一种基于Bert语言模型的中文写作短语推荐方法
一种基于bert语言模型的中文写作短语推荐方法
技术领域
1.本发明涉及自然语言处理领域,尤其涉及基于bert的上下文语义与句法信息融合的基于向量化表征的短语推荐方法。
背景技术:
2.互联网时代文本信息大量产生,例如每天各个行业如新媒体行业,新闻行业中蕴含大量有效的文本信息,获取这些数据进行挖掘,通过半监督和监督学习对其进行学习,从而衍生出了现在各种各样的语言模型。bert作为一种双向transformer的语言模型就是通过nsp和mlm两个自监督任务进行整体模型的学习。中文成为了很多人的基本学习语言,而中文语言相较于其他语言不仅组合模式多种多样,字形字音也时常有特定的意义,并且中文的词语短语中细分了很多种类,不同的语境下选用什么词语进行语义的表达也值得思考,因此很多初学者在一开始学习中文较为吃力。通过造句或者写作,是帮助语言学习者理解语义,语法的较为有效的方式。这就可以借助自然语言理解中的语言模型技术,来建模整个语句,针对不同的任务进行训练。随着深度学习技术的发展,文本表示模型可以使用word2vec、glove等分布式表示的语言模型,并使用神经网络进行信息提取和分类。近年来,注意力机制的提出和广泛使用,提升了语言模型的效果。但是仍然存在一些不足:
3.1)语言模型资源消耗大
4.现有的模型为了基于大规模语料建模语言模型,通常需要大量的参数致使模型的参数量巨大,且计算资源耗费较大,适应下游任务时需要额外的微调,又需要优化大量的参数,这对资源和时间有着较高的要求。
5.2)没有有效的短语预测模型
6.目前大多数的语言模型在进行下游任务时,大多关注一些分类问题,而没有一种方法,关注短语级别的语言预测方法,短语由多个字组成,需要特殊的处理方式,如何确定语言序列中一个位置的短语,需要多方面的考量。
技术实现要素:
7.本发明的目的是针对现有技术的不足而提供的一种基于bert语言模型的中文写作短语推荐方法,结合self-attention机制,使用基于词嵌入的短语表示方法,结合上下文的语义语境,同时关注语法结构的信息,提升短语的预测准确率,得到一个结合语义同时融合了语法知识的表征用于写作短语推荐的方法。
8.实现本发明目的的具体技术方案是:
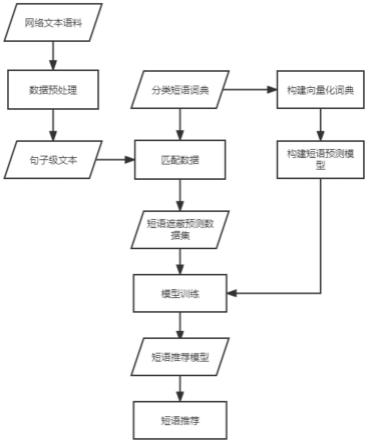
9.一种基于bert语言模型的中文写作短语推荐方法,该方法包括以下具体步骤:
10.步骤1:获取网络上的现代文长短文语料
11.在网络上爬取长短小说文本及新闻文本,爬取到的文本是基于段落和篇章级别的语料,对爬取到的文本进行分句,并进行基础的数据清洗,整理成为整洁规范的句子级别的文本数据;
12.步骤2:获取常用的短语及成语
13.同时在网络上搜集常用的中文短语及成语,按照词性类别进行爬取,保存并按照词性类别进行归档,得到常用短语集;
14.步骤3:构建短语遮蔽文本预测任务的数据集
15.将步骤2中得到的短语集与步骤1中处理得到的句子级别文本数据进行匹配,提取出包含短语集中短语的句子;基于匹配提取得到的句子,构建短语遮蔽文本预测任务的数据集,并按照8:1:1的比例,划分出训练集、验证集和测试集;
16.步骤4:对短语字典和类别字典进行向量化
17.对于步骤2中归档的短语集,构建一个向量化的字典;每个短语对应一个向量化的表征;对于步骤2中归档的短语集中的每一个类别,构建一个向量化的字典,每个类别同时对应一个向量化的表征,对所述两个向量化字典进行随机初始化;
18.步骤5:训练基于bert的遮蔽短语预测模型
19.构建一个基于bert的遮蔽短语预测模型,使用步骤3中构建的训练集对模型进行训练,通过adam优化器反向传播更新模型的参数,每次更新参数后计算模型在步骤3的验证集上计算模型的预测损失,重复上述过程直到验证集上模型的预测损失不再下降,保存此时的模型;步骤6:使用短语预测模型对用户进行短语推荐
20.在步骤5保存的模型中,增加接受用户输入和格式化输出模型预测结果的功能,得到模型预测的类别概率和概率值前k的类别下的每个短语的预测概率,并按照短语预测概率值排序,取前o个短语作为该类别下的预测短语推荐给用户。
