一种基于多模态协同自注意力网络的运动行为识别方法
1.本发明涉及计算机视觉技术领域,尤其涉及一种基于多模态协同自注意力网络的运动行为识别方法。
背景技术:
2.人体行为识别是计算机视觉领域中的研究热点之一,许多研究成果已经在图像分析、人机交互、智能监控、视频检索、体感游戏以及健康检测等领域中有了广泛的应用。
3.目前行为识别的研究主要基于深度图像序列、人体骨骼序列以及视频序列,由结构光深度传感器采集的深度图像序列对光照变化不敏感,而且提供了人体行为的深度数据,但依然受到光照、背景等因素的制约。运用骨骼序列能很好地克服外观因素的影响,具有特征明确简单、空间信息相关性强等优点,但是将人体简化成数十个关节点来表示不可避免地丢失了许多人体细节,视频序列包含最为完整的时空信息,但存在大量冗余信息,计算时间过长。
4.传统的行为识别主要依赖于人工提取特征进行识别,在泛化性能等方面存在一定的缺陷。
5.现有的基于骨骼数据的行为识别大都单独地利用各个骨骼节点信息,而人体动作过程中各关节部位是相互协同、相互作用的,人体运动具有整体性、协同性的特点。为了能够更好地反映这些特点,本发明提出了运动协同空间特征。
6.多模态融合指机器从多个领域获取信息,实现信息转换和融合,从而提升模型性能的技术,由于多模态数据可以使数据更加完整,实现多种异质信息的互补,剔除模态间的冗余性,从而学习到更好的特征表示,所以研究者们开始关注如何将来自多领域的数据进行融合,以提升模型性能,达到更好的识别效果。
技术实现要素:
7.针对现有算法的不足,本发明在transformer模型基础上使用深度数据与骨骼数据,综合各关节点信息的运动协同空间特征,反映人体运动的整体性与协同性,同时对各关节点参与运动的贡献程度提出了量化标准。
8.本发明所采用的技术方案是:一种基于多模态协同自注意力网络的运动行为识别方法包括以下步骤:
9.s1、通过惯性传感器采集骨骼序列数据;利用骨骼序列数据和运动协同空间向量算法构建运动协同空间特征序列集;将运动协同空间特征序列集输入基于transfomer网络的骨骼自注意力子网络,并通过softmax分类器进行分类;
10.进一步的,骨骼序列数据包括如下动作:右臂向左滑动、右臂向右滑动、挥动右手、两个手拍面前、右臂投掷、交叉手臂在胸部、篮球投篮、右手画x、右手画圆(顺时针)、右手画圆(逆时针)、画出三角形、保龄球(右手)、前拳击、棒球右摇摆、网球右手正手挥拍、旋臂(两臂)、网球发球、两个手推、右手敲门、右手抓住物体、右手捡起/扔、原地慢跑、原地走、坐姿
站立、站姿坐下、向前弓步(左脚向前)、蹲(两臂伸直);
11.进一步的,协同空间向量算法包括:人体在做各种动作时,身体各部位运动情况不尽相同,现有的基于骨骼数据的行为识别大都单独地利用各个骨骼节点信息,而人体动作过程中各关节部位是相互协同、相互作用的,人体运动具有整体性、协同性的特点,为了能够更好地反映这些特点,构建运动协同空间特征序列是通过构建运动协同空间向量,将人体划分为leftarm(左臂区域)、rightarm(右臂区域)、leftleg(左腿区域)、rightleg(右腿区域)四个区域,在每个区域内计算表示该肢体的协同空间向量,描述四肢运动,体现整体性与协同性;
12.leftarm区域的运动协同空间向量中共有四个关节点:leftshoulder(ls左肩)、leftelbow(le左肘)、leftwrist(lw左腕)和lefthand(lh左手),以spine点为中心,各个关节点的状态分别由向量表示,将表示,将拼接形成一个运动协同空间向量
13.进一步的,分别表示前后两帧图像中描述左手运动状态的协同空间向量,以spine点为原点坐标,将相邻两帧图像之间指向同一骨骼点的两个空间向量所形成的空间定义为空间向量幅值s,两个空间向量的夹角为θ;
14.当θ∈(0,90
°
]时,公式如下:
[0015][0016]
当角度变化大于90
°
时,表示该部位的运动幅度更大,为了使s与运动幅度继续保持正相关,当θ∈(90
°
,180
°
]时,公式如下:
[0017][0018]
将一个完整的骨骼图动作序列leftarm区域的n帧图像依次处理,得到空间向量幅值,公式如下:
[0019][0020]
其中,s
xoy
、s
yoz
、s
xoz
表示向三个面投影后的空间向量幅值;同理,计算出的空间向量幅值s
le
、s
lw
、s
lh
;
[0021]
再将leftarm区域内的值做归一化处理后即得运动状态衡量系数w,公式如下:
[0022][0023]
同理,计算出的空间向量的运动状态衡量系数w
le
、w
lw
和w
lh
;
[0024]
根据各关节点的空间向量乘以各关节点相应的运动状态衡量系数后再求和,得到leftarm区域的运动协同空间向量,公式如下:
[0025][0026]
同理,计算出区域rightarm、leftleg、rightleg的运动协同空间向量和并计算出各区域相应的运动状态衡量系数w
la
、w
ra
、w
ll
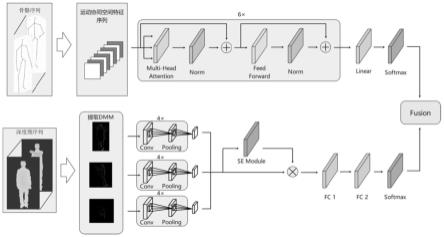
和w
rl
。
[0027]
计算整个人体骨骼的运动协同空间向量公式如下:
[0028][0029]
根据n帧骨骼的运动协同空间向量建立运动协同空间特征序列集(x1,x2,xi,
…
xn),其中xi为第i帧的运动协同空间向量
[0030]
进一步的,骨骼自注意力子网络包括:
[0031]
初始的骨骼序列经过提取运动协同空间特征序列后,神经网络接收的输入是很多大小不一的向量序列,并且不同向量之间存在时空上的联系,但是实际训练的时候无法充分发挥这些输入之间的关系而导致模型训练结果效果较差,针对全连接神经网络对于多个相关的输入无法建立起相关性的这个问题,通过自注意力机制来解决,自注意力机制通过聚合来自完整输入序列中的全局信息来更新序列的每个组成部分;
[0032]
用来表示n帧骨骼运动协同空间特征序列(x1,x2,xi,
…
xn),其中,d表示每个向量的嵌入维度;自注意力机制的目标是通过根据全局信息对每个向量进行编码来捕捉n个向量之间的交互;首先定义三个可学习的权重矩阵q和其中dq=dk,得到q=xwq,k=xwk和v=xwv,输出为:
[0033][0034]
其次,为了封装序列之中不同向量之间的多个复杂关系,多头注意力机制包括h个自注意力模块,每个模块都有自己的一组可学习权重矩阵{w
qi
,w
ki
,w
vi
},i=0,1,
…
,h-1,对于输入x,其次,多头注意力机制中h个自注意力模块的输出被连接成一个矩阵并投射到权重矩阵
[0035]
再其次,运动协同空间特征序列在输入时嵌入位置编码,保留序列的时序信息,进行multi-head attention操作之后,接入一个全连接前向网络,对每个向量分别进行相同的操作,包括两个线性变换和一个relu激活输出:
[0036]
ffn(x)=max(0,xw1+b1)w2+b2ꢀꢀꢀ
(8)
[0037]
其中,w1、w2为权重,b1、b2为偏置;
[0038]
最后,骨骼自注意力子网络由多个相同的多头注意力模块与前馈神经网络模块组合堆叠而成,最后连接softmax层得出分类结果。
[0039]
s2、采集深度图像数据,提取dmm,通过整合通道注意力机制的深度自注意力子网络进行训练,并通过softmax分类器进行分类;
[0040]
yang等人提出使用dmm(depth motion maps)来描述行为的3d结构和形状信息,为了利用深度图中附加的身体形状和运动信息,每个深度帧被投影到三个正交的笛卡尔平面上;然后将每个投影地图的感兴趣区域设置为前景(非零)区域的边界框,并进一步归一化为固定大小;这种标准化能够减少不同主体在执行相同动作时的内部变化,例如主体高度和运动范围。因此,每个3d深度框架根据正面视图、侧面视图和顶部视图生成三个2d地图,即mapf,maps,map
t
;对于每个投影图,通过计算两个连续映射图之间的差值并阈值化来获得其运动能量,运动能量的二值图表示运动区域或运动在每个时间间隔中发生的位置,最后通过整个视频序列叠加运动能量来生成dmmv;
[0041][0042]
其中,map
vi
和map
vi-1
为相邻两帧图像;
[0043]
提取dmm后,将其输入深度自注意力子网络中,深度自注意力子网络由一个三通道的卷积神经网络与一个通道注意力映射模块组成;
