一种基于AI处理器的通用矩阵乘算子的处理方法和装置与流程
一种基于ai处理器的通用矩阵乘算子的处理方法和装置
技术领域
1.本发明涉及矩阵处理技术领域,具体是涉及一种基于ai处理器的通用矩阵乘算子的处理方法和装置。
背景技术:
2.昇腾ai处理器的计算核心主要由ai core构成,ai core采用了达芬奇架构,其基本结构如图2所示。为了提升ai计算的完备性和不同场景的计算效率,达芬奇架构还集成矩阵计算单元(cube unit)、向量计算单元(vector unit)和标量计算单元(scalar unit)。同时支持多种精度计算,支撑训练和推理两种场景的数据精度要求,实现全场景需求覆盖。达芬奇架构,是华为自研的面向ai计算特征的全新计算架构,具备高算力、高能效、灵活可裁剪的特性。不同于传统的支持通用计算的cpu和gpu,也不同于专用于某种特定算法的专用芯片asic,达芬奇架构本质上是为了适应某个特定领域中的常见应用和算法,通常称为“特定域架构”(domain specific architecture,dsa)。
3.将hpl-ai中的hpl框架求解器与昇腾ai处理器结合,可以处理实现对矩阵的处理,比如对分解矩阵。其中,hpl-ai基准测试意为高性能计算(hpl)和人工智能(ai)的融合。传统的高性能计算侧重于模拟物理、化学、生物学等领域,这些计算一般需要双精度(64位)。另一方面,推动人工智能进步的机器学习方法在32位甚至更低的浮点精度格式下实现了预期的结果。对准确性需求的减少,促使人们对新的计算硬件产生兴趣,这些硬件具有前所未有的性能。hpl框架的求解器用于对超级计算机进行基准测试。hpl-ai致力于通过融合现代算法和现代硬件来统一高性能计算和人工智能这两个领域。hpl-ai选择的求解方法是lu分解(上三角矩阵和下三角矩阵分解)和之后执行的精度迭代的组合,后者使解恢复到64位精度。hpl-ai的创新之处在于在整个求解过程中放弃了对高精度计算单元的要求,而是选择了低精度(如16位的半精度浮点),并通过复杂的迭代来恢复lu分解中损失的精度,保证数值稳定的迭代方法是广义最小残差法(gmres)。这些算法的组合足以实现高精度。
4.大矩阵的lu分解由小矩阵的lu分解、三角矩阵求解、面板分解和通用矩阵乘组成。
5.现有技术中通用矩阵乘算子采用tvm开发方式,而tvm自动优化生成的算子难以充分发挥昇腾ai处理器的极致性能。
6.综上所述,现有技术处理矩阵的效率较低。
7.因此,现有技术还有待改进和提高。
技术实现要素:
8.为解决上述技术问题,本发明提供了一种基于ai处理器的通用矩阵乘算子的处理方法和装置,解决了现有技术处理矩阵的效率较低的问题。
9.为实现上述目的,本发明采用了以下技术方案:
10.第一方面,本发明提供一种基于ai处理器的通用矩阵乘算子的处理方法,其中,包括:
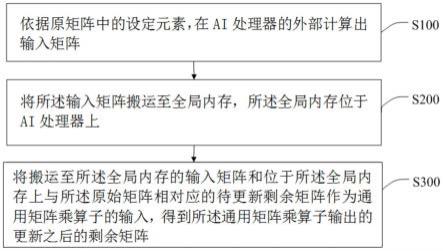
11.依据原矩阵中的设定元素,在ai处理器的外部计算出输入矩阵;
12.将所述输入矩阵搬运至全局内存,所述全局内存位于ai处理器上;
13.将搬运至所述全局内存的输入矩阵和位于所述全局内存上与所述原始矩阵相对应的待更新剩余矩阵作为通用矩阵乘算子的输入,得到所述通用矩阵乘算子输出的更新之后的剩余矩阵。
14.在一种实现方式中,所述依据原矩阵中的设定元素,在ai处理器的外部计算出输入矩阵,包括:
15.获取与所述原始矩阵所对应的矩阵块设定尺寸;
16.依据所述矩阵块设定尺寸对所述原矩阵进行分块,得到各个分块矩阵;
17.将各个所述分块矩阵中的其中一个分块矩阵作为设定分块矩阵;
18.依据所述设定元素,得到所述设定元素中的位于设定分块矩阵内的元素;
19.在所述cpu上对所述设定分块矩阵内的元素进行处理,得到所述设定分块矩阵所对应的上三角矩阵和下三角矩阵;
20.依据所述上三角矩阵,得到所述输入矩阵中的第一输入矩阵;
21.依据所述下三角矩阵,得到所述输入矩阵中的第二输入矩阵。
22.在一种实现方式中,所述将所述输入矩阵搬运至全局内存,所述全局内存位于ai处理器上,包括:
23.将所述第一输入矩阵和所述第二输入矩阵从cpu上搬运至所述全局内存。
24.在一种实现方式中,所述依据所述下三角矩阵,得到所述输入矩阵中的第二输入矩阵,包括:
25.依据所述设定分块矩阵,得到与所述设定分块矩阵位于同一行的各个分块矩阵;
26.对所述下三角矩阵、与所述设定分块矩阵位于同一行的各个所述分块矩阵应用三角矩阵求解算法,得到各个第二输入分块矩阵;
27.将各个所述第二输入分块矩阵按照与所述设定分块矩阵位于同一行的各个所述分块矩阵在所述原始矩阵中的排列顺序进行排列,得到第二输入矩阵。
28.在一种实现方式中,所述依据所述上三角矩阵,得到所述所述输入矩阵中的第一输入矩阵;
29.依据所述设定分块矩阵,得到与所述设定分块矩阵位于同一列的各个分块矩阵;
30.对所述上三角矩阵、与所述设定分块矩阵位于同一列的各个分块矩阵应用面板分解算法,得到各个第一输入分块矩阵;
31.将各个所述第一输入分块矩阵按照与所述设定分块矩阵位于同一列的各个分块矩阵在所述原始矩阵中的排列顺序进行排列,得到第一输入矩阵。
32.在一种实现方式中,所述将所述输入矩阵搬运至全局内存,所述全局内存位于ai处理器上,之后还包括:
