基于多策略原型生成的低资源神经机器翻译方法
1.本发明涉及基于多策略原型生成的低资源神经机器翻译方法,属于自然语言处理技术领域。
背景技术:
2.近年来,随着端到端翻译模型和注意力机制的提出,神经机器翻译(neural machine translation,nmt)取得了长足的发展,在主流语言对上的翻译性能迅速超过统计机器翻译,逐渐发展为目前主流的机器翻译模式。为提升神经机器翻译性能,研究者们提出了各种方法。其中,基于原型序列融入的原型方法受到很多关注。资源丰富场景下,利用相似性翻译作为目标端原型序列,能够有效提升神经机器翻译的性能。然而在低资源场景下,由于平行语料资源匮乏,导致不能匹配得到原型序列或序列质量不佳。因此,在低资源场景下,探索如何有效利用原型序列来提高神经机器翻译的性能,具有非常重要的研究和应用价值。
3.原型序列是存在于翻译记忆库中的目标端句子,内含目标语言端语义信息。原型方法通过在翻译进程中引入原型序列来利用目标端语义信息,使其被隐式地用于指导词对齐和解码约束等过程。目前原型方法领域的研究工作主要集中在原型检索和原型利用两个阶段。原型序列检索方法在资源丰富场景下得到了较好的发展,原因在于资源丰富场景下存在大规模的翻译记忆库。因此原型方法可以通过检索记忆库得到较高质量的原型序列,进而有效地提升翻译性能。然而在低资源场景下,受限于平行语料的规模和质量,传统的原型序列检索方法往往难以检索得到可用的原型。对下一步翻译任务的效果提升有限。除此以外,在对原型序列利用方面,尤其是将原型序列作为编码输入融入翻译模型的方式上,研究者们提出了很多改进方法。例如采用双编码器结构对输入句子和原型序列同时进行编码,同时在解码端引入门控机制来平衡源句和原型序列间的信息比例。然而,以上方法均带来了翻译性能上的提升,但是仍然主要面向资源丰富场景,较少针对低资源场景进行特定的改进。因此,本发明提出了基于多策略原型生成的低资源神经机器翻译方法,通过改进的原型获取方法和特定的翻译框架结构,更好地提升低资源神经机器翻译的性能。
技术实现要素:
4.本发明提供了基于多策略原型生成的低资源神经机器翻译方法,通过结合传统检索方法和所提出的伪原型生成方法提升原型序列获取的效率和质量,同时利用神经网络结构改变的方式将检索到的原型融入编解码器框架,在最大化利用原型序列所含语义信息的同时削弱低质量序列带来的影响;能提升低资源神经机器翻译的性能。
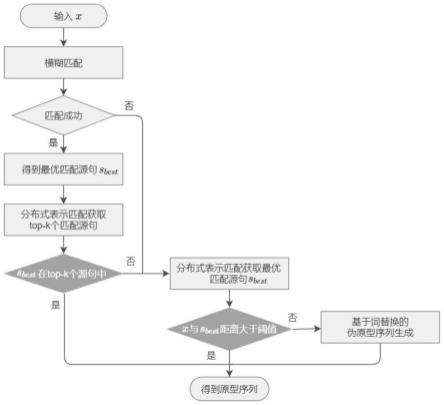
5.本发明的技术方案是:基于多策略原型生成的低资源神经机器翻译方法,所述方法的具体步骤如下:
6.step1、语料预处理:预处理不同规模的平行训练语料、验证语料和测试语料,用于模型训练、参数调优和效果测试;并构建多语言全局替换词典和关键词词典,用于伪原型生
成;
7.step2、原型生成:利用基于多种策略混合的原型生成方法进行原型生成,以保证原型序列的可用性;该步骤的具体思路为:首先结合使用模糊匹配和分布式表示匹配进行原型检索,如未检索到原型,则利用词替换操作对输入句子中的关键词进行替换,得到伪原型序列;
8.step3、融入原型序列的翻译模型构建:改进传统基于注意力机制的神经机器翻译模型的编解码器结构,以更好的融入原型序列,使用步骤step1,step2的语料作为模型输入,产生最终译文。
9.作为本发明的优选方案,所述step1的具体步骤为:
10.step1.1、使用机器翻译领域的通用数据集iwslt15进行模型训练,翻译任务为英-越、英-中和英-德;验证和测试方面,选择tst2012作为验证集进行参数优化和模型选择,选择tst2013作为测试集进行测试评估;
11.step1.2、使用panlex、维基百科、实验室自建的英汉-东南亚语词典以及谷歌翻译接口来构建英-越-中-德全局替换词典;
