基于深度学习的关系型数据库基数估计方法
1.本发明属于数据库基数估计技术领域,具体是一种基于深度学习的关系型数据库基数估计方法,通过对关系型数据库的基数估计,从而帮助数据库查询优化器生成效率更高的执行计划。
背景技术:
2.基数估计是查询优化过程中最有影响力的任务之一,基数估计是指在数据库中执行sql(structured query language,结构化查询语言)语句之前,事先预估该sql语句执行后可能返回的结果行数。数据库查询优化器是以计划执行成本为依据,在不改变期望结果的情况下使得数据库引擎计划执行时间最短,进而在多个备选方案中选择最佳执行计划。而基数估计值是计算计划执行成本的重要参数,若基数估计值不准确,将影响计划执行成本的计算,可能会导致错误执行计划的选择,从而影响执行效率和系统性能。
3.为了估计基数值,大多数商业数据库管理系统(dbms)都依赖于直方图,虽然直方图构建速度快,存储成本低,但是当涉及到多列查询和多表连接查询时,往往需要独立性的假设,这种假设忽略了列与列以及表与表之间的相关性,而当工作负载涉及复杂的查询且表的列属性之间存在相关性时,将会导致严重的估计误差,并阻碍系统性能。面对直方图的一些问题,开始走入大众的视野。
4.基于深度学习的基数估计可以解决基于直方图基数估计存在的问题,但是目前基于深度学习的基数估计普遍存在这些问题:1)深度学习模型规模较大,为了提高精度需要大量训练数据,从而导致模型的训练时间较长;2)训练得到的模型只能针对静态数据库进行基数估计,若是数据库中的数据发生改变,则需要重新训练模型,重新训练的成本较高,若没有及时更新模型,将导致严重的基数估计误差;3)训练得到的基数估计器只能针对训练过程中用到的sql语句进行基数估计,对于陌生sql语句的基数估计,一般都会存在较大的估计误差。
技术实现要素:
5.针对现有技术的不足,本发明拟解决的技术问题是,提供一种基于深度学习的关系型数据库基数估计方法。
6.本发明解决所述技术问题采用的技术方案如下:
7.一种基于深度学习的关系型数据库基数估计方法,其特征在于,该方法包括以下步骤:
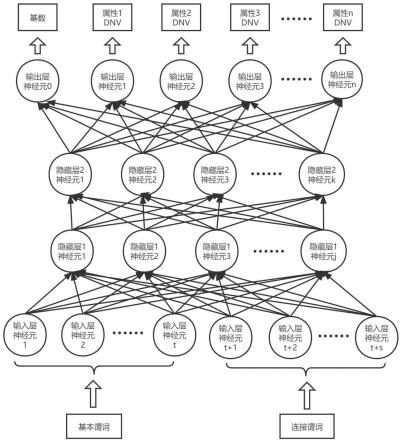
8.步骤1:获取关系型数据库的元数据和统计信息,包括各个数据库表的表名、属性以及数据库表之间的外键关联信息,根据外键关联信息构建数据库表之间的关系拓扑图;关系拓扑图的节点表示数据库表,节点间的连接表示两个数据库表之间存在外键关联;
9.步骤2:为关系拓扑图的各个节点和连通子图分别建立一个基数估计器,并确定各个基数估计器的网络结构;
10.节点和连通子图的基数估计器均由输入层、隐藏层和输出层构成;输入层包括两组输入层神经元,对应基本谓词和连接谓词两类输入信息,每组输入层神经元包含多个神经元,隐藏层包含多个隐藏层神经元,输出层包含1+n个输出层神经元,n为正整数,节点的基数估计器中n等于单个数据库表的属性数量,连通子图的基数估计器中n等于存在外键关联的多个数据库表包含的所有属性数量;输出层用于输出基数估计值和各属性不同值的数量;
11.步骤3:创建训练用的sql语句,在关系型数据库中执行sql语句并保存查询结果;将sql语句和查询结果作为训练数据,对基数估计器进行训练;
12.步骤4:利用训练后的基数估计器估计基数;
13.4.1)对用于查询的sql语句进行分析与拆分,若sql语句只涉及单张数据库表的查询或者连接查询所涉及的数据库表已存在相应的基数估计器,则执行步骤4.2),对基数进行直接估计;否则,将sql语句拆分为多个子查询再执行步骤4.2),对基数进行间接估计;拆分原则为:保证每个子查询所涉及的数据库表存在相应的基数估计器,且每个子查询中所涉及的数据库表应尽可能多;
14.4.2)利用sql语句进行基数估计;将sql语句或子查询进行向量化,得到输入向量,将输入向量输入到对应的训练后的基数估计器中,输出基数和各属性不同值的数量;若sql语句不需要拆分,则基数估计器输出基数估计值;否则,若sql语句被拆分为r个子查询s1,s2,
