深度学习差分隐私算法保护效果的评估方法、系统及装置
1.本发明涉及差分隐私算法保护效果的评估领域,尤其是涉及一种深度学习差分隐私算法保护效果的评估方法、系统及装置。
背景技术:
2.在过去的几十年里,机器学习在学术界和工业界都取得了显着的突破,包括图像、视频、文本、语音、医疗保健等领域。其中基于神经网络的深度学习凭借其良好的性能和应用性迅速成为机器学习技术的热门分支。深度学习方法需要具有代表性的数据集来学习所需的模型,这些数据集中可能包含例如用户名、密码、对话文本、搜索历史和病史等敏感信息。而一些攻击研究表明,深度学习模型有泄露训练数据集敏感信息的风险。
3.差分隐私作为一种隐私保护定义在2006年由dwork提出,dwork对其隐私保护强度进行了严格的数学证明,一个差分隐私算法能够提供的隐私保护强度必须是满足差分定义的。由于能够通过数学证明对隐私保护水平进行保证,差分隐私方法在传统的数据发布、用户数据收集等需要保护数据隐私的领域已经得到广泛应用。
4.目前已经有很多研究者试图将差分隐私和深度学习相结合,通过差分隐私的方法来保护训练数据集中的数据隐私。为了实现隐私保护效果和实用性的平衡,松弛的差分隐私定义被提出并被应用于深度学习中的差分隐私算法设计。和原有的差分隐私定义相比,松弛的差分隐私定义的隐私保证不再像之前那样严格,即允许一定程度的隐私信息泄露。允许隐私泄露的定义方法虽然在一定程度上解决了实用性和隐私保护效果间的平衡问题,但是隐私损失的存在让算法所能提供的隐私保护效果变得更加难以解释和衡量。
技术实现要素:
5.本发明的目的在于提供一种深度学习差分隐私算法保护效果的评估方法、系统及装置,旨在解决差分隐私算法保护效果的评估。
6.本发明提供一种差分隐私算法保护效果的评估方法,包括:
7.1.一种面向深度学习中差分隐私算法保护效果的评估方法,其特征在于,包括,
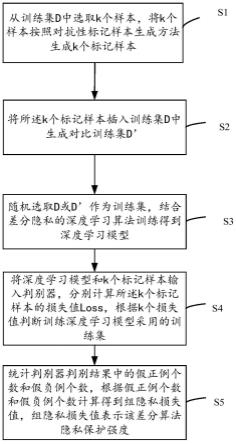
8.s1、从训练集d中选取k个样本,将k个样本按照对抗性标记样本生成方法生成k个标记样本;
9.s2、将所述k个标记样本插入训练集d中生成对比训练集d’;
10.s3、随机选取d或d’作为训练集,结合差分隐私的深度学习算法训练得到深度学习模型;
11.s4、将深度学习模型和k个标记样本输入判别器,分别计算所述k个标记样本的损失值loss,根据k个损失值判断训练深度学习模型采用的训练集;
12.s5、统计判别器判别结果中的假正例个数和假负例个数,根据假正例个数和假负例个数计算得到组隐私损失值,组隐私损失值表示该差分算法隐私保护强度。
13.本发明还提供一种面向深度学习中差分隐私算法保护效果的评估系统,包括,
14.选取生成模块:用于从训练集d中选取k个样本,将k个样本根据针对性标记样本生成方法生成k个标记样本;
15.生成模块:用于将所述k个标记样本插入训练集d中生成对比训练集d’;
16.训练模块:用于随机选取d或d’作为训练集,结合差分隐私的深度学习算法训练得到深度学习模型;
17.判断模块:用于将深度学习模型和k个标记样本输入判别器,分别计算所述k个标记样本的损失值loss,根据k个损失值判断训练深度学习模型采用的训练集;
18.计算模块:用于统计判别器判别结果中的假正例个数和假负例个数,根据假正例个数和假负例个数计算得到组隐私损失值,组隐私损失值表示该差分算法隐私保护强度。
19.本发明实施例还提供一种面向深度学习中差分隐私算法保护效果的评估装置,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现上述方法的步骤。
20.本发明实施例还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有信息传递的实现程序,所述程序被处理器执行时实现上述方法的步骤。
