一种基于多模态融合的肿瘤分类方法及系统
1.该发明创造涉及一种面向医学影像多模态融合的肿瘤分类方法及系统。
背景技术:
2.肿瘤是指机体在各种致瘤因子的作用下,局部组织细胞增生形成的新生物。不同肿瘤对人体会有不同的危害,从肿瘤大类来说,恶性肿瘤对人体的危害极大,甚至会造成患者的死亡,而一些良性肿瘤虽然不会恶变、很少复发、生长缓慢,但是依然对人体有一定的危险,特别是长在身体要害部位将会造成严重后果。从肿瘤的不同亚型来说,不同类型的肿瘤会对人体不同部位造成一定的危害,如神经鞘瘤通常会造成神经压迫、肺部肿瘤会造成呼吸性疾病等等。目前临床上,对肿瘤的分类主要基于病理切片的病理诊断结果,如何在早期通过患者影像数据对肿瘤的类别进行及时预判,制定相应的治疗方案,对于患者预后具有非常重要的临床意义。
3.由于肿瘤病理的复杂性,即使经验丰富的影像科医生或临床医生,也很难直接通过早期影像数据准确给出患者所患肿瘤的类别,往往需要依赖后期病理切片的病理诊断结果才能确定。随着计算机技术和图像处理技术的发展,基于医学图像的辅助诊断技术得到越来越多的关注。基于患者影像数据直接对肿瘤的类别进行人工智能判别具有极大的挑战,现有方法大都基于单个模态进行肿瘤的分析,缺乏对患者多种模态影像数据的有效融合,同时如何在小样本的情况下,提升模型分类性能,目前还缺乏相关的研究和有效的技术手段。
4.目前大多数利用影像数据对肿瘤进行分类的方法都是基于机器学习或深度学习,基于机器学习的方法通常使用手工设计的特征或者使用特定的医学图像分析软件提取出影像特征,然后使用机器学习分类器,如svm、k-means等方法来进行肿瘤的分类。基于深度学习的方法,通常以完整的扫描影像或者肿瘤区域影像作为输入,然后利用基于卷积神经网络的模型或者基于注意力机制的模型来进行肿瘤分类。通常基于深度学习的分类方法能够比基于机器学习的分类方法具有更好的性能。
5.目前大多数医学影像分析方法都是基于患者单一平面或者单一模态的影像数据,无法全面而准确的表征肿瘤的信息。而在临床应用上,影像科医生在进行肿瘤判别的时候往往会观察不同的扫描模态(如ct、mri等),不同的扫描平面(如轴位、矢状位、冠状位等),甚至是不同的序列(如t1、t2等),序列指的是采用不同扫描参数所获取到的不同的扫描序列,通常每个序列会包含多帧连续的影像。除此之外,还有其他的数据形式,如患者的年龄、既往病史等等,这些数据都可以被称为患者的多模态数据,医生在综合患者多种模态的数据信息之后,才会做出最终的判别结果。然而,目前大多数方法缺乏对患者不同模态数据的关联和融合,无法对多模态数据进行有效的挖掘和利用。另外,目前大多数深度学习方法依赖大量的有标注数据,针对训练数据量有限的分类任务,识别性能还有待提升。
技术实现要素:
6.本发明综合考虑患者不同模态的数据,并对其进行关联和匹配,以充分挖掘患者多模态数据之间的内在关联,得到多模态数据的肿瘤类别。同时,利用无监督学习在大量源域数据上构建预训练模型,并迁移到下游的肿瘤分类任务上,以进一步提升模型的分类性能。
7.本发明通过在患者不同模态的数据之间构建图结构,对图中的边进行特征提取和融合,并在决策级进行可信边集的筛选以及临床信息的融合,能够充分挖掘不同模态影像数据之间的关系,并将不同模态的影像数据以及临床信息进行融合,能够极大的提升多模态影像数据的分类精度。另外,针对肿瘤有标注样本量有限的难题,本发明通过无监督学习构建预训练模型,并将其迁移到下游的肿瘤分类任务上,能够进一步提升模型的分类性能精度。
8.具体来说,本发明提出一种基于多模态融合的肿瘤分类方法,其中包括:
9.步骤1、根据来自同一位用户的多模态影像构建多模态图,多模态图中顶点为该多模态影像中单帧影像,多模态图中边为模态相异的顶点间的匹配边;
10.步骤2、使用肿瘤分类模型对多模态图中所有匹配边进行特征的提取和融合,得到每条边的置信度;
11.步骤3、根据每条边的置信度,选择并构建出一个可信边集合,将可信边集的置信度和该用户的临床信息进行加权融合,得到该多模态影像建图的肿瘤识别结果。
12.所述的基于多模态融合的肿瘤分类方法,其中该肿瘤分类模型的训练过程包括:
13.利用未标注的肿瘤影像数据,构造自监督学习任务,得到一个初始编码器,提取肿瘤影像的通用特征;该初始编码器以图像重建任务为前置任务,以特征提取模型作为编码器来提取输入影像的特征,然后解码器根据该输入影像的特征恢复得到原图像,以编码器能够提取出样本的关键特征来使解码器能够更好的恢复影像为训练目标,训练该编码器,将训练完成的编码器迁移到多模态融合模型;
14.确定待识别的肿瘤类别以及影像模态,获取多组多模态影像作为训练数据,每一组训练数据均来源于同一位患者,同时获取该训练数据对应的病理诊断数据,并对原始数据中肿瘤区域进行检测和定位,并存储对应的肿瘤区域位置信息;
15.根据该病理诊断数据对多模态图中的每一条边附上相应的类别信息,作为边的标签;多模态融合模型的输入是多模态图中的边,多模态融合模型的每个分支对边上每个顶点所对应的影像进行特征提取,并在特征空间层面进行融合;使用多模态融合模型的全连接网络对融合后的特征进行预测,输出其预测概率,并通过损失函数将模型的预测概率和边所对应的标签进行损失的计算、梯度的反向传播、以训练该多模态融合模型,并将训练完成后的多模态融合模型作为该肿瘤分类模型。
16.所述的基于多模态融合的肿瘤分类方法,其中该多模态图中只有不同模态的顶点之间存在匹配边。
17.所述的基于多模态融合的肿瘤分类方法,其中该步骤3包括,用户的的临床信息,包括该用户的年龄和病史,根据该临床信息得到该用户患各肿瘤类别的概率,以和该可信边集的置信度进行加权融合。
18.本发明还提出了一种基于多模态融合的肿瘤分类系统,其中包括:
19.图构建模块,用于根据来自同一位用户的多模态影像构建多模态图,多模态图中顶点为该多模态影像中单帧影像,多模态图中边为模态相异的顶点间的匹配边;
20.特征提取融合模块,用于使用肿瘤分类模型对多模态图中所有匹配边进行特征的提取和融合,得到每条边的置信度;
21.加权融合模块,用于根据每条边的置信度,选择并构建出一个可信边集合,将可信边集的置信度和该用户的临床信息进行加权融合,得到该多模态影像建图的肿瘤识别结果。
22.所述的基于多模态融合的肿瘤分类系统,其中该肿瘤分类模型的训练过程包括:
23.利用未标注的肿瘤影像数据,构造自监督学习任务,得到一个初始编码器,提取肿瘤影像的通用特征;该初始编码器以图像重建任务为前置任务,以特征提取模型作为编码器来提取输入影像的特征,然后解码器根据该输入影像的特征恢复得到原图像,以编码器能够提取出样本的关键特征来使解码器能够更好的恢复影像为训练目标,训练该编码器,将训练完成的编码器迁移到多模态融合模型;
24.确定待识别的肿瘤类别以及影像模态,获取多组多模态影像作为训练数据,每一组训练数据均来源于同一位患者,同时获取该训练数据对应的病理诊断数据,并对原始数据中肿瘤区域进行检测和定位,并存储对应的肿瘤区域位置信息;
25.根据该病理诊断数据对多模态图中的每一条边附上相应的类别信息,作为边的标签;多模态融合模型的输入是多模态图中的边,多模态融合模型的每个分支对边上每个顶点所对应的影像进行特征提取,并在特征空间层面进行融合;使用多模态融合模型的全连接网络对融合后的特征进行预测,输出其预测概率,并通过损失函数将模型的预测概率和边所对应的标签进行损失的计算、梯度的反向传播、以训练该多模态融合模型,并将训练完成后的多模态融合模型作为该肿瘤分类模型。
