一种基于LSTM的双阶段分解风向预测方法
一种基于lstm的双阶段分解风向预测方法
技术领域
1.本技术属于风向预测技术领域,尤其是涉及一种基于lstm的双阶段分解风向预测方法。
背景技术:
2.随着世界能源日渐枯竭,风力发电作为一种环保可再生的新能源正在迅猛发展着,其电网接入量也在持续增长。在风力发电中,偏航系统是风电机组的重要组成部分,它是风电机组快速高效完成对风操作、减少风电机组功率损失的执行机构。然而,由于风向具有随机、间歇和不稳定性等特点,不仅给风电机组的高效控制带来了严峻挑战,甚至在风电转化效能上也产生着明显的冲击。所以,要实现偏航系统的高效调节,提高风电机组的发电效率和风电的产能利润,就离不开准确的风向预测模型。
技术实现要素:
3.本技术的目的是提供一种基于lstm的双阶段分解风向预测方法,通过双阶段分解对风向的原始时间序列数据进行分解,以充分挖掘时间序列数据潜在特征;再利用深度学习方法建立风向预测模型,分别对分解后的各个子序列进行预测;最后将各个子序列的预测结果通过线性集成得到原始时间序列的预测结果,提高了时间序列预测的精度,实现对未来短期风向数据的精准预测。
4.为实现上述目的,本技术所采取的技术方案是:
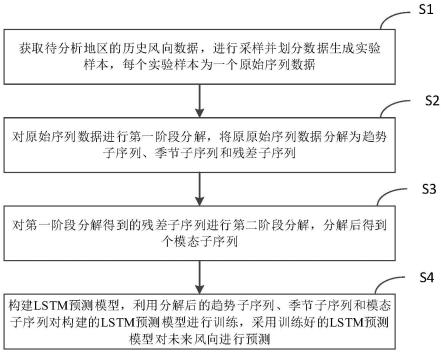
5.一种基于lstm的双阶段分解风向预测方法,包括:
6.获取待分析地区的历史风向数据,进行采样并划分数据生成训练样本,每个训练样本为一个原始序列数据;
7.对原始序列数据进行第一阶段分解,将原始序列数据分解为趋势子序列、季节子序列和残差子序列;
8.对第一阶段分解得到的残差子序列进行第二阶段分解,分解后得到h个模态子序列;
9.构建lstm预测模型,利用分解后的趋势子序列、季节子序列和模态子序列对构建的lstm预测模型进行训练,采用训练好的lstm预测模型对未来风向进行预测。
10.进一步的,所述进行采样并划分数据生成训练样本,包括:
11.对历史风向数据进行固定时长间隔的采样,将采样得到的所有采样数据按照预设的数据量进行划分,得到训练样本;
12.将训练样本中的每个数据除以360,获得类归一化处理后的训练样本。
13.进一步的,所述对原始序列数据进行第一阶段分解,将原始序列数据分解为趋势子序列、季节子序列和残差子序列,包括:
14.初始化分解参数,开始内循环;
15.用原始序列数据减去上一轮内循环的趋势子序列,去除趋势;
16.对去趋势后的子序列进行平滑操作,获取周期子序列;
17.去除周期子序列中的低频序列,得到季节子序列;
18.用原始序列数据减去本轮内循环的季节子序列,去除季节;
19.对去季节后的子序列进行平滑操作,得到趋势子序列;
20.计算得到残差子序列;
21.判断残差子序列是否小于给定阈值,若小于,则分解完成,输出最终的趋势子序列、季节子序列和残差子序列;若不小于,则进入外循环计算鲁棒权值,然后继续进入下一次内循环。
22.进一步的,所述对第一阶段分解得到的残差子序列进行第二阶段分解,采用vmd分解法进行第二阶段分解,包括:
23.将残差子序列表示为函数f(t),将函数f(t)分解为h个模态函数u(t),其中t表示时间变量,对每个模态函数ui(t)(i∈[1,h])进行希尔伯特变换,以获得其单边频谱u
′i(t),计算公式如下:
[0024][0025]
其中,δ(t)是狄拉克分布,j表示变换过程中的一个固定常数;
[0026]
以各个模态的中心频率ωi(t)为基准,将每个模态的单边频谱u
′i(t)通过如下公式调制到其相应基频带ψi(t),计算公式如下:
[0027][0028]
构建变分模型:
[0029][0030]
其中,f(t)为残差子序列数据,δ
t
(ψi(t))表示ψi(t)关于时间变量t的导数;
[0031]
