一种基于双解耦生成和半监督学习的活体检测方法及系统
1.本发明涉及人脸识别防欺骗检测技术领域,具体涉及一种基于双解耦生成和半监督学习的活体检测方法及系统。
背景技术:
2.如今,在企业和行业的使用面部生物识别技术的场景急剧增加,例如,可以使用面部解锁技术来保护电子设备中的个人隐私,可以使用面部生物识别技术对付款进行身份验证。但是,将面部用作身份验证的生物特征是不安全的。面部生物识别系统可能容易受到欺骗攻击。人脸欺骗攻击方式一般来说可分为四类:1)照片攻击:攻击者利用打印或者显示屏的照片来欺骗认证系统;2)视频重放攻击:攻击者利用提前拍摄的被攻击者的视频欺骗认证系统;3)人脸面具攻击,攻击者戴着根据被攻击者精心制作的人脸面具欺骗系统;4)对抗样本攻击,攻击者通过gan网络生成特定的样本噪声去干扰人脸认证系统产生错误的定向身份验证。这些人脸欺骗攻击不仅成本低廉而且能欺骗系统,严重影响和威胁着人脸识别系统的应用。
3.活体检测在防止人脸识别系统遭受假体攻击方面起着至关重要的作用,得益于深度学习网络强大的特征提取能力,基于深度学习的活体检测算法取得比基于传统手工特征算法更好的性能,尽管大多数基于深度学习的活体检测算法能在库内达到很好的检测效果,但是跨库检测性能欠佳,主要原因是库内和库外数据往往在不同条件下采集,例如拍摄设备、环境光照和攻击呈现设备不同等,导致库内和库外数据的分布不同,两者之间存在域位移。当训练数据的多样性不足时,容易在库内学习过程中过拟合,跨库泛化性能不好。尽管可以判断起因,然而在真实世界的应用过程中解决上述问题并不容易,活体检测模型难以收集所有场景下的有标签训练样本,导致目前大多数现有的反欺骗数据集多样性不足。例如,常用的casia、replay-attack、msu拍摄设备分别只有3、2、2种,拍摄背景分别只有3、2、1种。
技术实现要素:
4.为了克服现有技术存在的缺陷与不足,本发明提供一种基于双解耦生成和半监督学习的活体检测方法,通过解耦学习建模活体/假体特征,在潜在空间合成生成样本来扩充数据集,提升训练数据的多样性,同时,保证生成的样本的高区分度,减少生成噪声对模型学习的影响,具体采用了基于双解耦生成和半监督学习的技术方案,解决了活体检测模型数据多样性不足及泛化性差的技术问题,达到了保证库内准确率的同时,有效地提升泛化性能的技术效果。
5.为了达到上述目的,本发明采用以下技术方案:
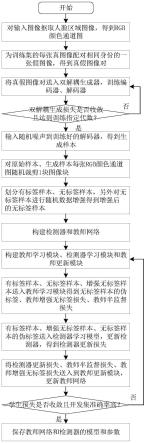
6.本发明提供一种基于双解耦生成和半监督学习的活体检测方法,包括下述步骤:
7.对输入图像抠取人脸区域图像,得到rgb颜色通道图;
8.对待训练的rgb颜色通道图原始样本的每张真图像配对相同身份的一张假图像,
构成真假图像对,并为假图像标注攻击类别标签;
9.构建真人编码器、假体编码器、解码器;
10.将真图像送入真人编码器得到真人身份向量,将配对的假图像送入假体编码器得到假体身份向量和假体模式向量,将真人身份向量、假体身份向量和假体模式向量合并送入解码器输出重建的真假图像对,构建双解耦生成损失函数进行优化;
11.从标准正态分布采样噪声输入到训练好的解码器得到生成样本;
12.裁剪原始样本和生成样本构成的训练集,构建有标签样本、无标签样本、增强后的无标签样本;
13.构建检测器和教师网络;
14.构建教师学习模块,将所述有标签样本、无标签样本和增强后的无标签样本送入教师学习模块,得到教师半监督损失、无标签数据的伪标签、教师增强无标签损失;
15.构建检测器学习模块,将有标签样本、增强后的无标签样本、无标签样本的伪标签送入检测器学习模块更新检测器参数,得到检测器更新损失;
16.利用教师半监督损失、教师增强无标签损失、检测器更新损失,更新教师网络参数;
17.根据损失函数用优化器迭代更新检测器和教师网络的参数,完成训练后保存教师网络和检测器的参数;
