融合面部表情的居家老人摔倒检测方法
1.本发明涉及老人摔倒检测技术领域,具体为一种融合面部表情的居家老人摔倒检测方法。
背景技术:
2.日常生活中,导致人体摔倒的原因主要有两种,一种是因腿脚不方便被绊倒或滑到,另一种是因疾病引起的摔倒,摔倒时如果没有得到及时的救助,往往会导致伤情加重,甚至付出生命代价,因此,对于人体的摔倒进行检测显得尤为重要。
3.目前,针对老年人摔倒检测多基于人体动作的特征,常见的人体摔倒检测技术可分为三类,包括基于穿戴式,基于环境传感器以及基于视频,例如中国专利cn 109584506 a公开了一种基于云平台居家老人摔倒监测系统及方法,该专利通过利用嵌入式、云平台技术构造出一个智能居家老人摔倒监测系统,从而为广大老人的居家养老服务,采用可穿戴式检测摔倒设备,成本低,私密性高,但是这些方法需穿戴传感器,舒适性较差,或者容易受周围环境的偶然性与不确定性影响,并且有时会因老人下蹲以及其他一些行为而产生误判,故而,提出一种融合面部表情的居家老人摔倒检测方法来解决上述问题。
技术实现要素:
4.(一)解决的技术问题
5.针对现有技术的不足,本发明提供了融合面部表情的居家老人摔倒检测方法,可及时监测居家老年人摔倒的异常行为,给予老年人及时的救助,尽可能的减少因摔倒对老年人造成的伤害。
6.(二)技术方案
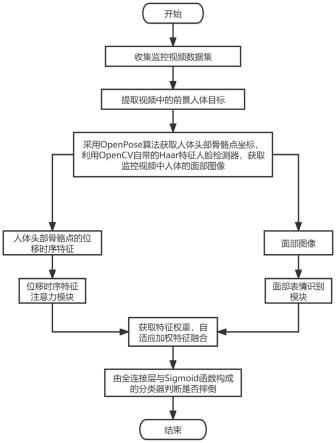
7.为实现上述目的,本发明提供如下技术方案:融合面部表情的居家老人摔倒检测方法,包括以下步骤:
8.1)收集监控视频数据集;
9.2)提取视频中的前景人体目标;
10.3)采用openpose算法获取人体头部骨骼点坐标并提取人体头部骨骼点的位移时序特征,利用opencv自带的haar特征人脸检测器,获取监控视频中人体的面部图像;
11.4)将头部骨骼点的位移时序特征与面部图像分别输入位移时序特征注意力模块与面部表情识别模块,分别得到包含位移关键帧信息的第一输出张量特征与包含面部表情信息的第二输出张量特征;
12.5)获取特征权重,对两个神经网络模块的输出张量特征采用自适应加权的特征融合方式进行融合;
13.6)融合后的特征经过由全连接层与sigmoid激活函数组成的分类器进行判断是否为摔倒。
14.优选的,所述步骤2)采用vibe方法提取前景人体目标,为后续的头部骨骼点位移
检测与面部表情检测做准备。
15.优选的,所述步骤3)首先通过openpose算法采集得到头部骨骼点的坐标,计算前后相邻两帧头部骨骼点的位移量,将视频中头部骨骼点的坐标逐帧计算位移量,组合成一个头部骨骼点位移序列,同时利用opencv自带的haar特征人脸检测器,获取监控视频中人体的面部图像,将得到的头部骨骼点的位移时序特征送入位移时序特征注意力模块,获取的面部图像送入由卷积神经网络(cnn)为主干网络,并在相邻网络层之间引入通道注意力网络(senet)构建的面部表情识别模块,将两个模块的输出特征进行自适应加权特征融合后送入分类器进行判断是否为摔倒。
16.所述计算头部骨骼点的位移时序特征的具体步骤如下:
17.a.假设t时刻头部骨骼点的坐标为(x
t
,y
t
),t+1时刻的头部骨骼点坐标为(x
t+1
,y
t+1
),d代表t时刻与t+1时刻时间跨度内头部骨骼点的位移量,计算公式为:
[0018][0019]
b.计算由连续时刻构成序列长度为t的头部骨骼点的位移时序特征q:
[0020]
q={d
p
p=1,2
…
t}
[0021]
其中,d
p
为p时刻与p+1时刻时间跨度内头部骨骼点的位移量。
[0022]
所述利用opencv自带的haar特征人脸检测器进行人脸检测,获取监控视频中人体的面部图像,输入面部表情识别模块。
[0023]
优选的,所述步骤4)将步骤3)获取的头部骨骼点的位移时序特征送入位移时序特征注意力模块,获取的面部图像送入由卷积神经网络(cnn)为主干网络,并在相邻网络层之间引入通道注意力网络(senet)构建的人脸表情识别模块,通道注意力网络(senet)是将特征通道采用“特征重标定”的思想来进行融合,将通道注意力网络(senet)加入到卷积神经网络(cnn)的卷积层与池化层之间,通过上述两个模块分别检测出包含位移关键帧信息的第一输出张量特征与包含面部表情信息的第二输出张量特征。
[0024]
