一种基于时效近邻可信选取的协同过滤推荐方法及系统
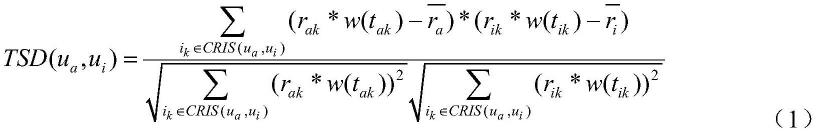
1.本发明涉及信息推荐技术,具体涉及一种基于时效近邻可信选取的协同过滤推荐方法及系统。
背景技术:
2.近年来随着社会生产与人们生活大规模向信息空间迁移,信息过载所引发的信息迷航现象日趋严重。为帮助人们从急剧膨胀的数据中筛选出有用信息,推荐系统应运而生。当前基于内容的推荐、协同过滤推荐、基于关联规则的推荐、基于效用的推荐、基于知识的推荐以及混合推荐等技术已广泛应用于各类电子商务平台,用于提升用户粘度、降低服务跳出率、助力用户构建信息茧房。据统计,netflix上80%被观看的电影、youtube上60%的视频点击量和google上38%的新闻点击量均源自于推荐;amazon上30%的商品页面浏览量、20%~30%的商品销售量,以及35%的销售收入均由个性化推荐所贡献。
3.其中,作为电子商务推荐系统中应用最成功的推荐技术之一,协同过滤推荐的基本思想是相似的用户可能会喜欢同一种物品、相似的物品可能会被同一个用户喜欢。虽然该类推荐具备无需领域知识、对推荐对象无特殊要求、易解释、便于工程实现等优势,然而传统的协同过滤推荐通常基于数据是静态的假设,在数据稀疏时存在推荐精度低下的问题。
4.为提高协同过滤推荐精度,一些研究尝试在推荐策略中添加有关用户兴趣变化的描述信息,例如:
5.liu提出一种基于聚类的协同过滤推荐算法,该算法利用时间衰减函数对用户评分进行预处理,使用兴趣向量对用户进行描述,使用聚类算法对用户进行聚类,实现了反映用户兴趣变化的多维度画像。董晨露等人提出一种基于用户兴趣变化和评论的协同过滤算法,该算法利用主题模型从评论文本中挖掘商品主题特征,利用艾宾浩斯遗忘曲线协助计算用户评论相似度,并结合用户评论相似度和评分相似度来获取用户之间的最终相似度。xu等人基于每个领域的专家都更具说服力、用户兴趣会随时间推移而变化的事实,提出一种基于用户可信度和时间上下文的协同过滤推荐算法,通过将这两个因素纳入到基于修正的余弦相似度模型,提高了用户间相似度计算的准确度。li等人依据推荐需要契合用户短期兴趣的事实,提出了一种使用社会信息和动态时间窗口的协同过滤算法,该算法依据艾宾浩斯遗忘曲线,借助细分时间窗口来界定用户的短期兴趣,引入时间函数区分各短期兴趣的重要度,实现对用户兴趣变化的及时捕捉。
6.然而,以上技术方案对恶意用户为干扰或误导推荐所实施的异常兴趣变迁现象并没有关注。以协同过滤推荐中常见的用户概貌攻击为例,恶意用户完全可以在目标用户已评分项目的评分上通过刻意迎合目标用户的兴趣来获取目标用户相似用户(近邻)身份,之后通过在目标用户未评分项目上实施策略评分,从而达到干扰或误导推荐的目的。与目标用户兴趣的正常变化不同,这种潜藏在恶意用户策略评分背后的兴趣异常变化如果得不到有效处置,势必会削弱推荐系统的抗攻击能力。
7.另外,目前也有人通过在推荐中引入信任关系来提高推荐精度和系统鲁棒性,例如:
8.陈婷等人提出一种社交网络环境下基于信任的推荐算法,但该算法在利用由评分数据产生的相似度和信任关系产生的信任度融合构建的用户偏好模型寻找邻居时,尚未对信任关系的动态性进行关注。wang等人针对智慧城市中面向用户轨迹行为序列预测的兴趣点推荐,将地理位置和时间信息纳入到基于兴趣点偏好的相似度计算模型,给出了具备信任增强的用户相似度计算方法,但该方法将评分时间简单地切分为24个时区的做法,无法在细粒度层面上可靠地反映用户信度随时间变化的情况。wang等人提出一种新的基于信任的协同过滤算法,但是如何保证所使用的信任度在时间跨度上具有一致性和可靠性并没有提及。贾冬艳等人提出一种基于双重邻居选取策略的协同过滤推荐算法,利用信度来刻画用户的推荐能力,但该算法对目标用户的兴趣变迁和近邻用户的信度波动欠缺考虑,推荐系统的推荐精度和抗攻击能力还有提升的空间。
