商品大数据并行云平台推荐精准推送系统的制作方法
1.本技术涉及一种网购商品大数据云平台推送系统,特别涉及一种商品大数据并行云平台推荐精准推送系统,属于电商云计算推送技术领域。
背景技术:
2.随着互联网技术和信息技术的飞速发展,大数据时代已经来临。然而随着数据量的不断增大,从海量数据中获取对人们有价值的信息正在变的越来越困难,信息过载问题日趋严重。搜索引擎在一定程度上解决了这一问题。但当前的搜索引擎只能根据用户相对明确的需求进行搜索。但很多时候,人们并不能明确的描述自身的需求,甚至不知道如何描述自身需求,推荐系统根据用户历史行为,向用户主动推送用户想要的信息,并不需要用户描述自身需求。电商推荐系统是一种软件工具和技术方法,它可以向用户建议有用的商品。当前推荐系统的实际应用已随处可见,如淘宝、亚马逊、京东、优酷等都有自己的推荐系统,但推荐效果并不完全令人满意,推荐方法依然有很大的进步空间。此外随着数据量的急剧增大,推荐效率不高的问题日益凸显。能否将最新的大数据处理技术改进后运用到商品推荐系统中,成为解决网购推荐系统效率不高的一种可行方案。
3.推荐系统发展至今已有30多年的历史。早期推荐系统是基于内容的,通过提取商品自身特征信息进行推荐,随着推荐范围的不断扩大,这种推荐方法的局限性也逐渐显露出来,于是各种新的推荐方法相继出现,2007年acm推荐系统会议正式成立。
4.自从2006年netflix的电影推荐系统比赛举办以来,隐语义模型迅速成为热点,这当中比较有名的是基于svd的模型,但svd分解存在计算复杂,存储空间大的问题,无法用于实际的推荐系统,netflixprize大赛中funksvd方法的提出,才真正使基于svd模型的推荐方法能用于实际的推荐系统中。
5.目前推荐系统广泛运用于音视频网站、社交网络、新闻网站、个性化广告、电子商务等。像阿里、腾讯、优酷等互联网大公司也早将自己的推荐业务迁移到云平台上。
6.但是,现有技术的商品大数据电商平台推荐推送系统仍然存在若干问题和缺陷,本技术解决的问题和关键技术难点包括:
7.(1)当前电子商务领域信息过载问题越来越严峻,消费者面对海量的商品无法做出正确的选择,而电商平台又无法针对性个性化的进行商品推荐,导致推荐系统的商品推荐精准度较差,有时间甚至造成消费者的反感,而如果要提高推荐精度,需要综合大量的数据进行大量的计算,但受制于硬软件等各方面的限制,大数据复杂计算下的商品推荐性价比依旧不高,存在成本高、速度慢、准确度依然不够的缺陷,推荐系统依然无法有效解决商品信息过载问题,当前亟需一种高效的商品推荐系统作为联系用户与商品的桥梁,通过深入挖掘用户历史行为记录,获取用户偏好,根据用户偏好向用户推荐其可能感兴趣的商品,因此亟需提升推荐方法的推荐准确度,解决传统推荐系统面对海量数据工作效率低下的问题,将大数据处理技术改进后应用到推荐系统中,解决当前电商推荐系统工作效率低下的问题。
8.(2)现有技术的商品推荐系统存在推荐速度慢且准确率不高的问题,面对海量商品数据,现有技术缺少基于并行云的大数据处理框架,针对商品推荐方法涉及大量的迭代运算没有很好的处理方法,缺少在并行云平台上搭建商品推荐系统的方法,无法解决分离云推荐在评分稀疏时推荐精度不高的问题,缺少基于n个近似用户近似度加权的分离云推荐,在计算商品评分偏差时,无法分离无关用户的评分,缺少以用户近似度作为加权权重。缺少基于标签的近似度加权分离云推荐方法,未考虑评分数据的稀疏性,采用商品评分计算的近似度不够准确,特别是在数据稀疏时,预测评分缺少以商品近似度为权重进行加权。现有技术缺少云计算平台下推荐方法并行化方法,无法在并行云分布式大数据处理平台下实现推荐系统近似度并行化,在处理商品大数据时执行效率和精确度不高,实际利用价值不高。
9.(3)现有技术商品云平台推荐存在忽略用户近似的缺陷,缺少对近似用户按近似度大小排序,在计算商品评分偏差时,缺少按用户近似度加权,预测精度低。相邻用户的选择取决于用户之间的近似程度,不同用户对商品的偏好不同,导致评分差异较大,现有技术不能分离掉一些兴趣差别较大的用户,无法选取与目标用户近似度较高的用户评分预测,造成推荐准确率低,同时计算量还很大。另外,现有技术较多的是基于hadoop大数据处理云平台的推荐系统,但hadoop平台会将中间结果保存到外部存储器上,频繁的i/o访问,导致系统效率低下,并且hadoop的mapreduce只提供了map和reduce两个操作,编码难度较高。
10.(4)当评分数据集较为稀疏时,现有技术预测精度不高,当用户评分较少时,用户近似度的计算并不准确,某两个被认为近似度很高的用户,可能仅仅因为他们对某一商品有相同的评分,但其实他们并不近似,现有技术通过矩阵填充解决,但人工填充费时费力,自动填充误差较大,且矩阵填充完毕之后会导致计算量和存储量增大,对于像淘宝这样的大型电商平台,用户实际评分商品数相对于系统中的商品数来说微乎及微,采用矩阵填充成本太高,不切合实际,现有技术商品的近似度计算缺少通过商品内容计算,在评分较少时,通过内容计算的近似度更准确。缺少通过标签来表征其内容,利用标签的近似度替代商品内容的近似度。现有技术本身除去忽略用户的近似度之外,也忽略了商品的近似度,造成准确度低,计算量大,在大规模推广应用中存在很大的弊端。
技术实现要素:
11.针对当前电商图片信息过载问题越来越严峻,本技术的商品大数据并行云平台精准推送系统提供一种有效解决方案,针对分离推荐方法存在的缺陷,本技术提出了两种改进方法,基于n个近似用户的近似度加权分离云推荐方法和基于标签的近似度加权分离云推荐方法,同时,进一步改进云计算平台下推荐方法并行化,并对并行云平台下推荐方法并行化解析优化,使其在处理商品大数据时执行效率和精确度更高。本技术专门针对电商大数据设计得准确推荐系统,通过深入挖掘用户历史行为记录,获取用户偏好,根据用户偏好向用户推荐其可能感兴趣的商品,准确度和大数据处理速度都有大幅提升,该商品推荐系统可作为联系用户与商品的桥梁,缺少了大数据时代,传统推荐系统面对海量数据工作效率低下的问题,将大数据处理技术改进后应用到推荐系统中,特别是在当今电商平台数据量大的分布式环境中具有推荐精准、效率高的独特优势。
12.为实现以上技术效果,本技术所采用的技术方案如下:
13.商品大数据并行云平台推荐精准推送系统,基于并行云的大数据处理框架,针对商品推荐方法涉及大量的迭代运算,在并行云平台上搭建商品推荐系统,解决分离云推荐在评分稀疏时推荐精度不高的问题,分阶段提出两个层级的改进方法,分别是基于n个近似用户近似度加权的分离云推荐和基于标签的近似度加权分离云推荐;
14.第一,基于n个近似用户的近似度加权分离云推荐:基于与目标用户近似度低的用户不参与评分预测,否则导致评分预测值不准,另外与目标用户越近似的用户在计算商品评分偏差时,其比重也越大,对近似用户按近似度大小排序,取近似度较大的前n个近似用户参与评分预测,另外,在计算商品评分偏差时,按用户近似度加权,进一步提高预测精度;
15.第二,基于标签的近似度加权分离云推荐:基于在进行商品评分预测时,采用商品近似度加权比同时评分用户数加权更准确,另外对于稀疏的商品评分矩阵,通过商品标签计算的商品近似度比通过商品评分计算的商品近似度更可靠,在计算商品近似度时,考虑评分数据的稀疏性,采用商品标签计算的近似度替代采用商品评分计算的近似度,在数据稀疏时通过标签计算的商品近似度更加准确,在预测评分时以商品近似度为权重进行加权;
16.另外,进一步改进云计算平台下推荐方法并行化:在并行云分布式大数据处理平台下实现推荐系统近似度并行化,基于n个近似用户的近似度加权分离云推荐并行化,基于标签的近似度加权分离云推荐方法并行化,并对并行云平台下推荐方法并行化解析优化,使其在处理商品大数据时执行效率和精确度更高。