21.采用本发明实施例,通过对一组训练样本的隐私损失进行计算,得到组隐私损失值。将组隐私损失值作为评估指标,克服了现有方案使用单一样本的隐私损失值作为评估指标造成的评估结果具有特殊性的问题,实现了评估结果能够代表整个训练集的隐私保护效果分布。
22.上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
23.为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
24.图1是本发明实施例的面向深度学习中差分隐私算法保护效果的评估方法的流程图;
25.图2是本发明实施例的面向深度学习中差分隐私算法保护效果的评估方法的框架示意图;
26.图3是本发明实施例的面向深度学习中差分隐私算法保护效果的评估系统的示意图;
27.图4是本发明实施例的面向深度学习中差分隐私算法保护效果的评估装置的示意图。
具体实施方式
28.下面将结合实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技
术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
29.方法实施例
30.根据本发明实施例,提供了一种面向深度学习中差分隐私算法保护效果的评估方法,图1是本发明实施例的面向深度学习中差分隐私算法保护效果的评估方法的流程图,如图1所示,具体包括:
31.s1、从训练集d中选取k个样本,将k个样本按照对抗性标记样本生成方法生成k个标记样本;
32.s1具体包括:
33.s11、从训练集d中选取一个样本,计算所述一个样本在分类模型上的最近扰乱类;
34.s12、根据最近扰乱类计算扰动向量;
35.s13、将所述一个样本中添加扰动向量,得到一个标记样本;
36.s14、重复s11到s13得到k个标记样本。
37.s2、将所述k个标记样本插入训练集d中生成对比训练集d’;
38.s3、随机选取d或d’作为训练集,结合差分隐私的深度学习算法训练得到深度学习模型;
39.s4、将深度学习模型和k个标记样本输入判别器,分别计算所述k个标记样本的损失值loss,根据k个损失值判断训练深度学习模型采用的训练集;
40.s4具体包括:将深度学习模型和k个标记样本输入判别器,使用交叉熵分别计算所述k个标记样本的损失值loss,根据k个损失值判断训练深度学习模型采用的训练集。
41.s5、统计判别器判别结果中的假正例个数和假负例个数,根据假正例个数和假负例个数计算得到组隐私损失值,组隐私损失值表示该差分算法隐私保护强度。
42.s5具体包括:
43.统计判别器判别结果中的假正例个数和假负例个数,根据假正例个数和假负例个数计算得到组隐私损失值,组隐私损失值表示该差分算法隐私保护强度,所述组隐私损失值表示如下:
44.其中,fp表示假正例个数,fn表示假负例个数,δ表示差分隐私算法隐私保护效果松弛程度。
45.专利设计了一种面向深度学习中差分隐私算法保护效果的评估方法,可以得到更具有可信度的评估结果,并且该评估结果可以体现整个训练集上的隐私分布。
46.其中,评估结果的可信度是指评估方案量化得到的差分隐私算法的隐私保护强度和理论值的接近程度。由于差分隐私算法具有严格的数学定义,可以根据数学公式得到一个差分隐私算法的理论隐私保护强度值。而根据评估方案由实验得到的隐私保护强度值越接近这个理论值,也就代表评估结果的可信度越高,即越具有参考价值。
47.整个训练集上的隐私分布是指分析差分隐私算法施加在不同训练样本上的隐私保护强度。虽然在设计差分隐私算法时分配到每个训练样本上的隐私保护强度是相同的,但是在实际应用中,由于训练样本的数据复杂度和特征不同,每个样本得到的隐私保护强
度是不同的,也就是说训练集上的隐私分布是不同的。现有的评估方案使用单个样本的隐私损失作为评估指标,得到的评估结果具有特殊性,无法体现训练集上的隐私分布。
48.本发明所提框架的基本流程如下:
49.图2是本发明实施例的面向深度学习中差分隐私算法保护效果的评估方法的框架示意图;
50.101,从训练集中选取k个样本(xi,l(xi)),通过针对性标记样本生成方法生成k个标记样本
51.102,将这k个标记样本插入训练集d中生成对比训练集d’。
52.103,随机选取d或d’作为训练集。
53.104,由差分隐私的深度学习算法训练得到深度学习模型f
θ
。
54.105,将模型f
θ
和标记样本输入判别器,分别计算这k个标记样本的损失值loss,然后综合k个损失值判断模型所用的训练数据集。
55.106,统计得到判别器判别结果的假正例fp和假负例fn,根据fp和fn计算得到组隐私损失值。组隐私损失值即代表该差分算法隐私保护强度。
56.具有针对性的标记样本生成方法(101)的具体步骤如下:
57.1011,选取一个样本(xi,l(xi)),并在我们构造的训练集上对该样本进行分析,计算该样本在分类模型上的最近扰乱类计算最近扰乱类的公式如下:
[0058][0059]fk
(x0)和代表的是模型函数;wk和代表的是对应模型的权重参数。
[0060]
1012,根据最近扰乱类计算需要向该样本添加的扰动向量γ*(x0)。计算扰动向量的公式如下:
[0061][0062]
是模型函数,代表的是对应模型的权重参数。
[0063]
1013,向选取的样本((x0,l(x0)))中添加扰动向量γ*(x0),得到标记样本
[0064]
标记样本损失值(105)的具体计算方法如下:
[0065]
1051,使用交叉熵(此处的损失值指标是可选的,不限于交叉熵这一种评估指标,可根据情况选取别的指标作为损失值)作为标记样本的损失值loss。计算公式如下:
[0066]
[0067]
其中是模型对样本x0的预测类,l(x0)是样本x0的真实类。
[0068]
组隐私损失量化指标(106)的具体计算方法如下:
[0069]
1061,统计得到判别器判别结果的假正例fp和假负例fn。然后根据fp和fn计算得到组隐私损失值ε
group
。计算公式如下:
[0070][0071]
其中,δ由pr[m(x)∈s]≤exp(ε)pr[m(x
′
)∈s]+δ得到,是一个人为设定的值,代表了隐私保护的松弛程度;
[0072]
m(.)表示深度学习模型,x和x'表示模型的不同输入,m(x)表示模型的输出。
[0073]
m(x)∈s表示模型的输出符合数据分布s,即s代表一种数据分布。
[0074]
pr[m(x)∈s]表示模型的输出符合数据分布s的概率大小,即pr(.)表示一个概率函数。
[0075]
ε是差分隐私算法的隐私预算,是一个实值参数,它的大小代表了pr[m(x)∈s]和pr[m(x')∈s]的接近程度。exp(ε)越小,代表这两个值越接近。
[0076]
δ的大小代表了一个概率,也就是公式pr[m(x)∈s]≤exp(ε)pr[m(x
′
)∈s]的不等关系有δ的概率不被满足。
[0077]
本发明设计了一种新的差分隐私算法保护效果评估指标。该指标通过对一组训练样本的隐私损失进行计算,得到组隐私损失值。将组隐私损失值作为评估指标,克服了现有方案使用单一样本的隐私损失值作为评估指标造成的评估结果具有特殊性的问题,实现了评估结果能够代表整个训练集的隐私保护效果分布。
[0078]
本发明设计了一种有针对性的标记样本生成方法。现有方案使用的是随机选择的标记样本生成方法,和现有方案相比,本方案通过分析样本的最近扰乱类生成具有针对性的标记样本,有效地实现了具有更高判别准确率的判别器。克服了使用随机样本造成的判别器准确率不高的问题,实现了提高隐私评估结果的可信度。
[0079]
本发明引入了一种新的差分隐私算法保护强度评估指标,即组隐私损失。现有方案使用的差分隐私算法保护强度评估指标是单个样本的隐私损失,和现有的方案相比,本方案通过将组隐私损失作为差分隐私算法隐私保护强度的评估指表,有效地实现了对训练集隐私保护分布的分析。
[0080]
