一种基于EfficientNet的水下目标识别方法
一种基于efficientnet的水下目标识别方法
技术领域
1.本发明属于模式识别技术领域,具体涉及一种水下目标识别方法。
背景技术:
2.目前传统水下目标分类识别方法通常是人工提取声纳回波中的若干特征并用于训练分类器完成目标识别。基于深度学习的识别方法可以直接从原始信号中自动提取特征、压缩特征向量并拟合目标映射,学习多层次的类别特征,从而避免手工提取过程中的特征损失,有效提高了泛化能力。基于深度学习的水下目标分类识别研究大多数都是使用被动声纳数据或合成孔径声纳(sas)数据,而基于主动声纳数据的识别研究则相对缺乏。同时由于水下环境复杂和机械降噪技术的快速发展使得水下目标隐蔽性越来越高,在实际中基于被动声纳的水下目标识别存在诸多困难,所以针对主动声纳数据的分类研究对于识别水下目标具有重要意义。
3.真实水下环境中声纳传感器会受到随机噪声、水体散射以及目标材料的声纳反射特性等影响,导致目标的主动声呐回波数据中混杂着强烈的混响和噪声干扰,同时水下目标的回波数据获取十分困难导致观测数据严重不足。
技术实现要素:
4.为了克服现有技术的不足,本发明提供了一种基于efficientnet的水下目标识别方法,首先对水下目标主动声呐回波信号使用mel谱特征提取方法得到每组回波信号的mel谱图像;将mel谱图像数据集分为训练集、验证集和测试集,并进行预处理;采用深度卷积生成对抗网络gan-s对训练集进行扩充;将扩充后的训练样本输入深度卷积神经网络convnet-s,进行有监督的训练,得到卷积神经网络的各层参数;将测试集中的mel谱图像输入训练后的深度卷积神经网络convnet-s中,得到每个mel谱图像的识别结果,统计各类目标的测试集识别准确率得到最终识别结果。本发明可以有效提取水下目标的类别特征,相较于其他现有算法显著提高了识别准确率。
5.本发明解决其技术问题所采用的技术方案包括如下步骤:
6.步骤1:对水下目标主动声呐回波信号使用mel谱特征提取方法得到每组回波信号的mel谱图像;
7.步骤2:由步骤1得到的mel谱图像构建水下目标的mel谱图像数据集,将mel谱图像数据集分为训练集、验证集和测试集,并进行预处理;
8.步骤3:采用深度卷积生成对抗网络gan-s对训练集进行扩充;
9.步骤4:将扩充后的训练样本输入深度卷积神经网络convnet-s,进行有监督的训练,得到卷积神经网络的各层参数;
10.步骤5:将测试集中的mel谱图像输入训练后的深度卷积神经网络convnet-s中,得到每个mel谱图像的识别结果,统计各类目标的测试集识别准确率得到最终识别结果。
11.进一步地,所述mel谱特征提取方法具体为:对水下目标主动声呐回波信号进行分
帧和预加重,然后对每一帧信号进行fft变换得到信号频谱,对信号频谱按照公式使用mel滤波器组进行滤波,计算每个滤波器的能量并取对数后得到mel谱图像,其中f表示信号频谱。
12.进一步地,所述构建水下目标的mel谱图像数据集的方法具体为:依次从每类目标的mel谱图像中,随机抽取15%作为测试集,剩余部分作为训练和验证集,所述预处理包括数据增强、尺寸缩放、裁剪、灰度化和归一化。
13.进一步地,所述深度卷积生成对抗网络gan-s包括用来捕获数据特点分布细节的生成模型g和来自真实训练数据x用来估计样本数据的判别模型d两部分;
14.设定生成模型g的任务是使得判别模型d判断错误的概率最大化,同时设定判别模型d的任务为辨别来自样本的数据和来自生成模型g的数据;定义生成模型g生成数据的分布为pg,输入噪声的先验变量为pz(z),使用g(z;θg)来代表数据空间的映射,其中g(
·
)是一个含有参数θg的多层感知机;再定义d(x;θd)也为一个多层感知机,用来输出一个单独的标签标量;d(x)代表x来自于真实数据分布p
data(x)
而不是pg的概率;通过训练判别模型d来最大化判别正确标签的概率,训练生成模型g来最小化log(1-d(g(z))),这样d和g的训练过程便是一个关于值函数v(g;d)的极小化极大的二人博弈问题:
[0015][0016]
其中:
[0017]
当训练d和g使d无法辨别g产生的数据和真实数据时,有pg(x)=p
data
(x),此时d(x)=0.5,即训练过程达到了最佳;
[0018]
