缺失POI的识别方法
缺失poi的识别方法
技术领域
1.本发明属于地理空间信息的的技术领域,具体涉及一种缺失poi的识别方法。
背景技术:
2.poi是“point of interest”的缩写,通常用来表示真实世界中存在的某一具备地理位置的事物,如购物商场或餐馆,并关联对应gps坐标。基于位置社交网络服务的流行(lbsns)吸引了越来越多的用户通过地点签到来分享他们的日常生活,签到的行为主要是由poi,签到时间,以及某些评论组成。随着互联网技术的不断发展以及对个性化需求的不断提高,从lbsn手机的数据被有效地用于各种应用(如poi推荐或预测)。
3.然而,数据质量问题(如签到poi缺失、数据稀疏)总是限制上述研究与应用的有效性。具体包括设备故障或用户作弊,使得给定签入发生的空间位置(即纬度和经度),没有相应的语义poi签到信息,即poi发生缺失。目前,基于poi的研究主要集中在推荐或预测用户未来可能去的poi,并假设所有用户签入指定了明确的poi,而没有考虑大签入poi的缺失情况。然而根据报道,在twitter和foursquare的lbsn平台中,超过一半的用户签到是缺失的。为此,我们提出的方法主要关注用户缺失poi的识别,即识别用户在过去特定的时间和空间位置访问过什么地方。它的意义在于:一方面,考虑到丢失的poi的候选分布,它有助于丰富的用户签到数据,以便更好地理解和建模用户移动性行为,提高poi推荐的服务质量;另一方面,几乎所有的poi推荐或预测任务都存在数据稀疏性问题,缺失poi识别可以缓解数据稀疏性问题;该任务也可用于社会公益,如嫌疑人追踪或失踪人口搜索分析。此外,通过确定患者在过去失联期间去过哪些场所,我们可以追踪可能与他/她在同一场所的人,以帮助避免交叉感染的风险。
4.现有研究中,与我们的问题最为相关的poi推荐和预测问题已经取得了很大的进展。个性化因子化马尔可夫链(fpmc)是贝叶斯个性化排序(bpr)优化的一种被广泛使用的方法,它嵌入用户偏好和个性化马尔可夫链进行poi推荐。个性化排名度量嵌入(prme)联合建模顺序转移、个性化偏好和地理影响,提高推荐性能。在扩展rnn的基础上,提出了空间-时间递归神经网络(strnn),该方法分别用时间间隔和地理距离的时间和距离转换矩阵对每一层的局部时空环境进行建模。此外,我们还采用了双曲度量嵌入(hme)方法代替传统的欧式度量空间来学习如何捕捉底层的层次结构和学习复杂的行为模式。
5.虽然这些方法取得了令人满意的结果,但仍存在一些缺点。首先,对于时间周期性影响、地理邻近性影响、用户偏好和顺序过渡模式,现有方法很少同时考虑所有这些影响因素,并且忽略了这些因素之间的关系。其次,目前的方法大多在相对稀疏的数据上建模相对精细的poi级用户偏好和顺序转移,这将导致较大的偏差。第三,上述方法不是为缺失poi标识而设计的,因为这样的问题需要在给定的查询时间前后利用相关上下文信息,而不是从单个角度推荐或预测。
技术实现要素:
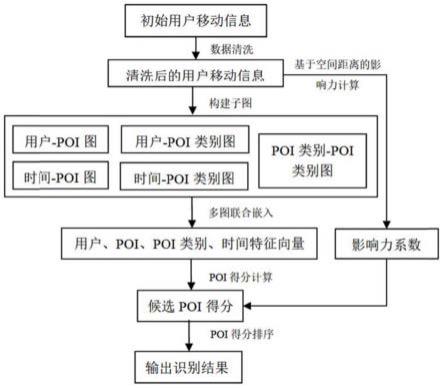
6.本发明的目的在于针对现有技术的不足之处,提供一种缺失poi的识别方法,较现有下一时刻poi的预测与推荐不同,该方法旨在通过建模整个历史信息与查询时间节点的前、后上下文信息,从而解决“你去了哪儿”识别的新问题。
7.为解决上述技术问题,本发明采用如下技术方案:
8.一种缺失poi的识别方法,包括如下步骤:
9.步骤1.输入基于位置社交网络服务平台的用户签到数据,进行数据清洗,并统一数据格式,保证数据一致性;
10.步骤2.根据步骤1处理后的数据,构建基于用户、时间分别与poi、poi类别以及poi与poi类别之间的关系图网格,之后将上述多个关系图进行联合图嵌入,从而将用户、时间、poi和poi类别的表达向量嵌入到统一共享维度空间中,共同捕获顺序转换模式、时间周期影响与用户偏好;
