一种基于潜在语义属性及影响因子优化的协同过滤方法及系统与流程
1.本发明涉及计算机技术领域,具体涉及一种基于潜在语义属性及影响因子优化的协同过滤方法及系统。
背景技术:
2.现有技术在推荐问题中,对于推荐对象和被推荐对象其中一方的属性无法获得的情况下,一般用以下两类方法进行属性关联,再进行推荐。
3.1、常规的协同过滤及优化过的协同过滤算法;
4.比较被匹配的各目标的属性找出相似的被匹配目标群,将同一个群订购或选择过的产品或信息等作为各群内各个被匹配目标共同可能会感兴趣的匹配对象而进行匹配。同样,作为属性类似或相同的产品或信息等,也可以归为一个类,订购或选择过其中一个的产品或信息,对该类其他产品或信息也可能会感兴趣。
5.对于该方法,虽然被匹配目标或匹配目标的属性比较可以获得匹配。但在大多数情况下会存在运算量过大,精确度不高。运算量大虽可以用阵列显卡的并行运算解决,但也是无端浪费计算资源。常规的协同过滤精确度不高,是因为被匹配对象与匹配对象并不是直接计算两两对应的直接属性,因此通过间接项进行计算时,仅是一一对应的比较,而不发掘其他辅助项或属性,是不易提升精准的。
6.2、优化过的协同过滤算法;
7.优化内容主要为相关被匹配的目标群之间的属性比较,匹配的产品或信息的属性比较。对属性比较的数据项的向量或相似离散矩阵进行简化或性能调优。
8.对于该方法,因优化是对属性比较的数据项的向量或相似离散矩阵进行简化或性能调优,因此同上述协同过滤算法一样,计算量和精准度不会有太大提升。
技术实现要素:
9.本发明的目的在于提供一种基于潜在语义属性及影响因子优化的协同过滤方法,减少协同过滤等相似比较的计算量,并提升协同过滤的推荐问题属性比较的精准性。
10.本发明提供一种基于潜在语义属性及影响因子优化的协同过滤方法,包括以下步骤:
11.获取匹配目标所有关联的被匹配目标的匹配目标属性;
12.对匹配目标属性进行潜在语义分析,获取匹配目标的潜在语义属性;
13.获取待匹配目标的待匹配属性,根据匹配目标的潜在语义属性和待匹配目标的待匹配属性进行影响因子评估,获得影响因子;
14.对影响因子进行匹配度计算,获取匹配度。
15.优选地,将匹配目标属性进行潜在语义分析,获取匹配目标的潜在语义属性,具体包括以下步骤:
16.对于匹配目标属性的数值类属性:计算数值类属性的属性值的有效平均值;
17.对于匹配目标属性的标签类属性:获取标签类属性的属性标签及其对应出现的次数;
18.数值类属性的属性值的有效平均值、标签类属性的属性标签及其对应出现的次数共同作为匹配目标的潜在语义属性。
19.优选地,获取待匹配目标的待匹配属性,根据匹配目标的潜在语义属性和待匹配目标的待匹配属性进行影响因子评估,获得影响因子,具体包括以下步骤:
20.对于待匹配目标的数值类属性,影响因子的计算方式为:
21.影响因子=相应的有效平均值/该待匹配属性的属性值;
22.对于待匹配目标的标签类属性,采用下述两种计算方式之一计算影响因子;
23.a)、影响因子=该因素对应出现的次数/该属性项各属性对应次数的最大值;
24.该因素对应出现的次数为:在匹配目标的潜在语义属性中,与待匹配属性相对应的标签类属性的属性标签的对应出现的次数;
25.该属性项各属性对应次数的最大值为:在匹配目标的潜在语义属性中,相应的标签类属性的属性标签所有对应出现的次数中的次数最大值;
26.b)、影响因子=该因素对应出现的次数/该属性项各属性对应次数的总和;
27.该属性项各属性对应次数的总和为:该被匹配目标的所有标签类属性的属性标签对应出现的次数的总和。
28.优选地,对于待匹配目标的标签类属性,待匹配目标的标签类属性与匹配目标的潜在语义属性进行匹配;
29.若匹配不成功,相应待匹配属性的影响因子分数为0;
30.若匹配成功,则计算影响因子。
31.优选地,待匹配目标的标签类属性与匹配目标的潜在语义属性的匹配方法为:查询待匹配属性是否出现在匹配目标属性中;若出现,匹配成功;否则;匹配不成功。
32.优选地,对影响因子进行匹配度计算,获取匹配度,具体包括以下步骤:
33.所有影响因子的平均值作为匹配度。
34.优选地,匹配度的计算方式为:
35.匹配度=所有待匹配属性的影响因子的总和/匹配目标的总特征数。
36.优选地,对于匹配目标属性的数值类属性,计算数值类属性的属性值的有效平均值,具体包括以下步骤:
37.如果数值类属性的属性值的标准差过大,则剔除过大或过小的属性值之后再进行平均计算,得到有效平均值。
38.优选地,还包括以下步骤:
39.根据匹配度进行推荐。
40.本发明还提供一种用于实现上述一种基于潜在语义属性及影响因子优化的协同过滤方法的系统,包括:
41.获取模块,用于获取匹配目标的所有关联的被匹配目标的匹配目标属性;用于获取待匹配目标的待匹配属性;
42.特征提取模块,用于对匹配目标属性进行潜在语义分析,获取匹配目标的潜在语
义属性;
43.特征匹配模块,用于根据匹配目标的潜在语义属性和待匹配属性进行影响因子评估,获得影响因子;影响因子决定了对应目标属性在匹配时的权重修正;
44.匹配度计算模块,用于对影响因子进行匹配度计算,获取匹配度。
45.与现有技术相比,本发明的有益效果为:
46.1、本发明解决了协同过滤等直接进行属性比较时,如果被匹配目标或匹配目标数量过大,会存在计算量过大的情况。
47.因为在现有技术中,如果被匹配目标数量有100万,无论匹配目标有多少,比较的计算次数均=100万*100万/2-100万=近5*10^11次,同理100万的匹配目标也同理;如果匹配项数量有100万也同理。
48.但是,如用本发明的协同过滤方法,有100万的被匹配目标与1万的匹配目标,或100万的匹配目标与1万的被匹配目标,计算次数=生成潜在语义项+相似计算=(1万*100万)+(100万*1万)=仅2*10^6次。
49.现有技术的计算次数远超过采用本发明的方法的计算次数。
50.2、准确度的提高。
51.由于现有技术中的协同过滤中,被匹配目标与被匹配目标、匹配目标与匹配目标的匹配计算,仅通过一次计算便得到了匹配度,然后进行关联映射到匹配目标,这明显会因为偶然性存在大量误差。
52.而本发明的方法中,计算的潜在语义项是在大量的与该潜在语义项关联的被匹配目标与匹配目标进行计算,就算存在一定的偶然因素,也会因大数据的训练修正而被消除掉,从而提高了准确度。
附图说明
53.下面结合附图对本发明的具体实施方式作进一步详细说明。
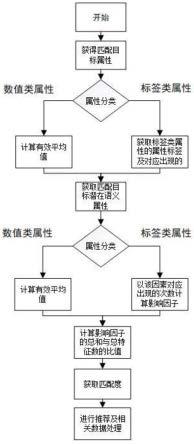
54.图1是本发明一种基于潜在语义属性及影响因子优化的协同过滤方法的流程示意图。
具体实施方式
55.下面结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不仅限于此。
56.本发明提供一种基于潜在语义及因子优化的协同过滤方法,主要适合一个匹配目标有多个被匹配目标与之关联;
57.匹配目标可以为产品、信息等,此时,被匹配目标为与之关联的用户等;
58.匹配目标也可以为用户等,此时,被匹配目标为与之关联的产品、信息等;
59.关联方式为购买、点击、观看等操作。
60.如图1所示,具体包括以下步骤:
61.步骤1:获取匹配目标的所有关联的被匹配目标的匹配目标属性;
62.匹配目标属性包括若干数值类属性和标签类属性;
63.数值类属性包括购买、点击、观看次数等;
64.标签类属性包括用户兴趣(如旅游、运动、电脑数码
……
),所在地域(如四川、浙江、广东
……
),所在行业(如农业、制造业、金融
……
)等。
65.步骤2:根据匹配目标属性,获取匹配目标的潜在语义属性;
66.数值类属性和标签类属性采用不同的计算方法;
67.对于数值类属性:分别计算每个相应数值类属性的所有属性值的有效平均值;
68.在有效平均值中,如果数值类属性的属性值的标准差过大,则需要剔除过大或过小的属性值之后再进行平均计算,即可得到有效平均值。
69.对于标签类属性:分别获取每个标签类属性的属性标签及其对应出现的次数;
70.例如:属性标签为“1”,对应出现的次数为4次;属性标签为“是”,对应出现的次数为3次。