12.step1.3、在step1.2的基础上,通过标记筛选方式得到关键词典,筛选过程中保留全部实体;为避免替换过于集中于某些热点名词,对名词性词汇于语料中检索并按出现频率进行倒排。
13.作为本发明的优选方案,所述step2的具体步骤为:
14.step2.1、结合使用模糊匹配和分布式表示匹配进行原型检索;具体实现如下:翻译记忆库是由l对平行句组成的集合{(s
l
,t
l
):l=1,
…
,l},其中s
l
为源句,t
l
为目标句;对给定的输入句子x,首先使用关键词匹配于翻译记忆库中进行检索;采用模糊匹配作为关键词匹配方法,其定义为:
[0015][0016]
其中ed(x,si)是x,si间的编辑距离,|x|为x的句长;
[0017]
与基于关键词的匹配方法不同,分布式表示匹配根据句子向量表征之间的距离进行检索,某种程度上是利用语义信息进行相似性检索的手段,也因此提供了与关键词匹配不同的检索视角;基于余弦相似度的分布式表示匹配定义为:
[0018][0019]
其中h
x
和分别为x和si的向量表征,||h
x
||为向量h
x
的度量;为实现快速计算,首先使用多语言预训练模型mbert得到句子x和si的向量表征,随后依据表征,使用faiss工具进行相似性匹配;
[0020]
当模糊匹配能够得到最优匹配源句s
best
时,利用分布式表示匹配得到top-k个匹配结果的集合s
′
={s1,s2,
…
,sk},如s
best
∈s
′
,则选取s
best
对应的目标端句子t
best
作为原型序列;当模糊匹配未能检索到匹配源句或时,则通过分布式表示匹配检索出最优匹配源句s
best
;
[0021]
step2.2、若step2.1未检索到原型,则对输入的句子进行关键词替换,生成伪原
型,称之为基于词替换的伪原型生成;具体包含以下两种替换策略;
[0022]
全局替换:当输入句子未能检索到匹配时,基于最大化原则,利用双语词典对输入句子中的词进行尽力替换,替换后的句子被称为伪原型序列;
[0023]
关键词替换:从双语词典中抽取重要名词和实体构建关键词词典;当输入句子未能检索到匹配时,利用该词典对输入句子中的关键词进行替换,生成伪原型序列,替换次数上限小于设定的阈值;期望在共享词表的基础上,该混合了源端和重要目标端词汇的伪原型序列能够为译文的生成提供指导。
[0024]
作为本发明的优选方案,所述step3中包括:
[0025]
编码端采用双编码器结构,能够同时接收句子输入和原型序列输入,然后将输入编码为相应的隐状态表示;句子编码器为标准的transformer编码器,由多层堆叠而成;其中每层又由2个子层构成:多头自注意力层和前馈神经网络层,均使用残差连接和层正则化机制;给定输入句子x=(x1,x2,
…
,xm),句子编码器将其编码为相应的隐状态序列h
x
=(h
x1
,h
x2
,
…
,h
xm
),其中h
xi
为xi对应的隐状态,原型编码器在神经网络结构上与句子编码器一致,给定原型序列t=(t1,t2,
…
,tn),原型编码器将其编码为相应的隐状态序列h
t
=(h
t1
,h
t2
,
…
,h
tn
),其中h
ti
为ti对应的隐状态。
[0026]
作为本发明的优选方案,所述step3中包括:
[0027]
解码端融入门控机制,利用神经网络自学习能力实现句子信息和原型信息间的比例优化,控制解码过程中的信息流动;改进后的解码器由三个子层构成:(1)自注意力层;(2)改进的编解码注意力层;(3)全连接前馈网络层;其中,改进的编解码注意力层由句子编解码注意力模块和原型编解码注意力模块构成;接收到i时刻多头自注意力层的输出s
self
和句子编码器的输出h
x
