基于任务选择过程强化学习的大数据作业调度方法与流程
1.本发明涉及一种基于任务选择过程强化学习的大数据作业调度方法,属于人工智能领域。
背景技术:
2.大数据应用就是对数据价值的利用,即通过数据分析从海量数据中挖掘有效信息,为用户提供决策支持。如何对这些数据进行高效处理成为关键,而数据处理中各个任务之间的的调度对整体的性能和资源的利用有着重大意义。
3.在工作流中,任务节点之间的依赖关系随节点数增多而变得更加复杂。然而,传统的启发式算法不能很好地对任务节点间复杂的依赖关系进行处理,只能通过人为的特征工程构造特征值对其进行处理,人为影响很大。图卷积神经网络可以自主学习任务节点特征,深入挖掘拓扑结构中关系,避免了人为干扰。因此,将图卷积神经网络用于工作流调度问题中的任务依赖关系处理从而提升算法调度效果成为了研究的热点方向。
4.目前,基于图卷积神经网络的既有方法仅能针对特定类型的大数据作业(运行在hadoop计算集群)进行调度和执行,不能对调度的任务执行动态参数调整来优化调度过程,存在较大的局限性。
技术实现要素:
5.本发明的目的是解决上述背景技术中提及的缺陷,用于在动态的工作流环境完成大数据作业的调度,且提高作业整体的完成效率。
6.为实现上述发明目的,本发明提供一种基于任务选择过程强化学习的大数据作业调度方法,包括如下步骤:s1对集群中作业向量化处理:若作业集合未完成,将嵌入向量输入到强化学习模块中进行决策;进行调度的决策网络在全连接层处理完成后,对各个任务节点进行差异化值再处理过程;最终,强化学习模块的智能体通过设置softmax层选择下一个被调度的任务节点;s2对于被选择的任务节点,智能体确定调度其多少个任务实例;对应的决策网络,在全连接层处理完后和softmax层,降低无法被调度的作业被选中的概率,根据被选择的任务节点的最高概率的任务执行器数量作为具体调度的任务实例数;s3对选择的任务节点,资源匹配模块选定资源最匹配的任务执行器种类,然后从该任务执行器种类中选择空闲的任务执行器来准备执行当前被调度的任务实例;s4在大数据任务执行平台部署调度的任务实例并执行:当前批次的作业子集执行结束后,根据这一轮调度的整体调度时间来量化动作的奖励值;如果智能体的决策提升了调度效果,那么智能体将会获得一个正向的奖励值,并增大之后选择该决策的概率;反之,智能体会获得一个反向的奖励值,并减小之后选择该决策的概率。
7.进一步地,所述步骤s1包括:s11使用图卷积神经网络来对图进行转化操作,处理完后的嵌入向量分成节点级别、作业级别以及全局级别三类;s12嵌入向量在决策网络的最后一个全连接层处理后,判断各个任务节点是否可以被调度。若无法调度,则减少任务节点
对应的向量值;否则维持不变;s13最终,决策网络会设置softmax层来做进一步处理,选择出下一个被调度的任务节点。
8.进一步地,所述步骤s2包括:s21判断被选择的任务节点所在的作业是否可选择,如果任务节点所在的作业无法被选择,那么在决策网络全连接层处理后,将该作业所对应的值减少;否则维持不变;s22决策网络通过softmax层的进一步处理来降低无法被调度的作业被选中的概率;s23根据被选择的任务节点所在的作业,计算出矩阵中对应的行向量,并选择该行向量中最高概率的任务执行器数量作为具体调度的任务实例数。
9.进一步地,所述步骤s3包括:s31当智能体确定好下一个被调度的任务节点时,资源匹配模块计算该任务节点和任务执行器种类的匹配值,并且选定最大匹配值所对应的任务执行器种类;s32资源匹配模块从选定的任务执行器种类中选择空闲的任务执行器来准备执行当前被调度的任务实例。
10.进一步地,所述步骤s4包括:s41当智能体确定好下一个被调度的任务节点和对应的任务节点实例后,资源匹配模块选择的任务执行器将在大数据作业集群中对给定的任务实例进行执行;s42当前调度周期结束后,以作业的整体调度时间作为自变量,利用奖励函数获得相应的奖励值;智能体利用正向或反向的奖励值反馈,进行不断学习,从而探索出一系列最佳动作,以最大化累计奖励期望值。
11.与现有技术相比,本发明的有益效果为:
12.适应性较强,对于不同类型的大数据作业,如mapreduce、spark等,具有通用性。
附图说明
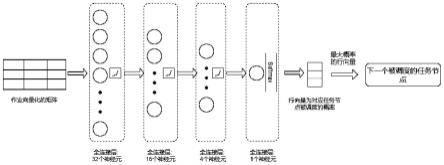