26.所述的基于多模态融合的肿瘤分类系统,其中该多模态图中只有不同模态的顶点之间存在匹配边。
27.所述的基于多模态融合的肿瘤分类系统,其中该用户的的临床信息,包括该用户的年龄和病史,根据该临床信息得到该用户患各肿瘤类别的概率,以和该可信边集的置信度进行加权融合。
28.本发明还提出了一种存储介质,用于存储执行所述任意一种基于多模态融合的肿瘤分类方法的程序。
29.本发明还提出了一种客户端,用于所述的任意一种基于多模态融合的肿瘤分类系统。
30.由以上方案可知,本发明的优点在于:
31.本发明通过深度学习技术,在患者不同模态数据之间构建图结构,然后使用多模态融合模型对图结构中的每条边进行概率输出,得到每条的肿瘤类别概率,并和临床信息统计模块结合进行患者级的融合,最后输出患者级的肿瘤识别结果。除此之外,还通过无监督学习构建预训练模型,并将其迁移到下游的多模态融合模型中进行肿瘤类别分类的任务,能够进一步提升模型对肿瘤的识别性能。该技术将有助于在患者早期,基于影像检测数据对肿瘤类别进行预判,从而提高治疗效率和提升预后效果,同时也能辅助提高医生的肿瘤类别诊断准确率。
附图说明
32.图1为本发明基于多模态影像的肿瘤分类整体框架图。
具体实施方式
33.针对现有技术基于影像的肿瘤分类鲁棒性不高的问题,提出了一种面向医学影像的基于多模态融合的肿瘤分类方法及系统。
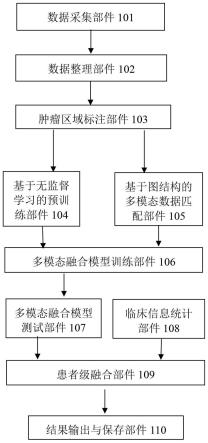
34.本发明提出了一种基于多模态影像数据以及临床信息进行患者级肿瘤判别的方法。首先在患者不同模态的影像数据之间构建图结构,图中的顶点为单帧影像数据,图中的边为不同模态数据之间的匹配边,例如,当顶点分别为一帧轴位影像和一帧矢状位影像的时候,这两个顶点之间的边即为这两帧影像的匹配边。然后使用多模态融合模型对图中的所有匹配边进行特征的提取和融合,得到每条边的置信度,在决策级融合阶段,通过可信边集筛选策略选取出若干可信的边集,这些边集能较好的表示肿瘤信息的匹配信息,然后将可信边集的置信度和患者的临床信息进行加权融合,得到最终的患者级肿瘤识别结果。除了上面的流程之外,在训练多模态融合模型之前,采用无监督学习方法在大量肿瘤数据上进行预训练模型的构建,然后将训练的模型迁移到多模态融合模型中,以进一步提升患者级肿瘤分类的性能。为实现上述技术效果,如图1所示,本发明包括如下关键技术点:
35.关键点1,数据集的采集和整理
36.首先需要确定待识别的肿瘤类别,比如肝癌,肺癌,或者乳腺癌等,以及影像模态,比如ct、核磁共振mri,采集平面,比如轴位、矢状位等。然后确定需要哪些患者的数据,在医院信息系统中导出这些患者的多模态影像数据,作为原始数据。同时需要获取这些患者对应的病理诊断数据。
37.数据整理指将原始数据按照一定规则进行重新归纳和整理,以更加适用于后期深度学习模型的训练和测试。规则包括以患者为单位进行影像数据的整合,即将同一患者不同时间段的影像检查数据合并在一个目录下。规则还包括按照一定的命名规则对某位患者目录下的数据进行目录名和文件名的重命名。规则还包括将每位患者病理诊断结果进一步归纳为具体肿瘤类别标签,这里可以是针对肿瘤良恶性的二分类,也可以是针对多种病理亚型的多分类任务。规则还包括将患者数据分为训练集和测试集。
38.关键点2,肿瘤区域标注
