一种基于深度神经网络的图像分类方法
1.本发明属于人工智能深度学习和计算机视觉领域,特别是涉及一种基于深度神经网络的图像分类方法。
背景技术:
2.图像分类应用极为广泛,是计算机视觉要解决的最基本问题,并且目标检测、语义分割、实例分割等其他问题的解决也都依赖于图像分类。深度神经网络技术首先在图像分类上获得突破,之后获得了巨大进展,网络结构从alexnet到vgg、resnet再到最新的se-net、nasnet,分类方法有二分类、多分类(multi-classes)、多标签分类(multi-labels)等不同的分类方式,并且整合了图像预处理、数据增强、多模型集成、同一张图像经过不同的处理(例如随机裁剪)多次输入神经网络然后对预测结果进行集成等技术,分类准确率越来越高。基于神经网络进行图像分类方法不仅在imagenet等竞赛中的准确率已经超过了人类,在大多数现实应用场景下也取得了非常好的效果。
3.当前图像分类针对同一个分类问题都是采用同样输入分辨率的深度神经网络模型,虽然在绝大多数场景下这样做毫无问题,在某些场景下效果会非常差,这些场景指的是不同类别中有些类别是根据图像的整体特征,有些类别只和图像的微小细节有关,而有些类别只和图像的很小的一个局部有关。
4.类似于特征金字塔fpn(feature pyramid networks)的方法在一个深度神经网络内能够融合不同层次的特征,这些特征既包括低层特征:位置准确但是整体特征语义信息很少,以及高层特征:语义信息比较丰富,但是目标位置比较粗略。特征金字塔的方法在目标检测等取得了很好的效果,但是不能解决上述复杂的分类场景下,不同的类别之间特征层次差别巨大的问题。因此,只使用同样输入分辨率的深度神经网络模型无法兼顾辨识图像的整体特征、局部特征和细节特征。特征金字塔等融合多尺度特征的网络结构,不能解决复杂的分类场景下,不同的类别之间特征层次差别巨大的问题。
5.以视网膜眼底图像的分类为例,也就是输入眼底图像,输出该图像是正常或者某种病变。这些类别中有些类别是和图像的整体特征有关,例如豹纹、视网膜色素变性等。而有些类别需要辨识图像的微小细节,例如糖尿病视网膜病变(diabetic retinopathy 简称dr)的dr1(dr国际标准分为五级dr1-dr5),其特征是存在微血管瘤,微血管瘤在图像上表现为小红点,即使在原始图像上也只有若干个像素大小。而有些类别只和原图像中的一个很小区域有关,例如青光眼和视神经萎缩只和视盘内部以及视盘周边区域有关,黄斑水肿只和黄斑区域有关等。
6.针对以上问题,如果使用同样分辨率的深度神经网络区分所有类别的话,模型的分辨率必须非常大(例如512*512),这样才可能辨识微血管瘤等细节,才可能比较好的区分类别dr1。一方面使用大模型对于诊断dr1是必须的,但是另一方面对于其他类别来说使用大模型反而带来坏处:包括更多的模型参数,更长的训练和预测时间,特别是因为大模型更容易产生过拟合,造成分类准确率反而降低。
7.从理论上,根据原始图像使用普通的深度神经网络模型来区分只和图像某一个小局部相关的类别(例如青光眼和视神经萎缩)是完全可行的,但是在实际中往往行不通。原因在于深度神经网络是根据训练样本去学习自动提取特征,由于真正的特征集中在原图的一个很小区域内,原图中的其他区域具有大量的无关特征,因此必须有大量的训练样本才可能教会深度神经网络提取到正确的特征,而现实中往往很难获得所需要的大量训练样本,例如在医疗影像领域,获得标注好的医疗影像成本很高,对于许多病种(例如罕见病)甚至是不可能的。
技术实现要素:
8.为解决上述问题,本发明提供了如下方案:一种基于深度神经网络的图像分类方法,包括:建立图像分类的二级分类体系,将眼底图像输入所述二级分类体系进行图像分类获得分类结果;根据所述分类结果判断图像是否正常。
9.优选地,建立所述二级分类体系包括,将需要辨识图像微小细节的类别划分为第一大类,基于所述第一大类再区分子类;将只和图像某一个局部相关的类别划分为第二大类,基于所述第二大类再区分子类;将其他病种或者特征类型放到其他大类中。
10.优选地,将眼底图像输入所述二级分类体系之前还包括,构建深度神经网络模型;所述深度神经网络模型包括普通分辨率模型、大分辨率模型、小分辨率模型;其中,所述大分辨率模型的输入大于普通分辨率模型的1.4倍,所述小分辨率模型的输入小于普通分辨率模型的0.7倍。
11.优选地,将所述眼底图像输入所述二级分类体系进行图像分类包括,通过所述普通分辨率模型分大类;针对第一大类再通过所述大分辨率模型分子类,针对第二大类首先进行定位、裁剪小局部区域然后用所述小分辨率模型去划分子类。
