一种图像瑕疵检测方法
1.本发明涉及图像检测的算法研究技术领域,特别是涉及一种图像瑕疵检测方法。
背景技术:
2.在当今时代,人工智能的发展势不可挡,对工业制造行业造成了重要影响。视觉检测是工业生产制造的重要环节之一,瓦楞纸箱高网线印刷设备具有高网线高分辨印刷、速度快、幅宽大和印刷图案纹理复杂多变等特点。现阶段行业面临缺少生产后端视觉检测设备的关键共性难题,印刷质量与稳定性难以保障,因此,需要一种对印刷瓦楞纸箱上的图像进行高速实时在线瑕疵检测的方法。
3.近年来瑕疵检测的方法技术发展迅速,主要有以下几种检测方法:1.利用高速图像扫描算法,利用动态大小、阈值和变换的线性和非线性滤波器检测边缘和边界,进行进一步分析。2.进行模版匹配,从而找到瑕疵所在的位置。3.从局部区域提取图像描述规则。这些检测方法适用于不能制备瑕疵模型的瑕疵检测问题,如划痕或叠加检测、纹理图像分析等。
4.以上这些方法最终都是以图像差分的方式进行瑕疵检测的,这也使得这些方法在卷烟包装纸这种小尺寸印刷品上效果较好,而在瓦楞纸箱这种大尺寸印刷品上的瑕疵检测中效果却不佳。因此,提供基于效果良好的文字检测方法在纸箱图像瑕疵检测中显得十分重要。
5.现有技术公开了一种瓦楞纸包装箱印刷瑕疵视觉检测方法及装置的中国发明申请,以标准瓦楞纸包装箱印品作为标准样本,将标准样本放置在工作台上定位;新建产品标准标准的模板库:检测系统采集所标准样本的无瑕疵印品的,通过定位设置和检测设置以设定各检测项目的标准参数及其检测算法,并以该瓦楞纸包装箱的条码作为名字保存,建立并保存标准参照标准的模板;取待测瓦楞纸包装箱作为测样,检测系统扫描测样的条码以获取与之相同条码的标准参照标准的模板;新建待测产品标准的模板:将测样放置在工作台上定位,通过检测系统框选并撷取测样图像,重新定位设置和检测设置以获取产品标准的模板;启动检测,对产品标准的模板的测样图像与标准参照标准的模板的进行对比分析,判断产品标准的模板是否存在瑕疵,但该方法检测瓦楞纸包装箱印品过程复杂,效率较低。
技术实现要素:
6.本发明提供了一种图像瑕疵检测方法,用于对待检测图像进行高速瑕疵检测。
7.本发明的目的至少通过以下技术方案之一实现,一种图像瑕疵检测方法,包括以下步骤:
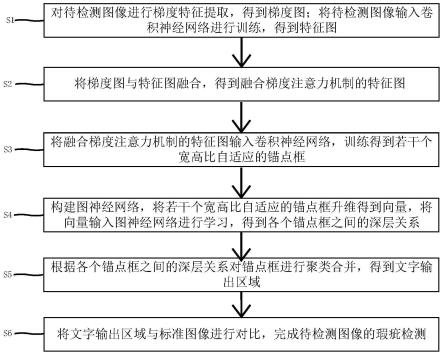
8.s1:对待检测图像进行梯度特征提取,得到梯度图;将待检测图像输入卷积神经网络进行训练,得到特征图;
9.s2:将梯度图与特征图融合,得到融合梯度注意力机制的特征图;
10.s2:将融合梯度注意力机制的特征图输入卷积神经网络,训练得到若干个宽高比自适应的锚点框;
11.s4:构建图神经网络,将若干个宽高比自适应的锚点框升维得到向量,将向量输入图神经网络进行学习,得到各个锚点框之间的深层关系;
12.s5:根据各个锚点框之间的深层关系对锚点框进行聚类合并,得到文字输出区域;
13.s6:将文字输出区域与标准图像进行对比,完成待检测图像的瑕疵检测。
14.其中,所述深层关系指各个锚点框之间的对应连接关系;
15.上述方案中,所述图神经网络为现有技术中公开的图神经网络;
16.本发明通过生成宽高比自适应的锚点框,利用图神经网络得到各个锚点框之间的深层关系,使锚点框能更好地聚类合并,实现待检测图像上的文字信息所在位置快速、准确定位,方便瑕疵检测的处理。
17.进一步的,步骤s1中,所述待检测图像为纸箱包装印刷品图像。
18.进一步的,步骤s1中,对待检测图像进行梯度特征提取时,分别计算待检测图像梯度特征的水平方向梯度值和竖直方向梯度值,取其中较大的一个梯度值作为最终的梯度值;