17.进一步的,基于n个近似用户的近似度加权分离云推荐:通过选取与目标用户近似度较大的前n个用户进行评分预测,且在计算商品评分偏差时,融入用户近似度,基于n个近似用户的近似度加权分离云推荐方法中商品j相对于商品i的评分偏差计算式为:
[0018][0019]
其中,r为整个评分数据,r
vi
和r
vj
分别表示用户v对商品i和商品j的评分,s
ji
(r)表示同时对商品i和商品j有评分,且与用户u近似的前n个用户的集合,sim(u,v)表示用户u和用户v的近似度,采用皮尔逊关联因子计算用户之间的近似度,|sim(u,v)|表示sim(u,v)的绝对值,分母用|sim(u,v)|代替sim(u,v)避免负的权重会导致预测评分超出允许的范围;
[0020]
利用式1计算商品j与商品i的评分偏差之后,采用分离云推荐方法中的式2计算用户u对商品j的预测值:
[0021][0022]
采用dev
ji
+r
ui
获得用户u对商品j的一个评分预测值,relevant(u,j)表示用户u评过分的商品中与商品j被同时评过分的商品集合,得到基于n个近似用户的近似度加权分离云推荐方法的预测结果;
[0023]
从输入、输出、实现流程三个方面对基于n个近似用户的近似度加权分离云推荐方法描述包括:
[0024]
(1)输入:用户-商品评分矩阵r(mxn),目标用户u,目标商品j,相邻用户个数n;
[0025]
(2)输出:用户u对商品j的pred(u,j)评分;
[0026]
(3)方法的详细实现步骤如下:
[0027]
第一步:获得目标用户u,已经评分商品的集合iu;
[0028]
第二步:获取对目标商品j和i中的商品都有评分的用户集合u
ji
;
[0029]
第三步:计算目标用户u与用户集合u
ji
中的每一个用户的皮尔逊关联因子,取皮尔逊关联因子较大的n个用户,构成集合s
ji
(r);
[0030]
第四步:利用式1计算目标商品j和iu中的每一个商品的评分偏差dev
ji
;
[0031]
第五步:由式2计算目标用户u对目标商品j的评分预测值pred(u,j)。
[0032]
进一步的,基于标签的近似度加权分离云推荐:首先通过商品标签计算商品近似度,在利用分离云推荐进行评分预测时融入商品近似度权重,通过临界值分离、权重校正来提高准确度;
[0033]
(1)临界值分离:通过设定标签近似度临界值,分离标签近似度小于等于近似度临界值的商品,定义sim(i,j)为计算的标签近似度,则标签近似度大于近似度临界值λ的集合,通过式3得出:
[0034]
s(uj)={uj|sim(i,j)>λ}
ꢀꢀ
式3
[0035]
(2)权重校正:采用商品标签近似度作为权重,加权的预测结果,通过式4计算得到:
[0036][0037]
其中,r
ui
是用户u对商品i评分,sim(i,j)表示商品i和商品j的标签近似度,采用近似因子计算商品之间的标签近似度,s(u,j)表示用户u评过分的商品中与商品j被同时评过分,且与商品j的近似度大于近似度临界值λ的商品集合,s(u,j)={i|i∈s(u),i≠j,|s
j,i
(r)|>0,sim(i,j)>λ},其中s(u)为表示用户u评过分的商品集合,|s
j,i
(r)|表示对商品i和商品j同时评分的用户数,dev
ji
表示商品j与商品i的平均评分偏差,dev
ji
+r
ui
为用户u通过对商品i的评分对商品j的评分的预测值;
[0038][0039]
其中r
ui
和r
uj
分别表示用户u对物品i和物品j的评分,r为整个评分数据矩阵,s
ji
(r)表示同时对物品i和物品j评分的用户集合,|s
ji
(r)|表示集合s
ji
(r)中用户的数量,采用式5计算商品j与商品i的平均偏差之后,采用式4计算用户u对商品j的预测值,即得到改进方法的预测结果。
[0040]
进一步的,基于标签的近似度加权分离云推荐方法:从输入、输出、实现流程三个方面对基于标签的近似度加权分离云推荐方法进行描述,包括:
[0041]
(1)输入:商品标签矩阵t(h
×
n),商品标签矩阵为预处理过的布尔型矩阵,用户-商品评分矩阵r(m
×
n),目标用户u,目标商品j,标签近似度临界值λ;
[0042]
(2)输出:目标用户u对目标商品j的预测评分pred(u,j);
[0043]
(3)方法的详细实现步骤如下:
[0044]
第1步:采用近似因子公式计算标签之间的近似度;
[0045]
第2步:从目标用户u已评分的商品中选取与目标商品j有共同评分用户的商品,再从中选择与目标商品j的标签近似度大于λ的商品,构成商品集s(u,j);
[0046]
第3步:利用式5计算目标商品j与s(u,j)中的每一个商品的平均偏差dev
ji
;
[0047]
第4步:由式4计算目标用户u对目标商品j的预测值pred(u,j)。
[0048]
进一步的,基于n个近似用户的近似度加权分离云推荐方法时间复杂度解析分为四步:
[0049]
步骤一:计算目标用户的近似用户集合:该步需要遍历所有用户,用户总数为m,计算目标用户与每一个用户的近似度,而计算用户间的近似度时,需要遍历用户有过评分的所有商品,用户平均有过评分的商品数为a*n,这一步的时间复杂度为θ(amn);
[0050]
步骤二:对目标用户近似用户集合排序:采用快速排序法,时间复杂度为θ(m log2m);
[0051]
步骤三:计算商品间评分偏差的平均值:用户平均评过分的商品为a*n个,计算目标用户评过分的每一个商品与目标商品的评分偏差时,需要遍历近似用户集合从中选择对这两个商品同时评过分的n个用户,假设平均需要遍历g次,这一步的时间复杂度为θ(agn);
[0052]
步骤四:预测目标商品评分:时间复杂度同分离云推荐最后一步,时间复杂度为θ(an),基于n个近似用户的近似度加权分离云推荐方法的时间复杂度为θ(amn+m log2m+agn)。
[0053]
进一步的,基于标签的近似度加权分离云推荐推荐方法时间复杂度解析分为四步:
[0054]
步骤1:计算同目标商品标签近似的商品集合:需要计算目标商品与所有商品,商品总数为n,的标签近似,而计算商品标签之间的近似度又需要遍历每一个标签,标签数为h,第一步时间复杂度为θ(hn);
[0055]
步骤2:计算目标用户评过分的商品中近似度大于近似度临界值λ的商品集合,用户平均评过分的商品为a*n个,需要对每一个商品进行比较,第二步的时间复杂为θ(an);
[0056]
步骤3:计算商品间评分偏差的平均值:假设目标用户评过分的商品中标签近似度大于近似度临界值入的商品的个数平均为d,则第三步的时间复杂度为θ(dm),其中d≤an;
[0057]
步骤4:预测目标商品评分:遍历d个标签近似的商品,时间复杂度为θ(d),基于标签的近似度加权分离云推荐推荐方法的时间复杂度为θ(hn+an+dm)。
[0058]
进一步的,云计算平台下近似度并行化:
[0059]
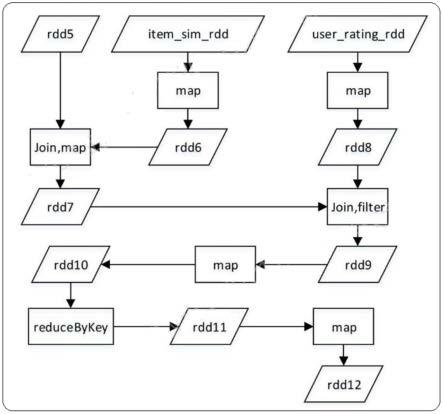
第i步,计算一对商品共同的标签数:首先采用map函数对标签矩阵进行转换,标签矩阵的形式为(item,label),转换后rdd1的形式为(label,item),采用join函数对rddl自身进行笛卡尔乘积,生成的rdd2的形式为(label,(item1,item2));接着采用map函数将rdd2转换为rdd3,rdd3的形式为((item1,item2),1),再利用reducebykey函数对商品1与商品2的共同标签数进行进行计算,生成rdd4,rdd4的形式为((item1,item2),count);紧接着利用filter函数,对rdd4进行不同的分离,生成的rdd5与rdd6,rdd5的形式与rdd4一致,是由rdd4的对角线元素组成的对角矩阵,rdd6的形式也与rdd4一致,由rdd4中去掉对角线元素以外的所有元素构成;最后对rdd5进行map转换生成rdd7,rdd7的形式为(item,count),