9.综上所述,现有技术未能对推荐中出现的用户兴趣异常变迁和用户信度波动这两个可能会对推荐结果造成干扰或误导的问题进行处置,使得推荐系统的抗攻击性、推荐稳定性与可信性均难得到保证。
技术实现要素:
10.发明目的:本发明的目的在于解决现有技术中存在的不足,提供一种基于时效近邻可信选取的协同过滤推荐方法及系统。
11.技术方案:本发明的一种基于时效近邻可信选取的协同过滤推荐方法,设定六元组cfrs=《u,i,r,ua,ib,r
ab
》,u={u1,u2,
…
,ui,
…
,um}是由m个用户ui所组成的用户集,1≤i≤m;i={i1,i2,
…
,ij,
…
,im}是由n个项目ij所组成的项目集,1≤j≤n;r={r
ij
}
m*n
是由m*n个评分r
ij
所组成的评分矩阵,r
ij
表示ui对ij的评分,若表示ui对ij暂未评分;依据评分矩阵r来预测目标用户ua在目标项目ib上评分r
ab
的具体步骤如下:
12.步骤s1、时效近邻筛选
13.先使用时效权重函数w(t)计算目标用户邻居在共同评分项目上的评分时效权重,然后通过纳入有时效权重的基于皮尔逊相关系数的兴趣相似度计算模型来计算出每个邻居与目标用户的时效相似度,最后依据时效相似度为目标用户动态筛选出时效近邻;
14.步骤s2、可信近邻选取
15.先利用项目级信任计算模型对步骤s1中筛选出的时效近邻的推荐能力进行推荐信度初估,然后利用pid控制器变体模型对推荐信度初估值进行重估,最后依据推荐信度重估值为目标用户动态选取可信近邻;
16.步骤s3、评分预测
17.先逐个依据每个可信近邻的推荐信度计算出其自身在目标项目上的推荐权重,然后利用所有可信近邻在目标项目上的评分来预测出目标用户对该项目的评分,进而完成向目标用户进行项目推荐。
18.上述技术方案充分考虑影响目标用户近邻筛选质量的用户兴趣异常变化和推荐能力可信度波动两个关键因素,构建包含时效近邻筛选、可信近邻选取和评分预测三个策略的推荐流程。
19.进一步地,所述步骤s1的详细过程为:
20.步骤s1.1、通过兴趣相似度计算目标用户ua与其邻居用户ui∈ns(ua)的时效相似度tsd(ua,ui);
[0021][0022]
式(1)中,r
ak
和r
ik
分别为ua和ui对项目ik∈cris(ua,ui)的评分;表示ua在其对应评分项目ris(ua)中所有项目上的评分均值,表示ui在其对应评分项目集ris(ui)中所有项目上的评分均值;t
ak
和t
ik
分别为评分r
ak
和r
ik
的生成时间(标准化后的时间),w(t
ak
)和w(t
ik
)分别为r
ak
和r
ik
的时效权重;cris(ua,ui)为目标用户ua和其邻居用户ui的共同评分项目集,且cris(ua,ui)=ris(ua)∩ris(ui);
[0023]
步骤s1.2、计算目标用户ua与邻居集ns(ua)中所有用户的时效相似度阈值为:
[0024][0025]
ns(ua)为目标用户ua的邻居集,且
[0026]
步骤s1.3、为目标用户ua筛选其对应的时效近邻集tecns(ua);
[0027][0028]
进一步地,所述时效权重w(t
ak
)和w(t
ik
)通过时效权重函数w(t)来计算,w(t)表达式为:
[0029]
w(t)=logistic(t)=(1+e-t
)-1
;t∈[-1,1]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)。
[0030]
进一步地,所述步骤s2的详细过程为:
[0031]
s2.1、基于项目级信任计算模型对时效近邻集tecns(ua)中的时效近邻进行推荐信度初估;
[0032]
先利用时效近邻ui信息预测目标用户ua对第j个项目ij的评分即
[0033][0034]
然后利用预测评分来估计ua对ui的推荐满意度satj(ua,ui),即:
[0035][0036]
其中,常数ε为ua定义的推荐偏差值,第4节实验中取ε为1.2
[17]
.
