一种糖网眼底图像数据的多类别病灶分割方法及系统与流程
1.本发明涉及人工智能技术领域,具体涉及一种糖网眼底图像数据的多类别病灶分割方法及系统。
背景技术:
[0002]“糖网”表示糖尿病性视网膜病变,是指糖尿病导致的视网膜微血管损害,是糖尿病最常见的微血管并发症之一,糖尿病患者做眼底筛查时所得糖尿病患者眼底图像相关数据信息即糖网眼底图像数据,早期的规范治疗可显著改善,糖网眼底图像病灶的类别多,可能是微血管的病理性改变,也可能是微血管系统渗漏或阻塞病变,对糖网眼底图像病灶通过观察直接划分无法保证划分结果的可靠性,亟需合理病灶类别分割方案,对病灶类型信息进行精准分割。
[0003]
现有技术中存在难以对糖网图像进行精细分割,导致难以对病灶进行多类别的精准识别的技术问题。
技术实现要素:
[0004]
本技术通过提供了一种糖网眼底图像数据的多类别病灶分割方法及系统,解决了难以对糖网图像进行精细分割,导致难以对病灶进行多类别的精准识别的技术问题,达到了智能优化糖网眼底图像数据的类别病灶分割方案,快速定位病灶类别信息,提高病灶图像分割及其多类别病灶识别精准度的技术效果。
[0005]
鉴于上述问题,本技术提供了一种糖网眼底图像数据的多类别病灶分割方法及系统。
[0006]
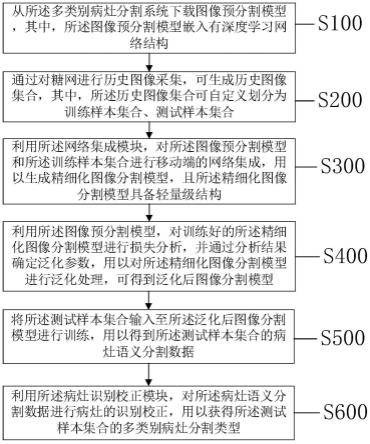
第一方面,本技术提供了一种糖网眼底图像数据的多类别病灶分割方法,其中,所述方法应用于多类别病灶分割系统,所述系统包括网络集成模块、病灶识别校正模块,所述方法包括:从所述多类别病灶分割系统下载图像预分割模型,其中,所述图像预分割模型嵌入有深度学习网络结构;通过对糖网进行历史图像采集,可生成历史图像集合,其中,所述历史图像集合可自定义划分为训练样本集合、测试样本集合;利用所述网络集成模块,对所述图像预分割模型和所述训练样本集合进行移动端的网络集成,用以生成精细化图像分割模型,且所述精细化图像分割模型具备轻量级结构;利用所述图像预分割模型,对训练好的所述精细化图像分割模型进行损失分析,并通过分析结果确定泛化参数,用以对所述精细化图像分割模型进行泛化处理,可得到泛化后图像分割模型;将所述测试样本集合输入至所述泛化后图像分割模型进行训练,用以得到所述测试样本集合的病灶语义分割数据;利用所述病灶识别校正模块,对所述病灶语义分割数据进行病灶的识别校正,用以获得所述测试样本集合的多类别病灶分割类型。
[0007]
第二方面,本技术提供了一种糖网眼底图像数据的多类别病灶分割系统,其中,所述系统包括:数据获取单元,所述数据获取单元用于从多类别病灶分割系统下载图像预分割模型,其中,所述图像预分割模型嵌入有深度学习网络结构;数据采集单元,所述数据采
集单元用于通过对糖网进行历史图像采集,可生成历史图像集合,其中,所述历史图像集合可自定义划分为训练样本集合、测试样本集合;数据分析单元,所述数据分析单元用于利用网络集成模块,对所述图像预分割模型和所述训练样本集合进行移动端的网络集成,用以生成精细化图像分割模型,且所述精细化图像分割模型具备轻量级结构;分析处理单元,所述分析处理单元用于利用所述图像预分割模型,对训练好的所述精细化图像分割模型进行损失分析,并通过分析结果确定泛化参数,用以对所述精细化图像分割模型进行泛化处理,可得到泛化后图像分割模型;训练整合单元,所述训练整合单元用于将所述测试样本集合输入至所述泛化后图像分割模型进行训练,用以得到所述测试样本集合的病灶语义分割数据;识别校正单元,所述识别校正单元用于利用病灶识别校正模块,对所述病灶语义分割数据进行病灶的识别校正,用以获得所述测试样本集合的多类别病灶分割类型。
[0008]
本技术中提供的一个或多个技术方案,至少具有如下技术效果或优点:
[0009]