[0044]
进一步的,深度自注意力子网络的网络模型首先是输入层,输入的是缩至224
×
224的dmm,三个通道分别输入正面视图、侧面视图和顶部视图,中间为训练层:卷积层后连接一个池化层,共叠加了4次,卷积核的大小和数量依次为7
×7×
32、5
×5×
64、3
×3×
128、3
×3×
256,卷积层步长都为1,采用卷积核填充算法,目的是不丢弃卷积过程中的特征图信息;选择2
×
2的池化核进行最大池化,池化层步长都为2,以避免平均池化的模糊化效果;
[0045]
进一步的,为了衡量三个通道的特征对于关键信息的贡献,在网络中加入通道注意力映射模块,从而提高网络特征提取能力;
[0046]
注意力映射模块主要构成部分为维度压缩、激励、加权,首先利用全局平均池化操作将每个二维的特征通道变成一个实数,然后利用全连接操作与激活函数(relu,sigmoid)得到比较全面的通道级别的权重关系,最后,利用元素乘法将得到的权重与原始特征进行融合。
[0047]
后两层为全连接层,第一个全连接层产生1024个神经元节点(fc-1024)输出,第二个全连接层产生20个神经元节点(fc-20)输出;同时卷积层和全连接层都采用修正线性单元:relu激活函数来加速网络训练,以提高cnn特征学习能力;并在第一个全连接层的relu函数后添加dropout,进而增强模型泛化能力,防止过拟合,最后连接softmax得出分类结果。
[0048]
s3、将基于骨骼自注意力子网络的骨骼序列分类与基于深度自注意力子网络的深度图像分类进行融合,得到融合后分类结果;
[0049]
此处采用的融合方式为后端融合方式中的最大值融合方法,即将不同模态数据的分类器输出分数进行融合,保留两个子网络输出分数的最大值作为最终分类结果。
[0050]
本发明的有益效果:
[0051]
1、提出了一种可以综合各关节点信息的运动协同空间特征,对各关节点参与运动的贡献程度提出了量化标准,能够有效的反映人体运动的整体性与协同性;
[0052]
2、基于多模态融合的思想,将基于骨骼数据的骨骼自注意力子网络与基于深度数据的深度自注意力子网络进行结合,使数据更加完整,实现多种异质信息的互补,剔除模态间的冗余性,建立了一种新的行为识别方法体系,为人体行为识别方法研究和应用提供新的思路和理论依据,并在ntu数据集与utd-mhad数据集上取得了较好的效果。
附图说明
[0053]
图1是本发明的基于多模态协同自注意力网络的运动行为识别方法结构框图;
[0054]
图2是本发明人体骨骼区域示意图;
[0055]
图3是本发明左上肢协同空间向量图;
[0056]
图4是本发明左上肢某骨骼点前后两帧图像协同向量示意图;
[0057]
图5是本发明se module注意力模块示意图。
具体实施方式
[0058]
下面结合附图和实施例对本发明作进一步说明,此图为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
[0059]
本发明在多模态动作数据集ntu rgb+d 60与utd-mhad上进行测试,utd-mhad中的所有样本都是同时分类的,使用subject 1,3,5,7的样本进行训练,使用subject 2,4,6,8的样本进行测试。
[0060]
ntu rgb+d 60数据集采取两种实验设置:
[0061]
in cross-subject evaluation将40名受试者分为培训组和测试组,每组20名受试者;对于该评估,训练集和测试集分别有40320和16560个样本,本次评估中培训对象的id为:1、2、4、5、8、9、13、14、15、16、17、18、19、25、27、28、31、34、35、38;剩下的受试者留作测试。
[0062]
for cross-view evaluation选择摄像机1的所有样本进行测试,并选择摄像机2和3的样本进行训练,训练集包括动作的正面视图和两个侧面视图,而测试集包括动作表现的左右45度视图,训练集和测试集分别有37920和18960个样本。
[0063]
如图1所示,一种基于多模态协同自注意力网络的运动行为识别方法,包括以下步骤:
[0064]
