基于反事实注意力学习的行人再识别方法、系统、介质
1.本发明属于计算机视觉技术领域,具体涉及一种基于反事实注意力学习的行人再识别方法、系统和计算机存储介质。
背景技术:
2.近年来,无监督域自适应(unsupervised domain adaptive,uda)是深度学习领域的一个研究热点,该任务是将在有标签的源域数据集上训练的模型应用到另一个任务相关但特征分布不同且无标签的目标域数据集。现有的无监督域自适应行人再识别方法通常包括三个步骤:使用有标签的源域数据进行特征预训练,针对目标域数据进行基于聚类的伪标签预测,以及特征表示学习和伪标签微调。
3.然而由于源域数据和目标域数据之间的差异/域间隙以及聚类算法的不完善性质,通过聚类分配的伪标签通常包含不正确的标签。这种嘈杂的标签会误导特征学习并损害域适应性能。因此,缓解噪声伪标签样本的负面影响及解决目标域数据行人图像存在背景杂波和遮挡问题对提高域自适应模型检索的性能十分重要。为了解决上述噪声标签问题,现有一些域自适应算法通过在线修正不正确的样本来帮助模型学习更具鲁棒性的特征表示。尽管这些域自适应算法已经取得了显著的进步,但是相对于有监督行人再识别其识别准确率依旧不尽人意。另外传统方法大多通过监督最终预测来优化注意力,并将整个网络视为黑匣子,忽略了学习的注意力图是如何影响预测的。造成基于聚类框架下伪标签微调过程中容易出现噪声伪标签的负面影响。
技术实现要素:
4.发明目的:针对现有技术中存在的问题,本发明提供一种基于反事实注意力学习的行人再识别方法,该方法能够有效提高行人再识别的准确度。
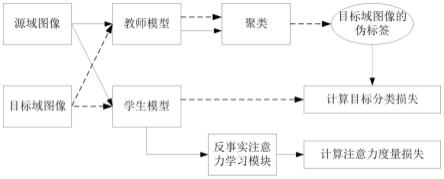
5.技术方案:本发明一方面公开了一种基于反事实注意力学习的行人再识别方法,包括步骤:
6.s1、建立教师模型和学生模型,所述教师模型和学生模型的结构相同;所述教师模型的输入为行人图像,结构包括主干网络和分类器,其中主干网络用于提取行人图像的特征,分类器用于根据行人图像的特征获取行人图像的类别概率;
7.采用源域数据集对教师模型进行预训练,所述预训练的目标为最小化分类损失函数,所述分类损失函数为:
[0008][0009]
其中p(y
s,n
∣x
s,n
)表示将输入图像x
s,n
识别为类y
s,n
的概率,y
s,n
是源域数据集中x
s,n
的类别标签,n为预训练过程中每个批次样本的数量;
[0010]
将学生模型的参数初始化为预训练后教师模型的参数;
[0011]
s2、将目标域数据集中的图像输入教师模型,所述教师模型主干网络输出目标域
图像的特征;对目标域图像的特征进行聚类,根据聚类后的类别生成目标域图像的伪标签,每个聚类中心的特征向量拼接为目标域聚类中心矩阵其中p
t
为目标域图像特征聚类后的类别数,c,h,w分别为教师模型主干网络提取到的特征的维度、高度、宽度;
[0012]
s3、将源域数据集中的图像输入教师模型,所述教师模型主干网络输出源域图像的特征;依照源域图像的真实身份标签,对提取到的属于同一身份的源域图像特征向量取平均得到该行人身份的类中心向量,每个类中心的特征向量拼接为源域类中心矩阵其中ps为源域数据的真实行人身份类别数;
[0013]rt
和rs拼接为参考中心矩阵kr=p
t
+ps;
[0014]
s4、令教师模型的参数保持不变,采用迭代训练优化学生模型的参数;迭代训练优化的目标为最小化损失函数,具体的训练中每个批次的样本包括n
t
个目标域图像和ns个源域图像;损失函数l
total
为目标分类损失l
class
和注意力度量损失之和;具体步骤为:
[0015]
s4.1a、计算目标分类损失l
class
:
[0016][0017]
其中为目标域图像xi的伪标签,为学生模型将输入图像xi识别为类的概率;
[0018]
s4.2a、计算源域图像zv注意力对预测的影响值,v=1,2,
…
,ns:
[0019]
将zv输入学生模型得到zv的第一特征fv,fv∈rc×h×w;
[0020]
利用空间注意力模块提取fv的注意力特征图fv:
[0021]fv
={f
v,1
,f
v,2
,...,f
v,m
,...f
v,m
}=attention(fv)