[0037]
接着使用推荐满意度估计ua对ui的推荐信度原始值rrtj(ua,ui),即:
[0038][0039]
s2.2、通过推荐信度重估来修正推荐信度原始值rrtj与ui真实推荐行为之间的度量偏差,具体的推荐信度重估计算如下:
[0040]
rtj(ua,ui)=α*rrtj(ua,ui)+β*hrt
1j-1
(ua,ui)+γ*drtj(ua,ui)+δ*drtj(ua,ui)*|sdrtj(ua,ui)|;0《α,β,γ,δ《1
ꢀꢀꢀꢀꢀꢀꢀ
(7)
[0041]
上式中rrtj,hrt
1j-1
,drtj,sdrtj和rtj分别表示推荐信度原始值、历史值、变化率、变化趋势以及重估值;α,β,γ和δ为各部分对应的权重;
[0042]
hrt
1j-1
,drtj和sdrtj的计算公式见式10至式12,其中ρ(0《ρ≤1)和θ(0《θ≤1)分别为历史推荐信度及其变化率的关注因子;
[0043][0044][0045][0046]
s2.3、可信近邻筛选:将目标用户ua的时效近邻推荐信度集{rt(ua,ui)|ui∈tecns(ua)}中的元素按照从大到小排序,并选取前topk个推荐信度所对应的时效近邻ui作为ua的可信近邻。
[0047]
进一步地,所述α,β,γ和δ的取值如下:
[0048]
β/α正比于j-1,γ和δ遵循式8和式9;
[0049][0050][0051]
进一步地,所述步骤s3的详细方法为:
[0052]
针对目标项目ij,依据时效近邻集tcns(ua)中用户对ij的评分,预测出ua在ij上的评分
[0053][0054]
本发明还一种基于时效近邻可信选取的协同过滤推荐系统,包括时效近邻筛选单元、可信近邻选取单元和评分预测单元;
[0055]
时效近邻筛选单元先使用时效权重函数w(t)计算目标用户邻居在共同评分项目
上的评分时效权重,然后通过纳入有时效权重的基于皮尔逊相关系数的兴趣相似度计算模型来计算出每个邻居与目标用户的时效相似度,最后依据时效相似度为目标用户动态筛选出时效近邻;
[0056]
可信近邻选取单元先利用项目级信任计算模型对步骤s1中筛选出的时效近邻的推荐能力进行推荐信度初估,然后利用pid控制器变体模型对推荐信度初估值进行重估,最后依据推荐信度重估值为目标用户动态选取可信近邻;
[0057]
评分预测单元先依据每个可信近邻的推荐信度计算出各自在目标项目上的推荐权重,然后利用他们在目标项目上的评分来预测出目标用户对该项目的评分,进而完成向目标用户进行项目推荐。
[0058]
有益效果:与现有技术相比,本发明具有以下优点:
[0059]
(1)、本发明的基于时效近邻可信选取的协同过滤推荐方法,充分考虑用户兴趣异常变迁和推荐信度波动两个时变因素,顺序利用时效近邻筛选、可信近邻选取和目标用户评分预测三个步骤,完成向目标用户的推荐,缓解了数据稀疏情况下协同过滤推荐精度低、稳定性差、抗用户概貌注入攻击力弱的问题。
[0060]
(2)本发明中提出一种基于兴趣时效相似度的时效近邻筛选策略,通过赋予传统的兴趣相似度时效性,使得评分相同但评分时间不同的用户在兴趣相似度上有所差异,缓解了传统基于用户兴趣相似度的近邻选取策略因为目标用户兴趣随时间变迁所导致的近邻选取不准确问题。
[0061]