11.步骤3.考虑区域级别的空间邻近性,将城市区域进行网格划分,并将每个poi嵌入对应网络区域,然后对地理空间的距离进行加权;
12.步骤4.将步骤2得到的用户偏好和步骤3距离权重融合进行联合概率估计,得出每个候选poi的概率得分并排名,根据排名,得出用户在过去某个时间缺失的poi签到,从而预测用户去过的位置信息。
13.进一步地,步骤1中数据清洗的方法为滤除签到次数少于n次的poi地点和用户,其中,n根据实际需要设定。
14.进一步地,步骤2具体还包括如下子步骤:
15.步骤2.1、基于步骤1处理后的数据,构建5个关系图网格,即用户—poi、用户—poi、时间—poi、时间—poi类别以及poi类别—poi类别,其中每个图中的权重表示发生此项签到的频率;
16.步骤2.2、基于2.1得到的5个关系图,使用联合图嵌入方法,将关系到用户个性化偏好的用户、poi、poi类别以及时间的表达向量,嵌入到统一共享维度空间中,得到统一共享维度空间中的用户、poi、poi类别、时间的嵌入向量:其中,包括和
17.步骤2.3根据步骤2.2得到的用户、poi、poi类别、时间的嵌入向量,挖掘用户在某个时间的静态偏好得分s
p
:
[0018][0019]
式中,p表示社会场所地点(point of interest,poi),如xx超市、xx面馆等),c表示社会场所地点的语义类别(如购物、餐饮),u表示用户,τ表示查询的时间项,t表示时间,为的转置矩阵;同时,为了表达用户在社会地点类别之间的转移偏好,我们对每个社会场所地点的语义类别c赋予两个角色:“出”和“入”分别对应和因此,用表示相邻时刻社会地点语义类别转换的得分,其值越大,表示在
τ
时刻用户访问的社会地点类别c
τ
后越有可能在下一τ+1时刻,越有可能访问c
τ+1
。
[0020]
并基于上述的嵌入向量表达用户对地点的序列转移偏好得分sq:
[0021][0022]
式中,c
τ
、c
τ-1
和c
τ+1
分别表示当前时刻、上一时刻和下一时刻社会场所地点类别,c
τ
表示,c
τ-1
表示,c
τ+1
表示,表示用户个性化项,p(c
τ
|c
τ-1
,c
τ+1
)为转移概率:
[0023][0024]
其中,表示-1时刻社会地点类别特征的“出”分量,表示τ时刻社会地点类别特征的“入”分量,表示+1时刻的社会地点类别特征的“入”分量,为发生缺失poi标注的时刻与连续前项签到的时间间隔,为发生缺失poi标注的时刻与连续后项签到的时间间隔,η表示为时间间隔阈值,当连续签到时间大于η时,表示用户发生签到行为不受序列影响,而只受到长期静态偏好影响;
[0025]
基于上述两项因素,结合用户的静态偏好和序列转移偏好得出用户对候选poi的概率得分:
[0026][0027]
式中,θ表示权重参数,范围为[0,1];当大于时间阈值η时,认为用户发生签到的行为只受长期静态偏好的影响;反之,则受两项因素同时影响。
[0028]
进一步地,步骤3具体包括:
[0029]
将城市划分成网格区域,得出每个网格区域的中心坐标;再根据用户发生poi缺失时的gps坐标,将其映射到对应网格区域,计算该网格区域和其他候选poi对应的网格中心坐标之间的距离,并计算空间距离的权重:
[0030][0031]
其中,l表示poi缺失时的gps坐标,p表示poi候选poi的gps坐标,d(
·
)表示为l2范式的gps坐标距离,a为参数,x
l
表示l坐标映射的网格区域中心gps坐标,xp表示候选poi映射的网格区域中心gps坐标。
[0032]
进一步地,步骤4中,将所有影响因素融合进行联合概率估计,得出每个候选poi的概率得分表示为:
[0033]stotal
(p,c|u,l,t)=(1+w
l,p
)
·sp+q
(p,c|
·
);
[0034]
式中,p表示社会场所poi,c表示社会场所的语义类别,u表示用户,l表示poi缺失时的gps坐标,t表示poi缺失时的时间,w