s1、通过惯性传感器采集骨骼红外序列数据;利用红外序列数据和协同空间向量算法构建运动协同空间特征序列集;将运动协同空间特征序列集输入transfomer网络的自注意力子网络;
[0065]
为了评估提取运动协同空间特征不同方法的效果,建立三种不同的模型在utd-mhad与ntu rgb+d上进行比较:模型1为未使用运动状态衡量系数处理但向三个笛卡儿面做投影后的运动协同空间特征;模型2为未将运动协同空间向量向三个笛卡儿面投影,直接计算运动状态衡量系数的运动协同空间特征;模型3为本发明使用运动状态衡量系数处理也向三个笛卡儿面做投影后的运动协同空间特征;模型1和模型3、模型2和模型3为两组对照组;
[0066]
表1运动协同空间特征模型比较
[0067][0068]
由表1可看出,模型3在utd-mhad上的识别率相对于模型1提高了8%,在ntu rgb+d上的识别率分别提高了4.2%和7.1%;运动状态衡量系数的引入使得模型对于各部位对运动做出的贡献有了清晰的判别标准,对各区域运动协同空间向量的提取以及拼接提供了权重比例判别依据,提高了识别效果。
[0069]
模型3在utd-mhad上的识别率相对于模型2提高了16.7%,在ntu rgb+d上的识别率分别提高了16.3%和17.5%;向三个笛卡儿面投影的处理加强了模型对于空间信息的提取,大幅提高了识别效果。
[0070]
可以看出:运动状态衡量系数的引入以及向三个笛卡儿面投影这两项设置都有效地提高了运动协同空间特征的识别效果,因此本发明后续实验将采用模型3来提取运动协
同空间特征。
[0071]
s2、采集深度图像数据,提取dmm,通过整合通道注意力机制的深度自注意力子网络进行训练,并通过softmax分类器进行分类;
[0072]
为了证明深度子注意力映射模块有效提高了深度自注意力子网的性能,本发明设计了消融实验来证明其有效性;
[0073]
表2通道注意力映射模块消融实验
[0074][0075][0076]
由表2可以看出,加入通道注意力映射模块之后,在utd-mhad上的识别率提高了0.6%,在ntu rgb+d上的识别率分别提高了0.3%和1.4%;可以看出:通道注意力映射模块对于各通道数据的关注度起到了很好的调节作用,有效提高了识别效果。
[0077]
s3、将基于骨骼自注意力子网络的骨骼序列分类与基于深度自注意力子网络的深度图像分类进行融合,得到融合后分类结果;
[0078]
为了评估模态融合对于模型效果的影响,对单独使用骨骼自注意力子网络、单独使用深度自注意力子网络、模态融合后的结果进行了比较,如表所示:
[0079]
表3单模态、多模态方法对比(utd-mhad)
[0080][0081]
表4单模态、多模态方法对比(ntu rgb+d)
[0082][0083]
由表3可看出,融合后的多模态协同自注意力网络在utd-mhad上的识别率相对于两个子网分别提高了1.2%和2.4%,在ntu rgb+d上的识别率平均提高了3.8%和4.5%,证明了骨骼数据和深度数据提供的信息存在互补,多模态数据进行融合后能够更准确的描述人体行为。
[0084]
本发明还与主流方法在在ntu rgb+d与utd-mhad进行横向比较,结果如表5、6所示:
[0085]
表5各方法在utd-mhad精度比较
[0086][0087]
由表5可知本发明方法在utd-mhad数据集上识别率达到93.9%,高于所列出的其他方法,识别率至少提高了1.1%,评价结果证明了该方法在utd-mhad数据集上先进的性能;
[0088]
表6各方法在ntu rgb+d精度比较
[0089][0090]
由表6可知本发明方法在ntu rgb+d数据集上cs识别率达到90.5%,高于所列出的其他方法,cv识别率达到94.7%,与其他方法识别率相当或更好,评价结果证明了该方法的优越性。
[0091]
以上述依据本发明的理想实施例为启示,通过上述的说明内容,相关工作人员完全可以在不偏离本项发明技术思想的范围内,进行多样的变更以及修改。本项发明的技术性范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1