对rdd6进行map转换生成rdd8,rdd8的形式为(item1,(item2,count12));
[0060]
输入:商品标签矩阵:(item,label)
[0061]
输出:(item,count),(item1,(item2,count_12))
[0062]
其中,item_label_rdd为商品标签矩阵,rdd1的形式为(label,item),rdd2的形式为(label,(item1,item2)),rdd3的形式为((item1,item2),1),rdd4、rdd5、rdd6的形式为((item1,item2),count),rdd7的形式为(item,count),rdd8的形式为(item1,(item2,count12));
[0063]
第ii步,计算近似因子:首先利用join函数连接rdd8与rdd7,生成的rdd9形式为(item1,((item2,count_12),count_1)),对rdd9进行map转换生成rdd10,rdd10的形式为(item2,(item1,count_12,count_1));然后采用join函数连接rdd10和rdd7生成rdd11,rdd11的形式为(item2,((item1,count_12,count_l),count_2);最后根据近似度计算式,对rdd11进行map转换生成rdd12,rdd12的形式为((item1,item2),count_12*1.o/(count_1+count_2));
[0064]
输入:(item,count),(item1,(item2,count_12))
[0065]
输出:((item1,item2),sim)
[0066]
其中,rdd7、rdd8为上一步的输出,rdd9的形式为(item1,((item2,count_12),count_1)),rdd10的形式为(item2,(item1,count_12,count_1)),rdd11的形式为(item2,((item1,count_12,count_1),count_2),rdd12的形式为((item1,item2),count_12*1.0/(count_1+count_2)));
[0067]
第iii步,按照相似度高低进行排序,取近似度较大的n个近似相邻:首先采用filter函数过滤掉负相关和不相关的项,接着采用groupby函数,以商品为key进行分类,然后对每一类,按照近似度排序,取近似度较大的前n项,最后采用flatmap函数将结果转换为(item1,item2,sim)的形式;
[0068]
输入:((item1,item2),sim),n:相似邻居数
[0069]
输出:(item1,item2,sim)
[0070]
其中,rdd5为上一步输出,rdd6和rdd5形式一样,rdd7的形式为(item1,list《item2,sim》),rdd8的形式为(item1,item2,sim)。
[0071]
进一步的,基于n个近似用户的近似度加权分离云推荐并行化分为三步:
[0072]
第a步,计算n个近似用户近似度加权的商品偏差:首先用户评分表经过map函数转换为rddl,rdd1的形式为(user,(item,rating)),rdd1对自身进行join操作,生成的rdd形式为(user,((item1,rating1),(item2,rating2)),采用filter分离掉item1=-item2的情况,采用map函数转换成rdd2,rdd2的形式为(item1,(user,item2,rating2-rating1));接着再次对用户评分表采用map函数,将其转换为rdd3,rdd3的形式为(item,(user,rating)),将rdd3与rdd2进行join操作,生成的rdd4的形式为(item1,((user1,rating1),(user2,item2,rating_dev))),rating_dev就是rating2-ratingl所代表的项,对rdd4进行map转换,转换后的rdd5形式为((user1,user2),(item1,item2,rating1,rating_dev));紧接着对商品近似度矩阵进行map转换,转换后的rdd6的形式为((user1,user2),sim),将rdd5和rdd6进行join连接,生成的rdd形式为((user1,user2),(item1,item2,rating1,rating_dev),sim)),经map转换为rdd7,rdd7的形式为((item1,item2,user1),(rating_
dev*sim,sim,rating1));最后,对rdd7进行reducebykey操作,以(item1,item2,user1)为key,对评分差乘以近似度求和,对近似度求和,生成的rdd8的形式为((item1,item2,user1),(sum_rating_dev,sum_sim,rating1)),在对rdd8采用map函数生成最终结果rdd9,rdd9的形式为((user,item),(sum_rating_dev/sum_sim,rating1,1));
[0073]
第b步,预测用户对商品的评分:首先采用map函数对上一步的输出进行转换,转换后的rdd10的形式为((user,item),(ratingl+rating_dev,1));然后采用reducebykey,以(user,item)为key,分别对rating1+rating和1求和;最后通过map函数预测评分;
[0074]
输入:((user,item),(rating_dev,rating1,1))
[0075]
输出:((user,item),pre_rating)
[0076]
其中,rdd9为上一步的输出,rdd10的形式为((user,item),(rating1+rating_dev,1)),rdd11为输出;
[0077]
第c步,完成topn推荐列表。
[0078]
进一步的,基于标签的近似度加权分离云推荐方法并行化分为三步:
[0079]
第a步,计算商品偏差:首先用户评分表经过map转换函数,转换为rdd1,rdd1的形式为(user,(item,rating));接着利用join函数,与rdd1做笛卡尔乘积,生成rdd2,rdd2的形式为(user,((itemi,rating1).(item2,rating2));紧接着利用filter函数,分离掉item1==item2的情况,采用map函数转换为rdd3,rdd3的形式为((item1,item2),(rating2-rating1,1);然后利用reducebykey函数对评分偏差和共同评分人数进行计算,生成的rdd4的形式为((item1,item2),(sum_dev,n));最后按(2-7)式进行map转换,求出商品平均偏差;
[0080]
输入:(user,item,rating)
[0081]
输出:((item1,item2),rating_dev)
[0082]
其中,rdd1的形式为(user,(item,rating)),rdd2的形式为(user,((item1,rating1),(item2,rating2)),rdd3的形式为((item1,item2),(rating2-rating1,1),rdd4的形式为((item1,item2),(sum_dev,n)),rdd5的形式为((item1,item2),sum_dev/n);
[0083]
