基于RS粗糙集和CPA算法的稻虾水质预测方法
基于rs粗糙集和cpa算法的稻虾水质预测方法
技术领域
1.本发明涉及水质预测技术领域,具体涉及一种基于rs粗糙集和cpa算法的稻虾水质预测方法。
背景技术:
2.我国是一个农业大国,现代农业在科技不断进步的推动下,智慧农业便应需而生,由于智慧农业的科学养殖理念,出现了一批农作物共作的养殖系统,稻虾共作便是其中之一。稻虾水质是共作系统重要指标之一,直接影响稻虾的产量与经济的收益,使得稻虾水质预测成为研究的热点问题。传统的水质预测模型主要包括神经网络模型、灰色系统理论模型、回归分析模型以及证据理论预测模型等。但是现有的单一预测技术存在精度不高,抗干扰性低等问题。
技术实现要素:
3.发明目的:针对现有技术中存在的问题,本发明提供一种基于rs粗糙集和cpa算法的稻虾水质预测方法,减低了不确定数据对数据融合的影响,简化输入特征,提高对稻虾水质预测的抗干扰性和准确性,具有一定的推广和应用价值。
4.技术方案:本发明提供了一种基于rs粗糙集和cpa算法的稻虾水质预测方法,包括如下步骤:
5.步骤1:对稻虾水域随机两块区域进行测量ph值、浑浊度、气压、温度、氨氮以及溶解氧六项指标,各区域每次重复测量一组,一天测量多次,分别记为a
1-a
12
和a
13-a
24
;
6.步骤2:对测量的水质数据预处理,将数据归一化以文本的形式存储,将数据转换至0-1之间;
7.步骤3:根据稻虾对不同水质的生存情况,将指标划分等级;
8.步骤4:通过rs粗糙集对a
1-a
24
属性约简,找出几组最简属性集;
9.步骤5:将步骤4几组最简属性集代入rbf神经网络进行mse比较,得出一组最优属性集,并将一组最优属性集的属性分为训练集和测试集;
10.步骤6:确定rbf神经网络的拓扑结构,将rbf神经网络的径向基函数的中心、宽度以及隐层到输出层的权值作为cpa算法的初始种群,使用cpa算法进行优化得到优化后的中心、权值和宽度;
11.步骤7:最终得出优化模型,利用该优化模型及步骤5中划分的训练集和测试集进行预测虾稻水质。
12.进一步地,所述a
1-a
12
为两组六参数水质指标,a
1-a
12
为同一块区域,a
13-a
24
为另一块区域两组六参数水质指标。
13.进一步地,所述步骤3中指标划分为:i(优)、ii(良)、iii(差)三个等级。
14.进一步地,所述步骤4对对a
1-a
24
的属性约简步骤如下:
15.步骤1)将预处理之后的水质数据按照各个属性对应的区间进行划分,并进行编
号,获得试验数据决策表;
16.步骤2)通过遗传算法,对试验数据决策表进行约简;
17.步骤3)根据公式γc(d)=|posc(d)|/|u|,计算出决策属性d({d1,d2,d3,
…di
})对条件属性c({c1,c2,c3,
…cj
})的依赖度γc(d),其中,d1,d2,d3,
…di
表示所有决策属性集合,c1,c2,c3,
…cj
表示所有条件属性集合,d表示决策属性,u表示论域;
18.步骤4)定义rduct(c)=c-{cj}为条件属性c的约简集,将条件属性cj逐个去除,比较γ
reduct(c)
(d)与γc(d)的大小,若γ
reduct
(d)=γc(d),则终止运算;若不等,将执行步骤1);
19.步骤5)使用染色体编码方法,根据公式其中,x表示对象子集,x表示对象,u表示论域,将每个条件属性对每个个体编码,通过二进制字符串[0,1]的形式;若条件属性属于本个体,就表示为1;否则表示0;从而得到个体适应度f(r)值:
[0020]
f(r)=(l-l
τ
)/l+γc(d)
[0021]
其中,编码1的染色体个数为l
τ
,条件属性个数为l;初始种群由pop_size的长度为|c|的二进制个体构成,且pop_size=2
|c|
;
[0022]
步骤6)计算下一代种群个体的适应度值,通过轮盘赌法从中选择,使用交叉概率pc来表示交叉点处染色体交叉概率,某个等位属性编码值反转概率用pm表示,也就是变异概率;
[0023]
步骤7)选择最优个体,将它代入下一代种群,观察适应度,若不再变化或迭代步数到最大值,将最优个体输出,否则跳转执行步骤6)。
