胶质瘤的类型识别方法、模型训练方法、装置、设备
1.本公开涉及图像处理技术,尤其涉及一种胶质瘤的类型识别方法、模型训练方法、装置、设备。
背景技术:
2.胶质瘤是最常见的原发性脑肿瘤,也是颅内最常见的恶性肿瘤。根据其组织学形态特征,胶质瘤被划分为星形细胞瘤、少突胶质细胞瘤和室管膜瘤三种类型。胶质瘤的准确分型十分重要。
3.现有技术中,对胶质瘤的分型主要依靠病理科医生观察组织病理图像,通过组织学形态特征来确认分型。
4.但是,人工方式对胶质瘤分型的准确率有待提高。
技术实现要素:
5.本公开提供了一种胶质瘤的类型识别方法、模型训练方法、装置、设备,可以在一定程度上提高对胶质瘤分型的准确率。
6.根据本公开第一方面,提供了一种胶质瘤的类型识别方法,所述方法包括:
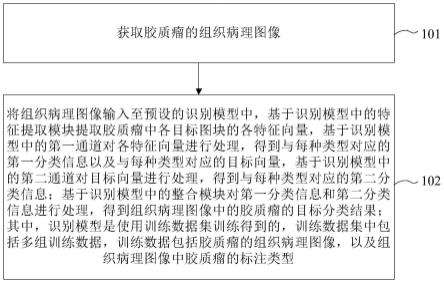
7.获取胶质瘤的组织病理图像;
8.将所述组织病理图像输入至预设的识别模型中,基于所述识别模型中的特征提取模块提取所述胶质瘤中各目标图块的各特征向量,基于所述识别模型中的第一通道对各所述特征向量进行处理,得到与每种类型对应的第一分类信息以及与每种类型对应的目标向量,基于所述识别模型中的第二通道对所述目标向量进行处理,得到与每种类型对应的第二分类信息;基于所述识别模型中的整合模块对所述第一分类信息和所述第二分类信息进行处理,得到所述组织病理图像中的胶质瘤的目标分类结果;
9.其中,所述识别模型是使用训练数据集训练得到的,所述训练数据集中包括多组训练数据,所述训练数据包括胶质瘤的组织病理图像,以及所述组织病理图像中胶质瘤的标注类型。
10.根据本公开第二方面,提供了一种模型训练方法,所述方法包括:
11.获取训练数据集;其中,所述训练数据集中包括多组训练数据,所述训练数据包括胶质瘤的组织病理图像,以及所述胶质瘤的标注类型;
12.将所述胶质瘤的组织病理图像输入至预设模型中,得到所述组织病理图像中的胶质瘤的预测类型;根据所述胶质瘤的标注类型和预测类型,优化所述预设模型中的参数,得到识别模型;其中,所述识别模型用于识别胶质瘤的类型。
13.根据本公开第三方面,提供了一种胶质瘤的类型识别装置,所述装置包括:
14.获取单元,用于获取胶质瘤的组织病理图像;
15.识别单元,用于将所述组织病理图像输入至预设的识别模型中,基于所述识别模型中的特征提取模块提取所述胶质瘤中各目标图块的各特征向量,基于所述识别模型中的
第一通道对各所述特征向量进行处理,得到与每种类型对应的第一分类信息以及与每种类型对应的目标向量,基于所述识别模型中的第二通道对所述目标向量进行处理,得到与每种类型对应的第二分类信息;基于所述识别模型中的整合模块对所述第一分类信息和所述第二分类信息进行处理,得到所述组织病理图像中的胶质瘤的目标分类结果;
16.其中,所述识别模型是使用训练数据集训练得到的,所述训练数据集中包括多组训练数据,所述训练数据包括胶质瘤的组织病理图像,以及所述组织病理图像中胶质瘤的标注类型。
17.根据本公开第四方面,提供了一种模型训练装置,所述装置包括:
18.获取单元,用于获取训练数据集;其中,所述训练数据集中包括多组训练数据,所述训练数据包括胶质瘤的组织病理图像,以及所述胶质瘤的标注类型;
19.训练单元,用于将所述胶质瘤的组织病理图像输入至预设模型中,得到所述组织病理图像中的胶质瘤的预测类型;根据所述胶质瘤的标注类型和预测类型,优化所述预设模型中的参数,得到识别模型;其中,所述识别模型用于识别胶质瘤的类型。
20.根据本公开第五方面,提供了一种电子设备,包括存储器和处理器;其中,
21.所述存储器,用于存储计算机程序;
22.所述处理器,用于读取所述存储器存储的计算机程序,并根据所述存储器中的计算机程序执行如第一方面、第二方面所述的方法。
23.根据本公开第六方面,提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,当处理器执行所述计算机执行指令时,实现如第一方面、第二方面所述的方法。
