一种结合特征增强与模板更新的目标跟踪方法
:
1.本发明属于计算机视觉技术领域,涉及一种结合特征增强与模板更新的目标跟踪方法。
背景技术:
2.在计算机视觉领域中,视觉目标跟踪是该领域的研究方向之一,具体的是指对视频序列中的目标进行持续定位的过程,其主要任务在于通过在视频的第一帧标记出要跟踪的目标,并在后续的每一帧中定位出目标,以生成目标的运动轨迹,并在每一时刻提供完整的目标区域。在智能交通,人机交互,智能医疗以及无人机等方面都有广泛的应用。虽然目前的跟踪器的性能有所提高,但在一些光照强度变化,背景杂乱,严重遮挡的情况下,给目标跟踪方法的设计带来了诸多的挑战。而现有的一些研究成果在特征表征方面和适应跟踪中的目标外观变化仍然存在一定的局限性,因此有必要进一步探索高效的实施方案以改善目标跟踪的性能。
3.近几年,由于深度学习在各个方向的应用,基于深度学习的目标跟踪算法逐渐占领整个跟踪领域。深度学习领域中的卷积神经网络具有很强的表征能力,可以自动的提取目标特征,在特征精度方面有了很大的提高。
4.为了提高跟踪算法的性能,有研究方法利用孪生网络的匹配能力,将目标跟踪任务看成图像的相似度匹配问题,通过孪生网络上下分支,分别提取模板图像和搜索图像的特征,然后用滑动窗口的形式在搜索图像中确定目标的位置,速度达到了实时性。由于直接利用两个特征之间的相似度,判断目标的位置,精度有待提高,有研究方法将跟踪算法看成分类和回归两阶段任务,使用rpn提升网络特征的表征能力,同时缓解跟踪中多尺度的问题。前期使用孪生网络进行跟踪的算法,使用的网络层次较浅,不能够提取到深层的语义特征,因此,有研究方法利用深层的残差卷积网络,提高网络提取深层语义特征的能力,进而提升跟踪算法的鲁棒性。有些研究者发现注意力机制可以有效的抑制背景干扰和目标变化对跟踪器带来的影响,为了提高特征的表征能力,同时又不引入过多的难以控制的超参数,研究者将注意力机制引入到跟踪领域中。其中,有研究方法通过构建语义分支和外观分支的双分支网络,同时在语义分支中加入通道注意力机制,将特征图加权输出,两分支相互补充,提高特征的表征能力。同时,也有研究方法引入空间和通道注意力,将光流信息和深度特征输入到注意力模块中,得到更精确的运动目标信息,经过互相关性操作得出个跟踪目标的位置。有研究者考虑多种注意力机制,结合残差注意力机制、通道注意力机制和一般注意力机制,将其加入到网络模型,开发了一种非常有效、高效的基于深度学习的跟踪器。由于自注意力可以建立特征之间的长期依赖关系,有研究者利用transformer开发了特征融合网络,该注意力方法可以自适应地关注边缘和相似目标等有用信息,使跟踪器获得更好的分类和回归结果。
5.目前一些经典的跟踪算法侧重于单独考虑普通的注意力机制和自注意力机制,普通的注意力机制,比如通道注意力、空间注意力等,只是在通道或者空间上进行特征处理。
而自注意力机制可以建立特征之间的内部关系,将二者进行结合,可以进行互补,提高特征的表征能力。同时,一些经典的跟踪算法在跟踪过程中仅依靠视频的初始帧特征,不能够很好的适应目标外观变化带来的影响。因此如何获取更具表征能力的特征,同时考虑目标外观变化带来的影响,提高跟踪器的鲁棒性具有重要意义。
技术实现要素:
6.本发明的目的在于提供一种结合特征增强与模板更新的目标跟踪方法,其克服了现有技术中存在的目标跟踪任务中特征表征能力不足,同时不能很好地适应目标外观变化对跟踪算法造成的性能低的问题。
7.为实现上述目的,本发明采用的技术方案为:
8.一种结合特征增强与模板更新的目标跟踪方法,其特征在于:该方法实现包括用于提取特征的孪生网络、进行特征增强的特征增强网络、常规分类和回归网络以及模板更新模块;该方法包括以下步骤:
9.(1)利用resnet50提取深层语义特征,将深层语义特征与浅层特征经过通道注意力后进行特征融合,将融合的特征分别经过两个transformer编码器构建特征内部之间的长期依赖关系;
10.(2)使用transformer解码器中的交叉注意力将两个分支的编码器输出的特征进行信息交互,构成特征增强网络,突出有用的全局上下文信息和通道信息,抑制相似性目标的干扰;