18.将验证集人脸rgb颜色通道图送入训练好的检测器,得到分类分数,根据不同的判决阈值得到预测的标签值,与真实标签比较,计算虚警率和漏检率,取两者相等时的阈值作为测试判决阈值;
19.将测试集人脸rgb颜色通道图送入训练好的检测器,得到分类分数,根据测试判决阈值得到最终预测的标签值,计算基准指标。
20.作为优选的技术方案,所述构建真人编码器、假体编码器、解码器,具体步骤包括:
21.真人编码器和假体编码器各自的主干网采用相同的网络结构,设有卷积层、实例归一化层和leakyrelu,以及五组由池化层、卷积层堆叠及跳级连接的残差块构成的单元;
22.真人编码器经过全连接层输出隐藏层真人向量,假体编码器经过全连接层输出隐藏层假体向量;
23.解码器主干网采用卷积层、上采样层、sigmoid激活层、残差块搭建,真人编码器和假体编码器输出的隐藏层真人向量和隐藏层假体向量首先输入全连接层,经过六组由卷积层堆叠及跳级连接的残差块、上采样层构成的单元,最后经过卷积层输出图像对。
24.作为优选的技术方案,所述将真图像送入真人编码器得到真人身份向量,将配对的假图像送入假体编码器得到假体身份向量和假体模式向量,具体步骤包括:
25.真人解码器输出真人隐藏向量,包括真人身份向量均值和真人身份向量方差
26.假体编码器输出假体隐藏向量,包括假体身份向量均值假体身份向量方差假体模式向量均值假体模式向量方差
27.从标准正态分布中采样真人身份变分量假体身份变分量和假体模式变分量
28.进行重参数操作,分别得到真人身份向量假体身份向量和假体模式向量具体表示为:
[0029][0030]
将真人身份向量假体身份向量和假体模式向量合并成隐藏向量,输入到解码器,输出重建真假图像对,包括重建真人图像和重建假体图像
[0031]
作为优选的技术方案,所述将真人身份向量、假体身份向量和假体模式向量合并送入解码器输出重建的真假图像对,构建双解耦生成损失函数进行优化,具体步骤包括:
[0032]
将假体模式向量送入全连接层fc(
·
),输出假体类别向量并与真实的假体类别标签ys计算交叉熵得到分类损失表示为:
[0033][0034]
其中,k为假体类别数,ys为经过独热编码的假体类别标签向量;
[0035]
在假体身份向量和假体模式向量加入角正交约束得到正交损失表示为:
[0036][0037]
其中,《
·
,
·
》表示内积;
[0038]
对重建真人图像重建假体图像与对应的原图计算重建损失表示为:
[0039][0040]
对真人身份向量假体身份向量计算最大平均差别损失表示为:
[0041][0042]
对重建真人图像和重建假体图像计算配对损失表示为:
[0043][0044]
通过计算kl散度进行约束,如下式所示:
[0045][0046]
其中,n为隐藏向量的维数;
[0047]
将各损失加权求和得到双解耦生成器损失函数表示为:
[0048][0049]
其中,λ1、λ2、λ3、λ4表示对应的权重值;
[0050]
采用adam优化器,以最小化双解耦生成器损失函数为目标优化真人编码器、假体编码器及解码器。
[0051]
作为优选的技术方案,所述从标准正态分布采样噪声输入到训练好的解码器得到生成样本,具体步骤包括:
[0052]
设隐藏向量维数为n,从标准正态分布采样维数为n的随机噪声两次,分别得到重建假体身份隐藏向量和重建假体模式隐藏向量
[0053]
重建真人身份隐藏向量直接由重建假体身份隐藏向量复制,然后经过解码器生成真假图像对,作为生成样本。
[0054]
作为优选的技术方案,所述检测器和教师网络,所述教师网络和检测器具有相同的网络结构,设有卷积层、批归一化层、relu、三组由卷积层堆叠及跳级连接的残差块构成的单元、全局平均池化层和全连接层,全连接层输出分类向量。
[0055]
作为优选的技术方案,将所述有标签样本、无标签样本和增强后的无标签样本送入教师学习模块,得到教师半监督损失、无标签数据的伪标签、教师增强无标签损失,具体步骤包括:
[0056]
有标签样本{x
l
,y
l
}输入参数为θ
t
的教师网络t输出教师有标签预测结果t(x
l
;θ
t
),与真实标签y
l
计算交叉熵得到教师有标签损失具体表示为:
[0057][0058]
其中,ce表示交叉熵损失;
[0059]
无标签样本xu及增强后的无标签样本分别输入教师网络t后得到教师无标签预测结果t(xu;θ
t
)和教师增强无标签预测结果将两者计算交叉熵损失,得到教师无标签损失具体表示为:
[0060][0061]
从教师无标签预测结果t(xu;θ
t
)取出其最大值所属类别作为伪标签具体表示为:
[0062][0063]
将教师有标签损失和教师无标签损失加权求和得到教师半监督
损失表示为:
[0064][0065]
其中,s为当前步数,s
tl
为总步数,λ为无标签损失的权重;
[0066]
对教师增强无标签预测结果与其自身取出的最大值所属类别h,经过交叉熵函数,得到增强无标签损失表示为:
[0067][0068][0069]
作为优选的技术方案,所述将有标签样本、增强后的无标签样本、无标签样本的伪标签送入检测器学习模块更新检测器参数,得到检测器更新损失,具体步骤包括:
[0070]
将增强后的无标签样本送入参数为θd的检测器d得到检测器增强无标签预测结果与伪标签计算交叉熵,得到检测器增强无标签损失具体表示为:
[0071][0072]
检测器无标签损失用梯度下降法优化检测器,得到优化后参数为θ
′d的检测器,具体表示为:
[0073][0074]
其中,ηd表示检测器学习率,表示梯度计算;
[0075]
有标签样本(x
l
,y
l
)分别送入优化前参数为θd的检测器和优化后参数为θ
′d的检测器,得到旧的检测器有标签损失和新的检测器有标签损失然后两者作差,得到检测器更新损失具体表示为:
[0076][0077][0078][0079]
作为优选的技术方案,所述利用教师半监督损失、教师增强无标签损失、检测器更新损失,更新教师网络参数,具体步骤包括:
[0080]
将检测器更新损失与教师增强无标签损失相乘,再与教师半监督损失相加,构成教师损失用梯度下降法优化教师网络,表示为:
[0081][0082][0083]
其中,θ
t
表示教师网络优化前参数,θ
′
t
表示教师网络优化后参数,η
t
表示教师网络
学习率,表示梯度计算。
[0084]
本发明还提供一种基于双解耦生成和半监督学习的活体检测系统,包括:数据预处理模块、双解耦生成器构建模块、双解耦生成器训练模块、生成样本构建模块、无监督数据增强模块、检测器构建模块、教师网络构建模块、教师学习模块、检测器学习模块、网络参数更新模块、验证模块和测试模块;
[0085]
所述数据预处理模块用于对输入图像抠取人脸区域图像,得到rgb颜色通道图,对待训练的rgb颜色通道图原始样本的每张真图像配对相同身份的一张假图像,构成真假图像对,并为假图像标注攻击类别标签;
[0086]
所述双解耦生成器构建模块用于构建真人编码器、假体编码器、解码器,组成双解耦生成器;
[0087]
所述双解耦生成器训练模块用于将真图像送入真人编码器得到真人身份向量,将配对的假图像送入假体编码器得到假体身份向量和假体模式向量,将真人身份向量、假体身份向量和假体模式向量合并送入解码器输出重建的真假图像对,构建双解耦生成损失函数进行优化;
[0088]
所述生成样本构建模块用于从标准正态分布采样噪声输入到训练好的解码器得到生成样本;
[0089]
所述无监督数据增强模块用于裁剪原始样本和生成样本构成的训练集,构建有标签样本、无标签样本、增强后的无标签样本;
[0090]
所述检测器构建模块、教师网络构建模块分别用于构建检测器和教师网络;
[0091]
所述教师学习模块用于将所述有标签样本、无标签样本和增强后的无标签样本送入教师学习模块,得到教师半监督损失、无标签数据的伪标签、教师增强无标签损失;
