一,许多研究成果已经在图像分析、人机交互、智能监控、视频检索、体感游戏以及健康检测等领域中有了广泛的应用。
3.行为识别的相关研究可以追溯到1973年johansson的一项实验(gunnar johansson.(1973)visual perception of biological motion and a model for its analysis in perception&psychophysics 1973.vol.14.no.2.201
·
211),通过使用10-12个人体关键节点的移动来描述人体运动,识别人体行为。行为识别研究在早期主要基于rgb视频序列,但受光照、视角、背景等因素限制,使基于图像视频的行为识别具有一定的局限性。随着成像技术的发展,尤其是深度相机的推出,人体行为识别的研究对象也开始由最初的rgb图像向深度图像发展。相比之前的rgb图像,由结构光深度传感器采集的深度图序列对光照变化不敏感,而且提供了人体行为的深度数据。
4.因骨骼数据克服了光照、背景等因素的影响,能够准确地提供人体关节点的坐标,更加直接地描述人体行为。传感器如微软kinect和一些先进的人体姿态估计算法使得我们更容易获得准确的3d骨骼数据。运用骨架序列能很好地克服外观因素的影响,具有特征明确简单、空间信息相关性强等优点。所以,骨骼数据在人类行为识别和检测方面受到了越来越多的研究人员的关注,骨骼数据的应用越来越广泛:shotton等人(shotton jamie,sharp toby,kipman alex,et al.real-time human pose recognition in parts from single depth images[j].communications of the association for computing machinery,2013,56(1):116-124)提出了一种新的方法,从深度图像中预测人体关节点的位置。lv等人(lv,f.and nevatia,r.(2006)recognition and segmentation of 3-d human action using hmm and multi-class adaboost.in euro-pean conference on computer vision,pp.359
–
372.springer.)通过将高维三维关节空间分解为一组特征空间,引入了基于骨骼关节的动作识别系统。每个特征都与单个关节或相应的多个关节的组合运动相关联。此外,xia等人(xia,l.,chen,c.-c.and aggarwal,j.k.(2012)view invariant human action recognition using histograms of 3d joints.in 2012ieee computer society conf.computer vision and pattern recognition workshops(cvprw),pp.20
–
27.ieee.)还提出了hoj3d特征来表征人类的多种行为。此外,yang等人(yang,x.and tian,y.l.(2012)eigenjoints-based action recognition using naive-bayes-nearest-neighbor.in 2012ieee computer society conf.computer vision and pattern recognition workshops(cvprw),pp.14
–
19.ieee)利用人体骨骼关节的位置、关节的时间位移和关节相对于人体骨骼初始框架的偏移量来表示人体动作。但这些识别方法依然较为单一,且对于骨骼数据的应用,不能够很好地反映出人体动作的整体性与协同性。
技术实现要素:
[0005]
发明目的:本发明的目的是提供一种利用运动状态衡量系数来判断各骨骼点对于人体运动的贡献程度,再在处理后的关键帧序列中提取运动协同空间特征,能提升识别率的人体行为识别方法。
[0006]
技术方案:本发明的人体行为识别方法,包括步骤:
[0007]
s1,对于初始骨骼序列和深度图序列分别进行基于运动状态衡量系数的关键帧提取;
[0008]
s2,对步骤s1处理后的骨骼序列,提取运动协同空间向量,并拼接成运动协同空间特征;对步骤s1处理后的深度图序列提取dmm特征,得到深度运动图;
[0009]
s3,将深度运动图和运动协同空间特征同时输入深度网络,进行分数融合。
[0010]
进一步,所述步骤s2中,在提取运动协同空间向量时,各关节的向量计算原则如下:根据各关节点的运动变化幅度,各关节点分别乘上各关节点相应的运动状态衡量系数后再相加。
[0011]
进一步,所述各关节点相应的运动状态衡量系数的实现步骤如下:
[0012]