生成模型g首先产生100维的随机噪声,通过全连接层映射为大小147456的矩阵,并将其转化为12
×
12
×
1024的特征图;使用分组对称填充方式,通过5个反卷积层transconv的反向卷积操作将特征图尺寸翻倍,再对特征图进行缩减,最终输出384
×
384
×
3的特征图;判别模型d则通过对生成器输出的384
×
384
×
3尺寸特征图进行卷积操作实现特征提取,最后由全连接层映射后输出;在生成器和判别器中均引入了批次标准化层bn以及激活函数对特征值进行归一化;判别器中加入dropout层抑制过拟合现象;
[0019]
进一步地,所述分组对称填充方式具体为:将1024通道的特征图按通道顺序分成数量均匀的256组,对每组的4通道特征图进行对称填充,经过填充得到的特征图尺寸为(channel,width,hight)=(1024,13,13),再通过卷积核大小为2
×
2,步长为2的反卷积操作对矩阵的长和宽进行扩充,将矩阵的维度进行缩减。
[0020]
进一步地,所述深度卷积神经网络convnet-s的基础卷积块是基于efficientnet网络模型搭建的,通过对基础卷积块和注意力机制模块进行堆叠和设计后,得到了本发明的分类模型,其结构如表1所示:
[0021]
表1深度卷积神经网络convnet-s结构表
[0022][0023]
进一步地,所述统计各类目标的测试集识别准确率的具体步骤是:统计tp:预测为正,实际为正;tn:预测为负,实际为负;fp:预测为正,实际为负;fn:预测为负,实际为正;得到上述tp、tn、fp和fn后,通过公式计算测试集识别准确率。
[0024]
本发明的有益效果如下:
[0025]
本发明方法识别精度高,泛化性强,可以针对存在混响和噪声干扰的水下环境,在样本数缺乏的情况下,通过深度卷积生成对抗网络有效扩充数据集,再经过分类模型提取多维度目标类别特征,从而精确识别水下目标。经验证,相比现有方法本发明在实测数据上取得了更好的效果。能够有效解决传统方法中的识别准确率低和模型泛化性差的问题,具有广泛的应用前景,可直接投入使用。
附图说明
[0026]
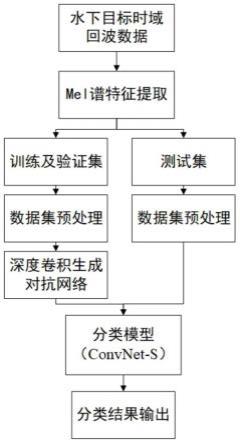
图1为本发明的流程图。
[0027]
图2(a)(b)(c)(d)依次为四类目标回波时域和mel谱图示例。
[0028]
图3本发明所提出的基础卷积块结构图。
[0029]
图4本发明的深度卷积生成对抗网络结构图。
[0030]
图5本发明的分组填充流程示意图。
[0031]
图6本发明的深度卷积网络模型(convnet-s)结构图。
[0032]
图7本发明实施例各算法在所建立的水池实验目标回波数据集上所得的实验结果,(a)为验证集损失随epoch迭代曲线,(b)为验证集准确率随epoch迭代曲线。
具体实施方式
[0033]
下面结合附图和实施例对本发明进一步说明。
[0034]
本发明针对回波数据缺乏的情况,利用深度卷积生成对抗扩充数据集,有效抑制过拟合现象。实际中水下目标的主动声呐回波中混杂着强烈的混响和噪声干扰,本发明可以有效提取水下目标的类别特征,相较于其他现有算法显著提高了识别准确率。
[0035]
如图1所示,一种基于efficientnet的水下目标识别方法,包括如下步骤:
[0036]
步骤1:对水下目标主动声呐回波信号使用mel谱特征提取方法得到每组回波信号的mel谱图像;
[0037]
步骤2:由步骤1得到的mel谱图像构建水下目标的mel谱图像数据集,将mel谱图像数据集分为训练集、验证集和测试集,并进行预处理;
[0038]
步骤3:采用深度卷积生成对抗网络gan-s对训练集进行扩充;
[0039]
步骤4:将扩充后的训练样本输入深度卷积神经网络convnet-s,进行有监督的训练,得到卷积神经网络的各层参数;
[0040]
步骤5:将测试集中的mel谱图像输入训练后的深度卷积神经网络convnet-s中,得到每个mel谱图像的识别结果,统计各类目标的测试集识别准确率得到最终识别结果。
[0041]
进一步地,所述mel谱特征提取方法具体为:对水下目标主动声呐回波信号进行分帧和预加重,然后对每一帧信号进行fft变换得到信号频谱,对信号频谱按照公式使用mel滤波器组进行滤波,计算每个滤波器的能量并取对数后得到mel谱图像,其中f表示信号频谱。