…
,sr,则记录每个子查询经基数估计器得到的基数估计值和原sql语句中连接谓词所涉及的各属性不同值的数量,并根据式(1)计算得到最终的基数估计值;
[0015][0016]
其中,c(s)表示基数估计值,c(sr)表示子查询sr经基数估计器得到的基数估计值,d(sr.k
r-1
)表示子查询sr经基数估计器得到的属性k
r-1
不同值的数量。
[0017]
进一步的,步骤3包括以下步骤:
[0018]
3.1)根据关系型数据库的元数据和外键关联信息创建若干条用于训练的sql语句,用于训练的sql语句需涵盖关系型数据库中的所有数据库表,并在关系型数据库中执行所有sql语句,然后保存包括基数和各属性不同值的数量在内的查询结果;
[0019]
3.2)将sql语句和查询得到的基数、各属性不同值的数量作为训练数据,对基数估计器进行训练;首先,将sql语句进行向量化处理,得到输入向量,输入向量分为基本谓词和连接谓词两部分,基本谓词是针对数据库表进行的谓词约束,连接谓词是指两个数据库表之间是否存在连接谓词约束;对所有sql语句向量化处理后,得到训练集;将训练集分为m份,每份训练集对应一个基数估计器,利用各份训练集对各自的基数估计器进行训练,得到m个训练后的基数估计器,m表示基数估计器数量。
[0020]
进一步的,当关系型数据库中的数据一旦发生变化或发生变化的数据量达到设定规模时,需要对相应的基数估计器进行更新,包括以下内容:
[0021]
记录变化数据所在的数据库表,并在关系拓扑图中对数据库表对应的节点进行标记;根据标记的节点,确定待更新的基数估计器,标记节点及标记节点所在的连通子图对应的基数估计器即为待更新的基数估计器;
[0022]
根据变化后的关系型数据库的元数据和和外键关联信息创建用于训练的sql语
句,对待更新的基数估计器进行训练,得到更新后的基数估计器;再用更新后的基数估计器替换原来的基数估计器,至此完成基数估计器的更新。
[0023]
与现有技术相比,本发明的有益效果是:
[0024]
1.该方法为关系拓扑图的各个节点和连通子图均建立一个基数估计器,将整个数据库对应的大规模的基数估计器分成了m个小规模的基数估计器,各个基数估计器利用各自的训练集进行并行训练,与现有的深度学习基数估计模型相比,有效缩短了训练时间。
[0025]
2.每个基数估计器只对应于数据库中的单个或部分数据库表,当数据库中的数据改变时,无需对所有基数估计器进行更新,只需要对变化数据涉及的数据库表和连通子图对应的基数估计器进行训练更新,即只需要对部分基数估计器进行训练更新,有效降低了数据库变化导致的更新成本。
[0026]
3.该方法能够对训练过程中未曾使用过的sql语句进行基数估计,即将sql语句拆分为多个子查询,通过基数估计器输出的各属性不同值的数量将拆分后的基数估计器进行关联,实现多表连接查询;与现有的基于深度学习的基数估计方法和数据库自带的多表连接的基数估计方法相比,本发明具有更高的估计精度。
附图说明
[0027]
图1为基数估计器的结构示意图;
[0028]
图2为关系拓扑图的示意图;
[0029]
图3为基数估计器的流程图;
[0030]
图4为变化数据的节点标记示意图;
[0031]
图5为实施例1中关系拓扑图的示意图;
[0032]
图6为实施例1中基数估计器net
person*order
的结构示意图。
具体实施方式
[0033]
下面结合附图和具体实施方式对本发明的技术方案进行详细描述,但并不以此限定本技术的保护范围。
[0034]
本发明为一种基于深度学习的关系型数据库基数估计方法(简称方法),包括以下步骤:
[0035]
步骤1:获取关系型数据库的元数据和统计信息,包括各个数据库表的表名、属性以及数据库表之间的外键关联信息,根据外键关联信息构建数据库表之间的关系拓扑图;关系拓扑图的节点表示数据库表,节点间的连接表示两个数据库表之间存在外键关联,在关系拓扑图中存在连接关系的节点构成的子图称为连通子图;
[0036]