优选的,所述步骤5)先将步骤4)得到的包含位移关键帧信息的第一输出张量特征与包含面部表情信息的第二输出张量特征通过权重获取模块计算得到各自的特征权重,将获取权重后的第一输出张量特征与第二输出张量特征进行维度上的加权融合,使融合后的特征具有更强的表达能力,能够更加准确的进行判断是否为摔倒,自适应加权特征融合方法表示为:
[0025]
g=ωf+(1-ω)m
[0026]
其中,g表示融合特征,ω表示权重系数,f表示包含面部表情信息的第二输出张量特征,m表示包含位移关键帧信息的第一输出张量特征。
[0027]
优选的,所述步骤6)采用分类器判断是否为摔倒,其中,若仅依靠头部骨骼点的位移来判断是否为摔倒,可能会因下蹲或坐下等动作产生误差,在头部骨骼点位移的基础上通过自适应加权融合的方法融入面部表情特征,当头部骨骼点的位移量过大且面部表情为痛苦时,输出为摔倒的概率大,反之,输出为非摔倒的概率大,二分类交叉熵损失函数l为:
[0028][0029]
其中,n为样本数,a表示计数器,a=1表示从第1个样本开始计数,为样本的标
签,正类为1,负类为0,ya为预测为正的概率。
[0030]
(三)有益效果
[0031]
与现有技术相比,本发明提供了融合面部表情的居家老人摔倒检测方法,具备以下有益效果:
[0032]
该融合面部表情的居家老人摔倒检测方法,通过采用自适应加权特征融合的方式将人体的面部表情特征与头部骨骼点的位移特征进行融合,能够针对不同的情况为面部表情特征与头部骨骼点位移特征分配不同的权重进行融合,进而做出更加准确的判断;将卷积神经网络(cnn)与通道注意力网络(senet)结合构建面部表情识别模块,能够获取图像中更多的特征,提高检测的准确性。
附图说明
[0033]
图1为本发明的流程图;
[0034]
图2为本发明的神经网络模型结构图。
具体实施方式
[0035]
下面将结合本发明的实施例和附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0036]
人体在摔倒过程中,骨骼点的位移量会发生变化,因此本发明选取头部骨骼点为感兴趣点,将头部骨骼点的位移量作为是否为摔倒的判断条件之一,同时,面部表情是人类表达情感和意图最为有效的方式之一,人体在摔倒时会表现出痛苦的表情,因此将面部表情作为是否为摔倒的另一个判断条件,通过获取人体头部骨骼点位移变化与面部表情两种特征,自适应加权融合后送入分类器进行分类,可进一步提高检测的准确率。
[0037]
本发明提供一种融合人体面部表情特征的摔倒检测方法,通过老年人面部表情特征与骨骼点的位移特征判断是否为摔倒,本发明共分为两个阶段,分别是训练阶段与测试阶段,在训练阶段训练好神经网络与分类器,在测试阶段随机输入一段老年人居家活动的监控视频数据,判断是否有摔倒现象,其中,训练阶段具体如下。
[0038]
请参阅图1-2,融合面部表情的居家老人摔倒检测方法,包括以下步骤:
[0039]
1)收集监控视频数据集;
[0040]
2)提取视频中的前景人体目标;
[0041]
3)采用openpose算法获取人体头部骨骼点坐标并提取人体头部骨骼点的位移时序特征,利用opencv自带的haar特征人脸检测器,获取监控视频中人体的面部图像;
[0042]
4)将头部骨骼点的位移时序特征与面部图像分别输入位移时序特征注意力模块与面部表情识别模块,分别得到包含位移关键帧信息的第一输出张量特征与包含面部表情信息的第二输出张量特征;
[0043]
5)获取特征权重,对两个神经网络模块的输出张量特征采用自适应加权的特征融合方式进行融合;
[0044]
6)融合后的特征经过由全连接层与sigmoid激活函数组成的分类器进行判断是否
为摔倒。
[0045]
其中,步骤2)采用vibe方法提取前景人体目标,为后续的头部骨骼点位移检测与面部表情检测做准备。
[0046]
步骤3)首先通过openpose算法采集得到头部骨骼点的坐标,计算前后相邻两帧头部骨骼点的位移量,将视频中头部骨骼点的坐标逐帧计算位移量,组合成一个头部骨骼点位移序列,同时利用opencv自带的haar特征人脸检测器,获取监控视频中人体的面部图像,将得到的头部骨骼点的位移时序特征送入位移时序特征注意力模块,获取的面部图像送入由卷积神经网络(cnn)为主干网络,并在相邻网络层之间引入通道注意力网络(senet)构建的面部表情识别模块,将两个模块的输出特征进行自适应加权特征融合后送入分类器进行判断是否为摔倒。
[0047]