33.将所述第一输入矩阵和所述第二输入矩阵从所述全局内存上搬运至所述ai处理器上的一级缓冲区;
34.将所述第一输入矩阵从所述一级缓冲区搬运至位于所述ai处理器上的左矩阵0级缓冲区;
35.将所述第二输入矩阵从所述一级缓冲区搬运至位于所述ai处理器上的右矩阵0级
缓冲区。
36.在一种实现方式中,所述将所述第一输入矩阵和所述第二输入矩阵搬运至所述ai处理器上的一级缓冲区,包括:
37.依据所述一级缓冲区的存储量、所述第二输入分块矩阵的内存占用量、所述第一输入分块矩阵的内存占用量,得到所述第二输入分块矩阵所对应的设定数量、所述第一输入分块矩阵所对应的设定数量;
38.每次将所述第二输入矩阵中设定数量的第二输入分块矩阵和所述第一输入矩阵中设定数量的所述第一输入分块矩阵搬运至所述一级缓冲区。
39.在一种实现方式中,更新之后的所述剩余矩阵为lu分解迭代过程中未完成分解的矩阵,所述将搬运至所述ai处理器的输入矩阵和位于所述ai处理器上与所述原始矩阵相对应的待更新剩余矩阵作为通用矩阵乘算子的输入,得到所述通用矩阵乘算子输出的更新之后的剩余矩阵,包括:
40.从所有所述分块矩阵中去除所述设定分块矩阵及所述设定分块矩阵所在行和所在列中的分块矩阵,得到所述待更新剩余矩阵中的待更新剩余分块矩阵;
41.对搬运至所述左矩阵0级缓冲区上的所述第一输入矩阵和搬运至所述右矩阵0级缓冲区上的所述第二输入矩阵使用矩阵计算单元进行矩阵乘运算,得到所述第一输入矩阵和所述第二输入矩阵的乘矩阵;
42.将所述乘矩阵保存在ai处理器的输出矩阵0级缓冲区;
43.将保存在所述输出矩阵0级缓冲区的所述乘矩阵、位于所述ai处理器上的所述待更新剩余分块矩阵使用向量计算单元进行加法运算,得到所述通用矩阵乘算子输出的更新之后的剩余矩阵。
44.在一种实现方式中,所述将保存在所述输出矩阵0级缓冲区的所述乘矩阵、位于所述ai处理器上的所述待更新剩余矩阵使用向量计算单元进行加法运算,得到所述通用矩阵乘算子输出的更新之后的剩余矩阵,包括:
45.将保存在所述输出矩阵0级缓冲区的所述乘矩阵搬运至所述ai处理器的统一缓冲区;
46.对搬运至所述统一缓冲区的所述乘矩阵和位于所述统一缓冲区上的所述待更新剩余矩阵使用向量计算单元进行加法运算,得到所述通用矩阵乘算子输出的更新之后的剩余矩阵。
47.在一种实现方式中,所述将将所述输入矩阵搬运至全局内存,所述全局内存位于ai处理器上,包括:
48.将所述输入矩阵转换成半精度的所述输入矩阵;
49.对半精度的所述输入矩阵进行存储格式的转换,得到设定存储格式的所述输入矩阵,所述设定存储格式与所述ai处理器的矩阵计算单元的矩阵输入输出格式相匹配;
50.将设定存储格式的所述输入矩阵搬运至所述ai处理器的全局内存。
51.在一种实现方式中,所述更新之后的剩余矩阵为lu分解迭代过程中未完成分解的矩阵,所述将搬运至所述全局内存的输入矩阵和位于所述全局内存上与所述原始矩阵相对应的待更新剩余矩阵作为通用矩阵乘算子的输入,得到所述通用矩阵乘算子输出的更新之后的剩余矩阵,包括:
52.对所述通用矩阵乘算子进行编程,得到算子程序;
53.对所述输入矩阵和所述待更新剩余矩阵应用算子程序,得到子矩阵。
54.在一种实现方式中,所述矩阵块设定尺寸为256*256的整数倍。
55.第二方面,本发明实施例还提供一种基于ai处理器的通用矩阵乘算子的处理装置,其中,所述装置包括如下组成部分:
56.输入矩阵计算模块,用于依据原矩阵中的设定元素,在ai处理器的外部计算出输入矩阵;
57.矩阵搬运模块,用于将所述输入矩阵搬运至全局内存,所述全局内存位于ai处理器上;
58.矩阵计算模块,用于将搬运至所述全局内存的输入矩阵和位于所述全局内存上与所述原始矩阵相对应的待更新剩余矩阵作为通用矩阵乘算子的输入,得到所述通用矩阵乘算子输出的更新之后的剩余矩阵。
59.第三方面,本发明实施例还提供一种终端设备,其中,所述终端设备包括存储器、处理器及存储在所述存储器中并可在所述处理器上运行的基于ai处理器的通用矩阵乘算子的处理程序,所述处理器执行所述基于ai处理器的通用矩阵乘算子的处理程序时,实现上述所述的基于ai处理器的通用矩阵乘算子的处理方法的步骤。
60.第四方面,本发明实施例还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有基于ai处理器的通用矩阵乘算子的处理程序,所述基于ai处理器的通用矩阵乘算子的处理程序被处理器执行时,实现上述所述的基于ai处理器的通用矩阵乘算子的处理方法的步骤。
61.有益效果:通用矩阵乘算子在处理矩阵时,涉及到大量的矩阵乘法运算,而矩阵乘法对硬件性能有较高的要求,只有具有高处理速度上的硬件上运行矩阵乘算子才能提高矩阵乘算子处理矩阵的速度。本发明在ai处理器上通过矩阵乘算子处理矩阵,能够使得ai处理器的计算资源得到充分利用,从而提高了处理矩阵的速度和效率。
附图说明
62.图1为本发明的整体流程图;
63.图2为达芬奇ai core架构图;
64.图3为分块矩阵示意图;
65.图4为图3中的分块矩阵第一次迭代示意图;
66.图5为图3中的分块矩阵第二次迭代示意图;
67.图6为图3中的分块矩阵第三次迭代示意图;
68.图7为本发明实施例中的fractal_nz格式示意图;
69.图8为本发明的输入矩阵复用示意图;
