一种使用注意力网络的值分解多智能体强化学习训练方法
1.本发明涉及一种强化学习训练方法,特别是一种使用注意力网络的值分解多智能 体强化学习训练方法。
背景技术:
2.强化学习(reinforcement learning,rl)是机器学习的一个细分领域,主要用于解决 序列决策问题。智能体通过不断的和环境进行交互,不断探索,优化策略,最终实现 回报的最大化或既定的目标。在多智能体强化学习中,多个智能体需要共同合作,完 成相同的目标。正因如此,多智能体强化学习更加贴近现实世界的问题,更具有现实 意义。
3.多智能体环境下,出现了一些单智能体环境中不存在的问题,如环境不稳定,维 度爆炸和信用分配问题等。环境不稳定是指当其他智能体的策略发生变化时,对于单 个智能体来说,其面对的环境也会发生变化,影响算法的收敛。维度爆炸是指联合动 作空间随着智能体数量的增加呈指数式的增加,增加学习的难度。信用分配问题是指 环境只会给出一个奖励,这个奖励是所有智能体执行联合动作的结果,而每个智能体 需要知道其动作对整体的贡献是多少,以此优化自身的策略。
4.q学习是经典的单智能体强化学习,其通过估计值函数(当前状态下可以获得的 累计回报)来优化策略。值分解是多智能体强化学习中的一种方法,其将联合动作的 值函数分解为每个智能体值函数的一个函数,让网络自动的学习信用分配,提高学习 的效率和效果。
5.中心化学习分布式执行是一种通用的解决范式,在训练时,网络可以使用全局信 息作为额外输入,在执行时,则不可以获取全局信息,只能使用自身的状态进行决策。
6.qmix是一个典型的基于值分解的多智能体强化学习算法,其使用每个独立值函 数加权求和生成联合动作值函数,权重则使用全局状态生成。
技术实现要素:
7.发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种使用注 意力网络的值分解多智能体强化学习训练方法。
8.为了解决上述技术问题,本发明公开了一种使用注意力网络的值分解多智能体强 化学习训练方法,包括以下步骤:
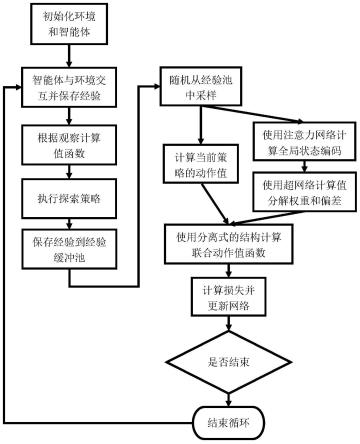
9.步骤1,初始化环境和所有智能体状态;包括:初始化智能体网络和环境,初始化 每个智能体的值函数网络,以及对应的目标网络,初始化用于计算联合动作值函数的 网络,初始化环境,得到最初的状态;
10.步骤2,智能体使用探索策略与环境交互,并将经验保存到经验缓存池中;
11.步骤3,执行智能体网络的训练:即从经验缓冲池中采样并计算损失函数;
12.步骤4,循环执行步骤2和步骤3,直到结束;最终根据智能体值函数得到智能 体贪婪策略,作为输出策略,完成多智能体强化学习训练。
13.本发明中,所述步骤2包括:
14.步骤2-1,智能体使用当前的观察和上一时刻的动作作为值函数网络的输入,输出当前时刻所有动作的值函数,即每个动作获得的累计回报;
15.步骤2-2,智能体根据当前的探索率决定采取随机动作或值函数最大的动作;
16.步骤2-3,智能体得到环境的奖励和新的观察,将当前观察,当前动作,奖励,新的观察作为一次经验保存到经验缓存池中。
17.本发明中,所述步骤2-1包括:
18.每个智能体i根据当前的观察和上一时刻的动作得到当前所有动作的值函数;值函数网络共包含3层,一层线性层,一层循环神经网络层以及最后一层线性层;循环神经网络(参考:chungj,gulcehrec,chokh,etal.empiricalevaluationofgatedrecurrentneuralnetworksonsequencemodeling[j].arxivpreprintarxiv:1412.3555,2014.)使用当前时刻的隐状态作为输入,输出当前时刻的编码以及下一时刻的隐状态;该过程表示如下:
[0019][0020][0021][0022]
其中mlp表示多层感知机,rnn表示循环神经网络,和为临时变量,表示当前时刻的隐状态,表示下一时刻的隐状态,qi表示智能体的动作值函数。
[0023]
本发明中,所述步骤2-2包括:
[0024]
智能体根据当前的值函数决定采取的动作;在积累经验阶段,智能体采取探索策略,而非单纯的执行最优的策略;智能体维持一个探索率ε,探索策略是指智能体会以ε的概率执行随机动作,以1-ε的概率执行最优动作,即值函数最大的动作;探索率随着时间的增加而不断减小但不为零,即执行随机动作的概率越来越小,但不为零;