需要说明的是,计算头部骨骼点的位移时序特征的具体步骤如下:
[0048]
a.假设t时刻头部骨骼点的坐标为(x
t
,y
t
),t+1时刻的头部骨骼点坐标为(x
t+1
,y
t+1
),d代表t时刻与t+1时刻时间跨度内头部骨骼点的位移量,计算公式为:
[0049][0050]
b.计算由连续时刻构成序列长度为t的头部骨骼点的位移时序特征q:
[0051]
q={d
p
p=1,2
…
t}
[0052]
其中,d
p
为p时刻与p+1时刻时间跨度内头部骨骼点的位移量。
[0053]
经过上述步骤可以得到头部骨骼点的位移时序特征,利用opencv自带的haar特征人脸检测器进行人脸检测,获取监控视频中人体的面部图像。
[0054]
步骤4)将步骤3)获取的头部骨骼点的位移时序特征送入位移时序特征注意力模块,获取的面部图像送入由卷积神经网络(cnn)为主干网络,并在相邻网络层之间引入通道注意力网络(senet)构建的人脸表情识别模块,通道注意力网络(senet)是将特征通道采用“特征重标定”的思想来进行融合,将通道注意力网络(senet)加入到卷积神经网络(cnn)的卷积层与池化层之间,不仅能够提高感受野,还可以使网络自动学习到不同通道的重要程度,从而提高检测效率,通过上述两个模块分别检测出包含位移关键帧信息的第一输出张量特征与包含面部表情信息的第二输出张量特征,其中,位移时序特征注意力模块由lstm层、时间注意力层、全连接层2以及relu层2组成,面部表情识别模块由conv1、senet1、池化层1、conv2、senet2、池化层2、全连接层1以及relu层1组成。
[0055]
步骤5)先将步骤4)得到的包含位移关键帧信息的第一输出张量特征与包含面部表情信息的第二输出张量特征通过权重获取模块计算得到各自的特征权重,权重获取模块由conv3、bn层1、relu层3、conv4以及bn层2组成,需要对不同的表情设置不同的权重来进行融合,融合权重的确定是加权融合方法的关键,当面部表情为痛苦时,权重系数大,当面部表情为愉快时,权重系数小,第一输出张量特征与第二输出张量特征的权重系数之和为1,得到包含面部表情信息的第二输出张量特征的权重系数之后,便可得到包含位移关键帧信息的第一输出张量特征的权重系数,将获取权重后的第一输出张量特征与第二输出张量特征进行维度上的加权融合,使融合后的特征具有更强的表达能力,能够更加准确的进行判断是否为摔倒,自适应加权特征融合方法表示为:
[0056]
g=ωf+(1-ω)m
[0057]
其中,g表示融合特征,ω表示权重系数,f表示包含面部表情信息的第二输出张量特征,m表示包含位移关键帧信息的第一输出张量特征。
[0058]
步骤6)通过采用分类器判断是否为摔倒,其中,若仅依靠头部骨骼点的位移来判断是否为摔倒,可能会因下蹲或坐下等动作产生误差,在头部骨骼点位移的基础上通过自适应加权融合的方法融入面部表情特征,当头部骨骼点的位移量过大且面部表情为痛苦时,输出为摔倒的概率大,反之,输出为非摔倒的概率大,二分类交叉熵损失函数l为:
[0059][0060]
其中,n为样本数,a表示计数器,a=1表示从第1个样本开始计数,为样本的标签,正类为1,负类为0,ya为预测为正的概率。
[0061]
测试阶段具体如下:
[0062]
在测试阶段,选取一段监控视频,首先提取视频中的前景人体目标,通过openpose算法获取头部骨骼点的坐标,计算得到头部骨骼点的位移时序特征,同时利用opencv自带的haar特征人脸检测器,获取监控视频中人体的面部图像,将头部骨骼点的位移时序特征送入训练好的时序特征注意力模块,将面部图像送入训练好的人脸表情识别模块后的输出送入权重获取模块,通过自适应加权特征融合的方法将两种输出张量特征融合,并送入分类器进行分类,输出摔倒与非摔倒的概率,概率高的为判断结果。
[0063]
本发明的有益效果是:
[0064]
该融合面部表情的居家老人摔倒检测方法,通过采用自适应加权特征融合的方式将人体的面部表情特征与头部骨骼点的位移特征进行融合,能够针对不同的情况为面部表情特征与头部骨骼点位移特征分配不同的权重进行融合,进而做出更加准确的判断;将卷积神经网络(cnn)与通道注意力网络(senet)结合构建面部表情识别模块,能够获取图像中更多的特征,提高检测的准确性。
[0065]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1