70.图9为现有技术中的搬运输入矩阵的示意图;
71.图10为本发明实施例中的gemm算子分解矩阵的流程图;
72.图11为本发明实施例中的分块矩阵与输入矩阵的示意图;
73.图12为本发明实施例提供的终端设备的内部结构原理框图。
具体实施方式
74.以下结合实施例和说明书附图,对本发明中的技术方案进行清楚、完整地描述。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
75.经研究发现,昇腾ai处理器的计算核心主要由ai core构成,ai core采用了达芬奇架构,其基本结构如图2所示。为了提升ai计算的完备性和不同场景的计算效率,达芬奇架构还集成矩阵计算单元(cube unit)、向量计算单元(vector unit)和标量计算单元(scalar unit)。同时支持多种精度计算,支撑训练和推理两种场景的数据精度要求,实现全场景需求覆盖。达芬奇架构,是华为自研的面向ai计算特征的全新计算架构,具备高算力、高能效、灵活可裁剪的特性。不同于传统的支持通用计算的cpu和gpu,也不同于专用于某种特定算法的专用芯片asic,达芬奇架构本质上是为了适应某个特定领域中的常见应用和算法,通常称为“特定域架构”(domain specific architecture,dsa)。将hpl-ai中的hpl框架求解器与昇腾ai处理器结合,可以处理实现对矩阵的处理,比如对分解矩阵。其中,hpl-ai基准测试意为高性能计算(hpl)和人工智能(ai)的融合。传统的高性能计算侧重于模拟物理、化学、生物学等领域,这些计算一般需要双精度(64位)。另一方面,推动人工智能进步的机器学习方法在32位甚至更低的浮点精度格式下实现了预期的结果。对准确性需求的减少,促使人们对新的计算硬件产生兴趣,这些硬件具有前所未有的性能。hpl框架的求解器用于对超级计算机进行基准测试。hpl-ai致力于通过融合现代算法和现代硬件来统一高性能计算和人工智能这两个领域。hpl-ai选择的求解方法是lu分解(上三角矩阵和下三角矩阵分解)和之后执行的精度迭代的组合,后者使解恢复到64位精度。hpl-ai的创新之处在于在整个求解过程中放弃了对高精度计算单元的要求,而是选择了低精度(如16位的半精度浮点),并通过复杂的迭代来恢复lu分解中损失的精度,保证数值稳定的迭代方法是广义最小残差法(gmres)。这些算法的组合足以实现高精度。
76.大矩阵的lu分解由小矩阵lu分解、三角矩阵求解、面板分解和通用矩阵乘组成。
77.现有技术中通用矩阵乘算子采用tvm开发方式,而tvm自动优化生成的算子难以充分发挥昇腾ai处理器的极致性能。
78.为解决上述技术问题,本发明提供了一种基于ai处理器的适用于hpl-ai的通用矩阵乘算子的处理方法和装置,解决了现有技术处理矩阵的效率较低的问题。具体实施时,依据原矩阵中的设定元素,在ai处理器的外部计算出输入矩阵;将所述输入矩阵搬运至全局内存,所述全局内存位于ai处理器上;将搬运至所述全局内存的输入矩阵和位于所述全局内存上与所述原始矩阵相对应的待更新剩余矩阵作为通用矩阵乘算子的输入,得到所述通用矩阵乘算子输出的更新之后的剩余矩阵。
79.举例说明,如图3所示的分块之后的原矩阵,原矩阵左上角的分块矩阵a
11
中的元素就是设定元素,在位于ai处理器的外部cpu上根据a
11
计算出图4中的由u
12
、u
13
、u
14
组成的输入矩阵,在外部存储器上根据a
11
计算出由l
21
、l
31
、l
41
组成的输入矩阵,之后将两个输入矩阵搬运至ai处理器,在ai处理器上两个输入矩阵以及图4中的a
22
、a
23
、a
24
、a
32
、a
33
、a
34
、a
42
、a
43
、a
44
(这九个分块矩阵组成了待更新剩余矩阵)作为布置在ai处理器上的矩阵乘算子的输入,矩阵乘算子就会输出对待更新剩余矩阵处理之后所产生的更新之后的剩余矩阵。比如在ai处理器上将l
21
、u
12
、a
22
输入到矩阵乘算子,矩阵乘算子就会输出针对a
22
更新之后的a
22
,然
后将a
22
转存至位于ai处理器外部的cpu上,在cpu上使用lu分解算法对更新之后的a
22
进行分解就得到图5中的l
22
、u
22
;在ai处理器上将l
31
、u
13
、a
33
输入到矩阵乘算子,矩阵乘算子就会输出针对a
33
更新之后的a
33
,然后将a
33
转存至位于ai处理器外部的cpu上,在cpu上使用lu分解算法对更新之后的a
33
进行分解就得到图6中的l
33
、u
33
。之所以不在ai处理器上进行lu分解,这是由于ai处理器(npu)的架构特性不适合进行lu分解。
80.示例性方法
81.本实施例的基于ai处理器的通用矩阵乘算子的处理方法可应用于终端设备中,所述终端设备可为具有计算功能的终端产品,比如电脑等。在本实施例中,如图1中所示,所述基于ai处理器的通用矩阵乘算子的处理方法具体包括如下步骤:
82.s100,依据原矩阵中的设定元素,在ai处理器的外部计算出输入矩阵。
83.本实施例是根据原矩阵中的设定元素在位于ai处理器外部的cpu上计算出运行矩阵乘算子所需要的输入矩阵。步骤s100包括如下的步骤s101至s1012:
84.s101,获取与所述原始矩阵所对应的矩阵块设定尺寸。