19.其过程为:待检测图像坐标为(x,y)的像素点i,从水平方向的梯度以及竖直方向的梯度中选取较大的一个进行赋值,作为像素点i的最终梯度值gi,其表达式如下:
[0020][0021]
其中,f(x,y)是指在图像坐标(x,y)处像素点i的像素值。
[0022]
上述方案中,最终的梯度值构成梯度图,可以更好地保留梯度特征。
[0023]
进一步的,步骤s1所述特征图为16维特征图。
[0024]
上述方案中,特征图为16维特征图既可以保留一定数量的特征,又不会使得整个网络过于庞大冗余。
[0025]
进一步的,步骤s2具体为:
[0026]
对最终的梯度值进行归一化处理,得到权重值,再将权重值与特征图进行融合,得到融合梯度注意力机制的特征图;
[0027]
其中,融合梯度注意力机制的特征图在第k维像素点i处的特征值t
i,k
表达式如下:
[0028][0029]
其中,n为所有像素点的集合,t
i,k
为特征图中像素点i在第k(1《k《16)维处的特征值。
[0030]
上述方案中,通过得到融合梯度注意力机制的特征图,可以更快速的检测待检测图像中的文字区域。
[0031]
进一步的,步骤s3中,训练得到的锚点框的信息中,锚点框的宽与锚点框的高成比例关系,其中,锚点框b表达式如下:
[0032]
b=(x,y,h,r,cosθ,sinθ,c)
[0033]
其中,x和y是锚点框的图像坐标点,h为锚点框的高度,r为锚点框的宽高比,θ为锚点框靠近水平方向的边与水平方向所构成的夹角,c为锚点框的置信度。
[0034]
进一步的,步骤s4中,向量输入图神经网络进行学习,得到各个锚点框之间的深层关系,其过程为:
[0035]
在向量输入图神经网络前,对每张待检测图像构建多个局部图,局部图由若干个节点构成,每个局部图只包含部分锚点框;
[0036]
计算局部图节点之间欧几里德距离的相似度es,作为辅助信息帮助图神经网络得到锚点框之间的深层关系,es表达式为:
[0037][0038]
其中,d(p,vi)为中枢p与节点vi之间的距离,hm和wm分别为图像的高和宽,v
p
为中枢p所在的局部图中的所有节点;
[0039]
其中d(p,vi)的表达式如下:
[0040][0041]
其中,x
p
为中枢p的横坐标,为节点vi的横坐标,y
p
为中枢p的纵坐标,为节点vi的纵坐标;
[0042]
对中枢p设定限制条件g
iou
,其表达式为:
[0043][0044]
其中,ξ是设定阈值,g
p
为局部图g
p
,gq为局部图gq,中枢p和中枢q在同一文字实例t中,g
p
∪gq为局部图g
p
和局部图gq的并集,g
p
∩gq为局部图g
p
和局部图gq的交集;
[0045]
上述方案中,锚点框之间的深层关系指锚点框之间的连接关系,中枢指置信度较高的锚点框,以它为节点来生成局部图,限制条件g
iou
的作用是使不同局部图之间的相同节点不要太多;构建多个局部图可以提高图神经网络的学习速度。
[0046]
进一步的,步骤s5具体过程为:
[0047]
通过图神经网络对各个锚点框之间的深层关系进行判断,判断各个锚点框之间的关联度,对各个锚点框进行分组,筛选出高关联度的锚点框,将高关联度的锚点框连接起来,得到文字预测区域,使用nms减少冗余,使用bfs对连接起来的锚点框进行聚类合并,得到文字输出区域;
[0048]
对文字预测区域设置损失函数l,其表达式如下:
[0049][0050]
其中,b为文字预测区域,c为锚点框的置信度,l为锚点框坐标位置,g为实际的文字区域,n为与实际的文字区域匹配的锚点框数,l
