一种基于多损失联合学习的车辆重识别方法
1.本发明属于计算机视觉和图像处理技术领域,具体涉及一种基于多损失联合学习的车辆重识别方法。
背景技术:
2.车辆识别不仅是智能城市交通的核心,也是计算机视觉研究的热点之一,并在车辆检测、车辆分类等各个领域已经得到了越来越广泛的应用。车辆重识别作为这个领域中新的具有挑战性和特殊性的课题,近年来吸引了越来越多的研究者。车辆重识别是指给出一张车辆图片,可以识别出在摄像头下或者其他照片中出现的同一辆车。它可以被分为图像检索的子问题。车辆重识别在现实中可以应用到真实交通系统中,起到对目标车辆的定位,追踪的作用,从而实现诸如打击犯罪等功能。但是在车辆重识别任务中,摄像头的位置不同会产生光照变化、视角变化及分辨率的差异,这导致同一车辆在不同视角下产生类内差异或不同车辆因型号相同形成类间相似,这就使得车辆重识别任务的研究人员面临巨大的挑战。
3.根据训练网络的目标函数的差异,基于深度学习的车辆重识别方法可以分为两类基于表征学习的方法和基于度量学习的方法。基于表征学习的方法在训练网络的时候并没有直接考虑图片的相似度,而是把车辆重识别任务当做分类(classification)问题或者验证(verification)问题来看待;基于度量学习的方法旨在通过网络学习出两张图片的相似度,可以当做聚类(cluster)问题来看待。表征学习和度量学习在车辆重识别领域都有大量的研究工作,也拥有各自的优缺点。经过一段时间的发展,目前车辆重识别领域最常用的方式为同时使用表征学习损失和度量学习损失来共同优化网络,从而融合两种方法的优点。但是三元组损失函数虽然不停地拉近同类距离,推远异类之间的距离,但是并未对类与类之间的绝对距离做一个明确的度量。即过于关注局部,导致难以训练且收敛时间长。除此以外,车辆重识别还存在一个特殊难点,由于属于同一车型的车辆彼此非常相似,即使用人眼来区分具有不同id但属于同一型号的车辆也是非常困难的。因此,车辆重识别需要更加鲁棒地区分目标与非目标之间的差异。
技术实现要素:
4.解决的技术问题:针对前述传统的三元组损失的弱约束性,以及具有不同id但属于同一型号的相似车辆难以区分的技术问题,本发明提出了一种基于多损失联合学习的车辆重识别方法。
5.技术方案:
6.一种基于多损失联合学习的车辆重识别方法,所述车辆重识别方法包括以下步骤:
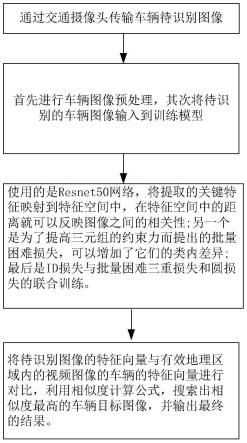
7.s1,对导入的车辆交通图像进行预处理,从中裁剪得到相同尺寸的车辆图像,对裁剪后的车辆图像进行随机擦除,得到车辆图像样本;
8.构建车辆重识别模型,车辆重识别模型包括resnet50网络模型、丢失网络、bn层和全连接层;
9.s2,采用resnet50网络模型提取得到车辆图像样本中的车辆关键特征;
10.s3,将提取得到的车辆关键特征映射到特征空间中,车辆图像样本在特征空间中的距离用于反映图像之间的相关性;对丢失网络不断训练和学习,使具有相同id的车辆样本在特征空间中形成聚类;其中,通过在随机生成的小批量样本里选择具有相同颜色的不同款式的车辆样本,作为困难三元组;采用三元组损失学习相似性度量,最小化正样本对之间的距离,同时最大化负样本对之间的距离;计算得到相应的批量困难三重损失l
t
;
11.s4,利用bn层对生成的全局特征进行归一化和纬度约减处理,提取得到车辆特征fi,将车辆特征fi送入全连接层;
12.s5,使用困难三重损失函数l
t
、id损失函数l
id
和圆损失函数lc来对特征向量进行联合学习,增强车辆重识别模型对相似样本的鉴别能力,扩大不同类型车辆的特征差异,提取更具区分和更高判别力的全局特征;id损失函数用于对输入具有相同id或者不同id的车辆图像样本的特征向量进行学习;圆损失函数用于学习类别区分性信息;
13.s6,采用测试集对车辆重识别模型进行测试。
14.进一步地,所述车辆重识别方法还包括以下步骤:
15.s7,将待识别的车辆图像导入车辆重识别模型,提取得到相应的特征向量;
16.将待识别的车辆图像的特征向量与有效地理区域内的视频图像的车辆的特征向量进行对比,利用相似度计算公式,搜索出相似度最高的车辆目标图像,输出最终识别结果。
17.进一步地,步骤s1中,对导入的车辆交通图像进行预处理,从中裁剪得到相同尺寸的车辆图像,对裁剪后的车辆图像进行随机擦除,得到车辆图像样本的过程包括以下步骤:
18.s11,对签名图像进行几何变换、水平翻转、镜像源处理使数据更加多样化;
19.s12,从整幅图像中将车辆部分裁剪成相同尺寸并提取;
20.s13,对提取的车辆图像进行随机擦除,针对不同的epoch,在原始图像中去除一个预先定义范围的矩形块。
21.进一步地,步骤s2中,采用resnet50网络模型提取得到车辆图像样本中的车辆关键特征的过程包括以下步骤:
22.s21,加载resnet50网络模型,使用该网络模型的参数作为初始参数来进行训练;
23.s22,采用训练完成的resnet50网络模型提取得到车辆的关键特征。
24.进一步地,步骤s3中,采用广义平均池将resnet50网络模型生成的特征聚合成全局特征。
25.进一步地,步骤s3中,根据下述公式计算车辆图像样本对之间的欧式距离:
[0026][0027]
式中,d(x,y)是指两个样本对特征向量之间的欧式距离,x和y分别指两个样本对提取的特征向量,num是特征向量中元素的个数,k是特征向量中的每个元素索引,xk和yk分别是两个样本的特征向量中索引为k的元素的值。
[0028]
进一步地,步骤s3中,批量困难三重损失l
t
的公式如下:
[0029]
l
t
=(d
a,p
+a-d
a,n
)
+
[0030]
式中,(
·
)
+
是铰链函数,a是添加的一个边际,是正负样本之间的欧式距离间隔,d(a,n)是锚点xa和类xn的距离,d
a,p
是锚点xa和类x
p
的距离,满足d(a,n)《d(a,p)。
[0031]
进一步地,步骤s5中,id损失指输入是一对车辆图x1和x2;y表示两辆车的图像是否属于同一个id,如果y=1表示两辆车属于同一标签,称其为正样本;y=0表示汽车来自不同的id,称其为负样本;通过对该损失函数的拟合,也在一定程度上增大了类间距离;
[0032]
所述id损失函数的公式如下:
[0033][0034]
式中,表示两次特征提取后对输入图像计算的欧氏距离,n为每一个batch的车辆总样本数量,y表示样本的标签,正类为1,负类为0,f(
·
)为特征提取器,β表示第β个特征索引,n表示特征数量,m arg in是设置的阈值参数,用来度量正负样本特征向量之间的距离差值的程度。
[0035]
进一步地,步骤s5中,圆损失用于学习类别区分性信息,即最大化类内相似度和最小化类间相似度;
[0036]
假设与样本空间x相关的类内相似度分数有k个,类间相似度分数有l个,则圆损失目标函数的公式如下:
[0037][0038]
其中,sn和s
p
分别为关于样本空间x的类间相似度和类内相似度,其采用余弦相似度来计算类内和类间相似度分数;和为非负整数,分别是和的权重,δn和δ
p
分别为类间和类内间隔,且满足和γ为尺度因子。
[0039]
进一步地,所述车辆重识别网络的总损失函数l
all
表示为:
[0040]
l
all
=l
id
+a
′
l
t
+b
′
lc[0041]
其中,a
′
和b
′
分别为三重损失和圆损失的权值。
[0042]
有益效果:
[0043]
1、对于传统的三元组损失的弱约束性,提出困难三重损失,既解决了随着训练的不断深入很多三元组变成“无用的”三元组的问题,也解决了训练耗时的问题。
[0044]
2、采用id损失与困难三元组损失联合学习,加强其约束。
[0045]
3、针对id损失和triplet损失优化特征在嵌入空间里分布不一致的现象,本发明引入circle loss联合学习,圆损失是一种基于一对相似性优化的深度学习方法以此来最大化类内相似性,最小化类间相似性。
附图说明
[0046]
图1为本发明实施例的基于多损失联合学习的车辆重识别方法的步骤示意图;
[0047]
图2为本发明实施例的基于多损失联合学习的车辆重识别方法流程图;
[0048]
图3为本发明实施例的基于多损失联合学习的车辆重识别方法对应的网络结构图;
[0049]
图4为本发明实施例的车辆差异示例图;图4(a)是类内差异性示意图,图4(b)是类间相似性示意图。
具体实施方式
[0050]
下面的实施例可使本专业技术人员更全面地理解本发明,但不以任何方式限制本发明。
[0051]
参见图1和图2,本发明实施例提出了一种基于多损失联合学习的车辆重识别方法,所述车辆重识别方法包括以下步骤:
[0052]
s1,对导入的车辆交通图像进行预处理,从中裁剪得到相同尺寸的车辆图像,对裁剪后的车辆图像进行随机擦除,得到车辆图像样本。