24.根据本公开第七方面,提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时,实现如第一方面、第二方面所述的方法。
25.本公开提供的胶质瘤的类型识别方法、模型训练方法、装置、设备,包括:获取胶质瘤的组织病理图像;将组织病理图像输入至预设的识别模型中,基于识别模型中的特征提取模块提取胶质瘤中各目标图块的各特征向量,基于识别模型中的第一通道对各特征向量进行处理,得到与每种类型对应的第一分类信息以及与每种类型对应的目标向量,基于识别模型中的第二通道对目标向量进行处理,得到与每种类型对应的第二分类信息;基于识别模型中的整合模块对第一分类信息和第二分类信息进行处理,得到组织病理图像中的胶质瘤的目标分类结果;其中,识别模型是使用训练数据集训练得到的,训练数据集中包括多组训练数据,训练数据包括胶质瘤的组织病理图像,以及组织病理图像中胶质瘤的标注类型。本方案中,可以通过识别模型中的第一通道得到每种类型对应的第一分类信息以及与每种类型对应的目标向量;通过第二通道对目标向量进行处理,得到每种类型对应的第二分类信息;并根据第一分类信息和第二分类信息,得到分类结果。可以在一定程度上提高对胶质瘤分型的准确率。
附图说明
26.图1为本公开一示例性实施例示出的胶质瘤的类型识别方法的流程示意图;
27.图2为本公开另一示例性实施例示出的胶质瘤的类型识别方法的流程示意图;
28.图3为本公开一示例性实施例示出的特征向量的融合过程的示意图;
29.图4为本公开一示例性实施例示出的模型训练方法的流程示意图;
30.图5为本公开一示例性实施例示出的胶质瘤的类型识别过程示意图;
31.图6为本公开一示例性实施例示出的胶质瘤的类型识别装置的结构图;
32.图7为本公开一示例性实施例示出的模型训练装置的结构图;
33.图8为本公开一示例性实施例示出的电子设备的结构图。
具体实施方式
34.胶质瘤是最常见的原发性脑肿瘤,也是颅内最常见的恶性肿瘤。胶质瘤约占所有脑和中枢神经系统肿瘤的30%,占所有恶性脑肿瘤的80%。根据其组织学形态特征,胶质瘤被划分为星形细胞瘤、少突胶质细胞瘤和室管膜瘤三种类型。胶质瘤的准确分型十分重要。现有技术中,对胶质瘤的分型主要依靠病理科医生观察组织病理图像,通过组织学形态特征来确认分型。
35.但是,现有技术仍然存在以下问题:1)胶质瘤不同类型之间存在一定的相似性,人工方式具有较强的主观性、且准确率有待提高;2)对于少突胶质细胞瘤的分型判断依赖异柠檬酸脱氢酶(isocitrate dehydrogenase,idh)基因突变状态和染色体1p/19q共缺失状态,通过基因测序获得;成本高且效率较低。
36.为了解决上述技术问题,本公开提供的方案中,可以通过识别模型中的第一通道得到每种类型对应的第一分类信息以及与每种类型对应的目标向量;通过第二通道对目标向量进行处理,得到每种类型对应的第二分类信息;并根据第一分类信息和第二分类信息,得到分类结果。可以在一定程度上提高对胶质瘤分型的准确率和效率,且无需通过基因测序获取idh基因突变状态等分子信息也可获得较高的准确率。
37.图1为本公开一示例性实施例示出的胶质瘤的类型识别方法的流程示意图。
38.如图1所示,本实施例提供的胶质瘤的类型识别方法包括:
39.步骤101,获取胶质瘤的组织病理图像。
40.其中,本公开提供的方法可以由具备计算能力的电子设备来执行,比如可以是计算机等设备。该电子设备能够获取胶质瘤的组织病理图像。
41.其中,胶质瘤的组织病理图像为胶质瘤组织病理全扫描图像。具体的,可以通过扫描仪扫描胶质瘤的组织切片,得到质瘤的组织切片在扫描仪下的图像,将该图像数字化后,得到胶质瘤的组织病理图像。其中,扫描仪可以为光学显微镜。