s21,以spine点为原点坐标,将相邻两帧图像之间指向同一骨骼点的两个空间向量所形成的三角形的面积为s,夹角为θ;
[0013]
当θ∈(0,90
°
]时:
[0014][0015]
当角度变化大于90
°
时,表示该部位的运动幅度更大,为确保s与运动幅度继续保持正相关,当θ∈(90
°
,180
°
]时:
[0016][0017]
其中,joint_1、joint_2分别表示前后两帧图像中描述关节运动状态的空间向量;
[0018]
s22,将两个空间向量分别向xoy面、yoz面、xoz面投影后再分别计算面积s
xoy
、s
yoz
、s
xoz
;将一个完整的骨骼图动作序列leftarm、rightarm、leftleg、rightleg区域的n帧图像依次处理:
[0019][0020]
s23,再将同一区域内的值做归一化处理后,得到运动状态衡量系数w
joint
:
[0021][0022]
进一步,所述各关节点相应的运动状态衡量系数的关键帧提取时,根据相邻两帧图像之间动作变化的差异,从两帧图像中抽出一帧,用剩下的另一帧图像来代表该相邻两帧图像;
[0023]
相邻两帧之间动作变化的差异判断原则如下:将相邻两帧图像之间所有部位的运动状态衡量系数加起来,得到的值越大,相邻两帧之间动作的差异越大,反之则说明差异越小;实现步骤如下:
[0024]
s031:依次计算相邻两帧图像之间所有区域的运动状态衡量系数之和,得到n-1项
运动状态衡量系数的集合:
[0025]
{w1,w2,w3…wn-1
};
[0026]
s032:将相邻两项运动状态衡量系数相加,得到衡量关键帧的动作变化参数ci:
[0027]ci
=wi+w
i+1
,i∈(1,n-2);
[0028]
s033:将ci按照大小排序,若第i项为最小值,则将第i+1帧图像删去:
[0029]cdelete
=min{c1,c2,c3…cn-2
};
[0030]
重复步骤s031-s033,直到得到满足描述人体行为的关键帧序列为止。
[0031]
进一步,所述步骤s3中,所述深度网络选用小型卷积神经网络vgg-16,共训练四个卷积神经网络,一个用于运动协同空间特征提取骨骼特征,另外三个分别用于dmm的三视图提取深度特征,最后使用加权融合法与乘积法对训练得到的分数进行融合。
[0032]
本发明与现有技术相比,其显著效果如下:
[0033]
1、针对人体运动的整体性与协同性的特点,在人体骨骼数据的基础上,提出了一种可以综合各关节点信息的运动协同空间特征模型;
[0034]
2、对各关节点参与运动的贡献程度提出了一种新的量化标准,运动状态衡量系数;基于运动状态衡量系数提出了一种新的关键帧提取方法,去除了冗余数据,提高了计算效率;
[0035]
3、基于多模态融合的思想,将骨骼数据与深度数据进行结合,使数据更加完整,实现多种异质信息的互补,剔除模态间的冗余性,建立了一种新的行为识别方法体系,为人体行为识别方法研究和应用提供新的思路和理论依据。
附图说明
[0036]
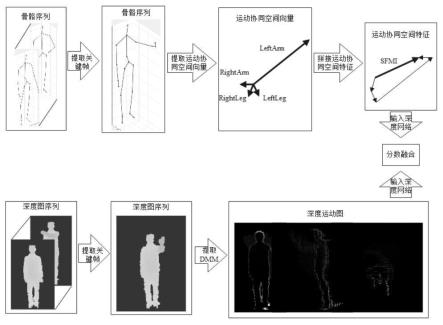
图1为本发明的总框架示意图;
[0037]
图2为本发明的人体区域图;
[0038]
图3为本发明的左上肢区域图;
[0039]
图4为本发明的运动状态衡量系数示意图;
[0040]
图5为本发明的vgg-16网络结构图;
[0041]
图6为本发明的提取关键帧效果图。
具体实施方式
[0042]
下面结合说明书附图和具体实施方式对本发明做进一步详细描述。
[0043]
本发明使用运动状态衡量系数来描述每个动作中人体各个部位的运动变化情况,将单独的骨骼数据合并成综合向量。并通过关键帧去除了冗余数据,减少计算量,再与深度特征进行融合,达到了较好的识别效果。
[0044]
本发明对于初始骨骼序列与深度图序列进行基于运动状态衡量系数的关键帧提取,再对处理后的骨骼序列提取运动协同空间向量,拼接成运动协同空间特征;对处理后的深度图序列提取dmm特征。最后将基于深度数据的dmm(深度运动图)特征与基于骨骼数据的sfmi特征相融合,提供了一种利用多模态对人体行为进行识别的方法,总体框架如图1所示。
[0045]
(一)运动协同空间特征
[0046]
人体在做各种动作时,身体各部位运动情况不尽相同。现有的基于骨骼数据的行为识别大都单独地利用各个骨骼节点信息,而人体动作过程中各关节部位是相互协同、相互作用的,人体运动具有整体性、协同性的特点。为了能够更好地反映这些特点,本发明提出了运动协同空间向量。
[0047]
(11)确定运动协同空间向量
[0048]
人体在运动过程中,躯干部分往往是相对稳定的,而四肢部分是相对活跃的。即:相邻两帧图像之间,人的四肢部分的变化往往更大。因此,相对于容易产生重复信息的躯干部份,四肢部分运动产生的时间空间信息对行为识别是更有帮助的。
[0049]