l,p
表示步骤3得到得空间距离权重,s
p+q
(p,c|
·
)表示步骤2得到的用户偏好对候选poi的概率得分;
[0035]
最后,对缺失的poi签到进行识别预测,得到最终结果:
[0036][0037]
其中,accuary@k代表top-k个候选中出现标准答案的概率,top-k为由s
total
按照得分顺序从高到低给出的推荐结果,hit@k表示给出的得分最高的top-k个候选poi中有正确的结果就设为1否则就为0;|dtest|表示测试集的样本数量。
[0038]
与现有技术相比,本发明的有益效果为:本发明通过提出一个类别感知网络嵌入模型来解决目前在基于位置社交网络服务(lbsn)的软件平台中,大约有30%的签到位置存在社会地点位置缺失以及数据质量问题(如签到poi缺失、数据稀疏)也限制了现有面向基于位置社交网络服务研究的有效性(如poi推荐或预测)的问题,该方法通过将五个关系图嵌入到共享空间中,共同捕获时间影响、用户偏好和顺序转换,对于poi类别顺序转换建模,该方法创新性地对每个poi类别分配了两个角色:即本身以及另一个类别的特定上下文身份,最后将上述所有影响因素融合进行联合概率估计,得出每个poi的概率得分并排名,根据排名,得出用户在过去某个时间缺失的poi签到识别,实现预测“他/她去过哪儿?”;同时,该方法通过可以通过变形,较自然地扩展到常规的下一时刻poi推荐和预测任务。
附图说明
[0039]
图1为本发明实施例缺失poi的识别方法的框架图;
[0040]
图2为本发明实施例缺失poi的识别方法的流程图。
具体实施方式
[0041]
下面将结合本发明实施例对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0042]
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
[0043]
下面结合具体实施例对本发明作进一步说明,但不作为本发明的限定。
[0044]
如图1和图2所示,本发明提供一种缺失poi的识别方法,包括以下步骤:
[0045]
步骤1.输入基于位置社交网络服务平台(微信,foursquare,facebook等)的用户签到数据,进行数据清洗,并统一数据格式,保证数据一致性;在该步骤中,数据清洗的方法为滤除签到次数少于n次的poi地点和用户,其中,n根据实际需要设定,在本实施例中,n设定为10次。
[0046]
步骤2.根据步骤1处理后的数据,构建基于用户、时间分别与poi、poi类别以及poi与poi类别之间的关系图网格,之后将上述多个关系图进行联合图嵌入,从而将用户、时间、poi和poi类别的表达向量嵌入到统一共享维度空间中,共同捕获顺序转换模式、时间周期影响与用户偏好;步骤2具体包括如下子步骤:
[0047]
步骤2.1、通过时间划分,其中,时间可以按照天(6个时段)和周(7天)划分为42个时间段,再基于步骤1中处理后的数据,构建5个关系图网格,即用户—poi:g
up
(u∪p,ε
up
)、用户—poi:g
uc
(u∪c,ε
uc
)、时间—poi:g
tp
(t∪p,ε
tp
)、时间—poi类别:g
tc
(t∪c,ε
tc
)以及
poi类别—poi类别:g
cc
(c∪c,ε
cc
),其中每个图中的权重表示发生此项签到的频率。g
up
、g
uc
、g
tp
、g
tc
的构建主要用于捕捉用户的长期,周期性偏好模式,g
cc
用于捕捉用户在进行序列伴随行为模式。
[0048]
步骤2.2、基于上一步得到的5个关系图,进行联合图嵌入,将关系到用户个性化偏好的用户、poi、poi类别以及时间的表达向量,嵌入到统一共享维度空间中,得到统一共享维度空间中的用户、poi、poi类别、时间的嵌入向量;具体地,该方法依次从每个图中抽取边,再依次进行节点嵌入学习,其中对于每个图网络的嵌入方法如下:
[0049]
(1)给定任意一个二部图网络g
ab
=(va∪vb,e),其中va和vb分别表示两种不同类别的节点类型,e表示其中节点之间的连边;
[0050]
(2)对于图g
ab
中的边e
ij
,其经验分布可以表示为:
[0051][0052]
其中,w
ij
表示边e
ij
的权重,deg(i)表示节点i的度;
[0053]
(3)同时,定义顶点vi生成顶点vj的条件概率定义为:
[0054][0055]
其中,和表示为节点i和节点j的嵌入表达向量,vk表示为经过负采样得到的负样本,表示节点vk嵌入表达向量的转置。
[0056]
(4)为了学习确保条件分布p(vj|vi)与经验分布接近的嵌入,在图g
ab
上最小化以下目标函数:
[0057][0058]
式中,v表示节点向量集合,λi表示节点vi重要程度参数,d
kl
表示kl散度函数,旨在度量两个分布之间的差异,p
θ
(
·
)表示给定参数θ下的节点概率分布;
[0059]
经过化简得到:
[0060][0061]
(5)同时,为了减少计算复杂度,引入负采样机制,最终得到损失函数:
[0062][0063]
其中,σ(
·
)表示sigmoid激活函数,表示负样本vk的采样,vk表示为经过负采样得到的负样本,vk~q(
·
|i)表示负样本节点vk的采样服从给定节点vi的q(
·
|i)分布,和表示为节点i和节点j的嵌入表达向量,表示负节点vk嵌入特征向量的转置,并对其取相反数;
[0064]
使用上述方法,对每个图网络进行图嵌入,得出整体损失函数:
[0065]
o=o
up
+o
uc
+o
tp
+o
tc
+o
cc
;
[0066]
根据得到的整体损失函数对模型进行训练。经过上述操作,得到统一共享维度空间中的用户、poi、poi类别、时间的嵌入向量:其中,在相关变量联合嵌入时,为了捕捉用户在访问不同社会地点之间的序列转移模式,较传统的单一身份,该方法使用两个独立的特征向量来表征统一poi类别,即包括和表示对每个poi类别节点赋予了两个特征向量和和分别代表这个节点的出、入身份;该步骤的算法伪代码如表1所示:
[0067]
表1为联合图嵌入算法的伪代码
[0068][0069][0070]
步骤2.3、根据步骤2.2得到的用户、poi、poi类别、时间的嵌入向量,挖掘用户在某个时间的静态偏好得分s
p
:
[0071][0072]
式中,p表示社会场所地点(point of interest,poi),如xx超市、xx面馆等),c表示社会场所地点的语义类别(如购物、餐饮),u表示用户,τ表示查询的时间项,t表示时间,为的转置矩阵;同时,为了表达用户在社会地点类别之间的转移偏好,我们对每个社会场所地点的语义类别c赋予两个角色:“出”和“入”分别对应和因此,用
表示相邻时刻社会地点语义类别转换的得分,其值越大,表示在
τ
时刻用户访问的社会地点类别c
τ
后越有可能在下一τ+1时刻,越有可能访问c
τ+1
;
[0073]
并基于上述的嵌入向量表达用户对地点的序列转移偏好得分sq:
[0074][0075]
式中,c
τ
、c
τ-1
和c
τ+1
分别对应表示当前时刻、上一时刻和下一时刻社会场所地点类别,表示用户个性化偏好项,p(c
τ
|c
τ-1
,c
τ+1
)为转移概率:
[0076][0077]
其中,表示-1时刻社会地点类别特征的“出”分量,表示τ时刻社会地点类别特征的“入”分量,表示+1时刻的社会地点类别特征的“入”分量,为发生缺失poi标注的时刻与连续前项签到的时间间隔,为发生缺失poi标注的时刻与连续后项签到的时间间隔,η表示为时间间隔阈值,当连续签到时间大于η时,表示用户发生签到行为不受序列影响,而只受到长期静态偏好影响;
[0078]
基于上述两项因素,结合用户的静态偏好和序列转移偏好得出用户对候选poi的概率得分:
[0079][0080]