11.(3)引入在线模板更新模块,缓解目标外观变化的影响,提高跟踪器的鲁棒性。
12.步骤(1)中,采用resnet50网络作为基准网络进行特征提取,网络的输入是从训练数据集的视频帧中选取一对图像,即模板图像z(128x128x3)和待搜索图像x(256x256x3),将其送入到孪生网络架构,通过基准网络得到所需要的特征。
13.步骤(2)中,特征增强网络包括基于通道注意力机制的特征融合部分和transformer长期依赖建立部分;其中,
14.1)基于通道注意力机制的特征融合包括以下步骤:
15.将模板图像和待搜索图像经过resnet50卷积神经网络,取出最后两阶段的特征,分别经过相同的通道注意力机制,计算得到一组权重系数,并对原特征图在通道上进行校正,得到加强后的注意力特征图;然后,再对各个阶段的特征进行深层和浅层信息的融合;
16.模板图像和待搜索图像经过resnet50的前四个阶段,分别取出layer2、layer3两阶段的特征向量f
l2_u
、f
l3_u
、f
l2_d
、f
l3_d
,将两阶段特征向量进行通道上的关键空间信息增强,利用特征融合模块对两个特征进行融合,得到上下分支的特征向量fu,fd;
17.2)transformer长期依赖建立部分包括以下步骤:
18.自注意力根据嵌入的特征向量得到自注意力中的query(q),key(k),value(v),根据q和k计算两者的相似性或者关联性,选择求两个向量点积进行相似度的计算,将得到的分值进行归一化处理,然后根据归一化的权重系数对v进行加权求和;自注意力的计算可以定义为公式(10):
[0019][0020]
其中,q,k,v均是来自特征的线性变换;
[0021]
在上下两个分支分别使用编码器学习模板图像特征和待搜索图像特征的内部关系,使用不含自注意力机制的解码器将编码器学习到的两分支图像特征进行信息交互,得到显著性特征;
[0022]
采用单头自注意力机制,内部运算表示为:
[0023][0024]
其中,分别表示q,k,v的权重矩阵向量,自注意力中取q,k,v相同;
[0025]
上下分支编码器接收通道增强特征向量fu和fd,在接收特征之前需要先将特征进行维度上的转换,转换成编码器所需要的特征向量和通过公式(10)对输入的模板图像特征进行自注意力的计算,同时在每个特征的位置上加入位置编码;
[0026][0027][0028]
其中,pz是位置编码,output
eu
和output
ed
表示上下分支编码器的输出;利用解码器对编码器两分支的输出进行特征之间的信息交互,得到最终通过特征增强网络用于分类和回归的优质特征向量;
[0029][0030]
其中,output
eu_k
+pk,output
eu_v
是编码器分支的k值和v值,在交叉注意力模块中进行信息交互,f
out
是经过解码器将上下分支特征进行信息交互后最终的输出,用于后续的定位跟
[0031]
步骤(3)中,在跟踪过程中,目标消失或者被遮挡时,不宜对模板进行更新,此时需要对得到的模板进行判断,避免更新导致的跟踪效果变差;在分类分支的位置增加一个目标置信度分数评判,分类分支有1024个向量,每个向量长度为2,分别代表前景和背景得分,目标置信度分数评判最大前景得分取出,与设置的阈值进行比较,如果得分超出所设定的阈值α(》0.7),将其图像替换初始帧的位置。
[0032]
步骤1)基于通道注意力机制的特征融合中,利用特征融合模块对两个特征进行融合,得到上下分支的特征向量fu,fd,具体包括以下步骤:
[0033]
首先对输入的f
l2_u
、f
l3_u
、f
l2_d
、f
l3_d
特征图经过通道注意力机制,上下分支特征通过通道注意力的具体过程定义为公式(4)和(5):
[0034][0035]
[0036]
其中,s
lk_u
、s
lk_d
表示全局信息,h,w表示特征图的高和宽,表示全局信息,h,w表示特征图的高和宽,表示上下分支两阶段的特征向量,k表示layer2、layer3的下标;对全局平均池化后得到的结果进行全连接操作,得到c/r维的向量,然后经过一次relu激活函数,再通过一个全连接层将c/r维的向量变回c维向量,再进行sigmoid激活函数,得到最终的权重矩阵,过程定义如公式(6)和(7):