因此,本发明将人体划分为leftarm、rightarm、leftleg、rightleg四个区域,如图2所示。在每个区域内计算表示该肢体的运动协同空间向量,描述四肢运动,体现整体性与协同性。
[0050]
以leftarm区域为例,运动协同空间向量的具体描述如图3所示,左上肢共有四个骨骼点:leftshoulder(左肩)、leftelbow(左肘)、leftwrist(左腕)和lefthand(左手),以spine点为中心,各个关节点的状态可分别由左肩向量左肘向量左腕向量左手向量来描述。左上肢的某一运动是由该四个向量整体作用、协同决定的。
[0051]
直接简单地将各向量进行拼接虽然能反应各骨骼点的运动,却不能精确地反映出各关节点对于整体运动状态的贡献程度。如左手挥手动作中,仅左上肢运动变化较为明显,且在左上肢的四个骨骼点中,左手(lefthand)的运动幅度也要比左肩(leftshoulder)的运动幅度更大。为了更好的识别人体动作,本发明结合各部位的运动状态,提出运动协同空间向量,以期能够更准确的反映出运动的整体性与协同性。
[0052]
依然以左上肢为例,根据各关节点的运动变化幅度,给予相应的权重,即乘上各关节点相应的w(运动状态衡量系数)后再相加,对于左上肢运动状态的描述更为精确,则表达式为:
[0053][0054]
其中,w
ls
、w
le
、w
lw
、w
lh
分别为左肩、左肘、左腕、左手部位的运动状态衡量系数。
[0055]
根据公式(1)求得,分别描述四肢运动的(左上肢区域运动协同空间向量)、(右上肢区域运动协同空间向量)、(左下肢区域运动协同空间向量)、(右下肢区域运动协同空间向量)后,再根据各运动协同空间向量相应的运动状态衡量系数将其拼接为运动协同空间特征(spatial features of motion coordination),则表达式为:
[0056][0057]
(12)确定运动状态衡量系数
[0058]
由于不同动作中,人体各部位的变化幅度不同,就各关节点的向量而言,可以从向量长度、转动角度这两方面来评估各部位的运动状态。向量长度、转动角度变化幅度越大,就说明该部位运动更剧烈,对于运动状态的贡献就越高。
[0059]
不同时刻同一关节点构成的两个向量之间相夹的面积,可以兼顾长度和角度两个属性,很好的描述该节点的运动变化幅度,基于此思路,本发明提出了运动状态衡量系数w。
[0060]
以leftarm区域中相邻两帧图像为例,如图4所示,分别表示前后两帧图像中描述左手运动状态的空间向量。以spine点为原点坐标,将相邻两帧图像之间指向同一骨骼点的两个空间向量所形成的三角形的面积为s,夹角为θ。
[0061]
当θ∈(0,90
°
]时:
[0062][0063]
当角度变化大于90
°
时,表示该部位的运动幅度更大,为了使s与运动幅度继续保持正相关,当θ∈(90
°
,180
°
]时:
[0064][0065]
为了更好地保留运动状态衡量系数的空间信息,可将两个空间向量分别向xoy面、yoz面、xoz面投影后再分别计算s。将一个完整的骨骼图动作序列leftarm区域的n帧图像依次处理:
[0066][0067][0068][0069][0070]
其中,s
ls
、s
le
、s
lw
、s
lh
分别为:左肩、左肘、左腕、左手部位的相邻两帧图像空间向量所夹空间面积;s
xoy
、s
yoz
、s
xoz
分别表示空间向量向xoy面、yoz面、xoz面投影后的面积。
[0071]
再将同一区域内的值做归一化处理后即得运动状态衡量系数w:
[0072][0073][0074][0075][0076]
将运动协同空间向量按时间序列依次求得之后,便可依次求得表示各个区域的运动状态衡量系数w,其中,w
ls
、w
le
、w
lw
、w
lh
分别为左肩、左肘、左腕、左手部位的运动状态衡量系数。
[0077]
(二)面向运动状态衡量系数的关键帧提取
[0078]
人的动作不可能是一成不变的,而且对于一个完整的动作序列来说,人的动作在每一帧图像上的分布也是不均匀的,会存在相邻两帧图像之间动作变化较小的情况。这时可以从这两帧图像中抽出一帧,用剩下的一帧图像来代表这两帧。如此,能将冗余信息删繁
就简,减少计算量,提高识别效率。
[0079]
在提取关键帧时,运动状态衡量系数可以作为一种很好的衡量标准。将相邻两帧图像之间所有部位的运动状态衡量系数加起来,得到的值就可以准确地反映出两帧图像之间动作的变化情况。值越大说明相邻两帧之间动作的差异越大,反之则说明差异越小。
[0080]
具体方法步骤如下:
[0081]
输入:骨骼图序列的关节点坐标,该骨骼图序列共有n帧图像。
[0082]
输出:基于运动状态衡量系数的关键帧序列。
[0083][0084]
step1:依次计算相邻两帧图像之间所有区域的运动状态衡量系数之和,可得到n-1项运动状态衡量系数的集合:
[0085]
{w1,w2,w3…wn-1
}
ꢀꢀꢀ