39.采集和整理完患者影像数据后,需要对肿瘤区域进行检测和定位,可以采用基于人工智能的肿瘤区域自动检测和区域标注方法,也可以采用人工标注方法。人工标注可以采用交互式标注工具,由专业人员利用矩形框或者勾边方式对患者影像数据中的每个肿瘤区域进行框取或者勾画,并存储对应的肿瘤区域位置信息。标注还包括将每位患者病理诊断结果进一步归纳为具体的肿瘤类别标签。
40.同时将标注好的数据,基于患者为单位划分为训练集和测试集。
41.关键点3,预训练模型的构建
42.由于针对肿瘤分类的有标注的训练样本有限,很难训练得到一个鲁棒的深度网络模型。本发明采用预训练方式,利用大量的未标注的影像数据学习,构造自监督学习任务,得到一个初始编码器,用以提取影像的通用特征。可以以除了测试集之外的所有该肿瘤的影像数据作为训练集,或者其他肿瘤的影像数据作为训练集,进行预训练模型的构建。本发
明以图像重建任务为前置任务,以特定的模型作为编码器来提取输入影像的特征,然后解码器利用编码器提取到的特征将原图像恢复出来,整体训练的目标是使得编码器能够提取出样本的关键特征来使解码器能够更好的恢复影像。最后,将训练好的编码器迁移到下游的肿瘤分类任务上进行微调。
43.关键点4,多模态图结构的构建
44.在关键点2划分好的训练集上,为了挖掘利用不同模态的特征,以患者不同模态的影像数据作为顶点,将这些顶点使用匹配边进行连接,以构建一个多模态图结构,需要注意的是,只有不同模态的顶点之间才会存在边,且这些边都为匹配边,而相同模态的顶点之间不进行边的连接。另外,每个顶点都为单帧影像。
45.关键点5,分类模型的训练
46.在关键点2划分好的训练集上,在构建好预训练模型和多模态图结构的基础上,根据病理结果,对图结构中的每一条边附上相应的类别信息,作为边的标签,以多分类为例,比如:该患者的肿瘤类别为神经鞘瘤,则图结构中所有边的类别都为神经鞘瘤。这些图结构中的边以及边所对应标签用于后续多模态融合模型的训练。
47.多模态融合模型为多分支网络,如第一个分支为卷积神经网络分支,第二个分支为注意力分支,这些分支也可以根据不同的任务替换成其他的模型。首先,将构建好的预训练模型迁移到多模态融合模型中。多模态融合模型的输入是图结构中的边,使用每个分支对边上每个顶点所对应的影像进行特征提取,然后在特征空间层面进行融合。之后,使用全连接网络对融合后的特征进行预测,输出其预测概率,并通过相应的损失函数将模型的输出概率和这条边所对应的标签进行损失的计算、梯度的反向传播、以及多模态融合模型参数的更新。
48.关键点6,临床信息统计模块
49.患者的临床信息,如年龄、既往病史等对诊断具有帮助作用,临床信息统计模块的作用是将文本化的临床信息数据转化为患者患对应肿瘤类别的概率,比如可以根据数据集中患者年龄信息与其患肿瘤类别的情况统计出不同年龄段患某类肿瘤的概率。
50.关键点7,模型的测试
51.在关键点2划分好的测试集上,对于图结构中的每条边,使用训练好的多模态融合模型得到其相应类别的概率,然后和临床信息统计模块结合进行患者级的融合。首先,将所有边的概率和根据临床信息统计模块得到患者患某类肿瘤的概率加权求和,得到每条边新的概率。然后根据每条边的概率值,筛选出概率值排在前k个的边作为可信边集,即模型认为最具有把握的匹配边,然后对这些匹配边进行概率计算,得到患者层面肿瘤的类别的概率,并选取出概率最大的类别作为患者当前所患的肿瘤类别。
52.为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。
53.以附图1说明本发明的内容,面向医学影像的基于多模态融合的肿瘤分类方法及系统包含如下步骤及部件:
54.步骤1:数据采集和整理
55.数据采集部件101:
56.首先需要确定待识别的肿瘤类别,比如肝癌,肺癌,或者乳腺癌等,以及影像模态,