ꢀꢀꢀ
(4)
[0022]
其中attention(
·
)表示空间注意力模块提取注意力特征图运算,f
v,m
∈rh×w为注意力特征图fv中第m个感兴趣区域的注意力特征图,m为感兴趣区域的数量;
[0023]
利用f
v,m
对第一特征fv进行加权,并采用全局平均池化操作进行聚合,得到局部注意力z
v,m
:z
v,m
=gap(fv*f
v,m
);其中gap表示全局平均池化操作;
[0024]
将局部注意力组合起来并归一化,得到源域图像zv的全局特征zv:
[0025]zv
=normalize([z
v,1
,z
v,2
,...,z
v,m
,...,z
v,m
])
ꢀꢀꢀ
(5)
[0026]
其中normalize表示归一化运算;
[0027]
将全局特征zv依次输入批归一化层和分类层,得到源域图像zv经空间注意力加权后的预测结果:
[0028]yv
=c(bn(zv))
ꢀꢀꢀ
(6)
[0029]
生成反注意力特征图所述反注意力特征图的尺寸与fv相同,其每个元素值为随机数;
[0030]
采用反注意力特征图对fv进行加权,并经全局平均池化操作、组合并归一化、依次输入批归一化层和分类层,得到源域图像zv经反空间注意力加权后的预测结果
[0031]
注意力对预测的影响值为:
[0032]
s4.3a、计算注意力度量损失:
[0033][0034]ys,v
是源域图像zv的类别标签;为将注意力对预测的影响值为的图像识别为类y
s,v
的概率;
[0035]
s5、对教师模型的参数进行加权平均更新;
[0036]
迭代训练优化结束后,根据学生模型的参数对教师模型的参数进行加权平均更新;将目标域图像输入更新后的教师模型,分类器输出类别概率,选择类别概率最大值对应的类别作为输入图像的识别结果。
[0037]
进一步地,所述教师模型的主干网络包括依次连接的第一卷积模块、第一池化模块、第一注意力模块、第二卷积模块、第二注意力模块、第三卷积模块、第三注意力模块、第四卷积模块、第四注意力模块、第五卷积模块、第五注意力模块、第二池化模块。
[0038]
进一步地,所述第一注意力模块、第二注意力模块、第三注意力模块、第四注意力模块、第五注意力模块的结构相同,包括级联的2d卷积层和激活单元。
[0039]
进一步地,通过计算教师模型和学生模型输出差异来计算不确定性,从而得到目标域图像伪标签的可信度或可靠性,并利用该可信度或可靠性对损失函数进行加权,具体地,所述加权后的目标分类损失计算步骤为:
[0040]
s4.1b、计算目标域图像xi的不确定性ui,i=1,2,
…
,n
t
:
[0041]
将xi输入学生模型,所述学生模型的主干网络输出xi的第一特征fi;
[0042]
计算第一特征fi与参考中心矩阵r的相似度,作为xi的第一软多标签li:li=softmax(r
·fi
);
[0043]
将xi输入教师模型,所述教师模型的主干网络输出xi的第二特征
[0044]
计算第二特征与参考中心矩阵r的相似度,作为xi的第二软多标签的第二软多标签
[0045]
基于kl散度计算xi的不确定性ui:
[0046]
其中l
i,k
表示第一软多标签li中预测为参考中心矩阵r对应的第k个身份的概率;表示第二软多标签中预测为参考中心矩阵r对应的第k个身份的概率;
[0047]
s4.2b、计算目标域图像xi的可信度权重ωi:ωi=exp(-ui);
[0048]
s4.3b、计算加权后的目标域分类损失l
class
,
[0049]
其中为目标域图像xi的伪标签,为学生模型将输入图像xi识别为类的概率。
[0050]
进一步地,所述损失函数还包括三重态损失,计算步骤包括:
[0051]
s4.4b、根据目标域图像构建三元组:从n
t
个目标域图像中随机选取p个类别、每个
类别包括k个实例,以选择的目标域图像为anchor样本构建三元组其中l=1,2,
…
,p,m=1,2,
…
,k,为第l类中的第m个实例,为的正样本,为的负样本;
[0052]
计算每个三元组中anchor样本、正样本、负样本的不确定性
[0053]
计算正样本对anchor样本的可靠性和负样本对anchor样本的可靠性和负样本对anchor样本的可靠性