conf
为文字预测区域置信度的交叉熵损失函数,l
loc
为文字预测区域的位置损失函数;
[0051]
文字预测区域置信度的交叉熵损失函数l
conf
,其表达式如下:
[0052][0053]
其中,为文字预测区域的真实标签,正类为1,负类为0;
[0054]
文字预测区域的位置损失函数l
loc
,其表达式如下:
[0055][0056]
其中,m为文字预测区域b的位置与实际的文字区域之间的欧式距离,其表达式如下:
[0057][0058]
上述方案中,通过设置损失函数可以同时参考锚点框的位置与置信度来对锚点框的准确度进行判断,提高图神经网络的准确率。
[0059]
上述方案中,使用nms(non-maximum suppression,非极大值抑制)减少冗余,使用bfs(breadth first search,宽度优先搜索)对连接起来的锚点框进行聚类合并,将图神经网络判断的高关联度的锚点框连接起来,得到文字输出区域,改善背景噪声信息对锚点框的负面影响。
[0060]
上述方案中,高关联度指锚点框与锚点框之间连接的可能性较高。
[0061]
进一步的,步骤s6的具体过程为:
[0062]
将得到的文字输出区域切割后得到若干图像块,将若干图像块分别输入到标准图像中,进行对比分析,在标准图像块上进行滑动窗口操作,衡量文字输出区域切割后的图像块和标准图像块之间的相似度,通过匹配出来的相似度进行瑕疵检测,判断是否出现位置瑕疵或内容瑕疵,完成待检测图像的瑕疵检测;其中,所述标准图像指完美、无瑕疵的印刷品图像,由标准图像块组成;
[0063]
判断是否出现位置瑕疵或内容瑕疵时,需设定一个阈值,衡量文字输出区域切割后的图像块和标准图像块之间的相似度后,得到文字输出区域与标准图像之间的相似度,若相似度低于设定的阈值,则判定检测到位置瑕疵或内容瑕疵,进而判定该待检测图像有瑕疵;若位置瑕疵或内容瑕疵没有检测到,则判定该待检测图像无瑕疵。
[0064]
进一步的,本发明提供一种图像瑕疵检测系统,用于实现一种图像瑕疵检测方法,包括:特征提取模块、融合梯度注意力机制模块、锚点框聚类合并模块和标准图像对比模块,其中:
[0065]
所述特征提取模块用于对待检测图像进行梯度特征提取,得到梯度图;并将待检测图像输入卷积神经网络,训练得到特征图;
[0066]
所述融合梯度注意力机制模块用于将梯度图与特征图融合,得到融合梯度注意力机制的特征图;
[0067]
所述锚点框聚类合并模块用于根据锚点框之间的深层关系对锚点框进行聚类合并,得到文字输出区域;
[0068]
所述标准图像对比模块用于将文字输出区域与标准图像对比,判断文字输出区域有无瑕疵。
[0069]
与现有技术相比,本发明技术方案的有益效果是:
[0070]
本发明提出一种图像瑕疵检测方法,通过生成宽高比自适应的锚点框,更好地贴合待检测图像中文字区域,利用图神经网络得到各个锚点框之间的深层关系,使锚点框能更好地聚类合并,更快速、准确地定位到待检测图像上不同尺度大小的文字信息和文字所在位置,方便瑕疵检测的处理。
附图说明
[0071]
附图仅用于示例性说明,不能理解为对本专利的限制;
[0072]
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不为实际产品的尺寸;
[0073]
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0074]
图1为本发明一实施例提供的一种图像瑕疵检测方法的待检测图像瑕疵检测步骤流程图;
[0075]