由于采用了从多类别病灶分割系统下载图像预分割模型;通过对糖网进行历史图像采集,可生成历史图像集合;利用网络集成模块,对图像预分割模型和训练样本集合进行移动端的网络集成,生成精细化图像分割模型;利用图像预分割模型,对训练好的精细化图像分割模型进行损失分析,通过分析结果确定泛化参数,对精细化图像分割模型进行泛化处理,得到泛化后图像分割模型;将测试样本集合输入至泛化后图像分割模型进行训练,得到测试样本集合的病灶语义分割数据;利用病灶识别校正模块,对病灶语义分割数据进行病灶的识别校正,获得测试样本集合的多类别病灶分割类型。本技术实施例达到了智能优化糖网眼底图像数据的类别病灶分割方案,快速定位病灶类别信息,提高病灶图像分割及其多类别病灶识别精准度的技术效果。
附图说明
[0010]
图1为本技术一种糖网眼底图像数据的多类别病灶分割方法的流程示意图;
[0011]
图2为本技术一种糖网眼底图像数据的多类别病灶分割方法的对样本数据进行自定义划分的流程示意图;
[0012]
图3为本技术一种糖网眼底图像数据的多类别病灶分割方法的确定多类别病灶分割类型的流程示意图;
[0013]
图4为本技术一种糖网眼底图像数据的多类别病灶分割系统的结构示意图。
[0014]
附图标记说明:数据获取单元11,数据采集单元12,数据分析单元13,分析处理单元14,训练整合单元15,识别校正单元16。
具体实施方式
[0015]
本技术通过提供了一种糖网眼底图像数据的多类别病灶分割方法及系统,解决了难以对糖网图像进行精细分割,导致难以对病灶进行多类别的精准识别的技术问题,达到了智能优化糖网眼底图像数据的类别病灶分割方案,快速定位病灶类别信息,提高病灶图像分割及其多类别病灶识别精准度的技术效果。
[0016]
实施例一
[0017]
如图1所示,本技术提供了一种糖网眼底图像数据的多类别病灶分割方法,其中,所述方法应用于多类别病灶分割系统,系统包括网络集成模块、病灶识别校正模块,所述方
法包括:
[0018]
s100:从所述多类别病灶分割系统下载图像预分割模型,其中,所述图像预分割模型嵌入有深度学习网络结构;
[0019]
具体而言,通过所述多类别病灶分割系统的数据存储单元,下载图像预分割模型,所述图像预分割模型嵌入有深度学习网络结构,所述多类别病灶分割系统进行数据预处理后,将预处理的数据信息输入所述图像预分割模型,进行数据分析处理,深度学习网络结构可以结合bp反向传播算法进行结构搭建,所述嵌入不表示具体技术操作,代表算法逻辑的嵌入,通过所述多类别病灶分割系统进行数据信息获取,能有效保证数据信息的可靠性。
[0020]
s200:通过对糖网进行历史图像采集,可生成历史图像集合,其中,所述历史图像集合可自定义划分为训练样本集合、测试样本集合;
[0021]
进一步而言,如图2所示,本技术实施例步骤s200还包括:
[0022]
s210:将所述历史图像集合作为样本数据,通过对所述样本数据进行多特征遍历检索,可确定所述样本数据的覆盖度特征、重复度特征以及可用性特征;
[0023]
具体而言,所述样本数据也就是参与数据处理的底层逻辑数据信息,将所述历史图像集合作为样本数据,对所述历史图像集合进行多特征遍历检索,获取所述样本数据的覆盖度特征、重复度特征以及可用性特征,所述覆盖度特征决定了所述历史图像集合的数据类型是否全面,有足够的覆盖性;所述重复度特征决定了所述历史图像集合之间的重复,应避免数据重复,确保所述历史图像集合数据的完整性,一般的,图片的清晰度高,对应的可用性特征数据量大;图片的清晰度低,对应的可用性特征数据量小;通过图片清晰度进行判断可用性特征,结合覆盖度特征、重复度特征共同对所述历史图像集合作为样本数据进行特征表达,结合多个数据特征参数,进一步保障了所述历史图像集合数据的完整性,为确保训练数据的稳定性、提高训练过程的数据处理效率提供技术支持。
[0024]