[0024]
进一步地,所述步骤6中cpa算法优化步骤为:
[0025]
1)初始化:初始化待求解问题的可能解,这里待求解问题的可能解分别为rbf神经网络的径向基函数的中心、宽度以及隐层到输出层的权值,随机初始化n个cplant食肉植物和n个prey猎物个体,位置表示如下:
[0026][0027]
其中,d为变量个数,n为ncplant和nprey总和,每个个体使用下式随机初始化:
[0028]
individual
i,j
=lbj+(ub
j-lbj)
×
rand
[0029]
其中,lb和ub分别为自变量的最小值和最大值,i∈[1,2,...,n],j∈[1,2,...,d],rand为[0,1]之间的随机数;
[0030]
对于第i个个体,通过将每一行作为适应度函数的输入来评估适应度值,计算得到的适应度值存在如下矩阵中:
[0031][0032]
2)分类与分组:每个个体按照其适应度值升序排序,排在前面的n个cplant食肉植物作为食肉植物cp,剩余的nprey作为猎物prey,排序后的适应度值和种群通过下列两式表示:
[0033][0034][0035]
分组的过程模拟每个肉食植物以及猎物的环境,将适合度最高的猎物分配给排名第一的食肉植物,类似地,第二名和第三名猎物属于第二和第三肉食植物;以此类推,直到排名ncplant的猎物分配给第ncplant的肉食植物,然后在猎物多余的情况下,ncplant+1名猎物分配给第一名肉食植物;
[0036]
3)成长:每一个种群都随机选择一个猎物,如果吸引率高于随机生成的数字,食肉植物就会捕获猎物并消化生长,食肉植物成长模型为:
[0037]
newcp
i,j
=growth
×
cp
i,j
+(1-growth)
×
prey
v,j
[0038]
growth=growth_rate
×
rand
i,j
[0039]
其中,cp
i,j
是排名第i的食肉植物,prey
v,j
为随机选择的猎物,成长率growth_rate为预定义的值,rand为[0,1]之间的随机数,每一个种群内部只有一个食肉植物,而猎物的数量必须多于两个,如果吸引率低于产生的随机值,则猎物逃跑并成长,表示为:
[0040]
newprey
i,j
=growth
×
prey
u,j
+(1-growth)
×
prey
v,j
,u≠v
[0041][0042]
其中,prey
u,j
是第i个种群中随机选择的另一个猎物;食肉植物和猎物生长过程持续到group_iter代(预定义值),且两式将新的解向高质量解空间方向指导;
[0043]
4)繁殖:排名第一的食肉植物,才允许繁殖,最优食肉植物繁殖过程如下:
[0044]
newcp
i,j
=cp
1,j
+reproduction_rate
×
rand
i,j
×
mate
i,j
[0045][0046]
其中,cp
1,j
为最优解,cp
v,j
为随机选择的食肉植物,繁殖率reproduction_rate是预定义的值,繁殖过程重复ncplant次,繁殖过程中,每个维度j都随机选择一个食肉植物v;
[0047]
5)适应度更新和合并:将新生成的食肉植物和猎物和之前的种群合并,得到新的维度种群,按照适应度值升序排序,选择排名前n的个体作为新的候选解,保准种群大小不变;
[0048]
6)重复1)到4)过程,每一次重复的结果作为rbf神经网络的最优三参数,直到满足停止准则。
[0049]
进一步地,通过rs粗糙集对a
1-a
24
属性约简时,所抽取的数据量大于24。
[0050]
有益效果:
[0051]
1、本发明通过rs粗糙集挖掘输入影响因子和数据特征,结合遗传算法对数据进行属性约简,减少由于电子干扰和环境等不确定因素对系统的影响,将cpa算法用于rbf神经网络参数的优化,进而得到网络模型的最优参数,最后构建网络模型。该方法很大程度减低了不确定数据对数据融合的影响,简化输入特征,提高对稻虾水质预测的抗干扰性和准确性,具有一定的推广和应用价值。
[0052]
