一种基于数值特征聚类的水文时间序列模体挖掘方法
1.本发明属于水文数据处理技术领域,具体涉及一种基于数值特征聚类的水文时间序列模体挖掘方法。
背景技术:
2.随着物联网技术的迅速发展,各种传感设备记录了随时间变化的海量数据,即时间序列。时间序列分析领域一个重要的研究点就是模体挖掘,这对于发现时间序列中的特征具有重要意义。模体指的是时间序列中重复的子片段或频繁出现的趋势。如今,模体挖掘已被广泛应用于气象、地震和昆虫行为分析等众多领域。
3.时间序列模体挖掘方法可以分为近似模体挖掘和精确模体挖掘,且时序数据可以是一维数据或者多维数据。在时间序列模体挖掘领域有许多经典方法。patel等人提出了一种高效的固定长度模体发现算法,他们首次使用暴力算法定位模体对。shasha和wang等人通过使用近似距离图(adm)对暴力算法进行优化,并提出了矩阵近似法(emma)。尽管如此,实际场景中的模体发现过程并不允许这么高的时间计算。因此,人们在效率提高方面做出了许多努力。chiu等人使用了符号聚合近似(sax)对时序数据进行降维处理,提出了随机投影(rp)算法。这种方法在数据压缩的同时降低了挖掘精度。mueen团队首创了matrix profile算法,将子序列间的距离体现在距离矩阵上,并对此完成了一些剪枝方法的设计,如排除重复子序列对(trivial match)等。此后,基于mp的方法一直在持续改进,精度和效率也在逐渐提升,其中最为典型的就是zhu等人提出的stomp和stamp方法。
4.然而在水文应用领域中,用户难以在一开始就确定好模体的长度。另一方面,成对出现的模体未必是严格等长的两个子序列。不等长的子序列同样可以体现相似的水文特征。因此,可变长的模体发现就显得尤为重要。linardi等人基于mp提出了可变长模体发现(valmod)方法。这种方法在给定范围中搜索所有可能的模体。另一种可行的方法是基于动态时间规整(dtw)算法的,它可以计算不等长序列之间的距离。alaee等人基于此提出了swamp算法。但以上方法仍然未解决动态长度模体的挖掘。
5.此外,由于水文学的领域特殊性,水文时间序列具有严格的解释意义,即可根据领域知识进行单位划分。一段时间内的水文时间序列即可反应一个事件甚至描述一个单一场景。现有模体挖掘方法大多基于长段时间序列,难以处理水文领域多特征且时间跨度广的时间序列,一种可行的解决方法是将水文时间序列预先进行相关数值特征聚类,在聚类集合中挖掘具有水文可解释特征的模体。zhou等人提出了if2cnn框架,该框架集成了迭代过滤(if)方法和卷积神经网络(cnns),用于时间序列的自动特征学习。但是,cnn特征提取过程主要服务于具体预测任务,难以提取时态特征外的其他重要特征。tiano等人提出了一种基于特征的半监督聚类框架(featts),该算法依赖于时间序列标签自适应地调整适合时间序列的关键特征,并基于现有聚类方法实现时间序列的聚类。然而,该监督方法需要部分时间序列标签,在部分应用中较难满足,且社区检测和相关度计算步骤分离,涉及的过多参数可以考虑进一步融合。
技术实现要素:
6.发明目的:为克服以上现有技术的不足,本发明一种基于数值特征聚类的水文时间序列模体挖掘方法,实现实时的、准确的、高效的模体挖掘。
7.技术方案:本发明提供一种基于数值特征聚类的水文时间序列模体挖掘方法,包括以下步骤:
8.(1)提取多个水文时间序列的数值特征,根据时间序列标签选择与时间序列标签高度关联的特征,并在此基础上选择大于覆盖率阈值的最小数量特征;
9.(2)以最小数量特征为基本单位构建边加权图,根据加权边筛选比例确定保留的距离阈值,对每个特征的加权图进行初始的社区检测;
10.(3)根据每个加权图的社区数量与预定义聚类个数计算特征权值,构建加权共现矩阵;在共现矩阵中计算行向量之间的相似度,实现时间序列聚类集合;