[0037]
su=σ(w2δ(w1s
lk_u
))
ꢀꢀ
(6)
[0038]
sd=σ(w2δ(w1s
lk_d
))
ꢀꢀ
(7)
[0039]
其中,w1,w2是两个全连接层的权重,δ和σ分别表示relu和sigmoid激活函数,su、sd是最终得到的权重矩阵;最后将学习的各个通道的激活值与原特征图进行相乘:
[0040]fuk
=su*f
lk_u
k=2,3
ꢀꢀ
(8)
[0041]fdk
=sd*f
lk_d
k=2,3
ꢀꢀ
(9)
[0042]fuk
、f
dk
是结合权重系数的通道特征图,su、sd是通道注意力权重,f
lk_u
、f
lk_d
为原始的layer2、layer3的特征图;得到两阶段的通道特征图后,将二者进行特征融合,得到上下分支最具表征能力的特征图fu、fd。
[0043]
与现有技术相比,本发明具有的优点和效果如下:
[0044]
本发明给出的一种结合特征增强与模板更新的跟踪方法,通过强大的transformer建立特征之间的内部关系与通过通道注意力机制的浅层和深层特征的融合,使得网络可以有效的选择关键信息,提高特征的表征能力。引入动态模板更新,可以自适应在目标发生外观变化时进行模板替换,同时可以丰富视频帧之间的时间上下文信息,提高跟踪器的鲁棒性。提出的跟踪算法在跟踪精确度、成功率上都有所提高。该方法对解决相关问题具有很强的参考价值。
附图说明:
[0045]
图1为本发明方法实现原理框图;
[0046]
图2为深层特征与浅层特征融合过程图;
[0047]
图3为transformer原理结构图;
[0048]
图4为基于分类分支的模板更新方法图;
[0049]
图5跟踪算法在otb100上的精度图和成功率图;
[0050]
图6为跟踪算法在lasot数据集上的精度图和成功率图。
具体实施方式:
[0051]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用于解释本发明,并不用于限定本发明。
[0052]
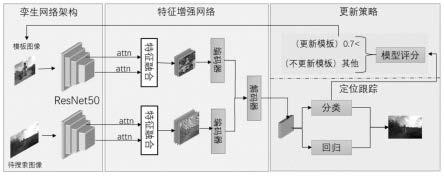
本发明为一种结合特征增强与模板更新的目标跟踪方法,主要用于解决目标跟踪任务中特征表征能力不足,同时不能很好地适应目标外观变化对跟踪算法造成的性能低的问题,方法具体的实现原理如图1所示。
[0053]
从图1可以看出,该方法实现包括四个部分,用于提取特征的孪生网络、进行特征
增强的特征增强网络、常规分类和回归网络、模板更新策略。利用resnet50提取深层语义特征,将深层语义特征与浅层特征经过通道注意力(attn)后进行特征融合,将融合的特征分别经过两个transformer编码器构建特征内部之间的长期依赖关系,使用transformer解码器中的交叉注意力将两个分支编码器输出的特征进行信息交互,构成特征增强网络,突出有用的全局上下文信息和通道信息,抑制相似性目标的干扰,提高了特征的表征能力。同时,引入了一个实时的模板更新策略,缓解目标外观变化的影响,提高跟踪器的鲁棒性。各模块实现细节描述如下:
[0054]
孪生网络架构:
[0055]
采用resnet50网络作为基准网络进行特征提取,相比于原始的alexnet网络,该基准网络可以提取更深层次的语义信息,提高对目标的判断和解释能力。网络的输入是从训练数据集的视频帧中选取一对图像,即模板图像z(128x128x3)和待搜索图像x(256x256x3),将其送入到孪生网络架构,通过基准网络得到所需要的特征。
[0056]
特征增强过程:
[0057]
为了获取具有更强表征能力的特征图,构建一个特征增强网络,在跟踪过程中可以保留更多显著性目标特征,加强特征之间的关联性。特征增强网络包括基于通道注意力机制的特征融合部分和transformer长期依赖建立部分。
[0058]
1)基于通道注意力机制的特征融合。
[0059]
