一种基于动态行为构图的浏览器挖矿检测方法
1.本发明涉及矿物开采技术领域,更具体地说是一种基于动态行为构图的浏览器挖矿检测方法。
背景技术:
2.浏览器挖矿攻击通过在网站部署恶意挖矿脚本,在未经访客允许的情况下侵占访客的计算资源,持续消耗电力,引起设备卡顿、发热等问题。由于此类攻击不会直接引发设备故障,所以很难被用户察觉。现有的浏览器挖矿检测方法主要分为两大类,一类是基于黑名单的检测方法,另一类则是基于动态特征的检测方法。
3.基于黑名单的检测方法是目前市场上比较常见的一种检测方法。这些方法通常以轻量级的脚本或者浏览器插件的形式出现,而它们所使用的黑名单则通常由权威机构或者公共安全平台进行发布和维护。典型的插件形式的开源检测工具是minerblock,主要根据黑名单列表来网络阻止url访问以及脚本请求。另一种脚本形式的开源检测工具是dr.mine,它可以在后台启动浏览器并捕获目标网站及其子页面的相关请求,以判断其是否包含黑名单中所标记的域名。由于这类方法的有效性完全依赖于黑名单,所以一旦挖矿网站的域名发生变化,这类方法的准确性就会受到影响。事实上,这些黑名单的更新速度往往跟不上网站域名变换的速度——据研究人员统计,超过20%的挖矿网站域名的持续时间不到9天,而黑名单平均每10到20天才更新一次。
4.基于挖矿特征的检测方法目前主要包含以下几种:
①
cpu观察法。因为挖矿网站通常会引起cpu使用率的迅速增长,所以人们往往通过观察cpu的使用情况来判断自己是否遭受了浏览器挖矿攻击。但是,这一方法受系统运行环境的影响较大,一旦设备上同时运行了多个程序,普通用户将很难分清是具体哪一个程序引起了cpu使用率的增长。另外,现有的大多数挖矿网站还会采用阈值限制技术来控制挖矿程序对cpu的使用,使得用户不易观察到cpu使用率的变化。
②
基于wasm指令分析的方法。例如,开源工具minesweeper和minerray。这类方法主要依靠分析wasm指令来判断网站所运行的wasm模块是否采用了挖矿相关的算法。但是此方法只适用于cryptonight挖矿算法以及与之相近的其他挖矿算法,对于一些新的挖矿算法来说效果并不理想。
③
基于局部行为特征的方法。例如,开源工具cmtracker和outguard。这类方法主要通过分析网站跟踪是否包含特殊的行为特征,比如,重复调用的函数栈,来判断目标网站是否为一个挖矿网站。但是这类方法所依据的特征太过普遍,所以很容易产生误报——将某些正常网站也判断为是挖矿网站。
技术实现要素:
5.本发明针对现有的浏览器挖矿检测方法准确率不足、误报率高的问题,提出了一种基于动态行为构图的浏览器挖矿检测方法,实现了对实时运行的挖矿网站的检测,能在保持低误报率的前提下找出绝大多数的挖矿网站。本发明基于谷歌puppeteer库所提供的自动记录网站运行时跟踪的功能,通过对网站运行时跟踪的分析,构造与网站运行时行为
相符合的网站行为图,利用深度学习中gin图神经网络,设计浏览器挖矿检测模型,为浏览器挖矿检测提供了技术支持,可以精准地找出挖矿网站,避免用户遭受浏览器挖矿攻击。
6.本发明的技术效果和优点:
7.1、不需要依赖于任何的黑名单。本发明基于网站运行时跟踪,在进行构图的过程中,无需提取任何的域名特征,避免了对黑名单列表的依赖。
8.2、可以找出使用新挖矿算法的挖矿网站。本发明主要根据网站的运行时行为进行构图,无需对具体的挖矿算法进行解析,具有更强的鲁棒性。
9.3、误报率更低。本发明在构图的过程中加入了充分的行为特征,以确保能准确区分挖矿网站和非挖矿网站,大幅地减少了模型的误报。
附图说明
10.图1网站运行时跟踪示例;
11.图2发明流程图;
12.图3数据预处理流程图;
13.图4行为图表示构造流程图;
14.图5图神经网络模型示意图。
具体实施方式
15.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