比如ct、mri等,影像平面,比如轴位、矢状位等,需要采集患者多个模态的数据。然后确定需要哪些患者的数据,在医院信息系统中导出这些患者的影像数据,作为原始数据。同时需要获取这些患者对应的病理诊断结果。为了保证患者的信息不被泄漏,需要对导出来的数据进行脱密处理,一般需要将患者姓名及住院号等信息进行匿名化,即脱密处理。
57.数据整理部件102:
58.数据整理指将原始数据按照一定规则进行重新归纳和整理,以更加适用于后期深度网络模型的训练和测试。规则包括以患者为单位进行影像数据的整合,即将同一患者不同时间段的影像检查数据合并在一个目录下。规则还包括按照一定的命名规则对某位患者目录下的数据进行目录名和文件名的重命名。患者的影像数据一般是按照dicom文件格式存取,dicom元数据中的一些字段可以作为文件夹命名的属性,同一患者不同检查所对应的文件夹命名格式可以参考如下所示:
59.id-性别-年龄-模态-位姿-检查信息-肿瘤类别
60.比如包含7个属性,其中id为患者编号,性别为男或女,年龄为患者做检测时的年龄,模态为ct,mri或者ct&mri,位姿也可以称为平面,如轴位、矢状位或者冠状位,检查信息来自dicom元数据study description字段,包含t1,t2或扫描部位等信息。以上信息采用数字化编码的形式进行保存,比如第二属性的1代表男,0代表女。规则还包括将患者病理诊断结果进一步归纳为具体的肿瘤类别标签。
61.规则还包括将患者数据分为训练集和测试集,同时需要确保训练集和测试集中包含的患者不重叠。
62.步骤2:数据标注
63.肿瘤区域的标注部件103:
64.采集和整理完数据后,需要对肿瘤区域进行标注,以采用基于人工智能的肿瘤区域自动检测和区域标注方法,也可以采用人工标注方法。人工智能的方法,比如提前标注一些肿瘤区域,利用当前流行的目标检测框架比如fastrcnn等,进行目标检测模型的训练,然后在训练集上自动检测和定位肿瘤区域,肿瘤的具体类别根据患者病理诊断结果获得。人工标注具体实施方法为:医生观察患者的影像帧,如果存在肿瘤,则在标注软件中使用矩形框对肿瘤区域进行标记,不标记出肿瘤的具体类别,肿瘤的具体类别根据患者病理诊断结果获得。
65.步骤3:预训练模型的构建
66.基于无监督学习的预训练部件104:
67.由于针对肿瘤分类的有标注的训练样本有限,很难训练得到一个鲁棒的深度网络模型。本发明采用预训练方式,利用大量的未标注的影像数据学习,构造自监督学习任务,得到一个初始编码器,提取影像的通用特征。可以以除了测试集之外的所有该肿瘤的影像数据作为训练集,或者其他肿瘤的影像数据作为训练集,进行预训练模型的构建。本发明以图像重建任务为前置任务,图像重建任务能够通过解码器的监督来使得编码器更好的提取出对图像重建起决定性作用的特征。以多模态融合模型的某些分支网络作为编码器,以上采样、卷积操作、上采样作为解码器来进行图像重建任务,使得编码器能够提取出更加通用的高层语义特征,共包含三个部分:输入层mask、编码器和解码器、损失函数。
68.(a)输入层mask
69.输入层mask指的是在将影像真正送入到深度学习模型之前,先将其切分为若干大小为h
×
w的patch,然后以一定的比例α屏蔽掉一些区域。这样做的目的是使编码器在影像信息部分缺失的情况下,能够尽可能通过所提取的特征使得解码器能够恢复原始的图像。解码器恢复的图像质量越好,表明编码器所提取的特征越具有代表性。
70.(b)编码器和解码器