s220:利用权重分配通道,对所述覆盖度特征、重复度特征以及可用性特征进行权重分配,可确定所述覆盖度特征对应的覆盖度权重占比、所述重复度特征对应的重复度权重占比、所述可用性特征对应的可用性权重占比;
[0025]
具体而言,所述权重分配通道为一功能性通道,具体的,所述权重分配通道分配所得的权重值之和均为1,所述权重分配通道在进行权重分配过程,存在统一的权值分配条件。对所述覆盖度特征、重复度特征以及可用性特征进行权重分配,一般的,所述覆盖度特征对应的覆盖度权值分配条件中要求:覆盖度越大,权重占比越大;覆盖度越小,权重占比越小;所述重复度特征对应的重复度权值分配条件中要求:重复度越小,权重占比越大;重复度越高,权重占比越小;所述可用性特征与可用性权值分配条件中要求对应:可用性越高,权重占比越大;可用性越低,权重占比越小,一般的,在进行权重分配的过程,对训练图像的清晰度要求高,覆盖面要求较广,重复度要求低,对应的,可用性权重占比大,覆盖度权重占比仅次于可用性权重占比,重复度权重占比小。所述权重分配的过程需要结合相关指标要求进行对照分析,具体结合实际数据信息进行对应确定,细化了特征权重分配的逻辑,为实现精确识别糖网眼底图像数据提供技术支持。
[0026]
s230:通过所述覆盖度权重占比、所述重复度权重占比以及所述可用性权重占比,对所述样本数据进行自定义划分。
[0027]
进一步而言,本技术实施例步骤s230还包括:
[0028]
s231:利用所述覆盖度权重占比、所述重复度权重占比以及所述可用性权重占比,对所述样本数据进行权重加和运算,获得权重加和结果;
[0029]
s232:通过样本数据自定义划分逻辑,对所述权重加和结果进行对应匹配,可确定所述权重加和结果对应的目标样本数据划分逻辑。
[0030]
具体而言,利用所述覆盖度权重占比、所述重复度权重占比以及所述可用性权重占比,对所述样本数据进行权重加和运算,所述权重加和可以结合数据特征信息进行具体设定,获得权重加和结果,通过样本数据自定义划分逻辑,所述自定义划分逻辑可以设置为:当权重加和结果满足(50-70),则训练样本数据量:测试样本数据量为70%:30%;当权重加和结果满足(70-80),则训练样本数据量:测试样本数据量为65%:35%;当权重加和结果满足(80-100),则训练样本数据量:测试样本数据量为60%:40%,对所述权重加和结果进行对应匹配,确定所述权重加和结果对应的目标样本数据划分逻辑,所述目标样本数据划分逻辑的划分方式不唯一,实际结合实际的数据信息特征进行具体细化,确定目标样本数据划分逻辑,为保证数据划分逻辑的稳定性提供技术支持,为深度挖掘数据特征信息提供基础。
[0031]
s300:利用所述网络集成模块,对所述图像预分割模型和所述训练样本集合进行移动端的网络集成,用以生成精细化图像分割模型,且所述精细化图像分割模型具备轻量级结构;
[0032]
具体而言,所述网络集成模块为一数据逻辑功能处理模块,通过对所述图像预分割模型和所述训练样本集合进行移动端的网络集成,所述网络集成简单来说就是通过相关算法进行数据集成操作,所述相关算法包括但不限于k-means算法、k-medoids算法等数据集成算法,生成精细化图像分割模型,且所述精细化图像分割模型具备轻量级结构,所述轻量级结构简单来说就是从保持精度减少参数角度对所述精细化图像分割模型的构建过程进行优化,示例性的,用nas通过优化模型的每个网络块来搜索全局网络结构,用netadapt算法搜索每个层的过滤器数量,所述轻量级结构的算法模型的搭建方案不唯一,示例不对实际数据运算分析产生限制,基于轻量级结构的精细化图像分割模型,可以减少数据分析处理过程的计算量,提高所述精细化图像分割模型的数据处理效率。
[0033]
s400:利用所述图像预分割模型,对训练好的所述精细化图像分割模型进行损失分析,并通过分析结果确定泛化参数,用以对所述精细化图像分割模型进行泛化处理,可得到泛化后图像分割模型;
