道路检测方法、设备、装置及存储介质与流程
本技术涉及图像处理,尤其涉及一种道路检测方法、设备、装置及存储介质。
背景技术:
1、道路检测属于图像语义分割技术,图像语义分割(semantic segmentation)是计算机视觉中非常重要的任务,它的目标是为图像中的每个像素分类。图像的语义分割将一张图像分成几个不同的、有意义的部分,其分割的结果可以用作进一步的图像分析,例如场景理解、人机交互和视觉问答。在智能网联汽车驾驶系统中,图像的语义分割能检测道路及障碍物,理解交通状况,因此图像的语义分割任务在自动驾驶中扮演重要角色,并且高的图像语义分割精度能够促进自动驾驶汽车对场景的精确理解,进一步提高智能网联汽车驾驶系统的安全性。
2、随着深度学习技术的发展,基于深度学习的图像分割算法逐渐兴起,例如全卷积网络(fully convolutional network,fcn)以及对fcn进行优化改进的segnet神经网络等,但这些网络模型对图形分类识别的泛化能力不足,不能很好地适用图像像素点分类问题,导致某些图像分割精度下降。
技术实现思路
1、针对现有技术存在的问题,本技术实施例提供一种道路检测方法、设备、装置及存储介质。
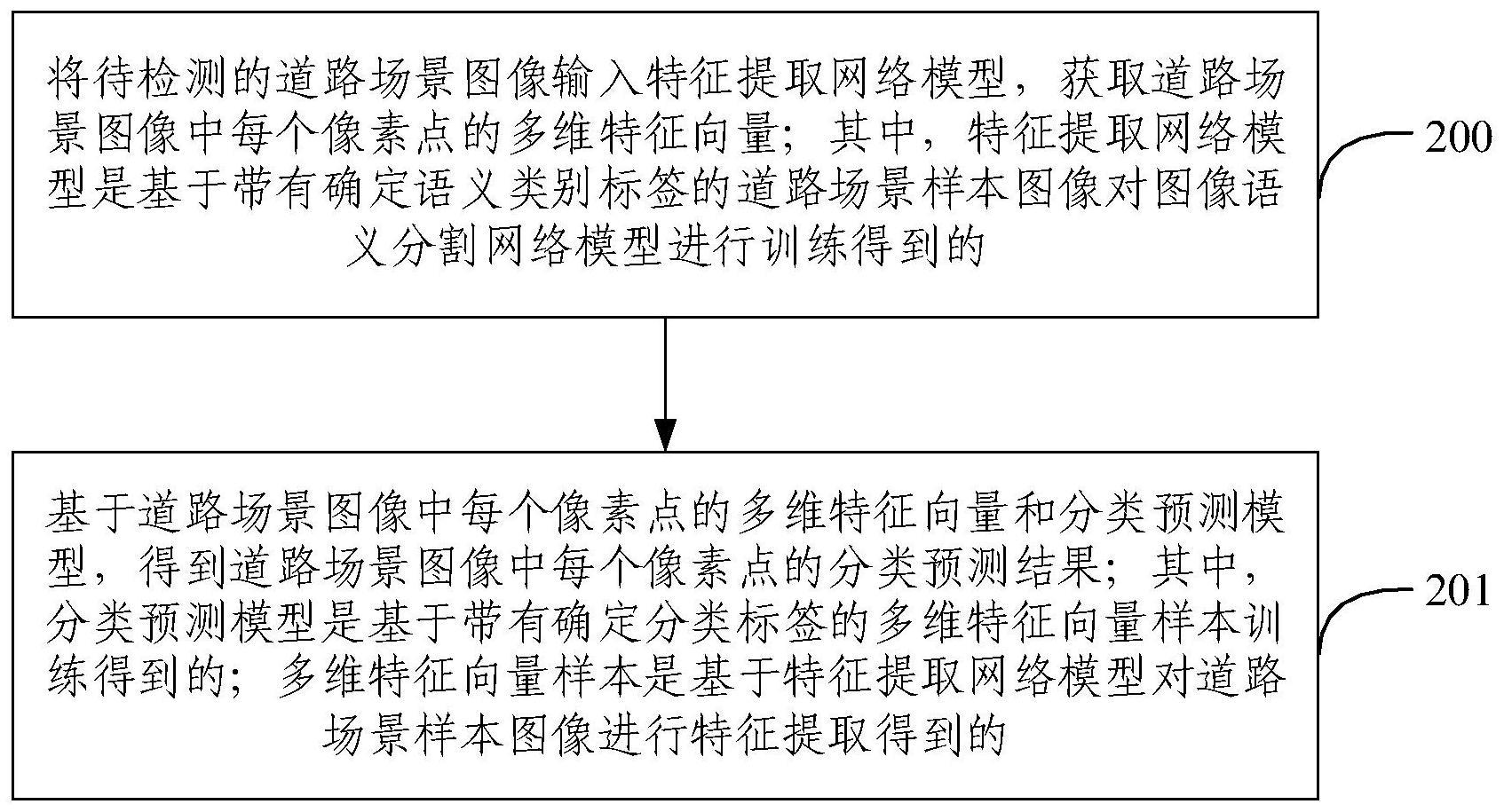
2、第一方面,本技术实施例提供一种道路检测方法,包括:
3、将待检测的道路场景图像输入特征提取网络模型,获取所述道路场景图像中每个像素点的多维特征向量;
4、基于所述道路场景图像中每个像素点的多维特征向量和分类预测模型,得到所述道路场景图像中每个像素点的分类预测结果;
5、其中,所述特征提取网络模型是基于带有确定语义类别标签的道路场景样本图像对图像语义分割网络模型进行训练得到的;所述分类预测模型是基于带有确定分类标签的多维特征向量样本训练得到的;所述多维特征向量样本是基于所述特征提取网络模型对所述道路场景样本图像进行特征提取得到的。
6、可选地,所述图像语义分割网络模型包括segnet模型,对所述图像语义分割网络模型进行训练得到所述特征提取网络模型,包括:
7、基于带有确定语义类别标签的道路场景样本图像对segnet模型进行训练;
8、将训练后的segnet模型最后的softmax输出层替换为线性输出层,得到所述特征提取网络模型;
9、其中,所述线性输出层用于基于输入的多通道特征图输出所述多通道特征图对应的每个像素点的多维特征向量。
10、可选地,所述基于输入的多通道特征图输出所述多通道特征图对应的每个像素点的多维特征向量,包括:
11、针对所述多通道特征图对应的各像素点,获取所述各像素点对应每个通道的特征值;
12、根据所述各像素点对应每个通道的特征值,确定所述各像素点的多维特征向量。