71.两者计算所得的数值类属性的属性值的有效平均值、标签类属性的属性标签及其对应出现的次数,这些加工后的数据作为目标具有的潜在语义属性,即匹配目标的潜在语义属性;
72.步骤3:获取新的匹配目标作为待匹配目标,获取待匹配目标的待匹配属性,根据待匹配属性和匹配目标的潜在语义属性,获得所有待匹配属性的影响因子,影响因子决定了对应目标属性在匹配时的权重修正,该步骤计算影响因子的过程为相似计算。
73.匹配目标、被匹配目标实际为训练集的比较目标,经训练计算后得出的属性值(如经计算的数值或标签的次数),待匹配目标可理解为测试集、测试目标,最终目的为计算这些待匹配目标与被匹配目标的相似性,从而得出待匹配目标对被匹配目标的的购买欲、使用的可能性等。
74.实际为用匹配目标、被匹配目标已产生出的数据,去预测待匹配目标的性质、行为等。
75.待匹配属性同样包括数值类属性和标签类属性;其中属性值为空的数据不参与计算。
76.对于数值类属性,影响因子的计算方式为:
77.待匹配属性的影响因子=相应的有效平均值/该待匹配属性的属性值;
78.对于标签类属性,待匹配目标的标签类属性与匹配目标的潜在语义属性进行匹配;匹配方法为查询匹配待匹配属性是否出现在匹配目标属性中;
79.若待匹配目标的标签类属性与匹配目标的潜在语义属性匹配不成功,相应待匹配属性的影响因子分数为0;
80.若待匹配目标的标签类属性与匹配目标的潜在语义属性匹配成功,则采用下述两种计算方式之一计算影响因子;
81.a)、待匹配属性的影响因子=该因素对应出现的次数/该属性项各属性对应次数的最大值;
82.该因素对应出现的次数为:在匹配目标的潜在语义属性中,与待匹配属性相对应的属性标签的对应出现的次数;
83.该属性项各属性对应次数的最大值为:在匹配目标的潜在语义属性中,相应的属性标签所有对应出现的次数中的次数最大值。
84.b)、待匹配属性的影响因子=该因素对应出现的次数/该属性项各属性对应次数
的总和;
85.该属性项各属性对应次数的总和为:在匹配目标的潜在语义属性中,所有属性标签对应出现的次数相加的总和。
86.例如,对于某一待匹配属性,属性标签“否”,对应次数4;属性标签“是”,对应次数3。该属性项各属性对应次数的最大值即为4;该属性项各属性对应次数的总和即为7。
87.采用训练数据不同,使用以上两种计算方法得出的结果的匹配精准不同,需根据实际监督数据获得的结果进行选用。
88.步骤4:根据所有待匹配属性的影响因子,获取匹配度;匹配度为所有待匹配属性的影响因子的平均值。
89.具体的计算方式为:
90.匹配度=所有待匹配属性的影响因子的总和/匹配目标的总特征数。
91.步骤5:根据匹配度进行相关推荐或者数据处理。
92.在具体实践中:
93.为每个与多个被匹配目标关联的匹配目标,计算其具有的匹配目标的潜在语义属性,匹配目标的潜在语义属性为匹配目标属性仅包含一种属性项或包含多种不同属性项。
94.同样,对于与多个匹配目标关联的被匹配目标,为其计算具有的匹配目标的潜在语义属性,匹配目标的潜在语义属性为最匹配的一个属性项或多种不同属性项。
95.经实验,发现以上计算出的匹配目标的潜在语义属性中,匹配目标属性包含多种属性项的情况最后得到的结果明显比匹配目标属性仅包含一种属性项最后得到的匹配结果会提升20-30%的精准性。因此本发明均会计算出匹配目标属性包含多种属性项,再进行属性比较。
96.本发明还提供一种用于实现上述基于潜在语义及因子优化的协同过滤方法的系统,包括:
97.获取模块,用于获取匹配目标的所有关联的被匹配目标的匹配目标属性;用于获取待匹配属性;
98.特征提取模块,用于根据匹配目标属性,获取匹配目标的潜在语义属性;
99.特征匹配模块,用于根据待匹配属性和匹配目标的潜在语义属性,获得所有待匹配属性的影响因子,影响因子决定了对应目标属性在匹配时的权重修正;
100.匹配度计算模块,用于根据待匹配属性的影响因子,获取匹配度。
101.本发明将协同过滤的相似比较从现有技术转变为本发明的技术方案;
102.现有技术为:被匹配目标间的比较或匹配目标之间的比较;