[0034]
进一步而言,本技术实施例步骤s400还包括:
[0035]
s410:将所述图像预分割模型作为teacher端,将所述精细化图像分割模型作为student端;
[0036]
s420:对所述teacher端进行损失函数分析,用以确定对应的teacher端损失参数l
t
;
[0037]
s430:对所述student端进行损失函数分析,用以确定对应的student端损失参数ls;
[0038]
s440:计算所述teacher端损失参数l
t
和所述student端损失参数ls进行加权计算,用以确定所述精细化图像分割模型的损失函数l。
[0039]
具体而言,通过采取teacher-student模式,将所述图像预分割模型作为teacher
端,所述精细化图像分割模型作为student端,teacher图像预分割模型来辅助student精细化图像分割模型的训练,增强所述精细化图像分割模型的泛化能力。所述teacher端损失参数l
t
和所述student端损失参数ls进行加权计算,所述精细化图像分割模型的损失函数l通过teacher端损失参数l
t
和所述student端损失参数ls加权运算确定,所述图像预分割模型的信息复杂且数据量大,以所述图像预分割模型为基础,辅助所述精细化图像分割模型的训练,可以增强精细化图像分割模型的泛化能力。
[0040]
进一步而言,本技术实施例步骤s400还包括:
[0041]
s441:基于公式:l=αl
t
+βls,确定所述精细化图像分割模型的损失函数l,其中,α、β为损失加权系数,α=0.9,β=0.1;
[0042]
s442:基于公式:对所述teacher端进行损失函数分析,其中,l
t
为图像预分割模型文件产生的teacher loss,pi′
是图像预分割模型文件softmax后产生的第i类的概率,vi为图像预分割模型中第i类未归一化的概率,qi′
是经教师网络学习后精细化图像分割模型文件softmax后产生的第i类的概率,zi为精细化图像分割模型第i类未归一化的概率;
[0043]
s443:基于公式:对所述student端进行损失函数分析,其中,ls为精细化图像分割模型文件产生的student loss,n为总类别数,ci为精细化图像分割模型第i类的真值,正样本为1,负样本为0,qi是经真值学习后精细化图像分割模型文件softmax后产生的第i类的概率,
[0044]
具体而言,通过teacher端损失参数l
t
和所述student端损失参数ls加权运算,确定所述精细化图像分割模型的损失函数l,所述精细化图像分割模型的损失函数l=αl
t
+βls,其中,α、β为损失加权系数,α=0.9,β=0.1,α、β均为多次试验计算优选确定,α、β的数值量不唯一。
[0045]
进一步具体说明,对所述teacher端进行损失函数分析,teacher端损失参数所述函数关系不进行具体数值细化,实际使用过程可能会在恒等变形,具体结合实际数据分析过程进行确定,其中,l
t
为图像预分割模型文件产生的teacher loss,n为总类别数(n为正整数),pi′
是图像预分割模型文件softmax后产生的第i类的概率,vi为图像预分割模型中第i类未归一化的概率,qi′
是经教师网络学
习后精细化图像分割模型文件softmax后产生的第i类的概率,zi为精细化图像分割模型第i类未归一化的概率,需了解,所述数据处理方案是进行优选所得,实际数据处理过程需要结合数据特征进行数据处理方案的优化,此处不做赘述。
[0046]