将模板图像和待搜索图像经过resnet50卷积神经网络,取出最后两阶段的特征,分别经过相同的通道注意力机制,计算得到一组权重系数,并对原特征图在通道上进行校正,得到加强后的注意力特征图。然后,再对各个阶段的特征进行深层和浅层信息的融合。浅层特征与深层特征融合的过程如图2所示:
[0060]
模板图像和待搜索图像经过resnet50的前四个阶段,分别取出layer2、layer3两阶段的特征向量f
l2_u
、f
l3_u
、f
l2_d
、f
l3_d
,将两阶段特征向量进行通道上的关键空间信息增强,利用特征融合模块对两个特征进行融合,得到上下分支的特征向量fu,fd。具体过程如下,首先对输入的f
l2_u
、f
l3_u
、f
l2_d
、f
l3_d
特征图经过通道注意力机制。上下分支特征通过通道注意力的具体过程定义为公式(4)和(5):
[0061][0062][0063]
其中,s
lk_u
、s
lk_d
表示全局信息,h,w表示特征图的高和宽,表示全局信息,h,w表示特征图的高和宽,表示上下分支两阶段的特征向量,k表示layer2、layer3的下标。对全局平均池化后得到的结果进行全连接操作,得到c/r维的向量,然后经过一次relu激活函数,再通过一个全连接层将c/r维的向量变回c维向量,再进行sigmoid激活函数,得到最终的权重矩阵。过程定义如公式(6)和(7):
[0064]
su=σ(w2δ(w1s
lk_u
))
ꢀꢀ
(6)
[0065]
sd=σ(w2δ(w1s
lk_d
))
ꢀꢀ
(7)
[0066]
其中,w1,w2是两个全连接层的权重,δ和σ分别表示relu和sigmoid激活函数,su、sd是最终得到的权重矩阵。最后将学习的各个通道的激活值与原特征图进行相乘:
[0067]fuk
=su*f
lk_u
k=2,3
ꢀꢀ
(8)
[0068]fdk
=sd*f
lk_d
k=2,3
ꢀꢀ
(9)
[0069]fuk
、f
dk
是结合权重系数的通道特征图,su、sd是通道注意力权重,f
lk_u
、f
lk_d
为原始的layer2、layer3的特征图。得到两阶段的通道特征图后,将二者进行特征融合,得到上下分支最具表征能力的特征图fu、fd。
[0070]
2)transformer长期依赖建立部分。
[0071]
自注意力根据嵌入的特征向量得到自注意力中的query(q),key(k),value(v),根据q和k计算两者的相似性或者关联性,本发明选择求两个向量点积进行相似度的计算,将得到的分值进行归一化处理,然后根据归一化的权重系数对v进行加权求和。自注意力的计算可以定义为公式(10):
[0072][0073]
其中,q,k,v均是来自特征的线性变换。
[0074]
在上下两个分支分别使用编码器学习模板图像特征和待搜索图像特征的内部关系,使用不含自注意力机制的解码器将编码器学习到的两分支图像特征进行信息交互,得到显著性特征。本发明transformer原理结构如图3所示:
[0075]
本文使用的是单头自注意力机制,内部运算可以表示为:
[0076][0077]
其中,分别表示q,k,v的权重矩阵向量,自注意力中取q,k,v相同。
[0078]
上下分支编码器接收通道增强特征向量fu和fd,在接收特征之前需要先将特征进行维度上的转换,转换成编码器所需要的特征向量和通过公式(10)对输入的模板图像特征进行自注意力的计算,同时在每个特征的位置上加入位置编码。
[0079][0080][0081]
其中,pz是位置编码,output
eu
和output
ed
表示上下分支编码器的输出。利用解码器对编码器两分支的输出进行特征之间的信息交互,得到最终通过特征增强网络用于分类和回归的优质特征向量。
[0082][0083]
其中,output
eu_k
+pk,output
eu_v
是编码器分支的k值和v值,在交叉注意力模块中进行信息交互,f
out
是经过解码器将上下分支特征进行信息交互后最终的输出,用于后续的定位跟踪。
[0084]
模型更新方法设计:
[0085]