[0092]
所述检测器学习模块用于将有标签样本、增强后的无标签样本、无标签样本的伪标签送入检测器学习模块更新检测器参数,得到检测器更新损失;
[0093]
所述网络参数更新模块用于利用教师半监督损失、教师增强无标签损失、检测器更新损失,更新教师网络参数,根据损失函数用优化器迭代更新检测器和教师网络的参数,完成训练后保存教师网络和检测器的参数;
[0094]
所述验证模块用于将验证集人脸rgb颜色通道图送入训练好的检测器,得到分类分数,根据不同的判决阈值得到预测的标签值,与真实标签比较,计算虚警率和漏检率,取两者相等时的阈值作为测试判决阈值;
[0095]
所述测试模块用于将测试集人脸rgb颜色通道图送入训练好的检测器,得到分类分数,根据测试判决阈值得到最终预测的标签值,计算基准指标。
[0096]
本发明与现有技术相比,具有如下优点和有益效果:
[0097]
(1)在数据生成阶段,本发明采用了真人编码器、假体编码器、解码器构建双解耦生成器,输入原始样本的真假图像对来训练双解耦生成器,然后从标准正态分布采样噪声输入到双解耦生成器中训练好的解码器,得到生成样本,作为无标签数据的一部分来丰富训练数据的多样性,解决训练数据多样性不足的问题。
[0098]
(2)在训练阶段,本发明采用教师生成伪标签,检测器反馈的半监督学习框架,具体来说,教师网络为检测器提供无标签数据的伪标签来监督检测器学习,检测器参数更新后在有标签数据上评估性能,通过损失反馈给教师网络从而优化其生成的伪标签,解决有
限有标签训练数据情况下的模型训练问题,以及由变分自编码器的缺陷导致生成样本模糊带来的标签不确定问题;挖掘图像块的高区分度特征,提升网络的学习能力,从而可更好地泛化到未见过的样本采集环境。
[0099]
(3)在检测阶段,模型测试加载数据到检测器,得到相应的分类分数,根据阈值判决分类结果,与现有技术相比,在保持库内低错误率的同时跨库错误率能较大下降。
附图说明
[0100]
图1为本发明基于双解耦生成和半监督学习的活体检测方法的流程示意图;
[0101]
图2为本发明真人编码器、假体编码器的网络结构示意图;
[0102]
图3为本发明解码器的网络结构示意图;
[0103]
图4为本发明双解耦生成器的训练阶段流程示意图;
[0104]
图5为本发明双解耦生成器的生成阶段流程示意图;
[0105]
图6(a)为本发明双解耦生成器生成的真人图像示意图;
[0106]
图6(b)为本发明双解耦生成器生成的假体图像示意图;
[0107]
图7为本发明检测器和教师网络的网络结构示意图;
[0108]
图8为本发明的半监督学习的整体框架图;
[0109]
图9为本发明基于双解耦生成和半监督学习的活体检测系统的整体框图。
具体实施方式
[0110]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0111]
本实施例利用replay-attack、casia-mfsd和msu_mfsd活体检测数据集进行训练和测试为例,详细介绍本实施例实施过程。其中replay-attack数据集包含1200个视频,利用分辨率为320
×
240像素的macbook摄像头,采集了来自50个测试者的真实人脸以及据此生成的欺骗人脸,并按照3:3:4划分为训练集、验证集和测试集;casia-mfsd数据集包含600个视频,利用分辨率分别为640
×
480像素、480
×
640像素、1920
×
1080像素的三种摄像机,采集了来自50个测试者的真实人脸以及据此生成的欺骗人脸,并按照2:3划分为训练集和测试集;msu_mfsd数据集包括280个视频,采集了来自35个测试者的真实人脸以及据此生成的欺骗人脸,其中15人用于训练集,20人用于测试集。由于casia-mfsd和msu_mfsd活体检测数据集不包含验证集,对于这两个数据集,本实施例利用对应的测试集作为验证集进行阈值确定。然后对以上的数据集的视频进行分帧得到图片。实施例在linux系统上进行,主要基于深度学习框架pytorch1.6.1来实现,所用显卡为gtx1080ti,cuda版本为10.1.105,cudnn版本7.6.4。