16.参照说明书附图1-5,该实施例的一种基于动态行为构图的浏览器挖矿检测方法,包括本发明所述的网站运行时跟踪是指通过谷歌浏览器自带的跟踪记录工具或者谷歌提供的puppeteer库在网站运行时所记录下的相关信息。如图1所示,网站运行时跟踪文件中通常包括网站的线程信息、函数调用信息、网络状态信息以及相关任务信息等。
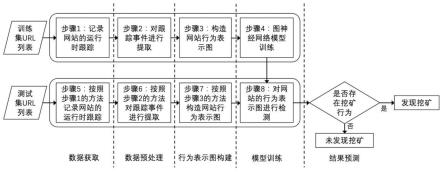
17.依照图2的发明流程图所示,本发明将实施方法分为了四个阶段:数据获取阶段、数据预处理阶段、网站行为图构造阶段、模型构建与训练阶段、测试阶段。
18.1、数据获取阶段
19.为了能在一个安全的环境下访问挖矿网站并且记录网站跟踪,本发明将数据获取阶段的代码(即,跟踪记录器)部署在一个docker容器中。通过限制docker容器的最大cpu使用率为0.5,我们可实现一个简单且轻量的安全沙箱。
20.在进行数据获取时,本发明首先接收来自用户的url输入,然后利用puppeteer库所提供的高级api,通过devtools协议控制chormium,使其以headless无界面模式访问目标网站。当跟踪记录器收到从目标网站返回的响应之后,它会继续在目标网站停留45秒以记录这段时间网站所产生的运行时跟踪。一般情况下,45秒的时间足以让挖矿网站启动挖矿脚本并执行挖矿任务。在这45秒的时间结束后,本发明将保存该网站的运行时跟踪,以方便进行后续处理。
21.2、数据预处理阶段
22.该阶段的主要任务是筛选出于挖矿行为有关的事件,并且对有用信息进行采集和处理。为此,我们首先对挖矿网站的常见工作流进行了分析,浏览器挖矿行为主要由以下七个步骤组成:
23.①
用户对目标网站发起请求,以获得必要的页面资源和挖矿启动脚本。
24.②
浏览器引擎开始解析页面资源,并启动挖矿脚本。
25.③
挖矿脚本下载核心的负载程序(通常是wasm格式或者asm.js格式)。
26.④
为了参与矿池任务,挖矿程序需要与矿池建立websocket连接。
27.⑤
为了能同时利用多个cpu,挖矿程序通常会创建多个线程,然后以并行的方式执行挖矿任务。
28.⑥
每个挖矿线程都需要循环地执行类哈希计算,此过程通常会消耗大量的cpu。
29.⑦
挖矿程序每隔一段时间就会提交一部分结果,以获得相应奖励,该过程通常需要主线程和多个子线程之间进行相互通信。
30.为了从浏览器运行时跟踪文件中获得与上述工作流有关的信息,我们就需要对跟踪文件进行预处理。如图3所示,本发明首先遍历跟踪文件中的所有事件,并根据事件中的ts属性,按照时间戳从小到大的顺序对事件进行排序。接着,本发明还需要对跟踪文件中与网站挖矿行为有关的事件进行解析和提取,具体步骤如下:
31.(1)线程识别
32.本发明读取名称为crrenderermain的事件,以识别主线程所对应的线程id;然后读取名称为dedicatedworker thread的事件,以识别子线程所对应的线程id。这样一来,就可以将后续事件划分为主线程发生和子线程发生两部分,从而区分主线程和子线程上的不同操作。
33.(2)函数调用事件提取
34.因为对于挖矿程序来说,函数是贯穿整个挖矿行为的最核心的部分,所以本发明先根据事件名提取所有名称为functioncall的事件,将其标注为函数调用事件。我们保留了函数调用事件的相关参数,包括函数名称、脚本号、代码行号、代码列号等,以方便后续对重复函数的识别以及相关特征的提取工作。
35.(3)功能事件提取
36.除了基本的函数调用过程以外,我们还需要理解函数的功能才能对挖矿行为进行较为准确的识别。因此,本发明进一步提取跟踪文件中所有名称为resourcesendrequest、websocketcreate的事件,并且将他们分别标记为资源请求事件和websocket连接建立事件。其中,根据资源请求事件参数中的url属性值,我们又将资源请求事件进一步进行划分。具体而言,当url以.js结尾时,就表示是一个js资源请求事件;当url以.wasm结尾时,就表示是一个wasm请求事件;当url以blob开头时,就表示是一个blob资源请求事件。在功能事件中,通常包含一个stacktrace属性,通过该属性可以找到产生事件的函数。但是由于代码混淆和匿名函数的存在,所以我们不宜使用这种方法进行函数匹配。因此,我们将这些功能事件与时间上离它们最近且发生在它们之前的函数调用事件进行关联,以代表函数与函数功能之间的关联关系。