[0042]
进一步地,所述构建水下目标的mel谱图像数据集的方法具体为:依次从每类目标的mel谱图像中,随机抽取15%作为测试集,剩余部分作为训练和验证集,所述预处理包括数据增强、尺寸缩放、裁剪、灰度化和归一化。
[0043]
进一步地,所述深度卷积生成对抗网络gan-s包括用来捕获数据特点分布细节的生成模型g和来自真实训练数据x用来估计样本数据的判别模型d两部分;
[0044]
设定生成模型g的任务是使得判别模型d判断错误的概率最大化,同时设定判别模型d的任务为辨别来自样本的数据和来自生成模型g的数据;定义生成模型g生成数据的分布为pg,输入噪声的先验变量为pz(z),使用g(z;θg)来代表数据空间的映射,其中g(
·
)是一个含有参数θg的多层感知机;再定义d(x;θd)也为一个多层感知机,用来输出一个单独的标签标量;d(x)代表x来自于真实数据分布p
data(x)
而不是pg的概率;通过训练判别模型d来最大化判别正确标签的概率,训练生成模型g来最小化log(1-d(g(z))),这样d和g的训练过程便是一个关于值函数v(g;d)的极小化极大的二人博弈问题:
[0045][0046]
其中:
[0047]
当训练d和g使d无法辨别g产生的数据和真实数据时,有pg(x)=p
data
(x),此时d(x)=0.5,即训练过程达到了最佳;
[0048]
生成模型g首先产生100维的随机噪声,通过全连接层映射为大小147456的矩阵,并将其转化为12
×
12
×
1024的特征图;使用分组对称填充方式,通过5个反卷积层transconv的反向卷积操作将特征图尺寸翻倍,再对特征图进行缩减,最终输出384
×
384
×
3的特征图;判别模型d则通过对生成器输出的384
×
384
×
3尺寸特征图进行卷积操作实现特征提取,最后由全连接层映射后输出;在生成器和判别器中均引入了批次标准化层bn以及激活函数对特征值进行归一化;判别器中加入dropout层抑制过拟合现象;
[0049]
进一步地,所述分组对称填充方式具体为:将1024通道的特征图按通道顺序分成数量均匀的256组,对每组的4通道特征图进行对称填充,经过填充得到的特征图尺寸为(channel,width,hight)=(1024,13,13),再通过卷积核大小为2
×
2,步长为2的反卷积操作对矩阵的长和宽进行扩充,将矩阵的维度进行缩减。
[0050]
进一步地,所述深度卷积神经网络convnet-s的基础卷积块是基于efficientnet网络模型搭建的,通过对基础卷积块和注意力机制模块进行堆叠和设计后,得到了本发明的分类模型,其结构如表1所示;
[0051]
进一步地,所述统计各类目标的测试集识别准确率的具体步骤是:统计tp:预测为正,实际为正;tn:预测为负,实际为负;fp:预测为正,实际为负;fn:预测为负,实际为正;得到上述tp、tn、fp和fn后,通过公式计算测试集识别准确率。
[0052]
具体实施例:
[0053]
本实施例实验环境为amd ryzen 9 3990x cpu,3070gpu,内存为64g的台式机工作站,操作系统为windows10。软件工具为spyder(python 3.7),pytorch1.10.0,cuda 11.3。在特征提取过程中,在spyder上配置神经网络各层参数,配置后用python编写的网络训练、网络前向传播等文件编译成python可执行文件,实现网络训练。实验过程中使用cuda进行gpu并行加速运算。具体实施方法如下:
[0054]
1.水下目标的时域回波数据为消声水池实测回波数据集,在该数据集中总共有四类不同的水下目标模型。将四类目标依次下水,以目标正横面正对接收阵为起始0度旋转姿态,保持发射换能器和接收阵列位置不变,以目标纵轴为轴逆时针旋转目标,以1度为步长,使用接收阵列接收各个旋转角度时目标信号,可以得到每类目标的360个角度回波,四类目标共计1440个角度的回波信号。
[0055]
2.对上述所得实测目标主动声呐回波数据使用mel谱特征提取方法得到四类共计360*4张时频图像,具体操作细节如下:
[0056]