2、本发明使用rbf神经网络模型进行稻虾水质预测,其具有局部逼近特点以及训练速度快,可以较好的解决实时性应用,为水质预测提供了实效性,同时将全局优化特点明显的cpa算法应用于rbf神经网络三参数(径向基函数的中心、宽度以及隐层到输出层的权值)的优化,优化的模型极大的提高了准确度。
附图说明
[0053]
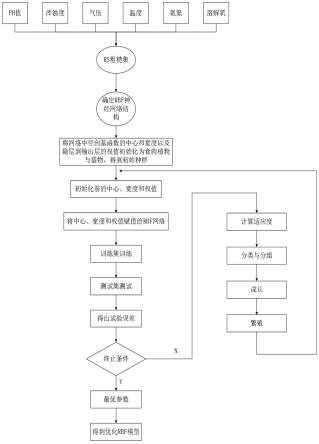
图1为本发明基于rs粗糙集和cpa算法的稻虾水质预测方法流程图;
[0054]
图2为本发明稻虾水质数据的最小约简mse;
[0055]
图3为本发明的模型误差对比图。
具体实施方式
[0056]
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
[0057]
如图1所示,本发明公开了一种基于rs粗糙集和cpa算法的稻虾水质预测方法,包括以下步骤:
[0058]
步骤1:对稻虾水域随机两块区域进行测量溶解氧、高锰酸钾、化学需氧量、氨氮、
生化需氧、总氮六项指标,各区域每次重复测量一组,一天测量多次,分别记为a
1-a
12
和a
13-a
24
,a
1-a
12
为两组六参数水质指标,a
1-a
12
为同一块区域,a
13-a
24
为另一块区域两组六参数水质指标。为了说明算法的有效性和准确性,下面以江苏淮安盱眙某稻虾养殖基地所采集的水质数据为例,建立预测模型。
[0059]
步骤2:对测量的水质数据预处理,将数据归一化以文本的形式存储,将数据转换至0-1之间。
[0060]
步骤3:根据稻虾对不同水质的生存情况,将指标划分等级,指标划分为:i(优)、ii(良)、iii(差)三个等级。
[0061]
步骤4:通过rs粗糙集对a
1-a
24
(6个指标)属性约简,找出最简几组最简属性集。
[0062]
约简按照以下步骤进行:
[0063]
1)将预处理之后的传感器水质数据按照各个属性对应的区间进行划分,并进行编号,获得试验数据决策表;
[0064]
2)通过遗传算法,对试验数据决策表进行约简;
[0065]
3)根据公式γc(d)=|posc(d)|/|u|,计算出决策属性d({d1,d2,d3,
…di
})对条件属性c({c1,c2,c3,
…cj
})的依赖度γc(d),其中,d1,d2,d3,
…di
表示所有决策属性集合,c1,c2,c3,
…cj
表示所有条件属性集合,d表示决策属性,u表示论域;
[0066]
4)定义reduct(c)=c-{cj}为条件属性c的约简集,将条件属性cj逐个去除,比较γ
reduct(c)
(d)与γc(d)的大小,若γ
reduct(c)
(d)=γc(d),则终止运算;若不等,将执行步骤1);
[0067]
5)使用染色体编码方法,根据公式其中,x表示对象子集,x表示对象,u表示论域,将每个条件属性对每个个体编码,通过二进制字符串[0,1]的形式。若条件属性属于本个体,就表示为1;否则表示0;从而得到个体适应度f(r)值。
[0068]
f(r)=(l-l
τ
)/l+γc(d)
[0069]
其中,编码1的染色体个数为l
τ
,条件属性个数为l;初始种群由pop_size的长度为|c|的二进制个体构成,且pop_size=2
|c|
;
[0070]
6)计算下一代种群个体的适应度值,通过轮盘赌法从中选择,使用交叉概率pc来表示交叉点处染色体交叉概率,某个等位属性编码值反转概率用pm表示,也就是变异概率;
[0071]
7)选择最优个体,将它代入下一代种群,观察适应度,若不再变化或迭代步数到最大值,将最优个体输出,否则跳转执行6)。最后得到如表1所示的数据约简集:
[0072]
表1
[0073][0074]
步骤5:将几组最简属性集代入rbf神经网络模型求mse,融合结果取1-3表示稻虾水质等级,比较得出一组最优属性集,得到如图2所示数据约简集mse。并将一组最优属性集的属性分为训练集和测试集。
[0075]
步骤6:确定rbf神经网络的拓扑结构,将rbf神经网络的径向基函数的中心、宽度
以及隐层到输出层的权值作为cpa算法的初始种群,利用cpa算法优化后得到最优的中心、宽度和权值,步骤如下:
[0076]