[0025]
所述步骤2-3包括:
[0026]
所有智能体维持一个经验缓冲池d,当智能体i做出一个动作后,智能体接收到环境的反馈,包含所有智能体共享的奖励r
t
和新的观察智能体将当前观察,当前动作,奖励,新的观察作为经验保存到经验缓冲池中,为后续的学习做准备;经验缓冲池如果满了,最早的经验被丢弃。
[0027]
本发明中,步骤3包括:
[0028]
步骤3-1,从经验缓冲池中采样,并使用智能体值函数网络得到当前时刻智能体的动作值函数;
[0029]
步骤3-2,将全局状态作为额外输入,并使用注意力网络(参考:vaswania,shazeern,parmarn,etal.attentionisallyouneed[j].advancesinneuralinformationprocessingsystems,2017,30.)计算全局状态编码;
[0030]
步骤3-3,使用超网络计算值分解权重和偏差,超网络的输入是全局状态编码;
[0031]
步骤3-4,使用分离式的值分解计算所有智能体联合动作的值函数,值分解权重和偏差是步骤3-3的输出;
[0032]
步骤3-5,使用目标网络计算联合动作值函数的损失,优化智能体值函数网络。
[0033]
本发明中,步骤3-1包括:
[0034]
每次训练时,从经验缓存池中采样n个经验回放,即包括当前观察,动作,回报, 下一观察的序列,使用智能体值函数网络计算当前观察下执行该动作可以获得的累计 回报,即值函数。
[0035]
本发明中,步骤3-2包括:
[0036]
使用注意力网络编码全局状态;注意力网络的输入为全局状态s
t
,注意力网络的计 算方式为:
[0037][0038][0039][0040]
其中,lf表示线性函数,attention表示注意力网络,q
t
,k
t
,v
t
为注意力网络的输 入矩阵,sf
t
表示全局状态编码,表示最终的全局状态编码;全局状态s
t
经过线 性函数后得到了划分成多个部分,每个部分单独使用线性函数计算注意力 机制的和矩阵,,注意力机制的计算方式为:
[0041][0042]
其中,exp表示指数函数,q,k,v为注意力网络输入矩阵,f为点乘函数用于计算ki和 所有q的相似度,分母为所有kj与所有q的相似度的和用于归一化;注意力网络输出 最终的全局状态编码
[0043]
本发明中,步骤3-3包括:
[0044]
使用超网络计算值分解权重和偏差,输入为步骤3-2中得到的全局状态编码;超 网络由两层线性层组成,全局状态编码分为两个部分和每个部分 内的值拼接到一起作为超网络的输入;这个过程为:
[0045][0046][0047]
其中lf表示超网络,是线性函数,w1和b1分别表示第一层超网络生成的值分解 权重和偏差,w2和b2表示第二层超网络生成的值分解权重和偏差。
[0048]
本发明中,步骤3-4包括:
[0049]
使用分离式的值分解结构计算联合动作值函数,输入为步骤3-3得到的权重和偏 差,最终的联合动作值函数是每个智能体独立值函数qi使用超网络得到的权重w和偏 差b融合的输出;这个过程为:
[0050]
h=qi*w1+b1[0051]qtot
=h*w2+b2[0052]
其中q
tot
表示所有智能体联合动作的值函数,h为临时变量。
[0053]
本发明中,步骤3-5包括:
[0054]
使用td(λ)计算(参考:suttonrs,bartoag.reinforcementlearning:anintroduction[m].mitpress,2018.)联合动作值函数的期望值y
tot
则损失函数为:
[0055][0056]
其中θ表示智能体值函数网络参数,e表示数学期望,d表示经验缓存,q
tot
表示联合动作值函数。
[0057]
有益效果:
[0058]
使用多智能体强化学习训练方法得到的最终模型可以更好的控制多个智能体,每个智能体只需要根据自身有限的信息就可以和其他智能体进行配合,共同完成相同的目标。对比现有的方法可以更高效的利用全局信息,更加精确的衡量每个智能体对整个系统的贡献,提高智能体之间的合作策略效果,提升复杂场景中多智能体的表现。
附图说明
[0059]
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
[0060]
图1为本发明的流程图。