[0054]
其中:
[0055][0056]
s4.5b、计算可靠性加权的三重态损失:
[0057][0058]
其中表示与之间的相似度,表示与之间的相似度;α》0,α为预设的距离常数。
[0059]
进一步地,所述损失函数还包括对比损失,计算步骤为:
[0060]
s4.6b、根据训练样本建立memory bank;将目标域图像xi作为query样本,在memory bank中查找与xi具有相同伪标签的样本作为正样本,与xi具有不同伪标签的样本作为负样本;计算对比损失:
[0061][0062]
其中和分别为memory bank中xi正样本和负样本的个数,表示第j个负样本与xi的相似度,表示第j个负样本对xi的可靠性,表示第h个正样本与xi的相似度,表示第h个正样本对xi的可靠性。
[0063]
另一方面,本发明还公开了一种基于反事实注意力学习的行人再识别系统,所述系统为根据上述方法得到的教师模型。
[0064]
本发明还公开了一种计算机存储介质,其上存储有计算机指令,所述计算机指令运行时执行上述行人再识别方法。
[0065]
有益效果:与现有技术相比,本发明公开的基于反事实注意力学习的行人再识别方法和系统具有如下优点:
[0066]
1、本发明针对数据集中行人图像存在背景杂波和遮挡问题,提出了反注意力学习机制。大多数现有方法以弱监督的方式学习视觉注意,即注意模块仅由最终损失函数监督,而没有强大的监督信号来指导训练过程。这种基于可能性的方法仅明确监督最终预测,但忽略了预测和注意之间的因果关系。本发明提出了一个新的基于因果推理的反事实注意力
学习方法来增强目标域行人图像的判别性特征学习解决目标域行人图像存在遮挡和背景杂波问题。其基本思想是通过比较事实(即学习的注意力)和反事实(即虚假的注意力)对最终预测的影响来量化注意力的质量。并最大化差异以促进网络学习更有效的视觉注意力并减少有偏训练集的影响。
[0067]
2、针对噪声标签问题,现有一些域自适应算法通过在线修正不正确的样本来帮助模型学习更具鲁棒性的特征表示。尽管这些域自适应算法已经取得了显著的进步,但是相对于无监督行人再识别其识别准确率依旧不尽人意。本发明通过测量两个模型(基于平均教师方法的学生模型和教师模型)的输出特征的不一致性水平,作为目标域样本的不确定性分布。通过估计和利用样本的不确定性来减轻噪声伪标签的负面影响,从而实现更加有效的域自适应算法。
附图说明
[0068]
图1为实施例1中的训练框架图;
[0069]
图2为反事实注意力学习模块的结构示意图;
[0070]
图3为实施例2中的训练框架图。
具体实施方式
[0071]
下面结合附图和具体实施方式,进一步阐明本发明。
[0072]
实施例1:
[0073]
本发明公开了一种基于反事实注意力学习的行人再识别方法,包括步骤:
[0074]
s1、建立教师模型和学生模型,所述教师模型和学生模型的结构相同;所述教师模型的输入为行人图像,结构包括主干网络和分类器,其中主干网络用于提取行人图像的特征,分类器用于根据行人图像的特征获取行人图像的类别概率;所述主干网络包括依次连接的第一卷积模块、第一池化模块、第一注意力模块、第二卷积模块、第二注意力模块、第三卷积模块、第三注意力模块、第四卷积模块、第四注意力模块、第五卷积模块、第五注意力模块、第二池化模块。本实施例中,教师模型和学生模型基于resnet50网络,对该网络增加5个注意力模块,具体网络如表1所示。
[0075]
表1给出了本实施例中第一卷积模块conv_1、第一池化模块maxpool_1、第一注意力模块att_1、第二卷积模块conv_2x、第二注意力模块att_2、第三卷积模块conv_3x、第三注意力模块att_3、第四卷积模块conv_4x、第四注意力模块att_4、第五卷积模块conv_5x、第五注意力模块att_5、第二池化模块maxpool_2和分类器classifier的结构参数。其中第一注意力模块att_1、第二注意力模块att_2、第三注意力模块att_3、第四注意力模块att_4、第五注意力模块att_5的结构相同,均为包括级联的2d卷积层和激活单元,但其中卷积层的输出通道数不同。
