一种基于迭代学习的半监督人眼多要素分割方法
1.本发明涉及图像处理技术领域,特别是涉及一种基于迭代学习的半监督人眼多要素分割方法。
背景技术:
2.人眼要素分割技术主要研究对人眼特定部位的提取。在不同光照条件下,利用人眼各要素的不同特征,对目标区域分割提取。早期的人眼要素分割主要是利用积分微分算子或圆形霍夫变换迭代求解出目标边界、利用灰度等底层信息检测目标边缘等方法。该类方法高度依赖图像的各类特征,对图像质量要求高,易受噪声影响。另外,红外光照明条件下,虽然可获得高质量人眼图像,对分割人眼各要素有较大帮助,但对图像获取环境要求较高,不如可见光条件下操作简单,而且由于与可见光图像域差异较大,难以扩展满足自然光下对人眼各要素分割的需求。随着深度学习的发展,基于可见光图像的人眼要素分割方法取得阶段性进展,然而受限于可见光人眼数据各要素真值标注困难,现有方法大多只针对人眼单要素开展研究,对多个要素的分割方法研究较少。
3.现有公开专利文献cn113343943a公开了一种基于先验信息的人眼多要素分割方法。该方法属于基于红外光图像的有监督人眼多要素分割范畴,旨在提高巩膜先验信息获取的速度与可解释性,提升眼部图像分割速度和分割精度,提高分割效率。该方案主要步骤是:通过残差网络提取巩膜区域的高维特征;利用该高维特征对原眼部图像的高维特征进行注意力调整;对调整后的原眼部图像的高维度特征进行编码得到编码语义特征;通过跨连接激励对编码语义特征进行改善,并将其输入到解码器进行解码得到解码语义特征;对解码语义特征进行通道调整,输出初步分割结果;计算初步分割结果与分割标签的总损失,并通过将其与设置阈值的比较,判断是否需要对所有的滤波器、编码器和解码器进行优化,输出瞳孔、虹膜和巩膜的最终分割结果。虽然该方案能够实现对人眼的多要素进行分割,但是其需要依托大量的有标签眼部数据,且其是针对红外光照明下采集的具备完整的像素级标注(巩膜,虹膜,瞳孔)的大体量数据集openeds发明研究,对于由于标注困难很难获取大量有标签数据的可见光人眼要素分割数据很难适用。
技术实现要素:
4.本发明所要解决的技术问题是提供一种基于迭代学习的半监督人眼多要素分割方法,能够在使用少量标签数据的情况下,提升模型的精度和鲁棒性。
5.本发明解决其技术问题所采用的技术方案是:提供一种基于迭代学习的半监督人眼多要素分割方法,包括以下步骤:
6.(1)将可见光下眼部数据集划分为有标签眼部数据集和无标签眼部数据集;
7.(2)基于所述有标签眼部数据集利用有监督深度学习网络进行训练,得到预训练模型;
8.(3)基于所述预训练模型通过前向推理获取所述无标签眼部数据集的伪标签;
9.(4)基于所述有标签眼部数据集对所述无标签眼部数据集和伪标签进行筛选,得到信任数据集;
10.(5)将所述有标签眼部数据集和信任数据集输入至所述有监督深度学习网络进行再训练,若未达到训练完成要求,则返回所述步骤(3),否则结束训练得到人眼分割模型;
11.(6)采用所述人眼分割模型对人眼进行多要素分割。
12.所述步骤(4)具体为:
13.(41)基于所述有标签眼部数据集中的标签获取标准参数;
14.(42)基于所述伪标签获取所述无标签眼部数据集中每张图像数据的伪标签参数;
15.(43)将所述标准参数与所述伪标签参数进行比较,若所述伪标签参数的总错误率小于阈值,则将所述伪标签参数对应的图像数据和伪标签加入到所述信任数据集中。
16.所述步骤(41)具体为:根据所述标签提取巩膜标签、虹膜标签和瞳孔标签,由所述巩膜标签、虹膜标签和瞳孔标签合成全眼标签;分别计算所述全眼标签、虹膜标签和瞳孔标签的凸性和坚固性;分别求所述全眼标签、虹膜标签和瞳孔标签的平均凸性和平均坚固性,并将所述平均凸性和平均坚固性作为标准参数。
17.所述步骤(42)具体为:根据所述伪标签提取伪巩膜标签、伪虹膜标签和伪瞳孔标签,由所述伪巩膜标签、伪虹膜标签和伪瞳孔标签合成伪全眼标签;分别计算每张图像数据对应的伪全眼标签、伪虹膜标签和伪瞳孔标签的凸性和坚固性。
18.所述步骤(43)具体为:分别计算每张图像数据对应的伪全眼标签、伪虹膜标签和伪瞳孔标签的凸性和坚固性与所述平均凸性和平均坚固性的差值;根据所述差值采用加权求和的方式计算总错误率;若所述伪标签参数的总错误率小于阈值,则将所述伪标签参数对应的图像数据和伪标签加入到所述信任数据集中。