85.本实施例中的矩阵块设定尺寸为256*256的整数倍,之所以选择这个尺寸是因为这个尺寸可以充分利用ai处理器的计算资源。
86.s102,依据所述矩阵块设定尺寸对所述原矩阵进行分块,得到各个分块矩阵。
87.如果原始矩阵的长宽不是256的整数倍就填充零以使得原始矩阵的长宽是256的整数倍。
88.如图3所示,对原矩阵进行了分块,分块之后得到的分块矩阵a
11
至a
44
的长宽都是nb(256)
89.s103,将各个所述分块矩阵中的其中一个分块矩阵作为设定分块矩阵。
90.s104,依据所述设定元素,得到所述设定元素中的位于设定分块矩阵内的元素。
91.本实施例中,如图4所示,当需要计算出u
12
、u
13
、u
14
、l
21
、l
31
、l
41
时,分块矩阵a
11
就是设定分块矩阵,a
11
内部的元素就是设定元素。
92.s105,将位于所述设定分块矩阵内的元素从所述ai处理器搬运至cpu,所述cpu位于所述ai处理器的外部。
93.原矩阵的所有元素都是存储在ai处理器上,当需要对设定分块矩阵进行分解时,就将设定分块矩阵从ai处理器搬运至cpu以进行分解。
94.s106,在所述cpu上对所述设定分块矩阵内的元素进行处理,得到所述设定分块矩阵所对应的上三角矩阵和下三角矩阵。
95.本实施例是对图3中的分块矩阵a
11
进行lu分解得到图4中的l
11
(下三角矩阵)和u
11
(上三角矩阵)。
96.s107,依据所述设定分块矩阵,得到与所述设定分块矩阵位于同一列的各个分块矩阵。
97.s108,对所述上三角矩阵、与所述设定分块矩阵位于同一列的各个所述分块矩阵应用面板分解算法,得到各个第一输入分块矩阵。
98.s109,将各个所述第一输入分块矩阵按照与所述设定分块矩阵位于同一列的各个所述分块矩阵在所述原始矩阵中的排列顺序进行排列,得到第一输入矩阵。
99.s1010,依据所述设定分块矩阵,得到与所述设定分块矩阵位于同一列的各个分块
矩阵。
100.s1011,对所述下三角矩阵、与所述设定分块矩阵位于同一行的各个分块矩阵应用三角矩阵求解算法,得到各个第二输入分块矩阵。
101.s1012,将各个所述第二输入分块矩阵按照与所述设定分块矩阵位于同一行的各个分块矩阵在所述原始矩阵中的排列顺序进行排列,得到第二输入矩阵。
102.本实施例中的同一行指的是图3中的a
11
所在的行,同一列指的是a
11
所在的列。u
11
和a
21
应用面板分解算法(panel factorization)就得到了l
21
,同样得到u
13
和u
14
。l
11
和a
21
应用三角矩阵求解算法(trsm)就得到了u
12
,同样可以得到l
31
和l
41
。
103.s200,将所述输入矩阵搬运至全局内存,所述全局内存位于ai处理器上。
104.本实施例中,输入矩阵用于通用矩阵乘算子(gemm)中乘法部分的计算,因此将输入矩阵搬运至全局内存,能够提高乘法计算的效率。本实施例之所以在ai处理器完成矩阵乘算子的计算,是因为ai处理器具有表1中的计算单元和表2中的存储单元,这些计算单元和存储单元相互协同作用可以提高计算速度。
105.表1
[0106][0107]
表2
[0108][0109]
不同类型的计算需要使用表2中不同类型的存储单元。例如向量加法运算,需要先将数据从全局内存global memory将数据拷贝到unified buffer,计算完成后拷贝回global memory,所以整体数据流应该是global memory
→
unified buffer
→
global memory。执行矩阵乘法的cube计算单元需要以l0a buffer和l0b buffer作为输入数据的存储。对于910型号的芯片,l0a buffer和l0b buffer的可用大小为131072byte,最大可以存储尺寸为256*256的半精度矩阵。
[0110]
ai处理器除了具有表1中的计算单元以及表2中的存储单元之外,还具有控制单元。
[0111]
ai处理器(ai core)中的控制单元主要包括:系统控制模块(system control),指
令发射模块(instr.dispatch),矩阵运算队列(cube queue),向量运算队列(vector queue),存储转换队列(mte queue)。系统控制模块负责指挥和协调ai core的整体运行模式,配置参数和实现功耗控制等。当指令通过指令发射模块顺次发射出去后,根据指令的不同类型,将会分别被发送到矩阵运算队列、向量运算队列和存储转换队列。
[0112]
在将输入矩阵搬运至ai处理器需要先对输入矩阵进行如下的精度转换和存储格式的转换:将所述输入矩阵转换成半精度的所述输入矩阵;对半精度的所述输入矩阵进行存储格式的转换,得到设定存储格式的所述输入矩阵,所述设定存储格式与所述ai处理器的矩阵计算单元的矩阵输入输出格式相匹配;将设定存储格式的所述输入矩阵搬运至所述ai处理器的全局内存。
[0113]