12.优选地,获得所述分类结果包括获得第一分类结果;获得所述第一分类结果包括,通过所述普通分辨率模型将所述眼底图像根据辨识图像情况划分为第一大类、第二大类、其他大类;所述第一大类为需要辨识所述图像的微小细节;所述第二大类为需要辨识所述图像和原图像的局部区域有关。
13.优选地,获得所述分类结果包括获得第二分类结果;获得所述第二分类结果包括,针对第一大类的分类结果,通过大分辨率模型划分所述第一大类的下属子类;针对第二大类的分类结果,将所述眼底图像中定位、裁剪出分类的相关区域,通过小分辨率模型划分所述第二大类的下属子类。
14.本发明公开了以下技术效果:本发明提供的一种基于深度神经网络的图像分类方法,通过构建用于图像分类的设置分类层次结构关系的初始神经网络模型,对采集视网膜的眼底图像进行图像分类;根据分类结果判断图像是正常或者某种病变。该方法针对有些类别是根据图像的整体特征,有些类别只和图像的微小细节有关,有些类别只和图像的某个很小的局部有关这样的场景,相比传统方法能够明显提高分类准确率。
附图说明
15.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
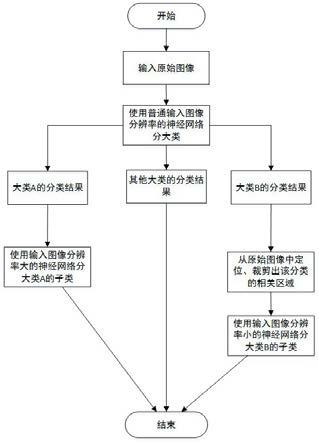
16.图1为本发明实施例的方法流程图;图2为本发明实施例的自定义大模型resnet的网络结构图;图3为本发明实施例的自定义小模型resnet的网络结构图。
具体实施方式
17.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
18.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
19.如图1所示,本发明提供了一种基于深度神经网络的图像分类方法,包括:建立图像分类的二级分类体系,将眼底图像输入所述二级分类体系进行图像分类获得分类结果;根据所述分类结果判断图像是否正常。
20.建立所述二级分类体系包括,将需要辨识图像微小细节的类别划分为第一大类,基于所述第一大类再区分子类;将只和图像某一个局部相关的类别划分为第二大类,基于所述第二大类再区分子类;将其他病种或者特征类型放到其他大类中。
21.将眼底图像输入所述二级分类体系之前还包括,构建深度神经网络模型;所述深度神经网络模型包括普通分辨率模型、大分辨率模型、小分辨率模型;其中,所述大分辨率模型的输入大于普通分辨率模型的1.4倍,所述小分辨率模型的输入小于普通分辨率模型的0.7倍。
22.将所述眼底图像输入所述二级分类体系进行图像分类包括,通过所述普通分辨率模型分大类;针对第一大类再通过所述大分辨率模型分子类,针对第二大类首先进行定位、裁剪小局部区域然后用所述小分辨率模型去划分子类。
23.获得所述分类结果包括获得第一分类结果;获得所述第一分类结果包括,通过所述普通分辨率模型将所述眼底图像根据辨识图像情况划分为第一大类、第二大类、其他大类;所述第一大类为需要辨识所述图像的微小细节;所述第二大类为需要辨识所述图像和原图像的局部区域有关。
24.获得所述分类结果包括获得第二分类结果;获得所述第二分类结果包括,针对第一大类的分类结果,通过大分辨率模型划分所述第一大类的下属子类;针对第二大类的分类结果,将所述眼底图像中定位、裁剪出分类的相关区域,通过小分辨率模型划分所述第二大类的下属子类。
25.实施例一
如图1-3所示,本发明提供了一种基于深度神经网络的图像分类方法,包括以下步骤:首先建立一个分类层次关系,将需要辨识图像微小细节的类别放到同一大类中,将只和图像某一个局部相关的类别放到同一个大类中。使用普通分辨率模型分大类,然后再分子类。用大分辨率的深度神经网络模型去分需要辨识图像微小细节的大类下属的子类,而对每一个只和图像某一个小局部相关的大类下属的子类,先对原图像进行目标区域定位和裁剪,然后对裁剪后的图像使用小分辨率的深度神经网络模型进行分类。其中,大模型的输入大于普通模型分辨率的1.4倍,小模型的输入小于普通模型分辨率的0.7倍。
26.进一步地,针对本发明技术方案的详细阐述如图1所示,本发明提出的基于深度神经网络的图像分类方法,其中大类a和大类b都包含若干子类,区分大类a的子类需要辨识图像的微小细节,而区分大类b的子类只和原图像的一个很小局部区域有关。
