基于局部电容电荷共享的SRAM存算一体芯片
基于局部电容电荷共享的sram存算一体芯片
技术领域
1.本发明涉及集成电路设计技术领域,尤其涉及一种基于局部电容电荷共享的sram存算一体芯片。
背景技术:
2.存内计算(compute-in-memory,cim)技术,是指把传统以计算为中心的架构转变为以数据为中心的架构,其直接利用存储器进行数据处理,从而把数据存储与计算融合在同一个芯片当中,即构成存算一体芯片,可以彻底消除冯诺依曼计算架构瓶颈,降低数据传输造成的额外功耗和性能损失。静态随机存取存储器(static random access memory,sram)因其高速、低功耗和高鲁棒性的特点,可被广泛用于构造存算一体芯片。
3.目前,存算一体芯片可以作为神经网络模型的乘累加运算的硬件化实现,但是现有的存算一体芯片,在模拟域中,一般采用大的额外加权电容器阵列以及模数转换器(analog-to-digital converter,adc)进行多位权重的乘法累加(multiply accumulate,mac)运算,这将造成较大的能量消耗,仅仅adc就可以覆盖几乎40%的芯片功耗。
技术实现要素:
4.本发明提供一种基于局部电容电荷共享的sram存算一体芯片,用以解决现有技术中存在的缺陷。
5.本发明提供一种基于局部电容电荷共享的sram存算一体芯片,包括:顺次连接的译码模块、按位计算模块、全局共享开关模块以及分区式模数转换模块;
6.所述译码模块用于确定输入数据;
7.所述按位计算模块包括多个位计算单元,每个所述位计算单元均用于在与运算模式下基于局部电容的电荷共享原理,将所述输入数据与按位存储的存储数据的一位数据进行乘法运算,得到所述存储数据的一位数据对应的乘法运算结果;或者,用于在异或运算模式下基于所述局部电容的电荷共享原理,将所述输入数据与按位存储的存储数据的一位数据进行异或运算,得到所述存储数据的一位数据对应的异或运算结果;
8.所述全局共享开关模块用于在所述与运算模式下将所述存储数据的各位对应的乘法运算结果进行累加,得到模拟累加结果;
9.所述分区式模数转换模块包括多个位比较单元,所述位比较单元与所述位计算单元一一对应,所有所述位比较单元用于在所述与运算模式下将所述模拟累加结果进行量化输出;每个所述位比较单元用于在所述异或运算模式下将所述存储数据的一位数据对应的异或运算结果进行量化输出。
10.根据本发明提供的一种基于局部电容电荷共享的sram存算一体芯片,所述存储数据包括神经网络中的多个4位的权重数据;
11.所述位计算单元的数量包括4的倍数个,且每4个所述位计算单元组成位计算单元组,每个所述位计算单元组用于确定每个所述权重数据的各位对应的乘法运算结果或异或
运算结果;
12.所述位比较单元包括对应位的全局位线上连接的4个比较器,所述位计算单元组对应的位比较单元组中,除最高位之外的其他位对应的所述位比较单元以及所述最高位的全局位线上的3个比较器,用于在所述与运算模式下将所述模拟累加结果进行量化输出。
13.根据本发明提供的一种基于局部电容电荷共享的sram存算一体芯片,在所述异或运算模式下,每条所述全局位线上连接的4个比较器,按序号由小到大的顺序,采用的参考电压由低至高,且分两阶段进行部分使能;
14.在所述与运算模式下,所述位比较单元组的各比较器按序号由小到大的顺序,采用的参考电压由低至高,且分两阶段进行部分使能。
15.根据本发明提供的一种基于局部电容电荷共享的sram存算一体芯片,所述全局共享开关模块包括一行全局共享开关阵列,所述全局共享开关阵列包括多个全局共享开关组,所述全局共享开关组与所述位计算单元组一一对应;
16.所述全局共享开关组中每个全局共享开关连接于对应的所述位计算单元组中相邻两个所述位计算单元之间。
17.根据本发明提供的一种基于局部电容电荷共享的sram存算一体芯片,所述位计算单元包括一列局部处理单元lpe阵列,所述lpe阵列包括多个lpe;
18.所述sram存算一体芯片还包括sram外围电路,所述多个lpe的全局位线均连接于所述sram外围电路。
19.根据本发明提供的一种基于局部电容电荷共享的sram存算一体芯片,每个lpe包括6t sram单元以及传输门开关,所述6t sram单元通过所述传输门开关与对应的全局位线连接;
20.每个lpe的局部位线之间存在寄生电容。
21.根据本发明提供的一种基于局部电容电荷共享的sram存算一体芯片,所述译码模块包括译码器阵列,所述译码器阵列中译码器与所述lpe阵列中所述6t sram单元一一对应连接;
22.所述sram存算一体芯片还包括sram控制器以及地址解码驱动,所述sram控制器分别与所述sram外围电路以及所述地址解码驱动连接。
23.根据本发明提供的一种基于局部电容电荷共享的sram存算一体芯片,所述sram存算一体芯片还包括存内计算控制器,所述存内计算控制器分别与所述译码模块、所述全局共享开关模块以及所述分区式模数转换模块连接。
24.本发明还提供一种通过上述的基于局部电容电荷共享的sram存算一体芯片实现的存内计算方法,包括:
25.在与运算模式下,基于sram存算一体芯片中按位计算模块包括的每个位计算单元,采用局部电容的电荷共享原理,将输入数据与按位存储的存储数据的一位数据进行乘法运算,得到所述存储数据的一位数据对应的乘法运算结果,并基于所述sram存算一体芯片中全局共享开关模块,将所述存储数据的各位对应的乘法运算结果进行累加,得到模拟累加结果,基于所述sram存算一体芯片中分区式模数转换模块包括的所有位比较单元,将所述模拟累加结果进行量化输出;
26.在异或运算模式下,基于每个所述位计算单元,采用所述局部电容的电荷共享原