(3)本发明中提出一种基于推荐信度的可信近邻选取策略,综合利用近邻推荐信度的原始值、历史值、当前变化率和未来趋势四方面因素对推荐信度进行重估,使得近邻无法利用策略波动的评分来改善他人对其推荐能力的信服程度,缓解了已有基于信度的近邻选取策略因为推荐信度不可靠所带来的目标用户近邻选取不可信的问题。
[0062]
(4)本发明中使用movielens数据集,基于平均绝对误差、平均预测增量、查准率、查全率和调和平均等指标,对本文所提策略与同类型策略进行了比较,证实了新方法在推荐精度(包括精度稳定性)和抗攻击力(包括攻击用户识别效果)上均有明显的提升。
附图说明
[0063]
图1为本发明的框架示意图。
具体实施方式
[0064]
下面对本发明技术方案进行详细说明,但是本发明的保护范围不局限于所述实施例。
[0065]
为便于进一步了解本发明技术方案,对下述符号参数做出解释。
[0066]
协同过滤推荐系统cfrs=《u,i,r,ua,ib,r
ab
》包含六个元素,其中u={u1,u2,
…
,ui,
…
,um}是由m个用户ui所组成的用户集,1≤i≤m;i={i1,i2,
…
,ij,
…
,im}是由n个项目ij所组成的项目集,1≤j≤n;r={r
ij
}
m*n
是由m*n个评分r
ij
所组成的评分矩阵,r
ij
表示ui对ij的评分,若表示ui对ij暂未评分。
[0067]
评分项目集,若用户ua对项目ij进行了评分,即则ij是ua的一个评分项目。用户ua的评分项目集ris(ua)是该用户所有评分项目形成的集合,即
[0068]
共同评分项目集,令ris(ua)和ris(ui)分别为用户ua和ui的评分项目集,则ua和ui的共同评分项目集cris(ua,ui)可表示为cris(ua,ui)=ris(ua)∩ris(ui).
[0069]
邻居集,令cris(ua,ui)为用户ua与用户ui的共同评分项目集,则ua的邻居集可表示为
[0070]
时效近邻集,令ns(ua)为用户ua的邻居集,tsd(ua,ui)为ua与用户ui的时效相似度,g
tsd
(ua)为ua限定的时效相似度阀值,则ua时效近邻集可表示为
[0071]
时效近邻信度集,令tecns(ua)为用户ua的时效近邻集,rt(ua,ui)为用户ui呈现给ua的推荐信度,则ua的时效近邻信度集可表示为
[0072]
可信近邻集,令tecns(ua)和tstecn(ua)分别为用户ua的时效近邻集和信度集,rt(ua,ui)为用户ui呈现给ua的推荐信度,则ua的可信近邻集可表示为其中topk({.})表示由{.}中前k个较大元素构成的集合。
[0073]
如图1所示,本实施例的基于时效近邻可信选取的协同过滤推荐方法,通过评分矩阵r来预测目标用户ua在目标项目ib上评分r
ab
,主要流程描述如下:
[0074]
(1)依据评分矩阵r,选取出目标用户ua的邻居集ns(ua);
[0075]
(2)依据兴趣时效相似度tsd(ua,*),利用算法1从邻居集ns(ua)中提取出ua的时效近邻集tecns(ua);
[0076]
(3)依据算法2计算到的推荐信度rt(ua,*),利用算法3从tecns(ua)中进一步筛选出ua的可信近邻集tcns(ua);
[0077]
(4)依据式13预测出ua对项目ij的评分完成项目推荐。
[0078][0079]
实施例1:本实施例的具体步骤如下:
[0080]