(1)首先进行对回波进行预加重从而补偿高频分量的损失,提升高频分量;通过将样本长度为2*104每个角度信号通过如下式的一阶fir高通数字滤波器,把信号分成较短的帧,在每帧中可将其看做稳态信号,可用处理稳态信号的方法来处理,为了使一帧与另一帧之间的参数能较平稳地过渡,在相邻两帧之间互相有部分重叠。
[0057]
h(z)=1-αz-1
[0058]
(2)加窗函数的目的是减少频域中的泄漏,将对每一帧音频信号乘以汉宁窗ω(n)。
[0059][0060]
(3)对加窗后的每一帧信号xi(m)进行点数(nfft)为512的fft变换得到其频谱,进而通过下计算出能量谱e(i,k),其中i表示分帧后的第i帧信号。
[0061]
e(i,k)=|x(i,k)|2=|fft[xi(m)]|2[0062]
(4)对功率谱用mel滤波器组进行滤波,计算每个滤波器里的能量取对数后得到mel频谱s(i,m)。如下式:
[0063][0064]
采用三角带通滤波器,频率响应为hm(k),滤波器个数m取值为26。如图2所示,为四类目标回波时域和mel谱图示例。
[0065]
3.为了与真实分类任务中的小样本情况保持一致,对每类目标随机选取136张mel谱图像,从而构建了基于实验数据mel谱图数据集。将所得到544张图像随机分为三个子集:训练集图像共380张(约占70%),验证集共82张(约占15%),其余图像作为测试集。
[0066]
4.对训练及验证样本集和测试样本集进行预处理,处理方式包括:(1)数据增强:对时频图子图进行锐化,然后亮度和饱和度进行调节;(2)尺寸缩放:利用opencv视觉库,对每张时频图子图进行线性插值,实现时频图子图的缩放,使得所有时频图子图大小一样,且长度与宽度相等;(3)裁剪:对缩放后的时频图子图进行裁剪,使其大小匹配卷积神经网络输入图片的大小;(4)灰度转换和归一化:使用torchvision库的transforms方法对样本集进行了灰度转换和归一化操作。
[0067]
5.本发明中提出的生成对抗网络是一种无监督的模型,该模型框架包括用来捕获数据特点分布细节的生成模型(generator model,g)和用来估计样本数据来自真实训练数据x而非来自生成模型的判别模型(discriminative model,d)两部分。设定生成模型g的任务是使得判别模型d的“判断错误”的概率最大化,同时设定判别模型d的任务为精准辨别来自样本的数据和来自生成模型g的数据。定义生成器生成数据的分布为pg,输入噪声的先验变量为pz(z),使用g(z;θg)来代表数据空间的映射,其中g是一个用含有参数θg的多层感知机。再定义d(x;θd)也为一个多层感知机,用来输出一个单独的标签标量。d(x)代表x来自于真实数据分布p
data
(x)而不是pg的概率。通过训练d来最大化判别正确标签的概率,训练g来最小化log(1-d(g(z))),这样d和g的训练过程便是一个关于值函数v(g;d)的极小化极大的二人博弈问题:
[0068][0069]
其中:
[0070]
当训练d和g使d无法辨别g产生的数据和真实数据时,有pg(x)=p
data
(x),此时d(x)=0.5,即训练过程达到了最佳。
[0071]
本发明设计的生成器g首先通过产生100维的随机噪声,通过全连接层映射为大小147456的矩阵,并将其转化为12
×
12
×
1024的矩阵;然后通过5个反卷积层(transconv)的反向卷积操作将特征图尺寸翻倍,最终输出384
×
384
×
3的生成图像。判别器g则通过对生成器输出的384
×
384
×
3尺寸特征图进行卷积操作(conv)实现特征提取,最后由全连接层映射后输出。在生成器和判别器中均引入了批次标准化层(bn)以及激活函数对特征值进行归一化,加速网络的收敛,提高网络的学习能力。此外在判别器中还加入了dropout层抑制过拟合现象,从而提升模型泛化能力。本发明搭建的生成对抗网络(gan-s)结构如图4。
[0072]
相较于常规的光学图像而言,mel谱图像纹理特征更加密集,且轮廓特征不明显,在生成器的反卷积过程中对感受野要求相较低,所以本发明提出使用了2*2(c2)偶数大小卷积核替代常规的3*3(c3)卷积核以达到缩减参数的目的。由卷积的特性可知,偶数大小的卷积核会造成不对称的接收场(rfs),在最终的特征图层中产生像素偏移,这种位置偏移在多重卷积叠加时累积,严重侵蚀空间信息。本发明提出使用一种分组对称填充方式(group-padding),将1024通道的特征图按通道顺序分成数量均匀的256组,对每组的4通道特征图进行对称填充,如图5所示。经过填充得到的特征图尺寸为(channel,width,hight)=(1024,13,13),再通过卷积核大小为2