理,将所述输入数据与所述存储数据的一位数据进行异或运算,得到所述存储数据的一位数据对应的异或运算结果,并基于所述分区式模数转换模块包括的每个所述位比较单元,将所述存储数据的一位数据对应的异或运算结果进行量化输出。
27.根据本发明提供的一种存内计算方法,还包括:
28.在所述异或运算模式下,从所述位比较单元中选取序号大于所述位比较单元中的第一序号中位数的第一类比较器进行第一阶段使能,并基于所述第一类比较器的输出结果,从所述位比较单元的各比较器中所述第一类比较器的一侧选取第二类比较器进行第二阶段使能;
29.在所述与运算模式下,从所述位比较单元组的各比较器中选取序号不等距的多个第三类比较器进行第一阶段使能,并基于所述多个第三类比较器的输出结果,从所述位比较单元组的各比较器中所述多个第三类比较器形成的区间之一选取第四类比较器进行第二阶段使能;
30.其中,序号大于所述位比较单元组中的第二序号中位数的第三类比较器的数量多于序号小于所述第二序号中位数的第三类比较器的数量。
31.本发明提供的基于局部电容电荷共享的sram存算一体芯片,包括:顺次连接的译码模块、按位计算模块、全局共享开关模块以及分区式模数转换模块,通过译码模块确定输入数据,通过按位计算模块基于局部电容的电荷共享原理,在与运算模式下实现输入数据与存储数据的乘法运算,得到乘法运算结果,在异或运算模式下实现输入数据与存储数据的异或运算,得到异或运算结果,并通过全局共享开关模块将乘法运算结果进行累加,得到模拟累加结果。最后通过分区式模数转换模块在与运算模式下将模拟累加结果进行量化输出,在异或运算模式下将异或运算结果进行量化输出。该芯片可以支持与运算模式以及异或运算模式,拓宽了应用范围。该芯片中不存在用于接收输入数据的dac结构,可以避免在芯片中出现多比特输入导致的计算的非线性和涨落现象。该芯片采用了分区式模数转换模块,以分区方式减少其中工作的比较器的数量,降低量化功耗。
附图说明
32.为了更清楚地说明本发明或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
33.图1是本发明提供的基于局部电容电荷共享的sram存算一体芯片的结构示意图之一;
34.图2是本发明提供的基于局部电容电荷共享的sram存算一体芯片中分区式模数转换模块中与位计算单元组对应的位比较单元组的结构示意图;
35.图3是本发明提供的基于局部电容电荷共享的sram存算一体芯片中lpe的结构示意图;
36.图4是本发明提供的基于局部电容电荷共享的sram存算一体芯片中xnor模式以及and11模式下lpe的配置结构图;
37.图5是本发明提供的基于局部电容电荷共享的sram存算一体芯片中and21模式下lpe的配置结构图;
38.图6是本发明提供的基于局部电容电荷共享的sram存算一体芯片中lpe运算时存储节点的波动特性示意图;
39.图7是本发明提供的基于局部电容电荷共享的sram存算一体芯片的结构示意图之二;
40.图8是本发明提供的基于局部电容电荷共享的sram存算一体芯片在and-1-4-4-64模式下的5个阶段的时序波形图;
41.图9是本发明提供的基于局部电容电荷共享的sram存算一体芯片中全局共享开关模块在实现乘法累加方案时乘法阶段结构图;
42.图10是本发明提供的基于局部电容电荷共享的sram存算一体芯片中全局共享开关模块在实现乘法累加方案时单位累加阶段结构图;
43.图11是本发明提供的基于局部电容电荷共享的sram存算一体芯片中全局共享开关模块在实现乘法累加方案时多位累加阶段结构图;
44.图12是本发明提供的基于局部电容电荷共享的sram存算一体芯片在xnor模式下从理想mac运算结果到模拟电压的传递函数示意图;
45.图13是本发明提供的基于局部电容电荷共享的sram存算一体芯片在and模式下从理想mac运算结果到模拟电压的传递函数示意图;
46.图14是本发明提供的基于局部电容电荷共享的sram存算一体芯片在mac运算中模拟电压在1.8mv左右的平均涨落示意图;
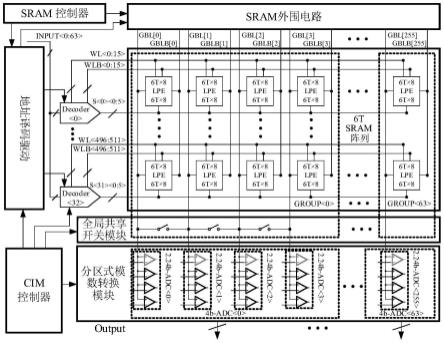
47.图15是本发明提供的基于局部电容电荷共享的sram存算一体芯片的adc的传递函数和inl示意图;
48.图16是本发明提供的存内计算方法的流程示意图。
具体实施方式
49.为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
50.深度卷积神经网络(deep convolution neural network,dcnn)在广泛的应用中实现了前所未有的增长,包括云计算和边缘计算中的人工智能(artificial intelligence,ai)。乘法累加(multiply accumulate,mac)运算具有高规律性和并行性,并在功率和延迟方面占主导地位,是dcnn中最常见的操作。对于大多数应用,ai边缘芯片需要具有多位和多模式mac运算的功能。由于冯
·
诺依曼瓶颈,传统的基于冯
·
诺依曼架构的数字ai边缘处理器在运行mac运算时容易出现过多的能耗和延迟。
51.存内计算(compute-in-memory,cim)是一种有吸引力的方法,可以通过启用并行计算、减少内存访问和中间数据来提高mac运算的能量效率,从而消除冯
·
诺依曼瓶颈。
52.早期基于静态随机存取存储器(static random access memory,sram)的cim结构是基于6t单元在电流域中计算的,这会导致由严重的电流涨落引起的潜在写入干扰和错误。然后出现了具有更大动态传感范围的时域计算和更稳健的电荷域计算的cim结构。多位输入的cim结构通常通过数模转换器(digital-to-analog converter,dac)实现,这会导致