19.所述步骤(41)具体为:根据所述标签提取巩膜标签、虹膜标签和瞳孔标签;分别计算所述巩膜标签、虹膜标签和瞳孔标签的hu矩;计算所述巩膜标签、虹膜标签和瞳孔标签的hu矩统计量作为标准参数。
20.所述步骤(42)具体为:根据所述伪标签提取伪巩膜标签、伪虹膜标签和伪瞳孔标签;分别计算每张图像数据对应的伪巩膜标签、伪虹膜标签和伪瞳孔标签的hu矩。
21.所述步骤(43)具体为:分别计算每张图像数据对应的伪巩膜标签、伪虹膜标签和伪瞳孔标签的hu矩与所述巩膜标签、虹膜标签和瞳孔标签的hu矩统计量的差值;根据所述差值采用加权求和的方式计算总错误率;若所述伪标签参数的总错误率小于阈值,则将所述伪标签参数对应的图像数据和伪标签加入到所述信任数据集中。
22.有益效果
23.由于采用了上述的技术方案,本发明与现有技术相比,具有以下的优点和积极效果:本发明通过合理利用可见光眼部数据少量标注,逐步完善未标注数据的标签,使得训练数据在迭代进程中不断扩充,在提高算法精度的同时增加模型的鲁棒性。本发明中的伪标签筛选策略通过充分统计可见光眼部数据标签的形状特性,找寻眼部数据在形状特性的共性,利用眼部形状共性对伪标签进行有效评价及筛选。
附图说明
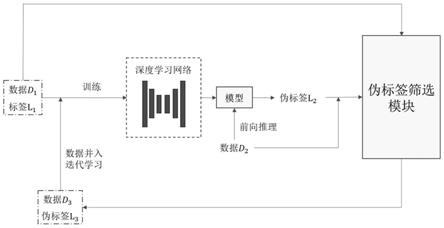
24.图1是本发明实施方式的整体流程图;
25.图2是本发明实施方式中伪标签筛选策略示意图;
26.图3是本发明实施方式中一种筛选器参数制定方案示意图;
27.图4是本发明实施方式中另一种筛选器参数制定方案示意图。
具体实施方式
28.下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本技术所附权利要求书所限定的范围。
29.本发明的实施方式涉及一种基于迭代学习的半监督人眼多要素分割方法,如图1所示,包括以下步骤:将可见光下眼部分割数据集划分为有标签眼部数据集和无标签眼部数据集;基于所述有标签眼部数据集利用有监督深度学习网络进行训练,得到预训练模型;基于所述预训练模型通过前向推理获取所述无标签眼部数据集的伪标签;基于所述有标签眼部数据集对所述无标签眼部数据集和伪标签进行筛选,得到信任数据集;将所述有标签眼部数据集和信任数据集输入至所述有监督深度学习网络进行再训练,若未达到训练完成要求,则返回上述的伪标签获取步骤,否则结束训练得到人眼分割模型。具体地说:
30.步骤1,处理可见光下眼部数据集,对其划分为有标签眼部数据集(数据d1,标签l1)和无标签眼部数据集d2;
31.步骤2,将有标签眼部数据集中标签l1处理为npy格式,获取标签l1与数据d1,并标记标签l1的类型,包括:背景、巩膜、虹膜和瞳孔,其中,部分数据标签类型可能会有缺失;
32.步骤3,基于预处理后的有标签数据,利用有监督深度学习网络进行训练,得到预训练模型;同时初始化信任数据集,该信任数据集用于放置符合条件的伪标签l3及对应数据d3,
33.步骤4,基于预训练模型,通过前向推理获取无标签眼部数据d2的伪标签l2,联合数据d1、标签l1一起送入伪标签筛选模块,挑选出标签可信任数据集(记作数据d3,伪标签l3)。
34.步骤5,混合有标签数据集(数据d1,标签l1)与信任数据集(数据d3,伪标签l3)输入有监督深度学习网络再进行训练,如果达到设定的循环轮数epoch或者损失函数loss值低于阈值则结束,否则跳转至步骤4进行迭代学习。本实施方式中的损失函数可以使用cross entropy loss与generalized dice loss的结合。完成训练后即可得到人眼分割模型,采用该人眼分割模型即可对人眼的巩膜、虹膜和瞳孔进行分割。
35.其中步骤4具体包括:基于所述有标签眼部数据集中的标签获取标准参数;基于所述伪标签获取所述无标签眼部数据集中每张图像数据的伪标签参数;将所述标准参数与所述伪标签参数进行比较,若所述伪标签参数的总错误率小于阈值,则将所述伪标签参数对应的图像数据和伪标签加入到所述信任数据集中。如图2所示,本实施方式中的步骤4筛选伪标签时,需要使用到筛选器参数制定模块。本实施方式筛选器参数制定模块有两种方案。
36.第一种方案的筛选器参数制定模块(见图3)旨在针对标签l1和伪标签l2分别获取标准参数和伪标签参数,以有效评价并筛选伪标签。可选择方式有两种:一种是基于形状特征参数整合的参数制定方案,以标签l1为例,具体技术方案如下所示,伪标签l2与之类似。