第b步,预测用户对商品的评分。首先商品近似度矩阵经过map函数转换后,生成的rdd6的形式为((item1,item2),sim),rdd6与rdd5通过join函数进行笛卡尔乘积,生成的rdd形式为((item1,item2),(sim,rating_dev)),经map转换后rdd7的形式(item1,(item2,sim,rating_dev));接着用户评分表经过map函数转换后,生成rdd8的形式为(item,(user,rating)),rdd7与rdd8进行join连接,生成的rdd形式为(item1,((user1,rating1),(item2,sim,rating_dev)),经filter函数分离掉商品近似度小于输入近似度临界值的项;紧接着采用map函数对rdd9进行转换,转换后的rdd10形式为((user1,item2),((ratingl+rating_dev)*sim,sim));最后对rdd10进行reducebykey操作,分别计算(rating1+rating_dev)*sim项与sim项之和,生成rdd11,rdd11的形式为((user1,item2),(sum_pre_rating,sum_sim)),对rdd11进行map转换,生成rdd12,rdd12的形式为((user1,item2),sum_pre_rating/sum_sim);
[0084]
输入:rdd5:(item1,item2),rating_dev),用户评分表(user_rating_rdd):(user,item,rating),商品近似度矩阵(item_sim_rdd):(item1,item2,sim),近似度临界值:λ;
[0085]
输出:((user,item),pre_rating)
[0086]
第c步,完成topn推荐列表。
[0087]
进一步的,并行云平台下推荐方法并行化解析优化:将application提交到并行云集群中启动一个对应的driver进程,driver进程向集群管理器申请资源,同时进行任务进行划分;
[0088]
(1)用户利用textfile()函数,从hdfs上读取a文件;
[0089]
(2)textfile()函数产生最初的rdd-o,rdd-0包含多个partition,这些partition分布在并行云集群的不同工作节点上,每个partition里包含若干行从a文件中读入的记录;
[0090]
(3)在rdd-0上执行flatmap操作之后,生成rdd-1,其中每个partition包含若干单词;
[0091]
(4)在rdd-1上执行map操作,生成rdd-2,其中每个partition中包含若干元组;
[0092]
(5)在rdd-2上执行reducebykey操作,生成rdd-3,该操作会将job分为两个stage,即shufflemapstage和resultstage,根据rdd之间的依赖关系从rdd-3开始回溯搜索,直到没有依赖的rdd-0,在回溯搜索过程中,rdd-3依赖rdd-2,并且是宽依赖,rdd-2和rdd-3之间划分stage,rdd-3被划分为最后一个stage,即resultstage中,rdd-2依赖rdd-1,rdd-1依赖rdd-0,这些依赖都是窄依赖,将rdd-o、rdd-1和rdd-2划分为同一个stage,即sufflemapstage中,数据记录会一次性执行rdd-0到rdd-2的转换;
[0093]
(6)采用saveastextfile函数将程序执行结果保存到分布式文件系统hdfs的out目录下。
[0094]
与现有技术相比,本技术的创新点和优势在于:
[0095]
第一,针对当前电商图片信息过载问题越来越严峻,本技术的商品大数据并行云平台精准推送系统提供一种有效解决方案,针对分离推荐方法存在的缺陷,本技术提出了两种改进方法,基于n个近似用户的近似度加权分离云推荐方法和基于标签的近似度加权分离云推荐方法,同时,进一步改进云计算平台下推荐方法并行化,并对并行云平台下推荐方法并行化解析优化,使其在处理商品大数据时执行效率和精确度更高。本技术专门针对电商大数据设计得准确推荐系统,通过深入挖掘用户历史行为记录,获取用户偏好,根据用户偏好向用户推荐其可能感兴趣的商品,准确度和大数据处理速度都有大幅提升,该商品推荐系统可作为联系用户与商品的桥梁,缺少了大数据时代,传统推荐系统面对海量数据工作效率低下的问题,将大数据处理技术改进后应用到推荐系统中,特别是在当今电商平台数据量大的分布式环境中具有推荐精准、效率高的独特优势。
[0096]
第二,本技术基于并行云的大数据处理框架,针对商品推荐方法涉及大量的迭代运算,在并行云平台上搭建商品推荐系统,解决了分离云推荐在评分稀疏时推荐精度不高的问题,分阶段提出两个层级的改进方法,分别是基于n个近似用户近似度加权的分离云推荐和基于标签的近似度加权分离云推荐;另外,进一步改进云计算平台下推荐方法并行化,在并行云分布式大数据处理平台下实现推荐系统近似度并行化,基于n个近似用户的近似度加权分离云推荐并行化,基于标签的近似度加权分离云推荐方法并行化,并对并行云平台下推荐方法并行化解析优化,使其在处理商品大数据时执行效率和精确度更高。在当今电商平台数据量大的分布式环境中具有鲁棒性好、跨平台能力强、硬软件要求低的优势。
[0097]
第三,本技术创造性的提出基于n个近似用户的近似度加权分离云推荐,基于与目标用户近似度低的用户不参与评分预测,否则导致评分预测值不准,另外与目标用户越近似的用户在计算商品评分偏差时,其比重也越大的思想,采用对近似用户按近似度大小排序,取近似度较大的前n个近似用户参与评分预测,另外,在计算商品评分偏差时,按用户近似度加权,进一步提高预测精度。经过以上一系列的改进,大幅减少了必须要的计算量,商品推荐的针对性更强,特别能适应商品数据量巨大的情况,推荐更加精准高效。
[0098]
第四,本技术创造性的提出基于标签的近似度加权分离云推荐,基于在进行商品评分预测时,采用商品近似度加权比同时评分用户数加权更准确,另外对于稀疏的商品评分矩阵,通过商品标签计算的商品近似度比通过商品评分计算的商品近似度更可靠,在计算商品近似度时,考虑评分数据的稀疏性,采用商品标签计算的近似度替代采用商品评分计算的近似度,在数据稀疏时通过标签计算的商品近似度更加准确,在预测评分时以商品近似度为权重进行加权。引入商品标签计算大幅提高了商品近似度更可靠,使得商品推荐更加准确有效,面对海量数据的推荐速度更快,用户体验更好。
附图说明
[0099]
图1是计算一对商品共同的标签数流程图。
[0100]
图2是并行化计算近似因子流程图。
[0101]
图3是按相似度高低排序取近似度较大的n个近似相邻流程图。
[0102]
图4是计算n个近似用户近似度加权的商品偏差流程图。
[0103]
图5是基于n个近似用户的近似度加权预测用户对商品的评分流程图。
[0104]
图6是基于标签的近似度加权计算商品偏差流程图。
[0105]
图7是基于标签的近似度加权预测用户对商品的评分流程图。
[0106]
图8是并行云平台下不同方法运行效率比较结果图。
[0107]
图9是并行云性能分析不同工作节点数实验对比图。
[0108]
图10是并行云性能分析不同内存大小实验对比图。
[0109]
图11是并行云性能分析不同分区数实验对比图。
[0110]
图12是并行云性能分析不同数据集大小实验对比图。
[0111]
图13是系统调优后的各推荐算法运行结果对比图。
具体实施方式
[0112]
下面结合附图,对本技术提供的商品大数据并行云平台推荐精准推送系统的技术方案进行进一步的描述,使本领域的技术人员能够更好的理解本技术并能够予以实施。
[0113]