步骤s1、时效近邻筛选单元先使用时效权重函数w(t)计算目标用户邻居在共同评分项目上的评分时效权重,然后通过纳入有时效权重的基于皮尔逊相关系数的兴趣相似度计算模型来计算出每个邻居与目标用户的时效相似度,最后依据时效相似度为目标用户动态筛选出时效近邻。具体过程为:
[0081]
步骤s1.1、通过兴趣相似度计算目标用户ua与其邻居用户ui∈ns(ua)的时效相似度tsd(ua,ui);
[0082][0083]
式(1)中,r
ak
和r
ik
分别为ua和ui对项目ik∈cris(ua,ui)的评分;表示ua在其对应评分项目ris(ua)中所有项目上的评分均值,表示ui在其对应评分项目集ris(ui)中所有项目上的评分均值;t
ak
和t
ik
分别为评分r
ak
和r
ik
的生成时间(标准化后的时间),w(t
ak
)和w(t
ik
)为r
ak
和r
ik
的时效权重;cris(ua,ui)为目标用户ua和其邻居用户ui的共同评分项目集,且cris(ua,ui)=ris(ua)∩ris(ui);
[0084]
步骤s1.2、计算目标用户ua与邻居集ns(ua)中所有用户的时效相似度阈值为:
[0085][0086]
ns(ua)为目标用户ua的邻居集,且
[0087]
步骤s1.3、为目标用户ua筛选其对应的时效近邻集tecns(ua);
[0088][0089]
上述时效权重w(t
ak
)和w(t
ik
)通过时效权重函数w(t)来计算,w(t)表达式为:
[0090]
w(t)=logistic(t)=(1+e-t
)-1
;t∈[-1,1]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)。
[0091]
其中,对任一与目标用户ua存在共同评分项目的用户ui而言,其评分时间与ua越近,其与ua的兴趣时效相似度就越大。
[0092]
本实施例中时效近邻选取算法如算法1所示,描述如下:
[0093][0094]
算法1中第2步是获取目标用户ua的邻居集ns(ua);第3~6步是计算ua与邻居ui的时效相似度和ua的时效相似度阈值;第7~11步是依据g
tsd
(ua)为目标用户ua筛选时效近邻
集tecns(ua)。本实施例可取g
tsd
(ua)为ua与邻居集中所有用户时效相似度的均值。
[0095]
步骤s2、可信近邻选取单元先利用项目级信任计算模型对步骤s1中筛选出的时效近邻的推荐能力进行推荐信度初估,然后利用pid控制器变体模型对推荐信度初估值进行重估,最后依据推荐信度重估值为目标用户动态选取可信近邻。令ua为目标用户,ui为ua的时效近邻,即ui∈tecns(ua),ij为ua与ui的共同评分项目,即ij∈cris(ua,ui),r
aj
和r
ij
分别为ua和ui对ij的评分,和为ua和ui的评分均值,tsd(ua,ui)为ua和ui的时效相似度;cris(ua,ui)中项目元素按ui评分时间先后有序,且ij是该集合中第j个项目。
[0096]
详细过程为:
[0097]
s2.1、基于项目级信任计算模型对时效近邻集tecns(ua)中的时效近邻进行推荐信度初估;
[0098]
先利用时效近邻ui信息预测目标用户ua对第j个项目ij的评分即
[0099][0100]
然后利用预测评分来估计ua对ui的推荐满意度satj(ua,ui),即:
[0101][0102]
其中,常数ε为ua定义的推荐偏差值,第4节实验中取ε为1.2.