输入出现非线性和涨落。并且在模拟域中,一般采用大的额外加权电容器阵列进行多位权重累加,造成较大的能量和面积消耗。用于mac运算的模数转换器(analog-to-digital converter,adc)覆盖了几乎40%的芯片功耗。注意到dcnn中低mac运算结果的比例很高,自适应的低mac运算结果感知adc方案和优先混合adc来提高能效的方案应运而生,二者均基于逐次逼近型adc和单斜率adc,需要进行大量比较。
53.总而言之,现有的cim结构仍然存在几个关键问题:(1)执行mac运算时的写入干扰;(2)多位输入的dac的非线性和涨落;(3)多位权重累积中过多的面积开销;(4)过多的adc功耗和面积成本。基于此,本发明实施例中提供了一种基于局部电容电荷共享的sram存算一体芯片。
54.图1为本发明实施例中提供的一种基于局部电容电荷共享的sram存算一体芯片的结构示意图,如图1所示,该芯片包括:顺次连接的译码模块1、按位计算模块2、全局共享开关模块3以及分区式模数转换模块4;
55.所述译码模块1用于确定输入数据;
56.所述按位计算模块2包括多个位计算单元21,每个所述位计算单元21均用于在与运算模式下基于局部电容的电荷共享原理,将所述输入数据与按位存储的存储数据的一位数据进行乘法运算,得到所述存储数据的一位数据对应的乘法运算结果;或者,用于在异或运算模式下基于所述局部电容的电荷共享原理,将所述输入数据与按位存储的存储数据的一位数据进行异或运算,得到所述存储数据的一位数据对应的异或运算结果;
57.所述全局共享开关模块3用于在所述与运算模式下将所述存储数据的各位对应的乘法运算结果进行累加,得到模拟累加结果;
58.所述分区式模数转换模块4包括多个位比较单元41,所述位比较单元41与所述位计算单元21一一对应,所有所述位比较单元41用于在所述与运算模式下将所述模拟累加结果进行量化输出;每个所述位比较单元41用于在所述异或运算模式下将所述存储数据的一位数据对应的异或运算结果进行量化输出。
59.具体地,本发明实施例中提供的基于局部电容电荷共享的sram存算一体芯片,采用译码模块1实现输入数据的接收和确定。该译码模块1可以包括译码器(decoder)阵列,译码器阵列中可以包括多个译码器,译码器阵列中译码器的数量可以根据需要进行设定,例如可以是32,则各译码器可以分布表示为decoder《0》、decoder《1》、
…
、decoder《31》。
60.输入数据的数量可以根据需要进行设定,例如可以是64,输入数据可以表示为input《0:63》,每个输入数据的位数可以是2位。每个输入数据均分别输入至各译码器中,通过各译码器可以得到用于输入至每个位计算单元的译码结果。
61.按位计算模块2可以包括多个位计算单元21,按位计算模块2中位计算单元21的数量可以根据需要进行设置,例如可以设置为256个,每个位计算单元21可以包括与译码器阵列中译码器数量相同的核心计算单元,译码器与核心计算单元一一对应连接。在每个核心计算单元内均可以存储有单个存储数据的对应位数据。每个核心计算单元可以包括两个核心计算子单元,每个核心计算子单元中也存储有单个存储数据的对应位数据。每个核心计算子单元可以对应于单个输入数据的一位数据计算。
62.每个核心计算单元还可以包括用于控制两个核心计算子单元工作状态的传输门开关,各传输门开关可以为cmos。传输门开关的数量可以根据需要进行设置,例如可以为7
个,此处不作具体限定。各传输门开关的工作状态可以相互独立,也可以存在工作状态相同的传输门开关,各传输门开关可以连接于两个计算子单元之间。
63.按位计算模块2中4个相邻的位计算单元可以共同实现所有输入数据与按位存储的一个4b的存储数据的计算。
64.按位计算模块2的工作模式可以包括与运算(and)模式以及异或运算(xnor)模式,与运算模式可以包括第一与运算(and11)模式以及第二与运算(and21)模式,第一与运算模式下,每个位计算单元21可以实现各输入数据的1b数据与单个存储数据的1b数据的乘法运算,此时每个位计算单元21中各核心计算单元中只有一个核心计算子单元工作;第二与运算模式下,每个位计算单元21可以实现各2b的输入数据与单个存储数据的1b数据的乘法运算,此时每个位计算单元21中各核心计算单元中两个核心计算子单元共同工作;异或运算模式下,每个位计算单元21可以实现各输入数据的1b数据与单个存储数据的1b数据的异或运算,此时每个位计算单元21中各计算单元中只有一个计算子单元工作。
65.每个核心计算单元中存在局部电容,该局部电容是每个核心计算单元的左列局部位线与右列局部位线之间的等效电容,该局部电容可以是其中两个计算子单元的共享电容。通过局部电容的电荷共享原理,每个核心计算单元可以实现连接的译码器输出的译码结果与按位存储的单个存储数据的1b数据进行相应运算。
66.也就是说,每个位计算单元21在与运算模式下基于局部电容的电荷共享原理,将输入数据与按位存储的存储数据的一位数据进行乘法运算,得到的存储数据的一位数据对应的乘法运算结果可以包括两个1b数据的乘法运算结果以及一个1b数据与一个2b数据的乘法运算结果。每个位计算单元21在异或运算模式下基于局部电容的电荷共享原理,将输入数据与按位存储的存储数据的一位数据进行异或运算,得到的存储数据的一位数据对应的异或运算结果可以包括两个1b数据的异或运算结果。
67.芯片中全局共享开关模块3可以包括一行全局共享开关阵列,该全局共享开关阵列可以包括多个全局共享开关,每个全局共享开关可以连接于按位计算模块2中相邻两个位计算单元21之间。
68.每个全局共享开关可以结合连接的位计算单元中的传输门开关,以实现与运算模式下将单个存储数据的一位数据对应的乘法运算结果进行累加,4个相邻的全局共享开关可以实现与运算模式下将单个存储数据的各位数据对应的乘法运算结果进行累加,256个相邻的全局共享开关共可以实现与运算模式下将64个存储数据的各位数据对应的乘法运算结果进行累加。最后,全局共享开关模块3可以得到并输出累加结果,该累加结果为模拟累加结果。