11.(4)以步骤(3)的每个聚类集合为基本单位,对集合内时间序列进行全连接形成完整时间序列,与自身比较形成全局距离矩阵;
12.(5)使用可变尺寸的滑动窗口在全局距离矩阵上滑动,每次滑动过程中同时计算窗口内局部距离矩阵的最短路径距离;
13.(6)基于最短路径距离构建子序列对三元组集合,并筛选形成候选模体列表,根据实际应用选择预定义数量的模体。
14.进一步地,所述步骤(1)包括以下步骤:
15.(11)根据水文领域关注的时间序列的持续时间、振幅和趋势等特征形成相关的数值特征;
16.(12)根据时间序列的标签计算特征的相关程度,即p值,按p值排序后选择前topf个特征;为减少特征冗余,选择满足覆盖率δ的最小数量特征。
17.进一步地,所述步骤(2)包括以下步骤:
18.(21)构建边加权图gw:对于一个特征fi和时间序列集合tss={ts1,ts2,
…
,tsm},每个时间序列ts
p
为边加权图的顶点集合v的一个结点v
p
;加权边集合e中每条边e
p,q
对应一个权值保留小于距离阈值ζ的边;
19.(22)应用社区检测算法在每个加权图中将若干节点分配到不同的社区中,社区检测算法利用图的连接结构统一时间序列聚类的不同表示。
20.进一步地,所述步骤(3)包括以下步骤:
21.(31)计算用户预定义聚类个数与社区个数之间比例确定每个特征的权重,具体计算方式为:
[0022][0023]
其中,c表示预定义的聚类个数,oi表示加权图中的社区数量;
[0024]
(32)统计每一对时间序列出现在同一个社区的次数,并填入共现加权矩阵
具体方法为:
[0025][0026]
其中,为共现带权矩阵,表示时间序列tsi和时间序列tsj之间的加权共现比率;计算公式为:
[0027][0028]
其中,wk表示任一特征对应的权值,w
k'
表示tsi和tsj共同出现在一个社区的任一特征对应的权值,m和m'分别表示特征总数和tsi和tsj共同出现在一个社区的总次数;
[0029]
(33)对的行与行进行距离计算,并利用聚类算法形成最终聚类集合。
[0030]
进一步地,步骤(4)所述距离矩阵为:
[0031]
在单个聚类集合csi中,将集合内所有时间序列按照时间顺序排列构成完整时间序列ts
glob
={ts1,ts2,
…
,tsm};完整时间序列ts
glob
中每个元素与ts
glob
中每个元素计算欧式距离,初始化全局距离矩阵mat
dis_glob
:
[0032][0033]
其中,表示时间序列在i时刻和j时刻的序列值之间的距离,n表示为时间序列长度。
[0034]
进一步地,所述步骤(5)包括以下步骤:
[0035]
(51)使用不同面积大小、不同边长比例的窗口以一定的步长st在全局距离矩阵上滑动;
[0036]
(52)在一次滑动过程中,计算滑动窗口内的局部距离矩阵mat
dis_local
的规整路径距离,即最短路径距离d
sp
:
[0037]dsp
=min{diswarping(mat
dis_local
)}
[0038]
(53)按照边长比例和面积设置,逐渐缩小滑动窗口大小,并重复步骤(51)和步骤(52);
[0039]
(54)对步骤(52)和步骤(53)中每个窗口内构成的局部距离矩阵mat
dis_local
计算最短路径的距离d
sp
;最短路径的距离使用最短路径距离计算优化方法,即复用前序大窗口内累积矩阵元素的累积距离和复用前序邻居窗口内矩阵的局部最短路径;最短路径的距离d
sp
需要根据子序列对长度归一化处理。
[0040]
进一步地,所述步骤(6)包括以下步骤:
[0041]
(61)构建子序列对三元组spt=《(idx1,len1),(idx2,len2),d