本实施例是基于如下原理实现精度和格式转换的:在cpu上分解完成的数据(第二输入矩阵u和第一输入矩阵l)在拷贝到npu(ai处理器)之前,不仅需要进行单精度到半精度的转换,还需要进行格式的转换。fractal_nz格式(设定存储格式)是华为自研的分形格式,在cube单元计算时,输入输出矩阵的数据格式为nw1h1h0w0。整个矩阵被分为(h1*w1)个分形,按照column major排布,形状如n字形;每个分形内部有(h0*w0)个元素,按照row major排布,形状如z字形。ai core的矩阵计算单元(cube)负责执行矩阵运算。矩阵计算单元每次执行可以完成一个fp16的16*16与16*16的矩阵乘。为了提高矩阵乘的运算数据块的访问效率,输入输出的矩阵都使用这种分形格式。h0,w0表示一个分形的大小,与cube的尺寸相关,均为16,如图7所示。每个尺寸为256*256的小矩阵块经过格式转换,变成尺寸为16*16*16*16的张量(tensor)。
[0114]
步骤s200采用如下的步骤s201、s202、s203、s204将输入矩阵搬运至ai处理器:
[0115]
s201,依据所述一级缓冲区的存储量、所述第二输入分块矩阵的内存占用量、所述第一输入分块矩阵的内存占用量,得到所述第二输入分块矩阵所对应的设定数量、所述第一输入分块矩阵所对应的设定数量。
[0116]
s202,每次将所述第二输入矩阵中设定数量的第二输入分块矩阵和所述第一输入矩阵中设定数量的所述第一输入分块矩阵搬运至所述一级缓冲区。
[0117]
对于昇腾910型号的ai处理器,它的一级缓冲区(l1 buffer)可用大小为1048576byte,最大可以装下8个16*16*16*16的半精度张量,因此一次可以将第一输入矩阵(图8中的纵向排列的矩阵)的6个第一输入分块矩阵以及第二输入矩阵(图8中的横向排列的矩阵)的1个第二输入分块矩阵拷贝到l1 buffer。以图8为例,本实施例的搬运方法能够相对图9中的现有技术的搬运方法减少60%的搬运次数。此外,本实施例的搬运方法,使得1个第二输入分块矩阵得到复用,每搬运1个第二输入分块矩阵就可以参与6次计算,从而使得本实施例减少了数据从global memory到l1 buffer的数据搬运次数。
[0118]
s203,将所述第一输入矩阵从所述一级缓冲区搬运至位于所述ai处理器上的左矩阵0级缓冲区。
[0119]
s204,将所述第二输入矩阵从所述一级缓冲区搬运至位于所述ai处理器上的右矩阵0级缓冲区。
[0120]
步骤s203和s204是基于如下原理实现对各个分块矩阵搬运的:
[0121]
矩阵计算需要用到cube计算单元,cube的输入存储是l0a buffer(左矩阵0级缓冲区)和l0b buffer(右矩阵0级缓冲区)(只要l0a buffer和l0b buffer有分块矩阵,cube就
执行两个分块矩阵的矩阵乘法运算)。l0a buffer和l0b buffer的可用大小均为131072byte,最大可以装下尺寸为16*16*16*16的半精度张量。cube的输出的矩阵乘法结果保存在l0c buffer(输出矩阵0级缓冲区),用于存储矩阵乘的计算结果。matmul是tik提供的矩阵乘api,函数原型为matmul(dst,a,b,m,k,n,init_l1out=true)。其中,dst是矩阵相乘结果操作数的起始element,存储于l0c buffer。a和b分别为矩阵乘的下三角矩阵和上三角矩阵,存储于l1 buffer。因此,gemm256(输入矩阵中的每一个分块矩阵的大小都是256*256,余下矩阵的每一个分块矩阵的大小也都是256*256,将大小为256*256的矩阵应用gemm就是gemm256算子)算子中矩阵乘的数据搬运流程为:对于a(余下矩阵)中的每一个16*16*16*16张量(每一个分块矩阵),将对应l、u中的16*16*16*16张量从global memory拷贝到l1 buffer,调用api matmul,输入矩阵会被拷贝到l0a buffer和l0b buffer,矩阵乘计算完成后,结果存储在l0c buffer。数据流为global memory
→
l1 buffer
→
l0a buffer/l0b buffer
→
l0c buffer。
[0122]
s300,将搬运至所述全局内存的输入矩阵和位于所述全局内存上与所述原始矩阵相对应的待更新剩余矩阵作为通用矩阵乘算子的输入,得到所述通用矩阵乘算子输出的更新之后的剩余矩阵。
[0123]
更新之后的所述剩余矩阵为lu分解迭代过程中未完成分解的矩阵,步骤s300是将图4中的a22至a44这九个余下分块矩阵进行分解,使得每个余下分块矩阵都分解成上三角矩阵和下三角矩阵。步骤s300包括如下步骤s301、s302、s303、s304、s305:
[0124]
s301,从所有所述分块矩阵中去除所述设定分块矩阵及所述设定分块矩阵所在行和所在列中的分块矩阵,得到所述待更新剩余矩阵中的待更新剩余分块矩阵。
[0125]
本实施例中的设定分块矩阵就是图3中的a11,待更新剩余分块矩阵就是图4中的a22至a44这九个待更新剩余分块矩阵。
[0126]
s302,对搬运至所述左矩阵0级缓冲区上的所述第一输入矩阵l和搬运至所述右矩阵0级缓冲区上的所述第二输入矩阵u应用矩阵乘算子中的矩阵计算单元进行矩阵乘运算,得到所述第一输入矩阵和所述第二输入矩阵的乘矩阵。
[0127]
s303,将所述乘矩阵保存在ai处理器的输出矩阵0级缓冲区。
[0128]