进一步具体说明,对所述student端进行损失函数分析,student端损失参数所述函数关系不进行具体数值细化,实际使用过程可能会在恒等变形,其中,ls为精细化图像分割模型文件产生的student loss,n为总类别数(n为正整数),ci为精细化图像分割模型第i类的真值,正样本为1,负样本为0,qi是经真值学习后精细化图像分割模型文件softmax后产生的第i类的概率,zi为精细化图像分割模型第i类未归一化的概率,需了解,所述数据处理方案是进行优选所得,实际数据处理过程需要结合数据特征进行数据处理方案的优化,训练过程简单来说就是根据输出的语义分割误差,将训练至拟合的模型文件进行保存。基于函数关系模型对数据数理逻辑进行训练拟合,可以加快模型训练效率,为实现眼底糖网图像病灶信息的快速分析处理提供技术支持。
[0047]
s500:将所述测试样本集合输入至所述泛化后图像分割模型进行训练,用以得到所述测试样本集合的病灶语义分割数据;
[0048]
s600:利用所述病灶识别校正模块,对所述病灶语义分割数据进行病灶的识别校正,用以获得所述测试样本集合的多类别病灶分割类型。
[0049]
具体而言,历史图像集合可自定义划分为训练样本集合、测试样本集合,训练样本集合用以构建训练模型,测试样本集合用以测试构建的模型的稳定性,将所述测试样本集合输入至所述泛化后图像分割模型进行模型稳定性测试,所述测试需要先对所述测试样本数据进行分组,每组数据的数据类型均一致,所述数据为糖网眼底图像的特征数据,具体的可以是颜色特征信息、色块分布特征信息及其他相关特征数据信息,将多组测试数据依次输入进行特征处理运算,用以得到所述测试样本集合的病灶语义分割数据;利用所述病灶识别校正模块,对所述病灶语义分割数据进行病灶的识别校正,用以获得所述测试样本集合的多类别病灶分割类型,从技术角度进一步保证了类别病灶分割方案的可靠性,为提高病灶分割结果精准度提供技术支持。
[0050]
进一步而言,如图3所示,本技术实施例步骤s600还包括:
[0051]
s610:所述病灶识别校正模块嵌入有densenet分类图像网络;
[0052]
s620:通过将所述病灶语义分割数据输入至所述densenet分类图像网络,进行分类校正,用以确定所述多类别病灶分割类型。
[0053]
具体而言,所述densenet分类图像网络的基础结构为:xi=hi([x0,x1,
…
,x
i-1
]),其中,xi第i层输出,hi表示第i层进行的非线性变换,符号“[]”表示concatenation(拼接),简单来说就是x0到x
i-1
层的所有输出特征向量按通道组合,训练过程简单来说就是根据输出的分类误差,将训练至拟合的模型文件进行保存,通过将所述病灶语义分割数据输入至所述densenet分类图像网络,具体来说就是将目标糖网眼底图像样本输入至所述densenet分类图像网络并经过分类校正,对病灶图像进行糖网语义分割,进行病灶识别校正,获得更
加准确的病灶结果,确定多类别病灶分割类型,所述多类别病灶分割类型的识别方案为进行方案优选所得,为精准快速进行定位病灶类型信息提供技术支持,提高病灶分割识别效率。
[0054]
进一步具体说明,对病灶图像进行糖网语义分割,进行病灶识别校正,获得更加准确的病灶结果,示例说明,由于糖网眼底图像上的小面积出血外观与微血管瘤相似,难以快速区分,为确保准确性,在所述图像预分割模型后级联了一个densenet分类图像网络,用于区分分割网络结果的病灶类型,经过分类校正,对眼底图像进行糖网语义分割得到病灶精细分割结果,提高糖网眼底图像数据分析的效率,提高多类别病灶分割结果的精准度。
[0055]
进一步而言,本技术实施例还包括:
[0056]
s630:通过所述图像处理监测设备,对所述测试样本集合中的任一在处理图像进行耗时监测,用以得到各图像处理耗时分布;
[0057]
s640:通过对所述各图像处理耗时分布进行异常耗时遍历,用以获取异常处理图像,并进行标记和二次处理。
[0058]