当前信息过载问题越来越严峻,推荐系统作为一种有效解决信息过载的方案,受到越来越多互联网公司的青睐。商品推荐系统作为联系用户与商品的桥梁,通过深入挖掘用户历史行为记录,获取用户偏好,根据用户偏好向用户推荐其可能感兴趣的商品。但推荐方法的推荐准确度依然有提升空间。此外进入大数据时代,传统推荐系统面对海量数据工作效率低下的问题日益突出,能否将大数据处理技术应用到推荐系统中,成为解决当前推荐系统工作效率低下的一种新的思路。
[0114]
针对分离推荐方法存在的缺陷,本技术提出了两种改进方法。基于n个近似用户的
近似度加权分离云推荐方法认为与目标用户近似度低的用户不应该参与评分预测,否则会导致评分预测值不准,另外与目标用户越近似的用户在计算商品评分偏差时,其比重也应该越大。基于标签的近似度加权分离云推荐方法认为在进行评分预测时,采用商品近似度加权可能比同时评分用户数加权更准确,另外对于稀疏的商品评分矩阵来说,通过商品标签计算的商品近似度应该比通过商品评分计算的商品近似度更可靠。
[0115]
一、基于n个近似用户的近似度加权分离云推荐
[0116]
本技术针对分离云推荐忽略用户近似的缺陷,提出基于n个近似用户的近似度加权分离云推荐方法,对近似用户按近似度大小排序,取近似度较大的前n个近似用户参与评分预测,另外,在计算商品评分偏差时,按用户近似度加权,进一步提高预测精度。
[0117]
相邻用户的选择取决于用户之间的近似程度,用户近似度描述是两个用户在品味或者兴趣方面表现出来的近似程度,近似度计算采用近似因子。
[0118]
不同用户对商品的偏好不同,导致评分差异较大,如果能分离掉一些兴趣差别较大的用户,选取与目标用户近似度较高的用户评分预测,不仅能够提高推荐准确率,还能减少计算量。本技术提出通过选取与目标用户近似度较大的前n个用户进行评分预测,且在计算商品评分偏差时,融入用户近似度,基于n个近似用户的近似度加权分离云推荐方法中商品j相对于商品i的评分偏差计算式为:
[0119][0120]
其中,r为整个评分数据,r
vi
和r
vj
分别表示用户v对商品i和商品j的评分,s
ji
(r)表示同时对商品i和商品j有评分,且与用户u近似的前n个用户的集合,sim(u,v)表示用户u和用户v的近似度,采用皮尔逊关联因子计算用户之间的近似度,|sim(u,v)|表示sim(u,v)的绝对值,分母用|sim(u,v)|代替sim(u,v)避免负的权重会导致预测评分超出允许的范围。
[0121]
利用式1计算商品j与商品i的评分偏差之后,采用分离云推荐方法中的式2计算用户u对商品j的预测值:
[0122][0123]
采用dev
ji
+r
ui
获得用户u对商品j的一个评分预测值,relevant(u,j)表示用户u评过分的商品中与商品j被同时评过分的商品集合,得到基于n个近似用户的近似度加权分离云推荐方法的预测结果。
[0124]
从输入、输出、实现流程三个方面对基于n个近似用户的近似度加权分离云推荐方法描述包括:
[0125]
(1)输入:用户-商品评分矩阵r(mxn),目标用户u,目标商品j,相邻用户个数n;
[0126]
(2)输出:用户u对商品j的pred(u,j)评分;
[0127]
(3)方法的详细实现步骤如下:
[0128]
第一步:获得目标用户u,已经评分商品的集合iu;
[0129]
第二步:获取对目标商品j和i中的商品都有评分的用户集合u
ji
;
[0130]
第三步:计算目标用户u与用户集合u
ji
中的每一个用户的皮尔逊关联因子,取皮尔
逊关联因子较大的n个用户,构成集合s
ji
(r);
[0131]
第四步:利用式1计算目标商品j和iu中的每一个商品的评分偏差dev
ji
;
[0132]
第五步:由式2计算目标用户u对目标商品j的评分预测值pred(u,j)。
[0133]
二、基于标签的近似度加权分离云推荐
[0134]
上一部分通过寻找用户近邻对分离云推荐方法进行了改进,但该方法存在一个问题,当评分数据集较为稀疏时,预测精度并不高,原因为当用户评分较少时,用户近似度的计算并不准确,某两个被认为近似度很高的用户,可能仅仅因为他们对某一商品有相同的评分,但其实他们并不近似。这种情况通过采用重要性赋权来克服。对于评分矩阵稀疏的问题,通过矩阵填充解决,但人工填充费时费力,自动填充误差较大,且矩阵填充完毕之后会导致计算量和存储量增大。对于像淘宝这样的大型电商平台,用户实际评分商品数相对于系统中的商品数来说微乎及微,采用矩阵填充成本太高,不切合实际。实际上,在进行推荐时,除去用户评分数据之外,还有很多数据可以利用,合理的利用这些数据更能提高预测精度。例如商品的近似度计算除去通过商品评分之外还可以通过商品内容计算,在评分较少时,通过内容计算的近似度更准确。对于像电影、图像、音乐一类的多媒体商品,很难提取其内容。可以为这些商品打标签,通过标签来表征其内容,利用标签的近似度替代商品内容的近似度。另外商品标签近似度与商品内容近似度相比还有一大优点。例如两份文档,它们采用了相同的词语,但是其中一份出自名家之手,而另一份则是小学生日常的作业,如果单单从内容来看,它们近似,但如果为两份文档打上质量标签,就会发现它们是不近似的,即标签不但能描述商品的内容还能描述商品的质量,标签近似的商品不会出现质量相差很大的情况,但商品内容近似的商品却可能出现质量差距很大的情况。
[0135]
分离云推荐方法本身除去忽略用户的近似度之外,也忽略了商品的近似度,如果忽略近似度较低的商品,选取近似度较高的商品进行评分预测,不仅可以提高预测准确度,还可以减少计算量,本技术基于标签的近似度加权分离云推荐方法,首先通过商品标签计算商品近似度,在利用分离云推荐进行评分预测时融入商品近似度权重,通过临界值分离、权重校正来提高准确度。
[0136]
(一)临界值分离与权重校正
[0137]
1.临界值分离:通过设定标签近似度临界值,分离标签近似度小于等于近似度临界值的商品,定义sim(i,j)为计算的标签近似度,则标签近似度大于近似度临界值λ的集合,通过式3得出:
[0138]
s(uj)={uj|sim(i,j)>λ}
ꢀꢀ
式3
[0139]
2.权重校正:采用商品标签近似度作为权重,加权的预测结果,通过式4计算得到:
[0140][0141]
其中,r
ui
是用户u对商品i评分,sim(i,j)表示商品i和商品j的标签近似度,采用近似因子计算商品之间的标签近似度,s(u,j)表示用户u评过分的商品中与商品j被同时评过分,且与商品j的近似度大于近似度临界值λ的商品集合,s(i,j)={i|i∈s(u),i≠j,|s
j,i
(r)|>0,sim(i,j)>λ},其中s(u)为表示用户u评过分的商品集合,|s
j,i
(r)|表示对商品i和商品j同时评分的用户数,dev
ji
表示商品j与商品i的平均评分偏差,dev
ji
+r
ui
为用户u通
过对商品i的评分对商品j的评分的预测值;
[0142][0143]
其中r
ui
和r
uj
分别表示用户u对物品i和物品j的评分,r为整个评分数据矩阵,s
ji
(r)表示同时对物品i和物品j评分的用户集合,|s
ji
(r)|表示集合s
ji
(r)中用户的数量,采用式5计算商品j与商品i的平均偏差之后,采用式4计算用户u对商品j的预测值,即得到改进方法的预测结果。
[0144]
(二)基于标签的近似度加权分离云推荐方法
[0145]
从输入、输出、实现流程三个方面对基于标签的近似度加权分离云推荐方法进行描述,包括:
[0146]
(1)输入:商品标签矩阵t(h
×
n),商品标签矩阵为预处理过的布尔型矩阵,用户-商品评分矩阵r(m
×
n),目标用户u,目标商品j,标签近似度临界值λ;
[0147]
(2)输出:目标用户u对目标商品j的预测评分pred(u,j);