图2为本发明一实施例提供的一种图像瑕疵检测方法的待检测图像瑕疵检测应用示意图;
[0076]
图3为本发明一实施例提供的锚点框生成算法网络结构示意图。
具体实施方式
[0077]
下面结合附图和实施例对本发明的技术方案做进一步说明。
[0078]
实施例1
[0079]
为了便于理解,请参阅图1和图2,本技术提供一种图像瑕疵检测方法的一个实施例,包括以下步骤:
[0080]
s1:对待检测图像进行梯度特征提取,得到梯度图;将待检测图像输入卷积神经网络进行训练,得到特征图;
[0081]
s2:将梯度图与特征图融合,得到融合梯度注意力机制的特征图;
[0082]
s3:将融合梯度注意力机制的特征图输入卷积神经网络,训练得到若干个宽高比自适应的锚点框;
[0083]
s4:构建图神经网络,将若干个宽高比自适应的锚点框升维得到向量,将向量输入图神经网络进行学习,得到各个锚点框之间的深层关系;
[0084]
s5:根据各个锚点框之间的深层关系对锚点框进行聚类合并,得到文字输出区域;
[0085]
s6:将文字输出区域与标准图像进行对比,完成待检测图像的瑕疵检测。
[0086]
其中,所述深层关系指各个锚点框之间的对应连接关系;
[0087]
本发明通过生成宽高比自适应的锚点框,利用图神经网络得到各个锚点框之间的深层关系,使锚点框能更好地聚类合并,实现待检测图像上的文字信息所在位置快速、准确定位,方便瑕疵检测的处理。
[0088]
实施例2
[0089]
在实施例1的基础上,结合具体的实施例子对方案进行说明,进一步体现本方案的技术效果,具体为:
[0090]
s1:对待检测图像进行梯度特征提取,得到梯度图;将待检测图像输入卷积神经网络进行训练,得到特征图;
[0091]
s2:将梯度图与特征图融合,得到融合梯度注意力机制的特征图;
[0092]
s3:将融合梯度注意力机制的特征图输入卷积神经网络,训练得到若干个宽高比自适应的锚点框;
[0093]
s4:构建图神经网络,将若干个宽高比自适应的锚点框升维得到向量,将向量输入
图神经网络进行学习,得到各个锚点框之间的深层关系;
[0094]
s5:根据各个锚点框之间的深层关系对锚点框进行聚类合并,得到文字输出区域;
[0095]
s6:将文字输出区域与标准图像进行对比,完成待检测图像的瑕疵检测。
[0096]
具体的,步骤s1中,所述待检测图像为纸箱包装印刷品图像。
[0097]
在具体实施过程中,文字检测可以通过分析图像的信息,定位图像中的文字区域,通常以边界框的形式将单词或文字行标记出来。在纸箱印刷品中往往存在大量的文字区域,将文字检测任务应用到纸箱瑕疵检测中可以快速定位到纸箱文字所在区域,再对该区域进行后续的操作从而更快速准确地判定该区域是否存在印刷瑕疵。
[0098]
具体的,步骤s1中,对待检测图像进行梯度特征提取时,分别计算待检测图像的水平方向梯度值和竖直方向梯度值,取其中较大的一个梯度值作为最终的梯度值;
[0099]
其过程为:待检测图像坐标为(x,y)的像素点i,从水平方向的梯度以及竖直方向的梯度中选取较大的一个进行赋值,作为像素点i的最终梯度值gi,其表达式如下:
[0100][0101]
其中,f(x,y)是指在图像坐标(x,y)处像素点i的像素值。
[0102]
具体的,所述特征图为16维特征图。
[0103]
具体的,步骤s2具体为:
[0104]
对最终的梯度值进行归一化处理,得到权重值,再将权重值与特征图进行融合,得到融合梯度注意力机制的特征图,提高卷积神经网络在待检测图像中文字边缘区域的注意力。
[0105]