[0112]
如图1所示,本实施例提供一种基于双解耦生成和半监督学习的活体检测方法,包括下述步骤:
[0113]
s1:对输入图像抠取人脸区域图像,得到rgb颜色通道图;
[0114]
在本实施例中,具体步骤包括:对输入图像使用mtcnn人脸识别算法检测人脸区域,裁剪并统一尺寸后得到人脸图像,人脸图像为rgb格式,有红、绿、蓝三个颜色通道。然后
对待训练的rgb颜色通道图原始样本的每张真图像配对相同身份的一张假图像,构成真假图像对,并为假图像标注攻击类别标签;
[0115]
s2:构建真人编码器、假体编码器、解码器,组成双解耦生成器;
[0116]
在本实施例中,如图2所示,真人编码器和假体编码器各自的主干网采用相同的网络结构,输入尺寸设为h
×w×
3,首先经过卷积层、实例归一化层、leakyrelu变成h
×w×
32,然后经过五组由池化层、卷积层堆叠及跳级连接的残差块构成的单元,输出尺寸分别为原始尺寸的1/2、1/4、1/8、1/16、1/32,通道数分别为64、128、256、512、512,得到尺寸为的特征向量。得到主干网的输出特征后,真人编码器经过全连接层输出尺寸为2
×
hdim的隐藏层真人向量;假体编码器经过全连接层输出尺寸为4
×
hdim的隐藏层假体向量。
[0117]
如图3所示,解码器主干网用卷积层、上采样层、sigmoid激活层、残差块搭建。输入尺寸设为3
×
hdim,首先输入全连接层尺寸变为然后经过六组由卷积层堆叠及跳级连接的残差块、上采样层构成的单元,输出尺寸分别为原始尺寸的1/32、1/16、1/8、1/4、1/2、1,通道数分别为512、512、512、256、128、64,最后经过卷积层输出尺寸为h
×w×
6的图像对。
[0118]
s3:构建双解耦生成模块,双解耦生成模块由双解耦生成器以及双解耦生成器损失函数组成,其中双解耦生成器由真人编码器、假体编码器、解码器组成,将真图像送入真人编码器得到真人身份向量,将配对的假图像送入假体编码器得到假体身份向量和假体模式向量,三者合并送入解码器输出重建的真假图像对,构建双解耦生成损失函数进行优化;
[0119]
如图4所示,输入配对的维度各为h
×w×
3的真图像和假图像,分别输入到真人解码器和假体编码器。设隐藏向量维数为n,真人解码器得到维数为2
×
n的真人隐藏向量,其包含维数同为n的真人身份向量均值和真人身份向量方差假体编码器得到维数为4
×
n的假体隐藏向量,其包含维数同为n的假体身份向量均值假体身份向量方差假体模式向量均值假体模式向量方差随后从标准正态分布中采样真人身份变分量假体身份变分量和假体模式变分量进行如下式所示的重参数操作,分别得到真人身份向量假体身份向量和假体模式向量
[0120][0121]
真人身份向量假体身份向量和假体模式向量合并成维数为3
×
n的隐藏向量,输入到解码器,输出维度各为h
×w×
6的重建真假图像对,其中包含维度同为h
×w×
3的重建真人图像和重建假体图像
[0122]
为了更好地学习不同攻击方式的假体模式的,将假体模式向量送入全连接层fc
(
·
),输出假体类别向量并与真实的假体类别标签ys计算交叉熵得到分类损失如下式所示:
[0123][0124]
其中k为假体类别数,ys为经过独热编码的假体类别标签向量。
[0125]
为了让假体身份向量和假体模式向量有效分离,对二者之间加入角正交约束得到正交损失如下式所示:
[0126][0127]
其中《
·
,
·
》表示内积。
[0128]
对重建真人图像和重建假体图像与对应的原图计算重建损失如下式所示:
[0129][0130]