37.(4)任务事件提取
38.此外,函数执行时的目标任务也是一个非常有价值的特征,因此我们还保留所有
事件参数中src_func属性值为postmessagetoworkerglobalscope、postmessagetoworkerobject、timerinstall的事件,并分别标记为全局消息传递事件、工作线程消息传递事件、计时器安装事件。因为这些任务事件均是通过函数调用来完成的,所以我们将这些任务事件与时间上离它们最近且发生在它们之后的函数调用事件进行关联,代表着任务与任务函数之间的关联关系。并且我们还需要调换任务事件与关联函数之间的顺序,以方便进行后续的构图工作。
39.3、行为表示图构建阶段
40.在得到预处理后的网站运行时跟踪之后,我们就可以开始对网站运行时的行为表示图进行构造,如图4所示。
41.(1)本发明首先读取并解析预处理后的网站运行时跟踪,并且对其中的每一个事件都进行遍历。
42.(2)如果当前事件是一个函数调用事件,则进一步判断同一个线程上是否有相同的函数调用结点存在。
43.其中,函数调用结点是否相同是由函数调用事件的参数决定的,如果函数调用事件的参数,包括函数名、脚本号、代码行号、代码列号等,完全一致,则表示两个函数调用结点相同。
44.如果已经有相同的函数调用结点存在,则代表该函数的调用出现重复,可能存在循环结构,因此无需创建新的函数调用结点,只需要与最近出现的同一线程的上一个函数调用结点进行连线。
45.如果没有相同的函数调用结点存在,则需要新建一个函数调用结点,再与最近出现的同一线程的上一个函数调用结点进行连线。这里的连线分为三种情况:一是主线程上的两个函数调用结点相连,此时用主线程时序边进行连线;二是子线程上的两个函数调用结点相连,此时用子线程时序边进行连线;此外,子线程上出现的第一个函数调用结点还需要与最近出现的主线程函数调用结点通过子线程时序边进行连线,以形成线程分支。
46.(3)如果当前事件是一个功能/任务结点,则创建新的功能/任务结点,并且根据数据预处理阶段的关联关系,将新创建的功能/任务结点与关联的函数调用结点进行连线。
47.这一步的连线共分为两种情况:一是功能结点与函数调用结点相连,此时用功能关联边进行连线;二是任务结点与函数调用结点相连,此时用任务关联边进行连线。注意,如果对于同一个函数调用结点已经存在一个同名的功能/任务结点与之相连,则不需要进行重复连线,同时需要删除多余的功能/任务结点,以避免冗余信息的出现。
48.(4)当所有的事件都遍历完成后,还需要进行向量化结点特征的工作。
49.这里我们主要对函数调用结点,四种功能结点,以及三种任务结点采取one-hot编码的方式生成特征向量的前8位。其中,one-hot独热编码也被称为一位有效编码,主要采用n位状态寄存器对n个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候只有一位有效。one-hot编码是分类变量作为二进制向量的表示。这里首先要求将分类值映射到整数值,然后每个整数值都被表示为二进制向量,除了整数的索引位置被标记为1外,其他都是零值。
50.此外,针对函数调用结点,我们还统计了它们的重复出现次数以及cpu累积占用时间。具体而言,当一个函数重复出现20次及以上时,第9位的特征值就是1;当一个函数出现
20次以下,比如x次时,第9位的特征值就是x/20;当一个函数的cpu累积占用时间超过10秒时,第10位的特征值就是1;当cpu累积占用时间小于10秒时,比如y秒,第10位的特征值就是y/10。而对于其他结点,特征向量的后两位均置为0。
51.4、模型训练阶段
52.(1)图神经网络模型gin