本实施例中,左矩阵0级缓冲区(l0a buffer)和右矩阵0级缓冲区(l0b buffer)是cube计算单元的输入端,cube计算单元对这两个指令缓存区上的分块矩阵进行矩阵乘法计算,乘法结果保存在输出矩阵0级缓冲区(l0c buffer)。
[0129]
s304,将保存在所述输出矩阵0级缓冲区的所述乘矩阵搬运至所述ai处理器的统一缓冲区。
[0130]
s305,对搬运至所述统一缓冲区的所述乘矩阵和位于所述统一缓冲区上的所述待更新剩余分块矩阵使用通用矩阵乘算子中的向量计算单元进行加法运算,得到所述通用矩阵乘算子输出的更新之后的剩余矩阵。
[0131]
本实施例矩阵乘的结果与待更新余下矩阵相减(通用矩阵乘算子中的矩阵减法部分),计算类型为向量计算,需要用到vector计算单元,vector的输入和输出均为unified buffer(统一缓冲区)。此时矩阵乘的结果还存储在l0c buffer(输出矩阵0级缓冲区),需要搬运到unified buffer。tik提供的fixpipe是与matmul配套的api,用于对矩阵乘的结果进行处理,例如加偏置和对数据进行量化、并把数据从l0c buffer搬迁到global memory中。
之后把矩阵乘的结果从globalmemory搬运到unifiedbuffer用于向量计算,计算完成后再搬运回globalmemory。数据流为l0cbuffer
→
globalmemory
→
unifiedbuffer
→
globalmemory。本实施例使用了tik文档未公开的接口tensor_mov优化上述数据流,tensor_mov支持直接将数据从l0cbuffer搬运到unifiedbuffer。优化后的数据流为l0cbuffer
→
unifiedbuffer
→
globalmemory。
[0132]
由于unifiedbuffer空间有限,在数据量很大的情况下,无法完整放入输入数据和输出结果,需要采用计算分片的方式,对输入数据分片搬入、计算、再搬出。对于ascend910型号的芯片,unifiedbuffer设计大小262144byte,实际可用253952byte。尺寸为16*16*16*16的半精度张量占用空间大小为131072byte,两个这样的张量就超过了unifiedbuffer的可用上限,因此需要将16*16*16*16的张量分片,每次拷贝一部分数据到unifiedbuffer中进行向量减法运算,分数次完成当前张量的减法操作。
[0133]
本实施例并不在ai处理器中暂存通用矩阵乘算子输出的乘矩阵,而是将乘矩阵搬运至位于ai处理器外部的外部存储器上,当需要计算步骤s306中的通用矩阵乘算子中的减法部分时,再将乘矩阵从外部存储器搬运至ai处理器上的统一缓冲区(unifiedbuffer)与unifiedbuffer上的余下矩阵进行减法运算,以完成对待更新剩余矩阵的分解处理。
[0134]
本实施例之所以选择通用矩阵乘算子(gemm)对原矩阵进行分解处理成上三角矩阵和下三角矩阵是因为gemm相对其它算子具有较低的计算复杂度。下面举例比较gemm的计算复杂度与其它算子的计算复杂度:
[0135]
gemm(通用矩阵乘)的数学定义为:
[0136]c←
αab+βc(1)
[0137]
其中,a(相当于本实施例中的输入矩阵l)、b(相当于本实施例中的输入矩阵u)和c(相当于待更新剩余矩阵a)为矩阵,α和β为浮点数,当β取1,α取-1时,上述公式就变成如下公式:
[0138]a←
a-lu(2)
[0139]
本实施例中就是采用公式(2)对待更新剩余矩阵a不断迭代,直至待更新剩余矩阵a中的所有分块矩阵完成上下三角矩阵的分解。
[0140]
cann内已经预置了gemm算子,该算子使用tvm开发方式。在hpl-ai内直接调用cann内置的gemm算子即可完成待更新剩余矩阵更新的操作。
[0141]
在hpl-ai应用中的ab矩阵都是狭长型的矩阵,第i次迭代a矩阵高度为(n-i)*nb、宽度为nb,b矩阵高度为nb、宽度为(n-i)*nb,n*nb是原始待分解矩阵的长宽,i是当前迭代步数。hpl-ai应用中nb的取值为256,nb的取值考虑了cpu与npu的负载均衡(nb过大会使cpu计算时间过长,难以覆盖npu异步执行的时间;nb过小又难以充分发挥npu计算效率。nb的取值不绝对,比如可以是512(256的2倍))。
[0142]
对内置gemm算子进行性能测试,表中列举了不同输入尺寸下的性能表现。当gemm算子采用公式(1)对矩阵c进行分解时,输入矩阵a的大小为m*k,输入矩阵b的大小为k*n,输出矩阵c的大小为m*n。本测试一律取值k=nb=256。
[0143]
表3
[0144][0145]
输入尺寸较小时难以发挥npu(ai处理器)全部性能,当输入尺寸较大时,算子性能表现较好。已知一块昇腾ai芯片(npu)的理论峰值为256tflops,代表每秒可以执行256*10^12次浮点计算。表中gemm算子最优性能为105tflops,浮点利用率约为105/256*100%=41%。
[0146]
