一种预测矿区地下水位的方法
1.本发明涉地下水科学技术领域,更具体的涉及一种预测矿区地下水位的方法。
背景技术:
2.华北型煤田是中国重要的产煤区,煤层底部下伏着巨厚的岩溶含水层,其具有高承压性。高压水头为矿井底板突水提供了强大的动力来源,随着上组煤层资源的逐渐枯竭,大部分矿井转入下组煤层开采,采区底板受高承压水的突水威胁日益突出,底板水害事件时有发生。因此,模拟并预测矿区岩溶水位对矿井水害预警、底板突水防治具有十分重要的意义。
3.当前,基于物理背景的数值模拟软件(如modflow、feflow、gms)是模拟地下水位的主要工具,但其需要大量的水文地质参数且后期维护成本巨大,受制于数据可用性和模型内部对复杂水文过程的简化致使实现准确模拟难度较大。更为关键的是与非采矿区不同,采煤扰动下矿区岩层结构和水文地质条件持续变化,基于物理背景模型无法表达矿区岩层结构、水文地质参数及边界条件的动态变化,而且存在输入成本高,后期不易维护的问题。
技术实现要素:
4.发明目的是本发明的目的在于提供了一种输入成本低、预测精度高、后期易维护的预测方法,能够精准的预测矿区地下水位。
5.本发明的耦合偏互信息与机器学习预测矿区地下水位的方法,包括:
6.收集矿区气象和采煤生产数据并构建输入变量库;
7.使用偏互信息算法pmi对输入变量库进行特征变量筛选;
8.使用stl算法对被筛选中的特征变量与地下水位时间序列进行去趋势;
9.利用去趋势的时间序列间的自相关和互相关性确定narx模型的输入、反馈延迟参数,构建机器学习模型narx;
10.在机器学习模型narx预测中输入矿区气象和采煤生产数据,预测矿区地下水位。
11.优选地,收集矿区气象数据和采煤生产数据,包括:
12.月降水量、月半均气温、月最高气温、月最低气温、月累计蒸发量、月半均大气压、原煤产量、巷道掘进长度、采空区面积。
13.优选地,使用偏互信息算法pmi对输入变量库进行特征变量筛选,具体包括:
14.对于x中每个候选输入变量xi,分别计算其与地下水位y的mi值,表示为i
pmi
(xi,y);
15.选择使得i
pmi
(xi,y)值最大的xq,根据xq计算t
aci
值,并将xq从x候选变量库移入q库中;
16.候选输入变量x与输出变量y之间的mi及其t
aci
计算公式如(1)和(2):
[0017][0018]
[0019]
其中,pi,pj为x,y在各个取值下的概率分布,p
ij
为两个变量的联合分布概率,ri为根据已选变量拟合y的回归残差,n为样本数,p已选变量的个数;
[0020]
若x不为空集,计算x集中每一个候选变量与q集中变量的条件期望m
xi
(q),并由此计算ui=x
i-m
xi
(q),v=y-my(q)及i
pmi
(ui,v);
[0021]
选择使得i
pmi
(xi,y)值最大的xq,并计算此时的t
aci
值;
[0022]
如t
aci
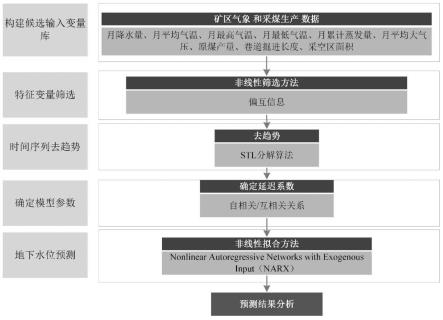
值减小,则将xq移入q集中,然后进入下一轮迭代,否则筛选结束;
[0023]
条件期望中的计算中选择高数高斯函数作为核密度估计函数,其表达式包括公式(3):
[0024][0025]
其中,x为待估计样本点,d为x的维数,c为x的协方差矩阵,det(c)为c的行列式,λ为窗口宽度,t为移动步长。
[0026]
优选地,使用stl算法对被筛选中的特征变量与地下水位时间序列进行去趋势,其表达式包括公式(4):
[0027]rt
=y
t-st
t
ꢀꢀꢀ
(4)
[0028]
其中,r
t
表示去趋势后的余项,y
t
表示观测序列,st
t
表示趋势项。
[0029]
优选地,利用去趋势的时间序列间的自相关和互相关性确定narx模型的输入、反馈延迟参数,包括:
[0030]
分别计算去趋势的地下水位的显著自相关阶数及去趋势的地下水位和去趋势的输入变量间的显著互相关阶数;
[0031]
其中,显著自相关阶数为narx模型中反馈入延迟系数,表达式包括公式(5);
[0032]
显著互相关阶数为narx模型中是输入延迟系数,表达式包括公式(6);
[0033][0034][0035]
其中,fd(max)表示去趋势后的地下水位显著自相关阶数,id(max)去趋势后的地下水位和去趋势好后的输入变量之间的显著互相关阶数。
[0036]
优选地,构建机器学习模型narx,具体包括:
[0037]
在narx模型中输入特征变量;
[0038]