构造拉格朗日函数l,通过加入二次正则化因子c和拉格朗日乘子θ(t),构造的拉格朗日函数l表达式如下:
[0032][0033]
其中,ui(t)表示第i个模态函数,θi(t)表示第i个拉格朗日乘子,h表示模态函数的个数,δ(t)表示狄拉克分布,ψi(t)表示第i个模态函数相应的基频带,f(t)表示为残差子序列的函数;
[0034]
利用交替迭代乘子法,按照下式交替迭代求解拉格朗日函数l的最优解:
[0035][0036][0037]
[0038]
其中,分别是f(t),ui(t),θ(t),的傅里叶变换结果,n为迭代次数,n为最大迭代次数(n∈[1,n]),τ表示噪声容忍度是一个常数,τ∈(0,1);
[0039]
当满足以下条件迭代终止:
[0040][0041]
其中,e为停止阈值,满足条件时迭代终止,输出分解所得的h个模态子序列。
[0042]
本技术提出的一种基于lstm的双阶段分解风向预测方法,采用stl(seasonal-trend decomposition procedure based on loess,基于局部加权回归的季节趋势分解)分解法对随机、间歇、不稳定的风向数据进行特征选取,筛选出相关度高的特征;同时采用vmd(variational mode decomposition,变分模态分解)分解法对变化规律不明显的残差分量进行二次分解,进一步挖掘风向输入的特征信息;最后采用lstm神经网络构建风向预测模型对分解所得的各个子序列进行预测,最后将预测结果相加得到最终的预测结果。本技术基于数据分解-特征提取策略的风向预测方法,具有适应性好、参数不敏感、预测精度高等特点,实现了风向的精确预测。
附图说明
[0043]
图1为本技术基于lstm的双阶段分解风向预测方法流程图;
[0044]
图2为本技术实施例stl分解方法流程图;
[0045]
图3为本技术实施例vmd分解方法流程图。
具体实施方式
[0046]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅用以解释本技术,并不用于限定本技术。
[0047]
在一个实施例中,如图1所示,提供了一种基于lstm的双阶段分解风向预测方法,包括:
[0048]
步骤s1、获取待分析地区的历史风向数据,进行采样并划分数据生成训练样本,每个训练样本为一个原始序列数据。
[0049]
本技术通过构建风向预测模型,采用历史风向数据训练构建的风向预测模型,对未来短期风向数据进行精准预测。
[0050]
本实施例采用待分析地区的历史风向数据来生成训练样本数据集,即对历史风向数据进行固定时长间隔的采样,将采样得到的所有采样数据按照预设的数据量进行划分,得到训练样本。然后将训练样本中的每个数据除以360,获得类归一化处理后的训练样本。
[0051]
具体的,获取风电场数据存储服务器的历史数据库,设置的采样数据点为风向值,采样间隔为固定时长。将所有采样数据按照预设的数据量划分多个样本,保证每个样本的数据量相等,例如每个训练样本中包括几个数据。对每个训练样本的数据进行类归一化的预处理操作,具体为把每个数据点的值除以360的到一个新值,然后每个新值组成的序列设为训练样本的原始序列。预处理后的每个训练样本为一个原始序列数据,是一个数据序列,
序列中每个数据即一个采样数据点。
[0052]
步骤s2、对原始序列数据进行第一阶段分解,将原始序列数据分解为趋势子序列、季节子序列和残差子序列。
[0053]
具体的,本技术对预处理后的原始序列数据采用stl(seasonal-trend decomposition procedure based on loess,基于局部加权回归的季节趋势分解)分解方法进行第一阶段分解,分解方法由内循环和外循环组成,内循环负责计算得到趋势子序列和季节子序列,外循环负责计算得到残差子序列。对于原始序列数据中每个数据点进行分解,然后分解后的各个数据组成子序列。三个子序列之间的关系可以用公式(1)表示:
[0054]yt
=t
t
+s
t
+r
t t=1,2,
…nꢀꢀꢀ
(1)
[0055]
其中,y
t
表示原始序列数据中t时刻的数据点,t
t
表示趋势子序列中t时刻的数据点,s
t
表示季节子序列t时刻的数据点,r
t
表示残差子序列t时刻的数据点。
[0056]
stl所述分解方法如图2所示,具体步骤如下:
[0057]
2.1)、初始化分解参数,开始内循环。
[0058]
首先设置好内循环数n(i)、外循环数n
(o)
、单个周期数据点的数量n
(p)
、第一平滑参数n
(s)
、第二平滑参数n
(l)
和第三平滑参数n
(t)
,然后开始第k轮内循环,用分别表示第k-1轮内循环结束时t时刻的趋势子序列和季节子序列,当k=0时初始化趋势子序列其中k表示内循环轮数,t表示时间。
[0059]
2.2)、用原始序列数据减去上一轮内循环的趋势子序列,去除趋势。
[0060]
用原始序列y
t
减去上一轮内循环的趋势子序列得到去除趋势后的子序列计算公式如下:
[0061][0062]
2.3)、对去趋势后的子序列进行平滑操作,获取周期子序列。
[0063]
对去趋势后的子序列做q=n
(s)
,d=1的loess(locally weighted regression,局部加权回归)平滑操作,其中q和d是loess平滑操作中的参数,n
(s)
为参数q的预设值。loess平滑操作不仅对子序列的每个数据点都计算了平滑值,还包括子序列前一个周期的数据点和后一个周期的数据点。平滑操作后得到长度为(n+2*n
(p)
)的周期子序列
[0064]
2.4)、去除周期子序列中的低频序列,得到季节子序列。
[0065]
对周期子序列依次做长度为n
(p)
、n
(p)
、3的移动平均,然后再做q=n
(l)
,d=1的loess平滑操作,得到低频序列然后用公式(3)计算出第k轮内循环的季节子序列计算公式如下:
[0066][0067]
2.5)、用原始序列减去本轮内循环的季节子序列,去除季节。
[0068]
用原始序列y
t
减去本轮内循环的季节子序列得到子序列计算公式如下:
[0069][0070]
2.6)、对去季节后的子序列进行平滑操作,得到趋势子序列。
[0071]
对去季节的子序列做q=n
(t)
,d=1的loess平滑操作,得到第k轮内循环的趋势子序列其中n
(t)
表示对子序列做loess平滑操作中参数q的预设值。
[0072]
2.7)、计算得到残差子序列
[0073]
计算公式如下:
[0074][0075]
2.8)、判断残差子序列是否小于给定阈值,若小于,则分解完成,输出最终的趋势子序列、季节子序列和残差子序列;若不小于,则进入外循环计算鲁棒权值,然后继续进入下一次内循环。
[0076]
进入外循环计算鲁棒权值时,定义t时刻数据的鲁棒权值为ρ
t
,则有如下公式:
[0077][0078]
其中,r
t
表示t时刻的残差子序列数据,median()表示中值函数,b()表示双平方函数,u表示b函数的自变量,b函数表达式如下:
[0079][0080]
由此得到鲁棒权值ρ
t
,用于减少外循环对下一个内循环中季节和趋势更新的影响。
[0081]
步骤s3、对第一阶段分解得到的残差子序列进行第二阶段分解,分解后得到h个模态子序列。
[0082]
本实施例采用vmd(variational mode decomposition,变分模态分解)分解法进行第二阶段分解,将残差子序列函数分解为h个模态函数,如图3所示,分解步骤如下:
[0083]
解析残差子序列:将残差子序列表示为函数f(t),可将其分解为h个模态函数u(t),其中t表示时间变量,对每个模态函数ui(t)(i∈[1,h])进行希尔伯特变换(hilbert transform),以获得其单边频谱u
