一种基于自适应加权损失的SISR网络训练方法及系统
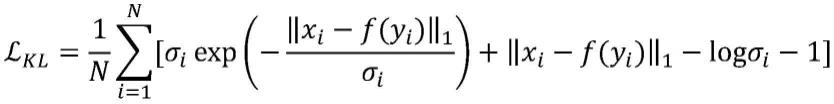
一种基于自适应加权损失的sisr网络训练方法及系统
技术领域
1.本发明涉及一种sisr网络训练方法及系统,具体涉及一种基于自适应加权损失的sisr网络训练方法及系统。
背景技术:
2.近年来,图像传感器的快速发展以及各种图像处理技术的不断更新,让高质量的图像和视频已经应用到了如视频监控(提高公共安全、协助破案等),医学成像(帮助病情分析、病体定位等),高清视频(高清电视、超清影院等),遥感应用(气象监测、环境分析、军事保护等)等与人们生活有着密切联系的领域。
3.现今,随着人们生活质量的提高,人们对图像分辨率的要求也越来越高。要获得高分辨率图像,最直接的办法就是采用高分辨率图像传感器,但由于传感器和光学器件制造工艺和成本的限制,以至于很难在大多数场景中实现这一点。此外,在成像过程中可能受到的外界影响如噪声、场景运动、模糊等,这些都会导致在现实生活中所获得的图像大多无法满足人们的要求。因此,如何使获得的图像拥有更高的分辨率这一视觉任务吸引了人们广泛的注意力。
4.单图像超分辨率(single image super resolution,sisr)是一项计算机视觉底层任务,目的是从相应的退化低分辨率(low resolution,lr)图像中重建高分辨率(high resolution,hr)图像,并增强其中的细节,以达到悦目怡心的目的。一般来说,这个问题天生不适定,因为总是有多个hr图像对应一个lr图像。然而,人们很早就认识到,相较于图像的平滑区域,图像的纹理和边缘区域包含了更重要的视觉信息。
5.到目前为止,人们已经提出了各种经典的单图像超分辨率方法,大致可以分为三种类型:基于插值的方法,基于重构的方法以及基于学习的方法。近年来,随着深度学习技术的快速发展,基于深度学习的单图像超分辨率方法得到了积极的探索。相较于传统单图像超分辨率方法存在的计算复杂度高、效果不理想等问题,基于深度学习的单图像超分辨率方法得益于其学习策略灵活、训练工具强大以及数据集丰富的优点,在性能上具有较好的表现。
6.由于基于深度学习的单图像超分辨率方法具备着强大的非线性表示能力,它在超分辨率中得到了广泛的研究。srcnn是最早将深度学习引入sisr的方法,见:chao dong,chen change loy,kaiming he,and xiaoou tang.learning a deep convolutional network for image super-resolution.in european conference on computer vision,pages 184
–
199,2014.它仅由三个卷积层构成,通过特征提取,非线性映射,特征重构等步骤,达到了恢复出高分辨率图像的目的。在这之后,针对现有研究工作的不足,提出了一系列关于基于深度学习的sisr方法的工作,例如基于残差学习设计了更深层次网络结构的vdsr和edsr,分别见chao dong,chen change loy,kaiming he,and xiaoou tang.image super-resolution using deep convolutional.ieee transactions on pattern analysis and machine intelligence,38(2):295-307,2016.bee lim,sanghyun son,
heewon kim,seungjun nah,and kyoung mu lee.enhanced deep residual networks for single image super-resolution.in 2017 ieee conference on computer vision and pattern recognition workshops(cvprw),pages 1132
–
1140,2017.,通过考虑空间维度或者通道维度的特征相关性来提高超分辨率的性能的rcan和san,分别见yulun zhang,kunpeng li,kai li,lichen wang,bineng zhong,and yun fu.image super-resolution using very deep residual channel attention networks.in proceedings of the european conference on computer vision(eccv),pages 286
–
301,2018.tao dai,jianrui cai,yongbing zhang,shu-tao xia,and lei zhang.second-order attention network for single image super-resolution.in proceedings of the ieee conference on computer vision and pattern recognition,pages 11065
–
11074,2019.