13.图1是本发明一个实施例的任务节点调度的决策网络结构图;
14.图2是本发明一个实施例的资源匹配模块决策结构图。
具体实施方式
15.下面结合附图和具体实施例,对本发明的技术方案做进一步说明。
16.如图1和图2所示,本发明的一个实施例,步骤1、对集群中作业向量化处理。若作业集合未完成,将嵌入向量输入到强化学习模块中进行决策。进行调度的决策网络,在全连接层处理完成后,对各个任务节点进行差异化值再处理过程。最终,强化学习模块的智能体通过设置softmax层选择下一个被调度的任务节点。
17.使用图卷积神经网络来对图进行转化操作,处理完后的嵌入向量分成节点级别、作业级别以及全局级别三类。
18.任务节点级别包含:任务节点vi中每个任务实例的执行时间duri;任务节点vi的总任务实例数insti;任务节点vi的剩余任务实例数resti;任务节点vi的优先级ranki;任务节点vi的每个任务实例对于cpu核数的要求corei;任务节点vi的每个任务实例对于内存大小的要求memi。作业级别包含:当前作业n已经占用的任务执行器总数used_num_execn,当前全局剩余空闲任务执行器数量gl_rest_num_exec。全局级别是在作业级别的基础上,使用相同的计算公式计算多个作业级别的嵌入向量计算得出的。
19.选择下一个被调度任务节点的决策网络由4个全连接层和3个leaky relu激活函数组成。4个全连接层分别包含32、16、4、1个神经元。
20.对任务节点维护的值,包括剩余实例数rest_num_inst、剩余执行时间rest_exec_time,它们会随着智能体不断执行调度操作而发生变化。两者使用二维向量表示如下:
21.(rest_num_inst,rest_exec_time)
22.公式中的rest_num_inst由任务节点的总实例数减去调度算法所维护的各个任务节点已经执行完成的任务实例数得出,rest_exec_time由rest_num_inst与任务实例所需执行时间dur相乘得出。
23.嵌入向量在决策网络的最后一个全连接层处理后,判断各个任务节点是否可以被调度。若无法调度,那么在全连接层处理完后的矩阵中,该节点所对应的值会被减去1e
10
。如果任务节点可以被调度,则维持原状。
24.该决策网络计算出来的矩阵维度为[total_num_task_nodes,1],在该矩阵中,每一个作业中的每一个任务节点都有对应值。该值表示任务节点被选择进行调度的概率。
[0025]
最终,决策网络会设置softmax层来做进一步处理,选择出下一个被调度的任务节点。
[0026]
在一个具体实例中:假设有10个任务节点,决策网络最终计算的结果矩阵为如下:
[0027][0028]
在对应概率最大的第8个任务节点(其概率是0.5723)被选择。
[0029]
图1为根据本发明一个实施例的任务节点调度的决策网络结构图。
[0030]
步骤2、进一步地,对于被选择的任务节点,智能体确定调度其多少个任务实例。对应的决策网络,在全连接层处理完后和softmax层,降低无法被调度的作业被选中的概率,根据被选择的任务节点的最高概率的任务执行器数量作为具体调度的任务实例数。
[0031]
判断被选择的任务节点所在的作业是否可选择。如果任务节点所在的作业无法被选择,那么在决策网络全连接层处理后,将该作业所对应的值减少;否则维持不变。
[0032]
智能体对作业维护的信息包括,作业所使用的任务执行器总数used_num_exec、全局剩余空闲任务执行器数量gl_rest_num_exec,使用二维向量来保存这些信息。具体内容表示如下:
[0033]
(used_num_exec,gl_rest_num_exec)
[0034]
而任务执行器的状态信息需要包含当前每一种任务执行器的剩余数量情况,使用向量表示如下:
[0035]
(free_num_exec_type1,free_num_exec_type2,...,free_num_exec_typek)作业的全局剩余空闲任务执行器数量gl_rest_num_exec的计算公式如下所示:
[0036][0037]
如上述公式所示,全局剩余任务执行器数量为所有维度的剩余空闲任务执行器数量之和。
[0038]