式中,θ表示权重参数,范围为[0,1];当大于时间阈值η时,认为用户发生签到的行为只受长期静态偏好的影响;反之,则受两项因素同时影响。
[0081]
步骤3.考虑区域级别的空间邻近性,将城市区域进行线性网格划分,将每个poi嵌入对应网络区域,然后对地理空间的距离进行加权;
[0082]
具体地,经过将城市划分成网格区域,得出每个网格区域的中心坐标,根据用户发生poi缺失时的gps坐标,经过映射,将其映射到对应网格区域,计算该网格区域和其他候选poi对应的网格中心坐标之间的距离,并将此作为基于空间距离的权重:
[0083][0084]
其中,l表示poi缺失时的gps坐标,p表示poi候选poi的gps坐标,d(
·
)表示为l2范式的gps坐标距离,a为参数,x
l
表示l坐标映射的网格区域中心gps坐标,xp表示候选poi映射的网格区域中心gps坐标。
[0085]
步骤4.将步骤2和步骤3中得出的所有影响因素融合进行联合概率估计,得出每个候选poi的概率得分并排名,根据排名,得出用户在过去某个时间缺失的poi签到,从而预测用户去过的位置信息;具体地,
[0086]
将上述影响因素融合得到联合概率得分:
[0087]stotal
(p,c|u,l,t)=(1+w
l,p
)
·sp+q
(p,c|
·
);
[0088]
然后进行测试:
[0089][0090]
其中,accuary@k代表top-k个候选中出现标准答案的概率,top-k为由s
total
按照得分顺序从高到低给出的推荐结果,hit@k表示给出的得分最高的top-k个候选poi中有正确的结果就设为1否则就为0;|dtest|表示测试集的样本数量。
[0091]
申请人在intel(r)core(tm)i7-7700k cpu@4.20ghz、2080ti gpu的计算机上运行,使用本实施例方法,使用公开的数据集nyc和tky和文献(q.liu,s.wu,l.wang,and t.tan,“predicting the next location:a recurrent model with spatial and temporal contexts,”in proceedings of the aaai conference on artificial intelligence,vol.30,no.1,2016.),(c.yang,l.bai,c.zhang,q.yuan,and j.han,“bridging collaborative filtering and semi-supervised learning:a neural approach for poi recommendation,”in proceedings of the 23rd acm sigkdd international conference on knowledge discovery and data mining,2017,pp.1245
–
1254.),(d.xi,f.zhuang,y.liu,j.gu,h.xiong,and q.he,“modelling of bidirectional spatio-temporal dependence and users’dynamic preferences for missing poi check-in identification,”in proceedings of the aaai conference on artificial intelligence,vol.33,no.01,2019,pp.5458
–
5465.)做了比较,识别精确度有较大的提高,因此可以应用于应用于推荐系统、失踪人口分析、疾病溯源、个性化服务等领域。
[0092]
以上仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1