一种基于全局上下文信息探索的RGB-D显著性目标检测方法
一种基于全局上下文信息探索的rgb-d显著性目标检测方法
技术领域:
1.本发明涉及计算机视觉和图像处理领域,提出了一种新的全局上下文探索网络(gcenet)用于rgb-d显著性目标检测(sod)任务,以细粒度的方式探索多尺度上下文特征的性能增益。
背景技术:
2.显著目标检测旨在从给定场景中分割出最具视觉吸引力的目标。作为一种预处理工具,sod已经广泛应用于计算机视觉任务,如图像检索,视觉跟踪等。大多数先前的sod方法集中于rgb图像,但是它们难以处理具有挑战性的场景,例如低对比度环境、相似的前景和背景以及复杂的背景。随着微软kinect、iphone xr、华为mate30等深度传感器设备的普及,rgb-d图像的采集是可行的,也是可以实现的。由于除了纹理、方向和亮度等2d特征之外,深度线索也影响视觉注意,因此rgb-d sod逐渐受到关注和研究。多尺度上下文特征的有效利用赋予了特征更丰富的全局上下文信息,有利于更好地理解整个场景,提高rgb-d sod网络的性能。
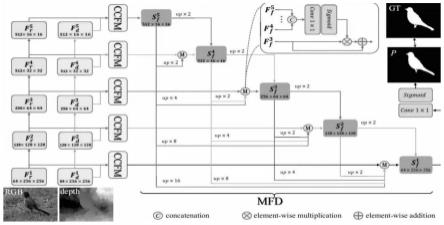
3.受多尺度特征优势的启发,许多rgb-d sod方法利用多尺度特征的优势来提高性能。然而,它们主要关注分层多尺度表示,不能在单个层中捕获细粒度的全局上下文线索。与这些方法不同的是,本发明提出了一个用于rgb-d sod的全局上下文探索网络(gcenet),以在细粒度级别上探索多尺度上下文特征的增益效应。具体而言,提出了一种跨模态上下文特征模块(ccfm),通过在单个特征尺度上的卷积算子栈从rgb图像和深度图中提取跨模态全局特征,然后在多路径融合(mpf)机制中融合多尺度多模态特征。然后,采用级联聚合的方式对这些融合特征进行融合。此外,需要考虑和整合来自主干的多个块的多尺度信息,以产生最终的显著结果。为此,本发明设计了一个多尺度特征解码器(mfd),以自顶向下的聚合方式融合来自多个块的多尺度特征。
技术实现要素:
:
4.针对以上提出的问题,提出了一种新的全局上下文探索网络(gcenet)用于rgb-d sod任务,并提出了多尺度特征解码器,具体采用的技术方案如下:
5.1.获取训练和测试该任务的rgb-d数据集
6.1.1)随机选取nlpr数据集的650个样本、nju2k数据集的1400个样本和dut数据集的800个样本作为训练集,将前三个数据集剩余样本及rgbd、stere、和rgbd数据集样本归类为测试集;
7.1.2)nju2k包含1985对rgb图像和深度图,其中深度图是从立体图像估计的。stere是第一个提出的数据集,总共包含1000对低质量的深度图。
8.2.基于连续卷积层堆叠用来构建跨模态上下文特征模块提取特征信息
9.2.1)提出了一种融合跨模态特征的多路径融合(mpf)策略,该策略采用多个元素级操作的协作集合,包括元素级加法、元素级乘法和级联。此外,为了减少跨通道整合过程
中的冗余信息和非显著特征,本发明利用空间通道注意机制,以过滤掉不需要的信息;
10.2.2)四个rgb特征和深度特征由一叠连续的卷积层提取,描述如下:
[0011][0012]
conv3表示具有3
×
3内核的卷积运算,α∈{r,d},和表示连续四个卷积层的输出。i∈{1,2,3,4,5},代表主干网的第i层;
[0013]
2.3)定义多尺度特征的多尺度特征解码器(mfd),mpf计算如下:
[0014][0015]
其中,o
ad
、o
ml
和o
ct
分别是元素加法、元素乘法和级联,分别是ccfm第一层的rgb和深度特征,i∈{1,2,3,4,5}表示逐层主干中的第i层;
[0016]
2.4)空间通道注意力的实现可以定义如下:
[0017][0018]
其中sa和ca分别表示空间注意和通道注意,是在mpf层呈现空间通道注意的增强特征;
[0019]
2.5)mpf的剩余层执行与第一层相似的步骤,可以获得另外三个融合特征和最后,采用高级全局信息引导机制来增强不同卷积层的输出的相关性,该机制可以表述如下:
[0020][0021]
表示分层主干第i层的特征;
[0022]
3.构建多尺度特征解码器
[0023]
3.1)自下而上的方式融合和定义如下:
[0024][0025][0026][0027]
其中,bn是批标准化层,conv1表示用于转换通道的卷积层,是mfd第k层的输出,w4是由生成的权重矩阵,sigmoid表示一种激活函数,up2表示两次上采集操作;
[0028]
3.2)下一步继续上面的步骤直至产生可以用下列公式表示:
[0029]
[0030]wt
=sigmoid(conv1(fu
t
))
ꢀꢀ
(9)
[0031][0032]
其中,t∈{1,2,3},表示2
5-t
倍的上采样,fu
t
表示的融合特征,比包含更多的全局信息,w
t
表示来自fu
t
的权重矩阵;
[0033]
4.计算损失函数,在训练阶段,本发明采用二元交叉熵(bce)来训练我们的网络,这是sod任务中的一个通用损失函数。它在不同的像素执行误差计算,定义为:
[0034][0035]
其中,p={p|0《p《1}∈r1×h×w和g={g|0《g《1}∈r1×h×w分别表示预测值和相应的真实值,h和w表示输入图像的高度和宽度,l
bce
每个像素预测值和实际值的误差。
[0036]
本发明与大多数方法采用的分层方式整合主干网络的多尺度特征不同,提出了一种细粒度的方法,在单个特征尺度而不是多个特征尺度上提取和集成多尺度特征,从而在单一层中捕获细粒度的全局上下文线索。首先,提出一种跨模态上下文特征模块(ccfm),通过在单个特征尺度上的卷积算子栈从rgb图像和深度图中提取跨模态全局特征,然后在多路径融合(mpf)机制中融合多尺度多模态特征;接着,采用级联聚合的方式对这些融合特征进行融合;随后,本发明设计了一个多尺度特征解码器(mfd),以自顶向下的聚合方式融合来自多个块的多尺度特征来考虑和整合来自主干的多个块的多尺度信息,以产生最终的显著结果。
附图说明
[0037]
图1为本发明的模型结构示意图
[0038]
图2为跨模态上下文特征模块示意图
[0039]
图3为多路径融合示意图
具体实施方式
[0040]
下面将结合本发明实例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,此外,所叙述的实施例仅仅是本发明一部分实施例,而不是所有的实施例。基于本发明中的实施例,本研究方向普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护范围。
[0041]
参考附图1,一种基于全局上下文信息探索的rgb-d显著性目标检测方法主要包含以下步骤:
[0042]
1.获取训练和测试该任务的rgb-d数据集,并定义本发明的算法目标,并确定用于训练和测试算法的训练集和测试集。随机选取nlpr数据集的650个样本、nju2k数据集的1400个样本和dut数据集的800个样本作为训练集,将前三个数据集剩余样本及rgbd、stere、和rgbd数据集样本归类为测试集;
[0043]
2.基于连续卷积层堆叠用来构建跨模态上下文特征模块提取特征信息
[0044]
2.1提出了一种融合跨模态特征的多路径融合(mpf)策略,该策略采用多个元素级
操作的协作集合,包括元素级加法、元素级乘法和级联。此外,为了减少跨通道整合过程中的冗余信息和非显著特征,本发明利用空间通道注意机制,以过滤掉不需要的信息;
[0045]
2.2四个rgb特征和深度特征由一叠连续的卷积层提取,描述如下:
[0046][0047]
conv3表示具有3
×
3内核的卷积运算,α∈{r,d},和表示连续四个卷积层的输出。i∈{1,2,3,4,5},代表主干网的第i层;
[0048]
2.3定义多尺度特征的多尺度特征解码器(mfd),mpf计算如下:
[0049][0050]
其中,o
ad
、o
ml
和o
ct
分别是元素加法、元素乘法和级联,分别是ccfm第一层的rgb和深度特征,i∈{1,2,3,4,5}表示逐层主干中的第i层;
[0051]
2.4空间通道注意力的实现可以定义如下:
[0052][0053]
其中sa和ca分别表示空间注意和通道注意,是在mpf层呈现空间通道注意的增强特征;
[0054]
2.5mpf的剩余层执行与第一层相似的步骤,可以获得另外三个融合特征和最后,采用高级全局信息引导机制来增强不同卷积层的输出的相关性,该机制可以表述如下:
[0055][0056]
表示分层主干第i层的特征;
[0057]
3.构建多尺度特征解码器
[0058]
3.1自下而上的方式融合和定义如下:
[0059][0060][0061][0062]
其中,bn是批标准化层,conv1表示用于转换通道的卷积层,是mfd第k层的输出,w4是由生成的权重矩阵,sigmoid表示一种激活函数,up2表示两次上采集操作;
[0063]
3.2下一步继续上面的步骤直至产生可以用下列公式表示:
[0064][0065]wt
=sigmoid(conv1(fu
t
))
ꢀꢀ
(9)
[0066][0067]
其中,t∈{1,2,3},表示2
5-t
倍的上采样,fu
t
表示的融合特征,比包含更多的全局信息,w
t
表示来自fu
t
的权重矩阵;
[0068]
4.计算损失函数,在训练阶段,本发明采用二元交叉熵(bce)来训练我们的网络,这是sod任务中的一个通用损失函数。它在不同的像素执行误差计算,定义为:
[0069][0070]
其中,p={p|0《p《1}∈r1×h×w和g={g|0《g《1}∈r1×h×w分别表示预测值和相应的真实值,h和w表示输入图像的高度和宽度,l
bce
每个像素预测值和实际值的误差。
[0071]
以上所述为本技术优选实施而以,并不用于限制本技术,对于本领域的技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包括在本技术的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1