在通过深度学习模型分析某种流行病的场景下,需要使用患者的就诊记录作为训练样本组成训练集。而攻击者可能根据训练得到的模型推测出训练集数据中患者的敏感信息,比如根据模型推测出某个患者的年龄信息,因此需要在模型训练过程中添加差分算法来保护训练集数据敏感信息,在这种场景下,提供训练样本的患者关心自己提供的训练样本受到了多大强度的隐私保护。
[0081]
作为训练数据的使用方,医院可以使用该差分隐私算法保护效果的评估方法对自己的差分隐私深度学习模型进行评估,将量化得到的隐私保护强度反馈给患者,也就是训练数据的提供者。
[0082]
发明的有益效果
[0083]
1)更加可信的评估结果:通过分析样本在模型上的最近扰乱类,在样本上有目的
性的添加扰动生成标记样本,有效地提高了判别器的判别准确率,从而提高了评估结果的可信度。
[0084]
2)能够实现对整个训练集上隐私保护效果分布的分析:将组隐私损失作为隐私保护强度的量化指标,通过分析一组标记样本的组隐私损失,有效地实现了对整个训练集上隐私保护效果分布的分析。
[0085]
系统实施例
[0086]
根据本发明实施例,提供了一种面向深度学习中差分隐私算法保护效果的评估系统,图3是本发明实施例的面向深度学习中差分隐私算法保护效果的评估系统的示意图,如图3所示,具体包括:
[0087]
选取生成模块310:用于从训练集d中选取k个样本,将k个样本根据针对性标记样本生成方法生成k个标记样本;
[0088]
选取生成模块310具体用于:
[0089]
从训练集d中选取一个样本,计算所述一个样本在分类模型上的最近扰乱类;根据最近扰乱类计算扰动向量;将所述一个样本中添加扰动向量,得到一个标记样本;重复得到k个标记样本。
[0090]
生成模块320:用于将所述k个标记样本插入训练集d中生成对比训练集d’;
[0091]
训练模块330:用于随机选取d或d’作为训练集,结合差分隐私的深度学习算法训练得到深度学习模型;
[0092]
判断模块340:用于将深度学习模型和k个标记样本输入判别器,分别计算所述k个标记样本的损失值loss,根据k个损失值判断训练深度学习模型采用的训练集;
[0093]
判断模块340具体用于:将深度学习模型和k个标记样本输入判别器,使用交叉熵分别计算所述k个标记样本的损失值loss,根据k个损失值判断训练深度学习模型采用的训练集。
[0094]
计算模块350:用于统计判别器判别结果中的假正例个数和假负例个数,根据假正例个数和假负例个数计算得到组隐私损失值,组隐私损失值表示该差分算法隐私保护强度。
[0095]
计算模块350具体用于:
[0096]
统计判别器判别结果中的假正例个数和假负例个数,根据假正例个数和假负例个数计算得到组隐私损失值,组隐私损失值表示该差分算法隐私保护强度,所述组隐私损失值表示如下:
[0097]
其中,fp表示假正例个数,fn表示假负例个数,δ表示差分隐私算法隐私保护效果松弛程度。
[0098]
本发明实施例是与上述方法实施例对应的系统实施例,各个模块的具体操作可以参照方法实施例的描述进行理解,在此不再赘述。
[0099]
装置实施例一
[0100]
本发明实施例提供一种面向深度学习中差分隐私算法保护效果的评估装置,如图4所示,包括:存储器40、处理器42及存储在存储器40上并可在处理器42上运行的计算机程
序,计算机程序被处理器执行时实现上述方法实施例中的步骤。
[0101]
装置实施例二
[0102]
本发明实施例提供一种计算机可读存储介质,计算机可读存储介质上存储有信息传输的实现程序,程序被处理器42执行时实现上述方法实施例中的步骤。
[0103]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换本发明各实施例技术方案,并不使相应技术方案的本质脱离本方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1