将显著自相关和互相关阶数作为模型的输入和反馈延迟系数;
[0039]
划分数据集为训练集和测试集,在闭环状态下训练模型,在预测精度达到稳定收敛后,训练停止;
[0040]
将模型转为开环状态用于预测矿区地下水位并进行预测评价;
[0041]
其中,narx表达式包括公式(7):
[0042]
y(t)=f(y(t-1),y(t-2),
…
,y(t-ny),u(t-1),u(t-2),
…
,u(t-n
x
))
ꢀꢀꢀ
(7)
[0043]
其中,y(t)代表输出反馈信号,u(t)代表外部输入信号,f为非线性函数,n
x
为输入层延迟系数,ny代表输出层反馈延迟系数。
[0044]
本发明实施例提供一种预测矿区地下水位的方法,与现有技术相比,其有益效果如下:
[0045]
本发明突破了传统物理模型所需水文地质参数多、建模成本高、模型表达真实采动能力差及模拟结果不确定性高等问题,转而利用一些易获取的气象和矿区采煤生产数据,提出了一种基于非线性的特征变量筛选方法耦合强大的机器学习模型对矿区地下水位进行精准预测的方法。该发明具有输入成本低、预测精度高、模型易维护等优势。
附图说明
[0046]
图1为本发明实施例提供的一种预测矿区地下水位的方法流程图;
[0047]
图2为本发明实施例提供的一种预测矿区地下水位的方法narx训练模式,其中左侧为开环训练状态,右侧为闭环预测状态;
[0048]
图3为本发明实施例提供的一种预测矿区地下水位的方法中pmi-narx耦合模型在6口观察井中观测值与预测值波动曲线及观测值与预测值拟合优度,其中,左图为pmi-narx耦合模型观测值与预测值波动曲线,右图为观测值与预测值拟合优度。
具体实施方式
[0049]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0050]
参见图1,本发明实施例提供一种预测矿区地下水位的方法,该方法包括:
[0051]
收集矿区气象和采煤生产数据并构建输入变量库,本发明选用了矿区月累积降水量、月平均气温、月最低气温、月最高气温、月累积蒸发量、月平均气压、月采煤量、月巷道开拓长度、月采空区面积作为候选输入变量;
[0052]
使用偏互信息算法pmi对输入变量库进行特征变量筛选,pmi筛选的特征变量为降雨量和采煤量;
[0053]
使用stl算法对被筛选中的降雨量、采煤量及地下水位时间序列进行去趋势;
[0054]
利用去趋势后的地下水位的自相关、去趋势后的地下水位和降水量及采煤量之间的互相关确定narx模型的反馈、输入延迟参数;
[0055]
将pmi筛选出来的特征变量作为机器学习模型narx输入变量;
[0056]
将显著自相关与互相关阶数作为narx模型的反馈、输入延迟参数;
[0057]
利用机器学习模型narx输出量预测平朔矿区6口观察井的地下水位。
[0058]
下面结合图和具体实施例对本技术进一步说明:
[0059]
1、pmi算法流程
[0060]
sharma(2000)提出了基于偏互信息的输入变量选择算法,算法对输入与输出结构不做任何假设,采用条件期望剔除输入变量间的相关关系再计算输出变量与各输入变量mi值,从而有效地提高了变量筛选的准确性。mi值定量地表征了两个或多个变量间共享的信息量,mi的大小反应了两个变量的相关程度。显然,在x与y无关时,mi值应该为0;x与y的相关性越强,则mi值越大。候选输入变量x与输出变量y之间的mi计算公式如下:
[0061]
[0062]
其中pi,pj为x,y在各个取值下的概率分布,pij为两个变量的联合分布概率。
[0063]
由于一般情况下已知x和y的样本数据而未知其概率分布,因此,一般采用概率密度估计的方法替代,具体公式如下:
[0064][0065]
式中:xi和yi分别为x和y的第i个取值;f(xi),f(yi),f(xi,yi)分别为x和y样本点i的概率密度及联合概率密度。
[0066]
估计观测样本的概率密度分布及联合概率密度分布是计算互信息的核心过程之一。非参数估计是一种用于对分布形式尚不清楚时的概率密度估计方法,核密度估计是一种稳定、有效的非参数估计方法,已在mi计算中得到了广泛的使用,本文选取高斯函数作为核函数估计样本概率密度函数,公式如下:
[0067][0068]
式中:x为待估计样本点;d为x的维数;c为x的协方差矩阵;det(c)为c的行列式;λ为窗口宽度。本文采用sharma(2000)推荐的宽度:
[0069][0070]