sp
》;其中,(idx,len)分别表示子序列的起始索引和长度,d
sp
为子序列对间的dtw距离;
[0042]
(62)根据预定义的候选模体相似度阈值τ对子序列对三元组筛选,形成候选模体三元组cmt,即归一化的最短路径距离sim(d
sp
)≥τ;其中,sim为相似度求解函数,相似度与dtw距离成反比;
[0043]
(63)在候选模体三元组cmt中依次选择子序列元素加入候选模体列表cml中;
[0044]
(64)候选模体列表cml的每个元素(cmidxi,cmleni)关联一条单向链表simlinklisti,链表中每个元素为候选模体三元组cmt中与(cmidxi,cmleni)相似的子序列,即满足其中,为单向链表的任意元素;
[0045]
(65)按照单向链表的长度排序,根据用户定义的模体个数k,选择排序后的候选模体列表cml的前k个元素,即为k-模体。
[0046]
进一步地,步骤(54)所述的最短路径距离计算优化方法包括以下步骤:
[0047]
(541)按照dtw算法最短路径求解过程计算划定的计算域mat
dis_local
[,:r+1]内所有元素的累积距离;
[0048]
(542)复用域mat
dis_local
[,n-st-1:n-st]内所有元素的累积距离求解,复用前序距离矩阵从计算域mat
dis_local
[,:r+1]到该元素的累积距离之差,即其中和分别表示前序累积距离矩阵和当前累积距离矩阵;(i,j)和(p,q)分别位于前序累积矩阵的计算域和重用域;
[0049]
(543)根据dtw最短路径求解过程和步骤(542)已知的复用域内所有元素累积距离,计算划定的计算域mat
dis_local
[,n-st:]内所有元素的累积距离,mat
dis_local
第m行、第n列元素的累积距离即为该矩阵的最短路径距离d
sp
。
[0050]
有益效果:与现有技术相比,本发明的有益效果:本发明利用可变尺寸窗口在dtw生成的全局距离矩阵上滑动,实现了将一维时间序列的子序列对的相似度计算,映射到二维滑动窗口内部的局部矩阵的最短路径求解;局部距离矩阵计算过程采用了优化算法,简化了最短路径的求解,因此可以实现实时的、准确的、高效的模体挖掘;同时,本方法在水文领域中具有实际应用价值。
附图说明
[0051]
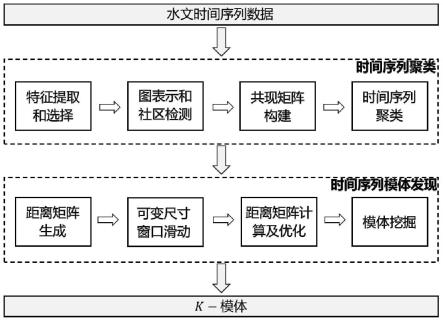
图1是本发明的流程图;
[0052]
图2为本发明时间序列各特征的社区检测结果示意图;
[0053]
图3为本发明完整时间序列构建全局距离矩阵示意图;
[0054]
图4为本发明局部距离矩阵的复用域和计算域划分示意图;
[0055]
图5为本发明候选模体列表示意图。
具体实施方式
[0056]
下面结合附图对本发明作进一步详细说明。
[0057]
本发明提出一种基于数值特征聚类的水文时间序列模体挖掘方法,如图1所示,具体包括以下步骤:
[0058]
步骤1:提取多个水文时间序列的数值特征,根据时间序列标签选择与时间序列标
签高度关联的特征,并在此基础上选择大于覆盖率阈值的最小数量特征。
[0059]
在时间序列集合tss={ts1,ts2,
…
,tsm}中使用tsfresh库提取特征,每个时间序列tsi对应一个特征向量fi={f1,f2,
…
,fn};将时间序列的特征向量与对应的分类标签共同组成m
×
(n+1)的二维矩阵,其中m表示时间序列总数,n表示特征总数。使用benjamini-yekutieli程序根据类别标签量化每个特征的重要性,即p值。在相关度排序中,选择前topf个特征,topf为预定义参数。使用主特征分析(pfa)算法将topf个特征筛选,满足筛选后特征的方差之和可以覆盖其余特征的大部分信息。其中,覆盖率δ需要预先定义,topf个特征经过筛选后个数为top