71.这里所采用的编码器为resnet18,即多模态融合模型中的卷积神经网络分支。resnet18共有4个阶段,分别在不同尺度下进行特征提取,以resnet18的最后一个阶段特征作为解码器的输入。为了防止解码器对特定的特征产生强记忆,造成过拟合,采用的解码器结构非常简单,即上采样、卷积操作、上采样,两次上采样的目的是使解码器的输出尺寸和原始图像的尺寸相等,卷积操作的目的是在解码器中加入可学习的参数。最后,解码器输出和原图尺寸相等的重建图像,并和原始图像结合计算重建损失,重建损失函数将在下面介绍。
72.(c)损失函数
73.衡量重建质量的好坏,可以将重建图像和原始图像进行逐像素对比,相应位置的像素值越接近,说明重建效果越好,基于此,采用均方误差损失来作为重建图像和原始图像之间的重建损失,如下公式所示,其中n表示像素的个数,表示重建图像,y表示原始图像。重建效果越好,则l值越小。优化的目标是使得l尽可能的小。
[0074][0075]
步骤4:多模态图结构的构建
[0076]
基于图结构的多模态数据匹配部件105:
[0077]
假设患者有m1、m2、m3三种不同模态的影像数据,并且m1中包含n帧影像,m2中包含m帧影像,m3中包含k帧影像。首先,将患者不同模态的影像数据划分集合,如模态m1的影像为集合a,模型m2的影像为集合b,模态m3的影像为集合c。集合中的每帧影像都被用作图的顶点,构建一个图结构,图中的连接边被称为匹配边。这些匹配边满足如下公式所表示的关系。即只有不同模态的数据顶点之间才会存在匹配边。构建好的图结构中一共有n
×m×
k个匹配边。需要注意的是,这里使用了三个模态进行举例,但是所提出的图结构并不局限于此,其能够支持更多模态。
[0078][0079]
步骤5:模型的训练
[0080]
多模态融合模型训练部件106:
[0081]
(a)特征提取和融合
[0082]
采用一种基于注意力学习和多分支的多模态融合模型,先分别对不同模态提取特征,然后再进行融合。首先使用一个共享的卷积神经网络分支分别对不同模态的肿瘤区域进行特征提取,得到模态mn对应的特征fn,其中卷积神经网络分支为一般的resnet模型。卷积神经网络分支能够进行影像局部特征的提取,但是缺少全局信息,这里使用了一种基于注意力的辅助分支,模态mn通过共享的辅助分支得到特征ln。不同于完全基于transformer的模型,本方面提出的注意力辅助分支非常简单,首先将输入的肿瘤区域切分成大小为8
×
8的patch,对每个patch进行向量空间映射,得到每个patch在向量空间的编码。然后,将当前批次所有patch的编码进行归一化操作,并使用一个多头注意力模块进行全局特征的关联,从而得到具有高响应的patch区域。最后,使用最大池化操作保留下响应值最大的区域作为特征l。
[0083]
对于模态mn,通过上述两个分支,将分别得到特征fn、ln,其中fn来自卷积神经网络分支,ln来自注意力辅助分支。通过如下公式进行融合,其中表示通道拼接操作。
[0084][0085]
然后,将h经过一个卷积操作、全局平均池化操作、以及全连接操作得到最后的输出结果并计算交叉熵损失。
[0086]
(b)损失函数
[0087]
交叉熵损失侧重于通过图中的单个边来优化模型,但没有考虑来自同一位患者的不同边之间可能存在的内在相关性,可能陷入次优解。在患者层面,来自不同模态的特征可能具有内在相似性,同一类型的特征也可能具有内在相似性。因此,从患者层面出发,提出了模态相似性损失函数pmsloss和类内相似性损失函数pitsloss,这两个损失函数并不是直接通过ground truth进行计算,而是通过构建相似性矩阵,鼓励模型在患者层面对不同模态或同一类别提取出尽可能相似的特征。以pmsloss为例,在训练阶段,对于每个batch,可能会包含来自同一个患者的数据,假设当前batch中包含的患者id集合为{i1,i2,...,im}∈id,多模态融合模型中任意分支对模态m1和m2提取到的特征为t1和t2,根据患者id集合可以得到模型对每一位患者的相应样本所提取的特征,如下公式所示。
