一种票据图像的文字提取方法及装置与流程
1.本发明涉及票据识别技术领域,尤其涉及一种票据图像的文字提取方法及装置。
背景技术:
2.近些年,我国医疗行业不断发展和进步,医疗行业的体系和制度趋向成熟、完善。但是,每个医院出具的票据格式都不一样,医疗票据递交后,报销单位以人工录入的方式进行,核对人员对录入信息进行核对,然后提交审核人员审核,整个流工作效率低,需要大量的人力资源,并且还会出现一些难以发现的错误。
3.对此现有技术采用文字检测识别模型对各医疗票据进行文字识别,但是现在技术只能单纯对票据中的文字进行识别,并不能依照不同票据的版面格式,对所识别的文字进行排版,通常需要人工对识别出的文字进行调整,排版使其与票据的版面格式一致,因此依旧存在工作效率低下的问题。
技术实现要素:
4.本发明实施例提供一种票据图像的文字提取方法和装置,能自动对票据图像的文字进行识别,并自动依照票据的版面格式进行文字排版后输出,降低了人力损耗并提高了效率。
5.本发明一实施例提供了一种票据图像的文字提取方法,包括:获取票据图像,将所述票据图像输入至预设的文字检测识别模型中,以使所述文字检测识别模型识别所述票据图像中的各字段、各字段的中心点横坐标以及各字段的中心点纵坐标;
6.根据各字段的中心点纵坐标差值对各字段进行聚类,继而将位于同一类的字段作为同一行的字段;根据每一行中字段的中心点纵坐标的平均值确定每一行的行序;根据字段的中心点横坐标确定每一字段在对应行中的排序;
7.根据各字段的中心点横坐标差值对各字段进行聚类,继而将位于同一类的字段作为同一列的字段;根据每一列中字段的中心点横坐标的平均值确定每一列的列序;根据字段的中心点纵坐标确定每一字段在对应列中的排序;
8.根据每一行的行序、每一列的列序、每一字段在对应行中的排序以及每一字段在对应列中的排序进行排版,并按排版后版面格式将各字段进行输出。
9.进一步的,在将所述票据图像输入至预设的文字检测识别模型中之前,还包括:对所述票据图像进行图像预处理;其中,所述图像预处理包括以下任意一项或其组合:剔除模糊图像、票据角度校正以及剔除票据公章。
10.进一步的,所述文字检测识别模型包括:文字检测子模型和文字识别模型;所述文字检测识别模型识别所述票据图像中的各字段、各字段的中心点横坐标以及各字段的中心点纵坐标,具体包括:
11.通过文字检测子模型对所述票据图像进行检测,并识别各疑似字段的矩形框坐标以及各疑似字段所对应置信度分数;
12.将置信度分数小于预设阈值的疑似字段的矩形框进行剔除,继而根据将剩余疑似字段的矩形框坐标截取对应矩形框图像,并将截取的各矩形框图像输入至所述文字识别子模型,以使所述文字识别子模型识别各矩形框图像中的字段、字段的中心线横坐标以及中心线纵坐标。
13.进一步的,在根据字段的中心点横坐标确定每一字段在对应行中的排序之后,还包括:
14.根据同一行中相邻字段的中心点横坐标差值,基于聚类算法对同一行中的字段进行聚类,并将字段数目最多的类别作为第一基准类别;
15.计算所述第一基准类别中各中心点横坐标差值的平均值,获得第一平均值,并将所述第一平均值作为对应行的列宽;
16.逐一判断各相邻字段的中心点横坐标差值是否大于对应行的列宽,若是,则在两相邻字段之间填充第一预设字符。
17.进一步的,在根据字段的中心点纵坐标确定每一字段在对应列中的排序之后,还包括:
18.根据同一列中相邻字段的中心点纵坐标差值,基于聚类算法对同一列中的字段进行聚类,并将字段数目最多的类别作为第二基准类别;
19.计算所述第二基准类别中各中心点纵坐标差值的平均值,获得第二平均值,并将所述第二平均值作为对应列的行高;
20.逐一判断各相邻字段的中心点纵坐标差值是否大于对应列的行高,若是,则在两相邻字段之间填充第二预设字符。
21.进一步的,根据每一行的行序、每一列的列序、每一字段在对应行中的排序以及每一字段在对应列中的排序进行排版,并按排版后版面格式将各字段进行输出,包括:
22.根据每一行的行序、每一列的列序、每一字段在对应行中的排序、每一字段在对应列中的排序、每一行中的第一预设填充字符以及每一列中的第二预设填充字符进行排版,并按排版后版面格式将各字段、各第一预设填充字段以及各第二预设填充字符进行输出。
23.进一步的,按排版后版面格式将各字段、各第一预设填充字段以及各第二预设填充字符进行输出,包括:
24.按排版后的版面格式以json格式或者excel文件格式将各字段、各第一预设填充字段以及各第二预设填充字符进行输出。