(13)
[0086]
w1表示第一帧与第二帧图像之间所有区域的运动状态衡量系数之和,w2表示第二帧与第三帧图像之间所有区域的运动状态衡量系数之和,以此类推,直至w
n-1
[0087]
step2:将相邻两项运动状态衡量系数相加,可得到衡量关键帧的动作变化参数c:
[0088]ci
=wi+w
i+1
,i∈(1,n-2)
ꢀꢀꢀ
(14)
[0089]
step3:将c按照大小排序,若第i项为最小值,则将第i+1帧图像删去:
[0090]cdelete
=min{c1,c2,c3…cn-2
}
ꢀꢀꢀ
(15)
[0091]
重复上述步骤step1-step3,直到得到足以描述人体行为的关键帧序列为止。
[0092]
(三)vgg-16卷积神经网络
[0093]
针对utd-mhad数据集样本数量较少的问题,使用小型卷积神经网络vgg-16(参照krizhevsky a,sutskever i,hinton g e.imagenet classification with deep convolutional neural networks[c]//international conference on neural information processing systems,2012:1106-1114.)来提取运动协同空间特征与dmm(depth motion maps)的特征信息。且因为数据集样本较少,重新开始训练容易出现过拟合现象,因此在ilsvrc-2012预训练模型的基础上进行训练,对网络参数进行微调。
[0094]
vgg-16网络结构如图5所示,通过反复堆叠3*3的小型卷积核和2*2的最大池化核,不断加深网络结构来提升性能。
[0095]
本发明中共训练四个卷积神经网络,一个用于运动协同空间特征提取骨骼特征,另外三个分别用于dmm的三视图提取深度特征,最后使用加权融合法与乘积法对训练得到
的分数进行融合。
[0096]
(四)实验验证
[0097]
实验在联想y7000p型号的笔记本上运行,windows 10系统,cpu为2.60ghz的i7-10750h,安装内存为16.00gb,matlab r2018b版本,python 3.7.0版本。
[0098]
(41)实验数据
[0099]
本发明在多模态动作数据集utd-mhad(参照chen,c.;jafari,r.;kehtarnavaz,n.utd-mhad:a multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor.in proceedings of the 2015ieee international conference on image processing(icip),quebec city,qc,canada,27
–
30september 2015.)上进行测试,该数据集由27个不同的动作组成:(1)右臂向左滑动,(2)右臂向右滑动,(3)挥动右手,(4)两个手拍面前,(5)右臂投掷,(6)交叉手臂在胸部,(7)篮球投篮,(8)右手画x,(9)右手画圆(顺时针),(10)右手画圆(逆时针),(11)画出三角形,(12)保龄球(右手),(13)前拳击,(14)棒球右摇摆,(15)网球右手正手挥拍,(16)旋臂(两臂),(17)网球发球,(18)两个手推,(19)右手敲门,(20)右手抓住物体,(21)右手捡起,扔,(22)原地慢跑,(23)原地走(24)坐姿站立,(25)站姿坐下,(26)向前弓步(左脚向前),(27)蹲(两臂伸直)。惯性传感器被戴在受试者的右手腕或右大腿上,这取决于动作主要是胳膊还是腿的类型。具体来说,对于动作1到21,惯性传感器被放置在受试者的右手腕上;对于动作22到27,惯性传感器被放置在受试者的右大腿上。
[0100]
utd-mhad数据集在室内环境中使用microsoft kinect传感器和可穿戴惯性传感器收集。数据集包含27个动作执行8名受试者(4女性和4男性)。每个被试者重复每个动作4次。在删除三个损坏的序列后,数据集包括861个数据序列。rgb视频、深度视频、骨骼关节位置和惯性传感器信号的四种数据模态在三个通道或线程中记录。其中一个通道用于同时捕捉深度视频和骨架位置,一个通道用于rgb视频,一个通道用于惯性传感器信号(三轴加速度和三轴旋转信号)。为了数据同步,记录了每个样本的时间戳。
[0101]
(42)实验设置
[0102]
在本发明中,utd-mhad数据集采用了两种不同的设置。
[0103]
设置1:
[0104]
为了根据训练数据集大小的变化评价模型的性能特征,对于utd-mhad数据集中的样本进行了三次实验:
[0105]
test1中使用1/4的数据作为训练集,3/4的数据作为测试集;
[0106]
test2中使用1/2的数据作为训练集,1/2的数据作为测试集;
[0107]