21.步骤1所述对爬取的文本进行分句,具体包括:
22.2-1:采用标点符号为基础的分句方法,将步骤1中篇章级别文本切割为句子;
23.2-2:对2-1中按照标点符号切分的句子,其长度超过预设值len,对其进行切割,保证每句句子长度不超过len;
24.2-3:将经过2-2处理的句子全部统一归档,得到整洁的句子级别文本数据。
25.步骤2所述按照词性类别进行归档,具体包括:
26.3-1:将短语按照词性划分为十大类别,具体包括代词、动词、副词、介词、连词、名词、数量词、形容词、疑问词及助词。
27.步骤3所述构建短语遮蔽文本预测任务的数据集,具体包括:
28.4-1:对与短语集匹配后得到的句子,将句子中包含的目标短语遮蔽,用“[mask]”进行替代;
[0029]
4-2:对词性类别进行标签转换,将类别映射到数字表示的标签,并对4-1中每一句句子包含的目标短语对应的类别,记录所对应的数字,作为短语词性类别标签;
[0030]
4-3:对步骤2中短语集中所有的短语进行标签转换,将短语映射到数字表示的标签,构成短语到数字的映射;
[0031]
4-4:对4-1中的每条句子,从短语集中随机选择m-1个不包含句子中原来包含短语的短语列表,与句子中原来包含的短语共同构成大小为m的短语候选列表,并将短语映射为4-3 中所述的短语到数字的标签;
[0032]
4-5:对上述生成的由句子和标签组成的数据集进行划分,按照8:1:1的比例将数据集划分出训练集、验证集和测试集。
[0033]
所述步骤4,具体为:
[0034]
5-1:对于步骤2中归档的短语集,构建一个向量化的字典,每个短语对应一个向量化的表征,维度为dw维,并对每个表征进行随机初始化;
[0035]
5-2:对于步骤2中归档的短语集中的每一个类别,构建一个向量化的字典,每个类别同时对应一个向量化的表征,维度为dc维,并对每个表征进行随机初始化。
[0036]
步骤5所述构建一个基于bert的遮蔽短语预测模型,其模型包含:bert文本编码器,步骤 3中构建的短语向量化字典和类别向量化字典,基于上下文的信息整合单元,以及基于前向连接网络的类别分类器和候选短语分类器;具体按照如下步骤构建:
[0037]
6-1:模型中的bert文本编码器由基于自注意力机制的transformer序列编码器encoder 构成,encoder包括multi-head attention模块和feed-forward networks模块; multi-head attention模块:设输入为x=(x1,x2,
…
,xn),输出用multihead(x)表示,公式如下:
[0038]
headi=attention(xw
ix
,xw
ix
,xw
ix
)(i=0,1,
…
,n)
[0039]
multihead(x)=concat(head1,head2,
…
,headh)wo[0040]
为权重矩阵,d
model
,d
x
,分别为输入向量维度和子空间维度;attention,表示self-attention机制,headi表示第i个子空间,concat表示合并操作;所述self-attention机制,公式如下:
[0041][0042]
其中,dk为输入维度,为尺度因子,q,k,v分别attention机制的query、key和value,在multi-head attention模块中,q,k,v的值与xw
ix
相同;
[0043]
feed-forward networks模块:该模块的输入为multi-head attention部分的输出加上输入原始输入x,设为x,输出为ffn(x),公式如下:
[0044]
x=multihead(x)+x
[0045]
ffn(x)=max(0,xw1+b1)w2+b2[0046]
上述wi,bi(i=1,2)分别表示第i层神经网络权重项和偏移项;
[0047]
基于上述encoder构建层级神经网络,层级指词级别和句级别,构建步骤为:
[0048]
