一种基于YOLOv5的水果识别方法
一种基于yolo v5的水果识别方法
技术领域
1.本发明属于计算机视觉技术领域,涉及一种基于yolo v5的水果识别方法。
背景技术:
2.目前国内众多超市水果售卖流程复杂且枯燥,需要大量人工成本,并且在人流高峰时期售卖压力很大。同时疫情期间,增大了公共场所人员接触风险,对防疫不利。因此对水果的智能化结算显得十分重要,使用水果智能称结算成为解决方法之一。这要求智能称可以完全代替人眼对水果进行识别,即需要识别出待识别区域的水果种类。
3.由于水果种类很多,并且每个大类中还有很多小分类,其外观形状相似,这很大程度上增加了水果识别的难度,导致水果种类的识别率降低,且处理速度变慢。目前大多数的水果种类识别方式都是,通过人工称重,并打印条形码标签,贴上标签,最后通过扫描条形码进行识别结算。这很不方便,并且不环保。同时由于是人工识别,长时间并且单调的工作很可能造成疲倦,导致工作的出错率提高。
4.近年来,随着计算机视觉与目标检测的快速发展,许多的目标检测算法可以很好的完成目标检测任务,目标检测的关键步骤是定位目标,以及目标分类。目前yolo v5在目标检测领域具有很好的表现。但是在智能称识别中,由于摄像头距离是固定的,水果大小,形状都相对单一,因此对模型对特定通道的关注十分的重要。然而yolo v5的特征提取,并没有对重要的通道进行重点关注,以及所有卷积操作都采用标准卷积,增加了模型计算量,因此存在很多改进的方面。
技术实现要素:
5.本发明的目的就是提供一种基于yolo v5的水果识别方法。将sknet与残差模块相结合设计新的模块替换yolo v5中的残差模块,同时使用空洞卷积降低模型复杂度,实现超市中水果的自动识别。
6.本发明包括以下步骤:
7.步骤一、水果图像收集:利用相机对超市水果进行视频拍摄,其中每次拍摄单品种水果,方便后续打标等处理。
8.步骤二、视频采样图片:对拍摄的视频进行间隔采样,获得图片。
9.步骤三、图像标注以及数据集划分:对获得的图片标注图中物体边界框位置和类别,然后将数据集划分为训练集、验证集、测试集,其比例为8:1:1。
10.步骤四、图像数据增强:对训练集图像进行预处理,旋转、裁剪,增加训练集图片数量,以提高模型的泛化能力。
11.步骤五、对真实框聚类分析设计先验框:首先对所有真实框进行划分,严格按照大中小面积划分,其中大目标定义为像素面积大于96*96,中目标定义为像素面积大于32*32并小于96*96,小目标定义为像素面积小于32*32。再分别对大中小真实框进行k-means聚类,得到大中小三个先验框的大小。
12.k-means聚类包括以下步骤:在数据集中确定聚类数量;随机设定每个聚类的质心向量;为每个数据分配距离最近质心,选用二范数,其计算方法如下:
[0013][0014]
其中(x,y)代表质心的向量,(xi,yi)代表非质心向量,i为整数表示聚类数量。
[0015]
将该数据分配到所属质心的聚类,直到全部分配完毕;更新质心向量,质心向量值为该聚类的均值;如果质心向量发生变化则重复3、4步骤,否则输出质心。
[0016]
步骤六、构建模型:yolo v5网络包括特征提取部分、特征融合部分和预测部分;
[0017]
对其特征提取部分和特征融合部分进行优化:
[0018]
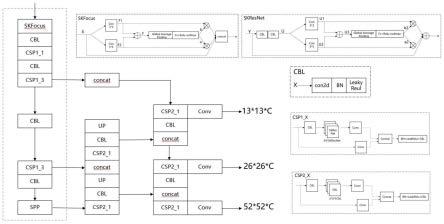
特征提取部分包括focus模块、cbl模块、由cbl模块和残差模块组成的csp模块、以及spp模块。focus模块用于对图像进行切片融合,cbl模块由2d卷积、批量归一化、leaky relu组成,csp由cbl和多个残差块组成,spp模块由多个多尺度最大池化组成。将sknet模块嵌入到focus模块中,形成skfocus。并将sknet与残差模块相结合设计新的sk残差模块。
[0019]
skfocus为:对输入图片x,分别使用卷积核大小为3*3卷积操作,卷积核为5*5的空洞卷积,得到特征图f1、f2。将两个特征按元素相加得到特征f。f在经过全局平均池化得到通道统计信息,其计算公式为:
[0020][0021]
其中,h为特征f的高,w为特征f的宽,c为特征f的通道数。
[0022]
sc在经过fc+sigmoid对特征图f1、f2分别生成对应权重向量a,b。然后分别按通道方向做softmax,其公式为:
[0023][0024]
其中c代表通道数,ac和bc分别与特征f1、f2加权相乘,在与原来输入x进行按通道拼接。
[0025]
sk残差模块为,对输入y经过两个cbl后输出特征u,该特征u分别使用卷积核大小为3*3卷积操作,卷积核为5*5的空洞卷积,得到特征图u1、u2。将两个特征按元素相加得到特征u3。u3在经过全局平均池化得到通道统计信息,在经过fc+sigmoid分别生成权重c2,d2,其中c2+d2=1。将c2和d2分别与特征u1、u2加权相乘按元素相加,然后与原来输入y按元素相加。
[0026]
其中空洞卷积为,在标准卷积的基础上增加参数dilated rate,这个参数就是在卷积核中填充dilation rate-1个0,在具体实现时,采用对输入的间隔dilation rate-1采样,从而在实现同样感受野的时候,减小参数量和运算量。
[0027]
特征融合模块主要采用了fpn+pan的结构对特征进行融合得到19*19,38*38,76*76的特征图,同时本方法将特征融合模块中卷积核大于等于5*5的卷积操作替换为dilated rate=2的空洞卷积。将上述得到的特征图输入预测模块进行预测。其中19*19特征图用于大目标的预测,38*38特征图用于中等目标的预测,76*76特征图用于小目标的预测。
[0028]
步骤七、训练模型并调参优化模型:在训练之前,使用步骤五中得到的先验框输入到模型检测头对目标的位置和类别进行训练,同时使用迁移学习,将已经在大数据集上训
练的yolo v5参数加载到此模型,然后使用经步骤一~步骤四处理的数据集进行训练;每次迭代都计算损失函数,并更新参数值,使损失函数的值最小,直到模型收敛,同时为防止过拟合,迭代次数不超过300次。
[0029]
步骤八、在完成模型训练后,保存模型权重参数,设置格式为.pt格式。对保存到模型权重文件重新加载,并用这个权重文件检测测试集的图片。
[0030]
本发明对预测框的聚类分析使模型针对水果形状更好的进行预测;改进的yolov5特征提取网络,针对市面上大部分水果进行特征提取,针对不同通道,分配不同的特征权重,降低重要特征在传递过程中的损失,提高针对水果的识别率;同时使用空洞卷积降低模型计算复杂度。
附图说明
[0031]
图1为拍摄的水果视频;
[0032]
图2为对视频进行处理采集到的水果图像;
[0033]
图3为使用labelimg对图像打标;
[0034]
图4为构建的特征提取与分类模型;
[0035]
图5为空洞卷积示意图;
[0036]
图6为训练集的损失函数图;
[0037]
图7为测试集的测试结果图。
具体实施方式
[0038]
步骤一、水果图像收集:如图1所示,利用相机对超市每种水果进行视频拍摄得到视频40个,得到水果种类40种。
[0039]
步骤二、视频采样图片:如图2所示,使用opencv对拍摄的视频进行间隔采样,每类250张共获得图片10000张。
[0040]
步骤三、图像标注以及数据集划分:如图3所示,使用labelimg对获得的图片进行标注物体边界框位置和类别,然后将数据集划分为训练集、验证集、测试集,其比例为8:1:1。
[0041]
步骤四、图像数据增强:使用torchvision对训练集图像进行预处理,旋转、裁剪,增加训练集图片数量,以提高模型的泛化能力。
[0042]
步骤五、对真实框聚类分析设计先验框。与原模型直接采用k-means算法不同,首先对所有真实框进行划分,严格按照大中小面积划分,其中大目标定义为像素面积大于96*96,中目标定义为像素面积大于32*32并小于96*96,小目标定义为像素面积小于32*32。在分别对大中小真实框进行k-means聚类,得到大中小类别分别三个先验框的大小。