δ
。
[0060]
步骤2:以最小数量特征为基本单位构建边加权图,根据加权边筛选比例确定保留的距离阈值,对每个特征的加权图进行初始的社区检测。
[0061]
构建边加权图gw,对于一个特征fi和时间序列集合tss={ts1,ts2,
…
,tsm},每个时间序列ts
p
为边加权图的顶点集合v的一个结点v
p
。加权边集合e中每条边e
p,q
对应一个权值保留小于距离阈值ζ的边。使用networkx库的贪心模块化算法对每个加权图进行社区检测,以搜索密集连接成社区的结点组合,如图2所示。
[0062]
步骤3:根据每个加权图的社区数量与预定义聚类个数计算特征权值,构建加权共现矩阵;在共现矩阵中计算行向量之间的相似度,实现时间序列聚类集合。
[0063]
根据社区检测算法从图中导出的社区数量oi和预定义的聚类个数c,为每个特征fi分配一个近似的权重wi:
[0064][0065]
统计每一对时间序列出现在同一个社区中的次数,并代入权重wi,构建加权共现矩阵具体方法为:
[0066][0067]
其中,第i行、第j列元素计算方法为:
[0068][0069]
其中,wk表示任一特征对应的权值,w
k'
表示tsi和tsj共同出现在一个社区的任一特征对应的权值,m和m'分别表示特征总数和tsi和tsj共同出现在一个社区的总次数。
[0070]
将加权共现矩阵的各行向量之间计算欧式距离。利用k-medoid算法将相似时间序列聚类,生成最终聚类集合cs。
[0071]
步骤4:以步骤3的每个聚类集合为基本单位,对集合内时间序列进行全连接形成
完整时间序列,与自身比较形成全局距离矩阵,如图3所示。
[0072]
将聚类集合cs中的每一个时间序列集合ci={ts1,ts2,
…
,tsn}内的所有时间序列全连接,形成完整时间序列ts
glob
={ts1,ts2,
…
,tsm}。
[0073]
将完整时间序列ts
glob
中每个元素与ts
glob
中每个元素计算欧式距离,构造全局距离矩阵mat
dis_glob
。构造全局距离矩阵mat
dis_glob
的具体方法为:
[0074][0075]
其中,表示时间序列在i时刻和j时刻的序列值之间的欧式距离,即d(i,j)=|ts
i-tsj|;n表示为时间序列长度。
[0076]
步骤5:使用可变尺寸的滑动窗口在全局距离矩阵上滑动,每次滑动过程中同时计算窗口内局部距离矩阵的最短路径距离。
[0077]
(5.1)使用不同面积大小、不同边长比例的窗口在全局距离矩阵上滑动。以窗口的左上角为参考点,面积采用从大到小的方式,方向采用从左到右、由上及下的方式。为提高时间效率,根据一定的步长st进行滑动;
[0078]
(5.2)在一次滑动过程中,计算滑动窗口内的局部距离矩阵mat
dis_local
的规整路径距离,即最短路径距离d
sp
。计算方式采用dtw算法中最短路径求解方式:
[0079]dsp
=min{diswarping(mat
dis_local
)}
[0080]
(5.3)重复以上步骤(5.1)和步骤(5.2)。在左右相邻矩阵间滑动过程中,采用距离矩阵计算优化策略。如图4所示,将局部距离矩阵分为复用域和计算域。复用域为第(n-st)列元素。计算域为fastdtw算法定义的前(r+1)列元素,以及最后st列元素,复用和计算过程基于以上划定区域执行。
[0081]
上下相邻矩阵间滑动同理;
[0082]
(5.4)重复以上步骤(5.1)、步骤(5.2)和步骤(5.3)。在窗口尺寸由大及小过程中,较小局部距离矩阵的最短路径距离可以复用较大局部距离矩阵的距离,即其中,cum
large
(i,j)为较大距离矩阵计算最短路径时累积距离矩阵的第i行、第j列的元素。i和j为较小局部距离矩阵的行数和列数。