[0103]
接着使用推荐满意度估计ua对ui的推荐信度原始值rrtj(ua,ui),即:
[0104][0105]
s2.2、通过推荐信度重估来修正推荐信度原始值rrtj与ui真实推荐行为之间的度量偏差,具体的推荐信度重估计算如下:
[0106]
rtj(ua,ui)=α*rrtj(ua,ui)+β*hrt
1j-1
(ua,ui)+γ*drtj(ua,ui)+δ*drtj(ua,ui)*|sdrtj(ua,ui)|;0《α,β,γ,δ《1
ꢀꢀꢀꢀ
(7)
[0107]
上式中rrtj,hrt
1j-1
,drtj,sdrtj和rtj分别表示推荐信度原始值、历史值、变化率、变化趋势以及重估值;α,β,γ和δ为各部分对应的权重;
[0108]
hrt
1j-1
,drtj和sdrtj的计算公式见式10至式12,其中ρ(0《ρ≤1)和θ(0《θ≤1)分别为历史推荐信度及其变化率的关注因子;
[0109][0110][0111]
[0112]
上述推荐信度评估算法如算法2所示,描述如下:
[0113][0114]
s2.3、可信近邻筛选:将目标用户ua的时效近邻推荐信度集{rt(ua,ui)|ui∈tecns(ua)}中的元素按照从大到小排序,并选取前topk个推荐信度所对应的时效近邻ui作为ua的可信近邻。
[0115]
可信近邻筛选算法描述如下:
[0116][0117]
上述α,β,γ和δ的取值如下:
[0118]
β/α正比于j-1,γ和δ遵循式8和式9;
[0119]
[0120][0121]
步骤s3、评分预测单元先依据每个可信近邻的推荐信度计算出各自在目标项目上的推荐权重,然后利用他们在目标项目上的评分来预测出目标用户对该项目的评分,进而完成向目标用户进行项目推荐:
[0122]
针对目标项目ij,依据时效近邻集tcns(ua)中用户对ij的评分,预测出ua在ij上的评分
[0123][0124]
实施例2:表1为本实施例中目标用户mike及其邻居u
1-u7在项目i
1-i5上的评分及评分(标准化)时间,分别采用传统pcc和带时效权重的pcc对mike与7个邻居的相似度进行了计算。
[0125]
(1)前者获得的结果依次为{0.4852,0.3225,0.0369,0.0678,0.4111,0.3025,0.4135}(mike相似度阈值0.2914),筛选出的mike近邻集为{u1,u2,u5,u6,u7};
[0126]
(2)后者获得的结果依次为{0.5064,0.2965,0.0846,0.0791,0.4090,0.3001,0.4472}(mike时效相似度阈值0.3033),筛选出的mike时效近邻集为{u1,u5,u7}.
[0127]
以u6为例,其和u5虽然在评分值上与mike一致,但由于其与mike的评分时间间距远大于u5与mike的时间间距,导致其被带时效权重的pcc方法剔除在mike近邻之外。
[0128]
表1相似度计算
[0129][0130]
超参数分别取α=0.2,β=0.8,γ1=δ1=0.05,γ2=δ2=0.2,ρ=θ=1,则根据式(7)的推荐信度重估模型改进自pid控制策略,综合利用推荐信度原始值(p)、历史值(i)、变化率(d)和变化趋势(sd)四个分量,通过加权d分量实现了对推荐行为突发波动的度量、通过加权平均i、d和sd三个分量实现了对推荐行为改善与恶化的区分、通过加权平均p分量与i分量实现了对无意识错误推荐行为的容忍和一致性推荐行为的反映、通过加权平均d分量与sd分量实现了对推荐行为变化趋势的跟踪,提高了推荐信度与真实推荐行为的逼近度。
[0131]
若取ε=0.5,α=0.2,β=0.8,γ1=δ1=0.05,γ2=δ2=0.2,ρ=θ=1,如表2所示,依据算法2可求出u1,u5和u7的推荐信度分别为0.73,1.00和0.61。
[0132]
表2推荐信度评估
[0133][0134]
本实施例取k值为2,依据算法3可遴选到mike的可信近邻为u1和u5,topk为90%,最后利用算法4可求出mike对i3的预测评分为2.463。
[0135]
实验数据与平台
[0136]
实验在movielens-100k(约1000名用户在近1700部电影上约10万次评分,稀疏率约96.695%)和ml-latest-small(约610名用户在近9742部电影上100837次评分,稀疏率约98.303%)这两个movielens电影评分数据集上进行。movielens数据集在评级数据包含用户标识、电影标识、评分和时间戳等字段,其中,评分为用户对看过的电影的评级,分值为1(“不喜欢”)~5(“非常喜欢”),时间戳是评分提交时间与1970年元旦零点之间的秒数间隔。