在跟踪过程中,目标消失或者被遮挡时,不宜对模板进行更新,此时需要对得到的模板进行判断,避免更新导致的跟踪效果变差。本发明在分类分支的位置增加一个目标置信度分数评判,分类分支有1024个向量,每个向量长度为2,分别代表前景和背景得分,目标
置信度分数评判最大前景得分取出,与设置的阈值进行比较,如果得分超出所设定的阈值α(》0.7),将其图像替换初始帧的位置。该方法可以充分利用跟踪过程的时间上下文信息,缓解目标外观变化的问题。基于分类分支的模板更新方法如图4。
[0086]
实施例:
[0087]
使用pytorch(1.5.0)深度学习框架,操作系统为ubuntu18.04,显卡为nvidiateslap100,计算机处理器为11th gen intel(r)core(tm)i5-11260h@2.60ghz。网络训练及优化过程中的主要参数设置如下:使用在imagenet上预训练的参数进行模型初始化。利用lasot、got-10k、coco数据集对整个网络进行离线训练,训练过程中,模板图像127x127、待搜索图像256x256,batch_size为64,使用adamw优化器进行优化。基准网络的学习率设置为10^(-5),其他模块的学习率设置为10^(-4),权重衰减和动量分别为1e-4和0.9,l1损失和l
giou
损失权重分别为5和2。
[0088]
为客观评价本发明方法的性能,在otb100和lasot两个基准数据集上分别与8个经典跟踪器(siamfc、siamrpn、cfnet、gradnet、srdcf、staple、dsst、meem)和10个经典跟踪器(siamban、siamrpn++、atom、trtr-offline[、siamfc、siammask、siamdw、vital、splt、meem)进行实验结果对比分析。并依据精确度和成功率评价指标进行评估。实验结果如图5和图6所示。
[0089]
由图5可以看出,提出的跟踪算法性能明显优于siamfc等其他几种算法。与siamfc相比,由于在siamfc的基础上增加特征增强网络和模板更新方法,得到的该方法在精度上提高10.4%,成功率上提高8.7%,表明该方法的有效性。siamrpn算法使用浅层的alexnet进行特征提取,对于深层语义特征提取能力不足,同时忽略了上下文信息,本发明提出的跟踪算法使用resnet50进行深层语义特征提取,加之提出的特征增强网络的使用,有效提高特征表征能力,该方法在精度和成功率上相比于siamrpn都有所提高。
[0090]
由图6可以看出,得益于提出的特征增强网络和模板更新策略的引入,提出的跟踪器在长时跟踪数据集lasot上取得了较好的性能,该跟踪算法相比于基础的siamfc网络,在精确度上提高18.5%,成功率上提高18.6%。siamban跟踪算法由于没有考虑特征之间的内部关系,仅仅使用初始帧作为模板,因此,在长时数据集lasot上效果并不是很突出。而本发明提出的特征增强网络不仅考虑到通道上的关键信息,同时使用自注意力机制建立特征之间的长期依赖关系,提高特征的关联性,模板更新策略能够有效的适应目标外观变化,因此,在长时数据集lasot上相比于siamban跟踪器性能略高。
[0091]
表1在lasot测试数据集上与trtr跟踪器的对比结果
[0092][0093]
在该方法未引入模板更新方法之前,仅采用提出的由通道注意力和transformer架构组成的特征增强网络,性能超出同样使用transformer架构的trtr-offline跟踪算法5.3%。由上述实验结果表明,将上下两个分支中,通过通道注意力融合的特征分别经过一个编码器,进行特征内部之间的关联之后,再经由解码器进行上下分支信息交互,相比于将上分支通过一个编码器然后输入到下分支的解码器过程,性能有所提高。
[0094]
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围,凡是
利用本发明的说明书及附图内容所做的等同结构变化,均应包含在发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1