时,句子编解码注意力模块进行注意力计算。
[0028]
作为本发明的优选方案,所述step3中,句子编解码注意力模块进行注意力计算包括:
[0029]sx
=multiheadatt(s
self
,h
x
,h
x
)
[0030]
其中multiheadatt(
·
)为基于多头的注意力计算,与此类似,原型编解码注意力的计算为:
[0031]st
=multiheadatt(s
self
,h
t
,h
t
)
[0032]
随后,句子编解码注意力输出s
x
和原型编解码注意力输出s
t
被连接,用于计算比例变量α:
[0033]
α=sigmoid(w
α
[s
x
;s
t
]+b
α
)
[0034]
其中w
α
和b
α
为可训练参数,α随后被用于计算编解码注意力层的最终输出,计算公式为:
[0035]senc_dec
=α*s
x
+(1-α)*s
t
[0036]
进而s
enc_dec
作为输入被填充到全连接前馈网络中:
[0037]sffn
=f(s
enc_dec
)
[0038]
其中f(x)的定义为:f(x)=max(0,xw1+b1)w2+b2,其中w1,w2,b1和b2均为参数,最终i时刻的译文yi计算如下:
[0039]
p(yi|y
<i
;x;t,θ)=softmax(σ(s
ffn
))
[0040]
其中t为原型序列,σ(
·
)为线性变换函数。
[0041]
本发明的有益效果是:
[0042]
1、本发明通过联合使用原型序列检索方法和基于词替换的伪原型生成方法来获取原型序列,从而在保证序列质量的前提下,最大化提升低资源场景下可用的原型序列数量;
[0043]
2、本发明对编码器-解码器翻译框架进行了改进,编码端使用双编码结构,句子编码器和原型编码器分别对输入的句子和检索到(生成)的原型进行编码。解码端使用门控机制控制信息的比例和流动过程;
[0044]
3、改进神经机器翻译模型损失计算方法。使模型在尽力利用高质量原型序列所含语义信息的同时,削弱低质量原型序列对翻译模型的负面影响,最终提高低资源场景下的翻译性能,同时能带来更好的翻译流畅度。
附图说明
[0045]
图1为本发明中的流程图;
[0046]
图2为本发明提出的模型整体结构图;
[0047]
图3为本发明展示的关键词替换次数对模型性能的影响。
具体实施方式
[0048]
实施例1:如图1-图3所示,基于多策略原型生成的低资源神经机器翻译方法,所述方法的具体步骤如下:
[0049]
step1、语料预处理:预处理不同规模的平行训练语料、验证语料和测试语料,用于模型训练、参数调优和效果测试;并构建多语言全局替换词典和关键词词典,用于伪原型生成;
[0050]
step1.1、使用机器翻译领域的通用数据集iwslt15进行模型训练,翻译任务为英-越、英-中和英-德;验证和测试方面,选择tst2012作为验证集进行参数优化和模型选择,选择tst2013作为测试集进行测试评估;
[0051]
step1.2、使用panlex、维基百科、实验室自建的英汉-东南亚语词典以及谷歌翻译接口来构建英-越-中-德全局替换词典;
[0052]
step1.3、在step1.2的基础上,通过标记筛选方式得到关键词典,筛选过程中保留全部实体;为避免替换过于集中于某些热点名词,对名词性词汇于语料中检索并按出现频率进行倒排。
[0053]
处理后的平行语料按规模分为两类:小规模平行语料和大规模平行语料。在不同规模的平行语料上应用本发明的方法,可以观察语料规模的提升对信息利用率的影响,验证所提出的方法适用于平行语料资源稀缺场景的设想。表1为实验数据信息。
[0054]
表1实验数据
[0055][0056]