例如,关系型数据库包含a、b、c、d四个数据库表,根据它们的外键关联信息得到图2所示的关系拓扑图,节点a分别与节点b、c连接,表明数据库表a分别与数据库表b和c之间存在外键关联,图2中一共包括g(a,b)、g(a,c)、g(a,b,c)三个连通子图;
[0037]
步骤2:为关系拓扑图的各个节点和连通子图分别建立一个基数估计器,一共建立m个基数估计器,并确定各个基数估计器的网络结构;
[0038]
图2中,将a、b、c、d四个节点的基数估计器分别记为neta、netb、netc、netd,将三个连通子图g(a,b)、g(a,c)、g(a,b,c)的基数估计器分别记为net
a*b
、net
a*c
、net
a*b*c
,故一种创
建7个基数估计器;
[0039]
节点和连通子图的基数估计器均由输入层、隐藏层和输出层构成;输入层包括两组输入层神经元,对应基本谓词和连接谓词两类输入信息,每组输入层神经元包含多个神经元,隐藏层包含多个隐藏层神经元,输出层包含1+n个输出层神经元,n为正整数,节点的基数估计器中n等于单个数据库表的属性数量,连通子图的基数估计器中n等于存在外键关联的多个数据库表包含的所有属性数量;输出层用于输出基数估计值和各属性不同值的数量(the number of distinct value,dnv);
[0040]
例如,若数据库表a含有3个属性,数据库表b含有4个属性,则节点a的基数估计器neta的输出层包含1+3=4个输出层神经元,节点b的基数估计器netb的输出层包含1+4=5个输出层神经元,连通子图g(a,b)的基数估计器net
a*b
的输出层包含1+3+4=8个输出层神经元;
[0041]
步骤3:创建训练用的sql语句,在关系型数据库中执行sql语句并保存查询结果;将sql语句和查询结果作为基数估计器的训练数据,对基数估计器进行训练;
[0042]
3.1)根据关系型数据库的元数据和外键关联信息创建若干条用于训练的sql语句,用于训练的sql语句需涵盖关系型数据库中的所有数据库表,并在关系型数据库中执行所有sql语句并保存包括基数(返回的行数)和各属性不同值的数量在内的查询结果,此查询结果即为sql语句在关系型数据库中查询得到的真实结果;
[0043]
3.2)将sql语句和查询得到的基数、各属性不同值的数量作为训练数据,对基数估计器进行训练;首先,将sql语句进行向量化处理,得到输入向量,输入向量分为基本谓词和连接谓词两部分,基本谓词是针对数据库表进行的谓词约束,连接谓词是指两个数据库表之间是否存在连接谓词约束;由于查询结果本身就是数字型,因此不需要向量化处理;对所有sql语句向量化处理后,得到训练集;将训练集分成m份,每份训练集对应一个基数估计器,将输入向量输入到基数估计器中,基数估计器输出基数估计值和各属性不同值的数量,利用各份训练集对各自的基数估计器进行训练,得到m个训练后的基数估计器;
[0044]
步骤4:利用训练后的基数估计器估计基数;
[0045]
4.1)将用于查询的sql语句进行分析与拆分,若sql语句只涉及单张数据库表的查询或者连接查询所涉及的数据库表已存在相应的基数估计器,则执行步骤4.2),对基数进行直接估计;否则,将sql语句拆分为多个子查询再执行步骤4.2),对基数进行间接估计;拆分原则为:需保证每个子查询所涉及的数据库表存在相应的基数估计器,且每个子查询中所涉及的数据库表应尽可能多;
[0046]
例如,某条sql语句sql
a*b*d
涉及a、b、d三张数据库表的连接查询,但是不存在对应的基数估计器net
a*b*d
,故需要将sql语句sql
a*b*d
进行拆分;sql语句sql
a*b*d
虽然可以拆分成子查询语句sa、sb和sd,但是因为节点a和b存在对应的基数估计器,故最终将sql语句sql
a*b*d
拆分为子查询s
a*b
和sd,分别对应基数估计器net
a*b
和netd,s
a*b
表示数据库表a和b的连接查询;
[0047]
