目标跟踪方法、装置、计算机设备和存储介质与流程
本技术涉及信息与通信,特别是涉及一种目标跟踪方法、装置、计算机设备和存储介质。
背景技术:
1、在机器人对环境的感知中,最重要的是对行人的三维感知,其中三维感知包括位置和速度。不同于二维视觉检测,基于三维的目标检测可用于空间路径规划,用于机器人的导航与避障。但是三维目标检测具有更大的挑战性,需要更多的输出参数来指定目标周围面向三维空间的边界框。现有的三维目标检测算法根据传感器不同,大致可以分为视觉、激光点云和多模态融合三类。视觉方法由于其成本低、纹理特征丰富等优势,在目标检测领域中被广泛使用,激光点云数据具有准确的深度信息,并且具有明显的三维空间特征,也被广泛应用于三维目标检测中。但是,激光雷达等方法的输入数据分辨率通常低于图像,这使得对于较远距离的目标检测精度不高。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种机器人,机器人上搭载有激光雷达和视觉传感器,所述机器人包括存储器和处理器,所述存储器中存储有可执行程序代码,所述处理器执行所述可执行程序代码时能够实现稳定准确的目标跟踪。
2、第一方面,本技术提供的机器人上的处理器执行所述可执行程序代码时用于实现以下步骤:
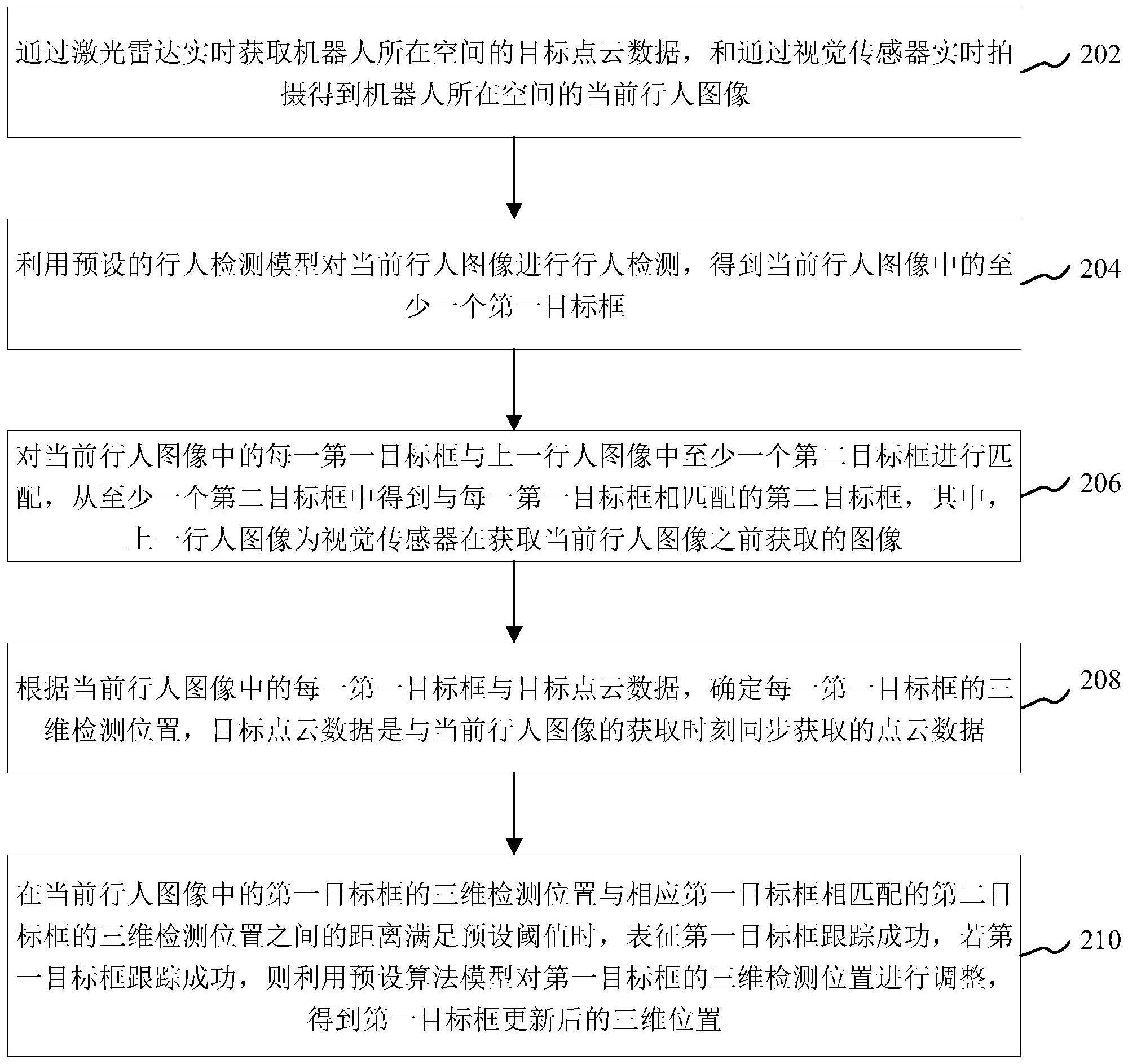
3、通过激光雷达实时获取机器人所在空间的目标点云数据,和通过视觉传感器实时拍摄得到机器人所在空间的当前行人图像;
4、利用预设的行人检测模型对当前行人图像进行行人检测,得到当前行人图像中的至少一个第一目标框;
5、对当前行人图像中的每一第一目标框与上一行人图像中至少一个第二目标框进行匹配,从至少一个第二目标框中得到与每一第一目标框相匹配的第二目标框,其中,上一行人图像为视觉传感器在获取当前行人图像之前获取的图像;
6、根据当前行人图像中的每一第一目标框与目标点云数据,确定每一第一目标框的三维检测位置,目标点云数据是与当前行人图像的获取时刻同步获取的点云数据;
7、在当前行人图像中的第一目标框的三维检测位置与相应第一目标框相匹配的第二目标框的三维检测位置之间的距离满足预设阈值时,表征第一目标框跟踪成功,若第一目标框跟踪成功,则利用预设算法模型对第一目标框的三维检测位置进行调整,得到第一目标框更新后的三维位置。
8、在其中一个实施例中,通过激光雷达实时获取机器人所在空间的目标点云数据,包括:
9、通过激光雷达实时获取机器人所在空间的当前多个第一数据;
10、对当前多个第一数据中每个第一数据进行坐标转换,得到当前多个第一数据中每个第一数据坐标转换后对应的第一目标点;
11、利用直线检测算法模型对多个第一目标点进行直线过滤检测,得到多个第二目标点;
12、对多个第二目标点进行聚类,得到多个第一目标类;
13、确定多个第一目标类中每个第一目标类中点的数量是否在预设范围内,将多个第一目标类中点的数量在预设范围内的第一目标类确定为第二目标类;
14、将所有第二目标类中各个点组成的集合确定为所述目标点云数据。
15、在其中一个实施例中,对当前行人图像中的每一第一目标框与上一行人图像中至少一个第二目标框进行匹配,从至少一个第二目标框中得到与每一第一目标框相匹配的第二目标框,包括:
16、对上一行人图像中至少一个第二目标框中每个第二目标框进行预测,得到上一行人图像中至少一个第二目标框中每个第二目标框对应的预测目标框;
17、将当前行人图像中的每一第一目标框与上一行人图像中至少一个第二目标框中每个第二目标框对应的预测目标框进行匹配,从上一行人图像中至少一个第二目标框对应的多个预测目标框中确定当前行人图像中的每一第一目标框对应的预测目标框;