1)初始化:初始化待求解问题的可能解,这里待求解问题的可能解分别为rbf神经网络的径向基函数的中心、宽度以及隐层到输出层的权值,随机初始化n个cplant食肉植物和n个prey猎物个体,位置表示如下:
[0077][0078]
其中,d为变量个数,n为ncplant和nprey总和,每个个体使用下式随机初始化:
[0079]
individual
i,j
=lbj+(ub
j-lbj)
×
rand
[0080]
其中,lb和ub分别为自变量的最小值和最大值,i∈[1,2,...,n],j∈[1,2,...,d],rand为[0,1]之间的随机数。
[0081]
对于第i个个体,通过将每一行作为适应度函数(取均方误差作为适应度函数)的输入来评估适应度值,计算得到的适应度值存在如下矩阵中:
[0082][0083]
2)分类与分组:每个个体按照其适应度值升序排序,排在前面的n个cplant食肉植物作为食肉植物cp,剩余的nprey作为猎物prey,排序后的适应度值和种群通过下列两式表示:
[0084]
[0085][0086]
分组的过程模拟每个肉食植物以及猎物的环境,将适合度最高的猎物分配给排名第一的食肉植物,类似地,第二名和第三名猎物属于第二和第三肉食植物。以此类推,直到排名ncplant的猎物分配给第ncplant的肉食植物,然后ncplant+1名猎物分配给第一名肉食植物(在猎物多余的情况下)。
[0087]
3)成长:每一个种群都随机选择一个猎物,如果吸引率高于随机生成的数字,食肉植物就会捕获猎物并消化生长。食肉植物成长模型为:
[0088]
newcp
i,j
=growth
×
cp
i,j
+(1-growth)
×
prey
v,j
[0089]
growth=growth_rate
×
rand
i,j
[0090]
其中,cp
i,j
是排名第i的食肉植物,prey
v,j
为随机选择的猎物,成长率growth_rate为预定义的值,rand为[0,1]之间的随机数。在cpa中,每一个种群内部只有一个食肉植物,而猎物的数量必须多于两个,cpa的吸引率一般设置为0.8.
[0091]
如果吸引率低于产生的随机值,则猎物逃跑并成长,表示为:
[0092]
newprey
i,j
=growth
×
prey
u,i
+(1-growth)
×
prey
v,j
,u≠v
[0093][0094]
其中,prey
u,j
是第i个种群中随机选择的另一个猎物。食肉植物和猎物生长过程持续到group_iter代(预定义值),且两式将新的解向高质量解空间方向指导。
[0095]
4)繁殖:排名第一的食肉植物(种群最好的解),才允许繁殖。最优食肉植物繁殖过程如下:
[0096]
newcp
i,j
=cp
1,j
+re production_rate
×
rand
i,j
×
mate
i,j
[0097][0098]
其中,cp
1,j
为最优解,cp
v,j
为随机选择的食肉植物,繁殖率re production_rate是预定义的值。繁殖过程重复ncplant次,繁殖过程中,每个维度j都随机选择一个食肉植物v。
[0099]
5)适应度更新和合并:将新生成的食肉植物和猎物和之前的种群合并,得到新的维度种群,按照适应度值升序排序,选择排名前n的个体作为新的候选解,保准种群大小不变。
[0100]
6)重复1)到4)过程,每一次重复的结果作为rbf网络的最优三参数,直到满足停止准则(预设定)。
[0101]
经过上述步骤,得出优化rbf网络模型,利用该优化rbf网络模型去预测虾稻水质。
[0102]
如图3所示模型试验对比图,本发明分别以rbf神经神经网络模型、rs-rbf神经网络模型以及本发明优化模型进行试验对比,发现本发明优化模型的试验误差最小,其在进行水质预测时,精确度、准确度会更高。
[0103]
上述实施方式只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明精神实质所做的等效变换或修饰,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1