具体而言,所述图像处理监测设备为所述多类别病灶分割系统的运行监测装置,所述多类别病灶分割系统与图像处理监测设备级联,对所述测试样本集合中的任一在处理图像进行耗时监测,获取各图像处理耗时分布,所述耗时量单位需要统一,一般的,耗时量单位可以确定为秒,所述各图像处理耗时分布与病灶类别分布所对应,对所述各图像处理耗时分布进行异常耗时遍历,确定耗时异常的病灶位置对应的异常处理图像,对异常处理图像进行标记,对耗时异常的病灶进行二次处理,提高糖网眼底图像数据分析的时效性。
[0059]
综上所述,本技术所提供的一种糖网眼底图像数据的多类别病灶分割方法及系统具有如下技术效果:
[0060]
1.由于采用了从多类别病灶分割系统下载图像预分割模型;通过对糖网进行历史图像采集,可生成历史图像集合;利用网络集成模块,对图像预分割模型和训练样本集合进行移动端的网络集成,生成精细化图像分割模型;利用图像预分割模型,对训练好的精细化图像分割模型进行损失分析,通过分析结果确定泛化参数,对精细化图像分割模型进行泛化处理,得到泛化后图像分割模型;将测试样本集合输入至泛化后图像分割模型进行训练,得到测试样本集合的病灶语义分割数据;利用病灶识别校正模块,对病灶语义分割数据进行病灶的识别校正,获得测试样本集合的多类别病灶分割类型。本技术通过提供了一种糖网眼底图像数据的多类别病灶分割方法及系统,达到了智能优化糖网眼底图像数据的类别病灶分割方案,快速定位病灶类别信息,提高病灶图像分割及其多类别病灶识别精准度的技术效果。
[0061]
2.由于采用了将图像预分割模型作为teacher端,将精细化图像分割模型作为student端;对teacher端进行损失函数分析,确定teacher端损失参数l
t
;对student端进行损失函数分析,确定student端损失参数ls;计算teacher端损失参数l
t
和student端损失参数ls进行加权计算,确定精细化图像分割模型的损失函数l。图像预分割模型的信息复杂且数据量大,以图像预分割模型为基础,辅助精细化图像分割模型的训练,增强精细化图像分割模型的泛化能力。
[0062]
3.由于采用了基于公式:l=αl
t
+βls,确定精细化图像分割模型的损失函数l;基于
公式:对teacher端进行损失函数分析;基于公式:对student端进行损失函数分析。基于函数关系模型对数据数理逻辑进行训练拟合,可以加快模型训练效率,为实现眼底糖网图像病灶的快速分析处理提供技术支持。
[0063]
实施例二
[0064]
基于与前述实施例中一种糖网眼底图像数据的多类别病灶分割方法相同的发明构思,如图4所示,本技术提供了一种糖网眼底图像数据的多类别病灶分割系统,其中,所述系统包括:
[0065]
数据获取单元11,所述数据获取单元11用于从多类别病灶分割系统下载图像预分割模型,其中,所述图像预分割模型嵌入有深度学习网络结构;
[0066]
数据采集单元12,所述数据采集单元12用于通过对糖网进行历史图像采集,可生成历史图像集合,其中,所述历史图像集合可自定义划分为训练样本集合、测试样本集合;
[0067]
数据分析单元13,所述数据分析单元13用于利用网络集成模块,对所述图像预分割模型和所述训练样本集合进行移动端的网络集成,用以生成精细化图像分割模型,且所述精细化图像分割模型具备轻量级结构;
[0068]
分析处理单元14,所述分析处理单元14用于利用所述图像预分割模型,对训练好的所述精细化图像分割模型进行损失分析,并通过分析结果确定泛化参数,用以对所述精细化图像分割模型进行泛化处理,可得到泛化后图像分割模型;
[0069]
训练整合单元15,所述训练整合单元15用于将所述测试样本集合输入至所述泛化后图像分割模型进行训练,用以得到所述测试样本集合的病灶语义分割数据;
[0070]
识别校正单元16,所述识别校正单元16用于利用病灶识别校正模块,对所述病灶语义分割数据进行病灶的识别校正,用以获得所述测试样本集合的多类别病灶分割类型。