对于存在多个变量的输入系统,设输入变量分别为x和z,预测变量为y,z为z中的元素,若变量x与变量z之间存在耦合关系,将使得x与y,z与y之间mi的计算出现偏差,因此使用条件期望mx(z)和my(z)剔除z后的x,y分别记为u,v,则有:
[0071][0072][0073]
u=x-m
x
(z)
[0074]
v=y-my(z)
[0075]
式中zi为为z中的第i个元素。
[0076]
x,y的pmi计算可有如下公式求出:
[0077]ipmi
(x,y)=i
pmi
(u,v)
[0078]
赤池信息量准则(aic)能够很好的平衡模型复杂度和数据拟合优良性,本文采用其作为筛选输入变量的判别条件。随着算法逐步迭代,taci值不断减小,当taci的值达到最小值时,整个筛选结束。taci公式如下:
[0079][0080]
式中:ri为根据已选变量拟合y的回归残差;n为样本数,p已选变量的个数。
[0081]
设候选变量库为x,x中含有i个随机变量x1,x2,
…
,xi,预测变量为y;最优输入变量库为q(初始值为空集);xq为每一轮迭代中ipmi值达到最大的输入变量。pmi筛选输入变
量流程如下:
[0082]
基于前人的建模经验、先验知识和数据可用性等确定候选输入变量库x;
[0083]
对于x中每个输入变量xi,分别计算其与y的mi值,表示为i
pmi
(xi,y);
[0084]
选择使得i
pmi
(xi,y)值最大的xq,根据xq计算t
aci
值,并将xq从x候选变量库移入q库中;
[0085]
若x不为空集,计算x集中每一个候选变量与q集中变量的条件期望m
xi
(q),并由此计算ui=x
i-m
xi
(q),v=y-my(q)及i
pmi
(ui,v);
[0086]
选择使得i
pmi
(xi,y)值最大的xq,并计算此时的t
aci
值;如t
aci
值减小,则将xq移入q集中,然后进入下一轮迭代,否则筛选结束。
[0087]
2、narx模型
[0088]
参见图2、narx网络是一种带有外部输入变量的动态循环神经网络,相比于静态、无反馈的前馈神经网络(如bp神经网络、多层感知机等),narx网络具有延迟单元(输入与输出延迟)和反馈结构,不仅考虑了外部输入变量(实时与延迟输入变量)对输出产生的影响,而且通过输出延迟单元将输出反馈也引入到网络结构中,使输出层能实时地将包含历史信息的输出数据反馈到输入层,参与下一次的迭代训练,从而使网络具有动态记忆能力且系统信息保留更加完整。因此,narx在解决非线性时间序列问题上具有强大的优势。同时,其收敛速度和泛化能力明显优于静态神经网。naxr网络有两种训练模式,分别为开环和闭环见图2。闭环模式下模型预测值将作为反馈输入直接参与下一时刻预测,常用于真实情景下的多步预测。而开环模式则下观测值将直接作为输出反馈,极大提高了模型的拟合精度,缩短了训练时间。在实际的建模中,常采用在开环模型下训练,然后将网络转为闭环,在闭环模型下完成多步预测。narx表达式如下:
[0089]
y(t)=f(y(t-1),y(t-2),
…
,y(t-ny),u(t-1),u(t-2),
…
,u(t-n
x
))
[0090]
式中y(t)输出反馈信号,u(t)代表外部输入信号,f为非线性函数,n
x
为输入层延迟系数,ny代表输出层反馈延迟系数。
[0091]
3、参见图3,为了评估耦合模型(pmi-narx)在预测矿区地下水位的有效性,本发明选取平朔矿区6口岩溶观察井进行长期预测模拟,其结果如下:
[0092]
各个观测井中pmi-narx耦合模型在预测集上r2、nash系数均突破0.9,一致性指数d均大于0.97,rsr最小值仅为0.260,虽部分观测井在某些时段有小幅度锯齿状波动,但在绝大部分时段预测曲线可以很好的跟真实水位曲线吻合(图3),尤其是在地下水位迅速变化时,pmi-narx均能够很好的捕捉其细节变化。以地下水位变幅最大的yg-11为例,pmi-narx模型可以很好的预测出2015年到2017年期间地下水位持续下降的过程。总体来说,耦合偏互信息和机器学习模型可以准确的预测矿区地下水位的变化。
[0093]
以上公开的仅为本发明的几个具体实施例,本领域的技术人员可以对本发明实施例进行各种改动和变型而不脱离本发明的精神和范围,但是,本发明实施例并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1