[0148]
(3)方法的详细实现步骤如下:
[0149]
第1步:采用近似因子公式计算标签之间的近似度;
[0150]
第2步:从目标用户u已评分的商品中选取与目标商品j有共同评分用户的商品,再从中选择与目标商品j的标签近似度大于λ的商品,构成商品集s(u,j);
[0151]
第3步:利用式5计算目标商品j与s(u,j)中的每一个商品的平均偏差dev
ji
;
[0152]
第4步:由式4计算目标用户u对目标商品j的预测值pred(u,j)。
[0153]
三、基于n个近似用户的近似度加权分离云推荐方法时间复杂度
[0154]
基于n个近似用户的近似度加权分离云推荐分为四步:
[0155]
步骤一:计算目标用户的近似用户集合:该步需要遍历所有用户(用户总数为m),计算目标用户与每一个用户的近似度,而计算用户间的近似度时,需要遍历用户有过评分的所有商品,用户平均有过评分的商品数为a*n,这一步的时间复杂度为θ(amn);
[0156]
步骤二:对目标用户近似用户集合排序:采用快速排序法,时间复杂度为θ(m log2m);
[0157]
步骤三:计算商品间评分偏差的平均值:用户平均评过分的商品为a*n个,计算目标用户评过分的每一个商品与目标商品的评分偏差时,需要遍历近似用户集合从中选择对这两个商品同时评过分的n个用户,假设平均需要遍历g次,其中k≤g≤m,这一步的时间复杂度为θ(agn);
[0158]
步骤四:预测目标商品评分:时间复杂度同分离云推荐最后一步,时间复杂度为θ(an),基于n个近似用户的近似度加权分离云推荐方法的时间复杂度为θ(amn+m log2m+agn)。
[0159]
四、基于标签的近似度加权分离云推荐推荐方法时间复杂度
[0160]
基本标签的近似度加权分离云推荐分为四步:
[0161]
步骤1:计算同目标商品标签近似的商品集合:需要计算目标商品与所有商品(商品总数为n)的标签近似,而计算商品标签之间的近似度又需要遍历每一个标签,标签数为h,第一步时间复杂度为θ(hn)。
[0162]
步骤2:计算目标用户评过分的商品中近似度大于近似度临界值λ的商品集合,用户平均评过分的商品为a*n个,需要对每一个商品进行比较,第二步的时间复杂为θ(an);
[0163]
步骤3:计算商品间评分偏差的平均值:假设目标用户评过分的商品中标签近似度大于近似度临界值入的商品的个数平均为d,则第三步的时间复杂度为θ(dm),其中d≤an;
[0164]
步骤4:预测目标商品评分:遍历d个标签近似的商品,时间复杂度为θ(d),基于标签的近似度加权分离云推荐推荐方法的时间复杂度为θ(hn+an+dm)。
[0165]
(1)时间复杂度分析比较
[0166]
基于n个近似用户的近似度加权分离云推荐方法因为要计算目标用户的近似用户集合,此外还要对近似用户集合进行排序,故需要额外耗时θ(amn+mlog2m),但时间复杂度和分离推荐方法还是处在同一个数量级。如果能提前将用户近似度计算好的话,还能稍微比分离云推荐方法快一点。另外基于标签的近似度加权分离云推荐方法因为需要计算标签近似度,分离不近似的商品,故需要额外耗时θ(hn+an),同样的如果能提前将商品标签近似度计算好的话,该方法也会比分离云推荐方法快。基于标签的近似度加权分离云推荐方法同基于n个近似用户的近似度加权分离云推荐方法相比,有hn<amn,an<mlog2m,故基于标签的近似度加权分离云推荐方法比基于n个用户近似的近似度加权分离云推荐方法时间复杂度要小。
[0167]
五、云计算平台下推荐方法并行化
[0168]
推荐系统面临海量的用户数据,如何快速的从海量的数据中得到推荐结果是推荐系统走出实验室,走进人们的生活必须解决的问题。采用传统的单机运行模式,显然不切合实际。因此在分布式大数据处理云平台上实现推荐方法尤为重要。
[0169]
现有技术较多的是基于hadoop大数据处理云平台的推荐系统,但hadoop平台会将中间结果保存到外部存储器上,频繁的i/o访问,导致系统效率低下,并且hadoop的mapreduce只提供了map和reduce两个操作,编码难度较高。并行云吸收了hadoop的优点,中间结果保存在内存中,不再需要频繁的读写外部io设备,并行云除去map和reduce操作以外,还包括更多的编码。
[0170]
(一)近似度并行化
[0171]
近似因子计算分三步:第i步,计算一对商品共同的标签数;第ii步,利用近似因子公式计算商品近似度;第iii步,对商品近似度进行排序,取近似度较大的n个近似相邻;
[0172]
第i步,计算一对商品共同的标签数:首先采用map函数对标签矩阵进行转换,标签矩阵的形式为(item,label),转换后rdd1的形式为(label,item),采用join函数对rddl自身进行笛卡尔乘积,生成的rdd2的形式为(label,(item1,item2));接着采用map函数将rdd2转换为rdd3,rdd3的形式为((item1,item2),1),再利用reducebykey函数对商品1与商品2的共同标签数进行进行计算,生成rdd4,rdd4的形式为((item1,item2),count);紧接着利用filter函数,对rdd4进行不同的分离,生成的rdd5与rdd6,rdd5的形式与rdd4一致,是由rdd4的对角线元素组成的对角矩阵,rdd6的形式也与rdd4一致,由rdd4中去掉对角线元素以外的所有元素构成;最后对rdd5进行map转换生成rdd7,rdd7的形式为(item,count),对rdd6进行map转换生成rdd8,rdd8的形式为(item1,(item2,count12));具体过程如图1所示。
[0173]
输入:商品标签矩阵:(item,label)
[0174]
输出:(item,count),(item1,(item2,count_12))
[0175]
其中,item_label_rdd为商品标签矩阵,rdd1的形式为(label,item),rdd2的形式为(label,(item1,item2)),rdd3的形式为((item1,item2),1),rdd4、rdd5、rdd6的形式为((item1,item2),count),rdd7的形式为(item,count),rdd8的形式为(item1,(item2,count12));
[0176]
第ii步,计算近似因子:首先利用join函数连接rdd8与rdd7,生成的rdd9形式为(item1,((item2,count_12),count_1)),对rdd9进行map转换生成rdd10,rdd10的形式为(item2,(item1,count_12,count_1));然后采用join函数连接rdd10和rdd7生成rdd11,rdd11的形式为(item2,((item1,count_12,count_l),count_2);最后根据近似度计算式,对rdd11进行map转换生成rdd12,rdd12的形式为((item1,item2),count_12*1.o/(count_1+count_2))。具体过程如图2所示。
[0177]
输入:(item,count),(item1,(item2,count_12))
[0178]
输出:((item1,item2),sim)
[0179]
其中,rdd7、rdd8为上一步的输出,rdd9的形式为(item1,((item2,count_12),count_1)),rdd10的形式为(item2,(item1,count_12,count_1)),rdd11的形式为(item2,((item1,count_12,count_1),count_2),rdd12的形式为((item1,item2),count_12*1.0/(count_1+count_2)));