[0137]
算法实现采用python 3.9.7和math库,实验所用机器配置如下:cpu(i7-11800h,2.30ghz)、内存(32g)、硬盘(1tb)、gpu(rtx3060 6gb)。
[0138]
性能评估指标
[0139]
本实施例采用的评估指标主要有2个,分别是:
[0140]
(1)、平均绝对误差(mean absolute error,mae)
[0141]
mae用于衡量预测评分与真实评分之间的误差。计算公式为:
[0142][0143]
式14中和r
aj
分别为目标用户ua在项目ij(1≤j≤n)上的预测评分与真实评分。mae值越小,算法推荐精度就越高。
[0144]
(2)、平均预测增量(average prediction shift,aps)
[0145]
aps用于衡量项目受攻击前后的系统预测的增量。计算公式为:
[0146][0147]
式(15)中和分别为项目受攻击前后目标用户ua在项目ij(1≤j≤n)上的预测评分。aps值越小,算法抗攻击能力就越强。
[0148]
此外,对攻击用户检测能力的评估拟采用3种常用的评估分类器度量标准:查准率、查全率和调和平均值。具体地,设tp是被正确识别为攻击用户的样本数、fn是被误判为非攻击用户的样本数、fp是被误判为攻击用户的样本数,则攻击用户查全率r=tp/(tp+fn),攻击用户查全率p=tp/(tp+fp),调和平均值f=2*p*r/(p+r)。
[0149]
推荐精度评估
[0150]
此处,为评估本发明技术方案的推荐精度,本实施例将本发明时效近邻选取策略(cf-tsd)、可信近邻确定策略(cf-rt)和时效近邻可信选取策略(cf-tecnts)的协同过滤推荐,与相关现有技术方的兴趣相似用户集(cf-psu)、用户信任计算模型(cf-utc)和双重邻
居选取策略(cf-dnc)的协同过滤推荐,以及项目集信任计算模型(cf-itc)的协同过滤推荐和传统的协同过滤推荐(cf)这8个同类型策略的推荐精度做了分类比较。
[0151]
实验使用movielens-100k数据集和mae评估指标,通过选取拥有不同数量的邻居的用户作为目标用户,计算出推荐偏差mae值如表3所示。
[0152]
表3不同策略的推荐偏差mae对比
[0153][0154][0155]
从表3可看出:
[0156]
(1)、在依据相似度筛选近邻的策略中,cf-psu和cf-tsd获得的mae明显低于cf(均值上分别降低了7.3616%和14.3482%),表明在近邻筛选时利用相似度阈值过滤掉低相似度用户能够提高近邻筛选质量,并进而提高系统推荐精度。再者,由于考虑了兴趣变迁,cf-tsd在mae波动程度上明显高于cf-psu,但其mae的整体均值却低于cf-psu(均值降低了7.5418%),表明依据本发明的兴趣时效相似度遴选近邻可进一步提升近邻筛选质量,并可带来更高的推荐精度。
[0157]
(2)、在依据信任度筛选近邻的策略中,cf-utc和cf-rt获得的mae低于cf-itc(均值分别降低了19.8553%和19.9555%),表明将用户信度从大众对其推荐能力的全局评价转变为目标用户个人的局部评价能够提升近邻筛选的针对性,从而提高推荐精度。再者,cf-rt在mae及其波动程度上均低于cf-utc(分别降低了0.1250%和68.7500%),表明依据本文提出的推荐信度遴选近邻,可以获得更稳定、更高的推荐精度。
[0158]
(3)、在融合相似度与信任度筛选近邻的策略中,cf-tecnts获得的mae及其波动程度均低于cf-dnc(分别降低了7.5778%和80.0000%),表明依据本文提出的时效近邻可信选取策略筛选近邻,可以获得更稳定、更高的推荐精度。
[0159]
(4)、cf-tecnts所展现出来的对用户兴趣变迁敏感反应的能力来自于cf-tsd、稳定推荐精度的能力来自于cf-rt。
[0160]
抗攻击力评估
[0161]
为评估本发明技术方案所提策略的抗攻击力,向ml-latest-small数据集中注入随机攻击数据。选取邻居用户数为40,攻击规模(虚假用户占比)分别为1%,3%,5%,10%,25%,填充规模(每个虚假用户的评分数占比)分别为1%,2%,5%,10%。随着攻击规模和填充规模的不断增大,8种策略的推荐偏差mae如表4所示。
[0162]
表4随机攻击下不同策略的推荐偏差mae对比
[0163][0164]
从表4可看出:
[0165]
(1)、在相同填充规模(攻击规模)下,随攻击规模(填充规模)的增大,8种策略的推荐mae基本上均呈现上升趋势,这表明系统中攻击越多,推荐质量也会越差;并且,相较于攻击规模对推荐mae的影响力而言,填充规模的影响力更大.