为了保持隐藏向量的身份一致性,对维数为n的真人身份向量假体身份向量计算最大平均差别损失如下式所示:
[0131][0132]
为了保持重建图像的身份一致性,对重建真人图像和重建假体图像计算配对损失如下式所示:
[0133][0134]
为了让隐藏向量的分布拟合成标准正态分布,通过计算kullback-leibler散度(kl散度)进行约束,如下式所示:
[0135][0136]
其中这里的n为隐藏向量的维数。
[0137]
最后,将以上损失加权求和得到双解耦生成器损失函数如下式所示:
[0138][0139]
其中λ1、λ2、λ3、λ4是权衡后的权重,最优值分别为10、0.5、0.1、1。
[0140]
采用adam优化器,以最小化双解耦生成器损失函数为目标优化真人编码器、
假体编码器及解码器,迭代训练t个代数,t的最优值为200。参数更新公式为:
[0141]mt+1
=β1m
t
+(1-β1)g
[0142]vt+1
=β2v
t
+(1-β2)g2[0143][0144]
其中β1,β2最优设置为0.9,0.999,防止除零的参数∈最优设置为1e-8,学习率η最优设置为0.0002,θ
t
表示第t次迭代的参数。
[0145]
s4:从标准正态分布采样噪声输入到训练好的解码器,得到生成样本;
[0146]
如图5、图6(a)和图6(b)所示,设隐藏向量维数为n,从标准正态分布采样维数为n的随机噪声两次,分别得到重建假体身份隐藏向量和重建假体模式隐藏向量为了保证真假图像对身份一致性,重建真人身份隐藏向量直接由重建假体身份隐藏向量复制,然后经过解码器可生成真假图像对,作为生成样本,如图6(a)和图6(b)所示,得到双解耦生成器生成的真假图像对,本实施例维数n最优值为128,生成样本数最优值为6400。
[0147]
s5:裁剪原始样本和生成样本构成的训练集,划分有标签样本、无标签样本,另外对无标签样本进行随机数据增强得到增强后的无标签样本;
[0148]
在本实施例中,首先将待训练的尺寸为h
×
w的rgb颜色通道图随机裁剪出一块尺寸为图像块,待训练的原始样本从中随机选取n张作为有标签数据,剩余样本与生成样本共同构成无标签数据,有标签样本和无标签样本的数量比值为μ。然后对无标签样本进行随机数据增强得到增强后的无标签样本。数据增强方法包括最大化对比度、调节亮度、调节色彩平衡、调节对比度、调节锐度、裁剪、直方图均衡化、反色、像素值最低0-4个比特位置0、随机旋转、水平方向错切、垂直方向错切、水平方向平移、垂直方向平移、将高于一定阈值的所有像素值反转,每个样本随机选取两种数据增强方法进行增强。本实施例的h、w、n、μ优选值为256、256、6000、4;
[0149]
s6:构建检测器和教师网络;
[0150]
如图7所示,教师网络和检测器各自有相同的网络结构,输入尺寸设为h
×w×
3,首先经过卷积层、批归一化层、relu变成h
×w×
16,然后经过三组由卷积层堆叠及跳级连接的残差块构成的单元,输出尺寸分别为原始尺寸的1、1/2、1/4,通道数分别为32、64、128,得到尺寸为的特征向量,再经过全局平均池化层尺寸变为1
×1×
128,最后经过全连接层输出维数为2的分类向量。
[0151]
s7:构建教师学习模块,将有标签样本、无标签样本和增强后的无标签样本送入教师学习模块,得到教师半监督损失、无标签数据的伪标签、增强后的无标签损失:
[0152]
如图8所示,首先约定ce(q,p)表示两个分布q和p的交叉熵损失;如果p是一个标签值则先经过one-hot编码变伪标签向量。设k是标签类别数,交叉熵损失表示为下式:
[0153]
[0154]
其次约定argmax(v)表示取出向量v中最大值所在的索引;
[0155]
对于有标签样本{x
l
,y
l
},送入参数为θ
t
的教师网络t输出教师有标签预测结果t(x
l
;θ
t
),与真实标签y
l