[0088][0089]
其中m表示一个batch中患者的数量,k
m-k
m-1
表示一个batch中id为im的患者所具有的样本数量,d表示特征的长度。t1表示模态m1的特征,t2表示模态m2的特征。将模态内每个患者的多个特征按列取平均,得到如下矩阵:
[0090][0091]
其中表示模态m1的患者级模态特征矩阵,表示模态m2的患者级模态特
征矩阵。根据如下公式,可以计算得到模态m1和模态m2的特征相似性矩阵。
[0092][0093]
的大小为m
×
m,m为一个batch中患者的数量,对角线的值表示模型对同一位患者的两个模态所提取出的特征的相似性,优化的目标是使得对角线的值尽可能为1,其他位置的值尽可能为0。将和单位矩阵进行均方误差的损失计算,得到最终的损失值。
[0094]
pitsloss的计算过程和pmsloss基本一样。不同点是在得到和之后,首先将这两个模态矩阵进行按位平均,得到同时包含两个模态特征值的矩阵这样做的原因是,已经有pmsloss来约束模型对不同模态提取特征的相似性,pitsloss只需要关心不同类别之间的相似性即可。在得到之后,对其做自相似的矩阵运算,如下公式所示。
[0095][0096]
其中,矩阵对角线的值恒为1,表示自身的相似性,非对角线的值表示不同类别之间的相似性,优化的目标是使非对角线的值尽可能为0,即不同类别特征之间的相似性尽可能小。将和单位矩阵进行均方误差的损失计算,得到最终的损失值。
[0097]
基于注意力学习和多分支的多模态融合模型在训练过程中的最终损失值为交叉熵损失、pmsloss、pitsloss的平均值。
[0098]
(c)训练参数
[0099]
多模态融合模型可以在多个显卡上进行分布式训练,比如4个1080ti显卡上进行分布式训练,学习率为0.0002,采用随机梯度下降(sgd)作为优化器,迭代次数为20个周期(epoch),肿瘤区域均被调整为224
×
224的大小,每一个batch大小为32。注意力辅助分支中patch的大小为8,向量空间映射的维度为768,多头注意力模块中注意力头的数量为4。这些参数可以根据任务的不同进行相应的调整。
[0100]
步骤6:临床年龄信息统计
[0101]
临床信息统计部件108:
[0102]
对于训练集中的所有患者,可以按照特定的属性(如年龄、既往病史)和患者所患肿瘤类别进行集合,统计出某个属性下,患者患某类肿瘤类别的概率。以年龄信息为例,假设训练集中共包含肿瘤类别为cn的患者为m,其中30~40岁之间患类比为cn肿瘤的患者数量为k,则在30~40年龄段,患者患cn肿瘤的概率为通过统计之后,能够得到每个年龄段内患者患某类肿瘤的概率。
[0103]
步骤7:模型的测试
[0104]
多模态融合模型测试部件107和患者级融合部件109:
[0105]
在测试阶段,多模态融合模型会逐一对这些匹配边进行预测,得到其是某类肿瘤的概率。对于同一位患者来说,在决策层融合阶段将得到集合c,其中的每一个元素分别为相应匹配边的概率,决策层融合的目的是根据集合c,来判断患者整体的肿瘤类别。
[0106]
在临床实践中,以年龄为例,患者的年龄信息对肿瘤的分类具有参考意义。根据临床信息统计部件108,得到患者年龄与其患某类肿瘤的概率关系集合k,将集合c中的每一个元素都和患者当前年龄患某类肿瘤的概率按照如下公式进行加权求和,其中λ1和λ2为两者之间的权重系数。