test3中使用3/4的数据作为训练集,1/4的数据作为测试集。
[0108]
设置2:
[0109]
utd-mhad中的所有样本都是同时分类的。使用subject 1,3,5,7的样本进行训练,使用subject 2,4,6,8的样本进行测试。
[0110]
本发明使用vgg-16网络架构cnn进行分类识别,使用预训练模型ilsvrc-2012,网络参数设置参见文献(krizhevsky a,sutskever i,hinton g e.imagenet classification with deep convolutional neural networks[c]//international conference on neural information processing systems,2012:1106-1114.)中的设置:
学习率设置为0.001,批次次数设置为32;训练的最大迭代次数设置为20 000次,其中每5 000次迭代后学习率下降一次。
[0111]
(43)实验结果与分析
[0112]
(431)运动协同空间特征模型实验结果
[0113]
为了评估提取运动协同空间特征不同方法的效果,建立三种不同的模型按照设置1的参数进行比较:模型1为未使用运动状态衡量系数处理但向三个笛卡儿面做投影后的的运动协同空间特征;模型2为未将运动协同空间向量向三个笛卡儿面投影,直接计算运动状态衡量系数的运动协同空间特征;模型3为使用运动状态衡量系数处理也向三个笛卡儿面做投影后的运动协同空间特征。模型1和模型3、模型2和模型3为两组对照组。
[0114]
表1运动协同空间特征模型比较
[0115][0116]
由表1可看出,模型3的平均识别率相对于模型1提高了3.3%。运动状态衡量系数的引入使得模型对于各部位对运动做出的贡献有了清晰的判别标准,对各区域运动协同空间向量的提取以及拼接提供了权重比例判别依据,提高了识别效果。
[0117]
模型3的平均识别率相对于模型2提高了31.1%。向三个笛卡儿面投影的处理加强了模型对于空间信息的提取,大幅提高了识别效果。
[0118]
从此实验可看出:运动状态衡量系数的引入以及向三个笛卡儿面投影这两项设置都有效地提高了运动协同空间特征的识别效果,因此本发明后续实验将采用模型3来提取运动协同空间特征。
[0119]
(432)关键帧的提取
[0120]
本发明使用基于运动状态衡量系数的关键帧提取算法来提取骨骼图序列中的关键帧。关键帧的数量直接影响到实验的性能。因此,需要设置适当的剩余帧数的百分比,既能去除冗余信息,又能完全保留关键信息。
[0121]
本发明按照设置1对于关键帧提取比例进行了实验,当剩余帧数的百分比设置不同时,对识别率的影响如图6所示。
[0122]
由图6可知,当关键帧比例在70%左右时,识别效果达到峰值,与原识别率相比平均提升了1.5%,且缩减了运算量,减少了运行时间。因此本文将后续实验关键帧比例设置为70%。
[0123]
(433)多模态融合实验结果
[0124]
为了评估模态融合对于模型效果的影响,按照设置2对单独使用骨骼数据、单独使用深度数据、模态融合后的结果进行了比较,如表2所示:
[0125]
表2单模态、多模态方法对比
boosting classifier.ieee trans.image process.2017,26,4648
–
4660。
[0135]
sdsr参照:annadani y,rakshith d,biswas s.sliding dictionary based sparse representation for action recognition[c]//computer vision and pattern recognition,2016:1-7。
[0136]
dmm-cthog-lbp-eoh参照:bulbul m f,jiang y,ma j.dmms-based multiple features fusion for human action recognition[j].international journal of multimedia data engineering and management,2015,6(4):23-39。
[0137]
由表3可知本发明的方法在utd-mhad数据集上识别率达到89.8%,高于所列出的其他方法,识别率至少提高了1.4%,评价结果证明了该方法的优越性。
[0138]
综上,本发明提供了一种针对人体运动整体性、协同性的行为识别算法,参考各骨骼节点之间的运动关系,利用运动状态衡量系数来判断各骨骼点对于人体运动的贡献程度,在处理后的关键帧序列中提取运动协同空间特征,与深度运动图进行多模态融合后,在utd-mhad数据集上取得了良好的识别效果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1