′i(t),计算公式如下:
[0084][0085]
其中,δ(t)是狄拉克分布(dirac distribution),j表示变换过程中的一个固定常数。π为常数。
[0086]
以各个模态的中心频率ωi(t)为基准,将每个模态的单边频谱u
′i(t)通过公式(8)调制到其相应基频带ψi(t),计算公式如下:
[0087]
[0088]
构建变分模型:若要使得残差子序列被分解为h个模态子序列,则需要保证分解序列为具有中心频率ωi(t)的有限带宽的模态函数ui(t),且各模态函数ui(t)的估计带宽之和最小。约束条件为每个模态函数ui(t)相加之和相等于残差子序列函数f(t)。
[0089]
进而构造如下变分模型:
[0090][0091]
其中,f(t)为残差子序列数据,δ
t
表示对公式9求时间变量t的导数。
[0092]
求解变分模型:构造拉格朗日函数l,通过加入二次正则化因子c和拉格朗日乘子θ(t),将上述约束变分问题转化为无约束变分问题,构造的拉格朗日函数l表达式如下:
[0093][0094]
其中,ui(t)表示第i个模态函数,θi(t)表示第i个拉格朗日乘子,h表示模态函数的个数,δ(t)表示狄拉克分布,ψi(t)表示第i个模态函数相应的基频带,f(t)表示为残差子序列的函数。
[0095]
接着,利用交替迭代乘子法连续更新各模态子序列及其中心频率,最终可以得到变分模型的最优解。所有的模态子序列都可以根据如下公式得到:
[0096][0097][0098][0099]
其中,分别是f(t),ui(t),θ(t),的傅里叶变换结果,n为迭代次数,n为最大迭代次数(n∈[1,n]),τ表示噪声容忍度是一个常数,τ∈(0,1)。是第n+1次迭代的模态函数,同理是第n次迭代的模态函数,也就是说本实施例中所有含有n或n+1的变量均表示相应迭代次数对应的变量,这里不再赘述。
[0100]
其中公式(12)、(13)负责更新,将每次分解循环得到的模态子序列的傅里叶变换带入公式进行更新,然后再更新中心频率,不断循环更新直到当前分解数i达到目标分解数h。然后根据公式(14)更新拉格朗日乘子,进入到下一步的迭代条件判断步骤。
[0101]
当满足以下条件迭代终止:
[0102][0103]
其中,e为停止阈值。若满足上述条件时迭代终止,输出分解所得的h个模态子序列。
[0104]
步骤s4、构建lstm预测模型,利用分解后的趋势子序列、季节子序列和模态子序列对构建的lstm预测模型进行训练,采用训练好的lstm预测模型对未来风向进行预测。
[0105]
本实施例将训练样本进行两次分解后所得到的趋势子序列、季节子序列和h个模态子序列,作为lstm(long short time memory,长短期记忆网络)预测模型的数据集,对构建的lstm预测模型进行训练。
[0106]
构建lstm预测模型时,第一层神经网络用于输入训练集数据,随后加入一层输出为一维的神经网络,并设置合适的激活函数,最终对模型进行编译。接着,继续选择合适的损失函数和优化器,模型构建完成。
[0107]
本实施例lstm预测模型涉及参数:输入特征维数、输出特征维数、每层网络的神经元数;优化器、最大迭代数、梯度阈值、初始学习率、学习率下降的迭代次数和衰落因子。
[0108]
在训练时,将训练集数据导入预测模型训练并保存,得到训练好的lstm预测模型。
[0109]
在对未来风向进行预测时,加载训练完成的模型,将测试集数据输入到lstm预测模型,得到各个子序列的预测结果。最后,把各个子序列的预测结果通过线性集成得到最终的预测结果。
[0110]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1