[0076]
表1网络结构参数
[0077][0078]
采用源域数据集对教师模型进行预训练,所述预训练的目标为最小化分类损失函数,所述分类损失函数为:
[0079][0080]
其中p(y
s,n
∣x
s,n
)表示将输入图像x
s,n
识别为类y
s,n
的概率,y
s,n
是源域数据集中x
s,n
的类别标签,n为预训练过程中每个批次样本的数量;为了提高模型的鲁棒性,在预训练前对源域数据集中的图像进行随机擦除、随机裁剪和随机翻转等扰动,用扰动后的图像进行预训练,以此来降低模型对图像的敏感度。
[0081]
将学生模型的参数初始化为预训练后教师模型的参数;
[0082]
s2、将目标域数据集中的图像输入教师模型,所述教师模型主干网络输出目标域图像的特征;对目标域图像的特征进行聚类,根据聚类后的类别生成目标域图像的伪标签,每个聚类中心的特征向量拼接为目标域聚类中心矩阵其中p
t
为目标域图像特
征聚类后的类别数,c,h,w分别为教师模型主干网络提取到的特征的维度、高度、宽度;
[0083]
s3、将源域数据集中的图像输入教师模型,所述教师模型主干网络输出源域图像的特征;依照源域图像的真实身份标签,对提取到的属于同一身份的源域图像特征向量取平均得到该行人身份的类中心向量,每个类中心的特征向量拼接为源域类中心矩阵其中ps为源域数据的真实行人身份类别数;
[0084]rt
和rs拼接为参考中心矩阵kr=p
t
+ps;
[0085]
s4、令教师模型的参数保持不变,采用迭代训练优化学生模型的参数;迭代训练优化的目标为最小化损失函数,具体的训练中每个批次的样本包括n
t
个目标域图像和ns个源域图像;本实施例中损失函数l
total
为目标分类损失l
class
和注意力度量损失之和,即:
[0086][0087]
其中λ
eff
为预设的注意力度量损失系数;
[0088]
注意力模块是行人再识别框架中指导网络提取行人图像最具判别力特征的重要组成部分。为了学习到更好的注意力权重,本发明引入了一种反事实注意力机制,通过衡量网络学习到的注意力特征图和随机生成的反事实注意力特征图对分类结果的影响,从而使网络学习更好的注意力权重。训练框架如图1所示,图中实线为源域图像的流向,虚线为目标域图像的流向,具体步骤为:
[0089]
s4.1a、计算目标分类损失l
class
:
[0090][0091]
其中为目标域图像xi的伪标签,为学生模型将输入图像xi识别为类的概率;
[0092]
s4.2a、计算源域图像zv注意力对预测的影响值,v=1,2,
…
,ns:
[0093]
将zv输入学生模型得到zv的第一特征fv,fv∈rc×h×w;
[0094]
利用空间注意力模块提取fv的注意力特征图fv:
[0095]fv
={f
v,1
,f
v,2
,...,f
v,m
,...f
v,m
}=attention(fv)
ꢀꢀꢀ
(4)
[0096]
其中attention(
·
)表示空间注意力模块提取注意力特征图运算,f
v,m
∈rh×w为注意力特征图fv中第m个感兴趣区域的注意力特征图,m为感兴趣区域的数量;本实施例中,m取经验值8,即将注意力特征图分为8个感兴趣区域,每个区域可能有不同的特征,如行人的背包、鞋子、衣服等均体现为不同的特征。本实施例中,空间注意力模块采用文献:rao y,chen g,lu j,et al.counterfactual attention learning for fine-grained visual categorization and re-identification[j].2021.中的方法,该空间注意力模块是使用一个2d卷积层和一个relu激活函数实现。
[0097]
利用f
v,m
对第一特征fv进行加权,并采用全局平均池化操作进行聚合,得到局部注意力z
v,m
:z
v,m
=gap(fv*f
v,m
);其中gap表示全局平均池化操作;
[0098]
将局部注意力组合起来并归一化,得到源域图像zv的全局特征zv:
[0099]zv
=normalize([z
v,1
,z
v,2
,...,z
v,m
,...,z
v,m
])
ꢀꢀꢀ
(5)
[0100]