13、可选地,所述分类预测模型包括梯度提升决策树gbdt模型,所述基于所述道路场景图像中每个像素点的多维特征向量和分类预测模型,得到所述道路场景图像中每个像素点的分类预测结果,包括:
14、针对所述道路场景图像中的各像素点,基于所述各像素点的多维特征向量和gbdt模型,得到所述各像素点分别属于每个类别的预测值;
15、根据所述各像素点分别属于每个类别的预测值,确定所述各像素点分别属于每个类别的概率值;
16、根据所述各像素点分别属于每个类别的概率值,确定所述各像素点的分类预测结果。
17、可选地,所述多维特征向量的维度和所述分类预测模型对应的分类类别数相等。
18、可选地,所述多维特征向量的维度和所述分类预测模型对应的分类类别数均为12。
19、可选地,所述特征提取网络模型和所述分类预测模型所使用的训练样本集包括camvid数据集。
20、第二方面,本技术实施例还提供一种电子设备,包括存储器,收发机,处理器,其中:
21、存储器,用于存储计算机程序;收发机,用于在所述处理器的控制下收发数据;处理器,用于读取所述存储器中的计算机程序并执行以下操作:
22、将待检测的道路场景图像输入特征提取网络模型,获取所述道路场景图像中每个像素点的多维特征向量;
23、基于所述道路场景图像中每个像素点的多维特征向量和分类预测模型,得到所述道路场景图像中每个像素点的分类预测结果;
24、其中,所述特征提取网络模型是基于带有确定语义类别标签的道路场景样本图像对图像语义分割网络模型进行训练得到的;所述分类预测模型是基于带有确定分类标签的多维特征向量样本训练得到的;所述多维特征向量样本是基于所述特征提取网络模型对所述道路场景样本图像进行特征提取得到的。
25、可选地,所述图像语义分割网络模型包括segnet模型,对所述图像语义分割网络模型进行训练得到所述特征提取网络模型,包括:
26、基于带有确定语义类别标签的道路场景样本图像对segnet模型进行训练;
27、将训练后的segnet模型最后的softmax输出层替换为线性输出层,得到所述特征提取网络模型;
28、其中,所述线性输出层用于基于输入的多通道特征图输出所述多通道特征图对应的每个像素点的多维特征向量。
29、可选地,所述基于输入的多通道特征图输出所述多通道特征图对应的每个像素点的多维特征向量,包括:
30、针对所述多通道特征图对应的各像素点,获取所述各像素点对应每个通道的特征值;
31、根据所述各像素点对应每个通道的特征值,确定所述各像素点的多维特征向量。
32、可选地,所述分类预测模型包括梯度提升决策树gbdt模型,所述基于所述道路场景图像中每个像素点的多维特征向量和分类预测模型,得到所述道路场景图像中每个像素点的分类预测结果,包括:
33、针对所述道路场景图像中的各像素点,基于所述各像素点的多维特征向量和gbdt模型,得到所述各像素点分别属于每个类别的预测值;
34、根据所述各像素点分别属于每个类别的预测值,确定所述各像素点分别属于每个类别的概率值;
35、根据所述各像素点分别属于每个类别的概率值,确定所述各像素点的分类预测结果。
36、可选地,所述多维特征向量的维度和所述分类预测模型对应的分类类别数相等。
37、可选地,所述多维特征向量的维度和所述分类预测模型对应的分类类别数均为12。
38、可选地,所述特征提取网络模型和所述分类预测模型所使用的训练样本集包括camvid数据集。
39、第三方面,本技术实施例还提供一种道路检测装置,包括:
40、特征提取单元,用于将待检测的道路场景图像输入特征提取网络模型,获取所述道路场景图像中每个像素点的多维特征向量;
41、分类单元,用于基于所述道路场景图像中每个像素点的多维特征向量和分类预测模型,得到所述道路场景图像中每个像素点的分类预测结果;
42、其中,所述特征提取网络模型是基于带有确定语义类别标签的道路场景样本图像对图像语义分割网络模型进行训练得到的;所述分类预测模型是基于带有确定分类标签的多维特征向量样本训练得到的;所述多维特征向量样本是基于所述特征提取网络模型对所述道路场景样本图像进行特征提取得到的。
43、第四方面,本技术实施例还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序用于使计算机执行如上所述第一方面所述的道路检测方法的步骤。
44、第五方面,本技术实施例还提供一种通信设备,所述通信设备中存储有计算机程序,所述计算机程序用于使通信设备执行如上所述第一方面所述的道路检测方法的步骤。
45、第六方面,本技术实施例还提供一种处理器可读存储介质,所述处理器可读存储介质存储有计算机程序,所述计算机程序用于使处理器执行如上所述第一方面所述的道路检测方法的步骤。
46、第七方面,本技术实施例还提供一种芯片产品,所述芯片产品中存储有计算机程序,所述计算机程序用于使芯片产品执行如上所述第一方面所述的道路检测方法的步骤。
47、本技术实施例提供的道路检测方法、设备、装置及存储介质,通过对基于深度学习的图像语义分割模型进行优化改进,利用训练好的特征提取网络模型提取道路场景图像中每个像素点的特征向量,结合分类效果较好的分类预测模型对每个像素点进行分类预测,由于特征提取网络模型与分类预测模型的融合模型的学习泛化能力强,分类效果较好,实现了像素级别的图像分类,提升了图像语义分割的准确率,可以满足智能网联汽车在非限制场景下的应用需求。
- 还没有人留言评论。精彩留言会获得点赞!