69.芯片中分区式模数转换模块4可以包括多个位比较单元41,每个位比较单元41可以连接于按位计算模块2中每个位计算单元21的全局位线上,即位比较单元41与位计算单元21一一对应。该全局位线可以是左列全局位线,也可以是右列全局位线,此处不作具体限定。
70.每4个位比较单元41可以在与运算模式下将每个存储数据的各位数据对应的模拟累加结果进行量化输出;每个位比较单元41可以在异或运算模式下将每个存储数据的一位数据对应的异或运算结果进行量化输出。
71.每个位比较单元41可以包括多个比较器,分区式模数转换模块4的工作原理是:在
与运算模式下,从每个位比较单元41的多个比较器中选取部分比较器进行两个阶段使能,且两个阶段使能的比较器也只是每个位比较单元41中包含的所有比较器的一部分,而非所有比较器;在异或运算模式下,从每4个位比较单元41的多个比较器中选取部分比较器进行两个阶段使能,且两个阶段使能的比较器也只是每4个位比较单元41中包含的所有比较器的一部分,而非所有比较器。每个位比较单元41中包括的比较器均可以是强臂比较器。
72.本发明实施例中提供的基于局部电容电荷共享的sram存算一体芯片,包括:顺次连接的译码模块、按位计算模块、全局共享开关模块以及分区式模数转换模块,通过译码模块确定输入数据,通过按位计算模块基于局部电容的电荷共享原理,在与运算模式下实现输入数据与存储数据的乘法运算,得到乘法运算结果,在异或运算模式下实现输入数据与存储数据的异或运算,得到异或运算结果,并通过全局共享开关模块将乘法运算结果进行累加,得到模拟累加结果。最后通过分区式模数转换模块在与运算模式下将模拟累加结果进行量化输出,在异或运算模式下将异或运算结果进行量化输出。该芯片可以支持与运算模式以及异或运算模式,拓宽了应用范围。该芯片中不存在用于接收输入数据的dac结构,可以避免在芯片中出现计算的非线性和涨落现象。该芯片采用了分区式模数转换模块,以分区方式减少其中工作的比较器的数量,降低量化时耗和功耗。
73.在上述实施例的基础上,本发明实施例中提供的基于局部电容电荷共享的sram存算一体芯片,所述存储数据包括神经网络中的多个4位的权重数据;
74.所述位计算单元的数量包括4的倍数个,且每4个所述位计算单元组成位计算单元组,每个所述位计算单元组用于确定每个所述权重数据的各位对应的乘法运算结果或异或运算结果;
75.所述位比较单元包括对应位的全局位线上连接的4个比较器,所述位计算单元组对应的位比较单元组中,除最高位之外的其他位对应的所述位比较单元以及所述最高位的全局位线上的3个比较器,用于在所述与运算模式下将所述模拟累加结果进行量化输出。
76.具体地,本发明实施例中,神经网络中通常包括大量的4位的权重数据,均可以将其作为存储数据按位存储至芯片中的位计算单元,并将其与神经网络的输入数据进行乘法累加运算或异或运算。
77.该芯片中,位计算单元的数量包括4的倍数个,例如包括256个,每4个相邻的位计算单元组成位计算单元组,每个位计算单元组用于确定每个权重数据的各位数据对应的乘法运算结果或异或运算结果。
78.图2为芯片中分区式模数转换模块4中与位计算单元组对应的位比较单元组的结构示意图,该位比较单元组包括4个位比较单元41,每个位比较单元41均包括对应位的全局位线上连接的4个比较器。每个位比较单元41包括的4个比较器可以连接在左列全局位线gbl上,也可以连接在右列全局位线gblb上,此处不做具体限定。图2中以4个比较器连接在gbl上为例,则每个位比较单元组中4个位比较单元41对应位的左列全局位线gbl分别表示为gbl《0》、gbl《1》、gbl《2》、gbl《3》,gbl《0》对应最低位,gbl《3》对应最高位。
79.图2中s_gshare分别为全局共享开关模块中连接于位计算单元组中相邻两个位计算单元之间的全局共享开关,adc_en为使能信号。图2中各比较器的反相端上侧的vref《i》表示为异或运算模式下每个位比较单元中第i个比较器的参考电压,0≤i≤3;各比较器的反相端下侧的vref《j》表示为与运算模式下4个位比较单元中第j个比较器的参考电压,0≤
j≤14。
80.从图2可以看出,在异或运算模式下,每个位比较单元中各比较器按与全局共享开关模块的距离由近到远的顺序进行标号,得到各比较器的序号分别为comp《i》;在与运算模式下,如图2中42所示,涉及的位比较单元组中各比较器按逐行递增的方式进行标号,得到各比较器的序号分别为comp《j》。由于第4个位比较单元中第4个比较器并未应用于与运算模式下,因此并非对其标号。
81.在异或运算模式下,每个位比较单元中各比较器可以将输入的模拟累加结果量化为2.24位,此时该位比较单元可以构成2.24b-adc《i》;在与运算模式下,4个位比较单元中各比较器可以将输入的模拟累加结果量化为4位,此时4个位比较单元可以构成4b-adc《k》,0≤k≤k-1,k为位计算单元组的数量,可以为64。
82.本发明实施例中,分区式模数转换模块可以在两种运算模式下实现不同尺度的量化,保证了不同运算模式下运算结果的量化输出,使芯片可以适用于不同应用需求。
83.在上述实施例的基础上,本发明实施例中提供的基于局部电容电荷共享的sram存算一体芯片,在所述异或运算模式下,每条所述全局位线上连接的4个比较器,按序号由小到大的顺序,采用的参考电压由低至高,且分两阶段进行部分使能;
84.在所述与运算模式下,所述位比较单元组的各比较器按序号由小到大的顺序,采用的参考电压由低至高,且分两阶段进行部分使能。