另外还对matmul(矩阵乘)和sub(向量减)算子进行了测试,在hpl-ai应用中这两个算子的组合可以等价于单独调用gemm算子。matmul算子最优能达到203tflops,浮点利用率79.3%,已经接近256tflops的上限。由于剩余子矩阵需要与matmul算子的输出相减,再调用sub算子后,性能大幅下降到63tflops。原因是matmul算子可以使用npu的矩阵计算单元,而sub算子只能使用npu的向量计算单元,npu的主要算力都集中在矩阵计算单元上,向量计算单元的算力远低于矩阵计算单元。分两次调用matmul和sub算子,与单独调用一次gemm算子相比,无法进行流水线上的优化,性能也会低于gemm算子,所以直接调用gemm算子是目前已有的最优选择。
[0147]
从上述分析可知,表3中的matmul+sub算子与本实施例中的gemm算子具有相同的功能,但是由于执行matmul+sub算子需要分别调用matmul和sub,即执行了两次调用,而gemm算子只需要调用一次就可以完成对余下矩阵的分解,因此能够使得npu的计算性能维持在105和98.3,原高于执行matmul+sub算子时npu的计算性能63.0和55.2。因此本实施例选择gemm算子。
[0148]
本实施例采用gemm算子以及对待更新剩余矩阵进行分片处理都是为了更好地发挥ai处理器的计算资源,为了进一步发挥ai处理器的计算资源,本实施例采用tik将gemm算子编写成程序,之后将程序置于ai处理器中就可以对待更新剩余矩阵进行分解了。
[0149]
tik(tensor iterator kernel)是一种基于python语言的动态编程框架,呈现为一个python模块,运行于host cpu上。开发者可以通过调用tik提供的api基于python语言编写自定义算子,即tik dsl,然后tik编译器会将tik dsl编译为昇腾ai处理器应用程序的二进制文件。
[0150]
tik是一种灵活的算子开发方式。tik在算子开发效率上存在不足,但在算子性能优化上有着一定的优势,开发者可以通过手动调度更加精确地控制数据搬运和计算流程,从而实现更高的性能,将昇腾ai处理器的能力发挥到极致。
[0151]
tik是基于昇腾ai软件栈tbe(tensor boost engine:张量加速引擎)算子开发框架开发出的一种算子开发方式。tbe除了开发了tik还开发了dsl:为了方便开发者进行自定义算子开发,昇腾ai软件栈借鉴了tvm中的topi机制,预先提供一些常用运算的调度,封装成一个个运算接口,称为基于tbe dsl开发。开发者只需要利用这些特定域语言声明计算的流程,再使用自动调度(auto schedule)机制,指定目标生成代码,即可进一步被编译成专用内核。
[0152]
cann(compute architecture for neural networks)是华为公司针对ai场景推出的异构计算架构,是芯片算子库和高度自动化算子开发工具。cann的核心是高度自动化算子开发工具tensor engine。通过统一的dsl接口,配合预置的高层模板封装、自动性能调优等工具集合,用户可以方便地在昇腾芯片上开发自定义算子。同时,cann已经支持所有主要ai框架。
[0153]
以图10为例,说明本实施例步骤s100至步骤s300的整体过程:
[0154]
本实施例的ai处理器为昇腾910型号的芯片,该芯片每个npu包含32个aicore,可以对在gemm算子的计算过程黄总进行多核优化。将余子矩阵按列进行多核划分,每个ai core处理1/32的数据,能够缩短计算时间。
[0155]
(一)从表示输入输出矩阵尺寸的张量height_width_input中获取矩阵尺寸信息和偏移量。
[0156]
在使用gemm256算子,需要给gemm256算子输入矩阵l尺寸张量、矩阵u尺寸张量、待更新剩余矩阵a中的每一个分块矩阵(对哪一个分块矩阵进行分解就输入哪个分块矩阵的尺寸张量)的尺寸张量。尺寸张量包括height、width、n和offset。其中height表示l矩阵中16*16*16*16张量的个数;width表示u矩阵中16*16*16*16张量的个数;total_length表示原始矩阵的尺寸n=n/nb;offset表示当前剩余子矩阵第一个16*16*16*16张量在原矩阵某一行中,距离该行第一个16*16*16*16张量的距离。以图11为例,height、width、n和offset(偏移量)的值分别为3、3、4和1。
[0157]
待更新剩余矩阵a是gemm256算子的唯一输出。在后处理阶段,需要将余下矩阵从npu的global memory拷贝到主机存储。待更新剩余矩阵不需要全部拷贝出来,只需要拷贝与下一步迭代相关的数据,减少数据传输。
[0158]
(二)根据昇腾ai处理器的核心数,启动多核并对矩阵u和待更新剩余矩阵a进行划分。在tik api for_range的原型定义里,用户通过设置参数block_num来实现多核并行。不同型号的昇腾ai处理器的ai core个数不同,对于昇腾910处理器,每个npu有32个ai core。
[0159]
(三)采用l1 buffer数据复用的优化方法,执行从global memory拷贝到l1 buffer的数据搬运。将l矩阵的6个block,u矩阵的1个block,待更新剩余矩阵对应位置的1个block拷贝到l1 buffer;
[0160]
(四)使用cube计算单元完成矩阵乘操作,计算结果存储在l0c buffer;
[0161]