其中normalize表示归一化运算;
[0101]
将全局特征zv依次输入批归一化层和分类层,得到源域图像zv经空间注意力加权后的预测结果:
[0102]yv
=c(bn(zv))
ꢀꢀꢀ
(6)
[0103]
生成反注意力特征图所述反注意力特征图的尺寸与fv相同,其每个元素值为随机数;
[0104]
采用反注意力特征图对fv进行加权,并经全局平均池化操作、组合并归一化、依次输入批归一化层和分类层,得到源域图像zv经反空间注意力加权后的预测结果
[0105]
注意力对预测的影响值为:
[0106]
的计算由反事实注意力学习模块完成,其结构如图2所示。
[0107]
s4.3a、计算注意力度量损失:
[0108][0109]ys,v
是源域图像zv的类别标签;为将注意力对预测的影响值为的图像识别为类y
s,v
的概率;
[0110]
s5、对教师模型的参数进行加权平均更新;
[0111]
迭代训练优化结束后,根据学生模型的参数对教师模型的参数进行加权平均更新。本实施例采用文献:tarvainen a,valpola h.mean teachers are better role models:weight-averaged consistency targets improve semi-supervised deep learning results[j].2017.中的方法对学生模型参数进行优化,并对教师模型的参数进行加权平均更新。
[0112]
将目标域图像输入更新后的教师模型,分类器输出类别概率,选择类别概率最大值对应的类别作为输入图像的识别结果。
[0113]
实施例2:
[0114]
本实施例与实施例1的区别是采用可信度权重对目标分类损失函数中的部分进行了加权。
[0115]
不正确的伪标签会在训练中误导特征学习,影响域自适应模型的性能。本实施例中,通过评估教师模型和学生模型输出差异来估计不确定性分布,从而评估目标域图像的伪标签的可信度或可靠性,并利用该可信度或可靠性对损失函数进行加权,以此抑制错误伪标签样本对训练的负面影响,提高模型的域自适应性能。迭代训练优化的目标为最小化损失函数,损失函数除了注意力度量损失外,还可以包括分类损失、三重态损失、对比损失中的一种或多种,本实施例中,损失函数为注意力度量损失和上述三种损失之和,训练框架如图3所示,具体地,一个训练批次包括步骤:
[0116]
s4.1b、计算目标域图像xi的不确定性ui,i=1,2,
…
,n
t
:
[0117]
将xi输入学生模型,所述学生模型的主干网络输出xi的第一特征fi;
[0118]
计算第一特征fi与参考中心矩阵r的相似度,作为xi的第一软多标签li:li=softmax(r
·fi
);
[0119]
将xi输入教师模型,所述教师模型的主干网络输出xi的第二特征
[0120]
计算第二特征与参考中心矩阵r的相似度,作为xi的第二软多标签的第二软多标签
[0121]
本发明使用kl散度来测量教师模型和学生模型所提取特征向量概率分布之间的差异,即:
[0122]
基于kl散度计算xi的不确定性ui:
[0123][0124]
其中l
i,k
表示第一软多标签li中预测为参考中心矩阵r对应的第k个身份的概率;表示第二软多标签中预测为参考中心矩阵r对应的第k个身份的概率;
[0125]
s4.2b、计算目标域图像xi的可信度权重ωi:ωi=exp(-ui);
[0126]
s4.3b、根据不确定性的计算式可知,教师模型和学生模型对同一图像输出的差异越大,则不确定性越高,相应地,可信度权重就越低;由此得到使用可信度权重加权后的目标分类损失l
class
:
[0127][0128]
其中为目标域图像xi的伪标签,为学生模型将输入图像xi识别为类的概率;
[0129]
s4.4b、根据目标域图像构建三元组:从n
t
个目标域图像中随机选取p个类别、每个类别包括k个实例,以选择的目标域图像为anchor样本构建三元组其中l=1,2,
…
,p,m=1,2,
…
,k,为第l类中的第m个实例,为的正样本,即为与类别相同的目标域图像;为的负样本,即为与类别不同的目标域图像;
[0130]