85.具体地,本发明实施例中,如图2所示,在异或运算模式下,每条左列全局位线gbl《i》上连接的4个比较器,序号可以通过各比较器与全局共享开关模块的距离的远近进行标号得到,距离远序号大,距离近序号小。在与运算模式下,位比较单元组中各比较器的序号可以通过按逐行递增的方式进行标号得到,每一行中序号从最低位向最高位依次增大,每一列中与全局共享开关模块的距离由近到远序号依次增大。
86.进而,每个位比较单元的4个比较器中,按序号由小到大的顺序,采用的参考电压由低至高,即在异或运算模式下,vref《0》、vref《1》、vref《2》、vref《3》依次升高;在与运算模式下,vref《0》-vref《14》依次升高。
87.此外,在每种运算模式下,涉及的各比较器均分两阶段进行部分使能。adc_en可以包括adc_en《0》和adc_en《1》,分别表示第一阶段使能信号以及第二阶段使能信号。
88.第一阶段使能可以粗略确定工作的第一类比较器,第二阶段使能时在第一阶段使能的基础上,基于第一类比较器的输出结果精确确定工作的比较器。
89.在异或运算模式下,第一阶段使能策略可以是从位比较单元中选取序号大于位比较单元中的第一序号中位数的第一类比较器进行第一阶段使能,由于位比较单元中共包括4个比较器,序号分别为0-3,则第一序号中位数为1.5,此时可以选取第三个比较器comp《2》作为第一类比较器进行第一阶段使能,使之工作。第一类比较器的输出结果可以是0或1,即out《2》=0或1。
90.在异或运算模式下,第二阶段使能策略可以是根据out《2》,从位比较单元的各比较器中第一类比较器的一侧选取第二类比较器进行第二阶段使能。当out《2》=0时,可以选取序号大于第一类比较器的比较器作为第二类比较器进行第二阶段使能,即选取comp《3》作为第二类比较器进行第二阶段使能;当out《2》=1时,可以选取序号小于第一类比较器的比较器作为第二类比较器进行第二阶段使能,即选取comp《0》和comp《1》作为第二类比较器
进行第二阶段使能。此后,第二类比较器的输出结果即作为异或运算模式下位比较单元的输出结果。
91.在与运算模式下,第一阶段使能策略可以是从位比较单元组的各比较器中选取序号不等距的多个第三类比较器进行第一阶段使能。序号不等距是指任意相邻两个第三类比较器的序号间距不同,也可以是序号越大的相邻两个第三类比较器的序号间距越小。由于位比较单元组中共包括15个比较器,序号分别为0-14,则可以选取第5个比较器comp《5》、第10个比较器comp《9》以及第13个比较器comp《12》作为第三类比较器进行第一阶段使能,使之工作。各第三类比较器的输出结果按序号由大到小的顺序组合可以得到000、100、110或111,即out=000、100、110或111。
92.在与运算模式下,第二阶段使能策略可以是根据out,从位比较单元组的各比较器中多个第三类比较器形成的区间之一选取第四类比较器进行第二阶段使能。
93.各第三类比较器形成的区间包括4个,分别为序号大于12的第一区间、序号在9和12之间的第二区间、序号在4和9之间的第三区间以及序号在小于4的第四区间。进而,当out=000时,可以选取第一区间中的comp《13》、comp《14》作为第四类比较器进行第二阶段使能;当out=100时,可以选取第二区间中的comp《10》、comp《11》作为第四类比较器进行第二阶段使能;当out=110时,可以选取第三区间中的comp《5》-comp《8》作为第四类比较器进行第二阶段使能;当out=111时,可以选取第四区间中的comp《0》-comp《3》作为第四类比较器进行第二阶段使能。此后,第四类比较器的输出结果即作为与运算模式下位比较单元的输出结果。
94.在与运算模式下,序号大于位比较单元组中的第二序号中位数的第三类比较器的数量多于序号小于第二序号中位数的第三类比较器的数量。例如,第二序号中位数为7,序号小于7的第三类比较器有1个,而序号大于7的第三类比较器有2个。由于模拟累加结果通过比较器的正相端的电压进行表征,正相端的电压越大,对应的模拟累加结果越小,因此较密集的选取序号大的比较器作为第三类比较器,可以更快速的准确确定出工作的第四类比较器进行第二阶段使能,实现小值译码优先,此时该分区式模数转换模块为基于子分区小值译码优先的2.24b/4b adc模块。该分区式模数转换模块可以适用于计算结果均比较小的神经网络,可以提高量化能量效率。
95.在上述实施例的基础上,本发明实施例中提供的基于局部电容电荷共享的sram存算一体芯片,所述全局共享开关模块包括一行全局共享开关阵列,所述全局共享开关阵列包括多个全局共享开关组,所述全局共享开关组与所述位计算单元组一一对应;
96.所述全局共享开关组中每个全局共享开关连接于对应的所述位计算单元组中相邻两个所述位计算单元之间。
97.具体地,本发明实施例中,位计算单元组可以包括4个相邻的位计算单元,故每个全局共享开关组中可以包括3个全局共享开关。由于每个位计算单元均与对应位的左列全局位线gbl以及右列全局位线gblb连接,因此每个全局共享开关可以连接于2个相邻的位计算单元的左列全局位线gbl之间。如此可以顺利实现每个位计算单元的乘法运算结果的累加。
98.在上述实施例的基础上,本发明实施例中提供的基于局部电容电荷共享的sram存算一体芯片,所述位计算单元包括一列寄生参数提取lpe阵列,所述lpe阵列包括多个lpe;
99.所述sram存算一体芯片还包括sram外围电路,所述多个lpe的全局位线均连接于所述sram外围电路。
100.具体地,本发明实施例中,每个位计算单元均可以包括一列局部处理单元(local process element,lpe)阵列,每个lpe阵列包括多个lpe。每个lpe均为一个核心计算单元,在每个核心计算单元内均可以存储有单个存储数据的对应位数据。