计算交叉熵得到教师有标签损失如下式表示。
[0156][0157]
对于无标签样本xu及经过一次数据增强得到的前文所述的增强后的无标签样本分别送进教师网络t后得到教师无标签预测结果t(xu;θ
t
)和教师增强无标签预测结果将这两个结果计算交叉熵损失,得到教师无标签损失教师无标签预测结果t(xu;θ
t
)取出其最大值所属类别作为伪标签如下式表示:
[0158][0159][0160]
然后将教师有标签损失和教师无标签损失加权求和得到教师半监督损失如下式表示。
[0161][0162]
其中s为当前步数,s
tl
为总步数,λ为无标签损失的权重。
[0163]
对教师增强无标签预测结果与其自身取出的最大值所属类别h,经过交叉熵函数,得到增强无标签损失如下式表示。
[0164][0165][0166]
s8:构建检测器学习模块,将有标签样本、增强后的无标签样本、无标签样本的伪标签送入检测器学习模块更新检测器参数,得到检测器更新损失;
[0167]
如图8所示,将增强后的无标签样本送入参数为θd的检测器d得到检测器增强无标签预测结果与伪标签计算交叉熵,得到检测器增强无标签损失如下式表示:
[0168][0169]
设检测器学习率为ηd,根据检测器无标签损失用梯度下降法优化检测器,得到优化后参数为θ
′d的检测器,如下式表示:
[0170][0171]
将有标签样本(x
l
,y
l
)分别送入优化前参数为θd的检测器和优化后参数为θ
′d的检测器,得到旧的检测器有标签损失和新的检测器有标签损失然后二者作差,得到检测器更新损失如下式表示。
[0172][0173][0174][0175]
s9:利用教师半监督损失、增强后的无标签损失、检测器更新损失,更新教师网络参数:
[0176]
如图8所示,将检测器更新损失与教师增强无标签损失相乘,再与教师半监督损失相加,构成教师损失设教师网络学习率为η
t
,用梯度下降法优化教师网络,表示为下式:
[0177][0178][0179]
s10:根据损失函数用优化器迭代更新检测器和教师网络的网络参数,完成训练后保存教师网络和检测器的参数,表示梯度计算:
[0180]
在本实施例中,教师网络和检测器均采用带nesterov动量的sgd优化器,其中动量为μ,优选值为0.9,学习率初始值为ε0,优选值为0.05,同时学习率随着训练迭代次数衰减;
[0181]
根据检测器学习模块中的检测器增强无标签损失利用检测器优化器以最小化损失为目标进行优化;根据教师更新模块中的教师损失利用教师网络优化器以最小化损失为目标进行优化。
[0182]
s11:利用验证集确定阈值;
[0183]
在本实施例中,具体步骤包括:将验证集人脸rgb颜色通道图送入检测器,得到分类分数p,然后在取值范围(0,1)中进行等间隔采样得到不同的判决阈值,并根据阈值得到预测的标签值,与真实标签比较,计算虚警率和漏检率,取两者相等时的阈值作为测试判决阈值t;
[0184]
s12:模型测试;
[0185]
在本实施例中,具体步骤包括:将测试集人脸rgb颜色通道图送入检测器,得到分类分数为p,然后根据测试判决阈值t得到最终预测的标签值,计算基准指标。
[0186]
本实施例活体检测算法性能评价指标采用错误接受率(false acceptance rate,far)、错误拒绝率(false rejection rate,frr)、正确接受率(true acceptance rate,tar)、等错误率(equal error rate,eer)、半错误率(half total error rate,hter。用表1的混淆矩阵对上述指标做详细说明:
[0187]
表1混淆矩阵表
[0188]
标签/预测预测为真预测为假标签为真tafr标签为假fatr
[0189]
错误接受率(far)指非活体人脸判断成活体人脸数占标签为非活体人脸数的比率:
[0190][0191]