25.在上述方法项实施例的基础上,本发明对应提供了一种票据图像的文字提取装置,包括:字段识别模块、行确定模块、列确定模块以及排版模块;
26.所述字段识别模块,用于获取票据图像,将所述票据图像输入至预设的文字检测识别模型中,以使所述文字检测识别模型识别所述票据图像中的各字段、各字段的中心点横坐标以及各字段的中心点纵坐标;
27.所述行确定模块,用于根据各字段的中心点纵坐标差值对各字段进行聚类,继而将位于同一类的字段作为同一行的字段;根据每一行中字段的中心点纵坐标的平均值确定每一行的行序;根据字段的中心点横坐标确定每一字段在对应行中的排序;
28.所述列确定模块,用于根据各字段的中心点横坐标差值对各字段进行聚类,继而将位于同一类的字段作为同一列的字段;根据每一列中字段的中心点横坐标的平均值确定
每一列的列序;根据字段的中心点纵坐标确定每一字段在对应列中的排序;
29.所述排版模块,用于根据每一行的行序、每一列的列序、每一字段在对应行中的排序以及每一字段在对应列中的排序进行排版,并按排版后版面格式将各字段进行输出。
30.进一步的,还包括:图像预处理模块,所述图像预处理模块,用于在字段识别模块将所述票据图像输入至预设的文字检测识别模型中之前,对所述票据图像进行图像预处理;其中,所述图像预处理包括以下任意一项或其组合:剔除模糊图像、票据角度校正以及剔除票据公章。
31.通过实施本发明实施例具有如下有益效果:
32.本发明实施例提供了一种票据图像的文字提取方法及装置,所述方法在通过文字检测识别模型对票据图像中的文字进行识别之后,通过聚类算法确定各字段所在的行与列,以及各字段在对应行、列中的顺序,最终根据确定各字段所在的行与列,以及各字段在对应行、列中的顺序对所识别出的文字进行自动排版后输出,实现了字段的自动排版,无需人工排版,降低了人力损耗并提高了效率。
附图说明
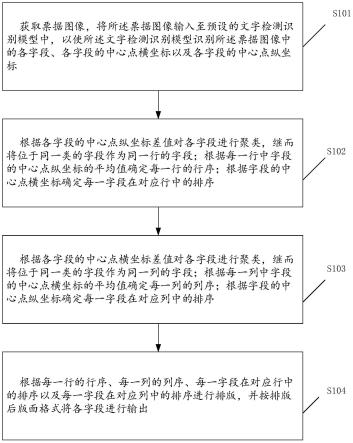
33.图1是本发明一实施例提供的一种票据图像的文字提取方法的流程示意图。
34.图2是本发明一实施例提供的一种票据图像的文字提取装置的结构示意图。
具体实施方式
35.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
36.如图1所示,本发明一实施例提供了一种票据图像的文字提取方法,包括:
37.步骤s101:获取票据图像,将所述票据图像输入至预设的文字检测识别模型中,以使所述文字检测识别模型识别所述票据图像中的各字段、各字段的中心点横坐标以及各字段的中心点纵坐标;
38.步骤s102:根据各字段的中心点纵坐标差值对各字段进行聚类,继而将位于同一类的字段作为同一行的字段;根据每一行中字段的中心点纵坐标的平均值确定每一行的行序;根据字段的中心点横坐标确定每一字段在对应行中的排序;
39.步骤s103:根据各字段的中心点横坐标差值对各字段进行聚类,继而将位于同一类的字段作为同一列的字段;根据每一列中字段的中心点横坐标的平均值确定每一列的列序;根据字段的中心点纵坐标确定每一字段在对应列中的排序;
40.步骤s104:根据每一行的行序、每一列的列序、每一字段在对应行中的排序以及每一字段在对应列中的排序进行排版,并按排版后版面格式将各字段进行输出。
41.对于步骤s101、在一个优选的实施例中,在将所述票据图像输入至预设的文字检测识别模型中之前,还包括:对所述票据图像进行图像预处理;其中,所述图像预处理包括以下任意一项或其组合:剔除模糊图像、票据角度校正以及剔除票据公章。
42.具体的,在本发明这一实施例中,通过扫描文件的方式获取票据图像,然后采用
opencv图像处理库对票据图像进行图像预处理,主要的图像预处理包括:
43.①
通过图像模糊度检测,剔除模糊图像:模糊的图像边界信息少,正常图像清晰边界信息大,因此通过计算图像二阶导的方差即可作为图像是否模糊的依据;基于现有的laplacian算子具有二阶可导性,可以计算出票据图像中密度变化快速的区域(边界),因此对票据图像计算laplacian算子并计算方差,方差越小,图像越模糊,可根据检测需要,动态设定模糊阈值,如果票据图像方差值小于此模糊阈值,则确定票据图像模糊,将票据图像进行剔除。
44.②
