一种结构化数据的建模方法、建模系统及管理方法与流程
本发明属于页岩气勘探开发领域,具体为一种结构化数据建模方法、建模系统及管理系统。
背景技术:
1、近些年,页岩气开采事业蓬勃发展,各大油气公司在页岩气勘探开发工作中,投入了大量的人力和资金,特别是在数据资源建设方面,页岩气相关数据的采集、存储、管理和应用,是油气公司信息化方面的重点关注内容。国内油气公司在常规油气数据库建设方面,已积累了二十几年的经验,也取得了重大成果,但数据库建设的方式方法,还停留在传统的模式:以如何管好数据为主要目标,技术上关注于符合第几范式、数据是否冗余等问题。近几年,it新技术、新思路层出不穷,油气公司管理和研究人员对数据的应用要求也是越来越高,如何在新环境下提升数据管理和应用水平,是油气公司面临的问题。
2、知识图谱(knowl edge graph)是近几年兴起的服务于知识管理与应用的新技术,它是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。
3、在石油勘探开发领域,知识图谱的应用,可以为研究提供切实的、有价值的参考。特别是以页岩气为代表的非常规油气开发,由于近些年刚刚起步,信息化建设还处于开始阶段,特别适用于知识图谱应用的落地。但是面临的问题就是,传统的数据库建模方式,完全不适合知识图谱的应用:其一,传统数据库建模,只重在如何管好数据,模型结果局限于“数据表”、“数据项”和“表间关系”,在后续建立应用时,还需要做大量的加工工作;其二,油气田勘探开发领域的数据库建设,重在对业务数据的精细化管理,90%以上的数据都是结构化基础数据,这样的数据只是知识加工的基础而非知识本身;传统数据库建模,只是对“数据”的建模,完全没有清晰体现“数据-信息-知识”的脉络,在后续知识加工时,工作量较大;其三,传统数据库建模,大多采用数据表的备注信息和数据项的备注信息作为标签,标签内容量少,而且无法自动形成体系化,完全不能支持智能检索和知识关联;其四,传统数据库建模,多采用一些商用的建模软件,这些软件侧重于模型的创建,而对模型的管理、特别是深层加工,功能较弱。因此,基于以上原因,应当采用面向知识图谱应用的页岩气结构化数据建模新方法和工具。
技术实现思路
1、本发明目的在于提供一种结构化数据建模方法、建模系统及管理系统,能够很好地处理了由数据到信息、再到知识的加工链路,并在建模过程中自动完成了知识标签体系的建设,自动完成了知识链路的构建,为后续知识搜索、智能推荐等应用的研发打下了坚实的数据模型基础。为实现上述目的,本发明提供如下技术方案:
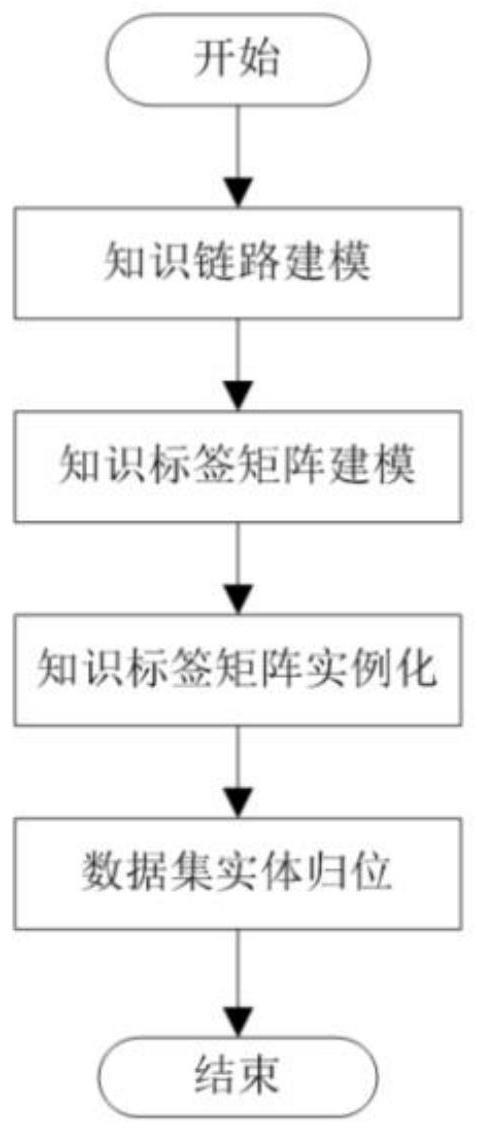
2、一种结构化数据建模方法,所述方法包括,
3、基于结构化数据,构建知识加工链路模型;
4、基于知识加工链路模型,构建知识标签矩阵模型;
5、对知识标签矩阵进行实例化判定;
6、将结构化数据与实例化判定后的知识标签矩阵,进行数据集实体归位,完成结构化数据建模。
7、优选的,所述结构化数据包括,基础实体数据、信息集实体和知识实体值,其中,
8、基础实体数据,包括全部业务的基础实体数据;
9、所述信息集实体是通过抽取融合多个基础实体数据形成的;
10、所述知识实体值是根据所述信息集实体获得的。
11、优选的,基于结构化数据,构建知识加工链路模型,具体为,
12、对基础实体数据进行身份标记,构建基础实体数据资源池;
13、根据基础实体数据的信息集实体,构建基础数据集实体数据资源池;
14、根据基础实体数据的知识实体,构建知识体系;
15、分析知识体系与数据集实体资源池、基础实体资源池的加工链条关系,构建知识加工链路模型。