103.本发明为:被匹配目标与匹配目标的潜在语义项之间或匹配目标与被匹配目标的潜在语义项之间的属性比较;
104.由于潜在语义项与比较方的匹配度也就是对应项与比较方的匹配度,这样本发明就为被匹配目标与匹配目标建立起了直接沟通的桥梁。
105.实例1:
106.假设匹配目标为商品a,被匹配目标为用户;用户的匹配目标属性有6个特征,购买商品a的用户有7位:
107.标签类属性的匹配目标的潜在语义属性计算:以出现过每个标签类属性的属性标
签及其对应出现的次数作为匹配目标的潜在语义属性。
108.数值类属性的匹配目标的潜在语义属性计算:以每个相应数值类属性的所有属性值的有效平均值。有效平均的取法:对标准差过大的数据集,剔除过大或过小的之后再进行平均。
109.数据为空的数据不参与计算。
110.如下表1所示:
111.表1
112.[0113][0114]
匹配度=所有匹配目标属性的影响因子的总和/匹配目标属性总数;
[0115]
相同特征取值的规则:
[0116]
只要比较的双方有一个取值为空,此匹配目标属性的影响因子分数为0;
[0117]
对于匹配目标属性中的标签类属性:
[0118]
若待匹配的用户的标签类属性与匹配目标的潜在语义属性相匹配,该项匹配目标属性的影响因子分数为:匹配特征的分值/所有匹配特征对应分值的最大值;
[0119]
若待匹配的用户的匹配目标属性中的标签类属性与目标潜在语义属性不相匹配,该项匹配目标属性的影响因子分数为0。
[0120]
比较数值型特征:
[0121]
待匹配属性的影响因子=相应的有效平均值/该待匹配属性的属性值;
[0122]
假设待匹配的用户的6个特征如下表2所示:
[0123]
表2
[0124][0125]
此匹配度=(1+0.75+0.952+0.917+0+1)/6=0.77
[0126]
用户a与商品a的匹配度即为0.77。
[0127]
实例2:
[0128]
假设商品有6个特征,用户a购买过7种商品:
[0129]
假设匹配目标为用户a,被匹配目标为商品;商品的匹配目标属性有6个特征,用户a购买过7种商品:
[0130]
标签类属性的匹配目标的潜在语义属性计算:以出现过每个标签类属性的属性标签及其对应出现的次数作为匹配目标的潜在语义属性。
[0131]
数值类属性的匹配目标的潜在语义属性计算:以每个相应数值类属性的所有属性值的有效平均值。有效平均的取法:对标准差过大的数据集,剔除过大或过小的之后再进行
平均。
[0132]
数据为空的数据不参与计算。
[0133]
如下表3所示:
[0134]
表3
[0135][0136][0137]
匹配度=所有匹配目标属性的影响因子的总和/匹配目标属性总数;
[0138]
相同特征取值的规则:
[0139]
只要比较的双方有一个取值为空,此匹配目标属性的影响因子分数为0;
[0140]
对于匹配目标属性中的标签类属性:
[0141]
若待匹配的商品的标签类属性匹配目标的潜在语义属性,该项匹配目标属性的影响因子分数为:匹配特征的分值/所有匹配特征对应分值的最大值;
[0142]
若待匹配的商品的匹配目标属性中的标签类属性不匹配目标的潜在语义属性,该项匹配目标属性的影响因子分数为0。
[0143]
对于匹配目标属性中的数值类属性:
[0144]
比较数值型特征:
[0145]
待匹配属性的影响因子=相应的有效平均值/该待匹配属性的属性值;
[0146]
假设待匹配的商品的6个特征如下表4所示:
[0147]
表4
[0148][0149]
匹配度=(1+0.75+0.952+0.917+0+1)/6=0.77
[0150]
商品a与用户a的匹配度即为0.77。
[0151]
最后,还需要注意的是,以上列举的仅是本发明的若干个具体实施例。显然,本发明不限于以上实施例,还可以有许多变形。本领域的普通技术人员能从本发明公开的内容直接导出或联想到的所有变形,均应认为是本发明的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1