错误拒绝率(frr)指活体人脸判断成非活体人脸数占标签为活体人脸数的比率:
[0192][0193]
正确接受率(tar)指活体人脸判断成活体人脸数占标签为活体人脸数的比率:
[0194][0195]
等错误率(eer)是frr与far相等时的错误率;
[0196]
半错误率(hter)为frr与far的均值:
[0197][0198]
为了证明本发明的有效性以及检验该方法的泛化性能,在casia-mfsd、replay-attack、msu-mfsd数据库上分别进行库内实验与跨库实验。库内实验结果和跨库实验结果分别如表2和表3所示:
[0199]
表2库内实验结果
[0200][0201]
表3跨库实验结果
[0202][0203]
由表2可知,本方法在库内的半错误率和等错误率都是较低的,库内具有欺骗检测的优秀性能;由表3可知,跨库检测的半错误率也是较低的;训练集由每段训练集视频抽取较少数量的帧的有标签样本以及无标签样本组成,但通过双解耦生成器得到生成数据来丰富训练数据的多样性,以及通过元学习渐进地训练模型,提高了对有限样本特征的学习能力以及模型启发能力。上述实验结果证明,本发明在有标签训练样本不充足情况下,保证库内高准确率的同时,大幅降低跨库错误率,明显改善泛化性能。
[0204]
如图9所示,本实施例还提供一种基于双解耦生成和半监督学习的活体检测系统,包括:数据预处理模块、双解耦生成器构建模块、双解耦生成器训练模块、生成样本构建模块、无监督数据增强模块、检测器构建模块、教师网络构建模块、教师学习模块、检测器学习模块、网络参数更新模块、验证模块和测试模块;
[0205]
在本实施例中,数据预处理模块用于对输入图像抠取人脸区域图像,得到rgb颜色通道图,对待训练的rgb颜色通道图原始样本的每张真图像配对相同身份的一张假图像,构
成真假图像对,并为假图像标注攻击类别标签;
[0206]
在本实施例中,双解耦生成器构建模块用于构建真人编码器、假体编码器、解码器,组成双解耦生成器;
[0207]
在本实施例中,双解耦生成器训练模块用于将真图像送入真人编码器得到真人身份向量,将配对的假图像送入假体编码器得到假体身份向量和假体模式向量,将真人身份向量、假体身份向量和假体模式向量合并送入解码器输出重建的真假图像对,构建双解耦生成损失函数进行优化;
[0208]
在本实施例中,生成样本构建模块用于从标准正态分布采样噪声输入到训练好的解码器得到生成样本;
[0209]
在本实施例中,无监督数据增强模块用于裁剪原始样本和生成样本构成的训练集,构建有标签样本、无标签样本、增强后的无标签样本;
[0210]
在本实施例中,检测器构建模块、教师网络构建模块分别用于构建检测器和教师网络;
[0211]
在本实施例中,教师学习模块用于将所述有标签样本、无标签样本和增强后的无标签样本送入教师学习模块,得到教师半监督损失、无标签数据的伪标签、教师增强无标签损失;
[0212]
在本实施例中,检测器学习模块用于将有标签样本、增强后的无标签样本、无标签样本的伪标签送入检测器学习模块更新检测器参数,得到检测器更新损失;
[0213]
在本实施例中,网络参数更新模块用于利用教师半监督损失、教师增强无标签损失、检测器更新损失,更新教师网络参数,根据损失函数用优化器迭代更新检测器和教师网络的参数,完成训练后保存教师网络和检测器的参数;
[0214]
在本实施例中,验证模块用于将验证集人脸rgb颜色通道图送入训练好的检测器,得到分类分数,根据不同的判决阈值得到预测的标签值,与真实标签比较,计算虚警率和漏检率,取两者相等时的阈值作为测试判决阈值;
[0215]
在本实施例中,测试模块用于将测试集人脸rgb颜色通道图送入训练好的检测器,得到分类分数,根据测试判决阈值得到最终预测的标签值,计算基准指标。
[0216]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1