42.步骤102,将组织病理图像输入至预设的识别模型中,基于识别模型中的特征提取模块提取胶质瘤中各目标图块的各特征向量,基于识别模型中的第一通道对各特征向量进行处理,得到与每种类型对应的第一分类信息以及与每种类型对应的目标向量,基于识别模型中的第二通道对目标向量进行处理,得到与每种类型对应的第二分类信息;基于识别模型中的整合模块对第一分类信息和第二分类信息进行处理,得到组织病理图像中的胶质瘤的目标分类结果;其中,识别模型是使用训练数据集训练得到的,训练数据集中包括多组训练数据,训练数据包括胶质瘤的组织病理图像,以及组织病理图像中胶质瘤的标注类型。
43.具体的,可以先将输入至预设的识别模型中的组织病理图像划分成大小相等的多块目标图块;并利用识别模型中的特征提取模块提取胶质瘤中各目标图块的各特征向量。具体的,可以采用卷积神经网络(convolutional neural networks,cnn),提取各目标图块
的各特征向量。
44.具体的,利用识别模型中的第一通道,对各特征向量进行处理,得到每种类型对应的第一分类信息以及与每种类型对应的目标向量。其中,识别模型可以识别多种类型,第一通道对各特征向量进行处理后,可以得到每种类型对应的第一分类信息。其中,第一分类信息可以表征胶质瘤所属类型的概率。具体的,可以将与每种类型的第一分类信息对应的特征向量确定为目标向量;目标向量可以有多个。
45.具体的,可以将与每种类型对应的目标向量输入至第二通道中,基于第二通道对目标向量进行处理,得到与每种类型对应的第二分类信息。其中,第二分类信息可以表征胶质瘤所属类型的概率。
46.具体的,整合模块可以基于与每种类型对应的第一分类信息和第二分类信息,得到胶质瘤的目标分类结果。
47.进一步的,识别模型为预先使用训练数据集训练得到的。其中,训练数据集中包括多组训练数据,训练数据包括胶质瘤的组织病理图像,以及组织病理图像中胶质瘤的标注类型。
48.具体的,通过标注类别训练得到的识别模型,能够识别的类型与标注类别中包括的类型相同。具体的,标注类型可以包括多种类型,比如,可以包括星形细胞瘤、少突胶质细胞瘤和室管膜瘤。
49.本公开提供的胶质瘤的类型识别方法,包括:获取胶质瘤的组织病理图像;将组织病理图像输入至预设的识别模型中,基于识别模型中的特征提取模块提取胶质瘤中各目标图块的各特征向量,基于识别模型中的第一通道对各特征向量进行处理,得到与每种类型对应的第一分类信息以及与每种类型对应的目标向量,基于识别模型中的第二通道对目标向量进行处理,得到与每种类型对应的第二分类信息;基于识别模型中的整合模块对第一分类信息和第二分类信息进行处理,得到组织病理图像中的胶质瘤的目标分类结果;其中,识别模型是使用训练数据集训练得到的,训练数据集中包括多组训练数据,训练数据包括胶质瘤的组织病理图像,以及组织病理图像中胶质瘤的标注类型。本公开采用的方法中,可以通过识别模型中的第一通道得到每种类型对应的第一分类信息以及与每种类型对应的目标向量;通过第二通道对目标向量进行处理,得到每种类型对应的第二分类信息;并根据第一分类信息和第二分类信息,得到分类结果。可以在一定程度上提高对胶质瘤分型的准确率和效率,且无需通过基因测序获取idh基因突变状态等分子信息也可获得较高的准确率。
50.图2为本公开另一示例性实施例示出的胶质瘤的类型识别方法的流程示意图。
51.如图2所示,本实施例提供的胶质瘤的类型识别方法包括:
52.步骤201,获取胶质瘤的组织病理图像。
53.具体的,步骤201与步骤101的原理、实现方式类似,不再赘述。
54.步骤202,将组织病理图像输入至预设的识别模型中,对组织病理图像进行预处理,得到胶质瘤的第一图像;其中,识别模型是使用训练数据集训练得到的,训练数据集中包括多组训练数据,训练数据包括胶质瘤的组织病理图像,以及组织病理图像中胶质瘤的标注类型。
55.具体的,由于完整的胶质瘤组织病理全扫描图像分辨率极高,可以达到10
11
像素级
别,受计算量的限制,直接将这类图像作为神经网络的输入是不现实的。因此,本方案可以先将组织病理图像切分成固定大小的图块,再对这些图块进行分析处理。