7.基于模型引导设计深度神经网络的dpdnn和mog-dun,分别见weisheng dong,peiyao wang,wotao yin,guangming shi,fangfang wu,and xiaotong lu.denoising prior driven deep neural network for image restoration.ieee transactions on pattern analysis and machine intelligence,41(10):2305
–
2318,2019.qian ning,weisheng dong,guangming shi,leida li,and xin li.accurate and lightweight image super-resolution with model-guided deep unfolding network.ieee journal of selected topics in signal processing,15(2):240
–
252,2021.doi:10.1109/jstsp.2020.3037516.等等。可以看出,沿着这一研究方向的统一主题似乎是,更深、更大和更复杂的网络可以通过促进重构高频细节,恢复图像的纹理和边缘,从而达到提高sisr性能的目的。
8.虽然继续朝着设计更深、更大和更复杂的网络这一方向进行研究,进一步提升神经网络模型的性能,但是这也同时会造成复杂的、参数量过大的模型结构,从而难以应用到实际场景中。
技术实现要素:
9.本发明的目的是提供基于自适应加权损失的sisr网络训练方法及系统,克服现有基于深度学习的单图像超分辨率方法为提升网络性能,盲目设计的神经网络模型结构复杂、参数量过大,难以应用到实际场景中的问题。
10.本发明的构思是:
11.现有的方法大多采用mse或损失函数来优化网络参数。mse或损失函数是在假设所有像素的重要性相同的前提下,平等对待每个像素,无论该像素是在纹理/边缘区域还是在光滑区域。但是,在摄影图像中,纹理和边缘区域比平滑区域承载更重要的视觉信息。因此,本发明通过在训练过程中赋予图像纹理和边缘区域更高的权重,在推理过程中无需增加额外的计算复杂度,不仅改善了客观性能而且恢复出了更高的视觉质量,这非常适用于需要生产高清图像的场景。
12.本发明的技术方案是提供一种基于自适应加权损失的sisr网络训练方法,其特殊之处在于,包括以下步骤:
13.步骤1、构建整体观测模型;
14.xi=f(yi)+∈σi,
15.其中y表示低分辨率lr图像,x表示低分辨率lr图像对应的高分辨率hr图像,i为像素点,f(
·
)表示任意的sisr网络,f(yi)表示sisr网络学习到超分辨sr图像,∈表示零均值和单位方差的拉普拉斯分布,σi表示sisr网络学习到的任意不确定性;
16.步骤2、向sisr网络输入低分辨率lr图像,训练sisr网络,同时学习f(yi)与σi;
17.步骤3、将步骤2学习的σi作为指导,计算自适应加权损失的损失函数:
[0018][0019]
其中wi=w
i-min(wi)是一个非负线性缩放函数;wi=lnσi,n为像素点数目;
[0020]
步骤4、基于损失函数指导sisr网络训练。
[0021]
进一步地,步骤2中基于下式同时学习f(yi)与σi:
[0022][0023]
其中l为拉普拉斯分布,为损失函数。
[0024]
本发明还提供一种基于自适应加权损失的sisr网络训练系统,其特殊之处在于:包括生成单元、计算单元与训练单元;
[0025]
生成单元,用于构建整体观测模型;
[0026]
xi=f(yi)+∈σi[0027]
其中y表示低分辨率lr图像,x表示低分辨率lr图像对应的高分辨率hr图像,i为像素点,f(
·
)表示任意的sisr网络,f(yi)表示sisr网络学习到超分辨sr图像,∈表示零均值和单位方差的拉普拉斯分布,σi表示sisr网络学习到的任意不确定性;
[0028]
计算单元,用于训练sisr网络,学习f(yi)与σi,同时将学习的σi作为指导,计算不确定性驱动的损失函数
[0029][0030]
其中是一个非负线性缩放函数;wi=lnσi,n为像素点数目;
[0031]
训练单元,用于基于不确定性驱动的损失函数对网络模型进行训练。
[0032]
进一步地,计算单元基于下式同时学习f(yi)与σi:
[0033][0034]
其中l为拉普拉斯分布,为损失函数。
[0035]
本发明的有益效果是:
[0036]
本发明通过在sisr网络中引入差异分布估计,可以同时学习高分辨率图像的均值