[0071]
进一步的,所述系统包括:
[0072]
特征检索单元,所述特征检索单元用于将所述历史图像集合作为样本数据,通过对所述样本数据进行多特征遍历检索,可确定所述样本数据的覆盖度特征、重复度特征以及可用性特征;
[0073]
权重分配单元,所述权重分配单元用于利用权重分配通道,对所述覆盖度特征、重复度特征以及可用性特征进行权重分配,可确定所述覆盖度特征对应的覆盖度权重占比、所述重复度特征对应的重复度权重占比、所述可用性特征对应的可用性权重占比;
[0074]
定义划分单元,所述定义划分单元用于通过所述覆盖度权重占比、所述重复度权重占比以及所述可用性权重占比,对所述样本数据进行自定义划分。
[0075]
进一步的,所述系统包括:
[0076]
数据处理单元,所述数据处理单元用于利用所述覆盖度权重占比、所述重复度权重占比以及所述可用性权重占比,对所述样本数据进行权重加和运算,获得权重加和结果;
[0077]
匹配确定单元,所述匹配确定单元用于通过样本数据自定义划分逻辑,对所述权重加和结果进行对应匹配,可确定所述权重加和结果对应的目标样本数据划分逻辑。
[0078]
进一步的,所述系统包括:
[0079]
数据分析单元,所述数据分析单元用于将所述图像预分割模型作为teacher端,将
所述精细化图像分割模型作为student端;
[0080]
数据分析单元,所述数据分析单元用于对所述teacher端进行损失函数分析,用以确定对应的teacher端损失参数l
t
;
[0081]
分析确定单元,所述分析确定单元用于对所述student端进行损失函数分析,用以确定对应的student端损失参数ls;
[0082]
参数运算单元,所述参数运算单元用于计算所述teacher端损失参数l
t
和所述student端损失参数ls进行加权计算,用以确定所述精细化图像分割模型的损失函数l。
[0083]
进一步的,所述系统包括:
[0084]
分析确定单元,所述分析确定单元用于基于公式:l=αl
t
+βls,确定所述精细化图像分割模型的损失函数l,其中,α、β为损失加权系数,α=0.9,β=0.1;
[0085]
分析运算单元,所述分析运算单元用于基于公式:分析运算单元,所述分析运算单元用于基于公式:对所述teacher端进行损失函数分析,其中,l
t
为图像预分割模型文件产生的teacher loss,pi′
是图像预分割模型文件softmax后产生的第i类的概率,vi为图像预分割模型中第i类未归一化的概率,qi′
是经教师网络学习后精细化图像分割模型文件softmax后产生的第i类的概率,zi为精细化图像分割模型第i类未归一化的概率;
[0086]
运算处理单元,所述运算处理单元用于基于公式:运算处理单元,所述运算处理单元用于基于公式:对所述student端进行损失函数分析,其中,ls为精细化图像分割模型文件产生的student loss,n为总类别数,ci为精细化图像分割模型第i类的真值,正样本为1,负样本为0,qi是经真值学习后精细化图像分割模型文件softmax后产生的第i类的概率,
[0087]
进一步的,所述系统包括:
[0088]
识别校正单元,所述识别校正单元用于所述病灶识别校正模块嵌入有densenet分类图像网络;
[0089]
分类校正单元,所述分类校正单元用于通过将所述病灶语义分割数据输入至所述densenet分类图像网络,进行分类校正,用以确定所述多类别病灶分割类型。
[0090]
本说明书和附图仅仅是本技术的示例性说明,在不脱离本技术的精神和范围的情况下,可对其进行各种修改和组合。本技术的这些修改和变型属于本技术权利要求及其等同技术的范围之内,则本技术意图包括这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1