101.该sram存算一体芯片还可以包括sram外围电路(sram peripheral circuits),该sram外围电路可以通过左列全局位线gbl以及右列全局位线gblb与每个lpe连接,以实现对每个lpe的驱动及控制。
102.本发明实施例中,采用lpe阵列作为位计算单元,实现存储数据的一位数据与输入数据的乘法运算或异或运算,为芯片的两种工作模式提供基础,提高了芯片性能。
103.在上述实施例的基础上,本发明实施例中提供的基于局部电容电荷共享的sram存算一体芯片,每个lpe包括6t sram单元以及传输门开关,所述6t sram单元通过所述传输门开关与对应的全局位线连接;
104.每个lpe的局部位线之间存在寄生电容。
105.具体地,本发明实施例中,如图3所示,每个lpe均包括6t sram单元以及传输门开关,6t sram单元以及传输门开关的数量可以根据需要进行设置,例如6t sram单元的数量有16个,传输门开关的数量有7个,8个6t sram单元构成一个核心计算子单元,两个核心计算子单元之间通过7个传输门开关连接。图3中传输门开关分别为2个s_left、1个s_gleft、1个s_xnor_u、1个s_xnor_d以及2个s_gright。1个s_gleft与左列全局位线gbl连接,2个s_gright均与右列全局位线gblb连接。7个传输门开关上侧的8个6t sram单元6t《0》-6t《7》构成第一核心计算子单元,第一核心计算子单元左右分别连接有左列局部位线lbl_u和右列局部位线lblb_u,左列局部位线lbl_u和右列局部位线lblb_u均存在固有位线电容c,因此在左列局部位线lbl_u和右列局部位线lblb_u之间形成2c的局部电容。左行字线wl《0:7》以及右行字线wlb《0:7》均分别与第一核心计算子单元中每个6t sram单元连接。
106.同理,7个传输门开关下侧的8个6t sram单元6t《8》-6t《15》构成第二核心计算子单元,第二核心计算子单元左右分别连接有左列局部位线lbl_d和右列局部位线lblb_d,左列局部位线lbl_d和右列局部位线lblb_d均存在固有位线电容c,因此在左列局部位线lbl_d和右列局部位线lblb_d之间形成2c的局部电容。左行字线wl《8:15》以及右行字线wlb《8:15》均分别与第二核心计算子单元中每个6t sram单元连接。
107.图3中,lpe支持三种工作模式:xnor、and11和and21。and11模式旨在实现1-b输入数据与1-b存储数据的乘法运算,而and21模式旨在实现2-b输入数据与1-b存储数据的乘法运算。通常,在每种模式下,lbl_u/d和lblb_u/d均先预充电到vdd。s_xnor_u、s_xnor_d和s_left由不同的模式和输入数据控制,形成不同值和可能的放电路径的局部上限。然后,根据输入数据和地址激活8/16个wl/wlb之一。最后,根据储存数据,形成的局部电容将被排放到地面或保留其电荷,这代表了乘法运算结果。
108.xnor模式以及and11模式下lpe的配置结构图如图4所示。在xnor模式下,s_xnor_u或s_xnor_d开启,形成一个局部电容lbl+lblb和两个可能的放电路径(从电容到q或qb)用于异或运算。在and11模式下,仅采用lbl+lblb和wl。当且仅当结果为1时,lbl+lblb正在对地放电。
109.xnor模式下,输入数据(input,in)为
±
1,存储数据为
±
1,s_xnor_u/d=1时,lbl与lblb连接,lbl+lblb被预充电到vdd,该模式下lpe的真值表如表1所示。
110.and11模式下,输入(input,in)为0/1,存储数据为0/1,s_xnor_u/d=1时,lbl与lblb连接,lbl+lblb被预充电到vdd,该模式下lpe的真值表如表2所示。
111.表1 xnor模式下lpe的真值表
112.inwlwlbwqqbresultlbl+lblb-1gndvdd-1vddgnd+1gnd+1vddgnd-1vddgnd-1vdd-1gndvdd+1gndvdd-1vdd+1vddgnd+1gndvdd+1gnd
113.表2 and11模式下lpe的真值表
114.inwlwlbwqqbresultlbl+lblb0gndidle0vddgnd0vdd1vddidle0vddgnd0vdd0gndidle1gndvdd0vdd1vddidle1gndvdd1gnd
115.在and21模式下,lpe的配置结构图如图5所示,除了输入数据=0的情况下,wl被激活。当输入数据为1、2和3时,局部放电电容将设置为lbl_u/lbl_d、lbl_u+lbl_d和lbl_u+lblb_u+lbl_d,分别显示用于多位输入实现的模式不敏感的2b-dac功能。同时,考虑到最坏的放电条件,100k点蒙特卡罗(mc)模拟表明,对低存储节点的破坏很小,避免了写入干扰,如图6所示。图6中圈出的部分为100k点蒙特卡罗(mc)出现的小波动,最大的局部电容可以是6ff。
116.and21模式下,2b输入数据(input,in<1:0>)为0/1/2/3,1b存储数据为0/1,lbl_u+lblb_u+lbl_d被预充电到vdd,input来自于wl_u/wl_d,结束于局部电容共享,此时,s_xnor_u=1,s_left=1。该模式下lpe的真值表如表3所示。
117.表3 and21模式下lpe的真值表
[0118][0119]
在上述实施例的基础上,本发明实施例中提供的基于局部电容电荷共享的sram存
算一体芯片,所述译码模块包括译码器阵列,所述译码器阵列中译码器与所述lpe阵列中所述6t sram单元一一对应连接;
[0120]