[0166]
(2)、在依据相似度筛选近邻的策略中,cf、cf-psu和cf-tsd三个策略的推荐mae逐渐降低(后者在均值上依次比前者降低63.1350%和3.0952%);在依据信任度筛选近邻的策略中,cf-itc、cf-utc和cf-rt三个策略的推荐mae逐渐降低(后者在均值上依次比前者降低72.0679%和0.0135%);在融合相似度与信任度筛选近邻的策略中,cf-tecnts的推荐mae在均值上比cf-dnc降低了6.9955%。
[0167]
表明本发明技术方案在随机攻击面前具有更低的推荐偏差。
[0168]
表5给出对应攻击规模与填充规模下8种策略的平均预测偏差。
[0169]
表5随机攻击下不同策略的预测偏差aps对比
[0170][0171]
从表5可以看出:
[0172]
(1)、在相同填充规模(攻击规模)下,随攻击规模(填充规模)的增大,8种策略的预测偏差aps基本上均呈现上升趋势,这表明系统中攻击越多,预测偏差也会越差;而且,相较于填充规模对预测偏差的影响程度而言,攻击规模的影响力表现得更大.
[0173]
(2)、在依据相似度筛选近邻的策略中,cf、cf-psu和cf-tsd三种策略的预测偏差aps逐渐降低(后者在均值上依次比前者降低72.8650%和63.4921%);在依据信任度筛选近邻的策略中,cf-itc、cf-utc和cf-rt三个策略的预测偏差aps逐渐降低(后者在均值上依次比前者降低92.4772%和1.7578%);在融合相似度与信任度筛选近邻的策略中,cf-tecnts的预测偏差aps在均值上比cf-dnc降低了11.4286%。
[0174]
这表明本发明技术方案在随机攻击面前具有更低的预测偏差。
[0175]
攻击用户检测能力评估
[0176]
采用ml-latest-small数据集,设定攻击规模和填充规模分别为25%和10%、邻居用户数为40,依据查全率、查准率和调和平均三项指标,表6给出了8种推荐策略检测随机攻击用户的能力比较。
[0177]
表6随机攻击下不同策略的攻击用户检测能力对比
[0178][0179]
从表6可看出,cf不具备攻击用户检测能力,而cf-psu和cf-tsd均检测到了数量不等的攻击用户,这表明在基于兴趣相似度的近邻筛选中,依据相似度阈值进行用户筛选能够对攻击用户进行显著过滤。相比于cf-psu,cf-tsd通过过滤掉更多的用户识别出更多的攻击用户,后者虽然在查准率上低于前者,但在查全率上较前者提升了35.9853%,这表明依据本发明技术放哪中的兴趣时效相似度筛选近邻能够排除掉更多的攻击用户。
[0180]
与上述类似,cf-itc也不具备检测攻击用户的能力,但cf-rt与cf-utc均检测到了一定数量的攻击用户,这表明依据信任度进行近邻筛选能够有效过滤到攻击用户。同时,cf-rt的攻击用户检测能力在随机攻击场景下与cf-utc区别不明显,这是因为随机攻击场景下攻击用户的评分波动不明显,导致cf-rt采用的信度重估技术无法体现优势。与cf-dnc相比,cf-tecnts通过过滤掉更多的用户检测出更多的攻击用户,在攻击用户查全率上提升了4.2842%,这表明本文提出的时效近邻可信选取策略具有更高的攻击用户检测能力。
[0181]
综上所述,本发明的基于时效近邻可信选取的协同过滤推荐方法,在目标用户近邻筛选过程中充分考虑了用户兴趣异常变化和推荐能力波动这两个因素,通过采用时效近邻筛选、可信近邻选取和目标用户评分预测三个推荐策略,实现向目标用户的精准推荐,有效缓解了传统协同过滤推荐在数据稀疏情况下存在的推荐精度低和抗攻击能力差的问题。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1