在具体实施过程中,待检测图像中文字信息具有边界清晰的特点,待检测图像上像素点i的梯度值与16维的特征图进行融合,得到融合梯度注意力机制的特征图,增强待检测图像边界区域在卷积神经网络任务中的权重。
[0106]
其中,融合梯度注意力机制的特征图在第k维像素点i处的特征值t
i,k
表达式如下:
[0107][0108]
其中,n为所有像素点的集合,t
i,k
为特征图中像素点i在第k(1《k《16)维处的特征值。
[0109]
具体的,步骤s3中,训练得到的锚点框的信息中,锚点框的宽与锚点框的高成比例关系,即融合梯度注意力机制的特征图输入卷积神经网络得到一系列有序的矩形锚点框,所构成的每个锚点框b与一组几何属性相关联,锚点框b表达式如下:
[0110]
b=(x,y,h,r,cosθ,sinθ,c)
[0111]
其中,x和y是锚点框的图像坐标点,h为锚点框的高度,r为锚点框的宽高比,θ为锚点框靠近水平方向的边与水平方向所构成的夹角,c为锚点框的置信度。
[0112]
在具体实施过程中,由于锚点框通常只与它的相邻锚点框相连接,如果对每个预测任务都构建一个完整的图像会导致计算效率低,因此对每张待检测图像构建多个局部图,每个局部图只包含部分锚点框,提高锚点框间关系的效率和图神经网络的学习速度。
[0113]
在具体实施过程中,步骤s3中,构建锚点框生成算法网络,所述锚点框生成算法网
络包括5个下采样模块、5个上采样模块和2个全连接层,将构建好的锚点框生成算法网络作为卷积神经网络。如图3所示,待检测图像中融合梯度注意力机制的特征图在锚点框生成算法网络中依次经过5个下采样模块进行下采样,再分别对每个下采样模块进行上采样,得到上采样输出结果,将上采样输出结果进行融合后输入到两个全连接层生成宽高比自适应的锚点框。锚点框回归对应锚点框的位置坐标,锚点框分类即判断锚点框是否为含有文字的锚点框。
[0114]
具体的,步骤s4中,向量输入图神经网络进行学习,得到各个锚点框之间的深层关系,其过程为:
[0115]
在向量输入图神经网络前,对每张待检测图像构建多个局部图,局部图由若干个节点构成,每个局部图只包含部分锚点框;
[0116]
计算局部图节点之间欧几里德距离的相似度es,作为辅助信息帮助图神经网络得到锚点框之间的深层关系,es表达式为:
[0117][0118]
其中,d(p,vi)为中枢p与节点vi之间的距离,hm和wm分别为图像的高和宽,v
p
为中枢p所在的局部图中的所有节点的集合;
[0119]
其中d(p,vi)的表达式如下:
[0120][0121]
其中,x
p
为中枢p的横坐标,为节点vi的横坐标,y
p
为中枢p的纵坐标,为节点vi的纵坐标。
[0122]
在具体实施过程中,为了避免训练过程中出现许多相同局部图,导致样本的梯度积累,对步骤s4中的中枢p设定限制条件g
iou
,其表达式为:
[0123][0124]
其中,ξ是设定阈值,g
p
为局部图g
p
,gq为局部图gq,中枢p和中枢q在同一文字实例t中,g
p
∪gq为局部图g
p
和局部图gq的并集,g
p
∩gq为局部图g
p
和局部图gq的交集。
[0125]
具体的,步骤s5具体过程为:
[0126]
通过图神经网络对各个锚点框之间的深层关系进行判断,判断各个锚点框之间的关联度,对各个锚点框进行分组,筛选出高关联度的锚点框,将高关联度的锚点框连接起来,得到文字预测区域,使用nms减少冗余,使用bfs对连接起来的锚点框进行聚类合并,得到文字输出区域;
[0127]
对文字预测区域设置损失函数l,其表达式如下:
[0128][0129]