所述sram存算一体芯片还包括sram控制器以及地址解码驱动,所述sram控制器分别与所述sram外围电路以及所述地址解码驱动连接。
[0121]
具体地,本发明实施例中,译码模块包括译码器阵列,译码器阵列可以包括多个译码器,每个译码器与lpe阵列中每个6t sram单元一一对应连接。
[0122]
sram存算一体芯片还包括sram控制器(sram controller)以及地址解码驱动(address decoder&driver),sram控制器分别与sram外围电路以及地址解码驱动连接,共同保证存储数据可以按位存储至每个lpe中。
[0123]
本发明实施例中,通过sram控制器可以实现芯片存储功能的自动化实现。
[0124]
在上述实施例的基础上,本发明实施例中提供的基于局部电容电荷共享的sram存算一体芯片,所述sram存算一体芯片还包括存内计算控制器(cim controller),存内计算控制器分别与译码模块、全局共享开关模块以及分区式模数转换模块连接。通过存内计算控制器,可以实现对芯片的计算功能的全局控制。
[0125]
图7为本发明实施例中提供的基于局部电容电荷共享的sram存算一体芯片的完整结构示意图,该芯片可以实现神经网络中与运算模式以及异或运算模式共存的需求。该芯片包括512
×
256的lpe阵列、sram控制器、sram外围电路、地址译码器驱动、cim控制器、32个译码器、包含有1
×
192个全局共享开关的全局共享开关模块、包含有1
×
64个4b-adc的分区式模数转换模块。lpe阵列的大小为512
×
256。lpe阵列的256列一共分为64个组,每个组包含4列,用于存放一个4b的权重数据。
[0126]
每列由32个lpe组成,每个lpe包括16个6t sram单元、7个传输门开关和一个用于sram和cim运算的固有位线电容。在与运算模式下,64个输入数据通过译码器逐行馈送到每一列lpe,然后在电荷域中与lpe中的权重数据相乘。单位权重数据累加由32个lpe之间的局部电容共享来执行。使用乘法累加方案,最终的4-b权重数据乘法累积是通过每个组内的局部电容共享来完成的。最后,模拟电压由分区式模数转换模块量化。在xnor模式下,乘法累加方案被跳过,最终结果被量化为2.24位。
[0127]
该芯片共可以支持64个4b的输入数据,可以表示为input《0:63》。输入数据经对应的译码器后得到的译码结果经左行字线wl《0:15》输入至各lpe,右行字线wlb《0:15》闲置。同时,译码器还可以接收cim控制器对各lpe内传输门开关的控制信号,并将控制信号s《0》《0:5》输入至各lpe。
[0128]
该芯片中,每4个相邻的lpe阵列以及每两个lpe之间连接的全局共享开关可以构成group,该芯片共可以包含有64个group。最终经分区式模数转换模块得到输出结果(output)。
[0129]
在上述实施例的基础上,本发明实施例中提供的基于局部电容电荷共享的sram存算一体芯片,采用的译码模块结构不涉及dac输入模块,如图8所示,以and-1-4-4-64模式(1-b输入数据,4-b权重数据,4-b输出数据,64并行度)的5个阶段的计算波形为例。其中,clk为时钟信号,pe为预充电信号,wl_en为wl使能信号,l_share为局部累加信号,g_share为全局累加信号。
[0130]
lbl+lblb预充电至vdd。当wl被激活时,lbl+lblb将被释放到地或保持它们的电
荷。然后所有按列的lbl+lblb将共享电荷。列共享后,乘法累加方案将被激活以进行全局共享,产生一个由分区式模数转换模块读出的平衡电压。7个输出门开关和wl/wlb的控制信号由译码器产生。在每个全局时序阶段,输出阵列信号和输入(模式、数据和地址)之间存在清晰的逻辑关系。因此,与传统的dac输入模块不同,无dac输入模块是一种设计友好的组合逻辑模块,没有非线性和pvt涨落问题。
[0131]
图8中,81为预充电阶段,82为乘法阶段,83为逐列累加阶段,84为多列累加阶段,85为分区式模数转换模块量化输出阶段。
[0132]
在上述实施例的基础上,本发明实施例中提供的基于局部电容电荷共享的sram存算一体芯片,所述全局共享开关模块在实现乘法累加方案时,需结合6t sram单元中的传输门开关,同一行中的四个6t sram单元组合为一个4-b权重数据。
[0133]
在乘法阶段,如图9所示,所有传输门开关以及所有全局共享开关都断开以进行乘法运算。
[0134]
在单位累加阶段,如图10所示,所有传输门开关均闭合,所有全局共享开关都断开以进行单位累加运算。
[0135]
在多位累加阶段,如图11所示,部分传输门开关断开,所有全局共享开关都闭合以进行4位累加运算。
[0136]
图9-图11中,s0《i》、s1《i》、s2《i》、s3《i》均表示6t sram单元中的s_gleft。
[0137]
在乘法和单位权重累加后,四个gbl通过全局共享开关连接。通过控制全局共享开关阵列,从lsb到msb,相应的gbl以1:2:4:8的电容比连接到存储阵列内的电容。电荷共享发生在选定的电容之间,平均电压,这代表了4-b权重数据累积的最终结果。该芯片采用了内存中的上限和lpe的控制驱动程序。因此,与在存储器外增加一个加权电容阵列的传统方法相比,乘法累加方案消除了额外和过度的补偿电容,从而节省了面积和额外的充放电能量。
[0138]
基于以上内容,本发明实施例中在tsmc 28纳米标准cmos工艺下前仿真和部分后仿真实现了该芯片。6t sram单元是基于逻辑规则设计。为了评估本发明实施例中提供的芯片,在不同模式和电源下仿真计算线性度和涨落、能耗组成和能量效率的性能。此外,基于从模拟中提取的电路级非理想性,对vgg-like cnn模型和cifar-10数据集进行了行为模拟,以评估由于非理想性导致的分类精度损失。