(五)采用计算分片的方式,对矩阵乘的结果、l1 buffer内剩余子矩阵的数据进行切分,分次拷贝到unified buffer;使用vector计算单元将矩阵乘的结果与剩余子矩阵相减,结果存储在unified buffer。向量减的计算结果从unitfied buffer搬运到global memory;
[0162]
(六)如果完成所有数据的计算(待更新剩余矩阵a中的每一个分块矩阵都被分解
了),结束该算子的运行;否则回到步骤(三),对下一个数据块(矩阵块)进行操作。
[0163]
下面以对比试验的方式说明本实施例采用gemm256算子比gemm算子具有更好的性能:
[0164]
本发明针对昇腾ai处理器的达芬奇架构的特征以及编程特性,结合hpl-ai程序的特点,提出了一种基于昇腾ai处理器的gemm256算子的程序实现和优化方案,实现了ai core计算资源的充分利用。通过底层tik开发方式并结合多核、数据搬运等优化方法,极致地发挥昇腾ai处理器的架构和性能优势。
[0165]
表4是cann内置的gemm算子与本实施例的gemm256算子的性能对比。表4中对比了两个算子在不同尺寸下的性能,测试性能数据结果如下:
[0166]
表4
[0167]
尺寸\tflopsgemmgemm256m=256 k=256 n=256x12871.299.5m=256x6 k=256 n=256x128105139
[0168]
gemm256算子性能可达139tflops,约为理论峰值的54.3%,比cann内置的gemm算子快32.4%。gemm256是针对hpl-ai应用进行特殊优化的算子,因此对输入尺寸有更多的要求,比如m的值只能是256或者256*6,k的值只能为256,n的值可以是256的任意倍数但必须在较大的情况下才能发挥出比较好的性能。
[0169]
综上,通用矩阵乘算子在处理矩阵时,涉及到大量的矩阵乘法运算,而矩阵乘法对硬件性能有较高的要求,只有具有高处理速度上的硬件上运行矩阵乘算子才能提高矩阵乘算子处理矩阵的速度。本发明在ai处理器上通过矩阵乘算子处理矩阵,能够使得ai处理器的计算资源得到充分利用,从而提高了处理矩阵的速度和效率。
[0170]
示例性装置
[0171]
本实施例还提供一种基于ai处理器的通用矩阵乘算子的处理装置,所述装置包括如下组成部分:
[0172]
输入矩阵计算模块,用于依据原矩阵中的设定元素,在ai处理器的外部计算出输入矩阵;
[0173]
矩阵搬运模块,用于将所述输入矩阵搬运至全局内存,所述全局内存位于ai处理器上;
[0174]
矩阵计算模块,用于将搬运至所述全局内存的输入矩阵和位于所述全局内存上与所述原始矩阵相对应的待更新剩余矩阵作为通用矩阵乘算子的输入,得到所述通用矩阵乘算子输出的更新之后的剩余矩阵。
[0175]
基于上述实施例,本发明还提供了一种终端设备,其原理框图可以如图12所示。该终端设备包括通过系统总线连接的处理器、存储器、网络接口、显示屏、温度传感器。其中,该终端设备的处理器用于提供计算和控制能力。该终端设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统和计算机程序。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该终端设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种基于ai处理器的通用矩阵乘算子的处理方法。该终端设备的显示屏可以是液晶显示屏或者电子墨水显示屏,该终端设备的温度传感器是预先在终端设备内部设置,用于检测内部设备的运行温度。
[0176]
本领域技术人员可以理解,图12中示出的原理框图,仅仅是与本发明方案相关的部分结构的框图,并不构成对本发明方案所应用于其上的终端设备的限定,具体的终端设备以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
[0177]
在一个实施例中,提供了一种终端设备,终端设备包括存储器、处理器及存储在存储器中并可在处理器上运行的基于ai处理器的通用矩阵乘算子的处理程序,处理器执行基于ai处理器的通用矩阵乘算子的处理程序时,实现如下操作指令:
[0178]
依据原矩阵中的设定元素,在ai处理器的外部计算出输入矩阵;
[0179]
将所述输入矩阵搬运至全局内存,所述全局内存位于ai处理器上;
[0180]
将搬运至所述全局内存的输入矩阵和位于所述全局内存上与所述原始矩阵相对应的待更新剩余矩阵作为通用矩阵乘算子的输入,得到所述通用矩阵乘算子输出的更新之后的剩余矩阵。
[0181]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本发明所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram(ddrsdram)、增强型sdram(esdram)、同步链路(synchlink)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
[0182]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1