step2、原型生成:利用基于多种策略混合的原型生成方法进行原型生成,以保证原型序列的可用性;该步骤的具体思路为:首先结合使用模糊匹配和分布式表示匹配进行原型检索,如未检索到原型,则利用词替换操作对输入句子中的关键词进行替换,得到伪原型序列;
[0057]
step3、融入原型序列的翻译模型构建:改进传统基于注意力机制的神经机器翻译模型的编解码器结构,以更好的融入原型序列,使用步骤step1,step2的语料作为模型输入,产生最终译文。
[0058]
作为本发明的优选方案,所述step2的具体步骤为:
[0059]
step2.1、结合使用模糊匹配和分布式表示匹配进行原型检索;具体实现如下:翻译记忆库是由l对平行句组成的集合{(s
l
,t
l
):l=1,
…
,l},其中s
l
为源句,t
l
为目标句;对给定的输入句子x,首先使用关键词匹配于翻译记忆库中进行检索;低资源环境下,由于语料中的长句数量较少,易导致匹配到的片段长度较短,难以形成有效的相似度度量。因此本文未采用n-gram匹配,而是采用模糊匹配作为关键词匹配方法,其定义为:
[0060][0061]
其中ed(x,si)是x,si间的编辑距离,|x|为x的句长;
[0062]
与基于关键词的匹配方法不同,分布式表示匹配根据句子向量表征之间的距离进行检索,某种程度上是利用语义信息进行相似性检索的手段,也因此提供了与关键词匹配不同的检索视角;基于余弦相似度的分布式表示匹配定义为:
[0063][0064]
其中h
x
和分别为x和si的向量表征,||h
x
||为向量h
x
的度量;为实现快速计算,首先使用多语言预训练模型mbert得到句子x和si的向量表征,随后依据表征,使用faiss工具进行相似性匹配;
[0065]
当模糊匹配能够得到最优匹配源句s
best
时,利用分布式表示匹配得到top-k个匹配结果的集合s
′
={s1,s2,
…
,sk},如s
best
∈s
′
,则选取s
best
对应的目标端句子t
best
作为原型序列;当模糊匹配未能检索到匹配源句或时,则通过分布式表示匹配检索出最优匹配源句s
best
;
[0066]
step2.2、若step2.1未检索到原型,则对输入的句子进行关键词替换,生成伪原型,称之为基于词替换的伪原型生成;具体包含以下两种替换策略;
[0067]
全局替换:当输入句子未能检索到匹配时,基于最大化原则,利用双语词典对输入
句子中的词进行尽力替换,替换后的句子被称为伪原型序列;
[0068]
关键词替换:从双语词典中抽取重要名词和实体构建关键词词典;当输入句子未能检索到匹配时,利用该词典对输入句子中的关键词进行替换,生成伪原型序列,替换次数上限小于设定的阈值;期望在共享词表的基础上,该混合了源端和重要目标端词汇的伪原型序列能够为译文的生成提供指导。
[0069]
为了说明本发明的在低资源场景下的原型检索效果,在不同的数据规模上本发明提出的方法与基线原型检索效果进行对比。表2展示了混合式原型检索模型带来的匹配质量的提升。
[0070]
表2模糊匹配与混合式原型检索效果对比
[0071][0072]
由表2的结果可以看出,在低资源场景下,模糊匹配检索得到原型序列数量明显不足。使用结合了模糊匹配和分布式表示匹配的混合式原型匹配后,可在一定程度上缓解该问题。在大规模数据集wmt14上,相比单独使用模糊匹配策略,结合使用分布式表示匹配能够得到较为理想的匹配结果。而对于小规模数据集iwslt15而言,结合模糊匹配和分布式表示匹配后,能够在关键词匹配基础上附加语义层面的综合考量,进一步提升原型序列质量。从而证明本发明所提的混合式原型检索方法适用于低资源场景。
[0073]