27.以视网膜眼底图像的分类为例,也就是输入眼底图像,输出该图像是正常或者某种病变。关键是这些类别中有些类别是和图像的整体特征有关,例如豹纹、视网膜色素变性等。有些类别需要辨识图像的微小细节,例如糖尿病视网膜病变的dr1,其特征是存在微血管瘤,微血管瘤在图像上表现为小红点,即使在原始图像上也只有若干个像素大小。有些类别只和原图像中的一个很小区域有关,例如青光眼和视神经萎缩只和视盘内部以及视盘周边区域有关,黄斑水肿只和黄斑区域有关等。
28.不同于传统的使用同样分辨率的深度神经网络采用多次二分类、多分类(multi-classes)、或者多标签分类(multi-labels)的方式,我们首先定义分类的层次结构:将眼底图像分为29个大类,部分大类中包含若干个子类。29个大类包括大类0(包括正常和dr1)、大类1(包括青光眼和视神经萎缩)、brvo(视网膜分值静脉阻塞)、crvo(视网膜中央静脉阻塞)、rp(视网膜色素变性)、referable dr(需要治疗的糖尿病视网膜病变)、rd(视网膜脱落)、silicon oil in eye(硅油眼)等(为了方便描述,这里忽略了其他大类,这些大类中部分也包含子类)。设计类层次结构的核心思想是:将需要辨识图像微小细节的类别放到同一大类中,然后在该大类中再区分子类,以及将只和图像某一个局部相关的类别放到一个大类中,然后在该大类中再区分子类。
29.定义好分类的层次关系之后,在分类的时候首先使用普通分辨率模型分大类,然后对于某些大类再去分子类,用大分辨率模型去区分需要辨识图像微小细节的大类所属的子类,对每一个只和原图的某一个小局部区域相关的大类,先对原图像进行目标区域定位和裁剪,然后对裁剪后的图像使用小分辨率的深度神经网络模型进行分类。
30.由于区分大类不需要辨识图像的微小细节,可以采用通用模型分大类,例如输入图像分辨率299*299的inception-v3、inceptionresnet-v2,224*224的vggnet、resnet(残差网络)等。本实施例通过使用tensorflow+keras框架进行开发,keras内置支持了绝大部分的常用模型,例如上述提到的所有模型。采取多次独立训练多个不同类型的模型,然后通过合并多个模型的预测结果(ensemble learning)以提高准确率,简化后的实现代码如下:num_big_classes=29 #定义大类的数目是29model1 = keras.applications.inceptionresnetv2(include_top=true, weights=none, classes=num_big_classes) #使用keras内置的模型inceptionresnetv2
定义深度神经网络模型模型训练好之后,使用它来进行分类,输出结果是29个大类类别的概率:probabilities=model1.predict(x)选取概率值最大的类别为预测的类别:y_pred1 = probabilities.argmax(axis=-1)如果某张图像分大类的结果是属于大类0,接下来需要将其分为子类,也就是正常或者糖尿病视网膜病变dr1。由于dr1的特征是微血管瘤,微血管瘤在图像上表现为小红点,即使在原始图像上也只有若干个像素大小,也就是说图像几个像素大小的细节可能决定整张图像的所属类别,因此必须用大分辨率的深度神经网络模型才能够辨识。
31.标准的resnet的输入大小是224*224,由于该模型采用全局平均池化层(global average pooling layer)而不是全连接层(fully connected layer),也可以接受其他大小的输入,但是不宜和224相差太大。标准的resnet包含4个卷积块(conv blocks),每一个卷积块由若干个残差块(residual blocks)构成。
32.本发明对其做了以下改进:输入图像采用448*448,比原来大了一倍,相应增加一个卷积块,并且将第一个卷积层的卷积核从7*7变为5*5,卷积核数目从64减少到32(因为从特征提取角度32足够了,从64减小到32可以大幅减少内存消耗,提高训练和预测速度),除此之外该模型按照resnet v2的结构,包括pre activation(非线性激活层位于卷积层之前)和bottleneck(每一个residual块包括1*1,3*3,1*1三个卷积层)的结构,该模型的结构如图2所示。使用汕头大学-香港中文大学联合汕头国际眼科中心(汕头大学医学院第五附属医院)提供的眼底图像,对于大类0分子类,采用自定义的大模型比采用普通模型分类准确率提高了8.5%,敏感度和特异度提高都很明显,采用自定义模型的混淆矩阵如下所示。