设第i句的词组成的序列长度为n,用xi=[x
i1
,x
i2
,
…
,x
in
]表示,将xi作为上述的encoder的输入,得到xi′
=[x
i1
′
,x
i2
′
,
…
,x
in
′
];
[0049]
使用soft attention对x
′
进行降维,得到句向量si,公式如下:
[0050]uij
=tanh(wwx
ij
′
+bw)
[0051][0052][0053]
其中,ww,bw为权重矩阵和偏移项,tanh为激活函数,u
ij
为输x
ij
′
经过一层神经网络的输出, uw为权重向量,α
ij
为x
ij
′
的权重,x
ij
′
为xi′
中第j个向量,u
ijt
为u
ij
转置;
[0054]
6-2:bert模型在句子开始和末尾分别加上“[cls]”以及“[sep]”字符,此时输入表征序列{x
cls
,x0,x1,
…
,x
t
,x
sep
+经上述bert模型后获得与语句长度相同的隐层状态序列 {h
cls
,h0,h1,
…
,h
n-1
,h
sep
+,对应“[mask]”位置的隐层状态序列为hm;
[0055]
6-3:信息整合单元为一个前向传播网络,对于“[mask]”位置的隐层状态序列,构建信息整合单元的输入hi,输入信息整合单元后得到对应的输出ho:
[0056][0057]
ffn
aggr
(hi)=max(0,hiw1+b1)w2+b2[0058]ho
=ffn
aggr
(hi)
[0059]
上述wi,bi(i=1,2)表示信息整合单元ffn
aggr
中的权重项和偏移项;
[0060]
6-4:针对类别信息整合单元的输出ho,将其输入到类别分类器中,取得类别概率最大的类别对应的向量化表示:
[0061]
ffn
cls
(ho)=max(0,how1+b1)w2+b2[0062]
ec=argmax(softmax(ffn
cls
(ho)))
[0063]
上述wi,bi(i=1,2)表示类别分类器ffn
cls
中的权重项和偏移项;
[0064]
6-5:基于6-4得到的最大判断概率得到的类别表征,将其与原始信息整合单元的输出进行拼接,输入到短语分类器中,与候选的m个短语向量化表征进行点积,并概率化每个候选输入短语的概率值:
[0065][0066]
ffnw(hc)=max(0,hvw1+b1)w2+b2[0067][0068]
其中,wi,bi(i=1,2)表示短语分类器ffnw中的权重项和偏移项。
[0069]
步骤6中所述增加接受用户输入和格式化输出模型预测结果的功能,具体实现方式如下:
[0070]
7-1:模型将输入的语句中的“*”转换为“[mask]”,输入到短语预测模型中;
[0071]
7-2:模型对输入的语句进行计算处理,依次预测对应位置的类别和概率,根据空缺位置词性类别的概率值排序,选取排序前k的类别进行引导式的短语预测,分别预测对应类别分布下的短语,并按短语预测概率值排序,取排序前o的短语作为该类别下推荐的短语;
[0072]
7-3:模型将7-2中的类别概率及该类别下对应的短语,按照概率值排序,输出给用户作为模型对于该句输入的空缺位置的短语推荐结果。
[0073]
本发明在引入基于bert的语言模型的同时,通过向量化的方法将短语和类别进行得到嵌入表征,针对一句输入语句,融合它的上下文语境,同时考虑语法结构,从而预测出该位置合适的短语候选,同时模型的计算时间和计算资源都比较可观,在为用户写作进行恰当短语推荐的同时,能够起到辅助学者进行写作训练和语言学习的目的。
附图说明
[0074]
图1为本发明基于bert语言模型的短语预测模型的结构示意图;
[0075]
图2为本发明流程图。
具体实施方式
[0076]
本发明使用网络上获取的文本语料进行数据集的构建,将获取到的段级别的文本通过采用标点符号为基础的分句方法,对过长的语句按逗号或其它标点符号进行分割,得到句子级别的文本。同时与网络上获取并进行规整的短语集进行匹配,构建出具有短语类别标签、短语标签、候选短语等的数据集。模型通过结合上下文语义及句子句法信息的特征,对空缺位置进行短语预测,根据数据集构建的标签进行分类损失计算,并进行梯度回传,从而优化整个模型的参数。