[0180]
第iii步,按照相似度高低进行排序,取近似度较大的n个近似相邻:首先采用filter函数过滤掉负相关和不相关的项,接着采用groupby函数,以商品为key进行分类,然后对每一类,按照近似度排序,取近似度较大的前n项,最后采用flatmap函数将结果转换为(item1,item2,sim)的形式。具体过程如图3所示:
[0181]
输入:((item1,item2),sim),n:相似邻居数
[0182]
输出:(item1,item2,sim)
[0183]
其中,rdd5为上一步输出,rdd6和rdd5形式一样,rdd7的形式为(item1,list《item2,sim》),rdd8的形式为(item1,item2,sim)。
[0184]
本技术计算的近似度,保存到hdfs上,或采用cache/persist缓存到内存中,作为广播变量广播到所有工作节点,以下对加权分离云推荐推荐方法,改进的推荐方法进行并行化改造。
[0185]
(二)基于n个近似用户的近似度加权分离云推荐并行化
[0186]
分为三步:第a步,计算n个近似用户近似度加权的商品偏差;第b步,预测用户对商品的评分;第c步,完成topn推荐列表;
[0187]
第a步,计算n个近似用户近似度加权的商品偏差:首先用户评分表经过map函数转换为rddl,rdd1的形式为(user,(item,rating)),rdd1对自身进行join操作,生成的rdd形式为(user,((item1,rating1),(item2,rating2)),采用filter分离掉item1=-item2的情况,采用map函数转换成rdd2,rdd2的形式为(item1,(user,item2,rating2-rating1));接着再次对用户评分表采用map函数,将其转换为rdd3,rdd3的形式为(item,(user,rating)),将rdd3与rdd2进行join操作,生成的rdd4的形式为(item1,((user1,rating1),(user2,item2,rating_dev))),rating_dev就是rating2-ratingl所代表的项,对rdd4进行map转换,转换后的rdd5形式为((user1,user2),(item1,item2,rating1,rating_dev));紧
接着对商品近似度矩阵进行map转换,转换后的rdd6的形式为((user1,user2),sim),将rdd5和rdd6进行join连接,生成的rdd形式为((user1,user2),(item1,item2,rating1,rating_dev),sim)),经map转换为rdd7,rdd7的形式为((item1,item2,user1),(rating_dev*sim,sim,rating1));最后,对rdd7进行reducebykey操作,以(item1,item2,user1)为key,对评分差乘以近似度求和,对近似度求和,生成的rdd8的形式为((item1,item2,user1),(sum_rating_dev,sum_sim,rating1)),在对rdd8采用map函数生成最终结果rdd9,rdd9的形式为((user,item),(sum_rating_dev/sum_sim,rating1,1))。具体过程如图4所示。
[0188]
输入:用户评分表:(user,item,rating),用户近似度矩阵:(user1,uer2,sim)
[0189]
输出:((user,item),(sum_rating_dev/sum_sim,rating1,1))
[0190]
其中user_rating_rdd为用户评分表,rdd1的形式为(user,(item,rating)),rdd2的形式为(item1,(user,item2,rating2-rating1)),rdd3的形式为(item,(user,rating)),rdd4的形式为(item1,((user1,rating1),(user2,item2,rating_dev))),rdd5的形式为((user1,user2),(item1,item2,rating1,rating_dev)),user_sim_rdd为用户近似度矩阵,rdd6的形式为((user1,user2),((item1,item2,rating1,rating_dev),sim)),rdd7的形式为((item1,item2,user1),(rating_dev*sim,sim,ratingl)),rdd8的形式为((item1,item2,user1),(sum_rating_dev,sum_sim,rating1)),rdd9为((user,item),sum_rating_dev/sum_sim,rating1,1));
[0191]
第b步,预测用户对商品的评分:首先采用map函数对上一步的输出进行转换,转换后的rdd10的形式为((user,item),(ratingl+rating_dev,1));然后采用reducebykey,以(user,item)为key,分别对rating1+rating和1求和;最后通过map函数预测评分。具体流程如图5所示。
[0192]
输入:((user,item),(rating_dev,rating1,1))
[0193]
输出:((user,item),pre_rating)
[0194]
其中,rdd9为上一步的输出,rdd10的形式为((user,item),(rating1+rating_dev,1)),rdd11为输出。
[0195]
第c步,与近似度并行化的第三步类似。
[0196]
(三)基于标签的近似度加权分离云推荐方法并行化
[0197]
分为三步:第a步,计算商品偏差;第b步,预测用户对商品的评分;第c步,完成topn推荐列表。
[0198]
第a步,计算商品偏差:首先用户评分表经过map转换函数,转换为rdd1,rdd1的形式为(user,(item,rating));接着利用join函数,与rdd1做笛卡尔乘积,生成rdd2,rdd2的形式为(user,((itemi,rating1).(item2,rating2));紧接着利用filter函数,分离掉item1==item2的情况,采用map函数转换为rdd3,rdd3的形式为((item1,item2),(rating2-rating1,1);然后利用reducebykey函数对评分偏差和共同评分人数进行计算,生成的rdd4的形式为((item1,item2),(sum_dev,n));最后按(2-7)式进行map转换,求出商品平均偏差。具体过程如图6所示。
[0199]
输入:(user,item,rating)
[0200]
输出:((item1,item2),rating_dev)
[0201]
其中,rdd1的形式为(user,(item,rating)),rdd2的形式为(user,((item1,rating1),(item2,rating2)),rdd3的形式为((item1,item2),(rating2-rating1,1),rdd4的形式为((item1,item2),(sum_dev,n)),rdd5的形式为((item1,item2),sum_dev/n);
[0202]