56.考虑到病理切片中存在大量的空白部分和被切碎的零散组织,这些区域对于类型识别意义不大。为了进一步降低计算量,本方案可以先提取出组织病理图像中主干组织部分,再在主干组织部分中提取图块,这样可以降低无意义样本对模型的干扰。
57.具体的,识别模型为预先使用训练数据集训练得到的。其中,训练数据集中包括多组训练数据,训练数据包括胶质瘤的组织病理图像,以及组织病理图像中胶质瘤的标注类型。
58.具体的,通过标注类别训练得到的识别模型,能够识别的类型与标注类别中包括的类型相同。具体的,标注类型可以包括多种类型,比如,可以包括星形细胞瘤、少突胶质细胞瘤和室管膜瘤。
59.在一种可实现方式中,根据预设比例值,压缩组织病理图像,得到压缩后的组织病理图像。
60.具体的,预设比例值比如可以为1/16。具体的,可以将组织病理图像压缩为原来的1/16,得到压缩后的组织病理图像。
61.根据压缩后的组织病理图像,以及预设的色相值、预设的饱和度值,确定胶质瘤的第二图像。
62.具体的,组织病理图像可以为基于苏木精-伊红染色的组织病理切片得到的图像。基于苏木精-伊红染色的组织病理切片呈现出细胞核染色为蓝紫色、细胞质染色为不同程度的红色的特点,本实施例中可以将压缩后的组织病理图像从rgb空间转换到hsv空间,以便通过色相和饱和度实现对被染色的组织区域的筛选。
63.其中,预设的色相值的范围可以为[0,20]或[160,360];预设的饱和度值可以为30。在hsv空间中,可以以色相值处于[0,20]或[160,360]范围内、饱和度值在30以上为标准,只保留符合标准的像素,得到胶质瘤的第二图像。
[0064]
其中,rgb色彩模式是工业界的一种颜色标准,是通过对红(r)、绿(g)、蓝(b)三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的,rgb即是代表红、绿、蓝三个通道的颜色,这个标准几乎包括了人类视力所能感知的所有颜色,是目前运用最广的颜色系统之一。
[0065]
其中,hsv(hue saturation value)是根据颜色的直观特性由a.r.smith在1978年创建的一种颜色空间,也称六角锥体模型(hexcone model)。这个模型中颜色的参数分别是:色调(hue,h),饱和度(saturation,s),明度(value,v)。
[0066]
对第二图像进行二值化处理,得到二值化处理后的图像;并对二值化处理后的图像进行中值滤波,得到第一图像。
[0067]
其中,图像二值化就是将图像上的像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的黑白效果。
[0068]
具体的,对二值化处理后的图像进行中值滤波,可以去除孤立噪声点,实现对细碎组织的剔除。
[0069]
步骤203,根据第一图像、预设滑动窗口,确定胶质瘤的中的各目标图块。
[0070]
具体的,可以利用预设滑动窗口在第一图像上滑动,来确定胶质瘤的中的各目标
图块。
[0071]
在一种可实现方式中,利用预设滑动窗口在第一图像上进行滑动,得到多个第一待选图块。
[0072]
具体的,预设滑动窗口为根据实际情况预先设置的。其中,预设滑动窗口包括预设的滑动窗口尺寸和预设的步长。其中,预设的滑动窗口尺寸可以为64*64;预设的步长可以为64。
[0073]
若第一待选图块的像素值大于预设像素值,则确定第一待选图块为第二待选图块。
[0074]
其中,预设像素值为根据实际情况预设设置的像素值。
[0075]
可选的,可以将第二图像为掩模,利用预设滑动窗口在该掩模上进行滑动,得到多个第一待选图块,若第一待选图块的像素值大于预设的像素值,则确定该第一待选图块为第二待选图块。
[0076]
具体的,第二待选图块即为筛选出的胶质瘤的主干组织部分。
[0077]
将与第二待选图块对应的组织病理图像中的区域,确定为目标图块。
[0078]
具体的,将第二待选图块在第二图像中的位置映射回组织病理图像,得到与第二待选图块对应的组织病理图像中的区域,该区域组成的图块,即为目标图块。
[0079]