图3展示了在越-英翻译任务上关键词替换次数对模型性能的影响。利用关键词替换进行伪原型生成过程中,我们首先依据经验设置替换阈值,随后基于验证集性能对阈值进行调整。评估结果表明,在顺序遍历词典策略下,当替换次数阈值设置较小时,生成的原型序列与原文区别有限,难以为翻译过程提供有效的指导信息;而当设置较大时,则趋向退化为全局替换;当关键词替换次数设置为3时模型表现最优.测试集上的结果显示了同样的变化趋势。
[0074]
作为本发明的优选方案,所述step3中包括:
[0075]
编码端采用双编码器结构,能够同时接收句子输入和原型序列输入,然后将输入编码为相应的隐状态表示;句子编码器为标准的transformer编码器,由多层堆叠而成;其中每层又由2个子层构成:多头自注意力层和前馈神经网络层,均使用残差连接和层正则化机制;给定输入句子x=(x1,x2,
…
,xm),句子编码器将其编码为相应的隐状态序列h
x
=(h
x1
,h
x2
,
…
,h
xm
),其中h
xi
为xi对应的隐状态,原型编码器在神经网络结构上与句子编码器一致,给定原型序列t=(t1,t2,
…
,tn),原型编码器将其编码为相应的隐状态序列h
t
=(h
t1
,h
t2
,
…
,h
tn
),其中h
ti
为ti对应的隐状态。
[0076]
作为本发明的优选方案,所述step3中包括:
[0077]
解码端融入门控机制,利用神经网络自学习能力实现句子信息和原型信息间的比例优化,控制解码过程中的信息流动;改进后的解码器由三个子层构成:(1)自注意力层;
(2)改进的编解码注意力层;(3)全连接前馈网络层;其中,改进的编解码注意力层由句子编解码注意力模块和原型编解码注意力模块构成;接收到i时刻多头自注意力层的输出s
self
和句子编码器的输出h
x
时,句子编解码注意力模块进行注意力计算。
[0078]
作为本发明的优选方案,所述step3中,句子编解码注意力模块进行注意力计算包括:
[0079]sx
=multiheadatt(s
self
,h
x
,h
x
)
[0080]
其中multiheadatt(
·
)为基于多头的注意力计算,与此类似,原型编解码注意力的计算为:
[0081]st
=multiheadatt(s
self
,h
t
,h
t
)
[0082]
随后,句子编解码注意力输出s
x
和原型编解码注意力输出s
t
被连接,用于计算比例变量α:
[0083]
α=sigmoid(w
α
[s
x
;s
t
]+b
α
)
[0084]
其中w
α
和b
α
为可训练参数,α随后被用于计算编解码注意力层的最终输出,计算公式为:
[0085]senc_dec
=α*s
x
+(1-α)*s
t
[0086]
进而s
enc_dec
作为输入被填充到全连接前馈网络中:
[0087]sffn
=f(s
enc_dec
)
[0088]
其中f(x)的定义为:f(x)=max(0,xw1+b1)w2+b2,其中w1,w2,b1和b2均为参数,最终i时刻的译文yi计算如下:
[0089]
p(yi|y
《i
;x;t,θ)=softmax(σ(s
ffn
))
[0090]
其中t为原型序列,σ(
·
)为线性变换函数。
[0091]
为了说明本发明的翻译效果,采用基线系统和本发明产生的译文进行对比,表3、表4为在小规模评语语料上的提升结果。
[0092]
表3 bleu值评测结果(%)
[0093][0094]
表4 ribes值评测结果(%)
[0095]
[0096]
从表3、表4的结果可以看出,本发明提出的方法能够在编码端使用额外的原型编码器学习原型序列表征,同时在解码端有效利用高质量原型序列所含语义信息、减少低质量原型序列引入的噪声信息。低资源场景下有效提升译文质量和流畅度。
[0097]
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1