[0077]
实施例1
[0078]
参阅图2,按下述步骤进行基于bert的中文短语预测模型训练:
[0079]
s1:收集目标网站和平台的文本语料,对收集到的文本进行文本预处理,并划分出训练集、验证集和测试集;其中,文本预处理包括数据清洗和长句分句,分句长度len选取256,同时收集不同类别下的常用短语,并按照类别归档,将预处理过后的文本与短语集进行匹配,得到匹配的句子级数据,例如:
[0080]
原始文本:
[0081]
话虽这样说,但要让球迷和教练认可,吉布斯还得靠比赛实践来挣得出人头地的空间,上轮联赛克里希受伤,温格临时用乔鲁顶,而不让替补席上的吉布斯出场多少就能证明一些问题,但今天这场比赛,吉布斯把握住了机会,全场打得有声有色,上半场不知道对手实力,所以打得有些保守,安于防守即可,下半场的吉布斯,才是真正的防守助攻两手硬的小天才。下半场吉布斯连续贡献两记射门,一次抽射被门将扑出,一次后点头球稍微高出,体现了他很不错的进攻欲望和质量,但最主要的是他的助攻,第50分钟,他漂亮的后场长传正好找到贝拉,墨西哥人停球过人,随后一次精彩吊射得分,吉布斯良好的大局观和后场起球的准度,这一击中尽现无疑......
[0082]
经过预处理和短语匹配后得到的分句文本:
[0083]
话虽这样说,但要让球迷和教练认可,吉布斯还得靠比赛实践来挣得出人头地的空间,上轮联赛克里希受伤,温格临时用乔鲁顶,而不让替补席上的吉布斯出场多少就能证明一些问题,但今天这场比赛,吉布斯把握住了机会,全场打得有声有色,上半场不知道对手实力,所以打得有些保守,安于防守即可,下半场的吉布斯,才是真正的防守助攻两手硬的小天才。 phrase_label=“知道”[0084]
s2:构建标签到数字的映射,即每一个短语对应一个数字,每个类别对应一个数字,方便模型进行输入,为每一句数据随机枚举m=7个包含真实短语的候选短语集,并且不重复,则s1 中的数据进一步可以得到一条训练数据如下所示:
[0085]
话虽这样说,但要让球迷和教练认可,吉布斯还得靠比赛实践来挣得出人头地的空间,上轮联赛克里希受伤,温格临时用乔鲁顶,而不让替补席上的吉布斯出场多少就能证明一些问题,但今天这场比赛,吉布斯把握住了机会,全场打得有声有色,上半场不“[mask]”对手实力,所以打得有些保守,安于防守即可,下半场的吉布斯,才是真正的防守助攻两手硬的小天才。 phrase_label=645,class_label=3,candidate=[231,442,645,84,665,433,235]
[0086]
s3:构建并初始化短语预测模型,首先构建两个向量化词典,一个是短语向量化词典,另一个是类型向量化词典。设置他们的维度dw=dc=768,则两个字典的维度分别是[短语总数, 768]和[类别总数,768],并对其进行随机初始化。
[0087]
s4:构建基于bert的短语预测序模型,进行输入句子的短语类型预测;
[0088]
模型主要包含bert文本编码器,通过向量化进行短语表示的向量化表征词典,通过向量化进行类别表示的向量化表征词典,基于上下文的信息整合单元,以及基于前向连接网络的类别分类器和短语分类器,具体如图1所示。
[0089]
模型中的bert编码器主要由基于自注意力机制的transformer序列编码器encoder构成, encoder包括multi-head attention模块和feed-forward networks模块;
[0090]
multi-head attention模块:设输入为x=(x1,x2,
…
,xn),输出用multihead(x)表示,公式如下:
[0091]
headi=attention(xw
ix
,xw
ix
,xw
ix
)(i=0,1,
…
,n)
[0092]
multihead(x)=concat(head1,head2,
…
,headh)wo[0093]
为权重矩阵,d model
,d
x