(超分辨率图像)及其对应的不确定性(方差)。最终,确定性较高的像素(例如,纹理和边缘像素)将根据其对视觉质量的重要性被sisr优先排序。本发明提出的这种不确定性驱动的损失比mse或损失具有更好的效果。在常用的sisr网络上的实验结果表明,在测试过程中不增加任何计算量的情况下,本发明提出的不确定性驱动的损失函数比传统的损失函数取得了更好的psnr结果以及更好的视觉效果。
附图说明
[0037]
图1为在数据集set14上,hr图像、edsr网络重建的sr图像以及二者之间的差异;其中(a)为数据集set14,(b)为hr图像,(c)为edsr网络重建的sr图像,(d)为hr图像和edsr网络重建的sr图像之间的差异;
[0038]
图2为实施基于自适应加权损失的sisr网络训练流程示意图;
[0039]
图3为用不同损失函数训练的edsr-s在urban100数据集(双三次下采样4倍)上的视觉质量比较,其中(a)为hr图像,(b)为edsr-s网络重建的sr图像,(c)为gram损失函数训练的图像,(d)为udl损失函数训练的图像,(e)为损失函数训练的图像,(f)为损失函数训练得到的不确定性;
[0040]
图4为用不同损失函数训练的dpdnn在urban100数据集(双三次下采样4倍)上的视觉质量比较,其中(a)为hr图像,(b)为dpdnn网络重建的sr图像,(c)为gram损失函数训练的图像,(d)为udl损失函数训练的图像,(e)为损失函数训练的图像,(f)为损失函数训练得到的不确定性;
具体实施方式
[0041]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合说明书附图对本发明的具体实施方式做详细的说明,显然所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明的保护的范围。
[0042]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
[0043]
现有的方法大多采用mse或损失函数来优化网络参数。众所周知,传统的mse或损失函数是在假设所有像素的重要性相同的前提下,平等对待每个像素,无论该像素是在纹理/边缘区域还是在光滑区域。但是,在摄影图像中,纹理和边缘区域比平滑区域承载更重要的视觉信息。例如,对比图1所示的hr图像和edsr网络重建的sr图像,可以发现恢复的纹理区域(如狒狒的毛发)不如光滑区域(如狒狒的鼻子)。图1中(d)描述了hr图像与edsr网络重建的sr图像的绝对差异,从图中可以观察到随空间变化的差异。这种观察表明,以方差为特征的纹理和边缘区域的不确定性要比光滑区域大得多。为此,如何解决这种不确定性奠定了本发明的研究基础。
[0044]
深度学习中的不确定性大致可以分为两类。认知/模型的不确定性描述了模型对
其预测的不确定性程度。另一种类型是任意/数据不确定性,指的是观测数据中固有的噪声。alex kendall and yarin gal.what uncertainties do we need in bayesian deep learning for computer vision?in i.guyon,u.v.luxburg,s.bengio,h.wallach,r.fergus,s.vishwanathan,and r.garnett,editors,advances in neural information processing systems,volume 30.curran associates,inc.,2017.中提出了一个贝叶斯深度学习框架,将任意不确定性与认知不确定性相结合,用于逐像素语义分割和深度回归任务。jie chang,zhonghao lan,changmao cheng,and yichen wei.data uncertainty learning in face recognition.in proceedings of the ieee/cvf conference on computer vision and pattern recognition,pages 5710-5719,2020.用估计的平均值和方差研究了人脸识别中的数据不确定性。这些工作提出的基于不确定性的损失函数可归纳为:
[0045][0046]