第b步,预测用户对商品的评分。首先商品近似度矩阵经过map函数转换后,生成的rdd6的形式为((item1,item2),sim),rdd6与rdd5通过join函数进行笛卡尔乘积,生成的rdd形式为((item1,item2),(sim,rating_dev)),经map转换后rdd7的形式(item1,(item2,sim,rating_dev));接着用户评分表经过map函数转换后,生成rdd8的形式为(item,(user,rating)),rdd7与rdd8进行join连接,生成的rdd形式为(item1,((user1,rating1),(item2,sim,rating_dev)),经filter函数分离掉商品近似度小于输入近似度临界值的项;紧接着采用map函数对rdd9进行转换,转换后的rdd10形式为((user1,item2),((ratingl+rating_dev)*sim,sim));最后对rdd10进行reducebykey操作,分别计算(rating1+rating_dev)*sim项与sim项之和,生成rdd11,rdd11的形式为((user1,item2),(sum_pre_rating,sum_sim)),对rdd11进行map转换,生成rdd12,rdd12的形式为((user1,item2),sum_pre_rating/sum_sim)。具体过程如图7所示。
[0203]
输入:rdd5:(item1,item2),rating_dev),用户评分表(user_rating_rdd):(user,item,rating),商品近似度矩阵(item_sim_rdd):(item1,item2,sim),近似度临界值:λ;
[0204]
输出:((user,item),pre_rating)
[0205]
其中,rdd5为上一步的输出,item_sim_rdd为商品近似度矩阵,user_rating_add为用户商品评分表,rdd6的形式为((item1,item2),sim),rdd7的形式的为(item1,(item2,sim,rating_dev)),rdd8的形式为(item,(user,rating)),rdd9的形式为(item1,((user1,rating1),(item2,sim,rating_dev)),rdd10的形式为((user1,item2),((rating1+rating_dev)*sim,sim)),rdd11的形式为((user1,item2),(sum_pre_rating,sum_sim)),rdd12的形式为((user1,item2),sum_pre_rating/sum_sim);
[0206]
第c步,与近似度并行化的第三步类似。
[0207]
(四)并行云平台下推荐方法并行化解析优化
[0208]
将application提交到并行云集群中启动一个对应的driver进程,driver进程向集群管理器申请资源,同时进行任务进行划分;
[0209]
1.用户利用textfile()函数,从hdfs上读取a文件;
[0210]
2.textfile()函数产生最初的rdd-o,rdd-0包含多个partition,这些partition分布在并行云集群的不同工作节点上,每个partition里包含若干行从a文件中读入的记录;
[0211]
3.在rdd-0上执行flatmap操作之后,生成rdd-1,其中每个partition包含若干单词;
[0212]
4.在rdd-1上执行map操作,生成rdd-2,其中每个partition中包含若干元组;
[0213]
5.在rdd-2上执行reducebykey操作,生成rdd-3,该操作会将job分为两个stage,即shufflemapstage和resultstage,根据rdd之间的依赖关系从rdd-3开始回溯搜索,直到没有依赖的rdd-0,在回溯搜索过程中,rdd-3依赖rdd-2,并且是宽依赖,rdd-2和rdd-3之间划分stage,rdd-3被划分为最后一个stage,即resultstage中,rdd-2依赖rdd-1,rdd-1依赖
rdd-0,这些依赖都是窄依赖,将rdd-o、rdd-1和rdd-2划分为同一个stage,即sufflemapstage中,数据记录会一次性执行rdd-0到rdd-2的转换;
[0214]
6.采用saveastextfile函数将程序执行结果保存到分布式文件系统hdfs的out目录下。
[0215]
六、实验分析
[0216]
本技术实验在虚拟机中完成,在实验室的一台服务器上搭建并行云集群,该集群共包含5台虚拟机,其中,1台为master节点,其它为worker节点。
[0217]
(一)比较并行云平台下不同方法运行效率
[0218]
实验采用moivelens(100k)数据集,预测每一个用户的topn推荐列表。利用python编程语言实现本技术介绍的几种推荐方法,将代码提交到并行云集群环境中运行,最后对几种方法的运行时间进行对比。
[0219]
实验结果如图8所示。在并行云平台下基于用户的推荐方法和基于商品的推荐方法执行效率较高,基于标签的近似度加权分离云推荐推荐方法执行效率比原分离云推荐推荐方法提高。
[0220]
(二)并行云性能分析
[0221]
为了弄清楚并行云平台上推荐方法到底适不适合海量数据的推荐,设计实验,采用moivelens(1m)数据集,通过该数据集生成100k、200k、400k、800k大小的数据集。
[0222]
1)不同工作节点数
[0223]
该实验采用100k数据集,计算用户之间的关联因子,方法时间复杂度为θ(n2),节点数分别为1个、2个、3个、4个,执行内存为2g。
[0224]
实验结果如图9所示。通过实验我们发现增加工作节点数可以系统执行效率,但当节点数达到一定程度时,在增加工作节点数,并不能提高系统执行效率。
[0225]
2)不同内存大小
[0226]
该实验采用100k数据集,计算用户之间的关联因子,方法时间复杂度为θ(n2),节点数为2,执行内存大小分别为500m、750m、1g、2g、4g、8g。
[0227]
实验结果如图10所示。实验发现在内存不足时,系统执行效率非常低,增加内存可以提高系统执行效率,但当内存太大时,系统执行效率反而降低。
[0228]
3)不同分区数
[0229]
该实验采用100k数据集,计算用户之间的皮尔逊关联因子,方法时间复杂度为θ(n2),节点数为2,执行内存为10g,初始分区数为2个、4个、8个、16个、32个。
[0230]
实验结果如图11所示。实验发现选择合适的分区数可以提高系统执行效率。如果能在程序执行的每一阶段都对分区数进行优化,选择最适合的分区数,可以很好的提高系统效率。
[0231]
4)不同数据集大小
[0232]
该实验计算用户之间的关联因子,方法时间复杂度为θ(n2),节点数为2,执行内存为10g,数据集大小分别为100k、200k、400k、800k。
[0233]
实验结果如图12所示。实验发现随着数据量的加大,方法执行效率一开始下降并不明显,但当数据量增大到某一值时,方法执行效率急剧下降。
[0234]
通过实验从四个方面对并行云的性能进行了分析。其中节点数和分区数可以认为
是系统并行度对执行效率的影响,实验结果表明并行度过低或者过高都会对系统性能造成影响。实验结果也表明内存过小会导致系统性能急剧下降,shuffle操作对系统性能影响较大,并且shufflewrite操作有可能出现shufflespill,一旦出现shufflespill系统性能会急剧下降。图13是并行云性能分析实验为指导进行系统调优后,得到的推荐方法运行结果。可以看出,经过调优后方法执行效率明显提高。实验表明并行云的高效性是建立在拥有强大配置的集群基础上的,同时也表明对系统调优可以明显提高方法执行效率,实验还表明推荐方法能够很好的处理商品大数据。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1