通过校正图像水平状态,实现票据角度校正:在通过扫描的方式获取票据图像,的过程中,需要人工放置纸质票据,存在一定的角度偏差,得到的票据图像存在一定的倾斜;为此需要进行票据角度校正,具体的,在每种票据中,都存在一条或者多条直线,采用opencv图像处理库的形态学函数erode和dilate寻找直线;因为可能存在多条直线,而计算倾斜角度,只需要一条直线,采用opencv的findcontours函数,计算最大周长的直线,并且返回此直线的角度,最后用opencv的warpaffine函数旋转图像,使票据图像处于水平状态;该方法可以处理任意角度的票据;
45.③
通过去除红色公章,剔除票据公章:一般票据盖着出具票据单位的公章,这个会影响识别文字的精度;采用opencv的split函数分离图像通道,得到r、g、b图像,然后r图像与g图像相减,相减之后的票据图像进行二值化处理,二值化之后获取票据图像中白色像素点的坐标,也就是红章位置的坐标,最后在原票据图像基础上用白色像素屏蔽红色像素。
46.在一个优选的实施例中,所述文字检测识别模型包括:文字检测子模型和文字识别模型;
47.所述文字检测识别模型识别所述票据图像中的各字段、各字段的中心点横坐标以及各字段的中心点纵坐标,具体包括:
48.通过文字检测子模型对所述票据图像进行检测,并识别各疑似字段的矩形框坐标以及各疑似字段所对应置信度分数;
49.将置信度分数小于预设阈值的疑似字段的矩形框进行剔除,继而根据将剩余疑似字段的矩形框坐标截取对应矩形框图像,并将截取的各矩形框图像输入至所述文字识别子模型,以使所述文字识别子模型识别各矩形框图像中的字段、字段的中心线横坐标以及中心线纵坐标。
50.在本发明中文字检测子模型可以使用dbnet文字检测网络,输出字段的矩形框坐标以及置信度分数;通过设置预设阈值,剔除置信度分数小于预设阈值的文字矩形框;最后,根据剩余的文字矩形框截取文字矩形框图像,输入到由cnn+rnn+ctc构建的文字识别子模型,文字矩形框图像中对应的字段、字段的中心点横坐标和纵坐标;
51.对于步骤s102:聚类时采用k-means聚类算法,逐一计算各字段两两之间的中心点纵坐标差值,然后采用k-means聚类算法进行聚类,如果两个字段位于同一行那么其差值是比较小的,如果两个字段位于不同行那么纵坐标的差值会比较大,依据这一原理,通过k-means聚类算法可以将各字段进行聚类,这样就可以将各字段划分入若干行,将各字段划分入对应的行之后,计算该行中所有字段的中心点纵坐标的平均值,根据平均值确定每行的行序,这样可以确定每个字段在具体的第几行,紧接着根据字段的中心点横坐标确定每一字段在对应行中的排序,这样就可以确定各个字段在对应行中的第几位。
52.在一个优选的实施例中,在根据字段的中心点横坐标确定每一字段在对应行中的排序之后,还包括:根据同一行中相邻字段的中心点横坐标差值,基于聚类算法对同一行中的字段进行聚类,并将字段数目最多的类别作为第一基准类别;计算所述第一基准类别中各中心点横坐标差值的平均值,获得第一平均值,并将所述第一平均值作为对应行的列宽;逐一判断各相邻字段的中心点横坐标差值是否大于对应行的列宽,若是,则在两相邻字段之间填充第一预设字符。
53.根据上述步骤已经确定了各字段所在的具体行,以及在每一行中的排序,但是这里存在一个问题,如果同一行中,某列的一个字段缺省,经过从小到大排序,后面的字段就会往前填充,最终在后续排版的时候,版面内容就会错乱。因此,在这一实施例中,还继续通过聚类算法计算出每一行所对应的列宽,根据计算得到列宽,对同一行排序之后的字段,计算相邻字段之间中心点横坐标差值,如果差值超过列宽,那么判断两个字段之间存在缺省字段,此时可以采用第一预设字符,填充至两个字段之间;可选的上述第一预设字段可以为双引号,也可以空格字符等,具体可根据实际情况进行调整,通过这一实施例可以使得在存在字段缺省时,也可以保持后续排版的正确性。
54.对于步骤s103、逐一计算各字段两两之间的中心点横坐标差值,然后采用k-means聚类算法进行聚类,如果两个字段位于同一列那么其差值是比较小的,如果两个字段位于不同列那么横坐标的差值会比较大,依据这一原理,通过k-means聚类算法可以将各字段进行聚类,这样就可以将各字段划分入若干列,将各字段划分入对应的列之后,计算该列中所有字段的中心点横坐标的平均值,根据平均值确定每行的列序,这样可以确定每个字段在具体的第几列,紧接着根据字段的中心点纵坐标确定每一字段在对应列中的排序,这样就可以确定各个字段在对应列中的第几位。
55.在一个优选的实施例中,在根据字段的中心点纵坐标确定每一字段在对应列中的排序之后,还包括:
56.根据同一列中相邻字段的中心点纵坐标差值,基于聚类算法对同一列中的字段进行聚类,并将字段数目最多的类别作为第二基准类别;
57.计算所述第二基准类别中各中心点纵坐标差值的平均值,获得第二平均值,并将所述第二平均值作为对应列的行高;
58.逐一判断各相邻字段的中心点纵坐标差值是否大于对应列的行高,若是,则在两相邻字段之间填充第二预设字符。
59.根据上述步骤已经确定了各字段所在的具体列,以及在每一列中的排序,但是这里存在一个问题,如果同一列中,某列的一个字段缺省,经过从小到大排序,后面的字段就会往前填充,最终在后续排版的时候,版面内容就会错乱。因此,在这一实施例中,还继续通过聚类算法计算出每一列所对应的行高,根据计算得到行高,对同一列排序之后的字段,计算相邻字段之间中心点纵坐标差值,如果差值超过行高,那么判断两个字段之间存在缺省字段,此时可以采用第二预设字符,填充至两个字段之间;可选的上述第二预设字段可以为双引号,也可以空格字符等,具体可根据实际情况进行调整,通过这一实施例可以使得在存在字段缺省时,也可以保持后续排版的正确性。
60.对于步骤s104、若经过识别之后,各行各列中都不存在字段缺省,那么此时可以直接根据每一行的行序、每一列的列序、每一字段在对应行中的排序以及每一字段在对应列
中的排序对各字段进行排版,并按排版后版面格式将各字段以json格式或者excel文件格式输出。
61.若经过识别之后,各行各列中存在字段缺省,则在一个优选的实施例中,根据每一行的行序、每一列的列序、每一字段在对应行中的排序以及每一字段在对应列中的排序进行排版,并按排版后版面格式将各字段进行输出,包括:
62.根据每一行的行序、每一列的列序、每一字段在对应行中的排序、每一字段在对应列中的排序、每一行中的第一预设填充字符以及每一列中的第二预设填充字符进行排版,并按排版后版面格式将各字段、各第一预设填充字段以及各第二预设填充字符进行输出。其中,按排版后版面格式将各字段、各第一预设填充字段以及各第二预设填充字符进行输出,包括:按排版后的版面格式以json格式或者excel文件格式将各字段、各第一预设填充字段以及各第二预设填充字符进行输出。
63.在上述方法项实施例的基础上,本发明对应提供了装置项实施例;
64.如图2所示,本发明一实施例提供了一种票据图像的文字提取装置,包括:字段识别模块1、行确定模块2、列确定模块3以及排版模块4;
65.所述字段识别模块,用于获取票据图像,将所述票据图像输入至预设的文字检测识别模型中,以使所述文字检测识别模型识别所述票据图像中的各字段、各字段的中心点横坐标以及各字段的中心点纵坐标;
66.所述行确定模块,用于根据各字段的中心点纵坐标差值对各字段进行聚类,继而将位于同一类的字段作为同一行的字段;根据每一行中字段的中心点纵坐标的平均值确定每一行的行序;根据字段的中心点横坐标确定每一字段在对应行中的排序;
67.所述列确定模块,用于根据各字段的中心点横坐标差值对各字段进行聚类,继而将位于同一类的字段作为同一列的字段;根据每一列中字段的中心点横坐标的平均值确定每一列的列序;根据字段的中心点纵坐标确定每一字段在对应列中的排序;
68.所述排版模块,用于根据每一行的行序、每一列的列序、每一字段在对应行中的排序以及每一字段在对应列中的排序进行排版,并按排版后版面格式将各字段进行输出。
69.在一个优选的实施例中,还包括:图像预处理模块,所述图像预处理模块,用于在字段识别模块将所述票据图像输入至预设的文字检测识别模型中之前,对所述票据图像进行图像预处理;其中,所述图像预处理包括以下任意一项或其组合:剔除模糊图像、票据角度校正以及剔除票据公章。
70.需说明的是,本发明装置项实施例是与本发明方法项实施例相对应的,其可以实现本发明任意一项所述的票据图像的文字提取方法。另,以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。另外,本发明提供的装置实施例附图中,模块之间的连接关系表示它们之间具有通信连接,具体可以实现为一条或多条通信总线或信号线。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
71.以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为
本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1