×
2,步长为2的反卷积操作对矩阵的长和宽进行扩充,将矩阵的维度进行缩减,这个过程称为(c2-gp)。
[0073]
6.本发明基于在光学图像识别领域取得优秀效果的efficientnet搭建了基础卷
积块。该卷积块搭建过程如下:采用残差结构在常规主路旁增加一个恒等映射作为支路,以防止网络出现退化现象;通过使用多种尺寸卷积核的组合替换标准3*3卷积;使用hardswish激活函数替换常规的relu激活函数,以减少模型的参数数量和计算消耗;每次完成卷积操作后使用bn进行正则化;采用自注意力机制自适应地在通道维度上对特征进行加权以提高特征的表达能力;最后使用dropout策略,缓解模型过拟合并完成主路与支路相叠加后输出。本发明所搭建的基础卷积块结构如图3所示。
[0074]
图6为本发明的分类模型结构图。区块1由1个卷积层组成,卷积核的大小为3*3像素,卷积核个数为28个;区块2由1个基础卷积块组成,卷积核大小为7*7像素,步长为1个像素,卷积核个数为28个;区块3由1个基础卷积块组成,卷积核大小为5*5像素,步长为2个像素,卷积核个数为112个;区块4由3个基础卷积块组成,卷积核大小为3*3像素,步长为2个像素,每个卷积块中卷积核个数为448个;区块5由3个基础卷积块组成其中包含自注意力机制,卷积核大小为3*3像素,步长为2个像素,每个卷积块中卷积核个数为112个;区块6由4个基础卷积块组成其中包含自注意力机制卷积核的大小为3*3像素,步长为1个像素,每个卷积块中卷积核个数为128个;区块7由6个基础卷积块组成其中包含自注意力机制卷积核的大小为3*3像素,步长为1个像素,每个卷积块中卷积核个数为256个;区块8由卷积层、池化层和全连接层组成,卷积层中卷积核大小为1*1,采用均值池化的方式,全连接层输出维度为4。训练实验使用sgd优化算法,初始学习率设置为0.01,采用余弦学习率衰减的策略训练50epoch,训练批次大小为8。
[0075]
7.设置测试集输入的批次大小为16,将测试集中各类目标mel谱图图输入训练后的深度卷积神经网络(convnet-s)中,得到每个子图的识别结果,并绘制混淆矩阵,同时统计各类目标的测试集识别准确率得到最终识别结果。
[0076]
上述为本发明算法的全部操作细则。为了体现本发明算法的有效性,在数据集和训练环境均相同的情况下进行了如表2所示四组实验。实验1为单独使用本发明提出的convnet-s网络模型;实验2为使用gan-s对训练集进行扩充后,再使用convnet-s进行识别实验;实验3为单独使用现有的iafnet网络模型;实验4为单独使用现有的efficientnet-v2s网络模型。结合表2的实验结果可知,convnet-s和gan-s相结合后在测试集识别准确率达到了92.5%,远高于其他现有的同时相比单独使用convnet-s也取得了2.5%的有效提升。观察实验2的验证集损失及准确率曲线可知迭代30epoch后验证集准确率降低和验证集损失增加的现象不再出现,训练过程更加平稳,这说明经过gan-s扩充数据后网络的过拟合被有效抑制,实验结果表明通过gan-s对时频图数据集进行有规律的增广是一种有效且实用的方法。可以预见,继续对数据集进行扩充仍能在一定程度上减轻网络过拟合,但同样需要付出训练时间增加的代价。而对比实验1和实验3、4可知,本文提出的convnet-s分类模型在实验数据集上取得了显著高于其他算法的测试集识别准确率。由于卷积模型深度的下降convnet-s训练耗时显著低于efficientnet-v2s。iafnet的结构偏向轻量化,虽然训练速度快,但其测试集准确率仅为73.8%,远低于本文网络。
[0077]
表2各算法的测试集识别准确率和训练耗时
[0078][0079]
图7本发明实施例各算法在所建立的水池实验目标回波数据集上所得的实验结果,(a)为验证集损失随epoch迭代曲线,(b)为验证集准确率随epoch迭代曲线。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1