18、根据当前行人图像中的每一第一目标框对应的预测目标框,从至少一个第二目标框中得到与每一第一目标框相匹配的第二目标框。
19、在其中一个实施例中,将当前行人图像中的每一第一目标框与上一行人图像中至少一个第二目标框中每个第二目标框对应的预测目标框进行匹配,从上一行人图像中至少一个第二目标框对应的多个预测目标框中确定当前行人图像中的每一第一目标框对应的预测目标框,包括:
20、计算当前行人图像中的每一第一目标框与上一行人图像中至少一个第二目标框中每个第二目标框对应的预测目标框之间的交并比,得到当前行人图像中的每一第一目标框的多个交并比值;
21、将当前行人图像中的每一第一目标框的多个交并比值中最小交并比值对应的预测目标框作为当前行人图像中的每一第一目标框对应的预测目标框。
22、在其中一个实施例中,上一行人图像与当前目标行人图像之间存在若干帧行人图像;相应地,对当前行人图像中的每一第一目标框与上一行人图像中至少一个第二目标框进行匹配,从至少一个第二目标框中得到与每一第一目标框相匹配的第二目标框,包括:
23、将上一行人图像、当前目标行人图像及若干帧行人图像,作为一组匹配图像;
24、将一组匹配图像中每相邻两帧行人图像中的目标框进行匹配,得到一组匹配图像中每相邻两帧行人图像中相匹配的目标框;
25、根据一组匹配图像中每相邻两帧行人图像中相匹配的目标框,确定至少一个第二目标框中与每一第一目标框相匹配的第二目标框。
26、在其中一个实施例中,将一组匹配图像中每相邻两帧行人图像中的目标框进行匹配,得到一组匹配图像中每相邻两帧行人图像中相匹配的目标框,包括:
27、将一组匹配图像中任意相邻两帧匹配图像中最早拍摄时刻的图像做第一匹配图像,将一组匹配图像中与第一匹配图像为相邻帧且拍摄时刻较第一匹配图像更晚的匹配图像作为第二匹配图像;
28、利用第一算法模型对第一匹配图像中任一目标框在第二匹配图像中的位置进行预测,得到第一匹配图像中任一目标框在第二匹配图像中的预测目标框;
29、利用第二预设算法对第二匹配图像中任一目标框与第一匹配图像中任一目标框在第二匹配图像中的预测目标框进行匹配,得到在第一匹配图像的预测目标框中与第二匹配图像中任一目标框相匹配的预测目标框;
30、根据第一匹配图像对应的预测目标框与第二匹配图像中目标框的对应关系,得到在第一匹配图像中和第二匹配图像中相匹配的目标框。
31、在其中一个实施例中,根据当前行人图像中的每一第一目标框与目标点云数据,确定每一第一目标框的三维检测位置,包括:
32、将目标点云数据中的各个点投影至当前行人图像中;
33、根据当前行人图像中每一第一目标框在当前行人图像中的位置,和目标点云数据中的各个点投影至目标行人图像中的位置,得到目标点云数据中属于当前目标行人图像中每一第一目标框的目标点;
34、根据目标点云数据中属于当前行人图像中每一第一目标框的点的三维坐标,得到当前目标行人图像中每一第一目标框的三维检测位置。
35、第二方面,本技术提供一种目标跟踪方法,方法包括:
36、通过激光雷达实时获取机器人所在空间的目标点云数据,和通过视觉传感器实时拍摄得到机器人所在空间的当前行人图像;
37、利用预设的行人检测模型对当前行人图像进行行人检测,得到当前行人图像中的至少一个第一目标框;
38、对当前行人图像中的每一第一目标框与上一行人图像中至少一个第二目标框进行匹配,从至少一个第二目标框中得到与每一第一目标框相匹配的第二目标框,其中,上一行人图像为视觉传感器在获取当前行人图像之前获取的图像;