[0061]
图2为发明的模型结构图。
[0062]
图3为注意力网络结构图。
具体实施方式
[0063]
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述有益效果或其他方面的优点将会变得更加清楚。
[0064]
本发明公开了一种使用注意力网络的值分解多智能体强化学习训练方法,本方法应用于解决复杂场景中的序列决策问题,提高多个智能体协作的效率,包括以下步骤:
[0065]
步骤1,初始化环境和所有智能体状态;
[0066]
步骤2,智能体使用探索策略与环境交互,并将经验保存到经验缓存池中:
[0067]
步骤2-1,智能体使用当前的观察和上一时刻的动作作为值函数网络的输入,输出当前时刻所有动作的值函数,即每个动作可以获得的累计回报;
[0068]
步骤2-2,智能体根据当前的探索率决定采取随机动作或是值函数最大的动作;
[0069]
步骤2-3,智能体得到环境的奖励和新的观察,将当前观察,当前动作,奖励,新的观察作为一次经验保存到经验缓存池中;
[0070]
步骤3,执行智能体网络的训练:
[0071]
步骤3-1,从经验缓存池中采样,并使用智能体值函数网络得到当前时刻智能体的动作值函数;
[0072]
步骤3-2,将全局状态作为额外输入,并使用注意力网络计算全局状态编码;
[0073]
步骤3-3,使用超网络计算值分解权重和偏差,超网络的输入是全局状态编码;
[0074]
步骤3-4,使用分离式的值分解计算所有智能体联合动作的值函数,值分解权重和偏差是步骤3-3的输出;
[0075]
步骤3-5,使用目标网络计算联合动作值函数的损失,优化智能体值函数网络。
[0076]
步骤4,循环执行步骤2、3,直到结束。最终根据智能体值函数得到智能体贪婪 策略,作为输出策略。
[0077]
下面结合附图和实施例对本发明做进一步的说明。
[0078]
本发明公开了一种使用注意力网络的值分解多智能体强化学习训练方法,如图1 所示,包含:首先初始化模型和环境,包括智能体值函数网络初始化,环境初始化, 经验缓冲池初始化。之后,智能体与环境进行交互,该过程可以描述为智能体先获得 环境给出的观察,再根据当前的观察和历史信息编码得到当前所有动作的值函数, 然后根据探索率∈选择执行随机动作或贪婪动作,环境接收到智能体的动作并执行,将 下一观察和回报r
t
返回给智能体,智能体将当前观察,动作,回报,下一观察存入 经验池中。经验收集完成后进入训练阶段:先从经验缓冲池中随机采样,计算每个智 能体的动作值函数,然后使用注意力网络计算值分解权重,使用权重计算智能体值函 数的加权和作为联合动作值函数,通过目标网络计算期望回报并最小化损失来更新网 络参数。
[0079]
模型的结构如图2所示,包括两个部分:智能体值函数网络和混合网络,图2中 右侧为值函数网络的详细结构,左侧为混合网络详细结构。值函数网络的输入为智能 体当前的观察和上一时刻的动作值函数网络结构分为三层:两层线性层(mlp) 和一层循环神经网络(rnn),其中循环神经网络用于编码当前时刻的隐状态得到下 一时刻的隐状态智能体得到当前时刻的值函数qi后执行探索策略,根据当前的 探索率∈选择执行的动作,得到对应动作的值函数qi。
[0080]
混合网络的输入为所有智能体的动作值函数和全局状态s
t
。全局状态s
t
使用注意 力网络进行编码得到全局状态编码,全局状态编码被分为两个部分,分别作为两层超 网络的输入,生成值分解权重和偏差,最终融合所有智能体动作值函数得到最终的联 合动作值函数q
tot
。图3展示了注意力网络详细结构,输入为使用线性函数得到的全局 状态编码这个编码被分成了多个部分:一直到每个部分单独计算 注意力网络输入矩阵,并计算注意力权重,最后使用点乘(dot)的方式计算输出全局 状态编码其中包含一直到以为例,首先使用线 性函数计算注意力网络输入矩阵和然后根据注意力计算公式得到注意力权 重α1,最后使用点乘(dot)计算输出
[0081]
在本实例中,使用注意力网络的值分解多智能体强化学习训练方法具体包括:
[0082]
步骤1:初始化智能体网络和环境;初始化每个智能体的值函数网络,以及对应的 目标网络;初始化用于计算联合动作值函数的网络;初始化环境,得到最初的状态
[0083]
步骤2:智能体执行探索策略,收集经验,并将经验保存到经验缓冲池中。这个步 骤包含:
[0084]
步骤2-1:每个智能体根据当前的观察和上一时刻的动作得到当前所有动作 的值函数。值函数网络共包含3层,一层线性层,一层循环神经网络层以及最后一层 线性层。循环神经网络使用上一时刻的隐状态作为输入,输出当前时刻的编码以及下 一时刻的
隐状态。这个过程可以表示为:
[0085][0086][0087][0088]
其中mlp表示多层感知机,rnn表示循环神经网络,和为临时 变量,表示当前时刻的隐状态,表示下一时刻的隐状态,qi表示智能体的动作值 函数。
[0089]
步骤2-2:智能体根据当前的值函数决定采取的动作。在积累经验阶段,智能体采 取探索策略,而非单纯的执行最优的策略。智能体维持一个探索率ε,探索策略是指智 能体会以ε的概率执行随机动作,以1-ε的概率执行最优动作,即值函数最大的策略。 探索率会随着时间的增加而不断减小但不会到0,即执行随机动作的概率会越来越小, 但不会为零。
[0090]
步骤2-3:所有智能体维持一个经验缓冲池d,每当智能体做出一个动作后,智能 体接收到环境的反馈,包含奖励r
t
和新的观察智能体会将当前观察,当前动作, 奖励,新的观察作为经验保存到经验缓冲池中,为后续的学习做准备。经验缓冲池是 有大小的,如果满了,最早的经验会被丢弃。
[0091]
步骤3:执行智能体的训练,即从经验缓冲池中采样并计算损失函数。包含:
[0092]
步骤3-1:每次训练时,需要从经验缓存池中采样n个经验回放,即包括当前观察, 动作,回报,下一观察的序列,使用智能体值函数网络计算当前观察下执行该动作可 以获得的累计回报,即值函数。
[0093]
步骤3-2:使用注意力网络计算值分解权重。注意力网络的输入为全局状态s
t
,注 意力网络的计算方式可以表示为:
[0094][0095][0096][0097]
其中,lf表示线性函数,attention表示注意力网络,q
t
,k
t
,v
t
为注意力网络的输 入矩阵,sf
t
表示全局状态编码,表示最终的全局状态编码;全局状态s
t
经过线 性函数后得到了划分成多个部分,每个部分单独使用线性函数计算注意力 机制的和矩阵,,注意力机制的计算方式为:
[0098][0099]
其中exp表示指数函数,f为点乘函数用于计算ki和所有q的相似度,分母为所有 kj与所有q的相似度的和用于归一化;注意力网络输出最终的全局状态编码
[0100]
步骤3-3:使用超网络计算值分解权重和偏差,输入为步骤3-2得到的全局状态编 码。超网络由一层线性层组成,全局状态编码被分为两个部分,每个部分内的值被拼 接到一起作为超网络的输入。这个过程可以表示为:
偏差是步骤3-3的输出;
[0126]
步骤3-5,使用目标网络计算所有模块联合动作值函数的损失,优化每个模块的智 能体值函数网络。
[0127]
步骤4,循环执行步骤2、3,直到结束。最终根据每个模块智能体值函数得到每 个模块的贪婪策略,作为输出策略。
[0128]
使用本发明得到的输出策略可以提高机器人控制的效率,提高合作策略的收敛速 度,更快的完成任务。分离式执行的特点使得机器人每个模块只需要根据自身的状态 就可以有效的和其他模块之间进行合作,达到整体的平衡和稳定,并且相较于基于规 则的方法由更强的适应性,可以适用于不同的环境,面对复杂环境也可以发挥作用。
[0129]
由此可见,使用注意力网络的值分解多智能体强化学习训练方法可以更高效的实 现多智能体之间的协同合作,其采用的注意力网络可以自动的注意到环境中的有利部 分,同时忽视不重要的部分,更加高效的编码复杂全局状态信息。分离式的值分解结 构可以减小超网络的学习难度,更加精确的计算值分解权重,加快模型的收敛,提高 学习的效率,最终学习到获得最大奖励的策略。
[0130]
本发明提供了一种使用注意力网络的值分解多智能体强化学习训练方法的思路及 方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式, 应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还 可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中 未明确的各组成部分均可用现有技术加以实现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1