[0043]
其中k-means聚类包括以下步骤:在数据集中确定聚类数量i,本实施中聚类数量i为3;随机设定每个聚类的质心向量;为每个数据分配距离最近质心,选用二范数,其计算方法如下:
[0044][0045]
其中(x,y)代表质心的向量,(xi,yi)代表非质心向量。
[0046]
将该数据分配到所属质心的聚类,直到全部分配完毕;更新质心向量,质心向量值为该聚类的均值;如果质心向量发生变化则重复步骤三、步骤四,否则输出质心。
[0047]
步骤六、构建模型:yolo v5网络包括特征提取部分、特征融合部分和预测部分,对其特征提取部分进行优化;
[0048]
如图4所示,yolo v5的特征提取部分包括focus模块、cbl模块、csp模块以及spp模块。其中focus模块用于对图像进行切片融合,cbl模块包括2d卷积、批量归一化和leaky relu,csp模块包括cbl模块和多个残差块组成,spp模块包括多个多尺度最大池化。将sknet模块嵌入到focus模块中,形成skfocus,并将sknet与残差模块相结合设计出skresnet模块。
[0049]
其中skfocus为:对输入图片x,分别使用卷积核大小为3*3卷积操作,卷积核为5*5的空洞卷积,得到特征图f1、f2,将两个特征按元素相加得到特征f。f在经过全局平均池化得到通道统计信息,其计算公式为:
[0050][0051]
其中,h为特征f的高,w为特征f的宽c为特征f的通道数。
[0052]
sc在经过fc+sigmoid对特征图f1、f2分别生成对应权重向量a,b。然后分别按通道方向做softmax,其公式为:
[0053][0054]
其中c代表通道数,ac和bc分别与特征f1、f2加权相乘,在与原来输入x进行按通道拼接。
[0055]
其中skresnet模块为:对输入y经过两个cbl模块后输出特征u,该特征u分别使用卷积核大小为3*3卷积操作,卷积核为5*5的空洞卷积,得到特征图u1、u2;将两个特征按元素相加得到特征u3。u3在经过全局平均池化得到通道统计信息,在经过fc+sigmoid分别生成权重c2,d2,其中c2+d2=1。将c2和d2分别与特征u1、u2加权相乘按元素相加,再与原来输入y按元素相加。
[0056]
空洞卷积为:在标准卷积的基础上增加参数dilated rate(在卷积核中填充dilation rate-1个0),在具体实现时,采用对输入的间隔dilation rate-1采样,从而在实现同样感受野的时候,减小参数量和运算量。如图5所示,本实施例中设置dilated rate为2。
[0057]
特征融合模块采用了fpn+pan的结构对特征进行融合得到19*19,38*38,76*76的特征图,同时本方法将特征融合模块中卷积核大于等于5*5的卷积操作替换为dilated rate=2的空洞卷积。将上述得到的特征图输入预测模块进行预测。其中19*19特征图用于大目标的预测,38*38特征图用于中等目标的预测,76*76特征图用于小目标的预测。
[0058]
步骤七、训练模型并调参优化模型:在训练之前,使用步骤五中得到的先验框输入到模型检测头对目标的位置和类别进行训练,同时使用迁移学习,将已经在大数据集上训练的yolo v5参数加载到此模型,然后使用经步骤一~步骤四处理的数据集进行训练。每次迭代都计算损失函数,并更新参数值,使损失函数的值最小,直到模型收敛,同时为防止过
拟合,如图6所以,迭代次数不超过300次。
[0059]
步骤八、在完成模型训练后,保存模型权重参数,设置格式为.pt格式。对保存到模型权重文件重新加载,并用这个权重文件检测测试集的图片,查看如图7所示的实际效果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1