39、根据当前行人图像中的每一第一目标框与目标点云数据,确定每一第一目标框的三维检测位置,目标点云数据是与当前行人图像的获取时刻同步获取的点云数据;
40、在当前行人图像中的第一目标框的三维检测位置与相应第一目标框相匹配的第二目标框的三维位置之间的距离满足预设阈值时,表征第一目标框跟踪成功,若第一目标框跟踪成功,利用预设算法模型对第一目标框的三维检测位置进行调整,得到第一目标框更新后的三维位置。
41、在其中一个实施例中,通过激光雷达实时获取机器人所在空间的目标点云数据,包括:
42、通过激光雷达实时获取机器人所在空间的当前多个第一数据;
43、对当前多个第一数据中每个第一数据进行坐标转换,得到当前多个第一数据中每个第一数据坐标转换后对应的第一目标点;
44、利用直线检测算法模型对多个第一目标点进行直线过滤检测,得到多个第二目标点;
45、对多个第二目标点进行聚类,得到多个第一目标类;
46、确定多个第一目标类中每个第一目标类中点的数量是否在预设范围内,将多个第一目标类中点的数量在预设范围内的第一目标类确定为第二目标类;
47、将所有第二目标类中各个点组成的集合确定为目标点云数据。
48、第三方面,本技术还提供了一种计算机可读存储介质。计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现以下步骤:
49、通过激光雷达实时获取机器人所在空间的目标点云数据,和通过视觉传感器实时拍摄得到机器人所在空间的当前行人图像;
50、利用预设的行人检测模型对当前行人图像进行行人检测,得到当前行人图像中的至少一个第一目标框;
51、对当前行人图像中的每一第一目标框与上一行人图像中至少一个第二目标框进行匹配,从至少一个第二目标框中得到与每一第一目标框相匹配的第二目标框,其中,上一行人图像为视觉传感器在获取当前行人图像之前获取的图像;
52、根据当前行人图像中的每一第一目标框与目标点云数据,确定每一第一目标框的三维检测位置,目标点云数据是与当前行人图像的获取时刻同步获取的点云数据;
53、在当前行人图像中的第一目标框的三维检测位置与相应第一目标框相匹配的第二目标框的三维检测位置之间的距离满足预设阈值时,表征第一目标框跟踪成功,若第一目标框跟踪成功,则利用预设算法模型对第一目标框的三维检测位置进行调整,得到第一目标框更新后的三维位置。
54、上述机器人和目标跟踪方法、计算机设备和存储介质,通过激光雷达实时获取机器人所在空间的目标点云数据,和通过视觉传感器实时拍摄得到机器人所在空间的当前行人图像;利用预设的行人检测模型对当前行人图像进行行人检测,得到当前行人图像中的至少一个第一目标框;对当前行人图像中的每一第一目标框与上一行人图像中至少一个第二目标框进行匹配,从至少一个第二目标框中得到与每一第一目标框相匹配的第二目标框,其中,上一行人图像为视觉传感器在获取当前行人图像之前获取图像;根据当前行人图像中的每一第一目标框与目标点云数据,确定每一第一目标框的三维检测位置,目标点云数据是与当前行人图像的获取时刻同步获取的点云数据;在当前行人图像中的第一目标框的三维检测位置与相应第一目标框相匹配的第二目标框的三维检测位置之间的距离满足预设阈值时,表征第一目标框跟踪成功,若第一目标框跟踪成功,则利用预设算法模型对第一目标框的三维检测位置进行调整,得到第一目标框更新后的三维位置。通过解耦2d和3d的卡尔曼滤波器,利用激光雷达和视觉传感器数据获取目标行人的3d信息,利用视觉传感器数据获取目标行人的2d检测框信息,充分利用全部数据对目标行人进行跟踪,提高了检测结果的准确性。
- 还没有人留言评论。精彩留言会获得点赞!