37.提取标签l1中的巩膜标签l
sclera
、虹膜标签l
iris
、瞳孔标签l
pupil
;
38.合成巩膜标签l
sclera
、虹膜标签l
iris
、瞳孔标签l
pupil
为全眼标签l
eye
(如缺失部分标签则跳过此步),公式为:l
eye
=l
sclera
∪l
iris
∪l
pupil
。
39.分别计算虹膜标签l
iris
、瞳孔标签l
pupil
、全眼标签l
eye
的形状特征量,根据眼睛形状选择凸性(convexity,c)和坚固性(solidity,s),公式为:
[0040][0041]
求解全眼、虹膜、瞳孔的平均凸性和平均坚固性,作为标准参数输出,公式为:
[0042][0043][0044]
其中,c
class
表示平均凸性,s
class
表示平均坚固性,c(l
class
),class∈{eye,iris,pupil}表示虹膜标签l
iris
、瞳孔标签l
pupil
、全眼标签l
eye
的凸性,s(l
class
),class∈{eye,iris,pupil}表示虹膜标签l
iris
、瞳孔标签l
pupil
、全眼标签l
eye
的坚固性,n
class
表示数据d1的总数。
[0045]
另一种方案是基于hu矩统计量计算(见图4),同样以标签l1为例,具体技术方案如下所示,伪标签l2与之类似。
[0046]
提取标签l1中的巩膜标签l
sclera
、虹膜标签l
iris
、瞳孔标签l
pupil
;
[0047]
分别计算巩膜标签l
sclera
、虹膜标签l
iris
、瞳孔标签l
pupil
的hu矩;
[0048]
计算巩膜、虹膜、瞳孔的hu矩统计量,本实施方式中选择中位数hu矩,作为标准参数输出,公式表示为:hu
class
=median(hu(l
class
)),class∈{sclera,iris,pupil}。
[0049]
本实施方式提出的伪标签筛选模块根据筛选器参数制定方式的不同,筛选方案不同。
[0050]
对应于第1种,其具体技术方案如下:
[0051]
对于标签l1和伪标签l2,分别通过筛选器参数制定模块,获得标准参数与伪标签参数,即形状特征量、选择凸性和坚固性;
[0052]
针对标准参数与伪标签参数的比较模块,计算全眼、虹膜、瞳孔的错误率作为比较标准,公式为:
[0053]eclass
=|c
class-c(p
class
)|,class∈{eye,iris,pupil}
[0054]
其中,c(p
class
),class∈{eye,iris,pupil}表示数据d2中的某张图像数据对应的伪全眼标签、伪虹膜标签和伪瞳孔标签的凸性和坚固性
[0055]
计算总错误率e=λ1e
eye
+λ2e
iris
+λ3e
pupil
,设置选择阈值。当e小于阈值时,提取对应图像数据d2与伪标签l2加入到信任数据集,完成伪标签筛选。
[0056]
对应于第2种,其具体技术方案如下:
[0057]
对于标签l1和伪标签l2,分别通过筛选器参数制定模块,获得标准参数与伪标签参数,即对应hu矩;
[0058]
针对标准参数与伪标签参数的比较模块,分别计算巩膜、虹膜、瞳孔的hu矩错误率作为比较标准,公式为:
[0059]eclass
=|hu
class-hu(p
class
)|,class∈{sclera,iris,pupil}
[0060]
其中,hu(p
class
),class∈{sclera,iris,pupil}表示数据d2中的某张图像数据对应的伪巩膜标签、伪虹膜标签和伪瞳孔标签的hu矩
[0061]
计算总错误率e=λ1e
sclera
+λ2e
iris
+λ3e
pupil
,设置选择阈值。e小于阈值时,提取对应图像数据d2与伪标签l2加入到信任数据集,完成伪标签筛选。
[0062]
下面以可见光人眼数据集sbvpi和espnet为例进一步说明本发明。
[0063]
步骤1:划分可见光人眼要素数据,分为有标签数据集(数据d1,标签l1)和无标签数据集(数据d2),准备深度学习网络(如espnet)
[0064]