[0139]
图12是xnor模式下从理想mac运算结果到模拟电压的传递函数示意图,图13是and模式下从理想mac运算结果到模拟电压的传递函数示意图。扫描mac运算结果并评估模拟输出,传递函数均具有大于0.999的拟合优度。由于gbl和adc输入电容上的金属线电容不可忽略,因此动态范围损失了150mv左右。图12中传递函数方程为y=-5.4272x+558.59,r2=0.9998;图13中传递函数方程为y=-0.5037x+890.69,r2=0.9997。图12和图13中传递函数的纵坐标范围是分区式模数转换模块的量化范围。图12和图13中横坐标为mac运算结果(mac value),纵坐标为平均模拟电压(average output),单位为mv。
[0140]
图14显示了mac运算中模拟电压在1.8mv左右的平均涨落。传递函数在动态范围内表现出良好的线性度,混合信号计算的可变性很小。adc的传递函数和inl如图15所示。传递函数和inl的平均涨落标准差为8.1mv。adc设计在目标动态范围上表现出良好的线性度。
[0141]
为了评估非理想情况下的分类精度损失,建立了行为级仿真模型。非理想是模拟的平均计算涨落(1.8mv)和平均ps-adc inl涨落(8.1mv)。将计算涨落等同于分区式模数转
换模块的inl(9.9mv),并将4-b量化精度的vgg-like cnn映射到该芯片。该芯片设置为and-2-4-4-32模式。使用的cnn模型和拓扑、数据集以及不同条件下的推理精度如表4所示。精度损失为1.37%,可以接受。
[0142]
表4行为级仿真模型和结果比较
[0143][0144][0145]
如表5所示为本发明实施例中提供的芯片结构与现有芯片结构的性能对比情况表,该芯片支持具有最高通道数的xnor模式和and模式的mac运算。计算获取时间为10ns,具有竞争力。该芯片在xnor模式和and-2-4-4-32模式下均实现了最高吞吐量,分别比现有芯片结构提高了5.42倍和3.28倍。xnor模式下的能效为2.28倍,and模式下为1.097倍。
[0146]
表5本发明实施例中提供的芯片结构与现有芯片结构的性能对比情况表
[0147][0148]
其中,表3中尾注的含义如下:1表示归一化为2b/4b输入/权重操作(normalized to 2b/4b input/weight operation);2表示归一化为1b/1b输入/权重操作(normalized to 1b/1b input/weight operation);3表示有偿(with compensation),4表示根据论文中120.56-198.61tops/w的范围估计,平均为159.59 tops/w(159.59 tops/w in average by estimated from the range 120.56-198.61 tops/w in the paper);5表示xnor模式(xnor mode);6表示and模式(and mode);7表示mnist数据集(mnist dataset);8表示根据论文中的95.8-136.8tops/w范围估计,平均为116.3 tops/w(116.3 tops/w in average by estimated from the range 95.8-136.8 tops/w in the paper)。
[0149]
如图16所示,在上述实施例的基础上,本发明实施例中提供了一种通过上述各实施例提供的基于局部电容电荷共享的sram存算一体芯片实现的存内计算方法,包括:
[0150]
s61,在与运算模式下,基于sram存算一体芯片中按位计算模块包括的每个位计算单元,采用局部电容的电荷共享原理,将输入数据与按位存储的存储数据的一位数据进行乘法运算,得到所述存储数据的一位数据对应的乘法运算结果,并基于所述sram存算一体芯片中全局共享开关模块,将所述存储数据的各位对应的乘法运算结果进行累加,得到模拟累加结果,基于所述sram存算一体芯片中分区式模数转换模块包括的所有位比较单元,将所述模拟累加结果进行量化输出;
[0151]
s62,在异或运算模式下,基于每个所述位计算单元,采用所述局部电容的电荷共
享原理,将所述输入数据与所述存储数据的一位数据进行异或运算,得到所述存储数据的一位数据对应的异或运算结果,并基于所述分区式模数转换模块包括的每个所述位比较单元,将所述存储数据的一位数据对应的异或运算结果进行量化输出。
[0152]
在上述实施例的基础上,本发明实施例中提供的存内计算方法,还包括:
[0153]
在所述异或运算模式下,从所述位比较单元中选取序号大于所述位比较单元中的第一序号中位数的第一类比较器进行第一阶段使能,并基于所述第一类比较器的输出结果,从所述位比较单元的各比较器中所述第一类比较器的一侧选取第二类比较器进行第二阶段使能;
[0154]
在所述与运算模式下,从所述位比较单元组的各比较器中选取序号不等距的多个第三类比较器进行第一阶段使能,并基于所述多个第三类比较器的输出结果,从所述位比较单元组的各比较器中所述多个第三类比较器形成的区间之一选取第四类比较器进行第二阶段使能;
[0155]
其中,序号大于所述位比较单元组中的第二序号中位数的第三类比较器的数量多于序号小于所述第二序号中位数的第三类比较器的数量。
[0156]
具体地,该存内计算方法,其执行主体为上述各实施例提供的基于局部电容电荷共享的sram存算一体芯片,具体实现方法参见上述实施例,此处不再赘述。
[0157]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1