其中f(yi)和分别表示学习到的均值和方差。在这些任务中,使用上述损失函数将具有高不确定性的像素作为不可靠像素,并承担损失衰减,确实提高了它们对含噪声数据的鲁棒性。然而,在sisr任务中,应该优先考虑高不确定性的像素(如复杂的纹理或边缘区域),因为这些区域在视觉上比平滑区域中的像素更重要,所以将上述损失函数应用于sisr会导致性能下降。
[0047]
与本发明相关的最新进展是gram和udl,分别见changwoo lee and ki-seok chung.gram:gradient rescaling attention model for data uncertainty estimation in single image super resolution.in 2019 18th ieee international conference on machine learning and applicatiohs(icmla),pages 8-13.ieee,2019.qian ning,weisheng dong,xin li,jinjian wu,and guangming shi.uncertainty-driven loss for single image super-resolution.advances in neural information processing systems,34,2021.,其中,gram分析了任意/数据不确定性对sisr重建的影响,降低了方差较高的像素的损失衰减,该方法较于直接将不确定性损失函数应用于sisr得到了更好的结果。然而,当像素方差较高时,gram的损失仍然是衰减的,这仍然与纹理和边缘区域的像素更重要的直觉相矛盾。因此,由于gram不能优先考虑方差高的像素,它仍然低于基线方法;udl通过在深度贝叶斯框架下量化sisr中的不确定性,提出了一种新的不确定性驱动的损失函数udl,使网络更集中于方差较高的像素,以更好地重构纹理和边缘区域,取得了比基线方法更好的表现。
[0048]
本发明提出了一种新的自适应加权损失的损失函数(kl-udl)。通过将真实图像x与恢复图像f(y)之间的差异建模成拉普拉斯分布l(x
i-f(yi),σi),并显式地约束这个分布接近拉普拉斯分布l(o,i),即最小化两个拉普拉斯分布的kullbacklebler(kl)散度来量化sisr中的不确定性,本发明提出的方法在取得了比基线方法更好的表现的同时,也取得了比同类方法更好的结果。
[0049]
与传统的mse或损失平均处理每个像素不同,本发明提出的新的自适应加权损
失函数旨在优先处理恢复的图像与真实地面图像差异大的像素,它们大多是纹理和边缘像素,这些像素在视觉上比平滑区域的像素更重要。为此,本发明介绍了一种在sisr中同时估计sr图像中间结果(均值)和不确定性(方差)的方法。
[0050]
先前的研究表明,在高级视觉任务(如图像分割)中,任意不确定性可以性能的改进以及提高对含噪声数据的鲁棒性。这种改进可以通过衰减不确定性较高的像素的权重来解释。然而,在低级的视觉任务(如sisr)中,衰减必须朝着相反的方向进行——也就是说,应该给不确定性较高的像素分配更大的权重(例如,纹理和边缘像素),因为它们在视觉上比平滑区域中的像素更重要。需要指出的是,现有的工作如gram不能识别这种差异,并没有优先考虑不确定性较高的像素,udl识别到了这种差异。与udl方法不同,本发明提出了一种新的自适应加权损失——基于kl散度的不确定性驱动损失(kl-based uncertainty-driven loss,kl-udl),它将重点关注sisr中恢复图像与真实图像的差异分布。
[0051]
在贝叶斯模型中有两类不确定性:捕获观测数据固有噪声的任意不确定性和解释模型对其预测的不确定性的认知不确定性。本发明选择研究前者(任意不确定性),通过设计新的不确定性驱动损失函数,探索其在sisr中的应用。为了更好地量化sisr中的任意不确定性,使用yi,xi分别表示lr图像和对应的高分辨率hr图像。设f(
·
)表示任意的sisr网络,任意不确定性可以用加法项σi表示。这样,整体观测模型可以表示为:
[0052]
xi=f(yi)+∈σi,
[0053]
其中∈表示零均值和单位方差的拉普拉斯分布。现有的基于深度学习的sisr方法的目标是训练网络只学习sr图像(均值)f(yi)。为了更准确地描述sisr的任意不确定度,本发明不仅估计sr图像(均值)f(yi),而且同时估计不确定度(方差)σi。
[0054]
首先,说明两个拉普拉斯分布的kl散度。拉普拉斯分布p(z)和拉普拉斯分布q(z)可表示为:
[0055][0056][0057]
式中p(z)表示z服从均值μ1和方差σ1的拉普拉斯分布,q(z)表示z服从均值μ2和方差σ2的拉普拉斯分布。