33.训练集:验证集:
由于dr1很难检测,这个准确率已经很好了,接近了专科医生的水平。
34.如果某张图像分大类的结果是属于大类1的话,需要对其进行进一步分类以区分青光眼和视神经萎缩。区分这两者只和视盘内部以及视盘周边区域有关,而视盘只占据了整张眼底图像的很小一部分。本实施例的做法是首先定位裁剪出视盘区域,然后使用小分辨率的深度神经网络对裁剪后的图像进行分类。视盘定位的方法很多,既有传统的图像处理方法更有深度神经网络方法。传统的图像处理方法包括根据图像直方图、模版、结合血管走向等方法。通过深度神经网络定位视盘也包括不同的方法:定位、目标检测、语义分割、实例分割。定位方法使用回归实现,由于每张眼底图像最多只有一个视盘,修改深度神经网络的输出层,输出视盘区域左上、右下的坐标。目标检测有单步法和两步法两种,单步包括yolo(只看一次)、yolov2、yolov3、ssd(single shot multibox detector单步多框检测器)以及最新的retinanet(视网膜网络)等,两步法包括faster r-cnn(快速区域卷积网络)、fcn(全卷积网络)等。语义分割有fcn、u-net(u形状网络)等,实例分割有mask r-cnn(生成掩码的区域卷积网络)等。
35.本实施例定位切割视盘区域尝试了多种不同方法,最开始使用matlab根据图像的直方图定位视盘,后来使用retinanet目标检测模型,最后决定使用实例分割模型mask r-cnn。原因是使用深度神经网络比传统图像方法准确率高,mask r-cnn的输出包括三个部分:置信度、目标的bbox坐标、二进制的mask掩码。置信度能够判断是否准确检测到了视盘(图像直方图以及使用深度神经网络定位的方法没有置信度),使用视盘分割的掩码图像(目标检测retinanet没有输出掩码)以后可以用来分割视盘内的视杯,计算杯盘比等。
36.假设results是mask r-cnn的输出,根据bbox坐标裁剪视盘区域的代码如下,使用python+opencv:y1,x1,y2,x2=results[0]['rois'][0] #获取bbox的坐标center_x = (x2 + x1) // 2 #获取视盘中心点的坐标center_y = (y2 + y1) // 2r = max((x2-x1)//2, (y2-y1)//2)r = r + 40# 正方形left = int(max(0, center_x
ꢀ‑ꢀ
r))right = int(min(image_preprocess.shape[1], center_x + r))bottom = int(max(0, center_y
ꢀ‑ꢀ
r))top = int(min(image_preprocess.shape[1], center_y + r))
image_crop = image [bottom:top, left:right]image_crop = cv2.resize(image_crop, (112, 112))该算法输出图像大小是112*112,包括视盘内和视盘周边区域,虽然裁剪后的图像小了一倍,但其实图像的分辨率比基于原图使用普通模型输入模型反而更高了,然后将该输出图像输入到定制的小分辨率深度神经网络中进行进一步区分青光眼和视神经萎缩子类。
[0037]
标准的resnet的输入大小是224*224,包含4个卷积块,由于裁剪视盘后输入图像采用112*112,只有原来的一半,因此需要自定义设计模型,自定义设计的模型删除了一个卷积块,该模型如图3所示。
[0038]
使用汕头大学-香港中文大学联合汕头国际眼科中心提供的眼底图像,如果使用普通模型分大类1的子类,虽然训练准确率很高,但是验证准确率和瞎猜差不多,此外根据模型输出的热力图(class activation maps)判断深度神经网络并未正确的提取到特征,大部分提取的特征都在无关区域。而当裁剪后使用自定义的小模型进行分类,效果却非常好,混淆矩阵如下所示:训练集:验证集:对部分图像自定义模型输出的热力图(class activation maps)进行分析,这些热力图清晰显示红色区域(值比较高)就是真正病变的关键区域。根据混淆矩阵和热力图的综合分析,本分类方法相对于传统方法有非常明显的提升。
[0039]
以上所述的实施例仅是对本发明的优选方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1