4.2)利用sql语句进行基数估计;将sql语句或子查询进行向量化,得到输入向量,将输入向量输入到对应的训练后的基数估计器中,输出基数和各属性不同值的数量;若sql语句不需要拆分,则基数估计器输出基数估计值;否则,若sql语句被拆分为r个子查询s1,s2,
…
,sr,则记录每个子查询经基数估计器得到的基数估计值和原sql语句中连接谓词所涉
及的各属性不同值的数量,并根据式(1)计算得到最终的基数估计值;
[0048][0049]
其中,c(s)表示基数估计值,c(sr)表示子查询sr经基数估计器得到的基数估计值,d(sr.k
r-1
)表示子查询sr经基数估计器得到的属性k
r-1
不同值的数量。
[0050]
该方法还包括下述内容:
[0051]
当关系型数据库中的数据一旦发生变化或发生变化的数据量达到设定规模时,需要对相应的基数估计器进行更新,具体过程为:
[0052]
首先,记录变化数据所在的数据库表,并在关系拓扑图中对数据库表对应的节点进行标记;如图4所示,若数据库表a中的数据发生变化,则对关系拓扑图中的节点a进行标记;然后,根据标记的节点,确定待更新的基数估计器,标记节点及标记节点所在的连通子图对应的基数估计器即为待更新的基数估计器;如图4所示,节点a所在的连通子图为g(a,b)、g(a,c)、g(a,b,c),因此待更新的基数估计器包括neta、net
a*b
、net
a*c
和net
a*b*c
;
[0053]
最后,根据变化后的关系型数据库的元数据和和外键关联信息创建用于训练的sql语句,对待更新的基数估计器进行训练,得到更新后的基数估计器;再用更新后的基数估计器替换原来的基数估计器,至此完成基数估计器的更新。
[0054]
实施例1
[0055]
本实施例的基于深度学习的关系型数据库基数估计方法,包括以下步骤:
[0056]
步骤1:获取关系型数据库的元数据和统计信息,关系型数据库包括三张数据库表,表名分别为person、item和order,表1为各数据库表的属性,*表示该属性与其他数据库表的属性存在外键关联;根据外键关联信息构建数据库表之间的关系拓扑图,参见图5,关系拓扑图包含三个节点,节点person与order两个数据库表之间存在外键关联;
[0057]
表1各数据库表的属性
[0058]
personitemorderid*ididnamenamenumagepriceperson_id*
ꢀꢀ
item_id
[0059]
步骤2、根据关系拓扑图,为各个节点和连通子图分别建立一个基数估计器,记为net
person
、net
order
、net
item
和net
person*order
,确定各个基数估计器的网络结构;
[0060]
节点和连通子图的基数估计器均由输入层、隐藏层和输出层构成,输入层包括两组输入层神经元,分别用于输入基本谓词和连接谓词两类信息;每组输入层神经元包括多个神经元,隐藏层包括多个隐藏层神经元,输出层包含输出层包含1+n个输出层神经元,节点的基数估计器中n等于单个数据库表的属性数量,连通子图的基数估计器中n等于存在外键关联的多个数据库表包含的所有属性数量,故基数估计器net
person
的输出层包括4个输出层神经元,基数估计器net
order
的输出层包括5个输出层神经元,基数估计器net
item
的输出层包括4个输出层神经元,基数估计器net
person*order
的输出层包括8个输出层神经元;
[0061]
步骤3、创建训练用的sql语句,在关系型数据库中执行sql语句并保存查询结果;将sql语句和查询结果作为基数估计器的训练数据,对基数估计器进行训练;
[0062]
3.1)以训练基数估计器net
person*order
为例,创建训练用的sql语句,例如“select*from person,order where person,id=order.person_id and person.id>2 and order.num<5;”在关系型数据库中执行sql语句并保存包括基数(返回的行数)和各属性不同值的数量在内的查询结果,此查询结果即为sql语句在关系型数据库中查询得到的真实结果;