[0083]
最短路径的复用和计算过程包括以下步骤:
[0084]
1)按照dtw算法最短路径求解过程计算划定的计算mat
dis_local
[,:r+1]内所有元素的累积距离;
[0085]
2)复用域mat
dis_local
[,n-st-1:n-st]内所有元素的累积距离求解,复用前序距离矩阵从计算域mat
dis_local
[,:r+1]到该元素的累积距离之差,即其中和分别表示前序累积距离矩阵和当前累积距离矩阵。(i,j)和(p,q)分别位于前序累积矩阵的计算域和重用域;
[0086]
3)根据dtw最短路径求解过程和步骤(532)已知的复用域内所有元素累积距离,计
算划定的计算域mat
dis_local
[,n-st:]内所有元素的累积距离。mat
dis_local
第m行、第n列元素的累积距离即为该矩阵的最短路径距离d
sp
。
[0087]
步骤6:基于最短路径距离构建子序列对三元组集合,并筛选形成候选模体列表,根据实际应用选择预定义数量的模体。
[0088]
(6.1)构建子序列对三元组spt=《(idx1,len1),(idx2,len2),d
sp
》。其中,(idx,len)分别表示子序列的起始索引和长度,d
sp
为子序列对间的dtw距离;
[0089]
(6.2)根据预定义的候选模体相似度阈值τ对子序列对三元组筛选,形成候选模体三元组cmt,即归一化的最短路径距离sim(d
sp
)≥τ。其中,sim为相似度求解函数,相似度与dtw距离成反比;
[0090]
(6.3)在候选模体三元组cmt中依次选择子序列元素加入候选模体列表cml中,如图5所示。由于候选模体三元组cmt存在二元对称性,(idx1,len1)和(idx2,len2)都需要添加在cml中;
[0091]
(6.4)候选模体列表cml的每个元素(cmidxi,cmleni)关联一条单向链表simlinklisti,链表中每个元素为候选模体三元组cmt中与(cmidxi,cmleni)相似的子序列,即满足其中,为单向链表的任意元素;
[0092]
(6.5)按照单向链表的长度排序。根据用户定义的模体个数k,选择排序后的候选模体列表cml的前k个元素,即为k-模体。
[0093]
以水文领域的洪水预报应用中的主导因素降雨为例,具体如下:
[0094]
选择昌化流域从1998年到2010年内共31条洪水数据集,主要包括七个雨量站监测点的降雨数据和出口流量值。七个雨量站监测点为:岛石坞、桃花村、龙门寺、双石、岭下、昱岭关和昌化。监测频率为一小时一条。根据七个站点空间分布占比计算昌化流域的面平均雨量,获得31条面平均降雨时间序列数据集tss={ts1,ts2,
…
,ts
31
}。其中,面平均降雨时间序列tsi上每个数据点的计算公式为:
[0095][0096]
其中,表示监测站测量的小时降雨量。rti表示监测站所在子流域面积与总流域面积比率。
[0097]
使用tsfresh库提取降雨时间序列数据集tss={ts1,ts2,
…
,ts
31
}的特征集合使用benjamini-yekutieli方法计算特征集合f的p值,根据实证研究,按相关性排序的前20个特征足以获得高质量的聚类。因此选择前20个特征使用pfa算法将特征集合f筛选。根据各种阈值实验,覆盖率选择90%。因此选择最小数量的特征,其方差之和覆盖其余特征产生的90%信息。筛选后的特征集合的三个特征为quantile、trend_stderr和trend_rvalue。
[0098]
构建边加权图每个边加权图中顶点集合v={v1,v2,
…
,v
31
}对应降雨时间序列数据集tss={ts1,ts2,
…
,ts
31