16、优选的,所述基础实体数据的每一个数据有且只有一个基础实体进行指代,为单一性基础实体数据。
17、优选的,所述身份标记为基础实体数据的唯一身份标记。
18、优选的,所述根据基础实体数据的信息集实体,构建基础数据集实体数据资源池,包括,
19、按最细粒度业务内容划分数据集实体,且无业务交叉;
20、针对每个划分后的数据集实体,从基础实体数据资源池中选择组合元素,建立数据集实体与基础实体数据的一对多关系;
21、对与基础实体数据的一对多关系的数据集实体进行唯一身份标记,构建基础数据集实体数据资源池。
22、优选的,所述分析知识体系与数据集实体资源池、基础实体资源池的加工链条关系,构建知识加工链路模型,包括,
23、列举出计算知识体系中每个知识实体所用到的数据集实体资源池或基础实体资源池中的基础数据实体;
24、固化知识体系中每个知识实体与数据集实体资源池、基础实体资源池的映射关系,构建知识加工链路模型。
25、优选的,所述基于知识加工链路模型,构建知识标签矩阵模型,包括,根据知识加工链路模型所在的业务领域,建立多维度知识标签矩阵;
26、对所述知识标签矩阵的维度进行主标签定档;
27、对每个定档的知识主标签,逐级进行知识子标签划分,获取最小粒度知识子标签,完成知识标签矩阵模型构建。
28、优选的,所述多维度知识标签矩阵中,每个维度代表一个知识标签体系,每个数据集实体对应矩阵中的一个元素,元素的所有维度的知识标签就是数据集的标签,数据集和知识标签元素是“n对1”的关系。
29、优选的,所述多维度标签矩阵,包括,
30、任意两个维度没有业务交叉;每个维度的内容能够拆解或逐级细分;
31、所述每个维度内拆解后的内容,有明确、固定的业务逻辑关系。
32、优选的,所述最小粒度子标签满足从业务理解上不能够再细分,或满足后续知识应用建设需求即停止再细分。
33、优选的,所述对知识标签矩阵进行实例化判定,包括,
34、在每个知识标签的维度上,对知识标签定档层级,其中,下级档位实例元素知识标签值与上级档位的实例元素知识标签值相同;
35、所述实例元素为n个维度中基础实体数据的交叉点。
36、优选的,所述对知识标签定档层级,具体为,
37、n个标签维度任意两两组合,即把n维矩阵,降维成“1+2+…(n-1)”个2维矩阵;
38、针对每个2维矩阵中的实例元素判断一级档位标签组合对应实例是否属于同一层级,若属于同一层级,自动剔除掉一级档位标签组合中不属于同一层级项下属的全部二级档位标签组合实例,以此逐级判断、逐级自动剔除,标记完成每个2维矩阵里全部实例元素的层级;
39、完成所述2维矩阵的全部实例元素层级判别后,自动实现n个维度全部实例元素的层级评定。
40、优选的,所述将结构化数据与实例化判定后的知识标签矩阵,进行数据集实体归位,具体为,
41、选择一个数据集实体,在每个标签维度中选择其对应标签,进行数据集实体归位;其中,所述对应标签为最小粒度的标签,每个数据集实体在每个标签维度中,有且只有一个对应标签。
42、一种结构化数据建模系统,所述建模系统包括,
43、模型建立单元,用于基于结构化数据,构建知识加工链路模型;基于知识加工链路模型,构建知识标签矩阵模型;
44、判定单元,用于对知识标签矩阵进行实例化判定;
45、归位单元,将结构化数据与实例化判定后的知识标签矩阵进行数据集实体归位,完成结构化数据建模。
46、优选的,所述构建知识加工链路模型,具体为,
47、模型建立单元对基础实体数据进行身份标记,构建基础实体数据资源池;
48、模型建立单元根据基础实体数据的信息集实体,构建基础数据集实体数据资源池;
49、模型建立单元根据基础实体数据的知识实体,构建知识体系;