[0063]
3.2)将sql语句和查询得到的基数、各属性不同值的数量作为训练数据,对基数估计器net
person*order
进行训练;首先,将sql语句进行向量化处理得到输入向量,采用one-hot编码方式将sql语句的连接谓词数字化为[0 1],基本谓词数字化为[1 0 0 0 0 1 0 0 2],[0 1 0 0 0 0 1 1 5],输入向量为[0 1 1 1 0 0 0 1 1 1 7];将输入向量输入到基数估计器net
person*order
中,基数估计器net
person*order
输出基数估计值和各属性不同值的数量,对基数估计器net
person*order
进行训练,得到训练后的基数估计器net
person*order
;
[0064]
步骤4、利用训练后的基数估计器估计基数;
[0065]
将用于查询的sql语句进行分析与拆分,若sql语句只包含单张数据库表的查询或者连接查询所涉及的数据库表已存在相应的基数估计器,则直接将sql语句向量化,利用训练后的基数估计器进行基数估计;否则,将sql语句拆分为多个子查询,保证每个子查询所涉及的数据库表存在相应的基数估计器,且每个子查询中所涉及的数据库表应尽可能多;
[0066]
例如,现有以下三条用于查询的sql语句:
[0067]
①
select*from item where item.price>5.2;
[0068]
②
select*from person,order where person.id=order.person_id and person.person.id>2 and order.num>1;
[0069]
③
select*from person,order,item where person.id=order.person_id and person.id>2 and order.num>1 and order.item_id=item.id and item.price>5.2;
[0070]
sql语句
①
是涉及数据库表item的单表查询,只涉及数据库表item,已经存在基数估计器net
item
,故直接将sql语句
①
进行向量化,将向量化后的sql语句
①
输入到训练后的基数估计器net
item
中,直接估计基数,输出基数估计值和各属性不同值的数量;
[0071]
sql语句
②
是涉及数据库表person和order的连接查询,涉及数据库表person和order,已经存在基数估计器net
person*order
,故直接将sql语句
②
进行向量化得到输入向量,将输入向量输入到训练后的基数估计器net
person*order
中,直接估计基数,输出基数估计值和各属性不同值的数量;
[0072]
sql语句
③
涉及数据库表person、order和item的连接查询,不存在相应的基数估计器,因此需要sql语句
③
拆分为sql语句
①
和
②
两个子查询,然后将两个子查询进行向量化,将向量化后的sql语句
①
输入到训练后的基数估计器net
item
中,输出基数估计值和各属性不同值的数量;将向量化后的sql语句
②
输入到训练后的基数估计器net
person*order
中,输出基数估计值和各属性不同值的数量;sql语句
③
的连接谓词“order.item_id=item.id”,连接谓词所涉及的各属性不同值的数量分别为d(item.id)和d(order.item_id),d(item.id)表示sql语句
①
经基数估计器net
item
得到的属性不同值的数量,d(order.item_id)表示sql语句
②
经基数估计器net
person*order
得到的属性不同值的数量;
[0073]
[0074]
通过上式得到最终的基数估计值,实现基数间接估计。
[0075]
本发明未述及之处适用于现有技术。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1