53.近年来,图神经网络受到了越来越多的关注。在结点分类和图形分类等图形任务中,图神经网络都取得优异的性能。与传统的规则结构不同,图数据结构为结构化数据提供了更为一般的抽象,因此规则结构可以被认为是图数据结构的一种特殊情况。图神经网络的强大之处在于它们可以直接定义任意图上的可学习的聚合函数,从而将经典的神经网络(如,cnn、rnn)扩展到更不规则且更一般的应用领域。
54.为了更好地解释图神经网络的优点,我们给出了一个具体的说明。如图5所示,对于图分类任务来说,当一个图被输入到神经网络之后,它首先会经过n轮迭代,好让每个结点都能聚合其n-hop邻域的信息,该过程可以由具体的aggregate函数和combine函数实现,这两个函数是决定图神经网络的表示学习能力的关键;之后,图形还需要经过一个readout池化函数的处理,以聚合图中所有结点的信息,并得到最终的输出结果。
55.尽管前人已经提出了许多具有不同邻域聚合和图级池化方案的图神经网络变体,但是他们中的大部分在设计上都主要基于经验直觉、启发式和实验试错。这些工作对图神经网络的性质和局限性缺乏理论上的理解,对图神经网络表示能力的形式化分析也十分有限。为此,有研究人员提出了一种分析图神经网络表示能力的理论框架。首先,他们证明了图神经网络在区分图结构方面最多和wl测试一样强大,其中,wl测试可以利用内部聚合更新将不同的结点领域映射到不同的特征向量。然后他们开发出了一种简单的神经结构,gin图同构网络。经实验证明,gin的图形表示学习能力堪比wl测试,并且在许多图形分类基准上实现了高的准确性和最好的性能。由于其具有良好的解释性和理论考证,所以本发明也将gin作为我们最终的分类器模型进行使用。
56.(2)模型参数设置
57.本发明将图神经网络的网络层数设置为3,网络层之间的dropout rate设置为0.2,隐藏层的向量维度为32,激活函数为relu,聚合函数为sum,每个batch的最大结点数量为10000,分类阈值为0.5。
58.(3)模型训练
59.神经网络模型的训练通常需要大量且丰富的数据。然而,要想从真实的网络环境中收集大量的恶意挖矿样本是很难的。一方面,在真实的网络环境下,恶意挖矿网站所占的比例并不高,因此我们很难获得大量具有代表性的阳性样本;另一方面,网络环境总是处于不断变化的状态,因此即便有前人为我们总结的黑名单,我们也不能百分百确定这些黑名单在当前状态下仍然是恶意的,必须通过手动检查的方式进一步确认。为了解决这一问题,本发明通过收集挖矿服务脚本并将其注入浏览器,来模拟产生大量的恶意挖矿网站以作为模型训练过程所需的恶意样本。
60.具体而言,我们收集了7种不同的恶意挖矿服务。在这些服务脚本中,有一部分能手动定制throttle、threads等挖矿参数,另一部分则不能。我们仍然通过puppeteer库所提供的api对网站进行访问,利用page.addscripttag函数实现脚本和代码植入,然后以随机
的方式设置脚本中的可选参数,以丰富训练集的样本多样性。我们从alexatop1m提供的前2万名的网站中随机挑选了其中的1万作为我们的url列表,每个url访问两次。第一次访问时,我们收集网站本身的跟踪记录,因为这些排名靠前的网站中存在挖矿攻击的概率极低,几乎可以忽略不计,所以我们将这些跟踪都视作良性样本,标签为0;第二次访问时,我们将挖矿服务植入浏览器,以获得包含挖矿行为的跟踪记录,也就是恶意样本,标签为1。我们以8:2的比例划分出训练集和验证集,经过50个epoch训练得到了最终的图网络分类模型。
61.4.5、结果预测阶段
62.在该阶段,我们先对待测试的url列表进行数据获取、数据预处理、行为表示图构建这一系列操作,最后采用我们已经训练好的gin图神经网络模型对待检测的行为表示图进行结果预测。如果模型输出结果为1,则表示当前网站存在挖矿行为,于是提醒用户发现了实时运行的挖矿网站,并告知用户如非必要则勿访问该站点;如果模型输出结果为0,则表示在当前网站中并未发现挖矿行为,并告知用户可以对网站进行访问。
63.最后:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1