[0107]ci
=λ1×ci
+λ2×ki
[0108]
然后,将集合c中的每一个元素从大到小进行排序,取出来概率值最大的topk个元素,形成集合s,即模型认为预测比较准确的topk个匹配边。然后,将这些匹配边中每个类别的概率进行累加,得到所有边中某类肿瘤概率的累加和,选取出累加和最大的肿瘤类别作为当前患者肿瘤的类别。
[0109]
结果输出与保存部件:110
[0110]
将患者最终的肿瘤识别结果进行输出,并保存在硬盘文件中,方便后续进行测试集的结果比对,或者对新的数据进行肿瘤预测。
[0111]
以上实施在训练的过程中,可以选择gpu为gtx 1080ti型号,具有12g显存,内存选择64g,cpu为e5-2640v2。预训练模型的训练为100个epoch,多模态融合模型的训练20个epoch,得到满足收敛要求的预训练模型和多模态融合模型。
[0112]
以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。
[0113]
本发明还提出了一种基于多模态融合的肿瘤分类系统,其中包括:
[0114]
图构建模块,用于根据来自同一位用户的多模态影像构建多模态图,多模态图中顶点为该多模态影像中单帧影像,多模态图中边为模态相异的顶点间的匹配边;
[0115]
特征提取融合模块,用于使用肿瘤分类模型对多模态图中所有匹配边进行特征的提取和融合,得到每条边的置信度;
[0116]
加权融合模块,用于根据每条边的置信度,选择并构建出一个可信边集合,将可信边集的置信度和该用户的临床信息进行加权融合,得到该多模态影像建图的肿瘤识别结果。
[0117]
所述的基于多模态融合的肿瘤分类系统,其中该肿瘤分类模型的训练过程包括:
[0118]
利用未标注的肿瘤影像数据,构造自监督学习任务,得到一个初始编码器,提取肿瘤影像的通用特征;该初始编码器以图像重建任务为前置任务,以特征提取模型作为编码器来提取输入影像的特征,然后解码器根据该输入影像的特征恢复得到原图像,以编码器能够提取出样本的关键特征来使解码器能够更好的恢复影像为训练目标,训练该编码器,将训练完成的编码器迁移到多模态融合模型;
[0119]
确定待识别的肿瘤类别以及影像模态,获取多组多模态影像作为训练数据,每一组训练数据均来源于同一位患者,同时获取该训练数据对应的病理诊断数据,并对原始数据中肿瘤区域进行检测和定位,并存储对应的肿瘤区域位置信息;
[0120]
根据该病理诊断数据对多模态图中的每一条边附上相应的类别信息,作为边的标签;多模态融合模型的输入是多模态图中的边,多模态融合模型的每个分支对边上每个顶点所对应的影像进行特征提取,并在特征空间层面进行融合;使用多模态融合模型的全连接网络对融合后的特征进行预测,输出其预测概率,并通过损失函数将模型的预测概率和
边所对应的标签进行损失的计算、梯度的反向传播、以训练该多模态融合模型,并将训练完成后的多模态融合模型作为该肿瘤分类模型。
[0121]
所述的基于多模态融合的肿瘤分类系统,其中该多模态图中只有不同模态的顶点之间存在匹配边。
[0122]
所述的基于多模态融合的肿瘤分类系统,其中该用户的的临床信息,包括该用户的年龄和病史,根据该临床信息得到该用户患各肿瘤类别的概率,以和该可信边集的置信度进行加权融合。
[0123]
本发明还提出了一种存储介质,用于存储执行所述任意一种基于多模态融合的肿瘤分类方法的程序。
[0124]
本发明还提出了一种客户端,用于所述的任意一种基于多模态融合的肿瘤分类系统。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1