[0058]
那么,p(z)和q(z)的kl散度可表示为:
[0059][0060]
当p(z)=l(x
i-f(yi),σi),q(z)=l(0,i)时,即本发明将真实图像xi与恢复图像f(yi)之间的差异建模成拉普拉斯分布,希望将这个差异的分布拟合成一个零均值、标准差的拉普拉斯分布,所以可以得到:
[0061][0062]
其中,f(yi)和σi分别表示深度神经网络学习到的sr图像(均值)和不确定性(方差)。
[0063]
使用损失可以准确地估计不确定性(方差),但它在sisr中仅能带来微弱的性能提升,结果如表1所示。这一观察的原因是损失函数没有将方差项(σi)剥离出来,难以控制当前像素应受到多大程度的惩罚。如图1所示,不确定性较大的像素携带着纹理、边缘等视觉上的重要信息,因此,方差较大的像素应赋予更大的权重。
[0064]
表1对bi退化的五个数据集研究l
kl
损失函数的平均psnr和ssim结果
[0065][0066]
为了更好地对具有较大不确定性的像素进行排序,提出了一种新的自适应加权损失——基于kl的不确定性驱动损失(kl-udl):
[0067][0068]
其中是一个非负线性缩放函数。为了防止不确定度值退化为零,将第一步的不确定度估计网络的结果作为注意信号传递到第二步(wi=lnσi),如图2所示。
[0069]
通过利用对数方差来表示具有较高不确定性的复杂像素点,本发明提出了一种新的加权损失——不确定性驱动损失在损失中,不确定性较高的区域如图像的纹理、边缘往往比平滑区域的像素具有更大的权重。综上所述,估计的不确定性σi作为连接两步的桥梁:它是第一步的输出;但将其转移到第二步,作为计算损失的指导。
[0070]
本发明还可以提供一种基于自适应加权损失的sisr网络训练系统,包括生成单元、计算单元与训练单元;生成单元,用于构建整体观测模型;计算单元,用于训练sisr网络,基于下式同时学习f(yi)与σi:
[0071][0072]
计算单元还用于将学习的σi作为指导,计算不确定性驱动的损失函数;
[0073][0074]
训练单元,用于基于不确定性驱动的损失函数对网络模型进行训练。
[0075]
为了证明本发明提出的不确定性驱动损失函数的有效性,设计了bi退化模型即双三次下采样在五个基准数据集上的实验。此外,还选择了两个不同的网络来验证所提出的不确定性驱动损失函数的有效性。第一个是edsr-s主要由16个具有64个通道的resblock组成,具有1.5m参数。第二个是dpdnn,它的去噪网络是模型引导框架下的u-net。
[0076]
表2在5个基准数据集上,bi退化的平均psnr和ssim结果
[0077][0078]
对于双三次下采样(bi),在两种不同的sisr网络上比较了我们提出的损失函数、udl、gram和原始损失函数(mse或)。表2中的平均psnr(峰值信噪比)和ssim(结构相似性)结果来自于相应的论文或官方发布的代码的再训练。由此可以看出,本发明提出的损失函数在psnr和ssim结果方面均优于gram和原始损失函数(mse或),几乎均优于udl损失函数。并且,本发明所提出的方法所实现的改进不会在测试期间带来任何额外的计算成本。通过对比edsr-s和dpdnn的情况,本发明提出的可以带来比大型网络更大的性能提升。视觉图像对比结果如图3和图4所示。如图3所示,本发明提出的比原始损失函数、gram和udl恢复的更好。图3中(f)描述了我们的学习到的不确定性,揭示了重构性能较差的具有挑战性的像素。从图4中(e)可以看出,窗口的线条恢复得更加清晰,精确估计的不确定性如(f)所示。的视觉质量提升主要是因为我们提出的方法能够充分利用捕获的不确定性来训练深度网络,从而聚焦于不确定性较高的挑战性像素。
[0079]
综上所述,本发明提出了一种新的自适应加权损失算法来训练sisr网
络,该网络主要针对不确定性较高的挑战性像素(如纹理像素和边缘像素)。通过在sisr中引入差异分布估计,可以同时学习高分辨率图像的均值及其对应的不确定性(方差)。最终,确定性较高的像素(例如,纹理和边缘像素)将根据其对视觉质量的重要性被sisr优先排序。本发明证明了这种不确定性驱动的损失比mse或损失具有更好的效果。在常用的sisr网络上的实验结果表明,在测试过程中不增加任何计算量的情况下,我们提出的基于kl散度的不确定性驱动的损失函数比传统的损失函数取得了更好的psnr结果以及更好的视觉效果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1