根据步骤s4.1b计算每个三元组中anchor样本正样本负样本的不确定性
[0131]
计算正样本对anchor样本的可靠性和负样本对anchor样本的可靠性和负样本对anchor样本的可靠性
[0132]
本实施例采用正样本和anchor样本可信度的均值作为正样本对anchor样本的可靠性,即:
[0133][0134]
同理,
[0135]
s4.5b、计算可靠性加权的三重态损失:
[0136][0137]
其中表示与之间的相似度,表示与之间的相似度;本实施例中采用欧氏距离表示相似度;α》0,α为预设的距离常数,使anchor样本和负样本之间的距离更大,anchor和正样本之间的距离更小;从数学的角度分析,样本对的可信度越低(不确定性越高),相似性权重越小。因此对应于优化中的梯度就越小,即对优化的贡献越小。
[0138]
s4.6b、根据训练样本建立memory bank;
[0139]
基于记忆库(memory bank)的方法已广泛用于无监督表示学习,这有助于为一般任务引入对比损失,它是在训练开始之前存储训练集数据通过主干网络提取的特征表示,以利用样本和全局memory bank的样本之间的相似性更好的优化网络。本发明采用文献:wang x,zhang h,huang w,et al.cross-batch memory for embedding learning[j].2019.中的方法建立与维护memory bank;
[0140]
将目标域图像xi作为query样本,在memory bank中查找与xi具有相同伪标签的样本作为正样本,与xi具有不同伪标签的样本作为负样本;计算对比损失:
[0141][0142]
其中和分别为memory bank中xi正样本和负样本的个数,表示第j个负样本与xi的相似度,表示第j个负样本对xi的可靠性,表示第h个正样本与xi的相似度,表示第h个正样本对xi的可靠性;此处相似度同样采用欧氏距离,可靠性的计算与步骤s4.4b中的相同,根据式(9)和(11)进行计算。由于样本对的可信度越低,梯度越小,对样本对优化的贡献越小。因此,使用可靠性加权的对比损失通过给与query样本最相似的负样本和与query样本最不相似的正样本更大的权重来获得对网络参数最优的更新。
[0143]
综上,本实施例中迭代训练优化的目标为最小化损失函数l
total
:
[0144]
l
total
=l
class
+l
triplet
+λ
ct
l
contrastive
+λ
eff
l
effect
ꢀꢀꢀ
(15)
[0145]
其中λ
eff
为预设的源域注意力度量损失系数,注意力度量损失l
effect
的计算同实施例1;
[0146]
本实施例在market-1501和dukemtmc-reid数据集上进行了对比实验,结果如表2所示。
[0147]
表2:在market-1501、dukemtmc-reid数据集上测试结果
mutual-training for person re-identification[c]//european conference on computer vision.springer,cham,2020.中的方法进行识别;unrn是采用文献:zheng k,lan c,zeng w,et al.exploiting sample uncertainty for domain adaptive person re-identification[j].2020.中的方法进行识别;glt是采用文献:zheng k,liu w,he l,et al.group-aware label transfer for domain adaptive person re-identification[j].2021.中的方法进行识别;ours是本实施例中的方法进行识别。
[0150]
由表2可以看出,本发明的rank-1、rank-5、rank-10和map指标均在一定程度上优于当时先进方法,在两个数据集上进行的跨域实验也证明了本方法在各种数据集上均具有良好的泛化性能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1