步骤204,利用特征提取模块提取目标图块的特征,得到目标图块的特征向量。
[0080]
具体的,可以使用imagenet预训练的cnn网络提取每个目标图块的特征向量。
[0081]
其中,imagenet是一个计算机视觉系统识别项目名称,是图像识别数据库。是模拟人类的识别系统建立的。
[0082]
步骤205,将特征向量输入至第一通道中与每种类型对应的全连接层中,得到特征向量与每种类型对应的中间分类信息。
[0083]
其中,识别模型可以为基于cnn创建的模型。其中,识别模型包括的第一通道中,可以包括多个全连接层。其中,全连接层可以对输入的每个特征向量进行处理得到特征向量与类型对应的中间分类信息。
[0084]
其中,中间分类信息可以表征胶质瘤所属类型的概率。
[0085]
具体的,胶质瘤可以包括多种类型,因此每个特征向量可以对应多个中间分类信息。
[0086]
步骤206,在与类型对应的中间分类信息中确定与类型对应的第一分类信息。
[0087]
具体的,在多个与类型对应的中间分类信息中,可以提取最具代表性的一个作为与该类型对应的第一分类信息。比如,可以将表征该类型最大概率的中间分类信息确定为第一分类信息。
[0088]
在一种可实现方式中,类型的中间分类信息用于表征胶质瘤属于类型的概率值;将用于表征胶质瘤属于类型概率最大的概率值确定为类型的第一分类信息。
[0089]
具体的,若类型的中间分类信息表征胶质瘤属于类型的概率值;则将用于表征胶质瘤属于类型概率最大的概率值确定为类型的第一分类信息。
[0090]
步骤207,将与第一分类信息对应的特征向量,确定为与类型对应的目标向量。
[0091]
具体的,将与作为第一分类信息的中间分类信息对应的特征向量,确定为与类型对应的目标向量。
[0092]
具体的,每种类型都有对应的目标向量,且每种类型对应的目标向量可以不同。
[0093]
步骤208,融合第一特征向量和各第二特征向量,得到第一特征向量对应的第一融合向量;其中,第二特征向量是与第一特征向量相邻的特征向量。
[0094]
具体的,可以通过预设滑动窗口得到多个图块,可以根据图块获取的时间顺序给多个图块排序。每个图块对应一个特征向量。可以按照图块的顺序给特征向量排序。每个特征向量与其前一个和后一个特征向量相邻。第一个特征向量与第二个和最后一个特征向量相邻。最后一个特征向量与第一个和倒数第二个特征向量相邻。
[0095]
在一种可实现方式中,根据第一特征向量和各第二特征向量,确定第一特征向量与自身的第一注意力权重,以及第一特征向量与各第二特征向量之间的各第二注意力权重。
[0096]
具体的,第二通道中可以包括三个全连接层,每个特征向量分别通过这三个全连接层,得到三个向量;可以通过每个特征向量对应的这三个向量,确定第一注意力权重和第二注意力权重。
[0097]
具体的,第一注意力权重的公式如下:
[0098][0099]
q0=x0*wq[0100]
k0=x0*wk[0101]
其中,wq,wk,分别为第二通道包括的两个全连接层,可以令wq,wk∈r
1024*256
;x0为第一特征向量,为d维向量,可以令d=1024;dk为超参数,可以令dk=64;t表示转置;q0为x0通过wq得到的向量,可以令q0∈r
256
;k0为x0通过wk得到的向量,可以令k0∈r
256
。
[0102]
第二注意力权重的公式如下:
[0103][0104]
q0=x0*wq[0105]
k1=x1*wk其中,wq,wk,分别为第二通道包括的两个全连接层,可以令wq,wk∈r
1024*256
;x0为第一特征向量,为d维向量;x1为第二特征向量,为d维向量,可以令d=1024;dk为超参数,可以令dk=64;t表示转置;q0为x0通过wq得到的向量,可以令q0∈r
256
;k1为x1通过wk得到的向量,可以令k1∈r
256
。
[0106]
根据第一特征向量和第一注意力权重确定第一乘积,根据第二特征向量和与第二特征向量对应的第二注意力权重,确定第二乘积;将第一乘积和各第二乘积之和确定为第一特征向量的第一融合向量。