50、模型建立单元分析知识体系与数据集实体资源池、基础实体资源池的加工链条关系,构建知识加工链路模型。
51、优选的,所述基于知识加工链路模型,构建知识标签矩阵模型,包括,
52、模型建立单元根据知识加工链路模型所在的业务领域,建立多维度知识标签矩阵;
53、模型建立单元对所述知识标签矩阵的维度进行主标签定档;
54、模型建立单元对每个定档的知识主标签,逐级进行知识子标签划分,获取最小粒度知识子标签,完成知识标签矩阵模型构建。
55、优选的,所述对知识标签矩阵进行实例化判定,包括,
56、在每个知识标签的维度上,对知识标签定档层级,其中,下级档位实例元素知识标签值与上级档位的实例元素知识标签值相同。
57、优选的,所述将结构化数据与实例化判定后的知识标签矩阵,进行数据集实体归位,具体为,
58、选择一个数据集实体,在每个标签维度中选择一个对应标签,进行数据集实体归位,其中,所述对应标签为最小粒度的标签,每个数据集实体在每个标签维度中,有且只有一个对应标签。
59、一种结构化数据管理方法,所述管理方法对权利要求1-14所述的建模方法进行管理。
60、优选的,所述管理方法包括对知识链路模型的管理、对知识标签矩阵模型的管理、对知识标签矩阵实例化的管理、对数据集实体归位的管理。
61、优选的,所述对知识链路模型的管理包括,基础实体资源池的管理、数据集实体资源池的管理、知识体系管理和知识图谱关联算法服务,
62、基础实体资源池的管理,包括基于基础实体注册入池,维护基础实体命名与唯一身份标识;
63、对数据集实体资源池的管理包括,基于数据集实体注册入池,维护数据集实体命名与唯一身份标识,维护数据集实体与基础实体关联关系;
64、知识体系管理,包括维护知识命名与唯一身份标识,管理知识层级,管理知识与数据集实体+基础实体衍生关系;
65、知识图谱关联算法服务的管理,包括分析对基础实体、数据集实体和知识体系的结构化数据关系,构建知识加工链路模型的管理。
66、优选的,所述对知识标签矩阵模型的管理包括,
67、对知识标签维度的内容和关系进行管理,
68、根据知识标签维度的内容和关系,定档主标签和划分子标签。
69、优选的,所述对知识标签矩阵实例化管理,包括,
70、通过两两维度组合和任意维度内标签档位,标记n个维度全部实例元素;
71、判断的2维矩阵内同档标签组合是否属于同一层级,逐级判断、逐级自动剔除,标记每个2维矩阵里全部实例元素的层级值;
72、根据全部2维矩阵的标记全部实例元素的层级值,自动判断出n维矩阵每个元素的层级值并反馈。
73、优选的,所述对数据集实体归位的管理包括,
74、标记和存储每个数据集实体的n维标签;
75、自动检验并判断每个数据集实体的n维标签是否属于同一层级。
76、优选的,所述管理方法还包括智能搜索与推荐引擎,包括,
77、根据输入标签,自动在标签矩阵中定位完全符合或相似的标签,或直接推荐出标签组合对应的数据集实体;
78、所述自动推荐出的数据集实体,能够根据知识链路模型,自动下关联出相关的知识体系或数据基础实体。
79、本发明的技术效果和优点:
80、本发明的结构化数据建模方法、建模系统及管理系统,很好地处理了由数据到信息、再到知识的加工链路,并在建模过程中自动完成了知识标签体系的建设,自动完成了知识链路的构建,为后续知识搜索、智能推荐等应用的研发打下了坚实的数据模型基础。本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书、权利要求书以及附图中所指出的结构来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!