,分别为输入向量维度和子空间维度;attention,表示self-attention机制,headi表示第i个子空间,concat表示合并操作;所述self-attention机制,公式如下:
[0094][0095]
其中,dk为输入维度,为尺度因子,q,k,v分别attention机制的query、key和value,在multi-head attention模块中,q,k,v的值与xw
ix
相同;
[0096]
feed-forward networks模块:该模块的输入为multi-head attention部分的输出加上输入原始输入x,设为x,输出为ffn(x),公式如下:
[0097]
x=multihead(x)+x
[0098]
ffn(x)=max(0,xw1+b1)w2+b2[0099]
上述wi,bi(i=1,2)分别表示第i层神经网络权重项和偏移项;
[0100]
基于上述encoder构建层级神经网络,层级指词级别和句级别,构建步骤为:
[0101]
设第i句的词组成的序列长度为n,用xi=[x
i1
,x
i2
,
…
,x
in-表示,将xi作为上述的encoder的输入,得到xi′
=[x
i1
′
,x
i2
′
,
…
,x
in
′
];
[0102]
使用soft attention对x
′
进行降维,得到句向量si,公式如下:
[0103]uij
=tanh(wwx
ij
′
+bw)
[0104][0105][0106]
其中,ww,bw为权重矩阵和偏移项,tanh为激活函数,u
ij
为输x
ij
′
经过一层神经网络的输出, uw为权重向量,α
ij
为x
ij
′
的权重,x
ij
′
为xi′
中第j个向量,u
ijt
为u
ij
转置;
[0107]
由于bert模型输入需要在句子开始和末尾分别加上“[cls]”以及“[sep]”,因此输
入表征序列{x
cls
,x0,x1,
…
,x
t
,x
sep
}经上述bert模型后获得与语句长度相同的隐层状态序列 {h
cls
,h0,h1,
…
,h
n-1
,h
sep
},对应“[mask]”位置的隐层状态序列为hm;
[0108]
对于“[mask]”位置的隐层状态序列,构建信息整合单元的输入位置的隐层状态序列,构建信息整合单元的输入信息整合单元为一前向传播网络,得到对应的输出ho;
[0109]
针对类别信息整合单元的输出ho,将其输入到类别分类器中,取得类别概率最大的类别对应的向量化表示:
[0110]
ffn(ho)=max(0,how1+b1)w2+b2[0111]
p=softmax(ffn(ho))
[0112]
对于s2中的输入,我们可以得到模型对于短语位置的,计算的所有类别下的概率:[0.0639, 0.0789,0.0629,0.4023,0.0631,0.0681,0.0636,0.0713,0.0631,0.0628] s5:基于s4计算出的概率,选择出向量化类别词典中,概率最大对应的类别向量
[0113]
ec=argmax(softmax(ffn(ho)))
[0114]
将其与原始信息整合单元的输出进行拼接,输入到短语分类器中,与候选的m=7个短语向量化表征进行点积,并概率化每个候选输入短语的概率值:
[0115][0116]
ffn(hc)=max(0,hvw1+b1)w2+b2[0117][0118]
基于s2中的数据,可以计算得到最终每一个短语基于类别3下的概率值,得分最高的argmaxp(v)为模型预测的短语,通过交叉熵损失函数,对结果进行损失计算
[0119][0120]
其中yi(i=1,2,
…
,c)等于1时表示短语属于第i类,为分类器预测短语属于第i类的概率。
[0121]
以上仅是本发明的一个实施示例,本发明的保护范围并不局限于上述实例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进,应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1