[0107]
具体的,第一融合向量的公式如下所示:
[0108][0109]
q0=x0*wq;q1=x1*wq;q2=x2*wq[0110]
k0=x0*wk;k1=x1*wk;k2=x2*wk[0111]v0
=x0*wv;v1=x1*wv;v2=x2*wv[0112]
其中,wq,wk,wv分别为第二通道包括的三个全连接层可以令wq,wk,wv∈r
1024*256
;x0为第一特征向量,为d维向量;x1和x2第二特征向量,都为d维向量,可以令d=1024;dk为超参数,可以令dk=64;t表示转置;softmax表示归一算法;q0为x0通过wq得到的向量,可以令q0∈r
256
;k0为x0通过wk得到的向量,可以令k0∈r
256
;v0为x0通过wv得到的向量,可以令v0∈r
256
;q1为x1通过wq得到的向量,可以令q1∈r
256
;k1为x1通过wk得到的向量,可以令k1∈r
256
;v1为x1通过wv得到的向量,可以令v0∈r
256
;q2为x2通过wq得到的向量,可以令q2∈r
256
;k2为x2通过wk得到的向量,可以令k2∈r
256
;v2为x2通过wv得到的向量,可以令v2∈r
256
。
[0113]
步骤209,融合目标向量和各第一融合向量,得到与目标向量对应的第二融合向量。
[0114]
具体的,每个类型对应一个目标向量,将每个目标向量与各第一融合向量进行融合,得到与该目标向量对应的第二融合向量。
[0115]
在一种可实现方式中,根据目标向量和各第一融合向量,确定目标向量与各第一融合向量之间的各第三注意力权重。
[0116]
具体的,第三注意力权重的公式如下所示:
[0117][0118]
q4=x4*wq[0119]
k5=x5*wk[0120]
其中,wq,wk,分别为第二通道包括的两个全连接层,可以令wq,wk∈r
1024*256
;x4为目标向量,为d维向量;x5为第一融合向量,为d维向量,可以令d=1024;dk为超参数,可以令dk=64;t表示转置;q4为x4通过wq得到的向量,可以令q0∈r
256
;k5为x5通过wk得到的向量,可以令k5∈r
256
。
[0121]
根据第一融合向量和与第一融合向量对应的第三注意力权重,确定第三乘积;将各第三乘积之和确定为目标向量的第二融合向量。
[0122]
具体的,第二融合向量的公式如下所示:
[0123][0124]
q4=x4*wq;km=xm*wk;vm=xm*wv[0125]
其中,wq,wk,wv分别为第二通道包括的三个全连接层,可以令wq,wk,wv∈r
1024*256
;x4为目标向量,为d维向量;xm表示第m个第一融合向量,为d维向量,可以令d=1024;dk为超参数,可以令dk=64;n表示第一融合向量的总个数;t表示转置;softmax表示归一算法;q4为x4通过wq得到的向量,可以令q4∈r
256
;km为xm通过wk得到的向量,可以令km∈r
256
;vm为xm通过wv得到的向量,可以令vm∈r
256
。
[0126]
具体的,本实施例中提供的特征向量融合方式如图3所示,其中,外圈中的圆表示特征向量,圆心处的圆表示目标向量。每个特征向量首先与相邻的两个特征向量进行融合得到第一融合向量;目标向量再与所有的第一融合向量进行融合,得到第二融合向量。
[0127]
步骤210,根据各目标向量对应的各第二融合向量,确定与每种类型对应的第二分类信息。
[0128]
具体的,每种类型都有对应的目标向量,每个目标向量都对应一个第二融合向量,因此每种类型都有对应的第二融合向量。利用与类型对应的第二融合向量可以确定该类型的第二分类信息。
[0129]
其中,第二分类信息可以用于表征胶质瘤所属类型的概率。
[0130]
步骤211,第一分类信息为第一概率值,第二分类信息为第二概率值;根据与各类型对应的第一概率值、第二概率值,确定与各类型对应的总概率。