其中,b为文字预测区域,c为锚点框的置信度,l为锚点框坐标位置,g为实际的文字区域,n为与实际的文字区域匹配的锚点框数,l
conf
为文字预测区域置信度的交叉熵损失函数,l
loc
为文字预测区域的位置损失函数;
[0130]
文字预测区域置信度的交叉熵损失函数l
conf
,其表达式如下:
[0131][0132]
其中,为文字预测区域的真实标签,正类为1,负类为0;
[0133]
文字预测区域的位置损失函数l
loc
,其表达式如下:
[0134][0135]
其中,m为文字预测区域b的位置与实际的文字区域之间的欧式距离,其表达式如下:
[0136][0137]
上述方案中,通过设置损失函数可以同时参考锚点框的位置与置信度来对锚点框的准确度进行判断,提高图神经网络的准确率。
[0138]
上述方案中,使用nms(non-maximum suppression,非极大值抑制)减少冗余,使用bfs(breadth first search,宽度优先搜索)对连接起来的锚点框进行聚类合并,将图神经网络判断的高关联度的锚点框连接起来,得到文字输出区域,改善背景噪声信息对锚点框的负面影响。
[0139]
具体的,步骤s6的具体过程为:
[0140]
将得到的文字输出区域切割后得到若干图像块,将若干图像块分别输入到标准图像中,进行对比分析,在标准图像块上进行滑动窗口操作,衡量文字输出区域切割后的图像块和标准图像块之间的相似度,通过匹配出来的相似度进行瑕疵检测,判断是否出现位置瑕疵或内容瑕疵,完成待检测图像的瑕疵检测;其中,所述标准图像指完美、无瑕疵的印刷品图像,由标准图像块组成;
[0141]
判断是否出现位置瑕疵或内容瑕疵时,需设定一个阈值,衡量文字输出区域切割后的图像块和标准图像块之间的相似度后,得到文字输出区域与标准图像之间的相似度,若相似度低于设定的阈值,则判定检测到位置瑕疵或内容瑕疵,进而判定该待检测图像有瑕疵;若位置瑕疵或内容瑕疵没有检测到,则判定该待检测图像无瑕疵。
[0142]
本发明提出一种图像瑕疵检测方法,通过生成宽高比自适应的锚点框,更好地贴合待检测图像中文字区域,对每张待检测图像构建多个局部图,每个局部图只包含部分锚点框,宽高比自适应的锚点框输入图神经网络进行学习,使锚点框能更好地聚类合并,更快速、准确地定位到待检测图像上不同尺度大小的文字信息和文字所在位置,大大提高了印刷品图像中文字区域的瑕疵检测效率。
[0143]
实施例3
[0144]
具体的,在上述实施例的基础上,结合具体的实施例子对方案进行说明,进一步体现本方案的技术效果,具体为:
[0145]
本发明提供一种图像瑕疵检测系统,包括:特征提取模块、融合梯度注意力机制模块、锚点框聚类合并模块和标准图像对比模块,其中:
[0146]
所述特征提取模块用于对待检测图像进行梯度特征提取,得到梯度图;并将待检测图像输入卷积神经网络,训练得到特征图;
[0147]
所述融合梯度注意力机制模块用于将梯度图与特征图融合,得到融合梯度注意力
机制的特征图;
[0148]
所述锚点框聚类合并模块用于根据锚点框之间的深层关系对锚点框进行聚类合并,得到文字输出区域;
[0149]
所述标准图像对比模块用于将文字输出区域与标准图像对比,判断文字输出区域有无瑕疵。
[0150]
本实施例中,构建图像瑕疵检测系统,实现对含有多种尺度的文字印刷内容纸箱中的图像进行快速定位,定位出文字所在图像中的位置,可以更好地进行图像瑕疵检测的研究。
[0151]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1