}。加权边集合e={e
1,2
,e
1,3
,
…
,e
30,31
}的
每条边上的权值计算方式为:保留小于距离阈值ζ的加权边。在实证评估中,使用80%的阈值在实际场景中效果很好。筛选后的加权边集合为e={e1,e2,
…
,e
93
};使用贪心模块化算法进行社区检测。对于边加权图检测后的社区
[0099]
记录31条降雨时间序列在三个边加权图中社区共现情况。其中:
[0100][0101][0102]
确定特征集合f中每个特征的权值wi。根据国标gb/t 28592-2012,降雨类别主要分为:微量降雨、小雨、中雨、大雨、暴雨、大暴雨和特大暴雨。结合洪水相关领域知识,导致洪水主要降雨集中在中雨到大暴雨范围。因此聚类个数c预定义为4。根据技术方案中公式,w1=0.66,w2=1,w3=0.5。构建加权共现矩阵以时间序列ts1和ts3为例,计算加权共现矩阵行向量间的欧式距离,即使用k-medoid算法将相似时间序列聚类,生成最终聚类集合cs={cs1,cs2,cs3,cs4}。
[0103]
以降雨时间序列簇cs1={ts1,ts3,ts8,ts
15
,ts
23
,ts
24
}为例,将6条降雨时间序列全连接,相邻时间序列之间进行标注fl={fl1,fl2,fl3,fl4,fl5},形成簇cs1的完整降雨时间序列ts
glob
={ts1,ts2,
…
,ts
273
}。生成完整降雨时间序列ts
glob
与ts
glob
的dtw距离矩阵矩阵的每个元素为数值之间的欧式距离。
[0104]
根据区域生成网络(rpn)的相关实验证明,滑动窗口选择1:1、1:2和2:1的边长比例可以较快地检测到目标位置。参照国标gb/t 28592-2012,降雨等级均按照12h降雨和24h降雨划分。因此,滑动窗口尺寸选择{48
×
48,48
×
24,24
×
48,24
×
24,24
×
12,12
×
24,12
×
12,12
×
6,6
×
12}。以窗口左上角为参考点,方向由上而下、由左及右。根据参数灵敏度实验,滑动步长st选择5。在一次滑动过程中,计算窗口内局部矩阵mat
dis_local
的最短路径距离d
sp
。以采用尺寸为24
×
12的窗口左右滑动为例,当前局部距离矩阵的复用域为第7列元素计算域为前28列重合区域和最后5列元素上下滑动区域分配同理。利用dtw算法计算区域内元素的累积距离。复用前序局部距离矩阵的部分局部最短路径,获得区域内元素的累积距离。继续利用dtw算法计算区域内元素的累积距离。以滑动窗口尺寸由48
×
48缩小至48
×
24为例,对于同一位置(即左上角参考点一致)的滑动窗口,一致)的滑动窗口,
[0105]
以子序列对ts
27,48
和ts
91,24
之间的归一化dtw距离为1.266为例,子序列对三元组
为spt=《(27,48),(91,24),1.266》。根据水文领域知识,相似度阈值τ设置为0.75。dtw距离为1.266转化为相似度约为0.79。因此,该三元组可作为模体候选三元组cmt。以s601候选模体三元组cmt=《(27,48),(91,24),1.266》为例,候选模体列表cml需要同时添加(27,48)和(91,24)。且分别以(27,48)和(91,24)为链表头节点,各在当前链表尾节点处插入(91,24)和(27,48)。若不存在单链表,则直接创建并在头节点后添加。按照所有链表simlinklisti的长度排序,选择排序后的候选模体列表cml的前3个候选模体作为最终模体。因此,在聚类集合cs中共有12个最终模体,12个模体具有不同的水文特征。此处,模体数量k可根据用户需求修改。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1