[0131]
具体的,与各类型对应的总概率公式如下所示:
[0132][0133]
其中,i表示第i个类型;k表示类型总数;表示第i种类型的第一概率值;表示第i种类型的第二概率值;ci表示第i种类型的总概率值。
[0134]
步骤212,根据各类型的总概率,在各类型中确定目标分类结果。
[0135]
具体的,将各类型中总概率最大的类型,确定为目标分类结果。
[0136]
图4为本公开一示例性实施例示出的模型训练方法的流程示意图。
[0137]
如图4所示,本实施例提供的模型训练方法包括:
[0138]
步骤401,获取训练数据集;其中,训练数据集中包括多组训练数据,训练数据包括胶质瘤的组织病理图像,以及胶质瘤的标注类型。
[0139]
具体的,训练数据集可以为x医院的历史胶质瘤组织病理图像。
[0140]
步骤402,将胶质瘤的组织病理图像输入至预设模型中,得到组织病理图像中的胶
质瘤的预测类型;根据胶质瘤的标注类型和预测类型,优化预设模型中的参数,得到识别模型;其中,识别模型用于识别胶质瘤的类型。
[0141]
具体的,通过标注类别训练得到的识别模型,能够识别的类型与标注类别中包括的类型相同。具体的,标注类型可以包括多种类型,比如,可以包括星形细胞瘤、少突胶质细胞瘤和室管膜瘤。
[0142]
图5为本公开一示例性实施例示出的胶质瘤的类型识别过程示意图。
[0143]
如图5所示,可以通过扫描仪扫描胶质瘤的组织切片获得胶质瘤的组织病理图像,接着从胶质瘤的组织病理图像中提取多个图块;利用cnn方法将图块转化为特征向量;
[0144]
利用第一通道处理各特征向量并进行类型预测,得到与各类型对应的第一分类信息以及与各类型对应的目标向量;
[0145]
利用第二通道处理各特征向量,将每个特征向量与其相邻的两个特征向量进行融合,得到与每个特征向量对应的第一融合向量;
[0146]
利用第二通道将目标向量与多个第一融合向量进行融合,得到第二融合向量;根据多个第二融合向量确定与各类型对应的第二分类信息;
[0147]
根据第一分类信息和第二分类信息确定各类型对应的总概率;并根据各类型的总概率,在各类型中确定目标分类结果。
[0148]
图6为本公开一示例性实施例示出的胶质瘤的类型识别装置的结构图。
[0149]
如图6所示,本公开提供的胶质瘤的类型识别装置600,包括:
[0150]
获取单元610,用于获取胶质瘤的组织病理图像;
[0151]
识别单元620,用于将组织病理图像输入至预设的识别模型中,基于识别模型中的特征提取模块提取胶质瘤中各目标图块的各特征向量,基于识别模型中的第一通道对各特征向量进行处理,得到与每种类型对应的第一分类信息以及与每种类型对应的目标向量,基于识别模型中的第二通道对目标向量进行处理,得到与每种类型对应的第二分类信息;基于识别模型中的整合模块对第一分类信息和第二分类信息进行处理,得到组织病理图像中的胶质瘤的目标分类结果;
[0152]
其中,识别模型是使用训练数据集训练得到的,训练数据集中包括多组训练数据,训练数据包括胶质瘤的组织病理图像,以及组织病理图像中胶质瘤的标注类型。
[0153]
识别单元620,具体用于将特征向量输入至第一通道中与每种类型对应的全连接层中,得到特征向量与每种类型对应的中间分类信息;
[0154]
在与类型对应的中间分类信息中确定与类型对应的第一分类信息;
[0155]
将与第一分类信息对应的特征向量,确定为与类型对应的目标向量。
[0156]
识别单元620,具体用于类型的中间分类信息用于表征胶质瘤属于类型的概率值;将用于表征胶质瘤属于类型概率最大的概率值确定为类型的第一分类信息。
[0157]
识别单元620,具体用于融合第一特征向量和各第二特征向量,得到第一特征向量对应的第一融合向量;其中,第二特征向量是与第一特征向量相邻的特征向量;
[0158]
融合目标向量和各第一融合向量,得到与目标向量对应的第二融合向量;
[0159]
根据各目标向量对应的各第二融合向量,确定与每种类型对应的第二分类信息。