[0053]
构建车辆重识别模型,车辆重识别模型包括resnet50网络模型、丢失网络、bn层和全连接层。
[0054]
s2,采用resnet50网络模型提取得到车辆图像样本中的车辆关键特征。
[0055]
s3,将提取得到的车辆关键特征映射到特征空间中,车辆图像样本在特征空间中的距离用于反映图像之间的相关性;对丢失网络不断训练和学习,使具有相同id的车辆样本在特征空间中形成聚类;其中,通过在随机生成的小批量样本里选择具有相同颜色的不同款式的车辆样本,作为困难三元组;采用三元组损失学习相似性度量,最小化正样本对之间的距离,同时最大化负样本对之间的距离;计算得到相应的批量困难三重损失l
t
。
[0056]
s4,利用bn层对生成的全局特征进行归一化和纬度约减处理,提取得到车辆特征fi,将车辆特征fi送入全连接层。
[0057]
s5,使用困难三重损失函数l
t
、id损失函数l
id
和圆损失函数lc来对特征向量进行联合学习,增强车辆重识别模型对相似样本的鉴别能力,扩大不同类型车辆的特征差异,提取更具区分和更高判别力的全局特征;id损失函数用于对输入具有相同id或者不同id的车辆图像样本的特征向量进行学习;圆损失函数用于学习类别区分性信息。
[0058]
s6,采用测试集对车辆重识别模型进行测试。
[0059]
步骤(1),对车辆图像进行预处理
[0060]
具体的,步骤(1)包括以下子步骤:
[0061]
(1.1)对签名图像进行几何变换,通过水平翻转通过镜像源图像来使数据更加多样化。
[0062]
(1.2)从整幅图像中将车辆部分裁剪成相同尺寸提取处理。
[0063]
(1.3)将裁剪后的车辆图像进行随机擦除(random erasing),即在不同的epoch中在原始图像中去除一个预先定义大小范围的矩形块。
[0064]
步骤(2),特征提取
[0065]
具体的,步骤(2)包括以下子步骤:
[0066]
(2.1)加载resnet50网络模型,使用该网络模型的参数作为初始参数来进行训练,其中resnet50是resnet系列其中的一个版本。
[0067]
(2.2)提取车辆的关键特征。
[0068]
步骤(3),聚合操作
[0069]
具体的,步骤(3)包括以下子步骤:
[0070]
(3.1)本发明实施例使用广义平均池(generalized-mean(gem)pooling),它是一个可学习的池层,作为一种细粒度的实例检索,它可以捕获特定领域的区别性特征。目的是降低特征图的空间分辨率,从而实现输入失真和平移的空间不变性,在本实施例中,广义平均池用于将骨干网生成的特征聚合成全局特征。
[0071]
(3.2)将步骤(2.2)中得到的车辆关键信息映射到特征空间中,在特定空间中的距离就可以反映图像之间的相关性。
[0072]
(3.3)计算三元组损失,使用三元组损失学习相似性度量时,目的是使同一标签的样本尽可能接近,并尽可能远离不属于同一标签的其他样本。首先简单介绍一下三元组,它是这样构成的:从训练数据集中随机选一个样本,该样本称为锚点,然后再随机选取一个锚点(记为xa)属于同一类的样本和不同类的样本,这两个样本对应的称为正样本(记为x
p
)和负样本(记为xn),由此构成一个(锚点,正样本,负样本)三元组。三重损失的目的就是通过学习,让xa和x
p
特征表达之间的距离尽可能小,而xa和xn特征表达之间的距和特征表达之间的距离尽可能大,并且让xa和x
p
与xa和xn之间的距离和和之间的距离最小间隔。
[0073]
在得到车辆图像样本对之间的欧式距离后,距离公式如下:
[0074][0075]
其中d(x,y)是指两个样本对特征向量之间的欧式距离,x和y分别指两个样本对提取的特征向量,num是特征向量中元素的个数,k是特征向量中的第几个元素索引,xk和yk分别是两个样本的特征向量中索引为k的元素的值。
[0076]
通过对丢失网络的不断训练和学习,具有相同id的车辆样本最终在特征空间中形成聚类,从而完成车辆的再识别任务。当使用三元组损失学习相似性度量时,目的是使同一标签的样本尽可能接近,并尽可能远离不属于同一标签的其他样本。通过对丢失网络的不断训练和学习,具有相同id的车辆样本最终在特征空间中形成聚类,从而完成车辆的再识别任务。三重态损失旨在一定距离上把正负样本分开,即最小化正样本对之间的距离,同时最大化负样本对之间的距离。公式如下:
[0077]
l
t
=(d
a,p
+a-d
a,n
)
+
[0078]
其中()
+
是铰链函数。这个损失能够确保,给定的锚点xa与相似的类x
p
比xa与不相似的类xn更加接近。a就是添加的一个边际,它是正负样本之间的欧式距离间隔。这样在训练过后,同一车辆的特征点比不同车辆的特征点更加接近。然后,与查询图像距离较小的图像则更高的概率是相同的车辆id。
[0079]
虽然三重损失有助于训练卷积神经网络具有一定的判别能力,也有一定的局限性。三重损失是随机选取三元组,数据集越大,三元组的数量可能就越大。给予大量的时间去训练是不切实际的。更糟糕的是,一些三元组能够较快的学习正确,从而造成大量“无用的”三元组。因此挑选困难三元组将会成为学习的重点。实际上,反复学习不同颜色的车辆
不是同一辆车,对于卷积神经网络而言,没有学习到关键信息。而具有相同颜色的不同款式的车辆(hard negative)则有助于理解“同一辆车辆”的概念。所谓hard triplet:此时negative比positive更接近anchor,即d(a,n)《d(a,p)。
[0080]
批量困难三重损失由于只是在一个小批量里面选择最难的正负样本,所有可以更有效率的选取三元组,既解决了传统的三重损失训练不收敛的问题,也解决了训练耗时的问题。
[0081]
步骤(4),归一化处理
[0082]
具体的,步骤(4)包括以下子步骤:
[0083]
(4.1)使用bn,用于对生成的全局特征进行归一化、纬度约减,目的是让模型关注更多和更大的区域,获得可以用于构建损失函数最后完成学习。
[0084]
(4.2)提取车辆特征fi。
[0085]
(4.3)将车辆特征送入全连接层,用于图像的分类。
[0086]
步骤(5),多损失函数联合学习
[0087]
步骤(5)具体为:最后将改进后的triplet loss和id loss、circle loss联合学习,使卷积网络能较好地提取同种类型车辆地相似特征,显著的扩大不同类型车辆的特征差异,增强模型对相似样本的鉴别能力,提取更具区分和更高判别力的全局特征。
[0088]
id损失指输入是一对车辆图x1和x2,这两张车辆图片可能有相同的id,也可能有不同的id。y表示两辆车的图像是否属于同一个id,如果y=1表示两辆车属于同一标签,我们称其为正样本;y=0表示汽车来自不同的id,这是一个负样本。其中id损失函数的公式如式(1)所示。其中d
x1,x2
由d
x1,x2
=||f
x1-f
x2
||2得到,它表示两次特征提取后对输入图像计算的欧氏距离,即计算它们的相似度。其中f(
·
)为特征提取器,m arg in是设置的阈值参数。
[0089][0090]
圆损失旨在学习类别区分性信息,即最大化类内相似度和最小化类间相似度,假设与x相关的类内相似度分数有k个,类间相似度分数有l个,则圆损失目标函数如式所示:
[0091][0092]
其中,sn和s
p
分别为关于样本空间x的类间相似度和类内相似度,其采用余弦相似度来计算类内和类间相似度分数;和为非负整数,分别是和的权重,δn和δ
p
分别为类间和类内间隔,且满足和γ为尺度因子。
[0093]
车辆重识别网络的总损失函数l
all
可表示为:
[0094]
l
all
=l
id
+a
′
l
t
+b
′
lc[0095]
其中a
′
和b
′
分别为三重损失和圆损失的权值。
[0096]
使用三元组损失函数和圆损失函数以及id损失函数来对特征向量进行联合学习,使卷积网络能较好地提取同种类型车辆地相似特征,显著的扩大不同类型车辆的特征差异。
[0097]
步骤(6),在测试集中进行测试
[0098]
步骤(6)具体为:在测试集中随机挑选两个车辆图像输入网络模型进行预测。查看分类器的最后输出结果,若网络最后输出结果为1则证明参考车辆图像与待检测车辆图像来自同一个车辆;若网络最后输出结果为0则证明参考车辆图像与待检测车辆图像来自不同车辆。
[0099]
步骤(7),图像识别
[0100]
如图3所示,将待识别图像的特征向量与有效地理区域内的视频图像的车辆的特征向量进行对比,利用相似度计算公式,搜索出相似度最高的车辆目标图像,并输出最终的结果。图4是采用本发明实施例的车辆重识别方法的车辆差异示例图。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1