1.1)联网下载sbvpi数据集,该数据集共有1856张眼部图像,其中122张带有瞳孔标签,129张带有虹膜标签,1840张带有巩膜标签;
[0065]
1.2)实验需要,以129张有虹膜标签的图像数据为主,将数据与对应所有标签放入有标签数据集中,其余数据划入无标签数据集中,对应的巩膜标签可用于伪标签筛选时的其中一项标准,设置信任数据集,文件为空;
[0066]
1.3)下载espnet网络模型。
[0067]
步骤2:将有标签数据集输入网络模型中进行训练获得预训练模型,使用预训练的模型得到无标签数据d2的伪标签l2。
[0068]
步骤3:将有标签数据集数据(数据d1,标签l1)与伪标签数据(数据d2的伪标签l2)分别输入本实施方式提出的筛选器参数制定模块,获取标准参数与伪标签参数。以标准参数获取为例,具体可选择方案一或方案二,其中方案一包括2.1)-2.4),方案二包括2.1)、2.5)、2.6),伪标签参数获取同理。
[0069]
2.1)由标签l1提取得到巩膜标签l
sclera
、虹膜标签l
iris
、瞳孔标签l
pupil
;
[0070]
2.2)由巩膜标签l
sclera
、虹膜标签l
iris
、瞳孔标签l
pupil
合成全眼标签l
eye
;
[0071]
2.3)分别计算全眼标签l
eye
、虹膜标签l
iris
、瞳孔标签l
pupil
的凸性c(l
eye
)、c(l
iris
)、c(l
pupil
)和坚固性s(l
eye
)、s(l
iris
)、s(l
pupil
);
[0072]
2.4)分别求全眼标签l
eye
、虹膜标签l
iris
、瞳孔标签l
pupil
的平均凸性c
eye
、c
iris
、c
pupil
和平均坚固性s
eye
、s
iris
、s
pupil
;
[0073]
2.5)分别计算巩膜标签l
sclera
、虹膜标签l
iris
、瞳孔标签l
pupil
的hu矩hu(l
sclera
)、hu(l
iris
)、hu(l
pupil
);
[0074]
2.6)计算巩膜、虹膜、瞳孔的hu矩统计量,hu
sclera
、hu
iris
、hu
pupil
。
[0075]
步骤4:在获取标准参数与伪标签参数的基础上,利用本实施方式提出的伪标签筛选模块对无标签数据d2和对应的伪标签l2进行筛选,得到信任数据集(数据d3,伪标签l3),具体可选择4.1)4.2)a)、4.3)、4.4),或者4.1)、4.2)b)、4.3)、4.4):
[0076]
4.1)在伪标签参数获取过程中,由伪标签l2提取得到巩膜伪标签p
sclera
、虹膜伪标签p
iris
、瞳孔伪标签p
pupil
,并由巩膜伪标签p
sclera
、虹膜伪标签p
iris
、瞳孔伪标签p
pupil
合成全眼伪标签p
eye
;
[0077]
4.2)a)(方案一)计算单张图像对应全眼伪标签、虹膜伪标签、瞳孔伪标签的错误率e
eye
、e
iris
、e
pupil
作为比较标准;
[0078]
4.2)b)(方案二)计算单张图像对应巩膜伪标签、虹膜伪标签、瞳孔伪标签的错误率e
sclera
、e
iris
、e
pupil
作为比较标准;
[0079]
4.3)基于错误率的比较标准,设计选择策略为阈值判别方式:计算总错误率e,即
当e小于阈值,原图数据与对应的伪标签从无标签数据集(数据d2的伪标签l2)移至信任数据集中(数据d3,伪标签l3);
[0080]
4.4)重复4.2至4.4),直到无标签数据d2全部操作完毕。
[0081]
步骤5:将信任标签数据集(数据d3,伪标签l3)与有标签数据集(数据d1,标签l1)结合输入预训练模型中继续训练,如果达到提前设定的损失函数值或循环轮数阈值则结束得到人眼分割模型,否则跳转至步骤2。
[0082]
步骤6:采用人眼分割模型图像中的人眼的巩膜、虹膜和瞳孔进行多要素分割。
[0083]
不难发现,本发明通过合理利用可见光眼部数据少量标注,逐步完善未标注数据的标签,使得训练数据在迭代进程中不断扩充,在提高算法精度的同时增加模型的鲁棒性。本发明中的伪标签筛选策略通过充分统计可见光眼部数据标签的形状特性,找寻眼部数据在形状特性的共性,利用眼部形状共性对伪标签进行有效评价及筛选。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1