[0160]
识别单元620,具体用于根据第一特征向量和各第二特征向量,确定第一特征向量与自身的第一注意力权重,以及第一特征向量与各第二特征向量之间的各第二注意力权
重;
[0161]
根据第一特征向量和第一注意力权重确定第一乘积,根据第二特征向量和与第二特征向量对应的第二注意力权重,确定第二乘积;将第一乘积和各第二乘积之和确定为第一特征向量的第一融合向量。
[0162]
识别单元620,具体用于根据目标向量和各第一融合向量,确定目标向量与自身的第三注意力权重,以及目标向量与各第一融合向量之间的各第四注意力权重;
[0163]
根据目标向量和第三注意力权重确定第三乘积,根据第一融合向量和与第一融合向量对应的第四注意力权重,确定第四乘积;将第三乘积和各第四乘积之和确定为目标向量的第二融合向量。
[0164]
识别单元620,具体用于第一分类信息为第一概率值,第二分类信息为第二概率值;根据与各类型对应的第一概率值、第二概率值,确定与各类型对应的总概率;
[0165]
根据各类型的总概率,在各类型中确定目标分类结果。
[0166]
识别单元620,具体用于对组织病理图像进行预处理,得到胶质瘤的第一图像;
[0167]
根据第一图像、预设滑动窗口,确定胶质瘤的中的各目标图块;
[0168]
利用特征提取模块提取目标图块的特征,得到目标图块的特征向量。
[0169]
识别单元620,具体用于根据预设比例值,压缩组织病理图像,得到压缩后的组织病理图像;
[0170]
根据压缩后的组织病理图像,以及预设的色相值、预设的饱和度值,确定胶质瘤的第二图像;
[0171]
对第二图像进行二值化处理,得到二值化处理后的图像;并对二值化处理后的图像进行中值滤波,得到第一图像。
[0172]
识别单元620,具体用于利用预设滑动窗口在第一图像上进行滑动,得到多个第一待选图块;
[0173]
若待选图块的像素值大于预设像素值,则确定第一待选图块为第二待选图块;
[0174]
将与第二待选图块对应的组织病理图像中的区域,确定为目标图块。
[0175]
图7为本公开一示例性实施例示出的模型训练装置的结构图。
[0176]
如图7所示,本公开提供的模型训练装置700,包括:
[0177]
获取单元710,用于获取训练数据集;其中,训练数据集中包括多组训练数据,训练数据包括胶质瘤的组织病理图像,以及胶质瘤的标注类型;
[0178]
训练单元720,用于将胶质瘤的组织病理图像输入至预设模型中,得到组织病理图像中的胶质瘤的预测类型;根据胶质瘤的标注类型和预测类型,优化预设模型中的参数,得到识别模型;其中,识别模型用于识别胶质瘤的类型。
[0179]
图8为本公开一示例性实施例示出的电子设备的结构图。
[0180]
如图8所示,本实施例提供的电子设备包括:
[0181]
存储器801;
[0182]
处理器802;以及
[0183]
计算机程序;
[0184]
其中,计算机程序存储在存储器801中,并配置为由处理器802执行以实现如上的任一种方法。
[0185]
本实施例还提供一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行以实现如上的任一种方法。
[0186]
本实施例还提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时,实现上述任一种方法。
[0187]
本领域普通技术人员可以理解:实现上述各方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成。前述的程序可以存储于一计算机可读取存储介质中。该程序在执行时,执行包括上述各方法实施例的步骤;而前述的存储介质包括:rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。
[0188]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1