进行作业选择判断的决策网络也是由4个全连接层和3个leaky relu激活函数构成。全连接层分别包含32、16、4、1个神经元。如果任务节点所在的作业无法被选择,那么在全连接层处理后的矩阵中,该作业所对应的值会被减去1e
10
,如果作业可以被选择,则维持原状。作业无法被选择的原因要么是作业已经执行完成,要么是全局剩余任务执行器数量gl_rest_num_exec为0。
[0039]
最终决策网络通过softmax层的进一步处理来降低无法被调度的作业被选中的概率。
[0040]
该决策网络的计算结果经过形状重建后的维度变为[total_num_jobs,total_num_exec]。在该矩阵中,每个作业都有相应的行向量,行向量中的维度表示还能为该作业分配多少任务执行器,对应的值表示分配该数量任务执行器的概率。由于智能体最终需要确定当前被选择的任务节点中具体调度的任务实例数,所以调度算法需要根据被选择的任务节点所在的作业计算出矩阵中对应的行向量,并选择该行向量中最高概率的任务执行器数量作为具体调度的任务实例数。
[0041]
在一个具体实例中,假设步骤1选择的任务节点为x,对应作业的任务执行器行向量为
[0042]
(4,3,2,5,1)
[0043]
对应的概率行向量是
[0044]
(0.35,0.12,0.27,0.15,0.11)
[0045]
在对应概率最大的任务执行器数量是4(其概率是0.35)被选择,也就是将会有4个任务执行器去执行任务节点x对应的作业。
[0046]
步骤3、对选择的任务节点,资源匹配模块选定资源最匹配的任务执行器种类。然后从该任务执行器种类中选择空闲的任务执行器来准备执行当前被调度的任务实例。
[0047]
当智能体确定好下一个被调度的任务节点时,资源匹配模块计算该任务节点和任务执行器种类的匹配值,并且选定最大匹配值所对应的任务执行器种类。
[0048]
任务实例对于资源的需求分为cpu和内存两部分。调度算法需要明确整体作业是侧重于优先满足cpu还是优先满足内存。如果cpu资源较为紧张,那么应当优先满足cpu,反之则优先满足内存。
[0049]
使用权重系数α来量化上述侧重点,α为优先满足cpu的权重,1-α即为优先满足内存的权重。其计算公式如下所示:
[0050][0051]
[0052][0053]
公式中的c(
·
)方法用于计算任务节点对于cpu核数的要求或者任务执行器本身的cpu核数配置,v表示所有作业中的所有任务节点集合,e表示所有任务执行器的种类,n(e)表示e类任务执行器的数量。公式中的m(
·
)方法用于计算任务节点对于内存大小的要求或者任务执行器本身的内存配置。
[0054]
当智能体确定好下一个被调度的任务节点v时,资源匹配模块将计算该任务节点和任务执行器种类e的匹配值score
v,e
:
[0055][0056]
资源匹配模块为任务节点v选定的是最大匹配值所对应的任务执行器种类即:
[0057][0058]
进一步地,资源匹配模块从选定的任务执行器种类中选择空闲的任务准备执行器来执行当前被调度的任务实例。
[0059]
图2为本发明一个实施例的资源匹配模块决策结构图。
[0060]
步骤4、在大数据任务执行平台部署调度的任务实例并执行。当前批次的作业子集执行结束后,根据这一轮调度的整体调度时间来量化动作的奖励值。如果智能体的决策提升了调度效果,那么智能体将会获得一个正向的奖励值,并增大之后选择该决策的概率;反之,智能体会获得一个反向的奖励值,并减小之后选择该决策的概率。
[0061]
当智能体确定好下一个被调度的任务节点和对应的任务节点实例后,资源匹配模块选择的任务执行器将在大数据作业集群中对给定的任务实例进行执行。
[0062]
当前调度周期结束后,以作业的整体调度时间作为自变量,利用奖励函数获得相应的奖励值。智能体利用正向或反向的奖励值反馈,进行不断学习,从而探索出一系列最佳动作,以最大化累计奖励期望值。
[0063]
一旦执行完所有设定的动作后,环境便会更新全局时间点为gtime。记先前的全局时间点为prev_gtime,初始的全局时间点为0。奖励函数设计如下:
[0064]
r=-(gtime-prev_gtime)*r_s
[0065]
公式中的r_s是超参数。
[0066][0067]
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1